Predicting Low Birth Weight in Big Cities in the United States Using a Machine Learning Approach
Yulia Treister-Goltzman

TL;DR
This study uses machine learning to predict low birth weight rates in large U.S. cities, identifying key factors like poverty and prenatal care.
Contribution
The study introduces a machine learning approach to predict low birth weight at the population level in big U.S. cities.
Findings
Machine learning models achieved high performance with R-squared values above 0.79.
Key predictors included chlamydia infection rates, racial segregation, and prenatal care.
The Best subset model provided the best balance of accuracy with only four predictors.
Abstract
Objective: Low birth weight is a serious public health problem even in developed countries. The objective of this study was to assess the ability of machine learning to predict low birth weight rates in big cities in the USA on an ecological/population level. Study design: The study was based on publicly available data from the Big Cities Health Inventory Data Platform. The collected data related to the 35 largest, most urban cities in the United States from 2010 to 2022. The model-agnostic approach was used to assess and visualize the magnitude and direction of the most influential predictors. Results: The models showed excellent performance with R-squared values of 0.82, 0.81, 0.81, and 0.79, and residual root mean squared error values of 1.06, 0.87, 1.03, 0.99 for KNN, Best subset, Lasso, and XGBoost, respectively. It is noteworthy that the Best subset selection approach had a high…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
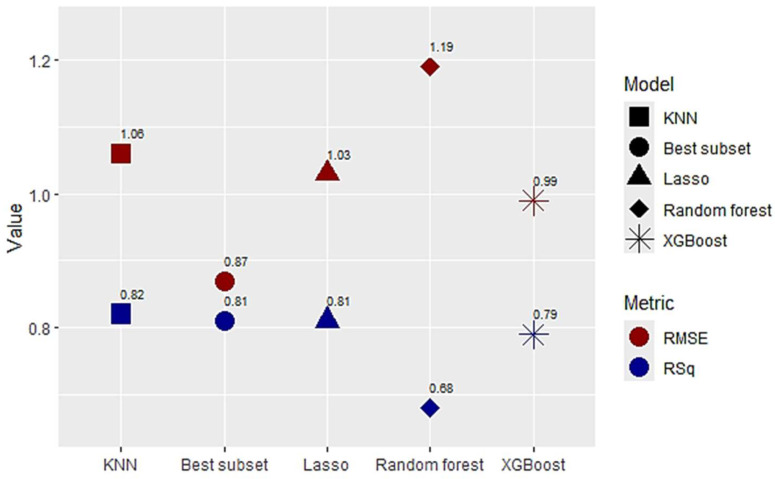 Figure 1
Figure 1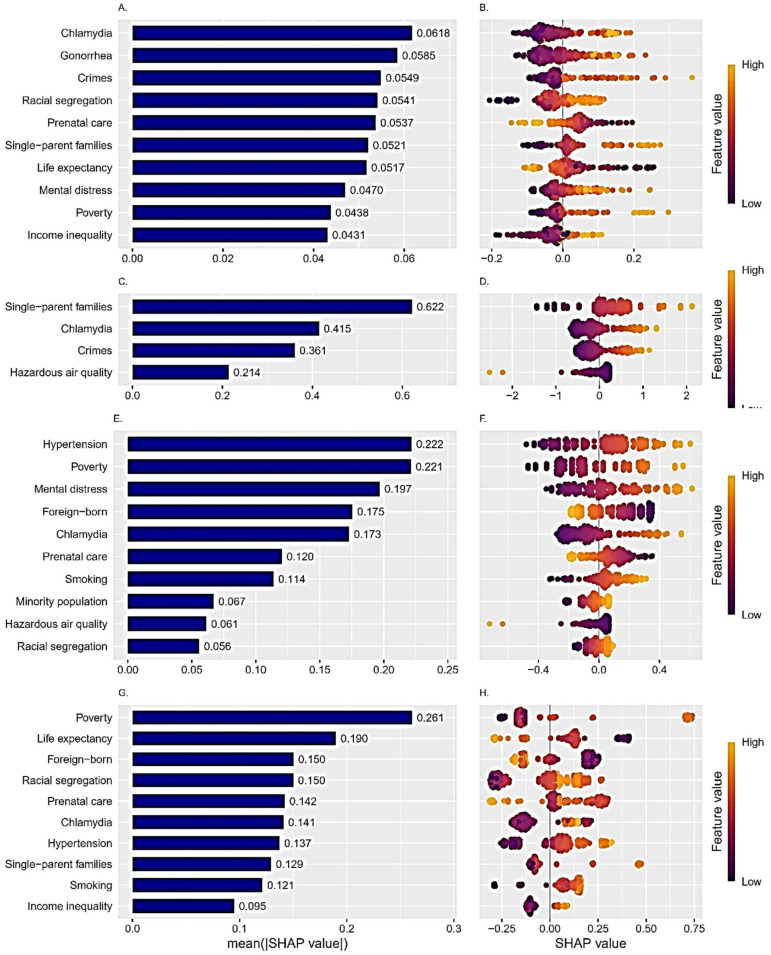 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHealth disparities and outcomes · Birth, Development, and Health · Insurance, Mortality, Demography, Risk Management
1. Introduction
Low birth weight (LBW), defined as babies with a birth weight under 2500 g, is a well-acknowledged risk-factor for perinatal and infant mortality, and for subsequent cardio-vascular, respiratory and cognitive disorders in adulthood. In 2020, 19.8 million newborns, an estimated 14.7% of all babies born worldwide, had LBW. Global progress on reducing LBW prevalence has been slow. In some regions, including South Asia, West and Central Africa, Eastern and Southern Africa, Europe, and Central Asia, the prevalence of LBW decreased slightly from 2000 to 2020. Several other regions, including Latin America, the Caribbean, North America, the Middle East, North Africa, East Asia and the Pacific demonstrated no change or a slight increase in prevalence from 2000 to 2020 [1]. In the United States the prevalence of LBW increased between 2016 and 2022 from 7.6% to 8.2% [2]. Preterm birth and LBW remained the second leading cause of infant death in the United States, accounting for 15% of infant deaths in 2021. The infant mortality rate among infants with LBW in the United States was 41.8 per 1000 live births in 2021, even higher among short-gestation and LBW infants (80.7 per 1000 live births) [3]. A large cohort study that assessed long-term morbidity associated with LBW showed significantly increased risks for obesity, hypertriglyceridemia, high LDL-cholesterol, high blood pressure, metabolic syndrome, non-alcoholic fatty liver disease, allergic and atopic symptoms, and lack of tertiary education, with risks increased by 1.11–1.35 for different pathologies [4]. LBW is a multifactorial phenomenon and many maternal, environmental, and social factors have been linked to LBW. The main maternal factors associated with LBW are malnutrition/poor diet, parity, obstetric history and antenatal care, infectious diseases, including sexually transmitted diseases, smoking, alcohol abuse, maternal age, and mental distress [5,6,7]. Hypertension during pregnancy is one of the leading factors for LBW, while diabetes mellitus and obesity are usually associated with higher infant birth weight [8,9]. Environmental factors such as ambient air pollution and extreme climate conditions can also have an impact [10]. Among social factors, low education, low income, and low socio-economic status were reported to be related to increased risk of LBW [7,11]. As a serious public health problem, even in developed countries [12], LBW stands at the intersection between medicine, environmental sciences, and sociology, hence a better understanding of this problem on the population level is crucial. The machine learning (ML) approach is a very promising tool to deal with complex and high-dimensional data and has already been introduced to predict LBW in several studies [11,13,14,15] in which multiple ML approaches were tested. These studies were carried out on an individual, not a population, level. They evaluated the performance of classifier algorithms, as LBW was treated as a binary outcome. The XGBoost algorithm showed an excellent predictive performance in two studies [11,14], as did the random forest in two studies [13,14], the deep learning feed forward in one study [13], and the category boosting and gradient boosting decision tree in one study [15]. In contrast, the logistic regression and decision tree showed average performance metrics [11,13,14,15].
Ecological studies, in which the unit of observation is the population or the community, allow for the comparison of aggregated data across different areas and the investigation of population-level exposures. Predicting LBW at a population level can direct and focus interdisciplinary initiatives at state and local levels, enabling timely interventions and mitigating adverse outcomes.
The primary goal of the present study was to assess the performance of ML approaches in predicting LBW in big US cities at a population level and to compare the predictive ability of different models. The secondary goal was to assess the relative importance of the contributing factors, highlighting the most important variables in the prediction process.
2. Methods
This ecological study was based on publicly available data from the Big Cities Health Inventory Data Platform (BCHI) [16]. The BCHI was launched by the Big Cities Health Coalition with funding from the Centers for Disease Control and Prevention and is now maintained by the Drexel University Urban Health Collaborative in partnership with the Big Cities Health Coalition. BCHI contains over 150,000 standardized data points for more than 120 health social, environmental, and health indices for the 35 largest, most urban cities in the United States from 2010 to 2022 [16]. Data on the rate of LBW in the BCHI are based on natality files from the National Vital Statistics System of the National Center for Health Statistics [16] and are expressed as a continuous variable of the number of LBW infants per 100 live births. Common sense, expert opinion, and findings from prior research in the domain were used to select candidate LBW predictors for this study.
Statistical analyses were carried out using R version 4.3.1, using the packages “caret”, “rsample”, “recipes”, “yardstick”, “randomForest”, “xgboost”, “leaps”, and “shapviz”.
Five statistical regression learning models—K-nearest neighbors (KNN), Best subset selection, Lasso regression, Random forest, and Extreme gradient boosting (XGBoost)—were trained. KNN is a simple and intuitive algorithm that makes predictions by finding the K nearest data points to a given input and averaging their target values [17]. Best subset selection performs selection of the best set of predictors by identifying the best model that contains a given number of predictors, where the best is quantified using the residual sum of squares [17]. Lasso stands for Least Absolute Shrinkage and Selection Operator. It facilitates automatic feature selection by adding a penalty term to the residual sum of squares, which is multiplied by the regularization parameter (lambda or λ). This shrinks some of the coefficients towards zero, thus reducing the importance or eliminating some of the features from the model altogether, resulting in automatic feature selection [17]. The bootstrapping Random Forest algorithm combines ensemble learning methods with the decision tree framework to create multiple randomly drawn decision trees from the data, averaging the results to output a new result that often leads to strong predictions [17]. Finally, XGBoost is an ensemble learning method that uses parallel gradient tree boosting and combines the predictions of multiple weak models to produce a stronger prediction [17].
The cases were randomly assigned to either the “training set” (70%) or the “test set” (30%) in all models. In the training set, internal validation was carried out with the help of 5-fold cross-validation. Several preprocessing procedures were performed. Given the dependency between observations related to the same city, data leakage of the observations from the same city was prevented between training and validation sets, during internal (cross-validation) and external (training and test set) validation. Standardization of the independent variables was carried out using the KNN and Lasso regression models, preventing features with larger magnitudes from disproportionately influencing the distance calculation in KNN, and improving the model’s ability to select important features and reducing the magnitude of the model coefficients in Lasso. The grid search method, which involves training a model for possible combinations of hyperparameters in a predefined set, was used for hyperparameter tuning.
Thirty-three potential predictors were assessed to predict the percent of infants born with LBW in the 35 big cities over 13 years (i.e., 455 observations).
Table S1 presents the description of the chosen predictors, that were grouped by four domains related to health/morbidity, climate/built environment, social/economic, and demographic factors. Missing datapoints were imputed by the value from the same variable for the same city from the nearest adjacent year.
The performance parameters of the prediction models were externally validated using the test set. Metrics, including R-squared (RSq) (the proportion of the variance of the dependent variable that can be explained by the regression), and residual root mean squared error (RMSE) (average difference between predicted and actual empirical values of data) were used to assess the predictive power of the models.
Ultimately, the best performing models were analyzed for the importance of their features. The model-agnostic approach was used. Model-agnostic methods do not account for the structure of the model, can be applied to any ML algorithms, and work on the ‘black box’ model approach. They obtain explanations by perturbing and mutating the input data and obtaining the sensitivity of the performance of these mutations with respect to the original data performance. SHAP (SHapley Additive exPlanations) values are a way to explain the output of any ML model. It uses a game theoretic approach that measures each player’s contribution to the outcome. In ML, each feature is assigned a SHAP value representing its contribution to the model’s output. Features with positive SHAP values positively impact the prediction, while those with negative values have a negative impact. The magnitude is a measure of how strong the effect is.
Many of the potential predictors could be highly correlated, i.e., obesity, hypertension, inactivity, and diabetes, or poverty and crime. Multicollinearity does not alter the predictive ability of the models, so potential multicollinearity did not affect the primary goal of the present study, i.e., assessing the performance of ML approaches in predicting LBW. Variable selection methods and modified estimator methods by regularization and penalty mechanisms are intrinsically used to solve multicollinearity in machine learning models [18,19]. It is well-known that the values of standard regression coefficients depend heavily on the collinearity of the predictors. But SHAP values, used in a model-agnostic interpretation, calculate feature contributions by averaging across all permutations of the features joining the model. This enables SHAP values to control for variable interactions. SHAP values are additive, meaning that you can attribute a portion of the model’s predictive value to each of the observation’s input variables. For example, if you have a model that is built with three input variables, then you can write the predicted value as the summation of the corresponding SHAP values plus the average predicted value across the input data set. Therefore, the secondary goal of the study, assessing the relative importance of the contributing factors, was also invulnerable to possible multicollinearity [20].
3. Results
Details on the missing values of the predictor variables are provided in Table S2.
Most variables had no missing values, while a few had less than 5% missing values. The only valuable with a substantial number of missing values was the uninsured population (105 (23.08%)).
Descriptive statistics of the characteristics of the study sample are presented in Table 1. The mean (SD) percent of LBW births was 9.11 (1.89), with the highest percent in Detroit ((14.2 (0.83)) and the lowest in Seattle ((6.51 (0.27)). The highest prevalence of noncommunicable diseases, such as obesity, diabetes, hypertension, and mental distress, was observed in Detroit, with means (SDs) of 35.5 (1.53), 18.00 (0.33), 46.30 (0.79), and 18.6 (1.52), respectively. Eighteen percent of the adult population in the big cities in the USA smoked and more than 25% did not engage in physical activity. Among individual cities these numbers were highest for Detroit at 29.00 (68.80) and 36.60 (1.22), respectively. Various social indices such as poverty level, unemployment, single-parent families, and violent crimes were also highest in Detroit with means (SDs) of 35.50 (3.26), 19.60 (5.06), 21.50 (1.68), and a rate of 2032.00 (116.00 per 100,000), respectively. In Seattle the mean rates (SDs) of diabetes, physical inactivity smoking, and unemployment were the lowest at 6.62 (0.34), 13.40 (0.66), 10.80 (57.20), and 4.98 (1.00), respectively.
Figure 1 displays the performance metrics (RSq, RMSE) of the five trained ML approaches on the test set. The models showed excellent performance with RSq results of 0.82, 0.81, 0.81, and 0.79, and RMSE results of 1.06, 0.87, 1.03, 0.99 for KNN, Best subset, Lasso, and XGBoost, respectively. The Best subset selection approach had a high RSq, but the lowest RMSE, with a subset of only four predictors. The Random forest model demonstrated a slightly worse performance with an RSq of 0.68 and an RMSE of 1.19. Table 2 shows tuning parameters selected by a grid search of the training set for each model.
Importance of the Predictors
Figure 2 presents an analysis of the importance of the variables in the best performing models using the model-agnostic approach, i.e., KNN, Best subset, Lasso and XGBoost. For each model (except for the Best subset in which the best performance was observed with four predictors), the top ten most influential predictors are shown. The left column of plots shows the absolute mean SHAP values of the predictors. The higher the value, the more significant the influence of this predictor in the model. The right column represents a set of beeswarm plots, where each dot corresponds to an individual subject in the study. The color represents the size of the feature value (purple color—low values, and yellow—higher values of the feature). The dots’ positions on the X axis show the positive or negative impact of each individual measurement on the prediction. The combination of the two columns facilitates comprehension of the strength and direction of the impact. The rate of chlamydia infection was an influential predictor of LBW rate in all four models. High rates of infection were associated with a higher prevalence of LBW. Influential predictors that appear in three of four models are racial segregation, single-parent families, poverty (high values were linked to higher prevalence of LBW), and prenatal care (low values were linked to higher prevalence of LBW). Several predictors (violent crime rate, life expectancy, mental distress, income inequality, hazardous air quality, prevalence of hypertension, percent of foreign-born citizens, and smoking) were influential in two models, with positive association for all, except life expectancy, where low values were associated with a higher prevalence of LBW.
4. Discussion
LBW is a public health problem of global concern. A multitude of health-related, social, environmental, and demographic factors are associated with it. In the present study, the performance of five different ML algorithms was evaluated, at the population level, in predicting the prevalence of LBW. Four of the five evaluated models had excellent predicting performance: KNN, best subset selection, and Lasso had an RSq of above 0.80, and XGboost 0.79. One of the simplest approaches, best subset selection, which had the lowest RMSE (0.87), predicted LBW with only four variables: single-parent families, rate of chlamydia infection, violent crimes rate, and hazardous air quality. All these variables were influential in the other models of the study as well. Single-parent family was reported as a risk-factor for LBW in two studies [21,22], though living without a partner had no effect on LBW in a population-level study from Spain [23]. A large body of evidence exists on the association of infection with chlamydia and multiple adverse pregnancy outcomes including LBW [24,25]. Several studies had previously demonstrated the negative impact of maternal exposure to neighborhood crime on infant weight [26,27,28]. Common environmental exposures, exacerbated by climate change, demonstrated significant associations with serious adverse pregnancy outcomes across the US and in other countries [11,29,30]. It should be noted that almost all the factors with the largest impact on models’ predictive performances were influential predictors in more than one model. The association of these factors with LBW is supported by strong scientific evidence as well [16,29,31,32,33,34]. The important predictors found in the present study belonged to different domains that were related to health/morbidity, and environmental, demographic, and socio-economic factors, highlighting the complexity of the problem of LBW and the need for a multidisciplinary approach to it.
Identification of the most influential predictors at the population level can inform healthcare authorities on more effective ways to tackle LBW. Proposed interventions include screening for chlamydia infections, which was found to be an influential predictor in four models, or increasing the rates of prenatal care visits, e.g., by cash-transfer programs. Screening and early treatment of mental distress and hypertension and the promotion of smoking cessation among women of childbearing age could also be helpful. At the municipality level, interventions should focus on decreasing racial segregation and support for single-parent families.
Large for gestational age births are also associated with short- and long-term complications, so future studies should address the predictive capacity of the ML approach to this problem [35].
Limitations and strengths. The main limitation of the present study was assessing LBW as a single entity, not dividing it into term and preterm LBW births. These two obstetric conditions have many common causes, including maternal malnutrition, poverty, black race, narrow child spacing, multiple gestations, low maternal education, poor antenatal care, substance abuse, smoking, emotional and physical stress, and illnesses. Some of the causes, however, are unique to preterm LBW (induction or cesarean section for maternal complications such as pre-eclampsia, some infectious and inflammatory processes, including chorioamnionitis, bacterial vaginosis, bacteriuria) [7]. Unfortunately, the BCHI data platform only includes data on preterm births since 2016, hence this factor could not be included. Another reservation is the questionable external validity of our findings to other settings, such as rural settings or small cities. Large urban areas tend to have better health outcomes with urban populations often enjoying higher access to healthcare, social services, and economic opportunities. However, urban areas can also face challenges like increased risk of infectious diseases and pollution-related health issues. Thus, the impact of the examined factors on LBW can be different in different settings. On the other hand, the assessment of the predictive ability of ML approaches on the prevalence of LBW at the population level in large cities was the goal of the present study.
Among the strengths of the study are the multitude of ML algorithms and predictors from different domains that were assessed, including predictors that were not included in previous studies with an ML approach.
5. Conclusions
KNN, Best subset, Lasso, and XGBoost ML algorithms showed excellent performance for the prediction of LBW rates in the big cities. Identification of the influential predictors, especially those that are significant in several models, could help local and state authorities and health policy decision makers to tackle this important health problem more effectively.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1UNICEF The United Nations Children’s Fund Data. Monitoring the Situation of Children and Women 2025 Available online: https://data.unicef.org/topic/nutrition/low-birthweight/(accessed on 27 May 2025)
- 2Zheng S. Cao Y. Strasser S. Wei H. Prevalence and risk factors of low birth weight in the United States: An analysis of 2016–2021 data Am. J. Hum. Biol.202436 e 2401610.1002/ajhb.2401637974547 · doi ↗ · pubmed ↗
- 3Ely D.M. Driscoll A.K. Infant mortality in the United States, 2021: Data from the period linked birth/infant death file Natl. Vital Stat. Rep.20237211937748084 · pubmed ↗
- 4Amadou C. Ancel P.Y. Zeitlin J. Ribet C. Zins M. Charles M.A. Long-term health in individuals born preterm or with low birth weight: A cohort study Pediatr. Res.20259757758510.1038/s 41390-024-03346-638965395 PMC 12015107 · doi ↗ · pubmed ↗
- 5Bianchi M.E. Restrepo J.M. Low Birthweight as a Risk Factor for Non-communicable Diseases in Adults Front. Med.2021879399010.3389/fmed.2021.793990 PMC 877086435071274 · doi ↗ · pubmed ↗
- 6Kumar M. Saadaoui M. Al Khodor S. Infections and Pregnancy: Effects on Maternal and Child Health Front. Cell. Infect. Microbiol.20221287325310.3389/fcimb.2022.87325335755838 PMC 9217740 · doi ↗ · pubmed ↗
- 7Cutland C.L. Lackritz E.M. Mallett-Moore T. BardajíA. Chandrasekaran R. Lahariya C. Nisar M.I. Tapia M.D. Pathirana J. Kochhar S. Low birth weight: Case definition & guidelines for data collection, analysis, and presentation of maternal immunization safety data Vaccine 2017356492650010.1016/j.vaccine.2017.01.04929150054 PMC 5710991 · doi ↗ · pubmed ↗
- 8Kong L. Nilsson I.A.K. Gissler M. Lavebratt C. Associations of Maternal Diabetes and Body Mass Index With Offspring Birth Weight and Prematurity JAMA Pediatr.201917337137810.1001/jamapediatrics.2018.554130801637 PMC 6450270 · doi ↗ · pubmed ↗