Age of Information Minimization in Multicarrier-Based Wireless Powered Sensor Networks
Juan Sun, Jingjie Xia, Shubin Zhang, Xinjie Yu

TL;DR
This paper proposes a new method to reduce information delay in wireless sensor networks by combining Lyapunov optimization and deep reinforcement learning.
Contribution
A novel approach combining Lyapunov optimization and model-free deep reinforcement learning to minimize Age of Information in WPSNs.
Findings
The proposed algorithm achieves significantly lower weighted average Age of Information than existing methods.
It effectively reduces excessive instantaneous AoI for individual sensors compared to DQN.
Simulation results validate the effectiveness of the method in real-world scenarios.
Abstract
This study investigates the challenge of ensuring timely information delivery in wireless powered sensor networks (WPSNs), where multiple sensors forward status-update packets to a base station (BS). Time is partitioned to multiple time blocks, with each time block dedicated to either data packet transmission or energy transfer. Our objective is to minimize the long-term average weighted sum of the Age of Information (WAoI) for physical processes monitored by sensors. We formulate this optimization problem as a multi-stage stochastic optimization program. To tackle this intricate problem, we propose a novel approach that leverages Lyapunov optimization to transform the complex original problem into a sequence of per-time-bock deterministic problems. These deterministic problems are then solved using model-free deep reinforcement learning (DRL). Simulation results demonstrate that our…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
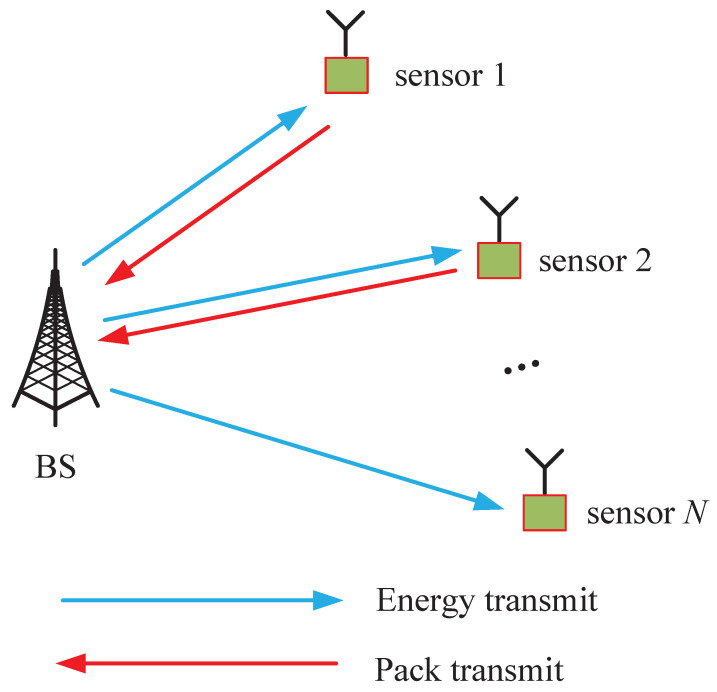 Figure 1
Figure 1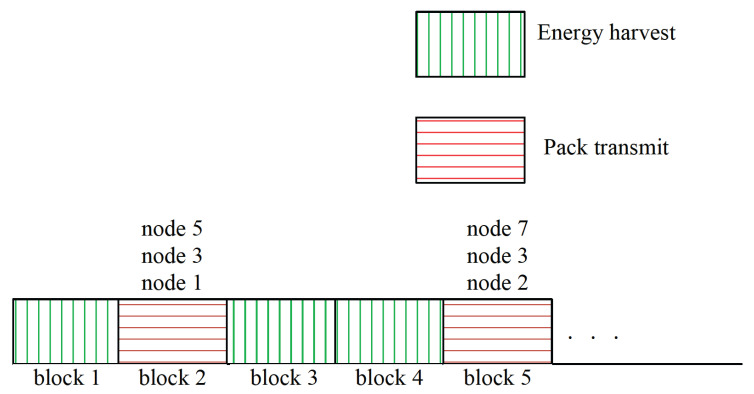 Figure 2
Figure 2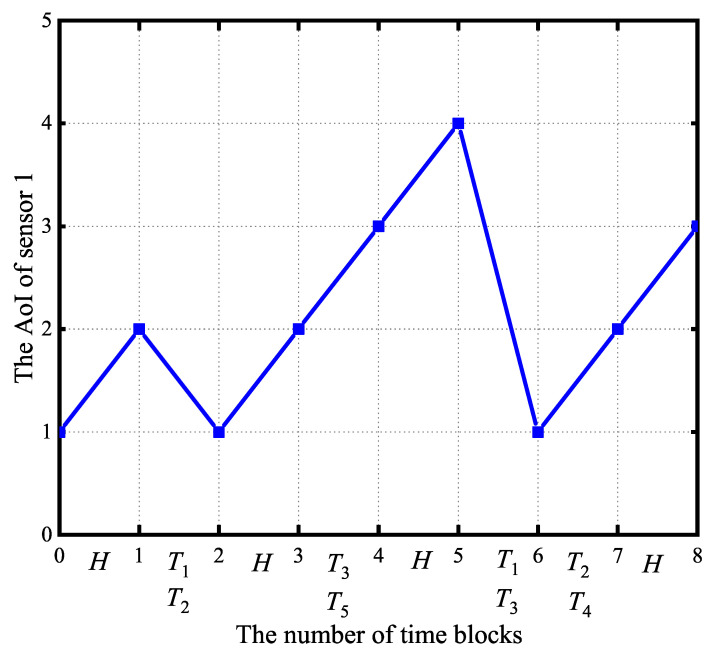 Figure 3
Figure 3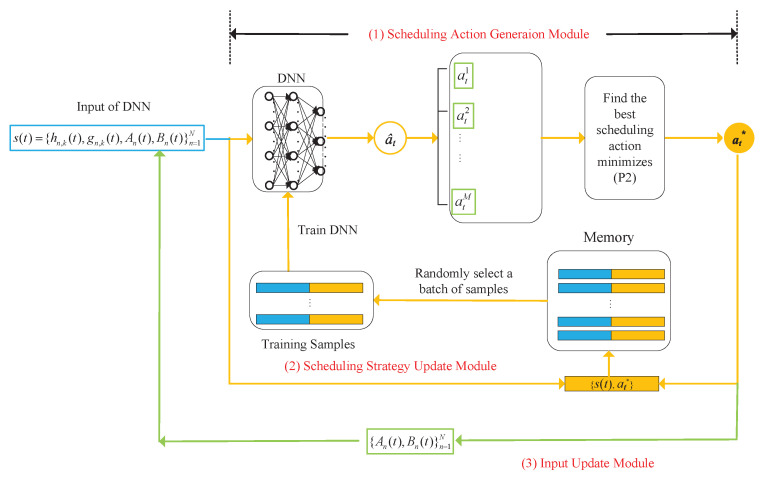 Figure 4
Figure 4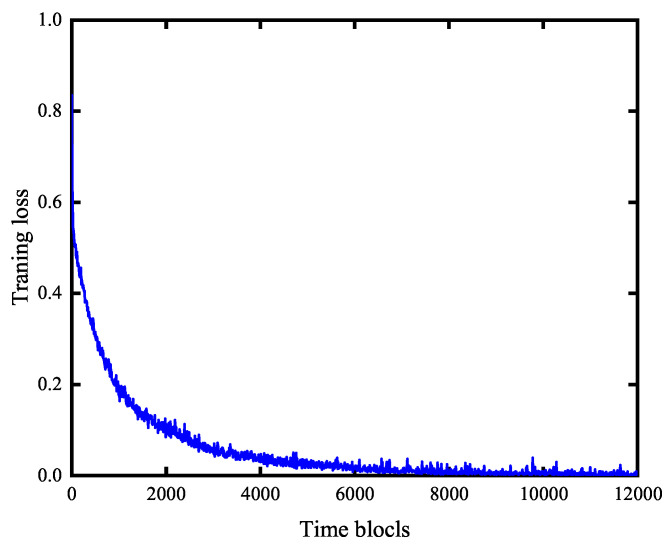 Figure 5
Figure 5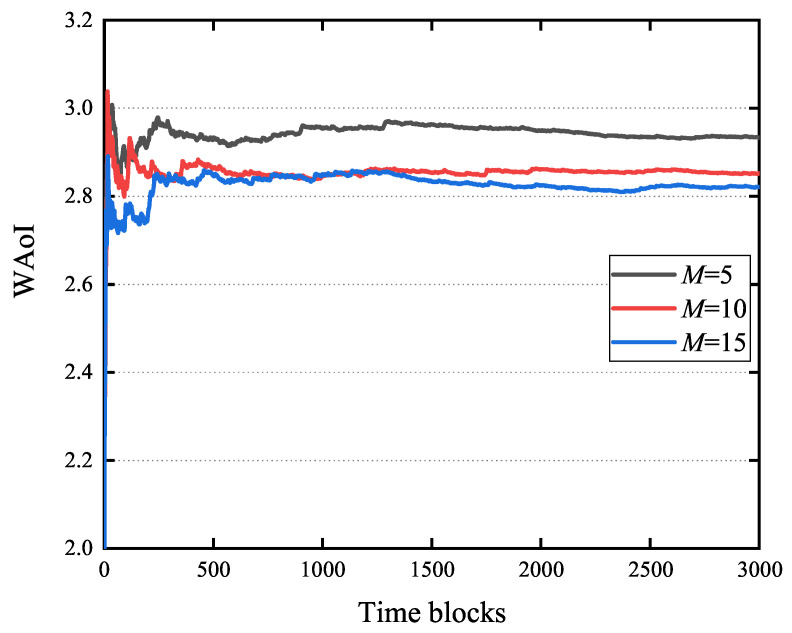 Figure 6
Figure 6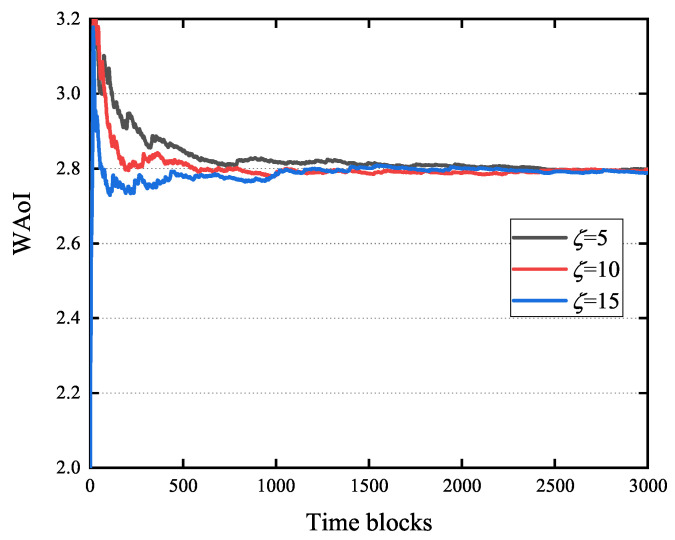 Figure 7
Figure 7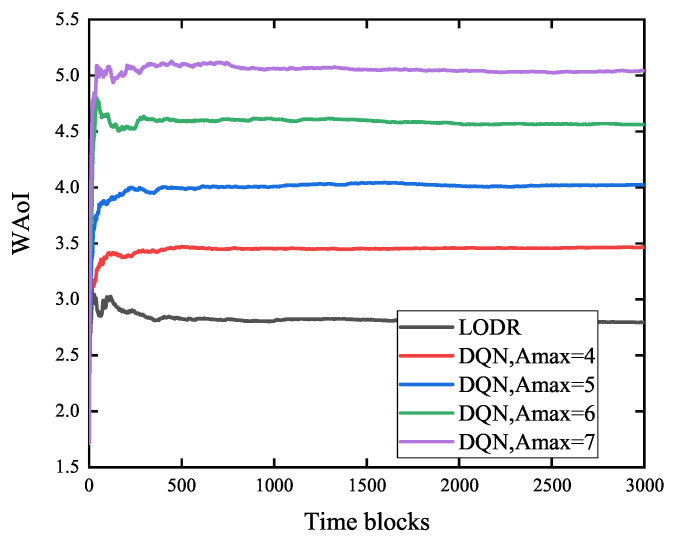 Figure 8
Figure 8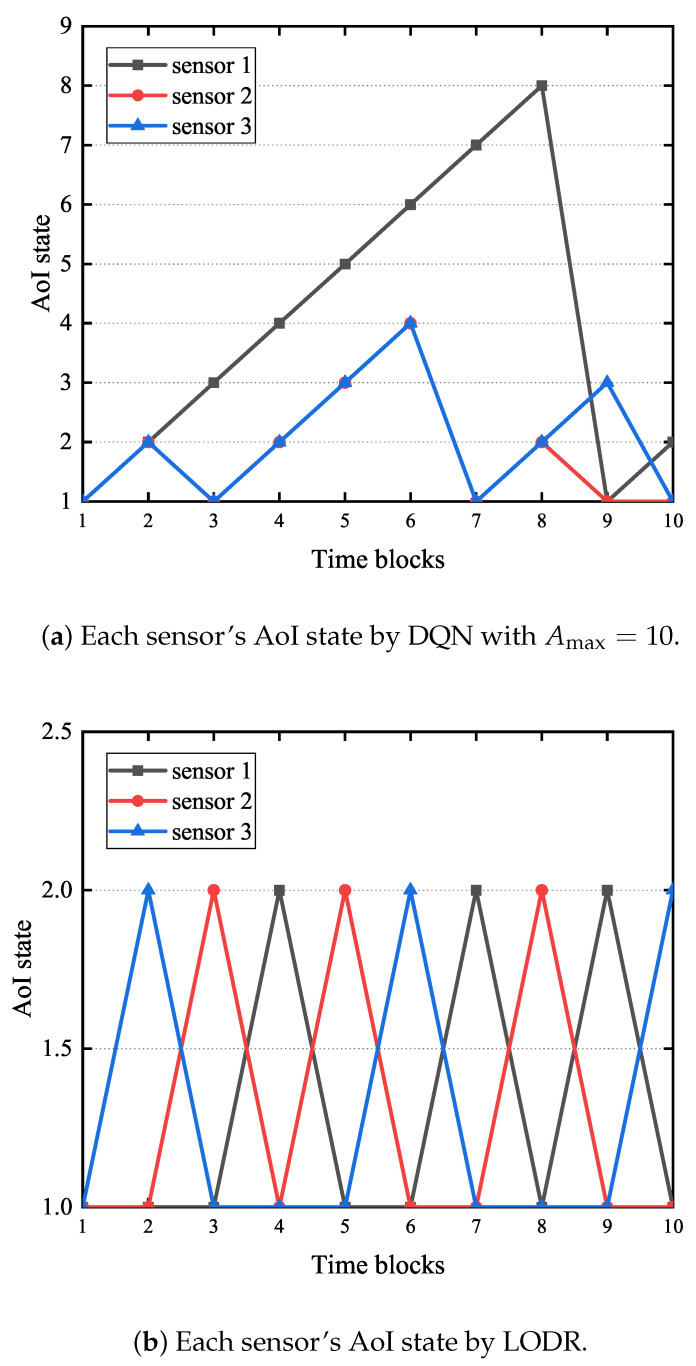 Figure 9
Figure 9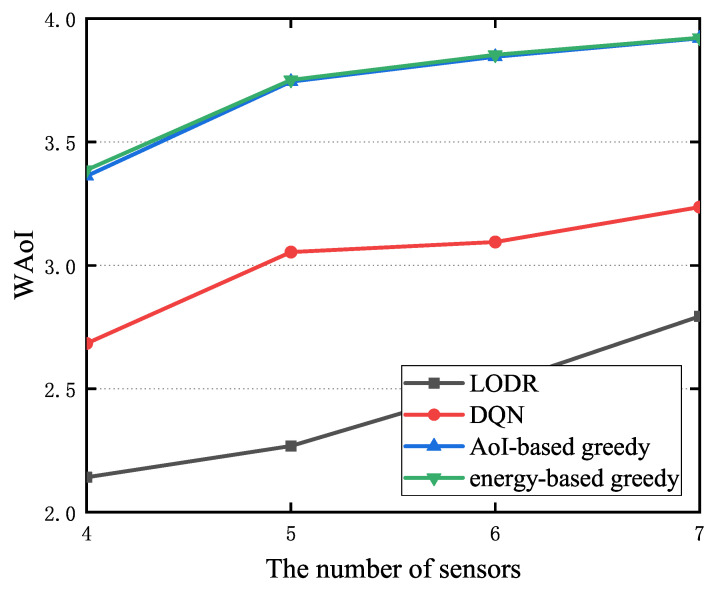 Figure 10
Figure 10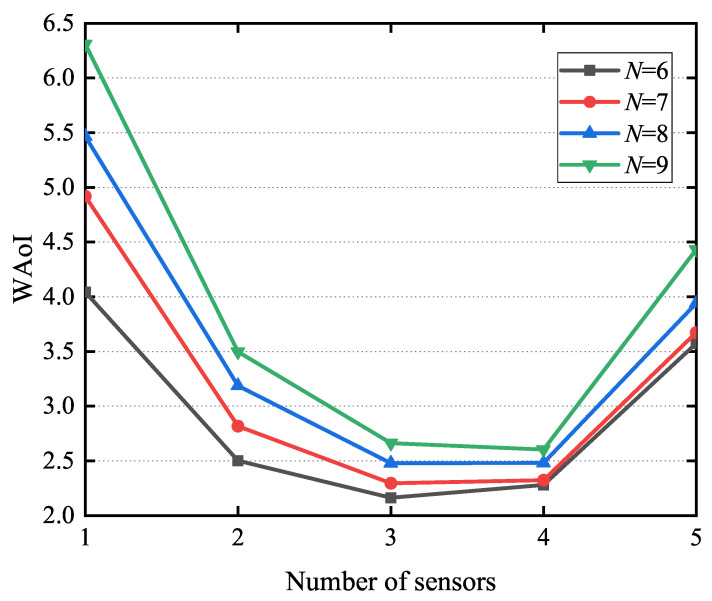 Figure 11
Figure 11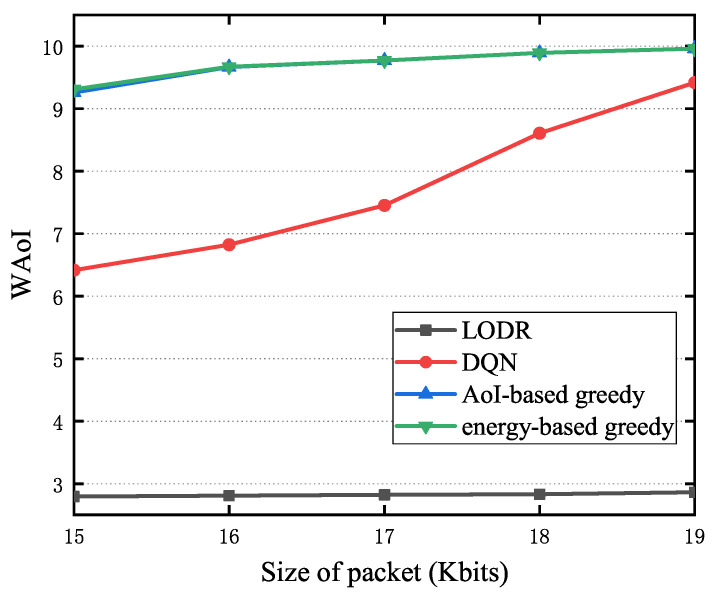 Figure 12
Figure 12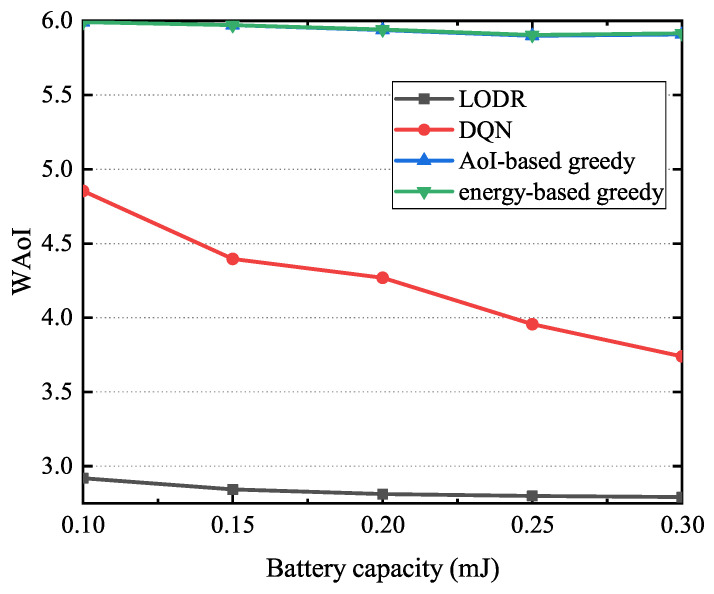 Figure 13
Figure 13 Figure 14
Figure 14- —Zhejiang Provincial Nature
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAge of Information Optimization · Congenital Heart Disease Studies · Distributed Sensor Networks and Detection Algorithms
1. Introduction
The timeliness of status updates, originating from diverse stochastic processes and collected by source nodes, plays a crucial role in the performance of numerous real-time systems [1,2,3]. Examples of such applications include safety-critical systems, health monitoring, and environmental surveillance. In these time-sensitive contexts, rapid delivery of sampled information to the destination is necessary. Outdated information can result in suboptimal control decisions and potentially severe consequences. Consequently, the Age of Information (AoI) metric has emerged as a valuable tool for quantifying the freshness and timeliness of status-update data [4]. It represents the elapsed time since the most recent update was generated at the source and successfully received at the destination. The AoI at time t is given by , where is the timestamp of the latest received update [5].
Energy limitations in wireless devices (WDs) pose a significant challenge to timely data delivery due to the increased likelihood of packet loss. Wireless energy transfer (WET) has emerged as a key technology to address this issue, allowing for over-the-air recharging of WD batteries and obviating the need for manual replacement [6]. In this work, we focus on the long-term average weighted sum of AoI (WAoI) performance in wireless powered sensor networks (WPSNs), where sensors rely on radio frequency (RF) energy harvested from the base station (BS) to sustain their sensing and communication activities. In WPSNs, the wireless link quality between sensors and the BS is time-varying. Furthermore, the residual energy of sensors and their monitored AoI values vary over time. Consequently, the design of a scheduling policy that minimizes the WAoI at the BS becomes crucial. The network should dynamically select sensors for packet transmission based on a combination of channel quality, energy availability, and AoI. Intuitively, sensors with strong channels, sufficient energy, and high AoI should be prioritized. Additionally, the BS should adapt to network conditions by conducting WET when the communication links are degraded or sensors’ energy is depleted.
1.1. Related Work
The introduction of AoI in [4] has spurred extensive research into the characterization of both average and peak AoI [7,8,9,10,11,12,13]. In another line of inquiry, researchers are developing the optimal transmission policy for AoI minimization in communication systems [14,15,16,17,18,19,20,21,22,23,24,25], e.g., broadcast networks [14,15,16], information-update systems employing multiple servers [17], relay-based multi-hop communication systems [18], Internet of Things (Iot) networks [19], UAV-enabled networks [20,21], cognitive radio communication systems [22], multicast networks [23,24], mission-critical vehicular networks [25], and multi-state time-varying networks [26]. Particularly, [14,15,16,17,18,19,20,21,22,23,25] do not consider source nodes utilizing an energy harvesting technique to maintain self-supplying communication operations.
Different from [14,15,16,17,18,19,20,21,22,23,25], another research direction focuses on communication systems that use an energy harvesting technique to power the source nodes. This research aims to determine age-oriented optimal policies for transmitting status-update packets, considering the source nodes’ energy causality constraint. In [27], the authors demonstrate that an energy-dependent threshold policy is optimal for minimizing AoI by triggering new samples. Multiple RF energy harvesting sensors are considered in [28]. To minimize the weighted sum of AoI, the authors employed a DRL framework that concurrently optimize WET and update packet transmissions. In [29], the authors studied relay-based networks, where a source sends status updates to a destination via a relay. Considering the spectrum scarcity, in [30], the authors address the problem of minimizing AoI in cognitive radio networks (CRNs). They derive optimal scheduling actions for both imperfect and perfect spectrum sensing scenarios. Different from traditional fixed energy sources, the work [31] dispatched a UAV to transfer energy to ground sensor nodes. To minimize the average AoI, the authors concurrently optimized energy harvesting durations, the UAV’s trajectory, and data collection time for sensors.
However, none of these prior studies has employed a DRL-based algorithm for the efficient design of freshness-aware WPSNs utilizing multiple subcarriers. In contrast to these works, this paper investigates a scenario where multiple RF-powered source nodes are deployed to sense potentially distinct physical processes and transmit status-update packets across multiple orthogonal subcarriers. For this setting, we provide a novel reinforcement. Before detailing our contributions, we emphasize the key distinctions between our work and those presented in [24,28].
Ref. [28] investigates a single-carrier system in contrast to this work, where we focus on a multicarrier system.Ref. [24] considers source nodes with embedded power supplies, whereas our work adopts WPT technology to energize these nodes.In contrast to the approach presented in [24], which aims to minimize the average total transmit power subject to per sensor AoI constraints, our work focuses on minimizing the long-term WAoI.In terms of optimization strategies, ref. [24] relies on conventional numerical methods. In contrast, our work pioneers a scheduling algorithm based on DRL. Moreover, while [28] employs the classical Deep Q-Network (DQN) algorithm, our research introduces a distinctly different DRL algorithm tailored to the specific challenges of our problem.
1.2. Contributions
This paper investigates WPSNs for status updates, comprising multiple sensors and a BS, where the BS receives timely information regarding different physical processes monitored by the sensors. The sensors harvest energy from RF signals transmitted by the BS and communicate using orthogonal subcarriers within each time block. The primary contributions of this work are summarized as follows:
- We formulate the problem of jointly optimizing subcarrier assignment, WET duration, and sensor sampling schedules to minimize the WAoI for diverse physical processes at the BS within a time-sensitive communication system. This is modeled as a multi-stage stochastic optimization problem, subject to energy causality constraints at the sensors.
- To address this optimization problem, we propose a novel dynamic control algorithm that integrates DRL and Lyapunov optimization techniques. Specifically, Lyapunov optimization is employed to decompose the multi-stage stochastic problem into a sequence of deterministic optimization problems, one for each time block. Subsequently, a DRL algorithm is utilized to determine the optimal scheduling decisions for each time block, with action exploration facilitated by a randomization policy.
- Extensive simulation results demonstrate the significant performance gains of our proposed algorithm in reducing the WAoI compared to benchmark algorithms, including the DQN, energy-based greedy, and AoI-based greedy schemes. Notably, our DRL algorithm exhibits good convergence performance and eliminates the need for a predefined upper limit for AoI values, unlike the DQN approach.
2. System Model and Problem Formulation
2.1. Network Model
A real-time monitoring system is considered, as shown in Figure 1, where a BS collects time-critical information from N sensors. The sensors are responsible for providing the BS with fresh information about their respective measured processes. Additionally, the sensors share K subcarriers, each with a bandwidth of W Hz. The BS is assumed to have a stable power supply, whereas each sensor n is powered by the RF energy transmitted by the BS in the downlink. This harvested energy is stored in a battery with a finite capacity of joules. The communication is divided into discrete time intervals, indexed by . In each time block, either energy transfer or pack transmission is conducted. Figure 2 illustrates a representative schedule, where the BS broadcasts RF energy in time block 0, 2, and 3, and sensors 1, 3, and 5 transmit update packs in time block 1.
We consider a quasi-static fading channel model, where the channel power gain is constant within a time block but varies independently across different time blocks. Let and represent the channel power gains on subcarrier k of the uplink and downlink channels between the BS and sensor n, respectively. Additionally, let and represent the AoI of sensor n’s monitoring process and its remaining energy, respectively. It should be noted that this paper does not impose an upper bound on the AoI.
2.2. State and Action Spaces
At time block t, sensor n’s state, , is defined by its downlink and uplink channel power gains on subcarrier k, the AoI of its measured process at the BS, and its battery level, i.e., . denotes the state space encompassing all combinations of , , , and . Consequently, denotes the state of the system at time slot t, where denotes the state space of the system. Then, at time block t, the possible action is expressed as . If , the BS transmits RF energy to the sensors via the downlink. For sensor n, the captured energy is expressed as
where denotes the efficiency of the energy harvesting and P represents the power transmitted by the BS.
If , K sensor nodes (i,e., node i, node j, …) send the status-update packs to the BS through the uplink over the K subcarriers. The sensors employ a generate-at-will strategy, where data packets are generated immediately following a scheduling decision [32]. It should be noted that when sensor n transmits a data packet of size to the BS at time block t, the energy consumption is denoted by . According to Shannon’s formula, is expressed as
where represents the noise variance. Therefore, sensor n is eligible for data transmission only if its remaining energy satisfies
At time block t, the AoI for different physical processes and the battery level of each sensor are updated after executing decisions as shown in Figure 1. Specifically, when , process n’s AoI observed by sensor n increments by one and the remaining battery energy of sensor n increases by . When , i.e., the packet is transmitted, and the battery level of K sensors scheduled decreases by , while the battery level of other sensors remain unchanged. Meanwhile, the AOI of the physical processes monitored by the selected K sensors are set to 1, while the other sensors remain unchanged. Therefore, the dynamic changes in sensor n’s remaining energy and the AoI are given, respectively, by
To help visualize (5), Figure 3 shows the AoI evolution of process 1 when taking action over time, where and . We can observe from Figure 3 that then , and then . Specifically, the AoI of process 1 is reset to 1 at the start of time blocks 2 and 6, corresponding to status updates transmitted at time blocks 1 and 5. During time blocks 0, 2, 3, 4, 6, and 7, sensor 1 remains inactive (either harvesting energy or idle), causing the AoI of its monitoring process increment by 1 in each of these time blocks.
2.3. Problem Formulation
We aim to minimize the WAoI at the BS by finding the optimal policy for action selection at each time block. The policy consists of a set of decision rules such that for any time block t, assigns an action to each possible system state . Given policy and initial state , process n’s long-term AoI is given by
Consequently, the WAoI minimization problem for WPSNs is formulated as
where denotes the optimal policy, and the weight is non-negative and satisfies . Clearly, if , the optimal policy is to allocate all sensors harvesting RF energy from the BS. If , the optimal policy is to allocate K sensors send status-update packs to the BS based on each sensor’s battery level, channel state information, and each process n’s AoI state monitored by sensor n.
Classic optimization techniques like combinatorial optimization and heuristics are not appropriate for this problem due to its long-term and stochastic nature. Primarily designed for deterministic scenarios, these methods can only optimize for the immediate time block, thus struggling to achieve optimal performance over extended periods.
3. The Decoupling Strategy for Multi-Stage Stochastic Optimization Based on Lyapunov Theory
This section introduces LODR, an algorithm that combines Lyapunov optimization and DRL, to tackle the problem (P1). We begin by employing Lyapunov optimization to transform the original problem into a series of deterministic problems, one for each time block. For each sensor, we define N virtual energy queues, denoted by . These queues are initialized with and updated according to the following equation
where is a scaling coefficient. functions as a queue, which is incremented by energy harvests and decremented by energy consumption .
We introduce a queue backlog vector to characterize the energy queue status of all sensors, where denotes the backlog of the energy queue for sensor n at time block t. We then define a Lyapunov function and its associated drift as [33]
Then, we utilize the Lyapunov-plus-penalty minimization method from [34] to minimize the WAoI subject to the stability constraint of the queue . Our approach involves minimizing an upper bound on the following drift-plus-penalty expression for time block t.
The parameter serves as a control variable, balancing the importance of the penalty term (i.e., the objective function) and the queue backlog sizes. Adjusting can achieve a desired balance between the objective function value and the sizes of the queue backlogs.
We next establish an upper bound for . To start, we obtain
Performing a summation over all queues, we obtain
Applying the conditional expectation operator to both sides of (13) [35], we obtain
Here, B is a constant given as
where is defined as sensor n harvesting RF energy at time block t, and is defined as sensor n forwarding data at time block t. Therefore, the drift-plus-penalty expression in (11) is upper-bounded by
Applying the principle of opportunistic expectation minimization [36] at time block t, the scheduling decision is made based on the observed queue backlog to minimize the upper bound established in (16). Noting that the control action decision at time block t is only affected by the second and third terms, the algorithm’s action selection at time block t is predicated on the minimization of the subsequent expression, derived after removing constants from the initial observation:
where the second term corresponds to RF energy harvesting by sensor n, and the third term indicates that sensor n is selected for transmission. Then, the original problem (P1) is reformulated as
If problem (7) admits a feasible solution, relying solely on channel-only policies is sufficient to approach the optimal performance with arbitrary precision. Given the assumption of stationary and independent and identically distributed (i.i.d.) channels across time slots, the feasibility of problem (7) implies that for any , a policy relying solely on channel state information exists that satisfies
where denotes the optimal value of WAoI.
Proof. See proof of Theorem 4.5 in [Ref. [33], Appendix 4.A]. □
Subsequently, the primary obstacle lies in the effective solution of problem (P2) for each time block to achieve the WAoI minimization. For the solution of (P2), we consider the system state at time block t, encompassing downlink and uplink channel gains, the AoI of sensor n’s monitoring process, and the remaining energy of sensor n. The scheduling control action is then determined based on this state. In general, obtaining the optimal policy requires enumerating scheduling actions, a computationally intensive task for moderate N and K values. Alternative search-based techniques, including block coordinate descent and branch-and-bound, also suffer from high computational cost. To address the challenge of online decision-making in dynamically varying channel environments, we introduce LODR, a based-DRL algorithm. In the following, we describe the LODR algorithm to solve (P2) efficiently.
4. Lyapunov-Guided DRL for Online Scheduling Decisions
Figure 4 shows the architectural framework of the LODR algorithm. It consists of three core modules: the scheduling action generation module, scheduling policy update module, and input update module. The scheduling action generation module begins by receiving the current system state, denoted as . Subsequently, it generates a set of potential scheduling actions. From this set, an evaluation process is executed, resulting in the selection of , the action deemed most advantageous. The policy of the scheduling action generation mechanism is refined over time by the scheduling policy update module. Following the execution of the scheduled actions, the input update module changes the state of battery remaining energy of sensors and their monitoring processes’ AoI. A sequential iterative process is followed by these three modules through successive interactions with the stochastic environment , as outlined in the subsequent sections.
(1) Scheduling Action Generation Module: The DNN, parameterized by , is employed for scheduling action synthesis. When , the parameters are initialized stochastically according to a Gaussian distribution with zero mean. Subsequent to the DNN’s production of a real-valued scheduling output , a discretization process is performed to formulate a set of binary-valued scheduling operations. Specifically, we set K largest values of to 1 and the rest to 0, where 1 indicates that the corresponding sensor is selected to send the status update to the BS, while 0 represents the sensor remaining idle. Furthermore, we generate another M random actions and one fixed action , together with the above DNN output action as candidate actions. Here, represents all the sensors harvesting RF energy from the BS.
It is established by the universal approximation theorem that a neural network with a single hidden layer of adequate size is capable of approximating any continuous function f, provided that an appropriate activation function is employed, such as the ReLU, tanh, or sigmoid [37] functions. In this implementation, the ReLU activation function is employed within the hidden layers, where the relationship between the neuron’s output y and input x is defined by . For the output layer, the sigmoid activation function is implemented, resulting in the relaxed scheduling action being constrained to the interval .
It is noted that each potential action yields , which represents the performance metric, through the solution of problem (P2), a defined optimization problem. Consequently, the optimal scheduling action at time block t is determined as
(2) Scheduling Policy Update Module: The scheduling solution obtained in (19) will be used to update the scheduling policy of the DNN. To facilitate training, a memory repository of bounded capacity, starting in an empty state, is maintained. In the tth time block, a fresh training sample is incorporated into the memory buffer. When the memory buffer is at maximum capacity, a first-in-first-out (FIFO) replacement policy is enacted, with the oldest sample being replaced by the newest.
Leveraging the data samples stored within the memory, the training process of the DNN is conducted, an approach recognized as experience replay [38]. The stochastic selection of a training data batch is performed from the memory during the tth temporal iteration, defined by the set of temporal indices . The DNN’s parameter is updated via the Adam optimization algorithm to minimize the mean cross-entropy loss as
where represents the number of elements within , indicates the operation of transpose, and the log function represents the application of the logarithm to each element of a vector. The DNN undergoes periodic retraining every time frames, triggered by the accumulation of a predetermined volume of fresh data.
(3) Input Update Module: Based on the scheduling action generation module, the system executes the scheduling action , then the battery level of sensor n is updated using (4), the AoI updates using (5), and the virtual energy queues updates using (8). Following the observation of wireless channel gains , the system utilizes the composite input to drive the DNN, thereby triggering a new iterative cycle starting from the scheduling action generation module in Step 1).
In summary, through successive iterations, the DNN refines its scheduling policy by learning from optimal state-action pairs, , thereby enhancing decision-making over time. Due to the limitation imposed by the finite replay memory, the DNN’s learning is restricted to the most recent data samples, which reflect the latest scheduling policies. Through continuous feedback and adaptation, this closed-loop reinforcement learning framework optimizes the scheduling policy, leading to convergence. Algorithm 1 delineates the methodology employed to determine the optimal scheduling policy for (P1). Algorithm 1: LODR algorithm to solve the AoI minimization problem.
5. Performance Evaluation
The proposed LODR algorithm’s performance was evaluated by comparing it with the DQN, energy-based greedy, and AoI-based greedy algorithms. Specifically, for the energy-based and AoI-based greedy algorithms, on the premise of ensuring the minimum energy requirement, we arranged K sensors with relatively large battery level and high AoI to send status-update packs to the BS.
5.1. Experimental Settings
This subsection details the simulation parameters. The channel model incorporates both small-scale fading and path loss effects. The downlink and uplink channel gains between the BS and sensor n, denoted by and , are modeled as random variables. Specifically, and are given by and . is the reference distance (1 m) signal power gain, is the distance between the BS and sensor n, and is the path loss exponent. and represent independent, exponentially distributed (mean 1) small-scale fading gains. Unless otherwise stated, the primary simulation parameters are as follows: , , , , , , , , mJ, , and . represents the distance between sensor n to the BS.
The DNN employed, whose architecture is specified in Table 1, processed input features. The network’s core consisted of two hidden layers, the first with 120 neurons and the second with 80, both employing the ReLU activation function. The final layer, responsible for generating outputs, utilized a sigmoid activation. Table 2 shows the simulation parameters for the LODR algorithm.
The state space for the DQN is constructed by discretizing system parameters. Five levels are used to represent both the uplink and downlink channel gains and four levels for the remaining battery energy.
5.2. Training Loss for LODR Algorithm
Figure 5 presents the training loss of LODR as a function of training steps for a network with and . The gradual decrease and subsequent convergence of the loss function to a low value demonstrate LODR’s ability to automatically adapt its scheduling policy and reach to the optimal value. The DNN within LODR reaches a stable state within approximately 8000 time blocks, indicating rapid convergence. This convergence behavior is consistently observed in simulations with a larger number of sensors. In contrast, the DQN exhibits significantly slower convergence, or even a lack thereof, as the state space expands. For instance, with seven sensors, discretizing the uplink and downlink channel gains into six and five levels, the battery energy into four levels, and the maximum AoI setting to 5 results in a state space of . Such a vast state space requires extensive exploration for Q-value stabilization, leading to slow convergence. Furthermore, even upon convergence, the DQN algorithm’s loss remains comparatively high.
5.3. Impact of M and ζ
Figure 6 illustrates the influence of the number of random actions M on the WAoI, employing a parameter configuration consistent with that used in Figure 5. This figure demonstrates rapid convergence of the WAoI for all three values of M considered. Furthermore, at 3000 time blocks, the WAoI for is greater than that observed for . This suggests that the number of random actions has a limited impact on the WoI. Meanwhile, as M increases, the WAoI decreases.
Figure 7 shows the effect of the training interval on the WAoI, using parameters consistent with Figure 5. The WAoI converge to similar values for , , and after 3000 time slots. was therefore selected for subsequent experiments.
5.4. The WAoI of LODR
Figure 8 shows the WAoI for LODR and the DQN, where the parameter setup is similar to that in Figure 5. From Figure 8, we can draw two conclusions. First, clearly the WAoI of our proposed LODR algorithm is superior to the classic DQN algorithm. Second, for the DQN, as increases, the system performance deteriorates. This is because the higher the degree of information stale (e.g., is larger) that the system can tolerate, the greater AoI is likely to be. Thus, the setting of obviously affects the performance of the DQN.
Figure 9 illustrates a comparison of AoI evolution for each sensor using LODR and the DQN. As shown in Figure 9, LODR achieves greater AoI stability for all sensors than the DQN. Using the DQN, sensor 1’s AoI reaches 8 by time block 8, and the status-update packet is sent at time block 9. Sensors 2 and 3 exhibit significantly lower peak AoI values, at and of sensor 1’s peak, respectively. Notably, the maximum AoI values for sensors 2 and 3 are significantly lower, at only and of sensor 1’s peak. This is due to the DQN algorithm’s failure to converge to an optimal policy. Conversely, LODR maintains a maximum AoI of 2 for all sensors, demonstrating its effective dynamic scheduling. Additionally, we observe the consequent time blocks, and the AoI of each sensor is the same in the steady state. It should be noted that this only applies to the current parameter setup. When we change the parameters, each sensor has a different AOI.
Figure 10 shows the WAoI for the LODR, DQN, AoI-based greedy, and energy-based greedy algorithms. As illustrated in Figure 10, LODR outperforms the other three algorithms. Our simulations revealed that the DQN struggles to converge with an increasing number of sensors. When the number of sensors is large but the selection is limited, considering the case of selecting two nodes, the stability of the DQN’s state is compromised. After multiple rounds of selection, there will inevitably be several sensors with continuously increasing AoI until the upper limit is reached. However, now, if two nodes are selected based on a greedy algorithm, the senor with the maximum energy will undoubtedly have the maximum AoI. At this point, the two greedy algorithms degenerate into one, resulting in similar AoI. Additionally, the WAoI increases with the number of sensors. Larger sensor deployments result in reduced transmission probability and increased WAoI.
Figure 11 illustrates how the WAoI varies with the number of subcarriers k, where the number of sensors N is set to 6, 7, 8, and 9. In Figure 11, we can observe that the WAoI exhibits a trend of initial decrease followed by a subsequent increase. Larger K values correlate with a higher chance of repeated sensor selections. When K is below about half of N, the probability of repeating the same sensor is less likely. The sensors are used evenly, entering a charging state slowly and reducing the WAoI with increasing K. However, when K surpasses about half of N, reusing the same sensor in different time blocks accelerates energy consumption, leading to faster charging and an increase in the WAoI with growing K.
Figure 12 illustrates the influence of the size of the status-update pack on WAoI for the LODR, AoI-based greedy, energy-based greedy, and DQN methods with . It is observed that the WAoI exhibits a positive correlation with the size of status-update pack. This is because the increased energy demands of larger status-update packets necessitate longer energy harvesting periods, consequently leading to a higher AoI.
Figure 13 illustrates the relationship between the battery capacity and WAoI for the LODR, AoI-based greedy, energy-based greedy, and DQN methods with . From Figure 13, we can see that the WAoI exhibits an inverse relationship with the battery capacity. This is because as the battery capacity increases, so does the energy storage capacity of sensors, which in turn increases the probability of status-update transmissions.
6. Conclusions
We considered the WPSNs where multiple sensors send status-update packets to the BS, aiming to minimize the WAoI of different processes at the BS. Specifically, we first formulated the WAoI minimization problem as a multi-stage stochastic optimization problem subject to energy causality constraints. Second, we designed the algorithm LODR, which jointly utilizes DRL and Lyapunov optimization. Compared to the classic DQN algorithm, LODR has better convergence performance, alleviates the problem that some sensors may have large AoIs, and is able to effectively schedule the energy transfer and packet transmit with the dynamic of network state. LODR achieves smaller WAoI than the DQN, AoI-based greedy, and energy-based greedy algorithms. Additionally, the WAoI is an increasing function with respect to the size of status-update packets, and it is a decreasing function with respect to the capacity of batteries.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kosta A. Pappas N. Angelakis V. Age information: A new concept, metric, tool Found. Trends Netw.20171217310.1561/1300000060 · doi ↗
- 2Yates R.D. Kaul S.K. The age of information: Real-time status updating by multiple sources IEEE Trans. Inf. Theory 2019651807182710.1109/TIT.2018.2871079 · doi ↗
- 3Sun Y. Kadota I. Talak R. Modiano E. Age information: A new metric for information freshness Synth. Lect. Commun. Netw.201912124
- 4Kaul S. Yates R. Gruteser M. Real-time status: How often should one update Proceedings of the IEEE Conference Computer Communications (INFOCOM)Orlando, FL, USA 25–30 March 201227312735
- 5Feng S. Yang J. Age of information minimization for an energy harvesting source With updating erasures: Without and with feedback IEEE Trans. Commun.2021695091510510.1109/TCOMM.2021.3083803 · doi ↗
- 6Bi S. Ho C.K. Zhang R. Wireless powered communication: Opportunities and challenges IEEE Commun. Mag.20155311712510.1109/MCOM.2015.7081084 · doi ↗
- 7Yates R.D. Kaul S. Real-time status updating: Multiple sources Proceedings of the 2012 IEEE International Symposium on Information Theory Cambridge, MA, USA 1–6 July 201226662670
- 8Kam C. Kompella S. Ephremides A. Age of information under random updates Proceedings of the 2013 IEEE International Symposium on Information Theory Istanbul, Turkey 7–12 July 20136670