Coarse-Grained Hawkes Processes
Shinsuke Koyama

TL;DR
This paper introduces a new model for analyzing event data when only aggregated counts are available, improving accuracy and efficiency.
Contribution
The novel coarse-grained Hawkes process model captures statistical features of aggregated event data effectively.
Findings
The model accurately captures second-order statistics of bin-count data with large bin sizes.
The proposed inference method performs as well or better than existing techniques in simulations.
The approach maintains computational efficiency during parameter estimation.
Abstract
When analyzing real-world event data, it is often the case that bin-count processes are observed instead of precise event time-stamps along a continuous timeline, owing to practical limitations in measurement accuracy. In this work, we propose a modeling framework for aggregated event data generated by multivariate Hawkes processes. The introduced model, termed the coarse-grained Hawkes process, effectively captures the second-order statistical characteristics of the bin-count representation of the Hawkes process, particularly when the bin size is large relative to the typical support of the excitation kernel. Building upon this model, we develop a method for inferring the underlying Hawkes process from bin-count observations, and demonstrate through simulation studies that the proposed approach performs comparably to, or even surpasses, existing techniques, while maintaining…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
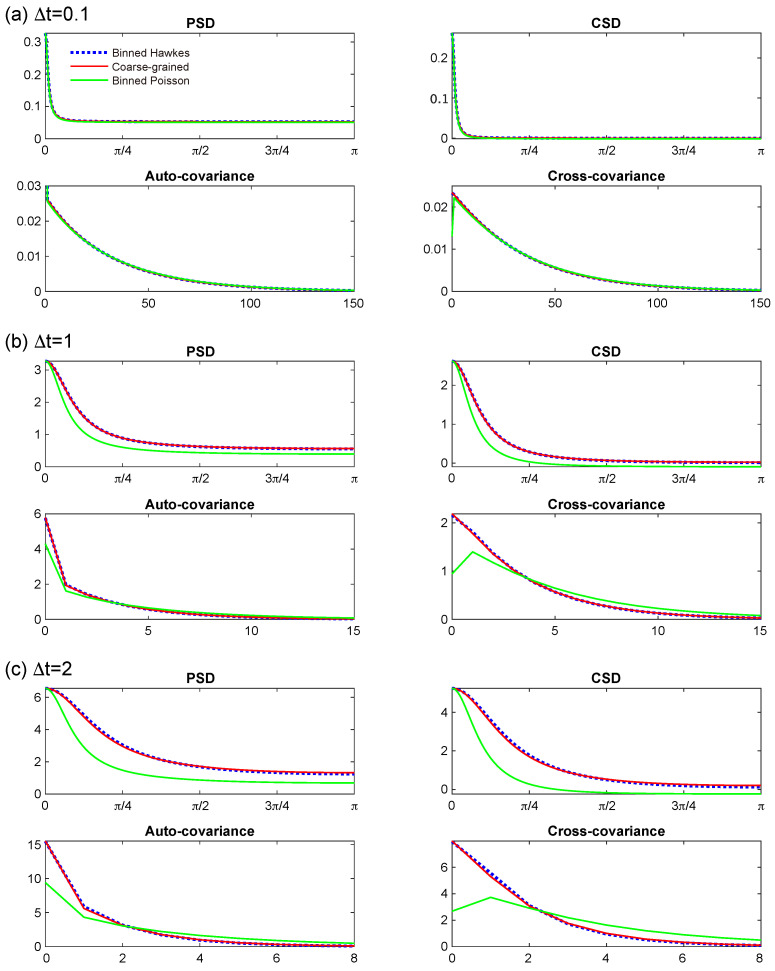 Figure 1
Figure 1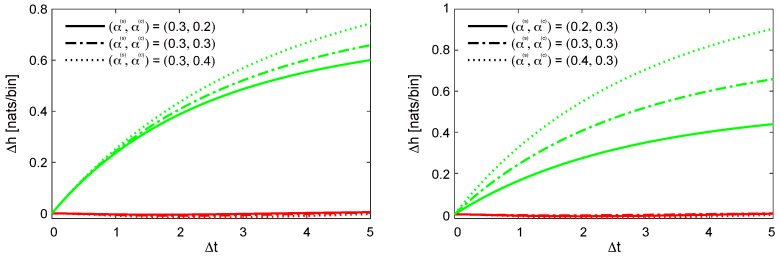 Figure 2
Figure 2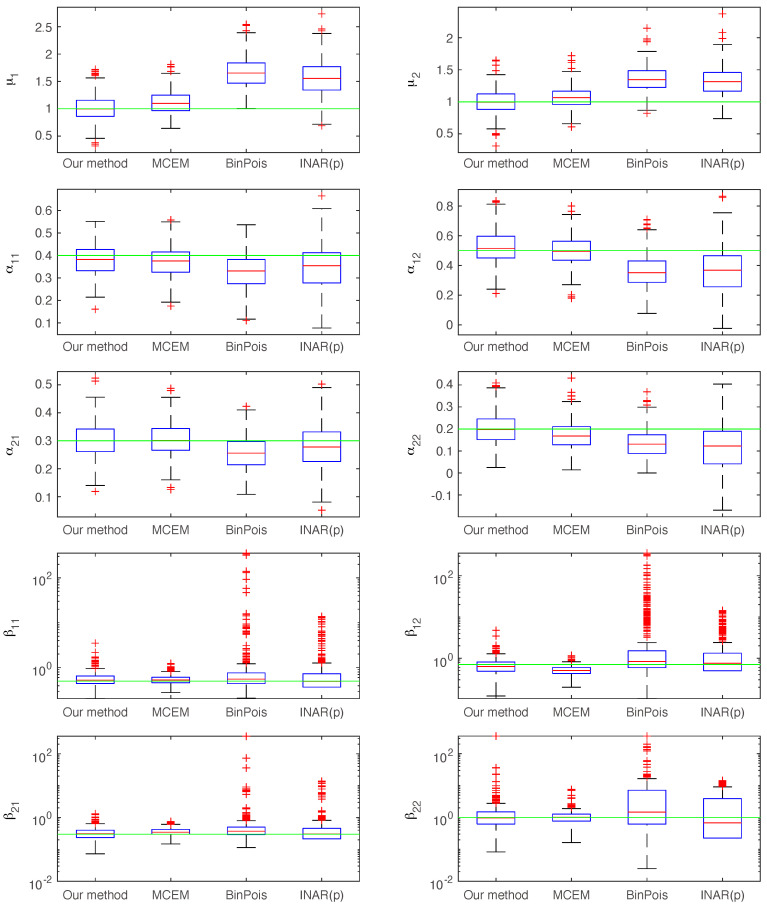 Figure 3
Figure 3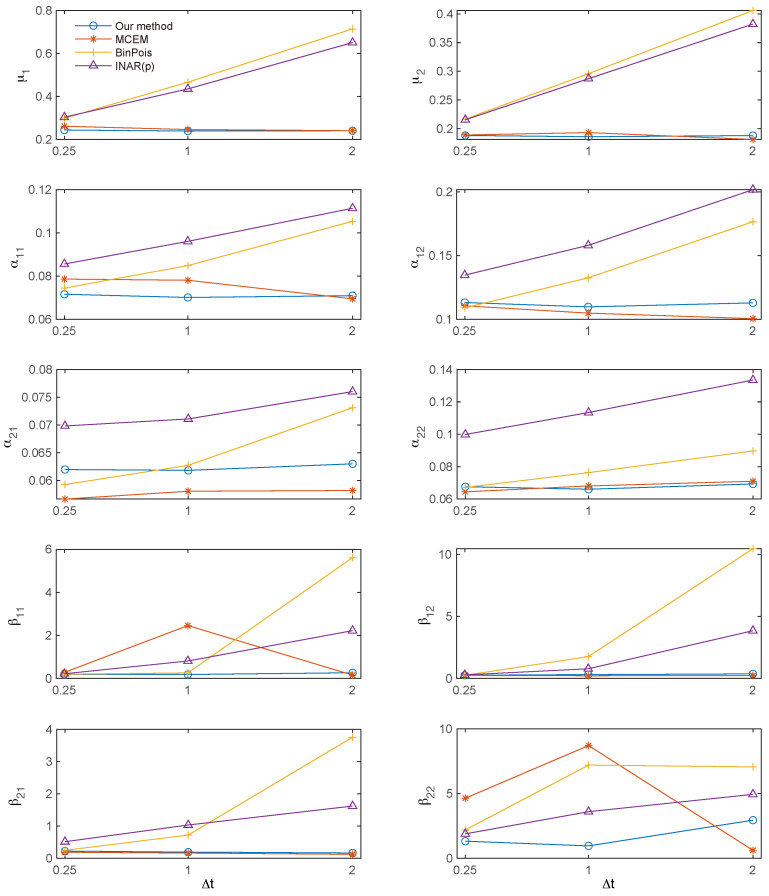 Figure 4
Figure 4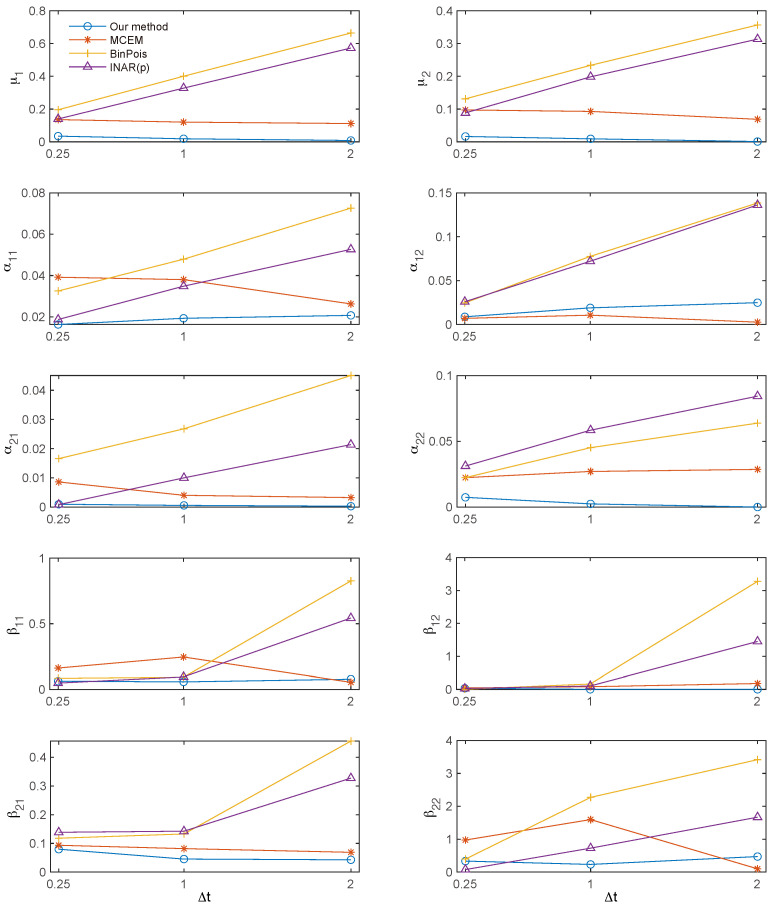 Figure 5
Figure 5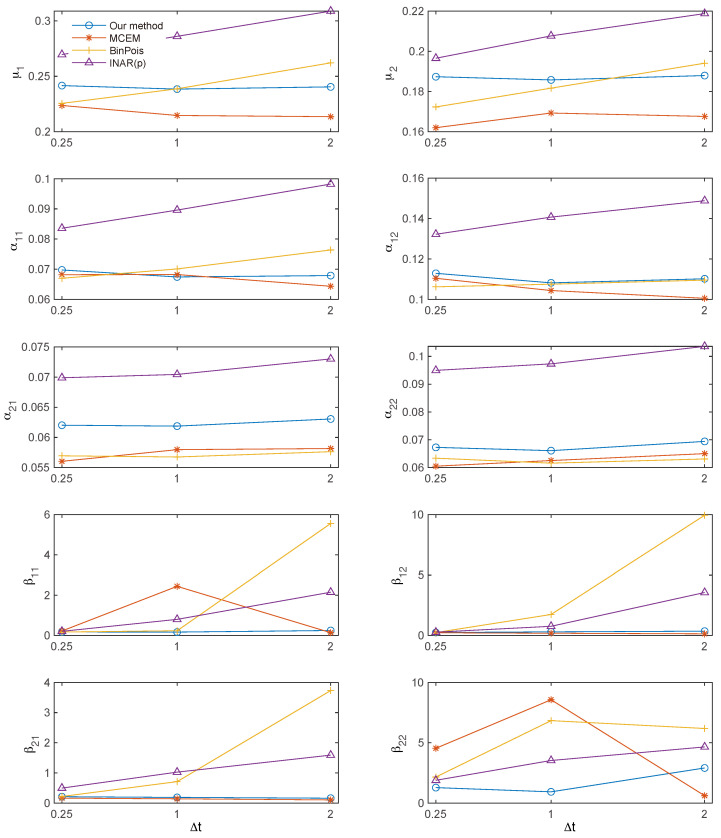 Figure 6
Figure 6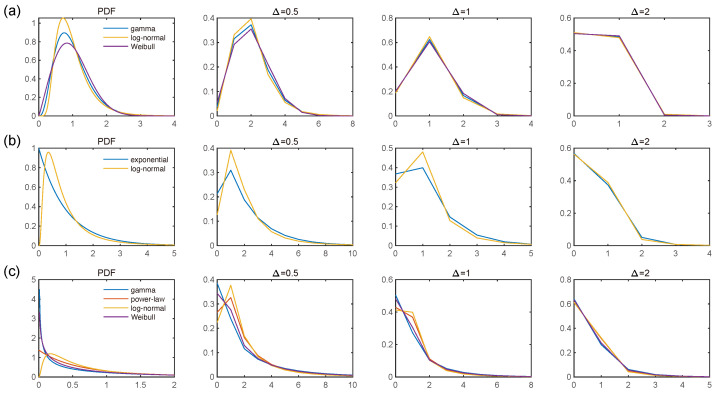 Figure 7
Figure 7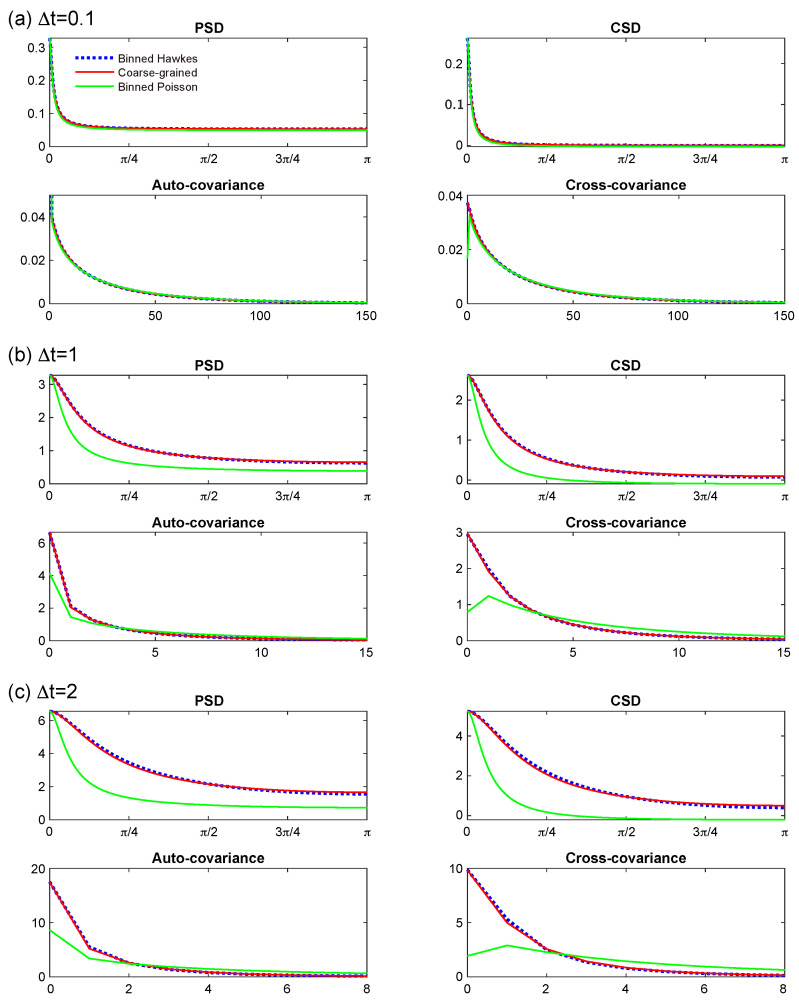 Figure 8
Figure 8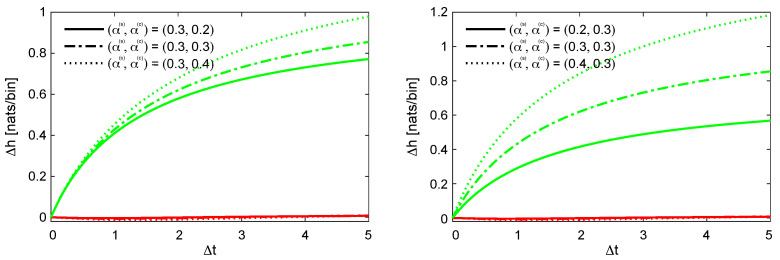 Figure 9
Figure 9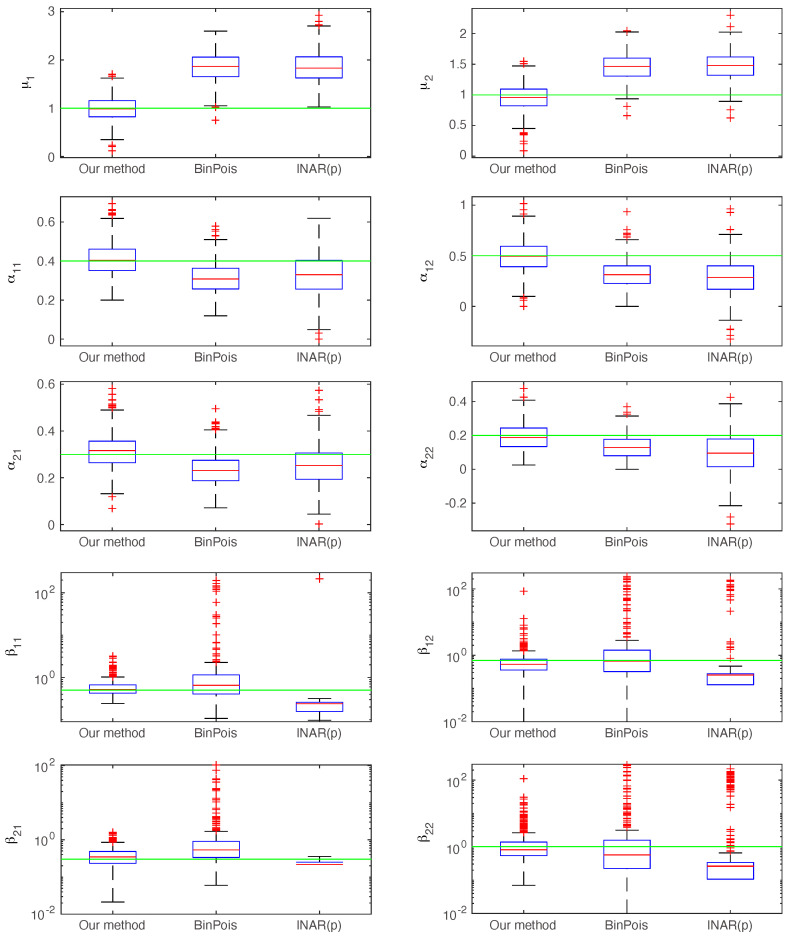 Figure 10
Figure 10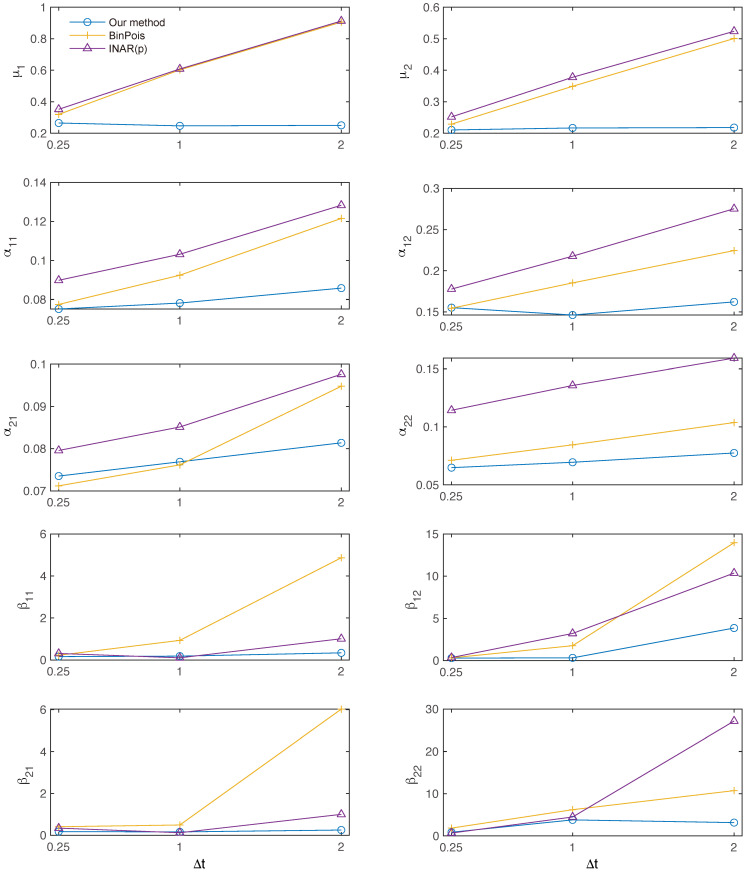 Figure 11
Figure 11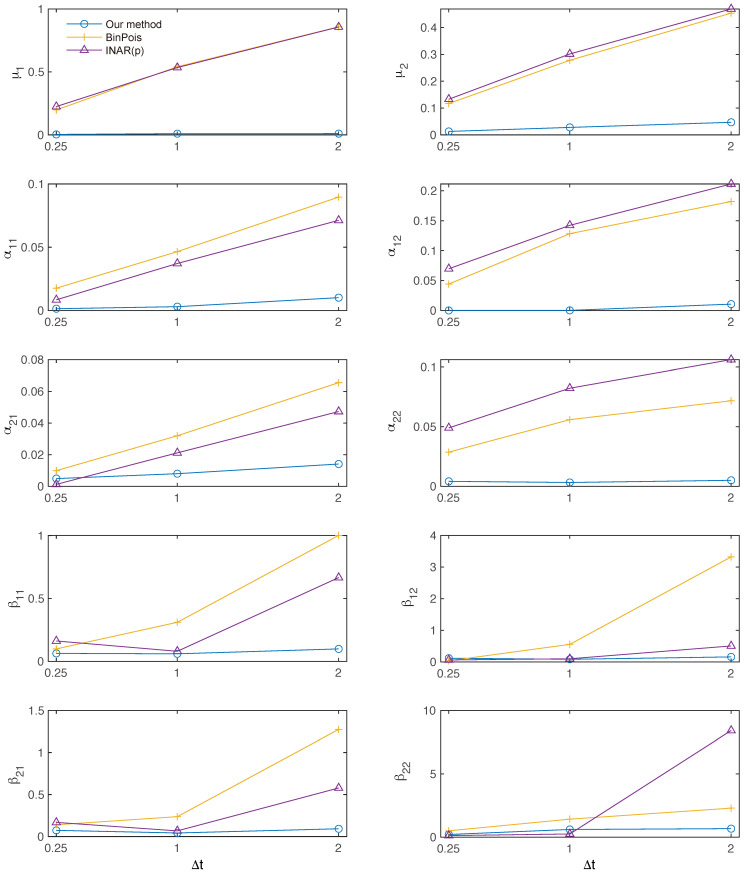 Figure 12
Figure 12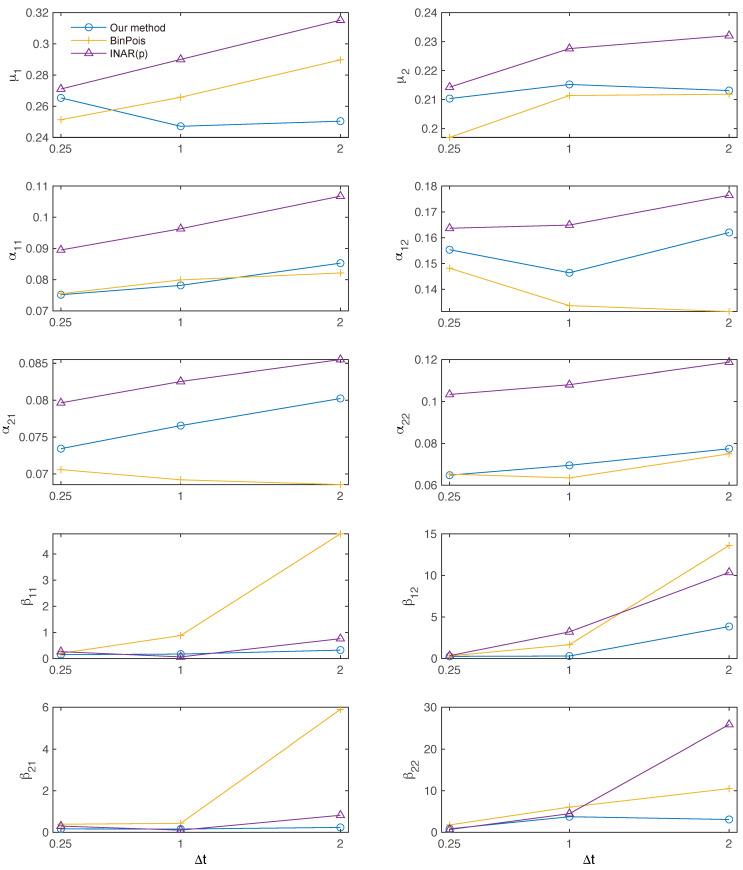 Figure 13
Figure 13- —Japan Society for the Promotion of Science (JSPS)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPoint processes and geometric inequalities · Diffusion and Search Dynamics · Bayesian Methods and Mixture Models
1. Introduction
Generally, past events in natural and social systems facilitate the occurrence of future events through a self-exciting mechanism. The Hawkes process [1,2], a class of self-exciting point processes, has become a popular tool for modeling such processes continuously. Its defining intensity function, or instantaneous event rate, is composed of a baseline rate augmented by the cumulative influence of prior events, thereby capturing the self-exciting mechanism wherein each event elevates the probability of subsequent occurrences. Owing to the prevalence of self-excitation across diverse domains, the Hawkes process has been extensively employed in a wide range of disciplines, including seismology [3,4], neurophysiology [5,6], genomics [7], finance [8,9], social media analytics [10,11,12], criminology [13,14], terrorism studies [15], and traffic incident analysis [16].
The Hawkes process is applicable to scenarios wherein individual events are distinguishable, as it characterizes a series of discrete occurrences along a continuous timeline. Nevertheless, it proves insufficient for modeling count-based sequences in which the precise timing of events is unobserved and only their aggregated counts within successive intervals are available. A representative case arises in epidemiological studies, where individual infection events are not monitored in real time, but rather, the daily incidence rates are recorded. Consequently, there is a need to develop a count-based time series model that retains the salient features of the Hawkes process for such contexts.
Multiple methodologies have been proposed for fitting the Hawkes process to bin-count data. Kirchner demonstrated that the distribution of bin-count sequences generated by Hawkes processes can be effectively approximated using an integer-valued autoregressive (INAR) model, wherein conditional least squares estimation is employed to infer the underlying Hawkes process [17,18]. Shlomovich et al. introduced a Monte Carlo expectation-maximization (MC-EM) framework, which integrates an efficient sampling algorithm for the latent event times with an EM procedure to maximize the likelihood function [19,20]. Similarly, Chen et al. developed a Pseudo-Marginal Metropolis–Hastings (PMMH) algorithm for maximum likelihood estimation, wherein the likelihood is approximated via a sequential Monte Carlo approach [21]. Alternatively, Cheysson and Lang advocated for a spectral estimation technique grounded in the Whittle likelihood within the univariate context [22].
Although Kirchner’s approach provides consistent and asymptotically normal estimators for the underlying Hawkes process as the bin width approaches zero, it introduces bias when the bin size exceeds the typical support of the excitation function, due to the INAR model’s neglect of intra-bin excitation dynamics. In contrast, the MC-EM, PMMH, and spectral estimation methods yield less biased results by accounting for excitation effects occurring within each bin. Nonetheless, the MC-EM and PMMH techniques are computationally intensive, whereas the spectral method is validated only in the univariate setting.
Accordingly, the objective of this study is to develop a computationally efficient methodology that extends naturally to the multivariate setting. Our proposed approach involves constructing a count-based time series model that approximates the bin-count sequence generated by Hawkes processes, upon which an estimation procedure is built. Unlike Kirchner’s method, which relies on a straightforward discretization, namely, evaluating the intensity function at discrete time points, to relate the Hawkes and INAR processes [17], our model is derived through a coarse graining procedure. The resulting framework, termed the coarse-grained Hawkes process, is defined in a conceptually simple and analytically tractable form, while effectively preserving the second-order statistical characteristics of the bin-count Hawkes process, even in regimes where the bin size is large relative to the excitation function’s effective range.
The structure of this paper is as follows. Section 2 provides a concise overview of Hawkes processes. Section 3 introduces the coarse-grained Hawkes process along with the proposed estimation methodology. In Section 4, we assess the approximation accuracy of the coarse-grained Hawkes process in representing the bin-count Hawkes process. Additionally, a simulation study is conducted to benchmark the performance of the proposed estimation technique against existing approaches. Section 5 concludes with a discussion of the findings.
2. Review of Hawkes Processes
In this section, we present a brief review of Hawkes processes. Let denote a sequence of nonnegative random variables representing the occurrence times of events on , satisfying for . Define the associated counting process by , and let denote the history of events up to, but not including, time t. We consider a point process such that
as , where is the conditional intensity function that uniquely characterizes the point process. A univariate Hawkes process is then defined by the conditional intensity function
where is the baseline intensity and is a nonnegative excitation kernel satisfying for [1]. This formulation captures the self-exciting nature of the process, wherein the intensity at any given time depends on the historical sequence of events. The branching ratio is defined as
which quantifies the expected number of subsequent events triggered by a single occurrence. The process admits a stationary distribution provided that .
The univariate Hawkes process naturally generalizes to the multivariate case [1,2]. For , a d-dimensional Hawkes process comprises d jointly defined point processes on . The corresponding vector-valued conditional intensity function is given by
where is the baseline intensity vector, and the excitation kernel is a matrix-valued function with nonnegative entries satisfying for . Each entry describes the influence of process j on the intensity of process i, thus capturing both self-excitation and mutual excitation among the components. The multivariate Hawkes process is asymptotically stationary if the spectral radius of the branching matrix
is strictly less than one.
Finally, we briefly recall the martingale properties of point processes that are instrumental for our methodological developments. For a comprehensive treatment, see [23]. Define the process , where . Then, is a martingale with respect to the filtration , satisfying the property that the conditional expectation of its increment is zero:
Moreover, the conditional covariance matrix of the martingale increment is given by
which follows from the quadratic variation of the martingale.
3. Coarse-Grained Hawkes Process
3.1. Motivation
We consider a scenario wherein the exact timing of individual events is unobserved; instead, we observe an aggregated count of these latent continuous-time events within discrete time intervals. We define
as the bin-wise event counts over intervals of size . When constitutes a Hawkes process, the corresponding discrete-time vector process is referred to as the binned Hawkes process [19,20].
Although a closed-form representation of the probability distribution of binned Hawkes processes is not available, an approximate formulation can be derived by discretizing the conditional intensity function as follows:
and assuming that the bin counts follow Poisson distributions:
This method, known as the binned Poisson approximation, converges in distribution to the true Hawkes process as . However, its accuracy degrades with larger due to discretization errors in (1) and the conditional independence assumption in (2), which neglects the intra-bin excitation effect. Nonetheless, it facilitates a tractable estimation procedure: the log-likelihood of the sequence is given by
Parameter estimation is then performed via maximization of this log-likelihood function [19,20,24].
In light of the limitations of this approximation for larger , we propose an alternative count time series model that more accurately approximates the binned Hawkes process while retaining computational simplicity for inference. The underlying heuristic is elucidated in the following discussion.
The central idea is to replace the crude discretization with the expected value of the conditional intensity integrated over each time bin. The expected count within the nth bin of process i is , which depends on the trajectory . Consequently, we consider the conditional expectation, given the bin counts :
As these conditional expectations do not admit closed-form expressions, we approximate them under the assumption that event times are uniformly distributed within each bin. Accordingly, the second term on the right-hand side of (3) is approximated as
where denotes the coarse-grained kernel, defined as
Similarly, the third term on the right-hand side of (3) is approximated by
where we have utilized the causal property for . Substituting these approximations back into (3) yields
In contrast to the formulation in (1), Equation (5) incorporates the coarse-grained kernel, capturing both inter-bin excitation and intra-bin self-excitation effects through the terms ( ). Building upon this approximation, we will formally define the coarse-grained Hawkes process in the subsequent section.
3.2. Definition
Firstly, we formally define the coarse-grained kernel, previously derived heuristically in (4).
Definition 1. Let be a nonnegative excitation kernel defined on the real line, satisfying for . The coarse-grained kernel with bin size is defined by
where
It can be readily verified that the formulation (6) and (7) coincides with the expression in (4).
Lemma 1. The coarse-grained kernel satisfies
Moreover, it holds that .
Proof. See Appendix A.1. □
Lemma 1 guarantees that the total mass of the coarse-grained kernel equals the integral of the excitation kernel, i.e., the branching ratio. Furthermore, it ensures that the kernel does not collapse to the degenerate case as long as .
Based on the coarse-grained kernel, we introduce the coarse-grained Hawkes process. Consider a probability space equipped with a sequence of d-dimensional, integer-valued random vectors . Define the history up to bin k as . We consider the d-dimensional coarse-grained process given in (5):
where is the baseline intensity vector, and each is a matrix whose elements are given by the coarse-grained kernels for bin size . Define the residual process as
and impose the following conditional moment properties, analogous to the martingale conditions in point process theory:
Importantly, these conditional moment properties do not fully specify the probability law of the process, but constrains its behavior through second-order statistical structure. Consequently, multiple processes may exist that fulfill these conditions. The coarse-grained Hawkes process is thus defined as the equivalence class of sequences satisfying (8)–(11).
The term on the right-hand side of (8) encapsulates the effect of intra-bin excitation, which induces both cross-correlations and overdispersion in the count statistics. Assuming that the spectral radius of is strictly less than one, the conditional expectation and covariance matrix of given are, respectively
where I denotes the identity matrix. Derivations of these expressions are provided in Appendix A.2. Due to the presence of the matrix factor , the conditional covariance matrix is generally nondiagonal, capturing cross-correlations, and its diagonal elements exceed those of , reflecting overdispersion. When is the zero matrix, implying the absence of intra-bin excitation, the conditional variance reduces to , corresponding to the conditional independence of Poisson-distributed counts.
3.3. Stationary Process
We investigate the coarse-grained Hawkes process under the assumption of stationarity and derive its second-order statistical properties. Assuming stationarity, Equations (8) and (10) yield
where
denotes the branching ratio matrix. Consequently, the spectral radius of A must be strictly less than one.
To derive the second-order moment of the stationary coarse-grained Hawkes process, we first establish a white noise property of the residual process.
Lemma 2. Let denote a coarse-grained Hawkes process whose branching ratio matrix has a spectral radius less than one. Then, the residual process (9) forms a stationary sequence satisfying , , and
where denotes the Kronecker delta.
Proof. See Appendix A.3. □
As a consequence of the white noise structure of the residual process, the stationary coarse-grained Hawkes process admits a moving average representation of infinite order,
where the effective kernel matrices are defined by
with denoting the j-fold convolution of , and . It is worth noting that the branching ratio matrix can be expressed in terms of the effective kernel matrices as follows:
thereby establishing a relationship between the branching ratio and the cumulative influence of preceding events. The detailed derivation is presented in Appendix A.4. Using the representation (16), the autocovariance structure is obtained analogously to linear time series models.
Theorem 1. Let be a coarse-grained Hawkes process with a branching ratio matrix whose spectral radius is less than one. Then, the autocovariance of is given by
Proof. See Appendix A.5. □
The spectral density matrix of the stationary coarse-grained Hawkes process is obtained by taking the Fourier transform of the autocovariance sequence:
where is the Fourier transform of the effective kernel matrix. Alternatively, it can be expressed via the Fourier transform of the coarse-grained kernel matrix, , as
utilizing the identity .
In summary, under the condition that the spectral radius of the branching ratio matrix is less than one, the expected value of the process remains constant over time, and its autocovariance depends solely on the lag between observations, not their absolute positions in time. Accordingly, the coarse-grained Hawkes process is weakly stationary.
3.4. Approximation to Hawkes Process
We now establish a rigorous connection between the original Hawkes process and its coarse-grained counterpart. Specifically, we examine the second-order statistical properties of both processes under the assumption of stationarity. A summary of the statistical properties of the stationary Hawkes process is provided in Appendix B.
Since the sum of the coarse-grained kernel coincides with the integral of the excitation kernel (see Lemma 1), the branching ratio matrices, and consequently, the conditions for stationarity, are identical for both processes. Under stationarity, the expected event counts of the coarse-grained Hawkes process (14) coincide with those of the original Hawkes process (A7).
We proceed to compare the spectral density matrices of the two processes, focusing in particular on the convergence behavior of the spectral density of the coarse-grained process toward that of the original Hawkes process.
Theorem 2. The spectral density matrix of the coarse-grained Hawkes process satisfies
as , where denotes the spectral density matrix (A6) of the original Hawkes process.
Proof. See Appendix A.6. □
Considering the binned Hawkes process, its spectral density matrix behaves as (see Appendix B)
as , which matches the expansion in (18) up to second-order terms in . This leads to the following corollary.
Corollary 1. The spectral density matrix of the coarse-grained Hawkes process approximates that of the binned Hawkes process to third-order accuracy as
as .
For comparative purposes, consider the binned Poisson approximation defined by Equations (1) and (2). Its spectral density matrix behaves as (see Appendix A.6)
Therefore, the coarse-grained Hawkes process yields a spectral approximation to the binned Hawkes process that is accurate to a higher order than the binned Poisson approximation.
3.5. Parameter Estimation Method
We address the problem of estimating the parameters of a Hawkes process from binned count data. Assume that we observe a sequence of binned event counts of length n generated by a d-dimensional Hawkes process, whose excitation kernel matrices are specified by a parametric form with an unknown parameter vector . Since the likelihood function of the coarse-grained Hawkes process is unavailable due to the absence of a fully specified probability law, we propose a parameter estimation method for grounded in the second-order statistical properties of the coarse-grained Hawkes process.
To this end, we utilize the AR(∞) representation of the coarse-grained Hawkes process (see Appendix A.4),
where , and is a zero-mean, cross-correlated white noise sequence satisfying
Based on this representation, we define a loss function in quadratic form, whose minimizer yields an estimator of the parameter vector:
where . In practice, the unknown mean vector is replaced by the empirical mean . The loss function then simplifies to
where the constant term has been omitted. The first term on the right-hand side of (20) corresponds to a weighted quadratic loss, while the second term serves as a regularization component that discourages trivial solutions of the form . The optimal parameter estimate is obtained by minimizing the loss function with respect to , which can be efficiently carried out using a gradient-based optimization algorithm.
The estimation procedure is summarized as shown in Algorithm 1. Algorithm 1 Estimation procedure for Hawkes processes
- 1:Given the observed bin-count sequence , compute the empirical mean and center the data as for .
- 2:Determine the parameter estimate by minimizing the loss function (20).
- 3:Using the estimated parameter vector , compute the estimate of the baseline intensity as
where denotes the estimated branching ratio matrix.
4. Numerical Experiments
4.1. Assessment of Second-Order Characteristics
As established in Corollary 1, the coarse-grained Hawkes process asymptotically approximates the spectral density matrix of the binned Hawkes process as the bin size . In this section, we conduct numerical investigations to evaluate the validity and robustness of this approximation for increasing values of . To this end, we consider a bivariate Hawkes process ( ), where each component of the excitation kernel matrix is defined as
with denoting a normalized kernel satisfying . The coefficient specifies the branching ratio from component j to component i, and characterizes the distribution of waiting times for event excitation. We specifically focus on a symmetric bivariate Hawkes process where the parameters satisfy , ( ), and the excitation kernel matrix takes the form
The stationarity condition for the process holds if . Under this constraint, the second-order statistical structure of the symmetric Hawkes process is described by the power spectral density (PSD) of each component (the diagonal elements of the spectral density matrix) and the cross-spectral density (CSD) between them (the off-diagonal elements).
We illustrate our findings using an exponential kernel defined as
where denotes the expected waiting time before excitation. Figure 1 presents the PSD and CSD, along with the auto- and cross-covariance functions, of the binned Hawkes process with parameters , , and , for bin sizes (a), 1 (b), and 2 (c). These are depicted using blue dotted lines.
The associated coarse-grained Hawkes process is constructed using the coarse-grained kernel derived from the exponential function:
In the same figures, the four second-order statistics of the coarse-grained process are represented by red lines, while those corresponding to the binned Poisson approximation are shown in green.
From these comparisons, we observe that for small bin sizes ( ), both the coarse-grained Hawkes process and the binned Poisson approximation closely reproduce the second-order behavior of the binned Hawkes process (Figure 1a). However, for , which is comparable to the mean waiting time, the Poisson approximation significantly deteriorates (Figure 1b), whereas the coarse-grained Hawkes process continues to provide a high-fidelity approximation. Even for a larger bin size , exceeding the characteristic time scale , the coarse-grained model remains accurate (Figure 1c).
To quantitatively assess the fidelity of the approximations, we introduce a divergence measure based on the log-determinant of the spectral density matrices. Specifically, let denote the spectral density matrix of the approximating process, where ‘ ’ indicates either the coarse-grained (cg) or Poisson (po) approximation. Then, the information loss relative to the binned Hawkes process is defined as
which corresponds to the gap in maximum entropy rates under spectral constraints.
Figure 2 plots the information loss for both approximations as a function of , across varying values of and . The results clearly indicate that the coarse-grained Hawkes process incurs minimal information loss across a wide range of parameter settings. In contrast, the accuracy of the binned Poisson approximation degrades with increasing , with the loss exacerbated further as and increase.
We additionally examined the case where the excitation kernel follows a power-law distribution instead of an exponential decay. The qualitative behavior remained consistent (see Appendix C; Figure A1 and Figure A2). These findings collectively demonstrate that the coarse-grained Hawkes process offers a substantially improved approximation of the second-order dynamics of the binned Hawkes process, particularly for larger bin widths.
4.2. Parameter Estimation
We now investigate the efficacy of the proposed estimation method in inferring the parameters of a Hawkes process from bin-count data. Specifically, we consider an asymmetric bivariate Hawkes process with exponential excitation kernels given by ( ). The parameters of the Hawkes process are set as follows:
The numerical experiments were conducted as follows. First, realizations of the Hawkes process were generated over the interval and subsequently discretized into bin-count sequences using bin size . The ten model parameters were then estimated from these sequences. Parameter estimation was performed by minimizing the loss function (20) using the quasi-Newton method (BFGS), with finite difference approximation employed for gradient evaluation.
To assess the performance of our proposed method, we compare it against three established approaches. The first is the MC-EM algorithm proposed in [20], for which we employed the publicly available implementation [25]. To ensure a fair comparison, we adopted the tuning parameters specified in [20], setting the number of Monte Carlo samples to 10. The second method is maximum likelihood estimation (MLE) applied to the binned Poisson approximation, with the MLE computed using the quasi-Newton method (BFGS). The third method involves conditional least squares estimation for the INAR(p) process, as introduced in [18]. Since the INAR(p) framework yields nonparametric estimates of the excitation kernels, we obtained the corresponding parametric kernel parameters by fitting an exponential function to the nonparametric estimates [19,20].
Figure 3 presents boxplots of the estimated values for each of the ten parameters across 500 simulated realizations of the binned Hawkes process, using and . It is apparent that both the binned Poisson MLE method and the INAR(p) method produce significantly biased estimates, which is expected given that these approaches disregard excitation effects within each bin. Furthermore, we observe a substantial number of outliers in the estimates of across all four methods, indicating that estimation of the kernel scales exhibits higher variance than estimation of the baseline intensities or branching ratios. For instance, our method yielded estimates of that deviated by a factor of 100 from the true value in 16 out of the 500 trials, highlighting the challenges in accurately estimating when the bin size is large relative to the kernel time scale.
Figure 4 displays the root mean squared error (RMSE) of the parameter estimates across various bin sizes. For the RMSE of , extreme outliers with values exceeding 100 were excluded to mitigate their undue influence. Overall, the proposed method demonstrates superior performance compared to both the binned Poisson MLE and the INAR(p) approach, and achieves accuracy comparable to the MC-EM algorithm. Additionally, both the MC-EM and the proposed methods consistently maintain low RMSE values across different bin sizes, whereas the RMSEs for the binned Poisson MLE and the INAR(p) approach increase with larger bin sizes. A similar trend is observed for , albeit with more fluctuation due to outliers.
Figure 5 and Figure 6 illustrate, respectively, the bias and standard deviation components of the RMSE for each of the ten parameters. The proposed method yields the lowest bias among all methods, with only a few exceptions (Figure 5); meanwhile, the MC-EM algorithm attains the lowest standard deviation (Figure 6).
We further investigated the case in which the excitation kernel follows a power-law distribution rather than an exponential decay, thereby testing a different (non-memoryless) kernel. Our results confirm that the proposed method remains effective in this setting (Appendix C; Figure A3, Figure A4, Figure A5 and Figure A6).
In conclusion, the proposed method matches the performance of the MC-EM algorithm while outperforming both the binned Poisson MLE and the INAR(p) method, particularly in terms of bias reduction. It provides robust and stable estimates for the baseline intensities and the branching ratios , with estimation accuracy largely unaffected by bin size. Accurate estimation of the kernel scales is feasible when the bin size is smaller than the characteristic kernel scale, but becomes unreliable as the bin size increases.
4.3. Choice of Parametric Form of Excitation Kernel
To investigate whether the statistical properties of the coarse-grained Hawkes process are influenced by the specific choice of parametric kernel function, we considered four probability density functions (PDFs): gamma, power-law, log-normal, and Weibull. Figure 7 illustrates the PDFs of these four distributions, all of which share a common mean and standard deviation, with their coarse-grained counterparts. It is evident that as the bin size increases, the coarse-grained kernels converge and become indistinguishable from one another, as the detailed shape of the distributions is averaged out. This observation suggests that our method is robust to the parametric form of the excitation kernel when the bin size is large relative to the kernel timescale.
5. Discussion
In this study, we introduced the coarse-grained Hawkes process as an analytical approximation to the binned Hawkes process. Unlike conventional discretization techniques, the proposed framework incorporates a coarse-grained excitation kernel that systematically accounts for intra-bin excitations. Consequently, the coarse-grained Hawkes process faithfully reproduces the second-order statistical properties of the binned Hawkes process, even when the bin size exceeds the characteristic timescale of the excitation kernel. Moreover, we demonstrated that the proposed approach enables stable estimation of Hawkes process parameters from bin-count data. In particular, both the branching ratios and baseline intensities can be reliably inferred, irrespective of the temporal resolution of the bin-count sequences.
A central distinction between our approach and the Monte Carlo Expectation-Maximization (MC-EM) algorithm lies in the treatment of latent event times within the bin-count data. Whereas the MC-EM method necessitates Monte Carlo sampling from the conditional distribution of unobserved events, resulting in considerable computational burden, our method employs a parsimonious assumption that events are uniformly distributed within each bin. This assumption facilitates the analytical derivation of approximate conditional expectations. Despite its simplicity, the proposed method achieves estimation accuracy on par with that of the MC-EM algorithm while offering substantial computational advantages.
An additional strength of our approach is its robustness to the parametric form of the excitation kernel as the bin size increases. As the detailed shape of the kernel becomes averaged out, the parametric specification becomes largely irrelevant. Consequently, for large bin sizes relative to the kernel timescale, our method remains effective irrespective of the precise functional form of the excitation kernel.
We further highlight a theoretical connection between our estimation framework and the spectral method, previously validated in the univariate setting [22]. Applying the Fourier transform, the loss function in Equation (19) asymptotically approximates a spectral likelihood for large n:
where ,
and denotes the Hermitian transpose. Notably, the spectral likelihood for the multivariate binned Hawkes process can be obtained by replacing with the spectral density matrix of the binned Hawkes process.
Although our analysis focused on temporal Hawkes processes, the proposed modeling framework readily extends to space-time Hawkes processes. By discretizing both the temporal and spatial domains and counting the number of events in each bin, one obtains multivariate bin-count sequences to which the coarse-grained Hawkes process can be applied. In this extension, the coarse-graining procedure must be conducted in both time and space.
Finally, we emphasize the potential extension of the proposed framework to nonstationary time series. Owing to its formulation in the time domain, the coarse-grained Hawkes process is amenable to integration within state-space modeling paradigms [26,27], offering a promising direction for modeling nonstationary dynamics. We propose this as a compelling avenue for future research.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Hawkes A.G. Spectra of some self-exciting and mutually exciting point processes Biometrika 197158839010.1093/biomet/58.1.83 · doi ↗
- 2Hawkes A.G. Point spectra of some mutually exciting point processes J. R. Stat. Soc. Ser. B (Methodol.)19713343844310.1111/j.2517-6161.1971.tb 01530.x · doi ↗
- 3Adamopoulos L. Cluster models for earthquakes: Regional comparisons J. Int. Assoc. Math. Geol.1976846347510.1007/BF 01028982 · doi ↗
- 4Ogata Y. Statistical models for earthquake occurrences and residual analysis for point processes J. Am. Stat. Assoc.19888392710.1080/01621459.1988.10478560 · doi ↗
- 5Chornoboy E.S. Schramm L.P. Karr A.F. Maximum likelihood identification of neural point process systems Biol. Cybern.19885926527510.1007/BF 003329153196770 · doi ↗ · pubmed ↗
- 6Pernice V. Staude B. Cardanobile S. Rotter S. How structure determines correlations in neuronal networks P Lo S Comput. Biol.20117 e 100205910.1371/journal.pcbi.100205921625580 PMC 3098224 · doi ↗ · pubmed ↗
- 7Reynaud-Bouret P. Schbath S. Adaptive estimation for Hawkes processes; application to genome analysis Ann. Stat.2010382781282210.1214/10-AOS 806 · doi ↗
- 8Bacry E. Mastromatteo I. Muzy J.F. Hawkes processes in finance Mark. Microstruct. Liq.20151155000510.1142/S 2382626615500057 · doi ↗