SODU2-NET: a novel deep learning-based approach for salient object detection utilizing U-NET
Hyder Abbas, Shen Bing Ren, Muhammad Asim, Syeda Iqra Hassan, Ahmed A. Abd El-Latif

TL;DR
This paper introduces SODU2-NET, a new deep learning model that improves the detection of salient objects in complex backgrounds using an enhanced U-NET architecture.
Contribution
The novel SODU2-NET model introduces a densely supervised encoder-decoder with attention and residual blocks for improved salient object detection.
Findings
SODU2-NET outperforms existing models like FCN, Squeeze-net, Deep Lab, and Mask R-CNN in precision, recall, and accuracy.
The model achieves superior performance on five public datasets and a new real-world dataset called the Changsha dataset.
The architecture includes an enriched encoder with attention modules and residual blocks to enhance saliency prediction and map refinement.
Abstract
Detecting and segmenting salient objects from natural scenes, often referred to as salient object detection, has attracted great interest in computer vision. To address this challenge posed by complex backgrounds in salient object detection is crucial for advancing the field. This article proposes a novel deep learning-based architecture called SODU2-NET (Salient object detection U2-Net) for salient object detection that utilizes the U-NET base structure. This model addresses a gap in previous work that focused primarily on complex backgrounds by employing a densely supervised encoder-decoder network. The proposed SODU2-NET employs sophisticated background subtraction techniques and utilizes advanced deep learning architectures that can discern relevant foreground information when dealing with complex backgrounds. Firstly, an enriched encoder block with full feature fusion (FFF) with…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
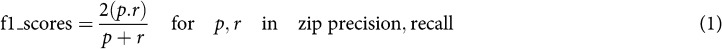 Figure 1
Figure 1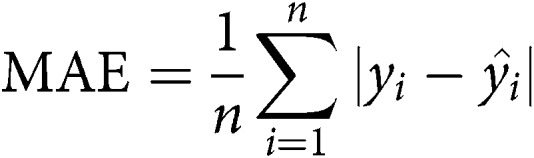 Figure 2
Figure 2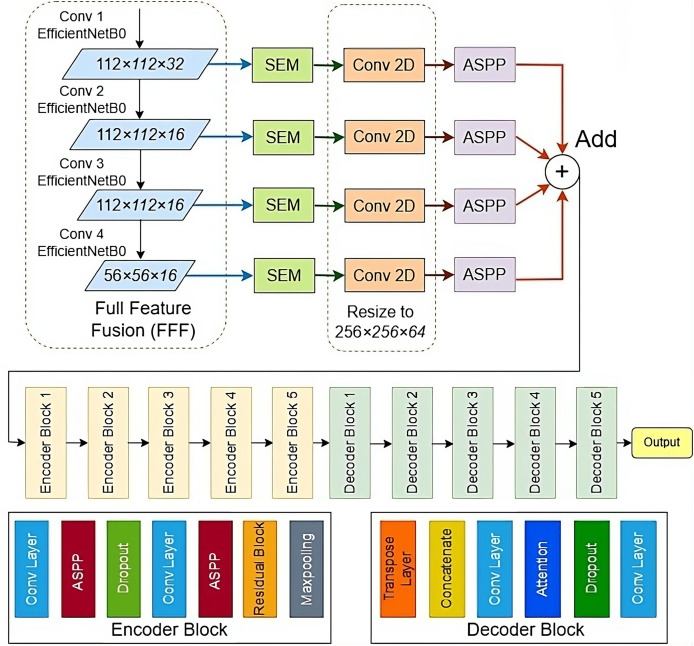 Figure 3
Figure 3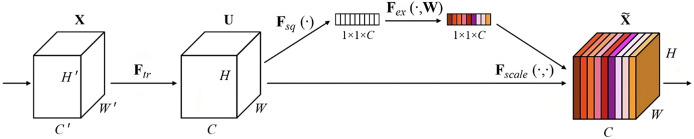 Figure 4
Figure 4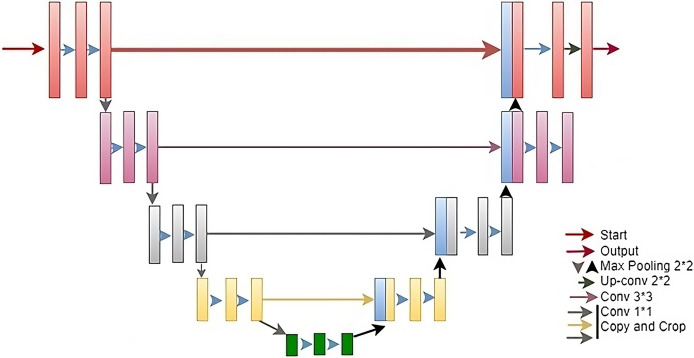 Figure 5
Figure 5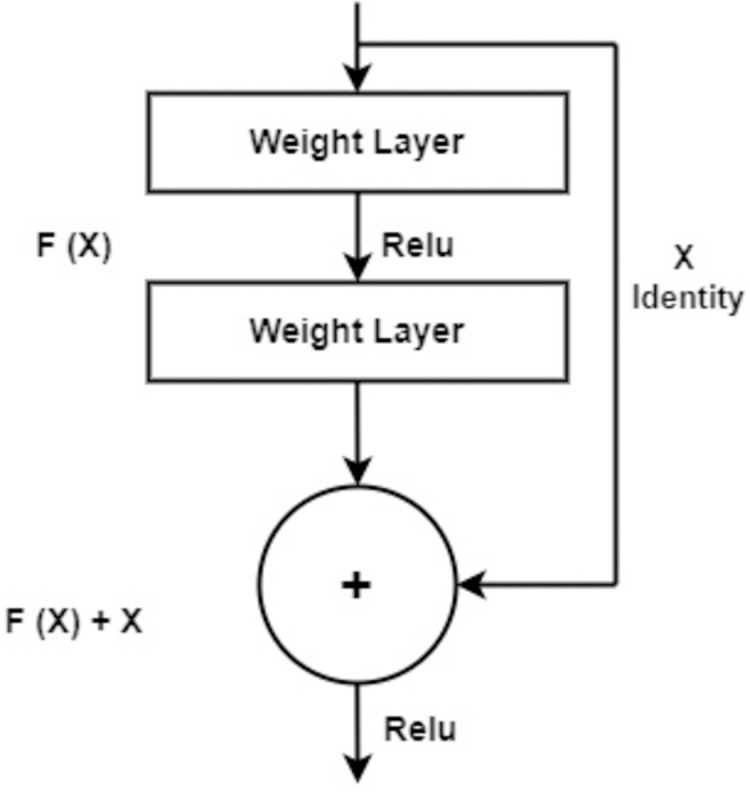 Figure 6
Figure 6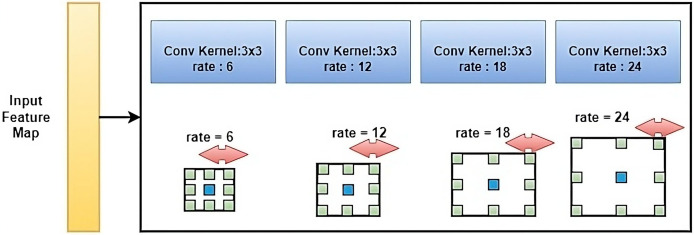 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14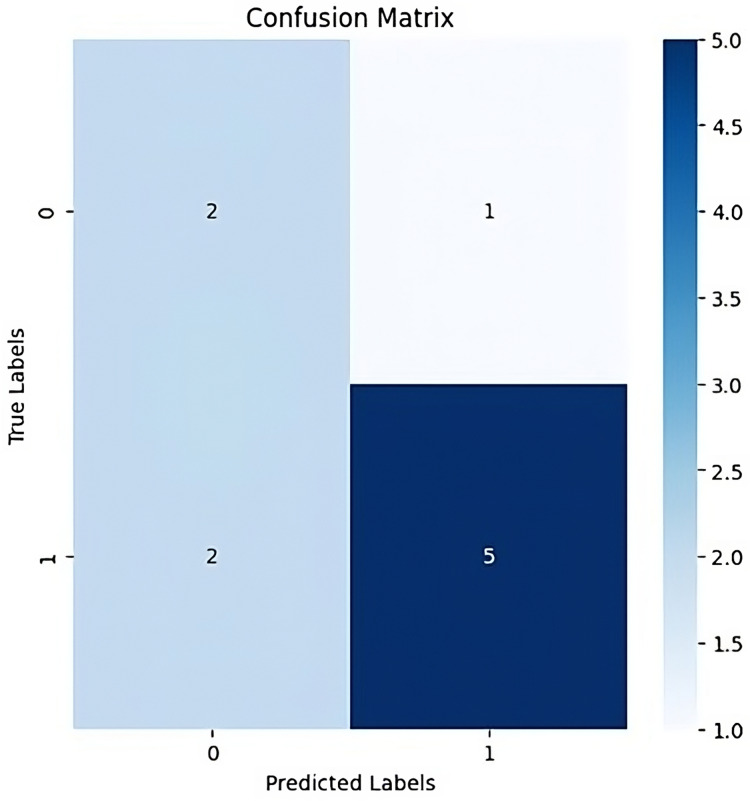 Figure 15
Figure 15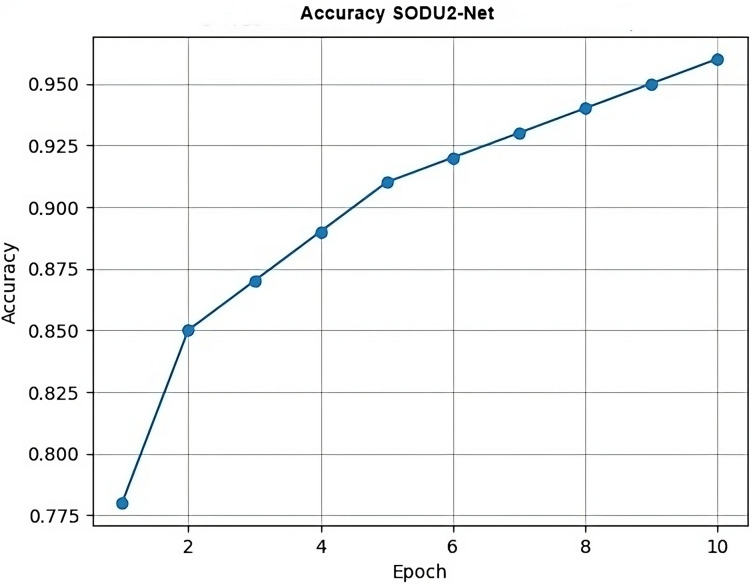 Figure 16
Figure 16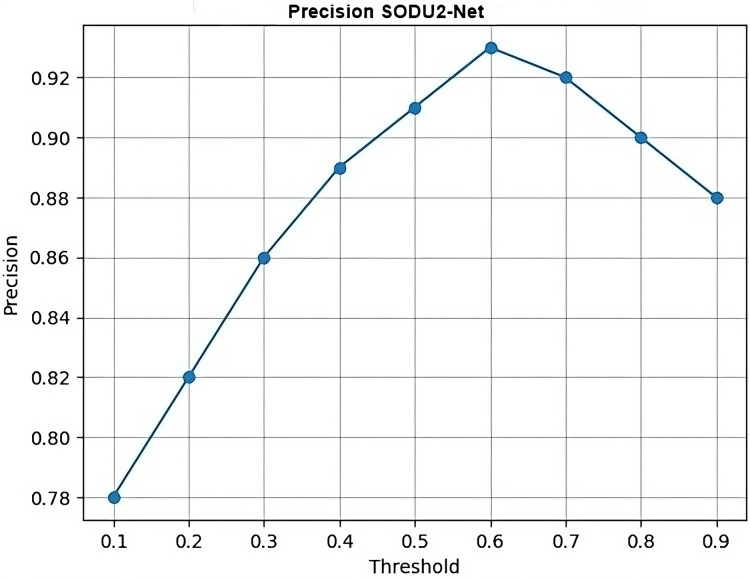 Figure 17
Figure 17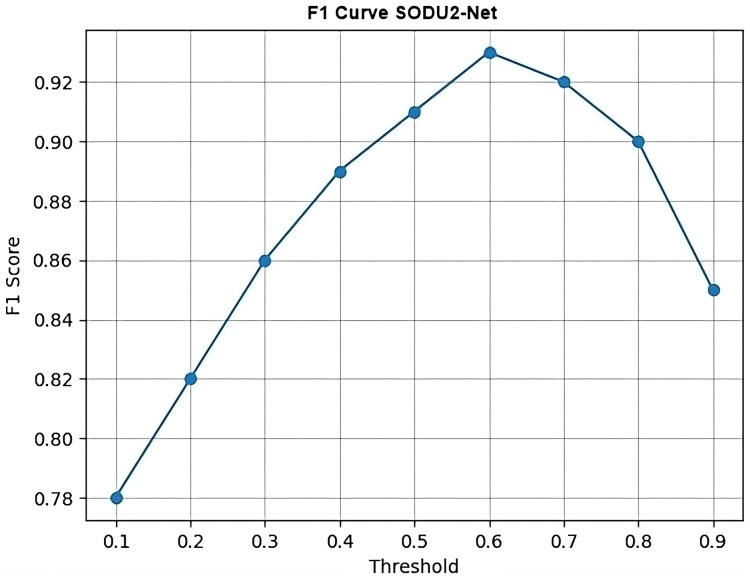 Figure 18
Figure 18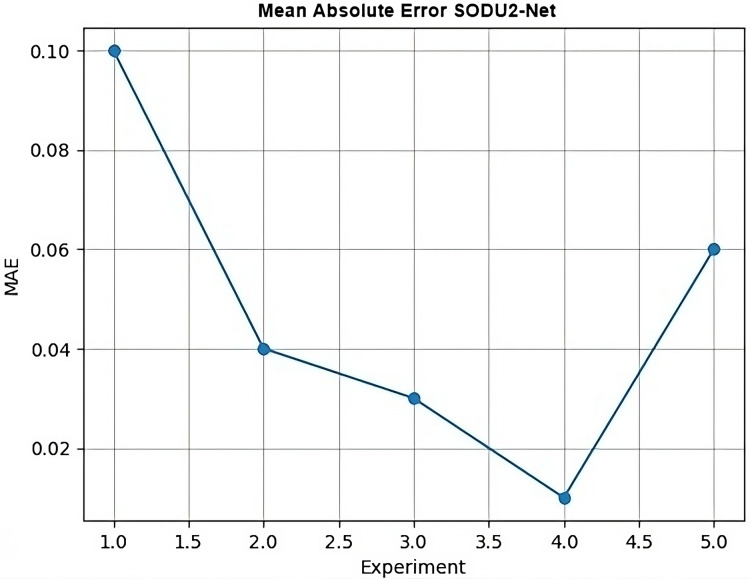 Figure 19
Figure 19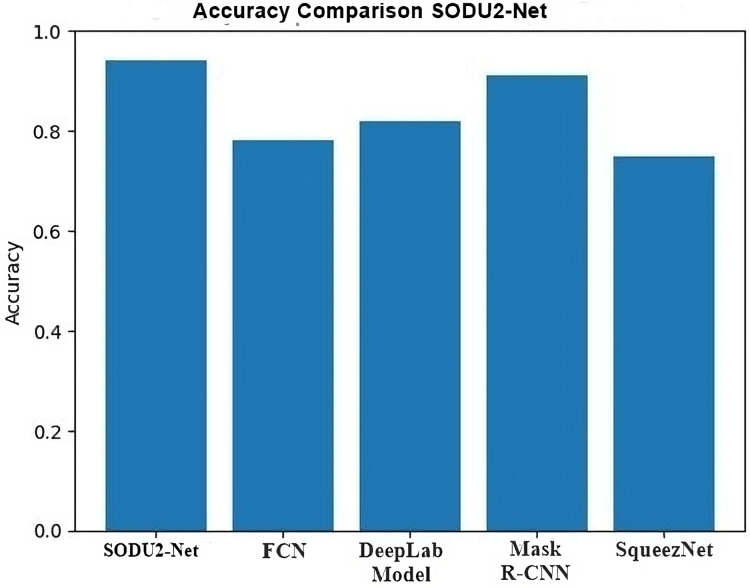 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22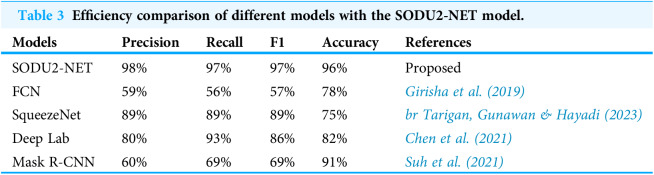 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVisual Attention and Saliency Detection · Advanced Neural Network Applications · Virtual Reality Applications and Impacts