Validation of a Novel Data-Driven Algorithm to Detect Atypical Prescriptions in Radiation Therapy
Connor Thropp, Jaroslaw Hepel, Timothy Leech, Eric E. Klein, Qiongge Li

TL;DR
A new data-driven model detects unusual radiation therapy prescriptions and performs well across different cancer types and institutions.
Contribution
The model's robustness is validated across multiple disease sites and institutions using a novel similarity learning approach.
Findings
The model achieved high F1 scores (90-99%) for detecting anomalies in brain and thoracic cancer radiation therapy prescriptions.
Statistical analysis showed no significant differences between model predictions and ground truth.
The model is feasible for use in peer review chart rounds to detect potential prescription errors.
Abstract
Erroneous radiation therapy (RT) prescriptions (Rx) can lead to injury or death of patients. A novel data-driven model that uses similarity learning to identify atypical Rx was recently published. In that study, prototype analysis was conducted within a single institution with a single treatment site. The present study sets out to validate the robustness of the model by applying the model to multiple disease sites using a different institution’s data. A query was conducted of Brown University Health RT treatment records for thoracic and brain cancer patients from 1995 to 2021 to create historical databases used for training. The query included records containing data on the Rx and patient-specific features. Simulated anomalies were created to mimic potential errors and were used in the training and testing of the model. Model performance was evaluated using F1 score. F1 scores for the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
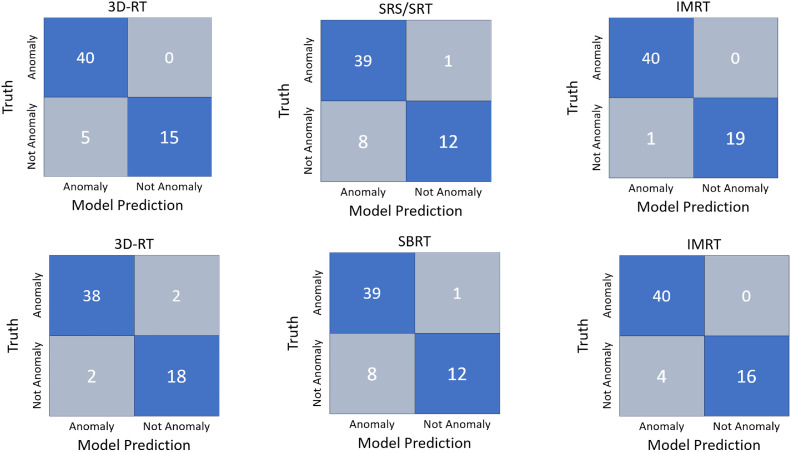 Figure 1
Figure 1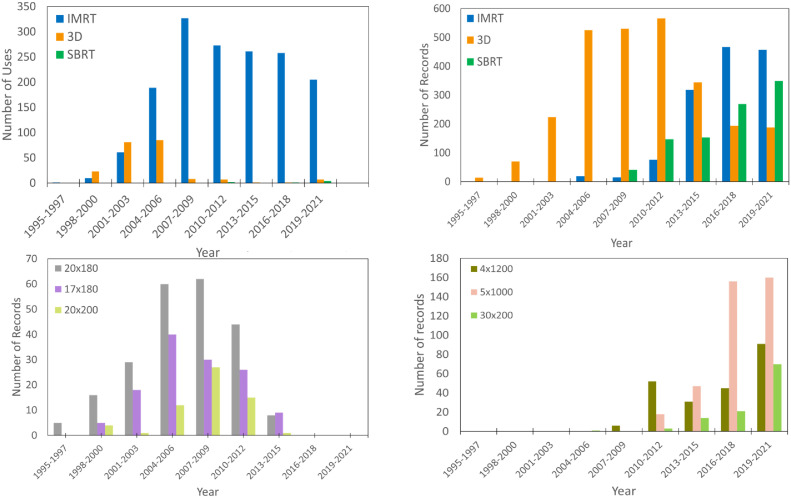 Figure 2
Figure 2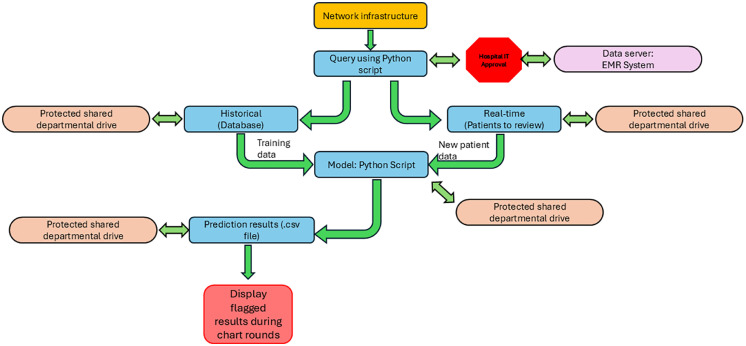 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMedical Imaging Techniques and Applications · Advanced X-ray and CT Imaging · Advanced Radiotherapy Techniques
Introduction
Errors stemming from inaccuracies in the prescription (Rx) for radiation therapy (RT) have a severe impact on clinical outcomes. Overdosing of radiation can lead to grave injuries or fatalities, whereas underdosing can result in suboptimal tumor control.1 Many Rx errors go undetected; however, a study by Portaluri et al2 exposed 37 RT errors within 5635 treatments, of which 12 were Rx-related. Another investigation by Yang et al3 brought to light 7 Rx-related issues during 1262 treatment courses. Physician-led peer-review (PR) chart rounds are the major step of quality assurance to prevent Rx errors from reaching the patient.
PR conducted by physicians represents a quality assurance mechanism aimed at mitigating human error and enhancing patient safety and treatment quality.4 However, PR often demands significant time, attention, and physician dedication, frequently yielding inefficient and ineffective results.5 Most RT centers hold weekly PR sessions, although some struggle to sustain this frequency because of workload and time constraints.6 A significant inefficiency of PR is the time investment required. Studies indicate that the average time dedicated to reviewing an individual patient's treatment plan during PR amounts to approximately 2.7 minutes, escalating to 7 minutes if cases warrant discussion.5, 6, 7 Assuming 40 patients are presented during each PR session, the time allocated for reviewing treatment plans could be as long as 108 minutes per session, with variations based on the extent of peer discussions. Attendance rates in PR mirror the time commitment involved; sessions with fixed timings show an 81% attendance rate, in contrast to 31% for groups without allocated time.8 Beyond its inefficiencies, PR also suffers from ineffectiveness. Notably, “hierarchical bias” occurs when senior clinicians' decisions remain largely unchallenged because of their seniority.8 Talcott et al9 examined PR effectiveness by introducing 20 anomalous cases over 9 weeks, revealing that PR identified only 67% of Rx anomalies. Another study10 linked virtual attendance to a 17.7% decline in overall case discussions, including a 10.2% drop in Rx-related discussions.
Anomaly detection is a challenging topic in machine learning because of a few reasons. Firstly, the lack of training samples from the anomaly class creates a significant hurdle for data-driven approaches, because the model needs exposure to anomaly samples to effectively learn.11, 12, 13, 14 Secondly, traditional machine learning tools often function as black boxes,15, 16, 17 lacking the capability to provide explanations for flagged anomalies. Thirdly, the creation of simulated anomaly samples often fails to accurately represent real-world anomalies,18, 19, 20 thereby preventing the model from generalizing and becoming less useful in predicting future realistic anomaly events. Li et al21 developed an anomaly detection algorithm aimed at overcoming these challenges by developing a rule-based model with clear flagging logic and no requirement for large anomaly data sets during training. Furthermore, in this study, the simulation of anomaly samples was based on conditional probability derived from extensive historical records and real-world anomalies, ensuring that the simulated anomalies closely resemble realistic clinical situations. Combining all the advantages discussed above, this tool could function as a powerful “electronic peer” to assist clinicians during PR.
Although initial testing of the model showed very promising results, it was conducted for a single disease site using only a single institution’s historical database.21 In this current study, we set out to apply the model to a new institution’s database as well as new disease sites to test the model’s overall robustness.
Methods and Materials
Data acquisition, preprocessing, and feature engineering
Data for this study were obtained through Brown University Health RT medical record system, MOSAIQ (Elekta Corp), with an IRB approval for a retrospective chart review. The query contained approximately 55,300 records of RT treatments from April 1995 to October 2021 that contained patient identifiers, Rx details, and patient-specific features. Moreover, the data collected included diagnostic code, treatment intent, treatment technique, beam energy, age, disease site, dose per fraction, number of fractions, and Rx isodose line, which we used as our feature set. Further preprocessing, discussed in the forthcoming text, reduced the number of historical records to around 2000 and 4100 for the thoracic and brain sites, respectively.
The preprocessing and data extraction phase involved in this work closely mimicked that of our original work.21 We aimed to remove records related to quality assurance testing and sought to categorize treatment features, such as modality, technique, and intent, into generalized categories. International Classification of Diseases (ICD-10) were used as a way of extracting site-specific records, as explained in our original work.21
Feature engineering techniques were used to impute missing values and reduce the diversity of categorical data. One approach adopted was the “most often” technique, where missing data for the treatment intent and Rx isodose line features were replaced with the most used value for each feature within each Rx for a given model. Additional feature engineering techniques were applied to the patient age data to convert the patient’s age to a categorical age group of either “pediatric” or “adult,” which was used to accentuate the differences between pediatric and adult treatments because of differing radiobiological effects.22, 23, 24 Another data engineering aspect entailed substituting categorical data with weighted numerical values for diagnostic codes. This converted the ICD-10 code into a weighted numerical value, which prioritized frequently used Rx and diagnostic code combinations. This was done by determining the counts of uses for each diagnostic code (ICD-10) within each Rx for a given model. The number of counts was divided by the number of times the Rx occurred in each model, giving a weighted numerical value. This prioritized records with similar Rx and diagnostic codes, and reconditioned the way the model used the feature, as it changed the feature from categorical values to numerical values.
Post engineering processing occurred to minimize excessive flagging of rarely used Rx. For example, reduced field records were intentionally increased in the historical database, increasing their weight. Other rarely used Rx were analyzed by our collaborating physician to determine if the records should be eliminated.
Model structure
The model used in this work is a distance model that uses 2 dissimilarity metrics to determine the distance between a new Rx and a previously treated Rx, as explicitly described in detail in our original work.21 The dissimilarity metrics are the prescription distance (R) and feature set distance (F). R uses Euclidean distance to measure how dissimilar the new Rx is from historically treated Rx, whereas F uses Gower distance25^,^26 to quantify the dissimilarity of the features associated with the Rx from features of previously treated similar (or same) Rx. The model not only can predict if an Rx is anomalous, but it can also specify why the new Rx is flagged. If R exceeds the threshold for Rx distance, then the record is flagged as a Rx anomaly. Similarly, if F is greater than the threshold for feature distance, then the record is flagged as a feature anomaly. For clarity, an Rx anomaly refers to deviations in the prescribed dose per fraction and the number of fractions, whereas a feature anomaly indicates a deviation in the feature set from those typically associated with that Rx.
Training and testing
Training and testing required the generation of simulated anomalies. These anomalies were either Rx or feature related and the creation process is described in our original work.21 Model training involved the cleaned historical data set relevant to the specific model (brain or thoracic). Sixty records were removed (20 for each technique) for training purposes and would later serve as normal records during testing. For training, each technique (intensity modulated radiation therapy [IMRT], 3-dimensional conformal radiation therapy [3DRT], stereotactic body radiation therapy/stereotactic crainial radiotherapy [SBRT/SRT]) within each treatment site model was provided with 30 simulated anomalies, resulting in a total of 90 anomalies used for each site model. Model training, as discussed in our original work,21 determined optimized model parameters which gave the highest-performing F1 scores. Model testing encompassed 20 simulated Rx anomalies, 20 simulated feature anomalies, and 20 normal records for each technique within each treatment site model. The testing parameters were derived from the aforementioned optimization and were specific to each treatment site and technique.
Validation of results
To validate the model’s predictions, we performed 2 types of validation. First, we gathered a list of 20 correctly predicted anomalies and 10 incorrectly flagged normal records by the model for each treatment site. We blindly provided our collaborating radiation oncologist (RO) with these records and asked him to determine if the records were normal or anomalous. This served to validate our model’s predictions versus those of a physician and to validate that our simulated anomalies were generated appropriately.
Our second form of validation was a statistical analysis using the χ^2^ test. Moreover, we compared the model’s predictions to the ground truth to determine if the model’s predictions were significantly different from the ground truth. We performed the χ^2^ test on the model’s output versus ground truth for all 360 records tested. A contingency table was generated containing a count of the number of predicted anomalies and normal records by the model and counts of the number of anomalies and normal records for the ground truth, which is displayed in Table 1. From the values in the contingency table, we conducted the χ^2^ test to determine if the model predictions were significantly different than the ground truth.Table 1χ^2^ test resultsTable 1Metric TypeAnomalyNormalTotalGround truth240120360Model prediction26496360Total504216720We conducted a χ^2^ test to determine the statistical significance of our results. We constructed a contingency table with the total number of anomalous records and normal records for the ground truth and the total number of models predicted anomalies and normal records. We performed the χ^2^ test with an alpha value of 0.05 and found a critical value of 3.84 with 1 degree of freedom. The χ^2^ statistic was determined to be 3.81, meaning we accept the null hypothesis that the model’s predictions are not significantly different from the ground truth.
Incremental learning
Periodic retraining with new data is necessary to make sure that the model is up to date with current treatment approaches. We tested a linear scaling approach on the thoracic IMRT data set, where records were scaled up in 2-year increments. For example, thoracic IMRT was first used in our clinic in 2006; hence, we applied a scale of 1x to records of those treated in 2006 and 2007; 2008 and 2009 were scaled by 2x, doubling the number of records of those treated during the 2-year interval. This process was repeated through 2021.
Results
The study's results, including training data and testing data performance using F1 scores and their optimization parameters (a, b, μ, ν, τ, and θ) are summarized in Table 2, along with information on the total historical records (S), simulated anomalies (S_a_), and normal records (S_n_) for training and testing. The fourth column from the right reports the average F1 score and its deviation over 50 runs for testing the training data. Training data testing included 40 normal records and 60 simulated anomalies per treatment site. Testing data included 40 simulated anomalies (20 of each type) and 20 unseen normal records.Table 2. Model resultsTable 2ParametersSiteData typeTechniqueabνμτθF1 (mean ± SD)S_normal_S_anomalies_SBrainTraining3D0.040.630.020.020.190.240.94 ± 0.0140601003SRT0.100.470.010.010.380.050.92 ± 0.0240601103IMRT0.021.120.010.010.130.450.98 ± 0.0140601868Testing3D0.040.630.020.020.180.250.9420401043SRT0.100.470.010.010.380.050.9020401143IMRT0.021.120.010.010.130.450.9920401908ThoracicTraining3D0.050.530.020.010.220.440.93 ± 0.24060404SBRT0.070.490.050.010.220.470.97 ± 0.014060611IMRT0.020.190.0180.030.120.300.93 ± 0.024060712Testing3D0.050.530.0180.010.210.430.952040444SBRT0.070.490.050.010.220.470.952040651IMRT0.020.190.020.030.120.290.9020407523D = 3-dimensional; IMRT = intensity modulated radiation therapy; S = number of historical records for the technique for each treatment site; S_anomalies_ = number of simulated anomalies in each training or testing set; SBRT = stereotactic body radiation therapy; S_normal_ = number of normal records used in the training or test set; SRT = stereotactic radiotherapy.F1 scores for training and testing are shown in the 10th column for each technique within each model. Standard deviations in training sets are found over 50 runs. Columns 4 to 9 show model parameters, which are as follows: a and b are optimization parameters for setting flagging thresholds (t_F_ and t_Rx_, respectively). ν and μ are percentages of the historical database for which the R and F statistics were generated, and τ and θ are mean pairwise feature and prescription distances.
Model performance across different treatment sites
The thoracic model achieved high F1 scores when testing both training data and test data. The scores were as follows: for IMRT, 0.93 for training data and 0.90 for test data; for SBRT, 0.97 for training data and 0.95 for test data; and for 3DRT, 0.93 for training data and 0.95 for test data. Classification results for the brain model are illustrated in Fig. 1. Notably, the model had a high success rate in predicting anomalies, with few misclassifications.Figure 1. Model classifications. Confusion matrices for the brain model (top) and thoracic model (bottom) are shown. Each 2 × 2 matrix represents the classification performance of the model, where the x-axis corresponds to the model predicted labels (anomaly or not anomaly) and the y-axis represents the truth labels. The 4 quadrants indicate the number of correct prediction (true positives and true negatives in blue) and incorrect predictions (false positives and false negatives in gray).Abbreviations: 3DRT = 3-dimensional conformal radiation therapy; IMRT = intensity modulated radiation therapy; SBRT = stereotactic body radiation therapy; SRT = stereotactic radiotherapy; SRS = stereotactic radiosurgery.Figure 1
Similarly, in the brain model, the F1 scores were strong. The scores were as follows: for IMRT, 0.98 for training data and 0.99 for test data; for SRT, 0.92 for training data, and 0.90 for test data; and for 3DRT, 0.94 for training data and 0.94 for test data. Binary classification of the thoracic model’s test data is illustrated in Fig. 1, revealing good performance for IMRT and 3DRT, with a few normal records incorrectly flagged as anomalies. However, SBRT showed more misclassifications with 8 normal records predicted as anomalies.
Physician validation of model predictions
Our collaborating RO reviewed a set of 30 model-flagged anomalies (correctly flagged anomalies and falsely flagged normal records) per site model. For the thoracic model, 18 out of 20 correctly flagged anomalies were confirmed to be anomalies. Two of the 10 incorrectly flagged normal records were identified by the oncologist to be valid flags and/or appropriate for review. For the brain model, 18 of 20 correctly flagged anomalies were confirmed to be anomalies, and 3 of 10 incorrectly flagged normal records were denoted as accurate flags and/or appropriate for review.
Statistical analysis
For our statistical analysis of the comparison of the model’s predictions to the ground truth, we found the χ^2^ statistics of 3.81 to be less than the critical value of 3.84 when using an alpha value of 0.05, meaning that we will keep our null hypothesis, and assume that the model’s predictions and ground truth are not significantly different.
Secular time analysis
Our linear scaling approach for incremental learning was used as a proof of concept in this study, and the results show that there is a secular time trend in our data, as F1 for the unscaled data set was 0.9 and increased to 0.95 when the scaled data set was used to give a higher weight to more recent treatment records.
New protocols and advancements in the field cause changes in the method of radiation delivery and dosage schemes over time,27, 28, 29 which contribute to the secular trend seen in our linear scaling approach. This led us to further analyze the trends in our data, and the clear evolutionary trends for RT techniques and dosage schemes are shown in Fig. 2. For thoracic treatments, we see an almost sole use of 3-dimensional (3D) treatments until the late 2000s, with a steep decline in subsequent years, and IMRT and SBRT quickly becoming the favored techniques. Similarly, prostate treatment sites follow the same trend. Three-dimensional was the preferred treatment technique until an almost exponential increase in the use of IMRT in the mid-2000s. This trend is influenced and coincides with studies such as Michalski et al’s30 analysis of the preliminary toxicities of 3D and IMRT, and others.31, 32, 33, 34 The trend of increasing use of IMRT and SBRT techniques is evident in Rx usage. Our collaborating physician identified the current commonly used Rx and retired Rx for the thoracic data sets. Three Rx rising in use are also depicted in Fig. 2; all 3 were not commonly used until the mid-2010s. On the other hand, Rx, whose use has ceased in recent years, are also shown. Moreover, 3D Rx in the mid to late 2000s were common; however, these Rx ceased to be used for treatments in the mid-2010s.Figure 2. Evolutionary trends. Advances in technology and treatment protocols have led to a shift from 3-dimensional conformal radiation therapy (3DRT) to intensity modulated radiation therapy (IMRT) and stereotactic body radiation therapy (SBRT). The top-left plot illustrates the transition from 3DRT to IMRT for prostate radiation therapy. The top-right plot highlights the predominance of IMRT in thoracic treatments since the early to mid-2010s, alongside a continuous upward trend in SBRT use, while 3DRT has steadily declined. The bottom-right plot depicts the increasing adoption of 3 radiation therapy prescriptions for thoracic treatments: 2 SBRT regimens (4 fractions of 1200 cGy and 5 fractions of 1000 cGy) and an IMRT regimen (30 fractions of 200 cGy), all trending upward from the early 2010s to 2021. In contrast, the bottom-left plot shows the decline of outdated 3DRT prescriptions (20 fractions of 180 cGy, 17 fractions of 180 cGy, and 20 fractions of 200 cGy) from the early to mid-2010s, reflecting a shift toward updated dosage schemes at the institution.Figure 2
Discussion
In this study, we validated a data-driven distance model that uses historical data to determine distances between Rx and feature sets for records with similar Rx. This study, along with our original work,21 is among the first on automatic Rx error detection in RT. Related works by Sharabi et al35 and Pashtan et al36 investigate automated RT Rx error detection; however, their studies employ different detection methods. Sharabi et al.’s35 method of Rx error detection cross-references new Rx with the frequency of previously treated Rx. If the new Rx was not previously seen or infrequently used, then it was flagged. We believe that conditional probability is a valid approach; however, it is very labor-intensive as it would require calculating the conditional probability for every feature combination. There has been no additional published information since 2012. Pashtan et al’s36 method incorporates rule-based error detection, where rules defining appropriate RT Rx were established. When a new Rx did not fall within the bounds of the rules, an automatic email was generated and sent to the prescriber. This method only looks at the Rx’s fractional and total dose and does not analyze patient-specific features. Expanding on this method could involve the generation of rules for every feature; however, this would be very time-consuming and would need to be adapted as RT regimens change. Our approach, a data-driven model, is much simpler than the alternative methods. The detection model is able to calculate appropriate thresholds for flagging, and with the addition of incremental learning, the model can adapt to new RT regimens. Additionally, our model is intuitive, as its predictions show why the Rx was flagged. Examples of the model predictions are seen in Table 3, where the model output gives the prediction, truth, and type of anomaly (if applicable).Table 3. Model prediction examplesTable 3MetricsRecord #FxDose per Fx (cGy)TechniqueEnergy (MV)Rx IDL (%)IntentDiagnostic codeAge groupTruthPredictionTypeRt_Rx_Ft_F_# Records in DB11150SRT1.2550CurativeC79.31Adult1110.5960.005--0232000SRT6x50PalliativeC79.31Adult1110.50.005--033600SRT6x82PalliativeC79.31Adult1110.0590.005--047300SRT6x82PalliativeC79.31Adult1110.5140.05--0511500SRT6x100PalliativeC79.31Adult11200.0050.3640.18045611800SRT1.2550PalliativeC79.31Pedi11200.0050.2020.1801777101003D6x99PalliativeC79.31Adult1110.3860.010--08125203D6x98PalliativeC79.31Adult1110.6250.010--0941803D6x100CurativeC71.3Pedi1110.0430.010--010103003D4e90PalliativeC69.31Adult11200.0100.40.1125191183003D10x95PalliativeC71.9Adult11200.0100.5070.112161251803D6x100PalliativeC71.7Pedi11200.0100.2970.112231320300IMRT6x100PalliativeC79.31Adult1110.3220.009--01425150IMRT10x100PalliativeC79.31Adult1110.250.009--01532200IMRT6x100CurativeC71.1Adult1110.0670.009--01610300IMRT6x100CurativeC71.9Pedi11200.0090.5250.14852175180IMRT6x100PalliativeC71.1Adult11200.0090.2020.1481421825180IMRT6x70PalliativeC71.2Adult1120030090.40.148341942000SBRT6x84CurativeC34.11Adult1110.5590.031--02051800SBRT6fff84CurativeC34.11Adult1110.750.031--02131800SBRT6fff88CurativeC34.32Pedi11200.0310.3040.104912231800SBRT6fff83CurativeC15.3Adult11200.0310.1320.1049123201003D10x97CurativeC34.31Adult1110.9010.021024102203D10x100PalliativeC34.10Adult1110.1000.021025301003D10x91PalliativeC34.31Adult1111.6770.021026102003D10x100CurativeC34.80Pedi11200.0210.2530.1122027103003D10x98PalliativeC22.8Adult11200.0210.0120.11225228152503D10x98CurativeC34.10Adult11200.0210.2210.112752952180IMRT10x100CurativeC15.4Adult1110.50.007--03018250IMRT6x100CurativeC15.4Adult1110.4860.007--03120250IMRT6x100CurativeC34.12Adult1110.4530.007--03223180IMRT6x100PalliativeC15.4Adult11200.0070.2430.022203332180IMRT6x100CurativeC15.5Adult11200.0070.330.022253425180IMRT6x100CurativeC15.5Adult00-00.00700.221363523200IMRT6x100CurativeC71.1Adult00-00.00900.14853536103003D6x97PalliativeC79.31Adult00-00.01000.1125193751000SBRT6fff86CurativeC15.3Adult10*-00.0310.0610.10437738252003D6x97CurativeC71.1Adult0110.1450.010--103925180IMRT10x100CurativeC15.4Adult01200.0070.0670.0221344030180IMRT6fff100CurativeC71.8Adult01200.0090.2050.148683D = 3-dimensional; F = average feature distance; IMRT = intensity modulated radiation therapy; Pedi = pediatric; R = average prescription distance; Rx = prescription; SBRT = stereotactic body radiation therapy; t_F_ = feature threshold for flagging; t_Rx_ = prescription threshold for flagging; IDL = Isodose line.⁎The error that occurs in the data.Displayed are examples of model predictions. The table shows the Rx (dose per fraction and number of fractions) along with the features used in this study (technique, energy, Rx isodose line, intent, diagnostic code, and age group). The truth column tells if the record was a normal record (0) or a simulated anomaly (1). The prediction column is the model’s prediction for that record, and the type of anomaly that it predicted (1 being an Rx anomaly or 2 being a feature anomaly). The last column shows the number of times that the Rx is seen in the historical database. The first record shows a Rx anomaly, where the model prediction (1) matches the truth (1) for a Rx type anomaly (1), because the R statistic exceeds the Rx threshold. It is seen that the Rx is not used in the historical database. Record 5 is an example of a correctly predicted feature type anomaly, where the t_Rx_ is not exceeded by the R statistic; however, t_F_ is exceeded by the F statistic. The given records show correctly predicted atypical records (records 1-33), normal records not flagged by the model (records 34-36), and incorrectly predicted records (records 37-40).
We aimed to assess the model's performance across different treatment sites and institutions. F1 scores for training data and test data for both treatment sites exceeded 0.90, as shown in Table 2, showing high stability for the model when applied to multiple sites. Additionally, this study’s results for the thoracic model show strong robustness across multiple institutions' data, as our results show similar model performance metrics, with this study scoring slightly higher for all 3 techniques when compared to our original work.21 This improvement was partly because of enhanced data engineering methods, such as adjusting how the model handled diagnostic codes and age categories, along with data imputation to fill missing values in nearly complete features. This resulted in data sets without missing values.
Limitations
In our methods, we aimed to remove anomalous records; however, some anomalies may remain, potentially affecting the model's accuracy. Averaging the parameters n and m, as discussed in our original work, can help mitigate this error.
Our data limitations arise from a restricted timeframe (1995 to 2021), in that we are missing current data reflecting recent protocol changes, which is evident in the prostate treatment site.37 A physician specializing in prostate RT treatments reviewed Rx data from our query and concluded that the data was out of date, as many current prostate treatments follow simultaneous integrated boost protocols.38^,^39 Additionally, we recognize several factors that may have influenced our results. The 2 institutions included in this study represent significantly different clinical environments, which may introduce systematic biases in Rx patterns. The first institution, a large academic center, features physicians from diverse training backgrounds with varying levels of experience, leading to greater variability in Rx practices. This center also serves as a demographically diverse patient population from multiple states, which may impact treatment decisions. In contrast, the second institution is a private clinic with physicians from more uniform training backgrounds and a more localized, homogeneous patient population, potentially leading to more standardized Rx behaviors. Furthermore, differences in treatment capabilities, such as the absence of a linac-based stereotactic radiosurgery (SRS) program at the first institution and the specialization in this technology at the second, may further contribute to variability in treatment approaches. These factors should be considered when interpreting our results.
The model is generalizable based on our validation results, but requires physician and data modeling expert input. Although this current study focuses on testing the model within a controlled environment with simulated anomalies and retrospective data only, we recognize that using real anomalies would be ideal for better capturing the complexity of real-world scenarios and is a necessary next step. Transiting from a controlled testing environment to live application will pose additional challenges that are beyond our study’s scope, such as adapting the model to diverse, dynamic clinical environment, patient-specific variations, extensive data collection on real-life anomalies and collaborations between various team members. We plan to address these challenges in a future study specifically through live clinical trials, which will assess the model's performance with actual patient data in real-time settings. These trials are essential to further validate the model’s adaptability and generalizability in clinical environments.
Implementing a new technological tool in clinical practice can be challenging and worrisome. Figure 3 provides a detailed workflow diagram that illustrates our approach in implementing the system based on a real-life scenario and the technological infrastructure required for clinical application of our model while complying with health care regulations.Figure 3. Integration into hospital infrastructure. Use of the model starts with the hospital network infrastructure. The infrastructure should include all required components to functionally use an electronic medical record (EMR) system (Wi-Fi, routers, personal computers connected to the network, and secure data transfer pathways [displayed as arrows]). In addition, the infrastructure should include shared departmental drives/folders that are secured with password protection to maintain patient confidentiality and data integrity, which are visualized as orange ovals. To query data, IT administration will need to approval and assist with the backend of the EMR system in order to run the python script to extract the necessary data from the secure data server, depicted in lilac. Our query has 2 components. The first is a historical database query, where we obtain data for training purposes. The second type of query would be used for real-time, new patient, data acquisition. The data obtained during both types of queries must be saved on protected shared drives. Next, a python script will be executed that will train and store the model in a protected departmental drive. The python script will then use the new patient data and the trained model to predict anomalies. The output of the model, in the form of a .csv file, will be saved to the protected departmental drive. For clinical use, a network PC can display the .csv file during chart rounds.Figure 3
Our method of validation does not resemble peer review, as peer review is a collaborative process that relies on discussion among experienced peers to determine the correctness of a patient’s Rx. However, a benefit of this method is that we were able to compare the model’s predictions to that of a single physician for atypical records, which allowed the physician to confirm that the simulated anomalies closely mimicked the real anomalies and were realistic. This also enabled us to conduct an error analysis, identifying the shortcomings of our model. Among the model predictions reviewed by the collaborative RO, all incorrect flags were related to features. The RO deemed less than 3 out of 10 predictions per model as atypical, indicating that the model tends to over-flag potential feature anomalies. This suggests there is room for future improvement and refinement of feature data.
Incremental learning
Acknowledgment of the outdated and rising Rx is vital to the success of the model. The inclusion of outdated Rx in the training data allows for the possibility of anomalies to go unflagged, meaning outdated Rx could be seen as typical. On the other hand, records with new Rx may be flagged as anomalies, because of the lack in the number of records. We propose several incremental learning strategies. First, we limit the use of data that are too old, such as data from more than 2 decades ago. Another option is to use a sliding window approach, where data are fed into the model every 2 years, and the oldest 2 years are retired. These approaches have not been tested in the current study but offer opportunities for future work.
To ensure model relevance, we emphasize the use of automated data collection and preprocessing systems, along with automation for simulating anomalies. We propose a structured approach for maintaining the model's clinical relevance by regularly integrating updates from major RT protocol changes, clinical trial results, and radiation safety guidelines. Professional organizations like the American Society for Radiation Oncology and the European Society of Radiotherapy and Oncology update clinical guidelines every 3 to 5 years, while regulatory bodies periodically revise safety protocols. To ensure the model stays current, we recommend formal reviews and retraining at least twice a year, with interim updates if significant changes occur. Continuous input from clinicians will also guide these updates, ensuring that practical insights from clinical practice are incorporated.
Conclusions
In conclusion, we have shown that the automated Rx anomaly tool generalizes well to a second institutional database and multiple treatment sites which highlights the potential usefulness of the tool as more generally adoptable for detecting Rx anomalies in RT, given the stated limitations.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Eaton D.J.Byrne J.P.Cosgrove V.P.Thomas SJ.Unintended doses in radiotherapy-over, under and outside?Br J Radiol 9120182017086310.1259/bjr.20170863 PMC 596598129293373 · doi ↗ · pubmed ↗
- 2Portaluri M.Fucilli F.I.M.Gianicolo E.A.L.Collection and evaluation of incidents in a radiotherapy department: A reactive risk analysis Strahlenther Onkol 18620106936992114012810.1007/s 00066-010-2141-2 · doi ↗ · pubmed ↗
- 3Yang R.Wang J.Zhang X.Implementation of incident learning in the safety and quality management of radiotherapy: The primary experience in a new established program with advanced technology Bio Med Res Int 2014201439259610.1155/2014/392596 PMC 412967025140309 · doi ↗ · pubmed ↗
- 4Martin-Garcia E.Celada-Álvarez F.Pérez-Calatayud M.J.100% peer review in radiation oncology: Is it feasible?Clin Transl Oncol 222020234123493255739510.1007/s 12094-020-02394-8PMC 7299249 · doi ↗ · pubmed ↗
- 5Brunskill K.Nguyen T.K.Boldt R.G.Does peer review of radiation plans affect clinical care? A systematic review of the literature Int J Radiat Oncol Biol Phys 97201727342781636010.1016/j.ijrobp.2016.09.015 · doi ↗ · pubmed ↗
- 6Lewis P.J.Court L.E.Lievens Y.Aggarwal A.Structure and processes of existing practice in radiotherapy peer review: A systematic review of the literature Clin Oncol (R Coll Radiol)3320212482603316079110.1016/j.clon.2020.10.017 · doi ↗ · pubmed ↗
- 7Lawrence Y.R.Whiton M.A.Symon Z.Quality assurance peer review chart rounds in 2011: A survey of academic institutions in the United States Int J Radiat Oncol Biol Phys 8420125905952244500610.1016/j.ijrobp.2012.01.029 · doi ↗ · pubmed ↗
- 8Huo M.Gorayski P.Poulsen M.Thompson K.Pinkham MB.Evidence-based peer review for radiation therapy – Updated review of the literature with a focus on tumour subsite and treatment modality Clin Oncol (R Coll Radiol)2920176806882852867910.1016/j.clon.2017.04.038 · doi ↗ · pubmed ↗