Neighbor-Enhanced Link Prediction in Bipartite Networks
Guangtao Cheng, Chaochao Liu, Chuting Wei, Yueyue Li, Xue Chen, Xiaobo Li

TL;DR
This paper introduces a new framework for predicting links in bipartite networks that improves accuracy by addressing biases caused by uneven node connections.
Contribution
The novel framework adjusts for degree heterogeneity and leverages quadrangle graphs to enhance link prediction in bipartite networks.
Findings
The proposed framework effectively mitigates degree bias in bipartite networks.
It outperforms nineteen existing methods on ten diverse networks.
The method captures unique structural properties of bipartite networks.
Abstract
Link prediction in bipartite networks is a challenging task due to their distinct structural characteristics, where edges only exist between nodes of different types. Most existing methods are based on structural similarity, assigning similarity scores to node pairs under the assumption that a higher similarity corresponds to a higher likelihood of connection. Local structural methods, in particular, are widely favored for their simplicity, interpretability, and computational efficiency. However, real-world bipartite networks often exhibit highly heterogeneous node degree distributions, which introduce biases and undermine the effectiveness of traditional local structure-based methods. To address this issue, we propose a novel link prediction framework that explicitly adjusts for the degree heterogeneity of intermediate nodes between unconnected node pairs and incorporates their…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
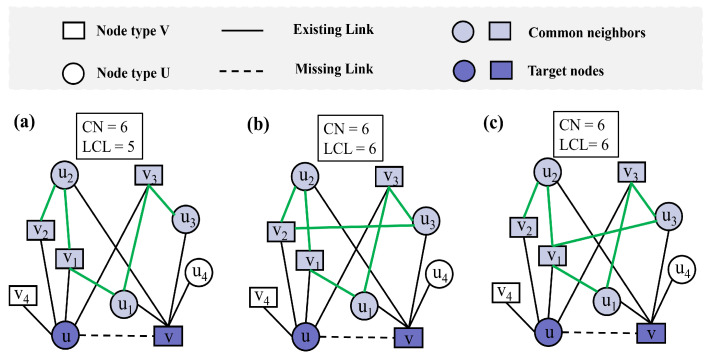 Figure 1
Figure 1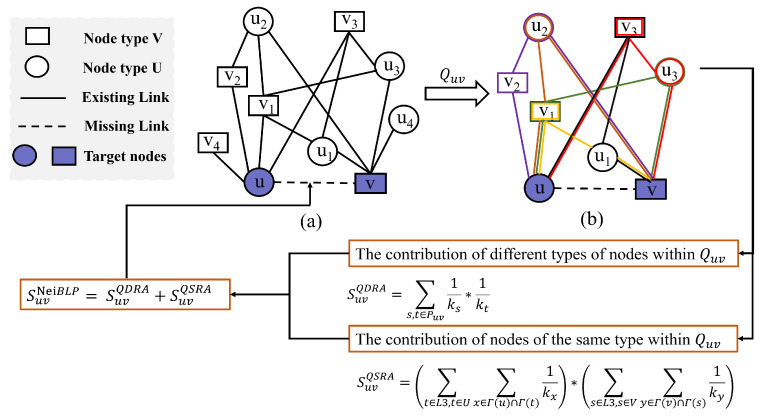 Figure 2
Figure 2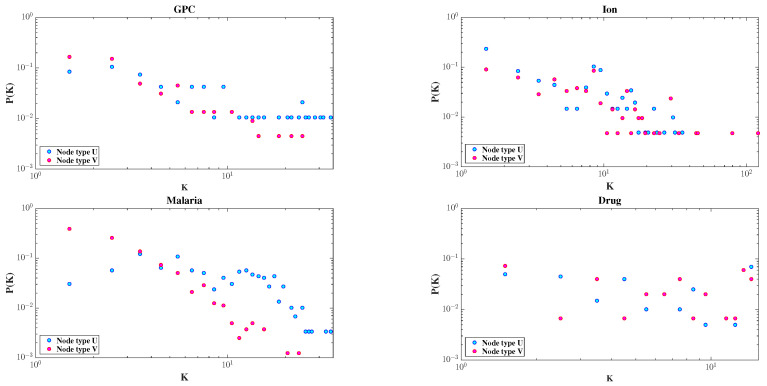 Figure 3
Figure 3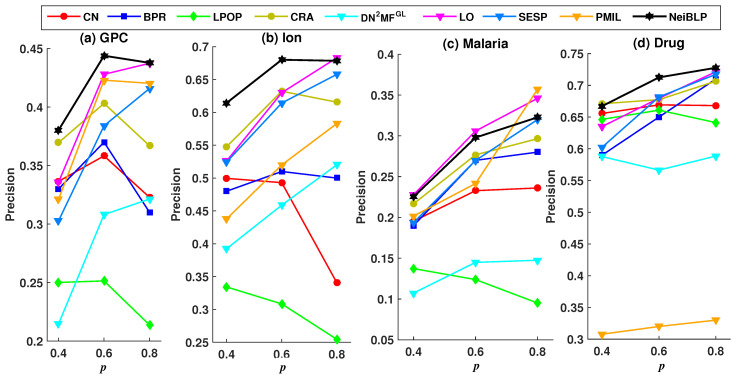 Figure 4
Figure 4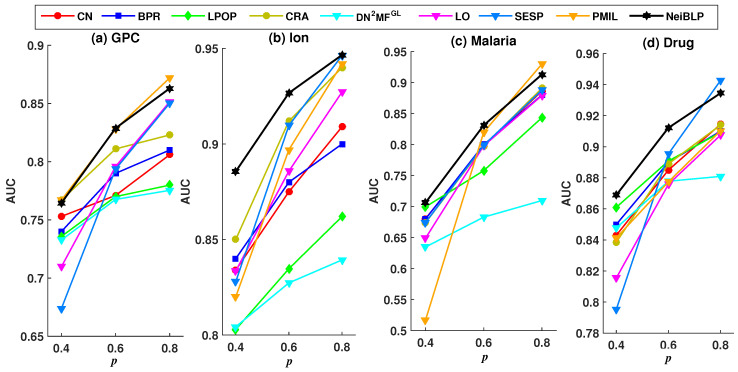 Figure 5
Figure 5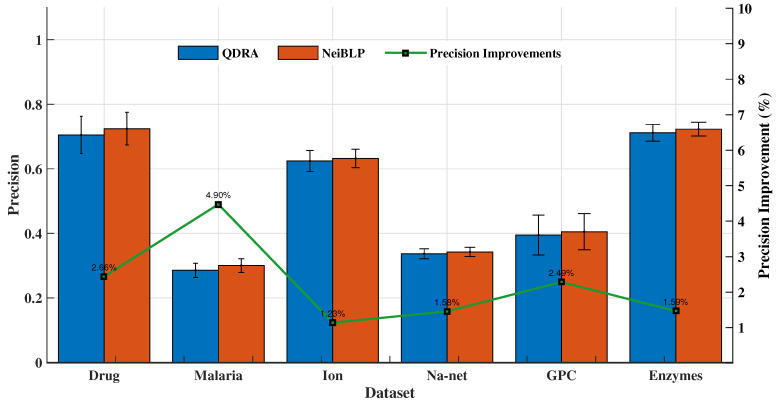 Figure 6
Figure 6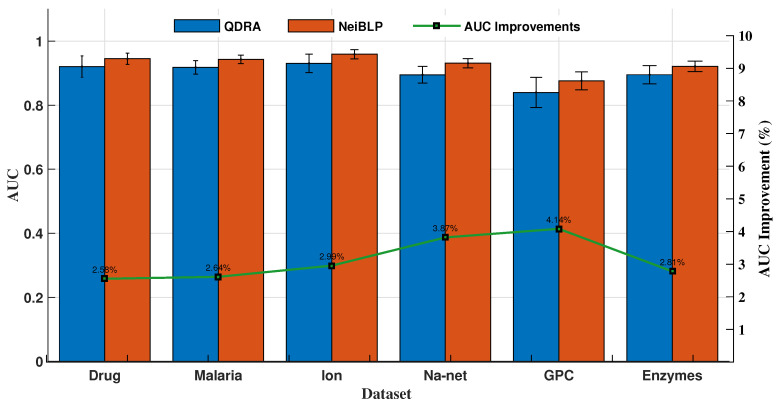 Figure 7
Figure 7| Category | Subcategory | Advantages | Disadvantages | Methods |
|---|---|---|---|---|
| Similarity-based | Local | Simple and efficient, low computational complexity | Capture limited structure information | CN [ |
| Global | Capture global structure information | High computational complexity | LPOP [ | |
| Quasi-local | Low time complexity | Limited information, network-dependent | LP35 [ | |
| Projection-based | Weighted projection | Advanced unipartite link prediction methods can be used | Loss of bipartite structure information | PLP [ |
| Unweighted mapping | Simple and intuitive | Association strength between nodes of the same type is missing | Refs. [ | |
| Dimensionality reduction-based | Matrix factorization-based | Capture global and local structure | Hyperparameter tunning | DNMF [ |
| Network embedding | Could utilize attribute information for prediction | Hyperparameter tunning, limited interpretability | STERLING [ | |
| Other methods | Structural perturbation theory | Efficient and robust | High time complexity | SPM [ |
| Information-theoretic | Highly interpretable | High time complexity | PMIL [ | |
| Deep learning | Capture non-linear structure information | Limited interpretability | ICTC [ | |
| GNN-based | Capture complex non-linear structural information | Limited interpretability | SRGL [ |
- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComplex Network Analysis Techniques · Advanced Graph Neural Networks · Bioinformatics and Genomic Networks
1. Introduction
Link prediction is a fundamental technique for analyzing relationships between entities within a network, and it has garnered significant attention across various fields of study [1,2]. The primary goal of link prediction is to identify missing connections or forecast future interactions. Due to its ability to unveil hidden mechanisms and the evolving patterns within real-world networks, link prediction has become invaluable in a wide range of practical applications. For instance, in criminal investigations, it assists in identifying concealed relationships between suspects or events [3,4]. In protein interaction studies, it supports the discovery of novel pathways that are essential for understanding cellular functions and drug design [5,6]. Additionally, link prediction has found widespread applications in recommendation systems, where it enhances personalization and improves user experience [7,8].
Traditional link prediction approaches can be categorized into similarity-based methods [9], probabilistic models [10], matrix factorization-based models [11], and network embedding approaches [12]. However, due to the distinct structure of bipartite networks, where links occur only between nodes from two different sets, traditional link prediction methods face inherent limitations and are not well suited for bipartite networks. To overcome these challenges, various methods specifically designed for link prediction in bipartite networks have been proposed, including similarity-based approaches, projection-based techniques, and dimensionality reduction methods.
Similarity-based methods [5,13] are relatively simple. They estimate the probability of a link between two unconnected nodes based on their similarity score, which is computed using the topological structure of the network. In particular, local similarity indices [9] often rely on the common neighbors (CNs) of two nodes, either in terms of the number of CNs or the topological structure of those CNs. These methods are generally straightforward and efficient as they only consider local neighborhood information of two unconnected nodes. Projection-based methods [14,15] transform bipartite networks into unipartite networks, enabling link prediction to be performed on the resulting projections. A key advantage of these methods is their ability to leverage advanced link prediction techniques designed for unipartite networks. However, the effectiveness of this approach heavily depends on the accuracy of the projection. Dimensionality reduction methods, such as matrix factorization (MF) [16] and network embedding techniques.
Ref. [17], aim to reduce the complexity of the data while preserving its underlying structure. Similar to projection-based methods, dimensionality reduction approaches must retain as much topological information as possible. However, their performance is highly sensitive to the choice of hyperparameters, and determining the appropriate values can be challenging.
Real-world bipartite networks often exhibit heterogeneous node degree distributions, characterized by a few high-degree nodes and many low-degree nodes [18,19]. This imbalance leads to substantial variation in the structure of bipartite networks. However, most existing similarity-based link prediction methods rely primarily on the number of common neighbors or their simple variants, without considering the structural organization of these neighbors. As a result, they are often ineffective at capturing subtle differences in local topology. To address this limitation, we propose the Neighborhood-enhanced Bipartite Link Prediction (NeiBLP) method, which not only accounts for the degree heterogeneity of intermediate nodes between unconnected node pairs, but also incorporates their contributions within the local connection patterns they form. This approach enables NeiBLP to differentiate between cases where intermediate nodes have varying degree distributions, an aspect often overlooked by traditional methods. Specifically, the framework leverages quadrangle graphs between unconnected nodes to analyze local topology and introduces two novel metrics to quantify the contributions of cross-type and same-type nodes, facilitating that both structural and degree variations are captured comprehensively.
The main contributions of this paper are summarized as follows:
- Model: The NeiBLP framework introduces a novel, parameter-free similarity approach to tackle degree heterogeneity in bipartite networks. By normalizing the contributions derived from the -Quadrangle Graph, the framework effectively mitigates the inherent degree bias commonly observed in such networks.
- Node contribution differentiation: NeiBLP proposes two novel indices, and , to distinguish the contributions of cross-type and same-type nodes. This differentiation effectively accounts for degree effects while simultaneously integrating shared neighbor information.
- Performance: We conducted experiments on ten real-world bipartite networks and compared NeiBLP to nineteen baseline algorithms. Our results demonstrate that NeiBLP outperforms the state-of-the-art bipartite link prediction algorithms and consistently achieves high AUC and Precision scores across diverse bipartite networks.
The rest of this paper is organized as follows. Section 2 provides an overview of related work on link prediction in bipartite networks. In Section 3, we present a detailed description of our proposed method. Section 4 introduces the datasets and their division, baselines, evaluation metrics, and discusses the experimental results. Finally, Section 5 summarizes the findings and concludes the paper.
2. Related Work
Recent years have witnessed the emergence of a wide variety of bipartite link prediction algorithms in the literature. These algorithms can be broadly categorized into four groups [2]: similarity-based methods, projection-based methods, dimensionality reduction-based methods, and other methods. In this section, we present a concise overview of representative methods, with a primary focus on similarity-based approaches due to their simplicity, interpretability, and widespread application. Moreover, Table 1 summarizes the advantages, limitations, and key studies associated with each category.
2.1. Similarity-Based Methods
Similarity-based methods are among the simplest and most effective approaches for link prediction. Based on their inherent characteristics, these methods can be broadly classified into local, global, and quasi-local indices.
Local indices rely on the immediate neighborhood of target nodes to compute similarity scores. Classic approaches include common neighbor (CN) [20], Adamic–Adar (AA) [21], and resource allocation (RA) [22]. RA leverages degree information of two nodes to compute their similarity, offering a simple yet effective approach for link prediction in unipartite networks. Despite its simplicity, RA has been successfully applied in personalized recommendation and graph reconstruction tasks [23]. Global indices, in contrast, utilize the entire network structure for similarity calculations. For instance, Katz [13] index considers all paths between node pairs, with shorter paths contributing more strongly to the connection probability. Quasi-local methods offer a balance between local and global indices by incorporating both local neighborhood and partial global information. Representative methods include local path (LP) [24] and local random walk [25].
Although these traditional methods are effective in unipartite networks, they encounter limitations when applied to bipartite networks. In bipartite networks, connections exist solely between nodes of two disjoint sets, and no links can form between nodes within the same set. This inherent structural property results in the absence of common neighbors between nodes of two different sets, thereby limiting the applicability of local and quasi-local indices that rely on shared neighbor information.
To address these challenges, researchers have developed modifications to traditional methods and developed new approaches. Cannistraci et al. [9] introduced the LCP theory, which extends the CN concept by considering not only the shared neighbors but also the structural organization of links between these neighbors. Although originally designed for unipartite networks, Daminelli et al. [26] adapted LCP theory for bipartite networks. In this adaptation, common neighbors in bipartite networks are derived from quadratic closures rather than traditional triadic closures. Classical indices, such as AA, CN, and PA, were redefined under this framework using the concept of links between common neighbors. Another promising direction involves methods leveraging the unique structural properties of bipartite networks. Since the shortest path length between two nodes in different sets is three, path-based methods have shown significant potential. For example, Kovács et al. [5] proposed a degree-normalized L3 score, which has proven effective for predicting missing protein–protein interactions in bipartite protein interaction networks. Zhao et al. [27] introduced odd-length path-based link prediction methods, encompassing all three subtypes of similarity-based indices and further expanding their applicability.
2.2. Projection-Based Methods
Bipartite networks are a unique network structure, and a common approach for link prediction in such networks is to project the bipartite network onto a unipartite network. Link prediction is then performed in the projected unipartite networks. Unweighted mapping is unable to provide the association strength between nodes of the same type [28,29]. One of the key challenges in projection-based link prediction methods is how to appropriately assign weights to the edges in the projected networks. Zhou et al. [14] proposed a weighting method based on a resource allocation process, where resources are allocated between nodes based on their connections in the original bipartite network. To improve computational efficiency, Gao et al. [15] performed link prediction within candidate node pairs (CNPs) in the projected graph. By focusing on link prediction exclusively within the CNPs, they reduced computational complexity. The connectivity of each CNP is determined by the weights of the patterns it covers. In the context of weighted networks, the concepts of weak and strong links have gained prominence. Aslan et al. [30] proposed the NARM model, which integrates a strengthened projection model with a time-aware proximity measure, allowing for the better capture of temporal dynamics in bipartite networks. Despite these advancements, a key limitation remains: it is difficult to accurately convert a bipartite network into a unipartite network. Moreover, the projected unipartite network must preserve the topological information of the original bipartite network to ensure effective link prediction.
2.3. Dimensionality Reduction-Based Methods
Dimensionality reduction-based methods include matrix factorization (MF) and network embedding methods.
Matrix factorization (MF) decomposes the adjacency matrix into the product of multiple low-dimensional matrices to uncover hidden relationships. Pech et al. [31] proposed a robust principal component analysis (RPCA) method, which decomposes the high-dimensional data matrix into a low-rank matrix and an error matrix. Chen et al. [32] focused on capturing intricate high-order relationships between nodes in bipartite networks and integrated these relationships into a unified framework for enhanced prediction accuracy. To capture hierarchical features of bipartite networks, Saberi et al. [33] introduced a deep non-negative matrix factorization method that preserves both global and local structures. The primary difference among them lies in the constraints applied during the factorization process, which influence the extraction of latent factors and the overall quality of the factorization.
Network embedding methods transform networks into low-dimensional vector spaces while preserving the structure information of bipartite network [34,35,36]. A seminal work in this domain is DeepWalk, proposed by Perozzi et al. [37], which pioneered the application of random walks for network embedding and opened a new research direction in the field. For bipartite networks, Huang et al. [38] proposed the BiANE framework, which captures both inter-partition and intra-partition proximities, offering a more comprehensive representation of the bipartite structure. To address the challenge of insufficient negative node pairs, Jing et al. [39] introduced a self-supervised learning method tailored for bipartite graphs. This approach preserves both local inter/intra-type synergies and global co-cluster synergies. However, these methods still face several challenges, including limited interpretability and the need for hyperparameter tuning.
2.4. Other Methods
Recent studies have demonstrated the effective application of perturbation theory for link prediction in unipartite networks [40], where it remains one of the most accurate approaches to date [41]. Building on the perturbation theory, Chen et al. [42] extended the perturbation framework to bipartite networks by constructing a two-layer network that integrates both implicit and explicit relationships between nodes. Additionally, Zheng et al. [43] proposed an RNA-disease association prediction model based on structural perturbation method, which effectively identifies biologically significant links within the bipartite networks.
Apart from perturbation-based methods, deep learning approaches have gained considerable attention in link prediction domain. For instance, Salha et al. [44] introduced a model that utilizes linear transformations in both the encoder and decoder, enabling effective processing of graph data. Shin et al. [45] applied a linear graph autoencoder, which facilitates the formation of new links by creating triangles in bipartite graphs. Furthermore, recent research has highlighted the importance of community structure in link prediction. Blöcker et al. [46] proposed MapSim, an information-theoretic measure that assesses node similarities based on the modular compression of network flow. The method is highly interpretable, as the network’s modular structure offers a clear explanation for the observed similarities.
Recently, with the rapid development of graph neural networks (GNNs), capturing network features has become more efficient and effective. Zhang et al. [47] proposed SEAL, a convolutional GNN-based link prediction framework that learns from both latent and explicit features of nodes as well as the structural information of graphs. However, SEAL is primarily designed for homogeneous graphs, whereas many real-world networks exhibit heterogeneous structures. To address this limitation, Zhang et al. [48] generalized SEAL to the bipartite graph link prediction task in recommender systems, introducing the Inductive Graph-based Matrix Completion (IGMC) model. Similar to SEAL, IGMC samples an enclosing subgraph around each target (user, item) pair but adopts a different node labeling scheme tailored for bipartite graphs. To further address the limitations of traditional GNN in modeling unobserved graph structures, Jin et al. [17] proposed a self-supervised learning approach called Self-supervised Reconstructed Graph Learning (SRGL), which simultaneously learns vertex embeddings and reconstructs the graph structure in a mutually beneficial manner.
3. Methodology
This section presents the proposed method, NeiBLP, starting with the problem definition. The limitations of existing structural measures are then discussed to motivate the development of a new approach. Finally, NeiBLP is presented in detail.
3.1. Problem Description
Consider an undirected and unweighted bipartite network , where U and V are two disjoint sets of nodes, and E is the set of edges that connect nodes exclusively between U and V. The given network can be represented by an adjacency matrix B, where and . In this matrix, if a links exists between two nodes and , and otherwise, . We further denote all possible edges as the set , and the set of non-existing edges as -E. The goal of link prediction in bipartite networks is to identify missing edges from the set -E.
3.2. From Structural Indistinguishability to a New Index
While traditional link prediction metrics provide valuable insights into network structures, they sometimes fail to capture subtle but significant differences in connection patterns. For example, in Figure 1a–c, nodes u and node v share the same set of common neighbors, i.e., , where the CN index [26] between nodes u and v is consistently 6. Thus, using CN alone cannot differentiate the link likelihood between these node pairs. Although the overall network topology remains largely consistent across the three subfigures, subtle changes in the local connections among common neighbors lead to differences in the LCL values. Specifically, compared with Figure 1a,b, which form an additional link, the LCL is increased to 6; and Figure 1c maintains the same LCL value as (b) but with a different pattern of interconnections. This highlights the importance of considering the connectivity between the neighbors of the two unconnected nodes, as it may vary despite identical sets of common neighbors.
Although the CN index and LCL index [50] between nodes u and v remain the same across Figure 1b,c, differences in the local topological structure are evident. For instance, in Figure 1b, the degree of is 3, while in Figure 1c, the degree of is 4. This example illustrates that the LCL index fails to account for such variations in node degrees within the local topology, which can influence link prediction performance. To address these shortcomings, we propose a new index that better captures local structural variations in bipartite networks.
3.3. NeiBLP: The Proposed Framework
In this section, we present two preliminary definitions that will be used in the rest of this paper. The concepts are defined as follows.
Definition 1( -Quadrangle Graph). Given two nodes and , the -Quadrangle Graph, denoted as , is the subgraph of the original bipartite network , consisting of all nodes and edges that belong to length-three (L3) paths between u and v, including u and v themselves.
Definition 2(Same-type resource allocation in bipartite networks). Inspired by the resource allocation (RA) index for unipartite networks, the same-type resource allocation (STRA) index extends the RA index to bipartite networks, specifically focusing on computing RA scores between nodes of the same type. Formally, the STRA score between two nodes and is defined as
where denotes the degrees of node x, and and represent the sets of all neighbors of u and t, respectively. The STRA index captures the intuitive idea that two nodes are more likely to connect if they share neighbors with low degrees.
Existing neighborhood-based indices in bipartite networks often neglect local connectivity patterns. To address the limitations, we propose the Neighborhood-enhanced Bipartite Link Prediction (NeiBLP) method. NeiBLP not only considers the degree heterogeneity of intermediate nodes between unconnected node pairs, but also incorporates the contributions of these nodes within the local connection patterns they form. NeiBLP can differentiate between such cases because the intermediate nodes have different degree distributions, which are often overlooked by traditional methods. Furthermore, NeiBLP preserves the neighborhood interaction structure between unconnected nodes in bipartite networks. The flowchart of the NeiBLP is shown in Figure 2.
Due to the effectiveness of the RA in unipartite networks, we extend it to bipartite networks by redefining the contributions of cross-type nodes within the framework established in Definition 1. This extension enables RA to better account for the structural characteristics unique to bipartite networks.
For a pair of target nodes and representing a potential interaction, let denote the -Quadrangle Graph as defined in Definition 1. The -based resource allocation (QDRA) for u and v is defined as
where is the set of all distinct L3 paths within , and and denote the degrees of intermediate nodes and , respectively. This normalization mitigates the influence of degree bias caused by variations in the intermediate nodes.
To better understand the structural characteristics of bipartite networks, we consider four real-world datasets: GPC, Ion, Malaria, and Drug. Each dataset consists of two disjoint types of nodes (denoted as U and V), with edges representing observed associations between them. These datasets are further described in Section 4.1.
The degree distributions of the two node types are shown in Figure 3. All four datasets exhibit skewed distributions; most nodes have very few connections, while a few serve as hubs. This highlights the heterogeneous nature of bipartite networks.
In such networks, node interactions are often influenced by biases originating from both same-type and cross-type neighbors. These biases can vary noticeably across different scenarios, thereby affecting the structural relationships between nodes. To effectively model this heterogeneity, it is important to account for the contributions of same-type nodes, under the assumption that nodes sharing common neighbors are more likely to exhibit higher similarity.
The same-type contribution, denoted as , captures the incremental similarity score contributed by same-type nodes along and is defined as
Here, and denote same-type intermediate nodes of u and v, respectively. The sets , , , and represent the neighbors of nodes u, v, t, and s, while and indicate the degrees of nodes and , respectively.
Due to considerations of complementarity, and capture different aspects of structural information. Addition allows these complementary informations to jointly influence the final similarity score, ensuring that both types of structural characteristics are effectively taken into account. The combined similarity score is given by
To illustrate the proposed NeiBLP framework, Figure 2 provides a step-by-step example. Specifically, Figure 2a depicts the original bipartite network, while Figure 2b shows a subgraph, denoted as , which contains six distinct L3 paths between nodes u and v. For example, one such path is . Within the subgraph, the NeiBLP framework separately calculates contributions by distinguishing the roles of same-type and cross-type nodes. For the cross-type contribution, the NeiBLP framework computes . For the same-type contribution, is calculated as . This example demonstrates how the NeiBLP framework effectively incorporates both same-type and cross-type node contributions by accounting for the degree heterogeneity of nodes within the local structure .
3.4. Algorithm Description
The NeiBLP framework differentiates between the roles of same-type nodes (nodes of the same type) and cross-type nodes (nodes of different types) by leveraging all L3 paths within the between two unconnected nodes. The calculation process is provided in Algorithm 1. Algorithm 1 The calculation process of NeiBLP frameworkInput: Bipartite network .Output: Predicted similarity matrix .
- 1:begin
- 2:for to 100 do
- 3: Divide B into training set and testing set
- 4: Calculate the contribution of cross-type nodes along according to Equation (2)
- 5:
- 6: Calculate the contribution of same-type nodes along according to Equation (3)
- 7:
- 8: Update according to Equation (4)
- 9:
- 10:end for
- 11:end
3.5. Complexity Analysis
The consists of two parts: and . For a node pair , computing involves enumerating all distinct length-3 paths from u to v within the quadrangle graph. Since each step involves visiting nodes with an average degree d, this process has a time complexity of . Similarly, calculating requires finding common neighbors between u and its same-type intermediate nodes, and between v and its same-type intermediate nodes, each contributing an additional time. Thus, the overall time complexity for computing for a node pair is In the worst-case scenario where all possible node pairs are considered for link prediction, the overall time complexity is .
4. Experimental Results
In this section, we evaluate the effectiveness of our proposed NeiBLP method using ten real-world bipartite networks. The experimental results demonstrate a consistent improvement in performance achieved by our method.
4.1. Datasets
To evaluate the performance of different algorithms, we utilized ten real-world bipartite networks from various domains as datasets. In these networks, and represent the number of nodes in the two distinct sets, while denotes the total number of edges. Key properties include average degree of nodes in U ( ), and average degree of nodes in V ( ). Sparsity indicates the proportion of unobserved interactions relative to the maximum possible number of interactions. The statistical characteristics of these datasets are summarized in Table 2.
The specific description of these networks are follows: (a) G-protein coupled receptors (GPC) [57]: This biological bipartite network consists of 223 drugs, 95 target proteins, and 635 experimentally validated drug–target interaction pairs. (b) Enzymes [57]: This biological bipartite network includes 445 drugs, 664 target proteins, and 2926 experimentally verified drug–target interaction pairs. (c) Ion channels (Ion) [57]: This biological bipartite network comprises 210 drugs, 204 target proteins, and 1476 experimentally confirmed drug–target interaction pairs. (d) Malaria [58]: This genetic bipartite network represents genetic sequences from the malaria parasite plasmodium falciparum. It includes 297 genes and 806 shared amino acid subsequences. (e) Drug–target (Drug) [59]: This biological bipartite network consists of 200 drugs, 150 target proteins, and 454 experimentally validated drug–target interaction pairs. (f) Southern women (SW) [60]: This social bipartite network represents 89 interactions between 18 white women and 14 social events. An edge exists between a woman and an event if she participated in that event. (g) Country–organization (C2O) [61]: This global bipartite network consists of 144 country nodes and 155 organization nodes, connected through 12,170 affiliation links. Each link represents a country’s membership or participation in an international organization. (h) Na-net [62]: This air transportation bipartite network consists of 940 city nodes and 940 coordinate nodes, connected by 6892 links. An edge indicates that a city is associated with a specific coordinate node based on the geographical position of its airport. (i) MovieLens100K (ML100K) (https://www.grouplens.org (accessed on 23 May 2025)): This social bipartite network consists of 943 users and 1574 movies, with a total of 82,520 user–movie rating interactions. The ratings range from 1 to 5, and in our experiments, we consider a link to exist between a user and a movie if the rating is greater than or equal to 3. (j) DBLP (https://www.dblp.uni-trier.de/xml (accessed on 23 May 2025)): This publication bipartite network represents the publishing relationships between 6001 authors and 1308 venues. An edge exists between an author and a venue if the author has published a paper at that venue.
4.2. Division of Datasets
To validate the accuracy of link prediction algorithms, bipartite network datasets are divided into training set and testing set based on different partition ratios. In this process, the set of edges removed for testing is denoted as , while the remaining edges constitute the training set, represented as . By definition, and . The algorithm’s predictive performance is assessed by its ability to identify edges in the testing set . Specifically, the prediction results are ranked in descending order, where edges from occupy the highest ranks and edges from appear at lower ranks.
4.3. Baseline Algorithms
In this paper, we select a total of nineteen representative link prediction methods from eight different categories in bipartite networks as baselines. These include three neighborhood-based methods, four path-based methods, two projection-based methods, three LCP-based methods, one structural perturbation method, four dimensionality reduction-based methods, one deep learning method, and one mutual information-based method. The selected baseline methods are summarized in Table 3.
4.4. Evaluation Metrics
and area under the receiver operating characteristic curve ( ) are used to measure the performance of various link prediction methods. specifically measures the proportion of correctly predicted links, while provides a comprehensive evaluation of the model’s overall performance.
(1) Precision
[64] evaluates the effectiveness of a link prediction model in correctly identifying relevant or true positive links among its predictions. Specifically, let the set of potential links be denoted as . If we rank all potential links by their similarity scores in descending order and select the top L links as the predicted missing links, and let be the number of these that are correctly predicted, then Precision is given by
In practice, L is often set to equal to the number of links in the test set .
(2) AUC
Compared to Precision, [65] measures the probability that a missing link receives a higher score than a non-existent link. For instance, consider n independent comparisons, where in each comparison, a missing link and a non-existent link are randomly selected to compare their scores. If the missing link has a higher score in cases and both links have the same score in cases, the AUC value is calculated as follows:
Obviously, higher scores in Equations (5) and (6) indicate greater prediction accuracy.
To evaluate prediction accuracy, the observed links E are randomly divided into a training set and a test set . All reported results are averaged over 100 independent runs. In our evaluation, we compute scores for all non-observed links between nodes in the bipartite network. Specifically, for each test link in , its score is compared against those of all other node pairs that are not connected in the training set . This setting ensures a more comprehensive and rigorous evaluation, particularly suitable for sparse bipartite networks.
4.5. Experiment Analysis
In this section, we present three experiments that were conducted to evaluate the performance of our proposed NeiBLP. First, we assessed its overall performance to evaluate the method’s effectiveness. Second, we analyzed its robustness under different training set ratios. Third, we performed ablation studies to investigate the contribution and effectiveness of each component within the framework.
4.5.1. Comparison with Baselines
To evaluate the performance of NeiBLP, we used AUC and Precision as the evaluation metrics for predicting missing links. For each experimental network, we partitioned of the links as the training set, while the remaining links were used as the testing set. To ensure robust results, we conducted 100 independent experiments for each method and calculated the average AUC and Precision. The results are summarized in Table 4 and Table 5, with the best values highlighted in bold and the second-best underlined. The hyperparameters used for the baseline methods are listed in Table 6.
In terms of AUC, NeiBLP achieves either the best or the second-best performance, showing consistent improvement over other baseline methods.
Several baseline methods could not be fully evaluated in our experimental comparison due to technical limitations. Specifically, as the PMIL method lacked publicly available source code, reimplementation was conducted based on the descriptions provided in the original publication. In addition, the ICTC was unable to operate effectively on the drug network, as its transformation into single-mode sparse matrices resulted in substantial information loss in highly sparse networks. Consequently, the corresponding entries in Table 4 and Table 5 are marked with the symbol “−” to denote unavailable results. Overall, perturbation-based method exhibits better predictive performance than neighborhood-based and LCP-based approaches. Among the path-based methods (i.e., L3, LP3, LP35, and LPOP), LP35 and LPOP consistently perform worse than LP3 across all datasets, highlighting the ineffectiveness of using paths longer than three. L3 achieves the best performance because it normalizes node degrees, mitigating the bias introduced by the varying degrees of intermediate nodes.
In terms of Precision, the LP3 exhibits lower performance than L3 across most bipartite networks. This observation suggests that solely considering third-order paths is insufficient to capture the connectivity between nodes, highlighting the necessity of considering node biases. LPOP shows a slight improvement over LP35 but remains inferior to L3. These results suggest that incorporating higher-order paths (e.g., LP35 and LPOP) often introduces additional invalid paths, which increases prediction noise and ultimately degrades performance. For neighborhood-based approaches, these methods generally demonstrate stable performance across most networks. RA typically outperforms CN and AA, which may be attributed to the fact that, in addition to considering common neighbors, RA considers the degree heterogeneity of the common neighbors. Among LCP-based approaches, CRA achieves the best performance, outperforming CAR and CAA on most bipartite networks, particularly on datasets such as Enzymes, SW, and ML. The SESP method, which employs a structural perturbation strategy and incorporates both implicit and explicit relationships, demonstrates strong performance on dense networks such as C2O, Na-net, and ML100K. However, its computational complexity is relatively high, which may limit its scalability in certain scenarios. Dimensionality reduction-based approaches exhibit strong performance on specific networks; however, these methods often involve a large number of hyperparameters, making their application more complex and less practical. In contrast, the NeiBLP method consistently achieves optimal performance across ten bipartite networks, demonstrating its stability and superior effectiveness.
4.5.2. Robustness Analysis
To evaluate the robustness of NeiBLP, we set the proportion of the training set p to , , and , and investigated the Precision and AUC under different training set ratios. A lower ratio indicates that more links are removed as the testing set. To ensure sufficient training set, we explored training set ratios no less than .
Considering the readability of the figures, we selected eight representative and relatively strong baseline methods for comparison. The evaluation results under different training set ratios are shown in Figure 4 and Figure 5.
In Figure 4 and Figure 5, the black line represents the performance of our NeiBLP, while the other color lines correspond to various approaches: red for neighborhood-based methods, yellow for LCP-based methods, dark blue for projection-based methods, green for path-based methods, light blue for structural perturbation, pink for dimensionality reduction, and orange for the mutual information-based approach. From Figure 4, when the proportion of the training set decreases from to , the proportion of missing links increases. The performance of NeiBLP exceeds that of other baseline methods, suggesting that NeiBLP is more effective under conditions with limited observable link information. This is particularly significant, as real-world bipartite networks are usually sparse. Additionally, an interesting trend is observed, for neighborhood-based and LCP-based methods, the Precision improves as the training set ratio increases from to . However, when the training set ratio further increases from to , a decline in Precision is observed.
As demonstrated in Figure 5, with the increases in the proportion of the training set p, all methods exhibit a consistent upward trend. The NeiBLP demonstrates the most stable performance across the four datasets and consistently achieves either the best or second-best results. As shown in Table 4, when the training data ratio reaches 0.9, the AUC and Precision values for the GPC and Malaria datasets in the PMIL method are lower than those of NeiBLP. Overall, the NeiBLP curve almost lies above the curves of other baseline methods, indicating that our method demonstrates superior robustness compared to others under different training set ratios.
4.5.3. Ablation Study
The QDRA index considers the contributions of different types of nodes within in bipartite networks, while NeiBLP extends beyond QDRA by also considering the contributions of nodes of the same type within . We evaluated the performance of QDRA and NeiBLP using AUC and Precision. Detailed comparisons are provided in Figure 6 and Figure 7. As shown in the figures, NeiBLP outperforms QDRA across all experimental datasets. The Precision improvements of NeiBLP over QDRA range from to , while the AUC improvements range from to . Moreover, NeiBLP demonstrates lower variance in performance compared to QDRA, highlighting its superior stability. The advantage of NeiBLP lies in its ability to consider the similarities among nodes of the same type within .
5. Conclusions and Discussion
In real-world bipartite networks, heterogeneous node degree distributions often undermine the effectiveness of traditional local structure-based link prediction methods, particularly in capturing subtle topological differences. To address this limitation, we propose NeiBLP, a parameter-free and interpretable link prediction framework that explicitly accounts for the degree heterogeneity of intermediate nodes between unconnected node pairs. By incorporating the influence of these intermediate nodes within local connection patterns, NeiBLP helps to improve prediction accuracy.
Unlike traditional methods, which are interpretable by nature but lack flexibility in handling structural heterogeneity, NeiBLP’s decomposition into cross-type resource allocation and same-type reinforcement components offers a more intuitive and fine-grained understanding of the underlying structure of predicted links. Comprehensive experiments on ten diverse real-world bipartite networks demonstrate that NeiBLP consistently achieves the best or second-best performance compared to nineteen state-of-the-art link prediction methods, confirming its effectiveness and robustness. In future work, the flexible design of NeiBLP can be further leveraged to incorporate node attribute information, where attribute similarities between same-type nodes could enrich the modeling of complex relationships. Moreover, enhancing the scalability of NeiBLP through the development of parallel implementations presents a promising direction to improve computational efficiency and broaden its applicability to large-scale bipartite networks.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kumar A. Singh S.S. Singh K. Biswas B. Link prediction techniques, applications, and performance: A survey Phys. A Stat. Mech. Its Appl.202055312428910.1016/j.physa.2020.124289 · doi ↗
- 2Arrar D. Kamel N. Lakhfif A. A comprehensive survey of link prediction methods J. Supercomput.2024803902394210.1007/s 11227-023-05591-8 · doi ↗
- 3Assouli N. Benahmed K. Gasbaoui B. How to predict crime—Informatics-inspired approach from link prediction Phys. A Stat. Mech. Its Appl.202157012579510.1016/j.physa.2021.125795 · doi ↗
- 4Rai A.K. Tripathi S.P. Yadav R.K. A novel similarity-based parameterized method for link prediction Chaos Solitons Fractals 202317511404610.1016/j.chaos.2023.114046 · doi ↗
- 5Kovács I.A. Luck K. Spirohn K. Wang Y. Pollis C. Schlabach S. Bian W. Kim D.-K. Kishore N. Hao T. Network-based prediction of protein interactions Nat. Commun.201910124010.1038/s 41467-019-09177-y 30886144 PMC 6423278 · doi ↗ · pubmed ↗
- 6Wong L. Wang L. You Z.-H. Yuan C.-A. Huang Y.-A. Cao M.-Y. Gklomli: A link prediction model for inferring mirna–lncrna interactions by using gaussian kernel-based method on network profile and linear optimization algorithm BMC Bioinform.20232418810.1186/s 12859-023-05309-w PMC 1016932937158823 · doi ↗ · pubmed ↗
- 7Dhelim S. Ning H. Aung N. Huang R. Ma J. Personality-aware product recommendation system based on user interests mining and metapath discovery IEEE Trans. Comput. Soc. Syst.20208869810.1109/TCSS.2020.3037040 · doi ↗
- 8Yu X. Tu L. Chai L. Wang X. Chen J. Construction of implicit social network and recommendation between users and items via the isr-rrm algorithm Expert Syst. Appl.202423512122910.1016/j.eswa.2023.121229 · doi ↗