Mixture of prompts learning for vision-language models
Yu Du, Tong Niu, Rong Zhao

TL;DR
This paper introduces a new method for improving vision-language models by using multiple prompts and a routing system to better adapt to new tasks with fewer parameters.
Contribution
The novel contribution is a mixture-of-prompts learning method with a routing module and a gating mechanism to enhance adaptability and reduce overfitting.
Findings
The proposed method improves few-shot learning and domain generalization across 11 datasets.
The routing module effectively captures dataset diversity and selects suitable prompts dynamically.
Abstract
As powerful pre-trained vision-language models (VLMs) like CLIP gain prominence, numerous studies have attempted to combine VLMs for downstream tasks. Among these, prompt learning has been validated as an effective method for adapting to new tasks, which only requires a small number of parameters. However, current prompt learning methods face two challenges: first, a single soft prompt struggles to capture the diverse styles and patterns within a dataset; second, fine-tuning soft prompts is prone to overfitting. To address these challenges, we propose a mixture-of-prompts learning method incorporating a routing module. This module is able to capture a dataset's varied styles and dynamically select the most suitable prompts for each instance. Additionally, we introduce a novel gating mechanism to ensure the router selects prompts based on their similarity to hard prompt templates, which…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
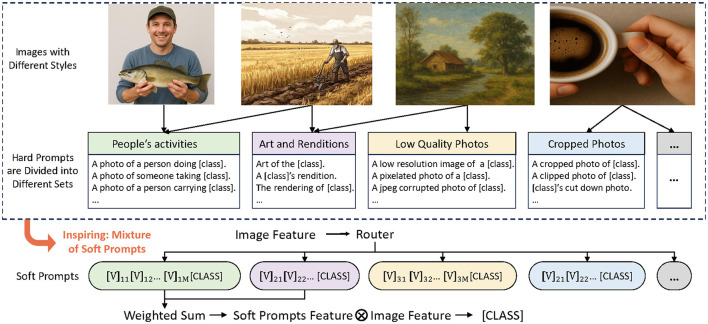 Figure 1
Figure 1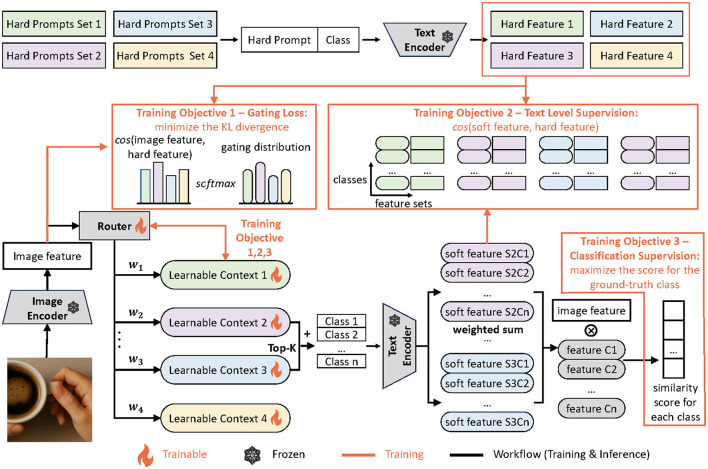 Figure 2
Figure 2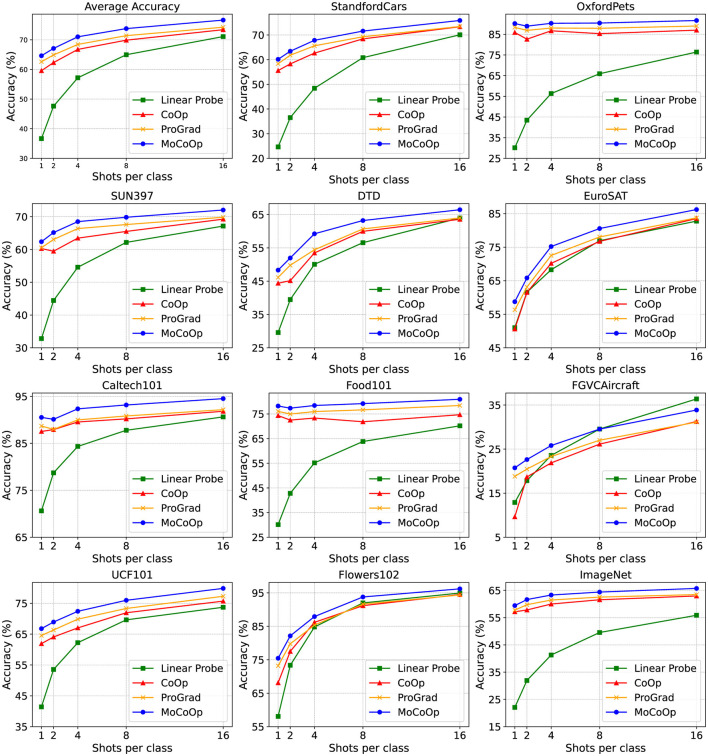 Figure 3
Figure 3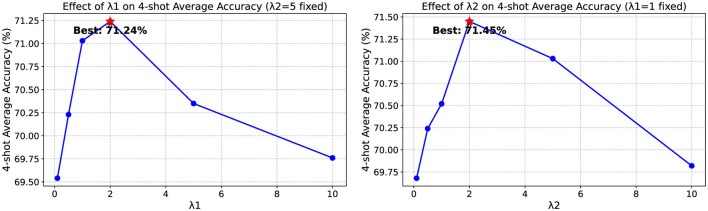 Figure 4
Figure 4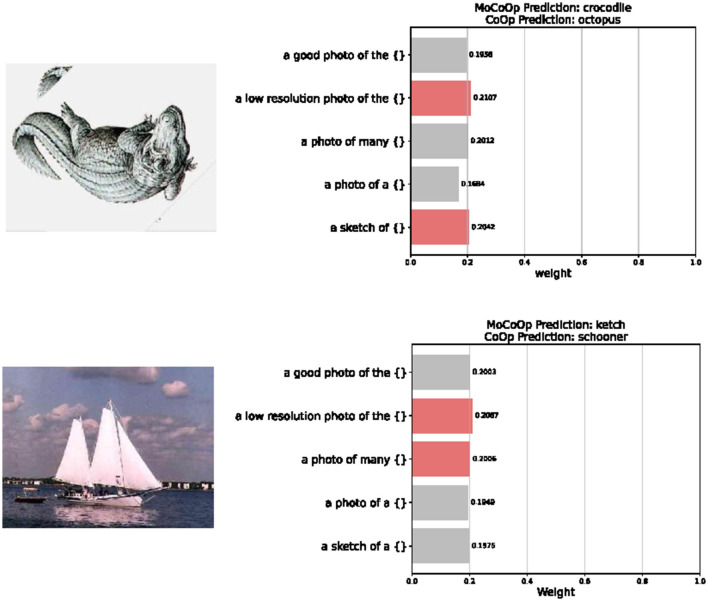 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMultimodal Machine Learning Applications · Advanced Image and Video Retrieval Techniques · Domain Adaptation and Few-Shot Learning