TMAC: a Transformer-based partially observable multi-agent communication method
Xuesi Li, Shuai Xue, Ziming He, Haobin Shi

TL;DR
This paper introduces TMAC, a new communication method for multi-agent systems that improves collaboration in complex environments.
Contribution
The novel contribution is a Transformer-based algorithm with a self-message fusing module for better multi-agent communication.
Findings
TMAC improves performance by 6% in the surviving environment.
The method achieves a 10% improvement in the StarCraft Multi-Agent Challenge.
The proposed algorithm enhances feature extraction and message generation for agents.
Abstract
Effective communication plays a crucial role in coordinating the actions of multiple agents. Within the realm of multi-agent reinforcement learning, agents have the ability to share information with one another through communication channels, leading to enhanced learning outcomes and successful goal attainment. Agents are limited by their observations and communication ranges due to increasingly complex location arrangements, making multi-agent collaboration based on communication increasingly difficult. In this article, for multi-agent communication in some partially observable scenarios, we propose a Transformer-based Partially Observable Multi-Agent Communication algorithm (TMAC), which improves agents extracting features and generating output messages. Meanwhile, a self-message fusing module is proposed to obtain features from multiple sources. Therefore, agents can achieve better…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
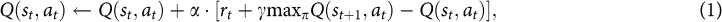 Figure 1
Figure 1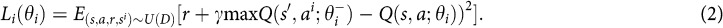 Figure 2
Figure 2 Figure 3
Figure 3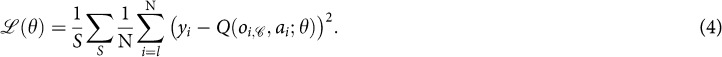 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7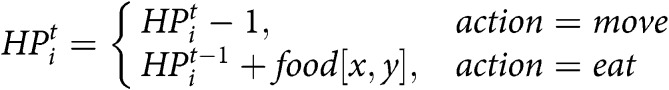 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11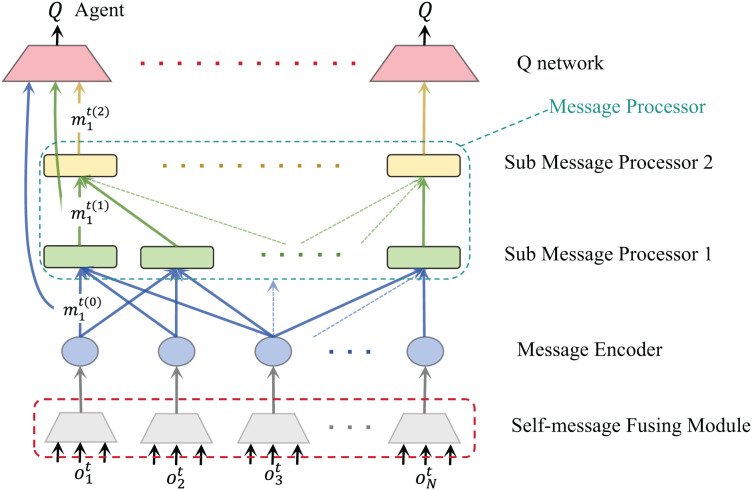 Figure 12
Figure 12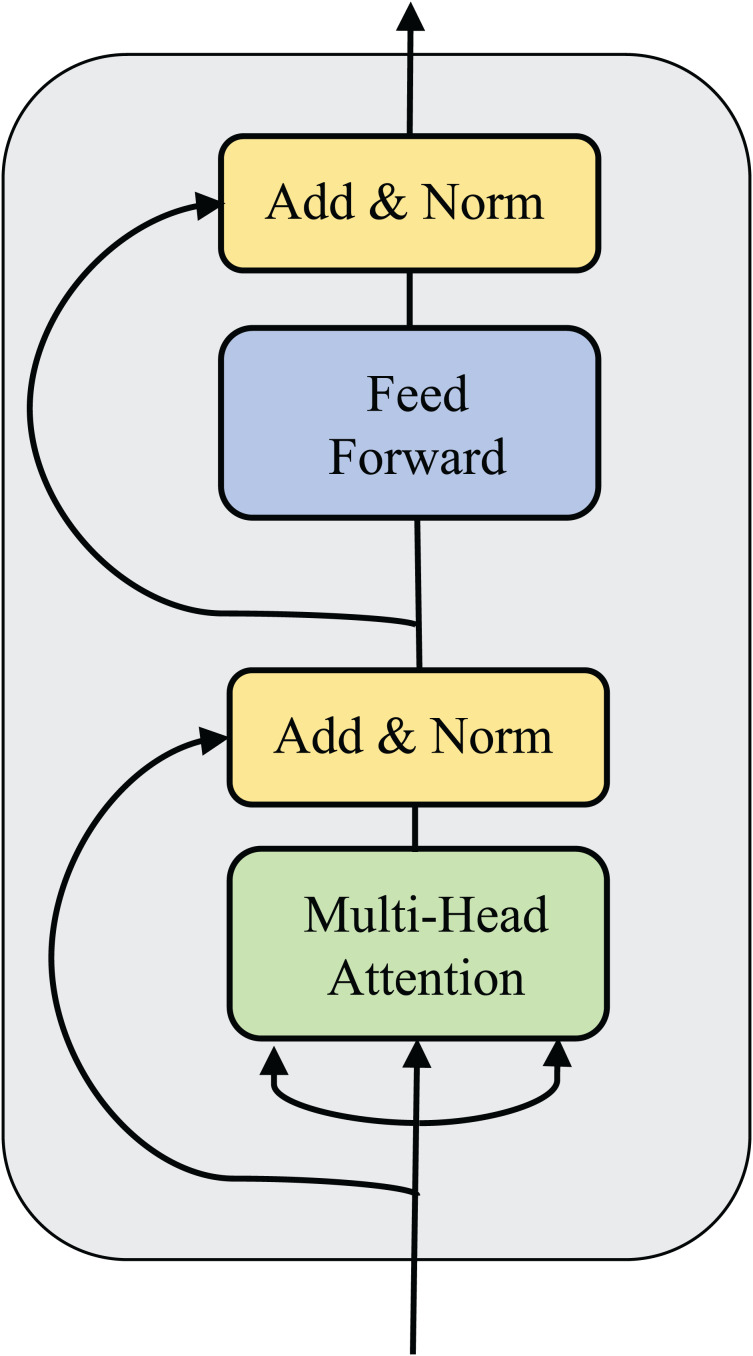 Figure 13
Figure 13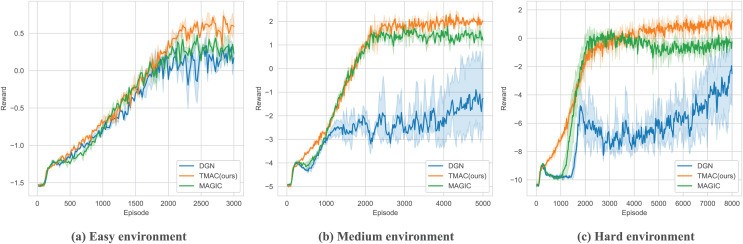 Figure 14
Figure 14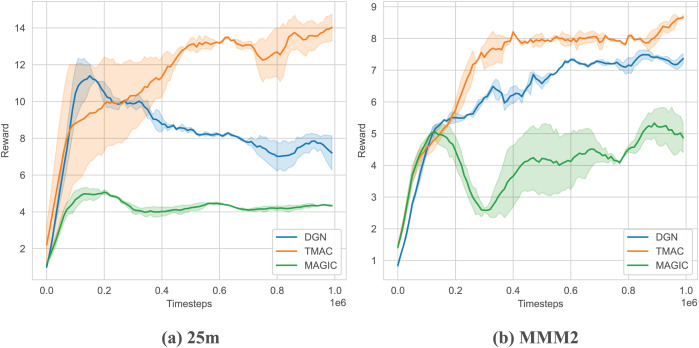 Figure 15
Figure 15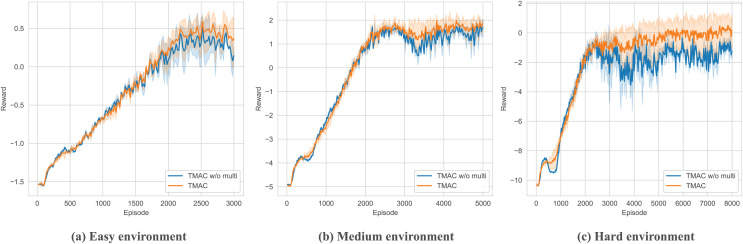 Figure 16
Figure 16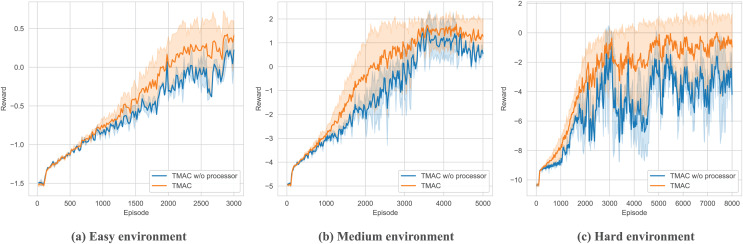 Figure 17
Figure 17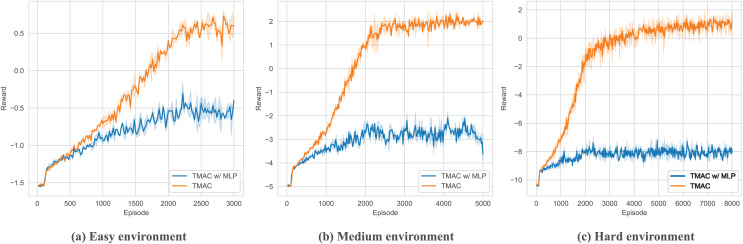 Figure 18
Figure 18 Figure 19
Figure 19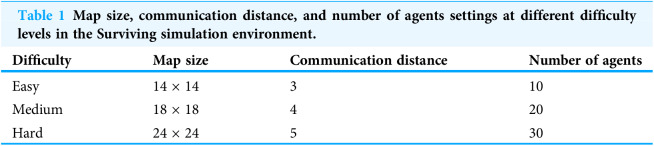 Figure 20
Figure 20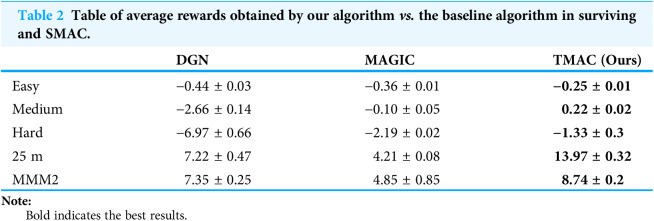 Figure 21
Figure 21 Figure 22
Figure 22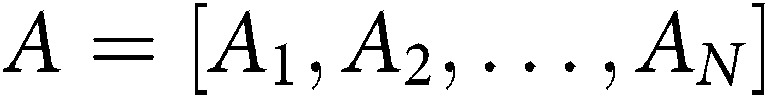 Figure 23
Figure 23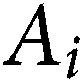 Figure 24
Figure 24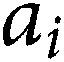 Figure 25
Figure 25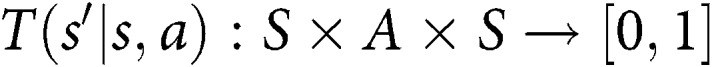 Figure 26
Figure 26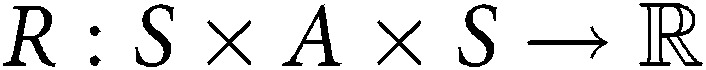 Figure 27
Figure 27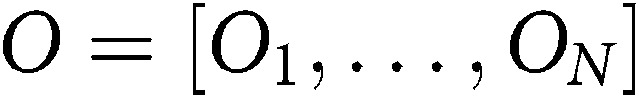 Figure 28
Figure 28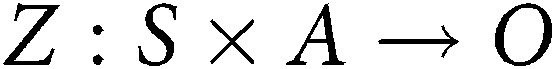 Figure 29
Figure 29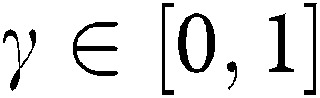 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39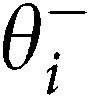 Figure 40
Figure 40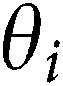 Figure 41
Figure 41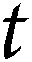 Figure 42
Figure 42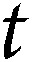 Figure 43
Figure 43 Figure 44
Figure 44 Figure 45
Figure 45 Figure 46
Figure 46 Figure 47
Figure 47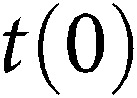 Figure 48
Figure 48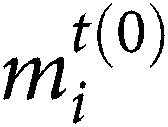 Figure 49
Figure 49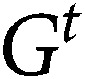 Figure 50
Figure 50Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsReinforcement Learning in Robotics · Distributed Control Multi-Agent Systems · Multi-Agent Systems and Negotiation