TSTBench: A Comprehensive Benchmark for Text Style Transfer
Yifei Xie, Jiaping Gui, Zhengping Che, Leqian Zhu, Yahao Hu, Zhisong Pan

TL;DR
TSTBench is a new benchmark for evaluating text style transfer methods, offering a codebase and standardized protocol to improve evaluation consistency and reproducibility.
Contribution
The novel contribution is TSTBench, a comprehensive benchmark with implementations of 13 algorithms and a standardized protocol for text style transfer.
Findings
TSTBench includes a codebase with 13 state-of-the-art algorithms and a standardized protocol for text style transfer.
Experiments across seven datasets produced over 7000 evaluations, providing insights into TST performance and evaluation processes.
Abstract
In recent years, researchers in computational linguistics have shown a growing interest in the style of text, with a specific focus on the text style transfer (TST) task. While numerous innovative methods have been proposed, it has been observed that the existing evaluations are insufficient to validate the claims and precisely measure the performance. This challenge primarily stems from rapid advancements and diverse settings of these methods, with the associated (re)implementation and reproducibility hurdles. To bridge this gap, we introduce a comprehensive benchmark for TST known as TSTBench. TSTBench includes a codebase encompassing implementations of 13 state-of-the-art algorithms and a standardized protocol for text style transfer. Based on the codebase and protocol, we have conducted thorough experiments across seven datasets, resulting in a total of 7000+ evaluations. Our work…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
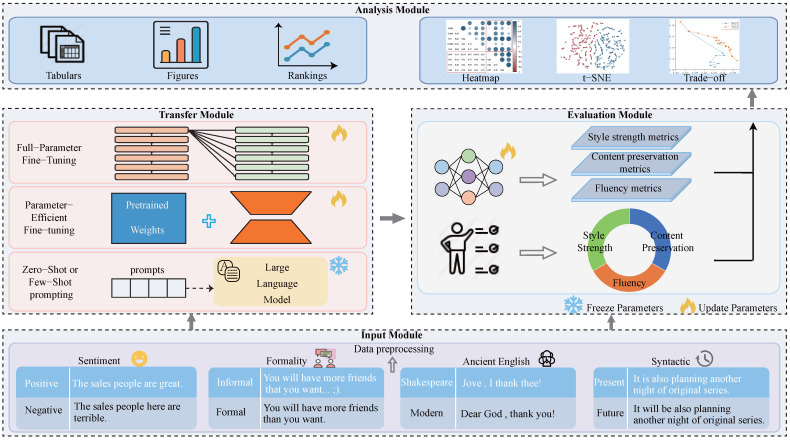 Figure 1
Figure 1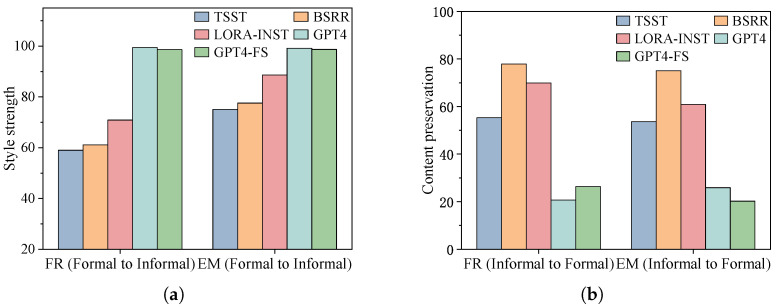 Figure 2
Figure 2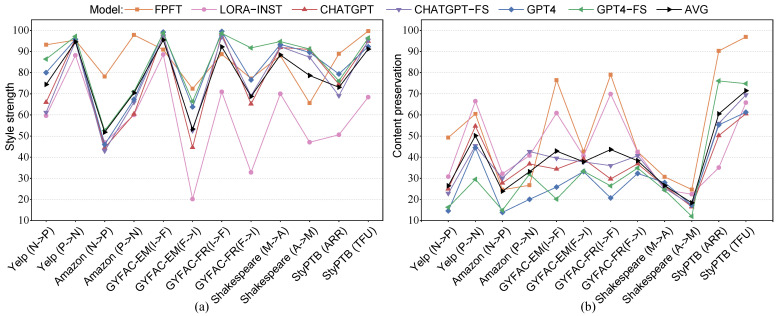 Figure 3
Figure 3 Figure 4
Figure 4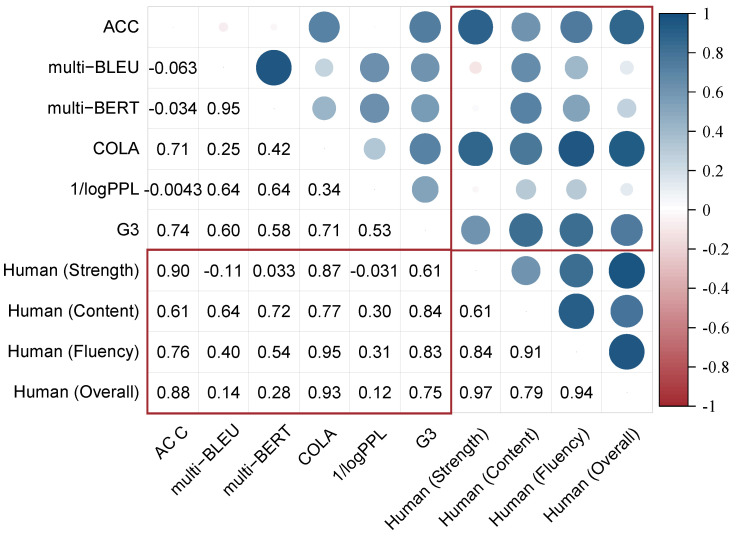 Figure 5
Figure 5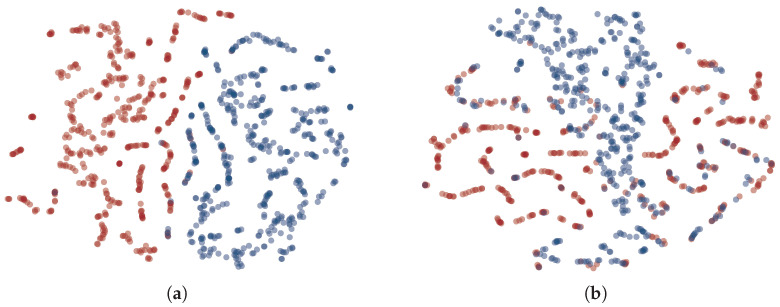 Figure 6
Figure 6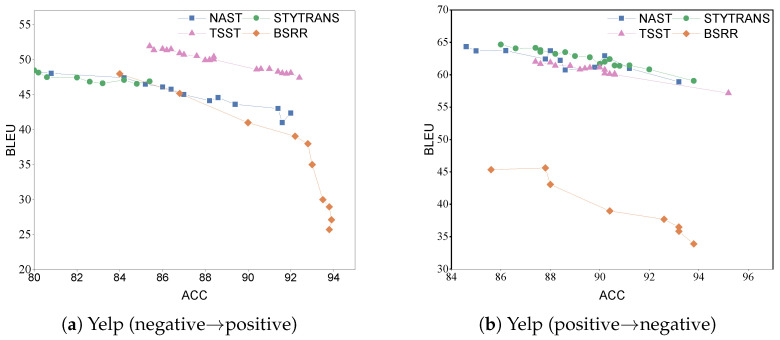 Figure 7
Figure 7- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTopic Modeling · Natural Language Processing Techniques · Music and Audio Processing
1. Introduction
As an important task in natural language processing, text style transfer (TST) aims to automatically change the style (e.g., emotion, formality, politeness, genre, and syntax) of text while preserving the main semantic content. This task is inherently linked to concepts in information theory, such as information preservation and entropy, as it involves transforming stylistic features without compromising the underlying meaning of the text. TST can be widely applied to natural language generation in many scenarios, such as human–machine dialogue, text formalization, translation into specific styles, and poetry generation. Despite the progress in new methods, TST lags behind other subfields of AI, such as computer vision with respect to style transfer. This situation is caused by various factors. Most research [1] has focused on learning style and content representations of text in an unsupervised manner due to the lack of parallel corpus. Another crucial reason is that we lack of a standardized criterion for evaluating these new methods. A recent study [2] calls for experimental comparisons to rank existing methods based on unified metrics. This situation is reflected in multiple aspects (e.g., there exist several commonly used methods for evaluating content preservation such as self-BLEU, ref-BLEU, BERT, BLEURT, etc.), which we explain in more detail below.
(1) Utilization of Different Datasets: The use of different datasets poses a challenge for comparing the performance of new methods. Even when using the same dataset, differences in format (e.g., whether pre-processed or not) can compromise the quality of model generation, ultimately impacting the model output [3]. Some methods may inherently only cater to some specific style or only one direction of style transfer, while others neglect to specify the direction altogether (e.g., [4,5,6]).
(2) Diverse Mechanisms for Model Inputs: New methods employ various mechanisms to generate model inputs. Most rely on pretrained language models (PLMs) to generate text representations (e.g., [7,8,9]), whereas others rely directly on task datasets (e.g., [4,5,6]). When conducting comparisons, it is more reasonable to specify whether a pre-trained model was used.
(3) Variation in Evaluation Metrics: New methods are often insufficiently evaluated, with varying evaluation setups, as shown in Table A1 in the Appendix A. Even for identical model output, the results of one metric, such as accuracy, may diverge from another based on different classification approaches. Furthermore, applying the same evaluation metrics to datasets with distinct styles has limitations due to differing levels of difficulty and unique characteristics within each task.
(4) Unfair Evaluation: Various factors, including diverse implementation settings (e.g., hyper-parameters for training) could potentially impact fair evaluations. These factors ought to be meticulously controlled when comparing TST methods, akin to how they are controlled in an ablation study for a single method.
Therefore, it is crucial to evaluate new methods using the same criteria. Otherwise, it becomes challenging to determine whether a new method outperforms its counterparts based on its foundational assumptions. Unfortunately, to the best of our knowledge, the current benchmarks do not adequately support thorough comparisons among methods for TST, as illustrated in Table 1. To bridge this gap, we have developed a comprehensive benchmark for TST, called TSTBench. The framework is built on an extensible modular-based codebase, comprising an input module, a transfer module, and an evaluation and analysis module. To ensure fair and reproducible evaluations, we provide a standardized protocol covering every step of the transfer process. Currently, we have incorporated 13 SOTA methods on TST and multiple visual analysis tools; researchers can easily integrate new methods and datasets into the evaluation framework for fair comparison. In this work, we also present the analysis from three perspectives: the effect of algorithms and datasets, the comparison between large language models (LLMs) and fine-tuned models, and the correlation between human and evaluation metrics, respectively. We summarize our contributions as follows.
We replicate and compare 13 text style transfer algorithms across seven datasets, providing both code and outputs.We provide a unified evaluation framework, utilizing 10 different evaluation metrics, which yield over 7000 evaluation outcomes. Our modular architecture allows researchers to integrate new methods and datasets, facilitating fair comparisons within a standardized evaluation environment.We conduct a thorough analysis and have obtained new findings and conclusions. We have made our code publicly available on GitHub (https://github.com/FayeXXX/A-Benchmark-of-Text-Style-Transfer (accessed on 28 April 2025)).
2. Related Work
2.1. TST Algorithms
Text style transfer (TST) has emerged as a significant area of research in natural language processing, aiming to transform text from one style to another while preserving its original content [15,16,17,18,19]. Early methods aim to learn and separate the content and style of text [20,21]. Many approaches adopt disentanglement strategies, mapping text into a latent space to obtain latent representations that separate content and attributes, achieving some promising progress [20,21,22,23,24,25,26]. Subsequently, numerous strategies utilizing reinforcement learning emerged, designing various reward functions to enable models to better learn the representations of text content and style, as demonstrated in [27,28,29,30]. Other methods employ back-translation strategies, such as [31,32]. Additionally, some approaches use pseudo-parallel corpora for training, as seen in [33,34,35]. Further techniques focus on separating the content and style of text from the perspective of the text itself, using strategies that involve deleting and replacing style-related words [36,37,38,39,40,41].
To date, large-scale pre-trained language models (PLMs) like BERT [42], RoBERTa [43], XLNet [44], GPT [45], BART [46], ELECTRA [47], and T5 [48] have gradually become the new paradigm in natural language processing. Leveraging large corpora and unsupervised learning based on the transformer architecture, these models achieve state-of-the-art (SOTA) performance with merely fine-tuning on downstream tasks. As such, enhancing transformer-based models for text style transfer has become a popular research topic. This paper, therefore, focuses on transformer-based models. These methods can be categorized into three main groups based on their approach to parameter tuning during training: full-parameter fine-tuning, parameter-efficient fine-tuning, and zero-shot or few-shot prompting.
(1) Full-Parameter Fine-Tuning (FPFT). These methods can be further categorized into three groups depending on their approach to controlling text style [6]: embedding-based, decoder-based, and classifier-based. Embedding-based methods (e.g., CAAE [49], NAST [50], StyIns [24], TSST [6], and Styletransformer [4]) leverage style embeddings to direct the style of generated text. The decoder-based approach involves using dedicated decoders for each style transformation direction to control text style and includes Multi-decoder [51], STRAP [9], BSRR [8], TYB [7], and DualRL [52]. The classifier-based approaches, such as PPLM [53], Gradient-guided TST [54], RevisionTST [55], and CTAT [5], adjusts the latent representation of text through a well-trained style classifier.
(2) Parameter-Efficient Fine-Tuning (PEFT). These approaches aim to effectively fine-tune LLMs by training only a small proportion of parameters [56]. These parameters can either be a subset of the current model parameters (e.g., BitFit [57], DiffPruning [58]) or a newly added set of parameters (e.g., Adapter [59], prefix-tuning [60], prompt-tuning [61], LoRA [62]).
(3) Zero-Shot or Few-Shot Prompting (ZSFS). LLMs like ChatGPT [63], InstructGPT [64], PaLM [65], and GPT4 [66], have shown promising results in text genration. Meanwhile, CAT [67], ICLEF [68], and StyleChat [69] design prompting methods to Chatgpt and GPT4 for text style transfer on formality and authorship datasets. Each of these methods has its unique strengths and weaknesses; we select some representative algorithms to evaluate within our TSTBench.
2.2. Related Benchmarks
Several benchmarks have been introduced to evaluate TST tasks, such as GYAFC [10], MATST [11], CDS [9], StylePTB [12], XFORMAL [13], and LMStyle [14]. However, as shown in Table 1, these benchmarks often focus on a limited number of style types and evaluate only a subset of available algorithms. Additionally, they may lack comprehensive evaluation metrics, making it challenging to compare different approaches effectively. The work most similar to ours is the benchmark presented by Hu et al. [70]. This study is notable for its survey of TST methods but lacks detailed experimental settings and evaluations, which are crucial for standardizing benchmarks. Our work, TSTBench, addresses these limitations by providing a comprehensive evaluation of a wide range of TST algorithms across multiple style types, detailed experimental settings and configurations to ensure reproducibility, an extensive set of evaluation metrics to assess various aspects of TST performance, and in-depth analysis of the results.
3. TSTBench
We evaluate 13 TST algorithms across seven datasets using 10 different metrics, alongside human evaluations. In the subsequent subsections, we provide comprehensive details: Section 3.1 introduces the baseline algorithms, Section 3.2 discusses the datasets, Section 3.3 describes the evaluation metrics, and Section 3.4 offers an overview of the codebase.
3.1. Baseline Algorithms
We include 13 TST algorithms for evaluation in our benchmark, as shown in Table 2. Transformer-based models have dramatically improved performance across various NLP tasks and now represent the leading approach in the field. As a result, this paper focuses on algorithms that leverage the transformer architecture. These algorithms are either well-known or the state-of-the art, representing the latest advancements in the field. Specifically, seven algorithms (STYTRANS [4], TSST [6], NAST [50], STRAP [9], BSRR [8], TYB [7], and CTAT [5]) are classic methods that span three strategies of FPFT. The remaining six algorithms—LlaMa-LORA, LlaMa-LORA-INST [62], CHATGPT [63], CHATGPT-FS [63], GPT4 [66], and GPT4-FS [66]—are recently published methods based on LLMs. This selection allows us to compare the performance between fine-tuned models and traditional models versus LLMs. The details of the implemented algorithms are presented in Appendix A.1.
3.2. Datasets
We employ datasets representing both high-level and fine-grained styles, as detailed in Table 3. Our selection process is guided by two main criteria: First, the chosen datasets must be well-maintained and widely recognized, while also covering a diverse range of text types. Second, each dataset must contain a sufficient number of instances for experimentation. Ultimately, we focus on seven datasets that correspond to four types of TST tasks:
(1) Sentiment Transfer. We leverage two widely used sentiment datasets, Yelp [36] and Amazon [71]. Both datasets contain non-parallel data, derived from restaurant reviews on Yelp and product reviews on the Amazon website, respectively. For the Yelp test dataset, we utilize the data provided by [52], where each source-style sentence corresponds to four target-style sentences for reference.
(2) Formality Transfer. GYAFC (EM) or GYAFC (FR) [10] is the most commonly used formality dataset that originate from entertainment/music and family relationship-themed content, respectively. We utilize the test dataset according to the data in [10], incorporating four reference target-style sentences for each testing sentence.
(3) Ancient English Transfer. We leverage the Shakespeare dataset [72], which comprises both Shakespearean-style Old English and modern English data. This dataset presents a unique opportunity to explore style transfer across different linguistic and temporal contexts.
(4) Syntactic/Semantic Style Transfer. We also include the recently proposed StyPTB-TFU and StyPTB-ARR datasets [12]. The former focuses on syntactic style transfer that updates the present tense to the future tense in the text. The latter explores semantic style transfer, involving the removal of adjectives and adverbs from the text. Notice that we do not include other datasets under StyPTB because of their limited sample sizes, which range from two hundred to two thousand samples.
We follow the established practices for each model and partition the datasets into training, validation, and testing sets, as outlined in Table 3. This ensures consistency with prior research methodologies. Before initiating training, we pre-process the data by cleaning and truncating them. Specifically, we remove additional white spaces or punctuation marks separated by spaces within sentences [3]. Additionally, we truncate sentences to 64 words based on the average length.
3.3. Evaluation Metrics
TSTBench utilizes both a uniform set of automatic metrics and human evaluation to systematically evaluate different TST algorithms in terms of style strength, content preservation, and fluency. Below, we elaborate on evaluation methods in detail.
3.3.1. Automatic Evaluation
The evaluation of automated metrics on text style transfer primarily encompasses three key characteristics: style strength, content preservation, and fluency.
(1) Style strength. Assessing the style strength of TST often involves training a binary classifier to determine if the generated sentences align with the target style [73]. This characteristic is typically measured by the accuracy metric, as the ACC (accuracy) of the output sentences reflects the success rate. Specifically, given input sentences in style i and the target style j, the classification model is trained to determine whether the output sentences adhere to style j. This includes utilizing various classifiers such as a linear classifier (e.g., fastText [74]), a 3-layer CNN (e.g., TextCNN [75]), and a classifier based on RoBERTa [43]. The training process employs cross-entropy loss to optimize the classification model. In information theory, cross-entropy measures the difference between two probability distributions—the true distribution of the data and the predicted distribution by the model. Minimizing cross-entropy loss effectively reduces the uncertainty in predictions, aligning with the goal of improving the model’s ability to accurately capture the stylistic properties of the target style. We leverage the RoBERTa classifer [43] due to its outstanding performance, as shown in Table 4. In our analysis, higher accuracy in evaluating the ground truth indicates superior performance of the respective evaluation model, highlighting its ability to accurately identify sentences that adhere to the desired style. However, using trainable classifiers can lead to biases during evaluation, particularly because these models, like many neural network models, can be susceptible to adversarial examples, as discussed in [1]. This issue is especially pronounced in sentiment classification tasks, where positive and negative sentences may differ by only a single word, making it challenging for RoBERTa to provide high-confidence judgments. In this work, we present the RoBERTa classifier as a baseline reference.
(2) Content preservation. BLEU stands as the most commonly employed metric and can be formulated as follows:
where BP represents the brevity penalty and calculates the precision of n-grams between candidates C to be evaluated and a collection of references.
where indicates the number of times an n-gram in the model’s output matches an n-gram in the reference sentence and represents the total occurrences of each n-gram in the candidate sentences, ensuring precision considers both matched and unmatched elements.
The brevity penalty (BP) is applied to penalize translations that are shorter than their corresponding reference texts, adjusting the score as a corrective measure:
Here, c represents the length of the candidate translation, and r is the length of the reference translation. This adjustment ensures that overly short translations do not achieve artificially high scores due to higher precision metrics.
However, these methods do not consider the inevitable alteration of style words during text style transfer [76] and are unable to determine the semantic similarity of synonyms. For example, in the sentiment transfer dataset, the original sentence “The food was tasteless and dry.” is transformed into “The food was flavorful and moist.”, resulting in a BLEU score of 0.3 despite most of the content being preserved. When the core content remains unchanged while only the style words are altered, BLEU tends to assign the low score. This occurs because BLEU’s n-gram matching mechanism fails to distinguish between style words and content words [1]. Most existing benchmarks did not consider these factors. A recent study by [77] shows that BERTScore metrics [78] can be utilized to a certain extent as a substitute for human evaluation. The language model enables the utilization of BERTScore metrics that harness their linguistic capabilities, thereby eliminating the sole dependence on superficial features of n-grams. The BERTScore calculates the precision and recall metrics by comparing each token representation x of the reference translation to each token representation of the candidate translation. Specifically, measures how well tokens in the candidate match those in the reference, while assesses how well tokens in the reference are represented in the candidate. The harmonic mean of these scores is given by , providing an overall measure of similarity:
To mitigate BLEU’s limitations, adjusting the weights in the BLEU calculation to assign higher importance to non-style n-gram matches or combining BLEU with the BERTScore as a hybrid metric could be an effective solutions We provide both BLEU and the BERTScore [78] to compare the output sentences with the input sentences (i.e., s-BLEU, s-BERT), or with reference sentences (i.e., r-BLEU, r-BERT; multi-BLEU, multi-BERT, if multiple references exist). We calculate the BLEU score using all available references in cases where human-written references exist.
(3) Fluency. Traditional methods to evaluate fluency often rely on manual human assessment in several aspects, including grammar, readability, and naturalness. However, to complement these subjective evaluations, Perplexity (PPL) offers an automated metric. PPL is defined as the exponentiated average negative log-likelihood of a sentence, given the language model LM, focusing on predicting the next word in a sequence based on training data:
where denotes the i-th word in the sentence, and N is the total number of words in the sentence. PPL leverages the inherent capabilities of language models such as KenLM [79] and GPT-2 [80]. However, challenges remain regarding unbounded values and the observation that sentences with common words can yield low perplexity scores. To address this, [9] introduces a RoBERTa-large classifier trained on the Corpus of Linguistic Acceptability (CoLA) [81], a grammar-checking classifier used to assess grammatical acceptability [9].
PPL evaluates fluency based on a language model’s training distribution, which suffers from model bias and is style-agnostic, while CoLA serves as a binary grammatical norm checker focusing on sentence correctness. Together, they offer a multi-dimensional evaluation from linguistic fluency and grammatical correctness, ensuring texts meet basic language standards. Recognizing the complementary nature of perplexity and the CoLA classifier in capturing distinct aspects of model performance, we employ both to ensure a comprehensive evaluation. Specifically, we utilize KenLM [79], a language model, as our primary tool to calculate perplexity. We fine-tune two distinct KenLM models on both source style sentences and target style sentences. Subsequently, we use the refined target-style model to assess the perplexity of the generated sentence
Finally, to comprehensively evaluate the overall performance across all three key characteristics, we compute the geometric mean (denoted as Joint) of ACC, BLEU, and . When multiple references are available, we use multi-BLEU; otherwise, we select r-BLEU as the BLEU score for the calculation of the Joint score. The current equal-weight Joint score metric, while widely adopted in TST studies, leaves room for improvement regarding optimal weighting strategies.
3.3.2. Human Evaluation
We collect human evaluation for the style strength, content preservation, fluency, and overall performance of the generated sentences. To achieve this, we invited three annotators who are fluent English speakers (each holding at least CET-6 certification or equivalent) and possess at least a master’s degree. Most of them have research experience in fields related to natural language processing. They assign scores on a scale from 1 to 5 for each aspect. A total of 50 samples from each algorithm are randomly selected and presented to the evaluators, resulting in 7300 annotated samples, with each sample receiving four scores. Many existing works do not provide details of the scoring standards, making it difficult to reproduce human evaluation. To address this, we have established specific scoring criteria for each of the three evaluation aspects. Raters strictly adhere to the standards while scoring, as follows:
Our evaluation considers each sentence’s text style strength, content preservation, text fluency, and overall quality using a scale of 1–5. Evaluators are simultaneously provided with the source style sentence, the reference sentence, and the candidates generated by different algorithms. For evaluating style strength, a fully transformed sentence into the target style scores 5, partial transformation scores 3, and no change in style scores 1. For content preservation, if the meaning is the same but expressed differently, it scores 3, and if the meaning is entirely different, it scores 1. For fluency, a sentence with no grammatical errors scores 5, minor grammatical errors that do not affect semantic expression score 3, and incoherent sentences score 1. As for the overall score, experts evaluate overall performance considering text style strength, content preservation, and text fluency. While experts usually use arithmetic averaging for overall scoring, there is a special case. When the candidate sentence is identical to the original, the text style strength score will be low, but the content preservation and text fluency scores will be high, resulting in a high overall score for the three indicators. In such cases, since no style correction has been made, we apply a penalty by multiplying the overall score by 0.6 to determine the final score. Inter-rater agreement is computed using Fleiss’ kappa coefficients across all evaluation dimensions: for style accuracy, for content preservation, and for fluency. Detailed guidelines and the scoring results are available in our code repository.
3.4. Codebase
As shown in Figure 1, we design TSTBench following a structured framework. It consists of four modules, including the input module, transfer module, evaluation module, and analysis module. We outline each of the modules in more detail as follows:
(1) Input module. The input module comprises two steps: dataset pre-processing and prompt formulation. We provide text cleaning scripts to pre-process all input data, aiming to avoid incomplete pre-processing issues that could compromise the quality of text outputs. After this process, we prepend natural language to the testing sentence for the PEFT and ZSFS algorithms. More details will be presented in Appendix A.3.
(2) Transfer module. As depicted in Table 4, three sub-modules are provided corresponding to the three major TST methods (FPFT, PEFT, and ZSFS), which generate target-styled sentences.
(3) Evaluation module. This module includes style strength (measured by ACC using a RoBERTa classifier), content preservation (evaluated through comparisons of the output sentences with the input sentences using s-BLEU and s-BERT or with reference sentences using r-BLEU, r-BERT, and, if multiple references exist, multi-BLEU and multi-BERT), fluency (assessed by PPL and COLA), and overall score evaluation metrics (Joint score).
(4) Analysis module. We provide analysis tools such as heatmaps, t-SNE, and trade-off figures. Heatmaps assist in analyzing the correlation between evaluation metrics and human ratings, while t-SNE helps visualize the distribution of source-styled sentences and target-styled sentences. We have also introduced a standardized protocol for invoking the aforementioned functional modules to ensure fair and replicable TST evaluations, including various stages such as data pre-processing, style transfer, result evaluation, and analysis.
4. Evaluations and Analysis
In this section, we first describe the evaluation settings before presenting our findings. We start by giving an overview of model performance across various styles. Following this, we compare large language models (LLMs) with fine-tuned models in the context of text style transfer (TST). Finally, we examine the correlation between automatic evaluation metrics and human evaluations.
4.1. Experimental Settings
The installation packages and versions for each replication algorithm are available on our homepage. We utilized the API interface to evaluate the capability of LLMs. Specifically, the ChatGPT version tested in the experiment was “gpt-3.5-turbo-1106”, and the GPT-4 version was “gpt-4-0125-preview”. Additionally, for PEFT algorithms, we employed the 7B-parameter Llama [82] and quantized it to 4-bits using QLoRA [83] to fit our GPU memory.
Classifier models for evaluating style strength are trained on the Roberta-base model for three epochs to prevent overfitting. Evaluation based on BERTScore was conducted using the original implementation (https://github.com/Tiiiger/bert_score (accessed on 28 April 2025)). For perplexity evaluation, we utilize the KenLM (https://github.com/kpu/kenlm (accessed on 28 April 2025)) model trained on each transfer style. In evaluating COLA score, we employ the RoBERTa-large classifier trained on the CoLA corpus (https://huggingface.co/cointegrated/roberta-large-cola-krishna2020 (accessed on 28 April 2025)). Consistent hyper-parameter settings are maintained for various style transfer directions within the same dataset. The replication experiments for TSTBench were conducted on 1 Tesla A100 GPUs (40 GB).
Regarding hyper-parameter settings, if specific values are provided in the original paper, we replicate the experiments utilizing those values. Otherwise, we conduct grid searches within a reasonable range for hyper-parameters that yield optimal performance. In addition to replicating experiments from papers, we also aim to explore the generalization of classic algorithms across different datasets. Most papers only experiment on one or two datasets, but we strive to cover as many datasets as possible. We have supplemented experiments with algorithms on other styles, except for the following cases: (1) papers explicitly stating that they can only perform certain specific style tasks, (2) algorithms themselves having requirements regarding the size of the dataset, and (3) algorithms only applicable to parallel datasets.
4.2. Overview of Model Performances Across Styles
Through the demonstration of Table A4, Table A5, Table A6, Table A7, Table A8, Table A9, Table A10, Table A11, Table A12, Table A13, Table A14 and Table A15 in Appendix B, we assess the performance of different models within every transfer direction. In order to visually discern the differences between these models, we represent the style strength, content preservation, and text fluency using bar graphs on the same dataset and style transformation direction, as depicted in Figure 2. Our findings indicate that no model excels in all evaluation metrics, nor are there universally applicable algorithms. TYB demonstrates superior generalization, achieving the highest joint scores in 6 out of 12 transfer directions. For more rigorous statistical validation, we calculate 95% confidence intervals for all Joint score comparisons to strengthen our findings. Our evaluation was conducted on four datasets that meet TYB’s requirement for parallel training data in supervised learning, with each dataset containing at least 1000 instances to ensure reliable statistical analysis. As shown in Table A16, there are statistically significant differences in performance between the models. TYB consistently shows superior performance across multiple datasets, with its confidence intervals not overlapping with those of other models. However, its reliance on parallel data for fine-tuning pre-trained models inherently limits its applicability in unsupervised scenarios (e.g., sentiment transfer). To address this limitation, future work could explore data augmentation techniques such as back-translation to generate pseudo-parallel data, thereby extending TYB’s utility to non-parallel settings. Following closely behind are the BSRR and TSST algorithms. The TSST algorithm, an unsupervised approach, even outperforms supervised methods in sentiment transfer. It employs transductive learning, where retrieved samples provide style examples in specific contexts. This enables the model to learn styles that match the content, thereby avoiding the generalization errors associated with inductive learning and achieving excellent performance. However, TSST faces challenges such as high time complexity in the retrieval process and a relatively complex model structure. Meanwhile, BSRR combines bootstrapping with reinforcement rewards, enabling efficient style transfer with minimal data. Despite its advantages, its performance relies on the data quality, which potentially limits its effectiveness in scenarios with data noise, such as the Amazon dataset.
Nonetheless, unsupervised algorithms consistently performed below average on COLA values. This suggests that unsupervised fine-tuning algorithms generated sentences that often do not adhere to grammatical rules. Despite this, the PPL evaluation metric performed well. Therefore, solely relying on PPL as a singular metric for evaluating semantic fluency is not justifiable; it requires a combined assessment with COLA values. Our observation further indicates that model performance varies across different transfer directions within the same dataset. For instance, on the GYFAC (FR) dataset, the TYB model performs exceptionally well in the informal to formal direction, while its performance in the formal to informal direction falls only at an average level. Consequently, it is crucial to specify the style direction when conducting TST evaluations in the future.
Finding 1: No single model performs exceptionally well across all evaluation metrics,and there are no universally applicable algorithms. Furthermore, as performance variesacross different transfer directions within the same style, we recommend clarifying thedirection of style transfer when evaluating its performance.
4.3. Comparison Between LLMs and Fine-Tuned Models on TST
To better contextualize the performance of LLMs against fine-tuned models (including models of full-parameter fine-tuning (FPFT) and parameter-efficient fine-tuning (PEFT)), we selected the SOTA fine-tuned models for comparison with LLMs. Figure 3 illustrates the performance of ACC and BLEU scores across all datasets. Specifically, we aim to answer three main questions: (1) How do the capabilities of LLMs on TST compare to those of fine-tuned SOTA models in terms of automatic metrics? (2) How does an LLM’s performance on TST compare to that of a fine-tuned SOTA model in terms of human evaluators? (3) Do the current evaluation metrics align with the assessment of LLMs? Below, we present a detailed analysis.
(1) Overall, the performance of most LLMs does not surpass that of fine-tuned SOTA models. We identified multiple reasons that could contribute to such a circumstance. Firstly, LLMs tend to paraphrase input sentences, resulting in lower content preservation. Secondly, the linguistic expression of LLMs is more flexible, causing the distribution of generated text to be inconsistent with the input text. This leads to a less favorable performance when using string-based methods to measure the fluency of generated text compared to fine-tuned SOTA models. Therefore, even while 5 out of 12 datasets show superior performance by LLMs in terms of style strength, their advantage in the overall performance across three evaluation aspects is not significant. Moreover, LLMs exhibit disparities in performance compared to fine-tuned SOTA models, especially in understanding negative texts, where the sentiment polarity often remains unchanged during style transfer. Additionally, GPT4 demonstrates a better understanding of negative sentiment compared to ChatGPT, consistent with findings in references [84,85]. Furthermore, LLMs struggle to effectively remove adjectives and adverbs, tending to generate sentences with more adjectives and adverbs compared to humans, resulting in relatively unsatisfactory results when tasked with their removal.
(2) Human preference strongly favors LLMs in TST tasks, indicating the superior performance of LLMs compared to fine-tuned SOTA models across various datasets, as shown in Figure 4. Analysis using correlation heatmaps reveals that human ratings exhibit a marked preference for linguistic fluency, consistently awarding higher scores to semantically fluent text. LLMs demonstrate an adeptness at generating linguistically fluent text, particularly in terms of grammatical correctness. Notably, across all datasets, the highest COLA values are associated with text generated by LLMs. Moreover, human evaluations consider GPT4 to be the best model on one third of the test datasets.
(3) The automatic evaluation metrics designed for fine-tuned models may not be suitable for evaluating LLM models. As previously mentioned, evaluation metrics used for LLMs indicate significantly lower scores compared to those used for SOTA models, particularly in terms of content preservation as measured by BLEU and fluency as measured by PPL. Due to LLMs’ tendency to rewrite input sentences, string-based content preservation evaluation methods are also not applicable to LLMs, similarly affecting string-based metrics such as METEOR [86] and chrF [87]. Moreover, PPL is sensitive to the length of the text, displaying instability, especially for short texts [88]. Table 5 presents statistics on the generated sentence lengths, revealing that LLMs’ generated sentences are 17.75% longer for formal transfer and 23.1% longer for positive transfer than the average ground-truth text.
4.4. Human Correlation of the Evaluation Metrics
To analyze the correlation between human evaluation metrics and automatic evaluation metrics, we adopt the Pearson correlation coefficient (PCC) for conducting a correlation analysis of the evaluation metrics. The obtained heatmap of evaluation metric correlation across different datasets is depicted in Figure 5. With values ranging from −1 to 1, the larger the absolute value of the number, the higher the correlation between the evaluation metrics. By presenting a heatmap for each typical style, the evaluation results can be clearly visualized and compared across different styles. Below, we present detailed results and their analyses.
(1) The correlation between the ACC classifier and human evaluations on sentiment transfer is limited due to the adversarial challenges arising within classification accuracy. When utilizing non-parallel sentiment datasets such as Yelp and Amazon, which contain human-generated sentences as ground truth references, lower accuracy results were surprisingly revealed when the ground truth was input into the accuracy (ACC) classifier during the testing process for the Amazon dataset and Yelp (Negative→Positive). As shown in Table 4, the ACC accuracy values are 64.8 and 45.6, respectively, which are notably lower than the average ACC classifier value of 81.7. This divergence can be attributed to the training data distribution disparities from the human-generated ground-truth data. Given that sentences following sentiment transfer occasionally differ by just a few words from those composed by humans, this similarity may mislead the classifier [89]. Therefore, in evaluating style intensity within sentiment transfer tasks, we suggest researchers consider the potential for adversarial examples resulting from similar word distributions that mislead classifier evaluations.
Finding 2: The disparity between human preference, which strongly favors LLMs in TSTtasks, and the inadequacy of automatic evaluations suggests that current evaluation metricsmay not be suitable for assessing the performance of LLM models. The performanceof most LLMs does not exceed that of fine-tuned SOTA models.
We utilized t-SNE [90] to visualize the embedding space of two distinct styles on test data and reference data. This was performed using the “CLS” embedding on the final layer of the classification model. The results of the testing and reference data spaces are depicted in Figure 6a and Figure 6b, respectively. These results indicate that the reference data are more intermixed, suggesting the difficulty in classifying the reference data using the classification model, which aligns with the aforementioned classifier accuracy results.
(2) The correlation between the evaluation metrics of content preservation and human evaluations varies depending on the dataset. The averaged PCC values for human evaluations of content preservation with BLEU and BERTScore values are 0.708 and 0.798, respectively, demonstrating a strong association and indicating consistency between the BLEU and BERTScore evaluation metrics and human assessment standards. Furthermore, regarding formality and sentiment styles, the correlation coefficient for the BERTScore is greater than that of BLEU. However, in modern English style transfer and fine-grained syntactic/semantic transfer, the PCC values for BLEU are higher than that of the BERTScore. One possible reason is that the BERT model has limited capability in understanding various syntactic expressions in ancient English. Therefore, it would be more reasonable to adopt different content preservation evaluation metrics for different style transfer tasks.
(3) The correlation between perplexity (PPL) and human ratings is not significant. A lower PPL score does not consistently reflect language that is similar to that used by humans [91]. Furthermore, the PCC for human ratings is 60.1% lower for PPL compared to COLA. Consequently, COLA proves to be more suitable for evaluating text fluency than PPL. Even in cases involving style shifts from modern to classical texts, where grammar rules differ, COLA can still maintain a high PCC value.
(4) The current automatic metrics struggle to provide a comprehensive evaluation. Although automatic evaluation metrics are highly correlated with human evaluation, the exact rankings do not align. Taking formality transfer on the GYAFC-FR dataset as an example, the order of the top five rankings by human is as follows: GPT4-ZS, CHATGPT-FS, CHATGPT-ZS, GPT4-FS, and TYB. However, the automatic evaluation rankings are as follows: TYB, LlaMa-LORA, LlaMa-LORA-INST, BSRR, and STRAP. The inconsistency in rankings indicates that the current evaluation metrics are insufficient. We recommend designing specific prompts, such as using chains of thoughts, to guide ChatGPT in evaluating the performance of different models.
Finding 3: The current automatic evaluation metrics are constrained by adversarialchallenges, dataset-dependent variations in correlation coefficients, and the unreliabilityof perplexity scores compared to human ratings. Furthermore, disparities in the rankingsof automatic evaluation metrics against human assessments highlight the need forspecific prompts or guiding mechanisms to improve the robustness and applicability ofthese metrics.
4.5. Contents in Appendixes A and B
To maintain clarity and focus in the main body of our work, we have chosen to include several important elements in the Appendix. Below is a concise overview of the Appendix contents to guide readers in easily locating specific information:
- Appendix A Algorithms and implemented details in TSTBench:
- -Appendix A.1: Descriptions of algorithms in TSTBench;
- -Appendix A.2: Various evaluation methods in existing TST algorithms;
- -Appendix A.3: Prompts in our experiment.
- Appendix B Additional results and analysis:
- -Appendix B.1: Sentiment transfer;
- -Appendix B.3: Ancient English transfer;
- -Appendix B.4: Fine-grained syntactic and semantic style transfer;
- -Appendix B.5: Analysis of trade-off curves;
- -Appendix B.6: Case study.
5. Discussion
TSTBench is presented as a benchmarking platform for text style transfer that not only includes the implementation of a wide range of transfer models but also encompasses a set of metrics for assessing the quality of the generated texts. We expect that this new benchmark will contribute to the TST community in several key aspects: providing a clear overview of current advancements based on transformer in TST, including those involving large language models (LLMs); improving the reproducibility and reliability of future research; enabling researchers to effortlessly compare new methods with existing ones; and sparking new research inquiries through comprehensive evaluations.
The continuous advancement of sophisticated language models presents promising opportunities for future benchmark development. Notably, integrating evaluation paradigms such as LLM-as-a-judge [92] could harness these models’ growing capabilities to conduct more effective evaluations. Additionally, few-shot prompting techniques hold potential for more efficient quality assessment, reducing reliance on costly human evaluations.
Despite its strengths, TSTBench has certain limitations that encourage further investigation. We implement evaluation approaches as a baseline reference, recognizing that more sophisticated evaluation metrics are urgently needed for development, such as weighting schemes in the overall score. These observations open up promising avenues for future research within this domain.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Jin D. Jin Z. Hu Z. Vechtomova O. Mihalcea R. Deep Learning for Text Style Transfer: A Survey Comput. Linguist.20224815520510.1162/coli_a_00426 · doi ↗
- 2Ostheimer P. Nagda M. Kloft M. Fellenz S. A Call for Standardization and Validation of Text Style Transfer Evaluationar Xiv 20232306.00539
- 3Suzgun M. Melas-Kyriazi L. Jurafsky D. Prompt-and-Rerank: A Method for Zero-Shot and Few-Shot Arbitrary Textual Style Transfer with Small Language Modelsar Xiv 202210.48550/ar Xiv.2205.115032205.11503 · doi ↗
- 4Dai N. Liang J. Qiu X. Huang X. Style transformer: Unpaired text style transfer without disentangled latent representationar Xiv 20191905.05621
- 5Wang K. Hua H. Wan X. Controllable unsupervised text attribute transfer via editing entangled latent representation Adv. Neural Inf. Process. Syst.20193210.48550/ar Xiv.1905.12926 · doi ↗
- 6Xiao F. Pang L. Lan Y. Wang Y. Shen H. Cheng X. Transductive learning for unsupervised text style transferar Xiv 20212109.07812
- 7Lai H. Toral A. Nissim M. Thank you BART! Rewarding pre-trained models improves formality style transferar Xiv 20212105.06947
- 8Liu Z. Chen N.F. Learning from Bootstrapping and Stepwise Reinforcement Reward: A Semi-Supervised Framework for Text Style Transferar Xiv 20222205.09324