Shinyscreen: mass spectrometry data inspection and quality checking utility
Todor Kondić, Anjana Elapavalore, Jessy Krier, Adelene Lai, Hiba Mohammed Taha, Mira Narayanan, Emma L. Schymanski

TL;DR
Shinyscreen is a tool for analyzing mass spectrometry data, helping scientists check data quality and streamline workflows.
Contribution
Shinyscreen introduces a vendor-independent, open-source tool for mass spectrometry data quality control and visualization.
Findings
Shinyscreen supports compound and mass list-based screening for diverse analytical needs.
The tool is adaptable for use in research, education, and data curation workflows.
It is available as an open-source R package with Docker support for easy deployment.
Abstract
Shinyscreen is an R package and Shiny-based web application designed for the exploration, visualization, and quality assessment of raw data from high resolution mass spectrometry instruments. Its versatile list-based approach supports the curation of data starting from either known or “suspected” compounds (compound list-based screening) or detected masses (mass list-based screening), making it adaptable to diverse analytical needs (target, suspect or non-target screening). Shinyscreen can be operated in multiple modes, including as an R package, an interactive command-line tool, a self-documented web GUI, or a network-deployable service. Shinyscreen has been applied in environmental research, database enrichment, and educational initiatives, showcasing its broad utility. Shinyscreen is available in GitLab (https://gitlab.com/uniluxembourg/lcsb/eci/shinyscreen) under the Apache License…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
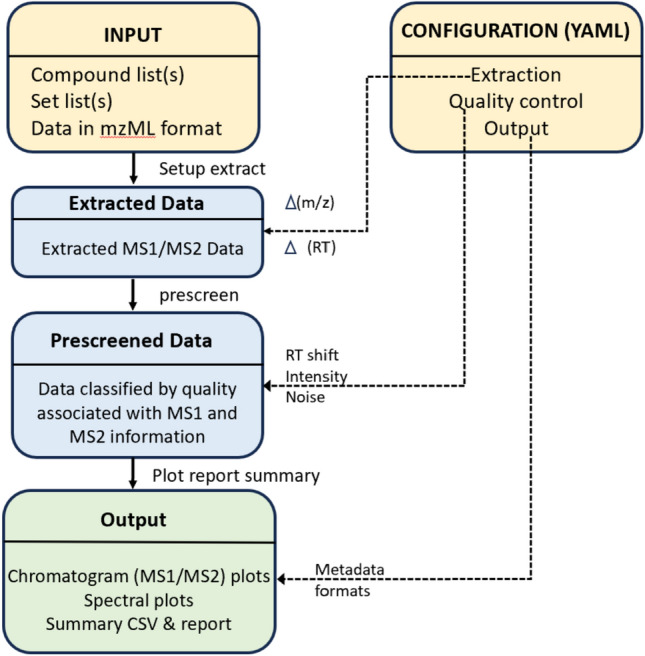 Figure 1
Figure 1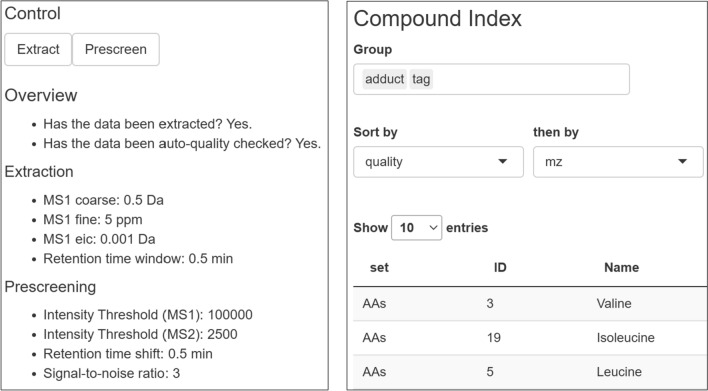 Figure 2
Figure 2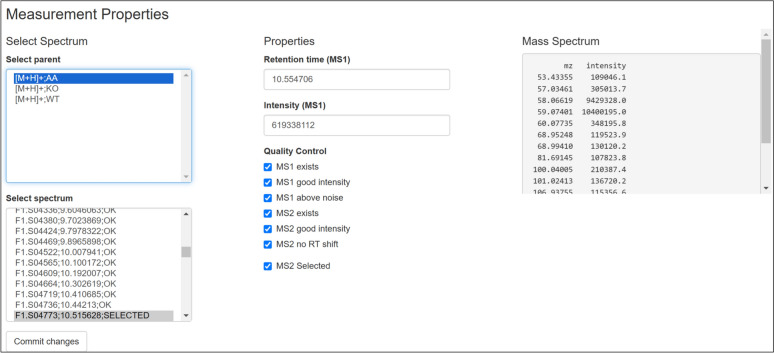 Figure 3
Figure 3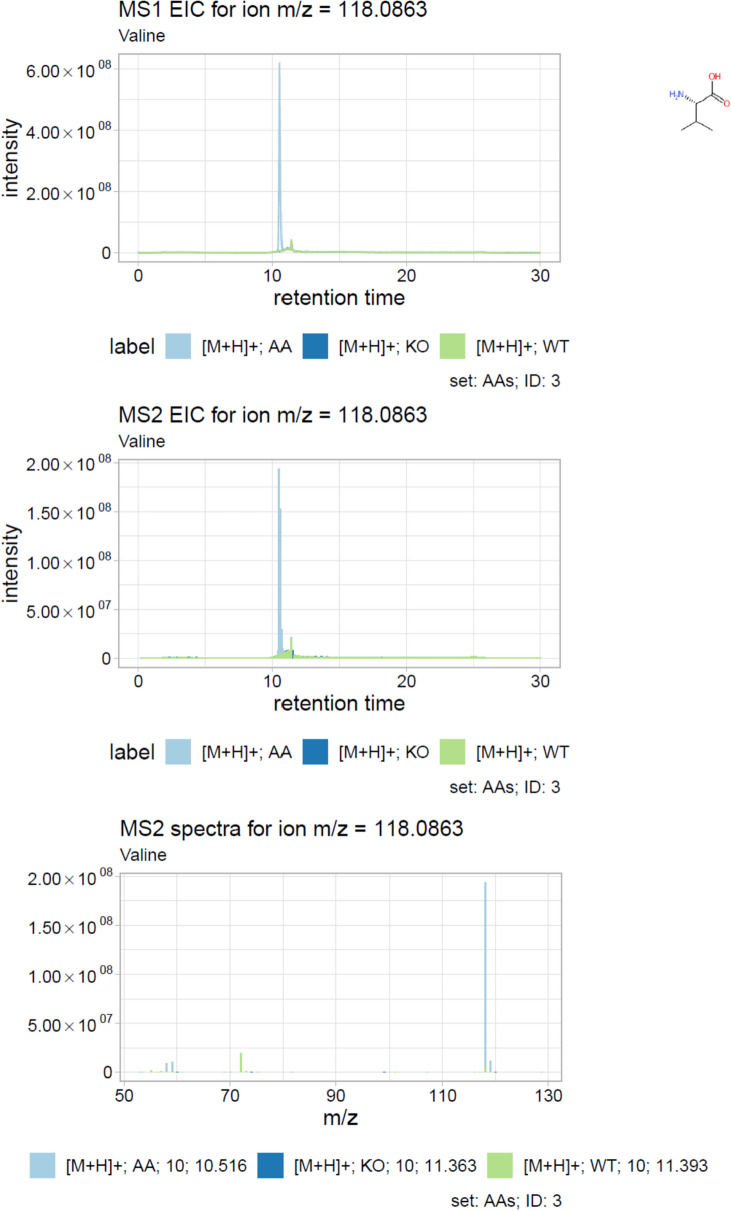 Figure 4
Figure 4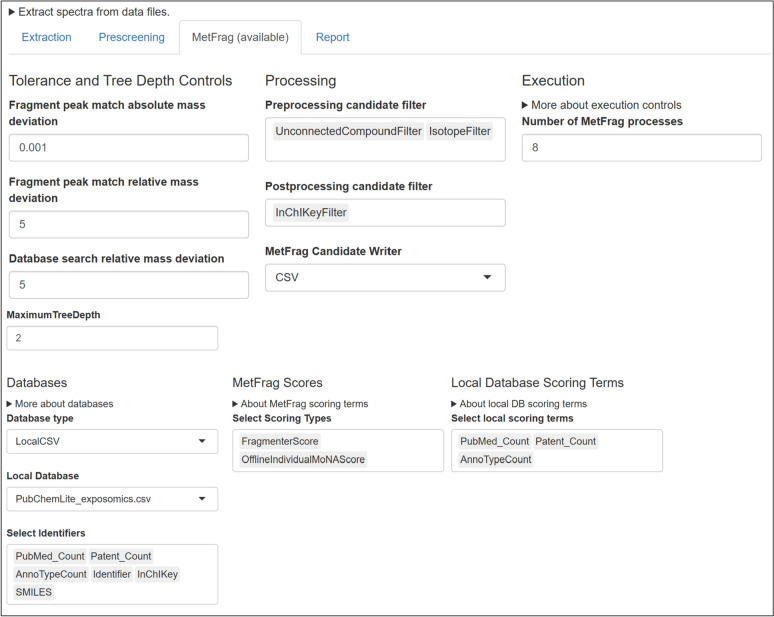 Figure 5
Figure 5 Figure 6
Figure 6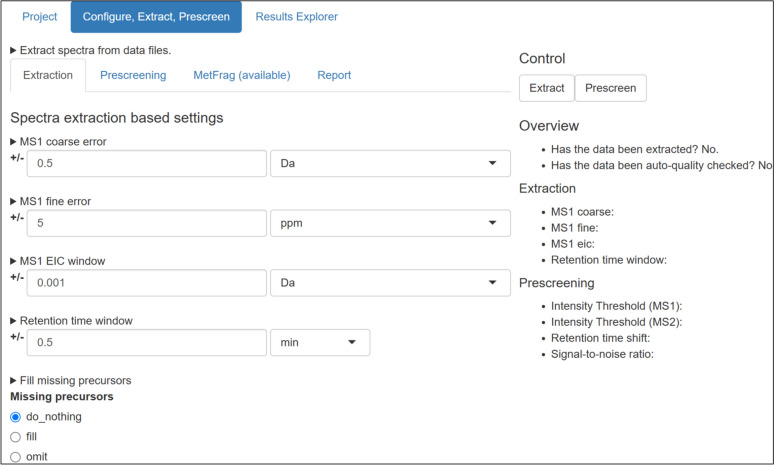 Figure 7
Figure 7- —https://doi.org/10.13039/501100001866Fonds National de la Recherche Luxembourg
- —The European Union Research and Innovation program Horizon Europe for PARC
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetabolomics and Mass Spectrometry Studies · Isotope Analysis in Ecology · Mass Spectrometry Techniques and Applications
Introduction
In recent years, high resolution mass spectrometry (HRMS) has become an indispensable analytical tool across various disciplines including metabolomics, proteomics, environmental chemistry, forensics and drug discovery [1]. HRMS enables researchers to analyze complex mixtures, identify compounds, and quantify their presence with high selectivity and sensitivity [2]. Typical HRMS workflows often follow one of several paths, tailored to specific analytical goals. Targeted analysis focuses on quantifying a predefined set of known compounds. Suspect screening investigates compounds on a curated list for identification, while non-targeted analysis (NTA) aims to uncover unknown compounds within a sample, requiring advanced analytical instruments and data processing software to process and annotate spectral data [3].
The increasing sophistication of MS instrumentation, coupled with the growing size and complexity of MS datasets, poses significant challenges in data processing, visualization, and interpretation [4]. To address these challenges, researchers rely on specialized software solutions tailored for MS data analysis. On one hand, device manufacturers usually provide software for data inspection and visualisation such as Xcalibur [5] for Orbitrap instruments. However, these tools are often constrained by restrictive licensing, limited compatibility with non-native platforms, and have a narrow focus on specific instrument models [6]. Consequently, they fail to meet the needs of users working with diverse MS platforms or seeking greater customization and transparency in their workflows [7].
On the opposite end of the spectrum, the open source community has developed robust software approaches to address the challenges associated with MS data analysis. These range from collaborative browser-based solutions such as GNPS Dashboard and GNPS Dataset Explorer [8] to several solutions offered in various open programming languages including python, Julia and R. In the programming language R, the main focus of this article, these include powerful, but low-level R packages such as mzR [9] and the more modern MSnbase [10, 11], which offer great flexibility in analysis of MS data and can be used for a first-look data exploration and prescreening, but require some programming expertise to fully utilize their functionality. On the other end of the scale, there are options such as xcms [12], RforMassSpectrometry [13] and patRoon [14], which provide comprehensive solutions for non-targeted metabolomics and environmental workflows. These approaches are very powerful, but often require significant computational resources, extended configuration time, and expertise in navigating their complex functionality. Further extending the toolkit, MetFrag [15] and RMassBank [16, 17] are both methods to support compound identification. MetFrag focuses on in silico fragmentation to match experimental data to candidate compounds, aiding in compound annotation during suspect and non-target screening workflows [18]. RMassBank facilitates the creation and management of high-quality spectral libraries, for higher confident compound annotation [3], but was originally designed to process single-injection pure standards and not mixtures. Despite their utility, these tools often serve specialized needs within broader HRMS workflows, such that integrating them effectively can be challenging for users without extensive computational experience.
Shinyscreen was designed to fill the niche in-between. Its focus is exclusively on data exploration, visualisation and automated quality control combined with manual overrides to offer simple but powerful functionality without the complexity of the advanced workflows. Unlike other tools that give users unrestricted access to raw MS data—the vast majority of which is irrelevant for a particular investigative effort—the Shinyscreen approach is centered on a preselected list of compounds or masses of interest. Thus, it can be used to support a wide variety of HRMS workflows, including target, suspect (“known”) and NTA (“unknown”) data interrogation without a confusing array of options that can overwhelm inexperienced users and students learning the basics of data processing.
This paper introduces Shinyscreen as a versatile and user-friendly interface for high-throughput HRMS data quality control, discussing the design principles, and demonstrating its utility through real-world applications. By bridging the usability gap between low-level programming tools and complex, resource-intensive platforms, Shinyscreen empowers researchers to focus on their investigative goals, enhancing both accessibility and efficiency in MS data exploration, while also serving a role in teaching activities at the University.
Implementation
Shinyscreen is built as a modular [19], extensible architecture that seamlessly integrates user accessibility with computational efficiency. It is tailored to support a wide range of MS data analysis ranging from target and suspect screening workflows to non-targeted studies. The application emphasizes streamlined data processing and intuitive visualisation, making it versatile for different research scenarios and educational purposes. A comprehensive overview of the conceptual workflow for Shinyscreen is presented in Fig. 1, outlining each step of the process. The core steps of Shinyscreen include initialisation, extraction and prescreening, visualisation and integration with MetFrag for further analysis, all wrapped in a front-end (user interface). Following the inputs and configuration (shown in yellow), data is first extracted and then prescreened (blue boxes in Fig. 1) and finally visualized / exported (green box, Fig. 1). This section describes the underlying software framework and technical design of Shinyscreen, while the results and discussion section gives a practical demonstration of Shinyscreen, highlighting its capabilities and key features.Fig. 1. Main stages of Shinyscreen workflow
Software dependencies
Shinyscreen is distributed as an R package. Its source code is primarily written in the R language, with some support code written in JavaScript. Several external dependencies are required for asynchronous graphical interface design, htmltools [20] for customisation of some GUI widgets, withr [21] for safe directory excursions, data.table [22] for efficient implementation of the internal Shinyscreen database, yaml [23] for processing of YAML files and RColorBrewer (RRID:SCR_016697) [24] for plotting.
The application includes various functions to handle the data extraction, prescreening, visualisation and integration with MetFrag. The data.table package is used extensively for handling mass spectrometry data for reading, writing and processing large internal tabular datasets. The DT package [25] integrates interactive tables into shiny interface allowing filtering and dynamic data exploration, thereby improving user engagement and accessibility [14]. The enviPat package (RRID:SCR_003034) [26] provides rapid calculation of adduct masses from molecular formulas, supporting workflows that require precise mass calculations. Finally, ggplot2 [27] serves as the primary tool creating high quality graphical outputs essential for interpreting complex datasets. Complementing ggplot2, the cowplot package [28] is utilized to arrange multiple plots in cohesive layouts within the application. Together, these packages optimize Shinyscreen’s data processing capabilities, ensuring robust, interactive, and visually informative outputs suited to large-scale cheminformatics applications.
Shinyscreen workflow
Initialisation
Any Shinyscreen workflow is based on two fundamental groups of inputs: the compound list (in CSV format) and experimental data files (in mzML format). The compound lists contain information describing the compounds of interest. For non-target (unknown) workflows, mass-to-charge (m/z) ratios of the precursors of interest are required, as well as, optionally, the expected retention times of the precursors. This input may often come via statistical or other prioritisation methods. For target/suspect (known) workflows, structural data can be provided instead of mass, along with (optional) retention time information.
If some degree of structural information about the compounds is known for example a molecular formula, or a SMILES [29] string as in target or suspect workflows Shinyscreen will automatically calculate required precursor ion masses for extraction, using the given adduct setting. If no structural information is known, the precursor ion masses must be supplied directly. An additional step required for the command-line mode of operation is to parametrise (a) experimental m/z and retention time errors; (b) quality control parameters such as MS1 and MS2 intensity thresholds and retention time shifts; and (c) output visualisations and metadata. Default values are provided, based on Orbitrap settings, but will need to be adjusted for other instrumentation.
Extraction and prescreening
At this stage, the precursor ion masses from the compound lists, their extracted ion chromatograms (EICs, within the specified m/z tolerance) as well as their corresponding MS2 spectral scans are retrieved from the data files. The data is extracted from mzML files using the MSnbase package which enables precise retrieval of extracted ion chromatograms (EICs) and MS2 spectra from mzML files. This is the most time-intensive step of the process. The extraction process can be carried out concurrently on multiple files using the future package [30]. This parallelization significantly reduces processing time, particularly for large-scale analyses involving multiple mzML files.
After the extraction is done, the data is subjected to a quality assessment stage. The quality of each MS1 parent data point is assessed based on the existence of MS1 and MS2 data, the noise level and the retention time shift compared with the provided thresholds. This step is also used to select a representative MS2 spectra (if present) for the input masses. These checks are all automated based on the input parameters, but can be reviewed manually once processing is done. The GUI will inform the user when the extraction is done and summarise the main parameters (Fig. 2, left). After prescreening, it is possible to navigate the spectra via the Compound Index (Fig. 2, right), using fully searchable tables. It is also possible to filter based on quantities of interest such as m/z, retention time, or quality score. A detailed overview of the experimental properties and quality for a particular measurement is available in the Measurement Properties pane (Fig. 3).Fig. 2. Left: Shinyscreen status overview showing extraction parameters. Right: Compound index after prescreeningFig. 3Measurement properties (quality control) pane
Visualisation
Shinyscreen’s visualization capabilities are integral to its user centric design. The ggplot2 [27] and cowplot [28] R packages are employed to generate high-quality plots of MS1 and MS2 chromatograms, as well as MS2 spectra. These visual outputs are designed for both on-screen inspection and publication purposes (see Fig. 4). Shinyscreen also incorporates the DT package to enable dynamic, interactive data exploration through the GUI. Users can sort and query data based on parameters such as m/z, retention time, or quality scores thus enhancing efficiency and accessibility.Fig. 4. An example plot from Shinyscreen consisting of MS1 chromatogram (top), MS2 chromatogram (middle) and representative MS2 spectrum (bottom) for Valine (structure shown in inset)
Integration with MetFrag
Shinyscreen integrates MetFrag, a widely used tool for in silico fragmentation and candidate structure ranking [15]. A local CSV database version is typically employed to rank candidate structures based on MS2 information, with the current default use set to PubChemLite [31, 32]. While the local runs are much better option for large datasets, the configuration can be complicated for databases with advanced scoring terms such as PubChemLite, and especially for data processing with many MS2 inputs. Shinyscreen provides a MetFrag configuration interface (Fig. 5) that hides a lot of the complexity and runs several MetFrag instances in background to speed up the analysis. The integration is streamlined through an automated configuration interface, hiding the complexity of MetFrag setup. Shinyscreen has been primarily tested with local databases, such as PubChemLite, which is downloaded from Zenodo (RRID:SCR_004129) within the Docker image. PubChemLite includes additional fields, such as annotation count, patent count, and PubMed (RRID:SCR_004846) count, which can be utilized by MetFrag as additional scoring terms to aid in the ranking of candidate structures. The results are aggregated into summary tables, allowing users to efficiently review candidate structures and their associated scores for all the MS2 spectra that passed the quality control criteria.Fig. 5. MetFrag Configuration Interface within Shinyscreen
Output
Shinyscreen provides a range of different outputs. There are plots of MS1 and MS2 chromatograms coupled with MS2 spectra organised in a PDF report (Fig. 4), providing visual summaries. Then, there are global summaries in CSV format. These include (a) a summary table consolidating key metadata, quality control results, spectral and experimental information such as retention times and peak intensities; (b) an MS2 spectra table, containing the precursor information for all MS2 spectra, facilitating further analysis and interpretation, and (c) the MetFrag summary table summarising MetFrag candidates for extracted MS2 spectra. Finally, the object returned by a prescreen call contains the extracted data, associations between MS1 and MS2, as well as other data generated by Shinyscreen during the execution of the pipeline organised in multiple related tables. This is the lowest level of all the outputs, but offers the largest degree of flexibility in terms of further processing.
Extensibility, deployment and scalability
To combat installation challenges in windows and mac platforms (since the primary development operating system (OS) was Linux), a Docker image was created using a Linux OS base image to encapsulate Shinyscreen along with its dependencies. This allowed Shinyscreen to run seamlessly on Windows through Docker Desktop, circumventing the compatibility issues and enabling a consistent, reliable environment for the users. The Docker image, which includes all necessary dependencies and configurations, is now available in the container registry [33]. This approach not only resolved the installation and execution issues but also enhances the portability of the software, making it more accessible to a broader range of users across different operating systems. This solution also paved the way for the next phase of the project’s deployment, where the Docker container can be easily integrated into a variety of platforms and computing environments, including cloud-based systems, local servers, and multi-user configurations, while also optimizing the deployment and scalability of Shinyscreen.
In Shinyscreen’s deployment, a Continuous Integration (CI) pipeline is configured within GitLab to support automated testing and streamline application updates. The CI pipeline runs builds and tests to provide with immediate feedback on the code integrity. This pipeline also simplifies the creation of installation files, which bundle all dependencies required for deploying Shinyscreen effectively. For multi-user educational access, Shinyscreen is hosted within a Kubernetes cluster, designed to support scalability and resource management for a teaching platform (ECI-ISB401). The Kubernetes setup allows multiple students to use the application simultaneously, with dynamic allocation of computational resources to optimize performance and user experience. Together, the CI/CD pipeline, Docker containerization, and Kubernetes orchestration create a robust, accessible, and scalable platform tailored to both individual and multi-user settings.
Results and discussion
Front-end (user interface)
Shinyscreen is developed using the R Shiny framework with an intent to support web-based data analysis and visualisation. The user interface (UI) for Shinyscreen (Fig. 6) is defined in Shiny UI scripts using fluid layouts to enable data input, visualisation and control elements. Each UI component is reactive, automatically updating in response to user interactions, such as modifying input configurations or adjusting analysis parameters. This design ensures an interactive and intuitive user experience, enabling efficient handling of complex mass spectrometry data in real-time.Fig. 6. Shinyscreen user interface
Configuration can also be done using the GUI as in Fig. 7.Fig. 7. Shinyscreen configuration screen
Another feature of Shinyscreen is interactivity. A great deal of development effort has been poured into a self-documented web-based interface which enacts a seamless configuration—extraction—prescreening—visualisation loop (see Fig. 1). Moreover, it is possible to serve the web interface in a multi-user environment, such as a lab computing platform, or workshops. Finally, Shinyscreen has been designed to fit into more comprehensive workflows. It can run without GUI, in headless mode, on local computers, servers and clusters. Shinyscreen outputs are self-contained and available in interchangeable formats such as RDS and CSV. Not only the data, but also the program itself is embeddable by the virtue of a top-level R API.
While Shinyscreen currently leverages Shiny’s reactive framework, the GUI could potentially be enhanced in the future by decoupling the front end from Shiny’s default rendering mechanisms. This would enable the integration of modern JavaScript-based frameworks, such as React or Vue.js, for a more dynamic, scalable, and user-friendly interface, while maintaining the robust analytical backend in R.
Environmental studies
Shinyscreen has been applied in several studies. Shinyscreen was used in a study investigating pesticides and their transformation products (TPs) in Luxembourgish waters [18]. By enabling targeted and non-targeted analysis of HRMS data, Shinyscreen facilitated the discovery and characterization of contaminants, showcasing its utility in environmental cheminformatics workflows. Similarly, it was utilized to study the occurrence and distribution of pharmaceuticals and their TPs in surface waters [34], highlighting its capacity for processing complex environmental datasets and supporting public health research. In addition, Shinyscreen has been used in adding open spectral data (5546 records) to public databases with high-quality mass spectra [3]. This includes contributions to resources such as MassBank and PubChem, enabling improved compound annotation for non-targeted exposomics of chemical mixtures. These efforts support global initiatives for open data sharing and enhance the reproducibility of non-targeted analytical workflows.
Teaching
Since 2020, Shinyscreen has been an integral part of the master’s teaching curriculum ISB401 at the University of Luxembourg, where it is used to familiarize students with MS data analysis. The teaching module is centered on targeted and non-targeted analysis of amino acids in Saccharomyces cerevisiae (yeast) wild-type and knock-out strains. This data set also serves as the test data provided in the package vignette. The practical session not only provides students with experience in handling complex HRMS datasets but also introduces them to the principles of data exploration, quality control, and annotation. The output of Shinyscreen can be readily used with MetFragWeb (good for students to learn the features and understand the results during teaching) [15, 35]), or integrated with MetFrag Command Line itself (better for batch processing) [36] for further analysis, enabling seamless integration into workflows for compound annotation. Notably, Shinyscreen’s development was shaped, in part, by feedback and input from the 2019 student cohort, ensuring its relevance as an educational tool both for teaching the subject but also in teaching software development for a non-expert audience. Student feedback has highlighted Shinyscreen as a user-friendly tool that bridges the gap between theoretical knowledge and practical application in MS data analysis while developing a strong foundational understanding of HRMS workflows. These case studies underscore Shinyscreen’s flexibility and robustness, making it a valuable tool for advancing research in environmental chemistry, database curation, and education.
Conclusion
In conclusion, Shinyscreen’s prescreening capabilities have proven valuable in different environmental studies, particularly where it has significantly enhanced data analysis and compound annotation. Shinyscreen has been especially beneficial for students, providing them with a practical application in MS studies while also fostering a deeper understanding of open source software development. The open source nature of Shinyscreen has encouraged collaboration, facilitating its use and continuous improvement within the research community. Furthermore, ongoing collaboration with the patRoon team aims to make both tools complementary in mass spectrometry workflows, further enhancing research capabilities. We welcome feedback and new use cases to continue refining Shinyscreen’s functionality.
Availability and requirements
- Project name: Shinyscreen
- Project home page: https://gitlab.com/uniluxembourg/lcsb/eci/shinyscreen
- Operating system(s): Platform independent
- Programming language: R (93%), JavaScript (4.5%)
- Other requirements: R 4.0.0 or higher
- License: Apache 2.0
- Any restrictions to use by non-academics: None
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Thermo Scientific (2024) Xcalibur™ Software. https://www.thermofisher.com/order/catalog/product/OPTON-30967. Accessed 2 Dec 2024
- 2Fischer B, Neumann S, Gatto L, Kou Q (2017) mz R: parser for net CDF, mz XML, mz Data and mz ML and mz Ident ML files (mass spectrometry data). http://bioconductor.org/packages/mz R/. Accessed 2 Dec 2024 [cito:cites As Authority]
- 3Laurent Gatto JR (2017) M Snbase. https://bioconductor.org/packages/M Snbase. Accessed 24 May 2025 [cito:cites As Authority]
- 4Colin A. Smith <Csmith@Scripps. Edu> RTC (2024) Xcms: LC-MS and GC-MS Data Analysis. https://bioconductor.org/packages/xcms. Accessed 6 Dec 2024 [cito:cites As Authority]
- 5Gatto L, Gibb S, Rainer J (2024) R for mass spectrometry. https://www.rformassspectrometry.org/. Accessed 6 Dec 2024
- 6Stravs M, Schymanski E, Neumann S, et al (2020) R Mass Bank: workflow to process tandem MS files and build Mass Bank records. https://bioconductor.org/packages/R Mass Bank/. Accessed 20 Jan 2020 [cito:cites As Authority]
- 7Wikipedia (2025) Modular programming. In: Wikipedia. https://en.wikipedia.org/wiki/Modular_programming. Accessed 24 May 2025
- 8Cheng J, Sievert C, Schloerke B, et al (2024) Htmltools: tools for HTML. https://cran.r-project.org/web/packages/htmltools/index.html. Accessed 18 Nov 2024 [cito:cites As Authority]