Machine Learning Identifies a Parsimonious Differential Equation for Myricetin Degradation from Scarce Data
Andrew Fulkerson, Ipek Bayram, Eric A. Decker, Carlos Parra-Escudero, Jiakai Lu, Carlos M. Corvalan

TL;DR
This paper uses machine learning to model how myricetin, a food antioxidant, degrades in oil, even with limited data, helping improve food shelf life.
Contribution
The study introduces a novel machine learning method combining neural differential equations and symbolic regression for scarce data scenarios.
Findings
The model accurately predicts myricetin degradation trends across various initial concentrations.
It successfully extrapolates beyond the training data, showing robustness in complex food systems.
The approach provides a framework for enhancing antioxidant efficiency in food formulations.
Abstract
Accurately modeling the degradation of food antioxidants in oils is essential for understanding oxidative stability and improving food shelf life. This study presents an innovative machine learning approach integrating neural differential equations and sparse symbolic regression to derive a parsimonious differential equation for myricetin degradation in stripped soybean oil. Despite being trained on a small experimental dataset, the model successfully predicts degradation trends across a wide range of initial concentrations and extrapolates beyond the learning data. This capability demonstrates the robustness of machine learning for uncovering governing equations in complex food systems, particularly when experimental data is scarce. Our findings provide a framework for improving antioxidant efficiency in food formulations.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
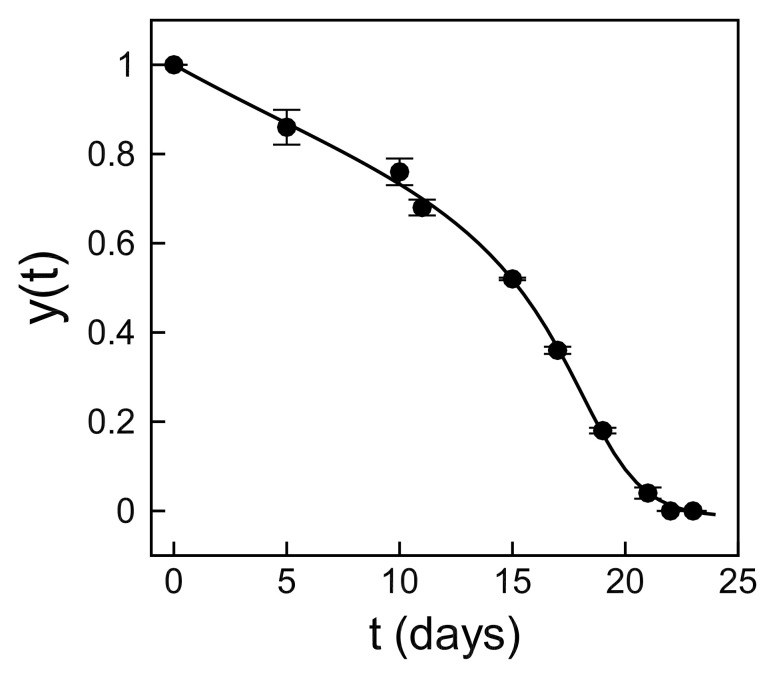 Figure 1
Figure 1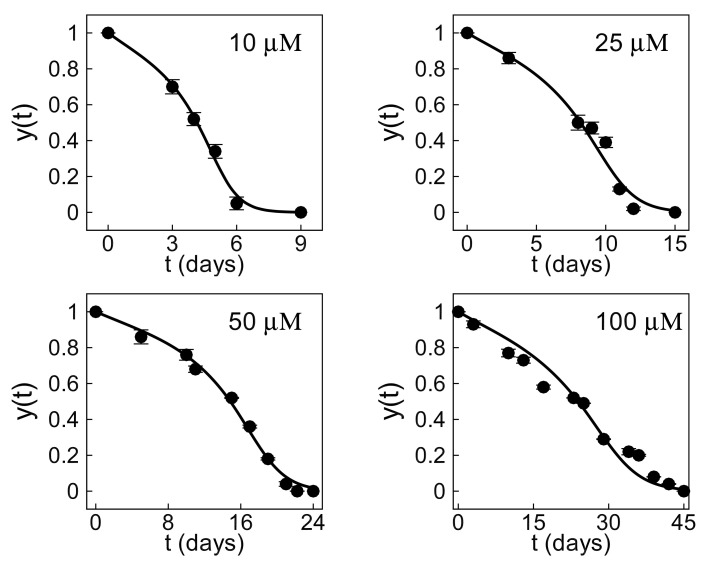 Figure 2
Figure 2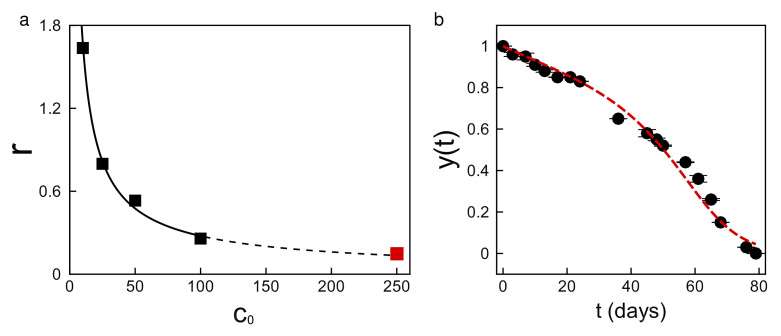 Figure 3
Figure 3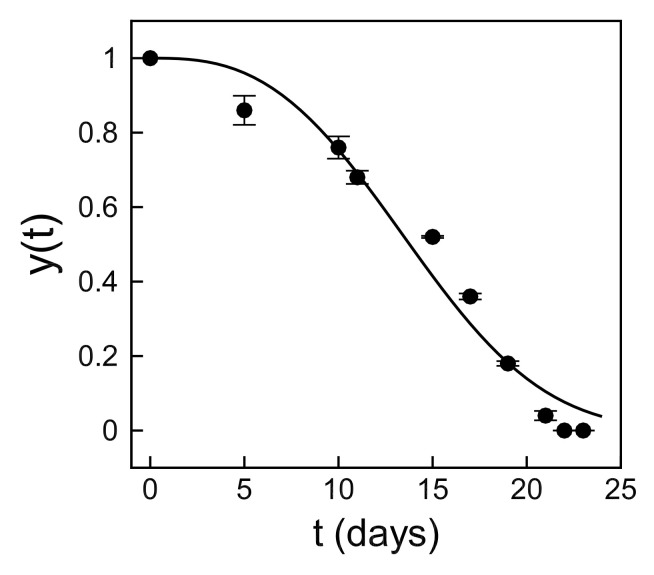 Figure 4
Figure 4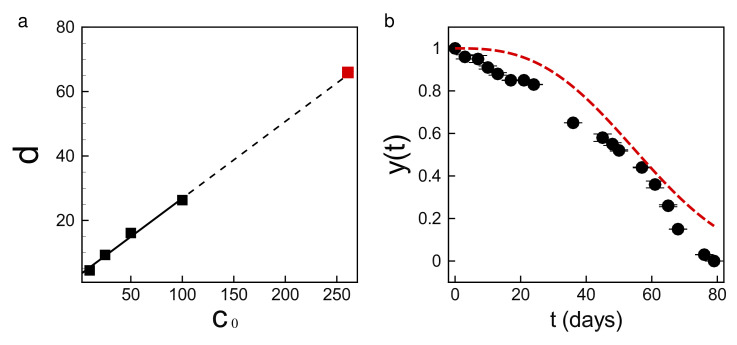 Figure 5
Figure 5- —USDA-NIFA Agriculture and Food Research Initiative Program
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpectroscopy and Chemometric Analyses · Metabolomics and Mass Spectrometry Studies · Antioxidant Activity and Oxidative Stress
1. Introduction
Food scientists need to characterize the breakdown of antioxidants in food oils to understand and control factors affecting lipid oxidation and stability, and thus the shelf life of foods. Mathematical modeling provides a critical foundation for quantitative analysis and has long been used to study quality changes in food, including oxidative stability in emulsions [1,2,3,4,5,6]. Traditional modeling approaches often rely on fitting experimental observations to pre-assumed models based on expert knowledge [1]. While this approach has successfully forecasted food shelf life, it can be challenging when experimental data is scarce [7].
Myricetin, a flavonol with potent antioxidant properties, plays a key role in enhancing the oxidative stability of bulk oil [8] and food emulsions [9,10]. Its ability to inhibit lipid oxidation, particularly of linoleic acid—one of the major components of soybean oils—makes it highly relevant in food preservation studies [11,12]. The inhibition of lipid oxidation prevents the formation of free radicals, which can lead to emulsion breakdown [12,13,14].
To address the challenge of extracting governing equations from limited experimental observations, we introduce an innovative machine learning approach integrating neural differential equations (NDEs) and sparse symbolic regression. NDEs learn a neural network representation of the degradation rate, as they are a powerful new class of models that integrate dynamical systems and deep learning [15,16,17]. They have been successfully applied to problems such as reduced-order models of turbulence [18] and optimizing treatment strategies for HIV [19]. By augmenting limited experimental data with NDEs, we enable sparse symbolic regression [20] to identify a governing equation for the degradation process without prior assumptions about the underlying dynamics. Sparse symbolic regression, which focuses on deriving parsimonious differential equations [21], has been successfully applied to diverse scientific domains ranging from epidemiology [22] to complex fluid dynamics [23].
In this study, we leverage machine learning to develop a predictive differential model for myricetin degradation in soybean oil using a small experimental dataset. Our approach seamlessly integrates neural differential equations and sparse symbolic regression to extract a governing equation that accurately describes myricetin degradation across various initial concentrations. The results demonstrate that this model extrapolates beyond the training data, offering a powerful tool for uncovering reduced-order equations in food systems where experimental data is scarce.
2. Material and Methods
Soybean oil was obtained from a store in Hadley, MA, USA, and medium chain triacylglycerol (MCT) was purchased from Warner Graham Company (Baltimore, MD, USA), and was kept frozen at −80 °C until use. Hexane was bought from Fisher Scientific (Fair Lawn, NJ, USA), and myricetin was purchased from Combi-Blocks Inc. (San Diego, CA, USA). Activated charcoal, silicic acid, ethanol, and 1,4-dioxane were purchased from Sigma-Aldrich (St. Louis, MO, USA).
2.1. Preparation of Stripped Soybean Oil
The isolation of soybean oil triacylglycerols was performed using the method described by Boon et al. [24] to eliminate the impact of endogenous antioxidants and prooxidants. Prior to the experiment, silicic acid was washed seven to eight times to remove any impurities and dried in an incubator at 125 °C for 24 h. The column was packed with 22.5 g of silicic acid, 5.25 g of activated charcoal, and 22.5 g of silicic acid, with each layer being dissolved in approximately 40 mL of hexane, followed by the elution of excess hexane. Soybean oil (30 g) and hexane (30 mL) were combined and added into the packed chromatographic column. Stripped soybean oil (SSO) was collected by eluting a total of 270 mL of hexane over the course of three to four hours. A round-bottom flask used to collect SSO plus hexane mixture was placed on ice to prevent further lipid oxidation during the stripping process. Similarly, aluminum foil was used to cover the chromatographic column to minimize light-induced oxidation. At a temperature of 27 °C, hexane was separated from SSO utilizing a vacuum rotary evaporator (Model RE 111, Buchi, Flawil, Switzerland). The recovered SSO was flushed with nitrogen for 10 min to remove any traces of hexane, and then stored at −80 °C until use.
2.2. Preparation of Samples for Oxidation Study
The lipid oxidation study used a 50:50 mixture of oxidizable stripped soybean oil (SSO) and non-oxidizable medium chain triacylglycerols (MCT) to reduce waste associated with excess oil stripping. Ethanol stock solution of myricetin was prepared and pipetted into the oil blend to achieve final myricetin concentrations of 10, 25, 50, 100, and 250 M. The samples were mixed on a magnetic stirrer at 300 rpm at 4 °C overnight to ensure that the myricetin was distributed evenly throughout the oil. The samples (0.5 mL) were placed in 10 mL Supelco GC headspace vials, capped with aluminum caps with PTFE/silicone septa, and stored in the dark at 60 °C. Three vials from each sample group were taken on a regular basis to analyze the myricetin degradation kinetics.
2.3. Measurement of Myricetin Concentrations
The concentration of myricetin during oxidation was determined periodically using a Shimadzu Prominence-i LC-2030C HPLC (Shimadzu, Kyoto, Japan) having a Supelcosil LC-Diol column (25 cm by 4.0 mm, particle size 5 M, Bellefonte, PA, USA), a Supelguard LC-Diol guard column (2 cm by 4.0 mm, particle size 5 M) and an in-built photodiode array detector (PDA). The samples were prepared by dissolving 125 L oil samples in 1 mL of 1,4-dioxane and filtering them into the HPLC vials using 0.22 M PTFE syringe filters (Fisher Scientific, Pittsburgh, PA, USA). A total of 40 L of samples were injected with an autosampler into the analytical column at 37 °C. The isocratic flow of 40% hexane and 60% 1,4-dioxane at a mobile phase flow rate of 1 mL/min was used to detect myricetin. Myricetin was identified and quantified at about 3.9 min of retention time over a 10 min separation period at 370 nm, the wavelength of maximal absorbance. The remaining myricetin percentage on a given day was calculated by dividing the measured peak area by the measured peak area of day zero. Sampling time points were selected based on prior studies of antioxidant degradation kinetics in bulk oils, which typically occur over several days [10,25]. This schedule ensured adequate resolution of the degradation profile while minimizing unnecessary sampling.
2.4. Machine Learning Approach for Myricetin Degradation
To derive a governing equation for myricetin degradation, we employed a machine learning framework combining neural differential equations (NDEs) and sparse symbolic regression. The NDE establishes a data-driven representation of the degradation process, allowing us to model the rate of change using a neural network. Sparse regression then extracts a parsimonious differential equation by selecting relevant monomial terms through regularization techniques. A detailed description of this approach, including implementation specifics, is provided in Section 3.1 and Section 3.2 of Section 3.
3. Results and Discussion
To demonstrate our machine learning approach, we first measured the degradation of myricetin in soybean oil over a range of initial concentrations from 10 to 100 M, as described in Section 2, Methods. Table A1 in Appendix A shows the measurement results. The concentration data were normalized by dividing each data point by the corresponding initial concentration.
As discussed in the Introduction, our approach to learning the myricetin dynamics consists of two steps:
- First, we solve a neural differential equation (NDE) [15,16] to augment the limited experimental observations. We demonstrate the effectiveness of this method using the observations for the intermediate myricetin concentration of 50 M (Figure 1).
- Then, we use the NDE solution in a sparse regression problem [21] to discover a parsimonious differential equation underlying the degradation dynamics (Equation (3)).
We elaborate on the results of the neural differential equation, the sparse regression, and the model’s predictions in the following sections. For completeness, we also outline a conventional approach based on assuming a model beforehand in Appendix B.
3.1. Neural Differential Equation
Standard machine learning models require a large amount of training data. This can be a limitation when only scarce experimental data is available. To overcome this limitation, we first built a data-driven representation of the myricetin dynamics using a neural differential equation to augment the experimental dataset. An NDE is essentially a differential equation in which the derivative is specified by a neural network [16]. The extra information added by imposing a differential form allows the neural network to learn from a smaller amount of training data.
The NDE used in this work is a simple ordinary differential equation for the normalized myricetin concentration , where the degradation rate is described by a neural network as
The subscript represents the vector of parameters (weights and biases) of the neural network. We trained Equation (1) on experimental measurements to learn the parameters that represent the underlying dynamics. The NDE (Equation (1)) was solved using a hybrid numerical approach. The dynamics of ordinary differential equations were integrated through an adaptive Runge–Kutta 4th/5th order (RK45) scheme, while the unknown term was parameterized by a neural network. Specifically, we used a fully connected feedforward neural network that features a shallow architecture: an input layer, two hidden layers, each with five neurons, and an output layer. The hidden layers used the Rectified Linear Unit (ReLU) activation function, while the output layer, yielding a single output for each time step, employed a linear activation suitable for the final regression. This parsimonious architecture was chosen following an empirical evaluation of networks with varying depths up to 50 layers and widths from 3 to 100 neurons, balancing model capacity and generalization. The network parameters were optimized through backpropagation using automatic differentiation [26,27] to minimize the loss of the mean squared error (MSE) between the numerical solution and the experimental measurements (at M). Optimization was performed using the Adam optimizer [28] with an initial learning rate of 0.001. Due to the limited size of the dataset, the full batch gradient descent was utilized, achieving convergence in fewer than 500 iterations with a final training MSE of . The models were implemented in Python 3.12 using Keras [29] with the TensorFlow 2.14 backend [30] and trained on a Nvidia GeForce RTX GPU, NVIDIA Corp., Santa Clara, CA, USA.
Figure 1 illustrates the model-agnostic solution of the neural differential equation trained on measurements for the intermediate initial concentration of 50 M. The solid line shows the learned degradation dynamics, while the symbols show the experimental measurements. The NDE was able to learn a good representation of the dynamics, even though it was trained on a small experimental dataset using a shallow network. Importantly, this is a model-agnostic representation, which avoids imposing an arbitrary analytical form to describe the degradation rate in the differential equation. The neural network cannot generalize nor predict beyond the learning data, but it does provide an augmented high-dimensional representation of the experimental data and their derivatives. These high-dimensional solutions can be used to find an analytical expression for the differential equation using sparse regression.
3.2. Sparse Identification of Nonlinear Dynamics
In a second step, we used sparse regression to identify an analytical expression for the differential degradation model able to generalize to different initial concentrations. We applied the Sparse Identification of Nonlinear Dynamics (SINDy) algorithm. SINDy is an effective machine-learning technique for extracting parsimonious dynamics from high-dimensional time-series data. A comprehensive description of the SINDy algorithm, along with its source code implementation, is available in the original publication by Champion et al. [31]. Accordingly, this section provides a brief outline within the context of our dataset.
The implementation is straightforward using the information provided by Equation (1). We construct two high-dimensional input vectors and . The vector is the augmented vector of concentrations generated by sampling the NDE solution at several time steps with . The vector is the corresponding vector of time derivatives generated by feeding the vector to the trained neural network . Note that represents the degradation rate (i.e., the derivative) in the NDE.
The SINDy algorithm then searches for a linear combination of basis functions of that best approximates the vector . The basis functions are typically polynomials or trigonometric functions if oscillatory behavior is expected. In this work, we are interested in a mass-action type solution, so we use basis functions in the vector space of monomials of . In other words, each term in the array represents a potential mass-action order for the degradation kinetics. The SINDy algorithm then solves the regression problem
using sparsity-promoting regularization, which penalizes the number of active basis functions [31]. Solution is a sparse vector of coefficients that determine which terms are active in the array of polynomials . One way to promote sparsity in the regression problem is to use -norm regularization, which penalizes the number of nonzero entries in the array. However, regularization is nonconvex, making it difficult to identify the global optimum of the regression problem. A better choice is the penalty, known as the least absolute shrinkage and selection operator (LASSO) algorithm, which is the convex approximation to the penalty [32]. LASSO can be computationally intensive, so we implemented the more computationally efficient sequentially thresholded least-squares (STSL) algorithm [33,34], as used in the standard SINDy algorithm [31]. Another common form of computationally efficient regularization is ridge regression, which uses an penalty. However, ridge regression does not necessarily promote sparsity, because the norm does not penalize the number of nonzero coefficients [35].
When applied to the NDE solution for M, illustrated in Figure 1, the SINDy algorithm identified three active monomials y, , and to represent the degradation rate. Optimizing the coefficients of the three monomials resulted in the following analytical expression for the differential equation:
This equation describes a cubic correction to a logistic decay of myricetin, with r and K being the rate coefficient and capacity constant, respectively. The logistic term reflects the autocatalytic behavior commonly observed in antioxidant degradation, while the cubic term captures the dynamics of late-stage decay [36,37]. These components align with known chemical mechanisms in lipid oxidation systems. The values of r and K characterized for the four initial concentrations (Table A1) are summarized in Table 1.
3.3. Model Predictions
The rate coefficients in Table 1 decrease rapidly with the initial concentration. This means that shelf life increases as the initial concentration of the antioxidant increases. The capacity constant, on the other hand, is largely independent of the initial concentration. This indicates that the degradation is self-similar in normalized concentration, although not in time, which scales with the rate coefficient. Figure 2 compares the predictions of the differential model (solid line) to the experimental data (symbols) for initial concentrations of 10 to 100 M, spanning a shelf life of approximately one to six weeks. The differential equation with just two parameters can describe the degradation process over a decade-long range of initial concentrations. This suggests that the uncovered equation is a robust model of the degradation process.
We further tested Equation (3) by extrapolating its predictions to a sample with an initial concentration much larger than those in Table 1. First, we established that the rate coefficient r for the four concentrations in Table 1 decreases approximately as a power-law , as shown by the solid line of Figure 3a. This allowed us to directly extrapolate the rate coefficient to more concentrated samples, as represented by the dashed line in Figure 3a. In a demanding test, we used the rate coefficient extrapolated to M (red symbol), which is 2.5-times larger than the highest initial concentration in the training set. The result of the test is shown in Figure 3b, where the dashed line represents the model predictions and the solid symbols represent the experimental data. The figure shows that the model is able to estimate the degradation of the antioxidant over time up to a shelf-life of more than two and a half months.
Food antioxidants degrade through a complex process involving many finely coordinated chemical reactions [38,39,40]. A complete understanding of the process would require identifying all intermediate species involved and characterizing a large number of rate constants, which is often impractical. Instead, Equation (3) is a reduced-order model with only two kinetic parameters that can be characterized from our observations. This parsimonious model can describe and predict myricetin degradation over a large range of concentrations, as demonstrated in Figure 2 and Figure 3. However, it does not provide a complete mechanistic understanding of the full kinetics. Despite this limitation, the reduced-order model does more than make meaningful quantitative predictions. The model also uncovers important qualitative features of the underlying dynamics, which are not immediately apparent from the experimental data.
First, the model identified three distinct stages of degradation: initiation, propagation, and termination (Figure 2 and Figure 3b). Most food antioxidants show this pattern [25,41,42,43]. In our case, initiation is a brief early stage, accounting for about 6% of the reaction’s progress. At this point, the normalized concentration decreases to , which corresponds to the first inflexion point of Equation (3). The reaction rate decreases with time during this brief initial stage. Propagation is a longer stage, occurring at intermediate times, until the concentration decreases to . This value corresponds to the second inflexion point of Equation (3). The reaction rate increases with time during this stage. Termination is the final stage, proceeding until all of the antioxidant has been consumed. The reaction rate decreases with time during this last stage.
Second, the model identified a subtle mechanism: antioxidants often decay at later times through an autocatalytic process [37,44]. This is consistent with the characteristic sigmoidal decay observed at later times in Figure 2 and Figure 3b. More precisely, as the myricetin concentration decreases with time, the contribution of the cubic nonlinearity in Equation (3) becomes progressively smaller. Eventually, the degradation is governed by the logistic decay , which is characteristic of autocatalytic reactions [36,45,46].
The model’s ability to learn these features directly from data provides insights into the underlying dynamics of the myricetin degradation process.
4. Conclusions
Understanding how antioxidants degrade in oil and oil emulsions is essential for extending the shelf life of many foods. In this study, we introduce a machine learning approach for discovering differential equations that model antioxidant breakdown without relying on prior assumptions about the underlying dynamics. We demonstrate this method by identifying a parsimonious, two-parameter differential equation that accurately describes the degradation of myricetin in stripped soybean oil. Despite being trained on limited experimental data, the model captures degradation behavior across a wide range of initial concentrations (10–100 M) and generalizes well beyond the training set, up to 250 M. Although data-driven, the model’s structure reflects known chemical mechanisms, including autocatalytic behavior and late-stage decay dynamics commonly associated with lipid oxidation. These features improve the interpretability of the model and its relevance to food chemistry. While the current model focuses on myricetin in stripped soybean oil at a fixed temperature, its robustness across varying concentrations suggests broader applicability to other antioxidants, oil systems, and environmental conditions. However, it does not yet account for key environmental variables such as temperature, oxygen partial pressure, or interfacial dynamics, factors known to influence antioxidant degradation. Incorporating these parameters, either through additional data or by integrating mechanistic insights from food chemistry, could significantly improve the model’s predictive power and extend its utility to a wider range of food formulations and storage conditions. Finally, although we applied this approach to antioxidant degradation, it holds strong potential for modeling other complex food processes where traditional methods struggle due to limited data.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Corradini M.G. Shelf life of food products: From open labeling to real-time measurements Annu. Rev. Food Sci. Technol.2018925126910.1146/annurev-food-030117-01243329328810 · doi ↗ · pubmed ↗
- 2Van Boekel M.A. Kinetic Modeling of Reactions in Foods CRC Press Boca Raton, FL, USA 2008
- 3Seilert J. Moorthy A.S. Kearsley A.J. Flöter E. Revisiting a model to predict pure triglyceride thermodynamic properties: Parameter optimization and performance J. Am. Oil Chem. Soc.20219883785010.1002/aocs.12515 · doi ↗
- 4Sun Y.E. Wang W.D. Chen H.W. Li C. Autoxidation of unsaturated lipids in food emulsion Crit. Rev. Food Sci. Nutr.20115145346610.1080/1040839100367208621491270 · doi ↗ · pubmed ↗
- 5Decker E.A. Warner K. Richards M.P. Shahidi F. Measuring antioxidant effectiveness in food J. Agric. Food Chem.2005534303431010.1021/jf 058012 x 15884875 · doi ↗ · pubmed ↗
- 6Ghelichi S. Hajfathalian M. Yesiltas B. Sørensen A.D.M. García-Moreno P.J. Jacobsen C. Oxidation and oxidative stability in emulsions Compr. Rev. Food Sci. Food Saf.2023221864190110.1111/1541-4337.1313436880585 · doi ↗ · pubmed ↗
- 7Corradini M.G. Peleg M. Shelf-life estimation from accelerated storage data Trends Food Sci. Technol.200718374710.1016/j.tifs.2006.07.011 · doi ↗
- 8Wanasundara U.N. Shahidi F. Stabilization of marine oils with flavonoids J. Food Lipids 1998518319610.1111/j.1745-4522.1998.tb 00119.x · doi ↗