Deep generative models for Bayesian inference on high-rate sensor data: applications in automotive radar and medical imaging
Tristan S. W. Stevens, Jeroen Overdevest, Oisín Nolan, Wessel L. van Nierop, Ruud J. G. van Sloun, Yonina C. Eldar

TL;DR
This paper explores using deep generative models for Bayesian inference in high-rate sensor data from automotive radar and medical imaging.
Contribution
It addresses challenges in applying generative models to sensor data with high dynamic range and non-Gaussian noise.
Findings
High-rate sensor data require specialized generative models due to complex data-generating processes.
Approximate models lead to non-Gaussian discrepancies in Bayesian inverse problems.
Real-time processing demands impose strict latency and throughput requirements.
Abstract
Deep generative models (DGMs) have been studied and developed primarily in the context of natural images and computer vision. This has spurred the development of (Bayesian) methods that use these generative models for inverse problems in image restoration, such as denoising, inpainting and super-resolution. In recent years, generative modelling for Bayesian inference on sensory data has also gained traction. Nevertheless, the direct application of generative modelling techniques initially designed for natural images on raw sensory data is not straightforward, requiring solutions that deal with high dynamic range signals (HDR) acquired from multiple sensors or arrays of sensors that interfere with each other, and that typically acquire data at a very high rate. Moreover, the exact physical data-generating process is often complex or unknown. As a consequence, approximate models are used,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
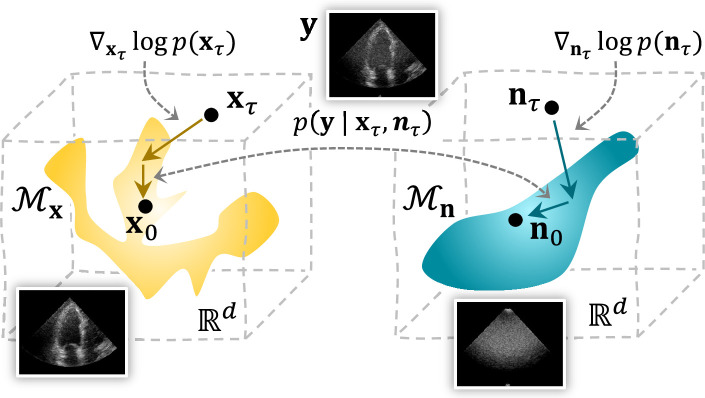 Figure 1
Figure 1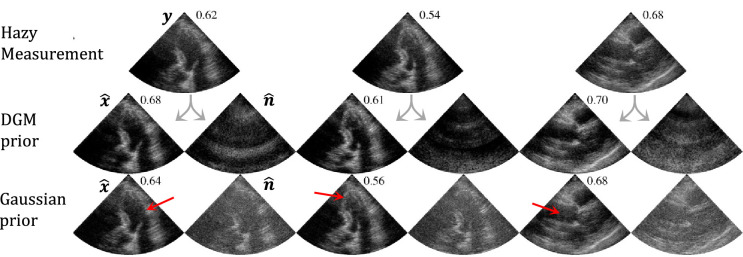 Figure 2
Figure 2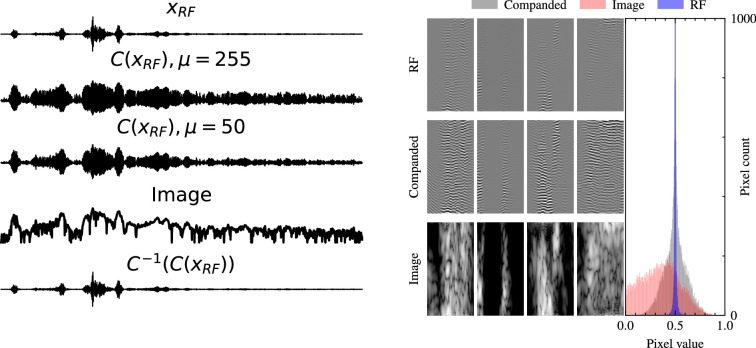 Figure 3
Figure 3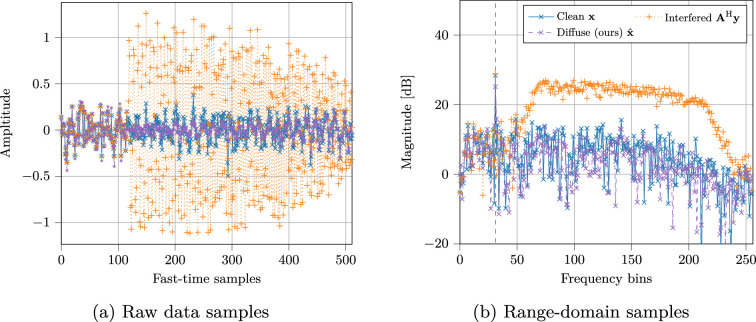 Figure 4
Figure 4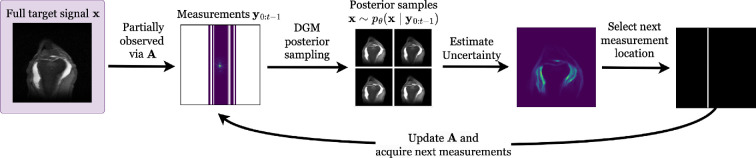 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsImage and Signal Denoising Methods · Underwater Acoustics Research · Target Tracking and Data Fusion in Sensor Networks
Introduction
Active array sensing techniques are at the core of numerous advanced technologies, playing a critical role in fields such as automotive radar and medical imaging. These sensor arrays consist of multiple individual elements that actively emit signals and capture the reflected waves (sound or light) to obtain accurate representations of the scenery. The culmination of many sensory signals leads to massive data rates and corresponding challenges [1–3]. These systems are required to provide high-resolution and real-time imaging, all while dealing with interference, noise and a changing environment.
Many of the challenges faced in array sensing can be effectively reformulated as inverse problems, which seek to estimate unknown parameters from observations. In the context of array sensing, this typically means reconstructing images or (distance, velocity or angular) measures from the raw data captured by the sensors. However, due to the underdetermined nature of these inverse problems, strong priors and knowledge of the underlying processes at hand are key for reliable reconstructions. This necessitates advanced modelling techniques that extract and capture meaningful information from the raw sensory data.
Recent advances in deep generative models (DGMs) have shown great potential in solving problems with high-dimensional data by learning and exploiting the data manifold in domains ranging from medical imaging [4], computer vision [5] and natural language processing [6]. Specifically, they seek to model the distribution of data and subsequently sample from it, which can serve as a signal prior and aid in the inverse problem solving. However, applying these techniques directly to raw sensory data presents additional challenges due to the high dynamic range (HDR) and rapid data acquisition rates, which impose stringent requirements on latency and throughput, further complicating the use of DGMs. Consequently, these challenges necessitate the development of tailored techniques involving generative models that effectively manage the unique characteristics of sensory data while adhering to the requirements of high-rate real-time sensing applications.
In this article, we review ongoing work in application of DGMs to sensory data. We start with some background on sensing applications, DGMs and finally Bayesian inference with DGMs in §2. Then, in §§3 and 4, respectively, we discuss the two main challenges, namely, model mismatches and real-time inference. In both of these sections, we discuss methods that mitigate these challenges, ranging from improved forward models with the use of DGMs, to accelerated inference techniques through approaches such as deep unfolding, temporal inference and active compressed sensing.
Background
Sensing applications
(a)
Many sensor modalities, such as medical imaging and radar sensing, share a common objective, namely, the measurement of an unknown channel impulse response. These channels are often deeply complex, with signals exhibiting significant dynamic range variations in combination with high sample rates. These characteristics of sensory data challenge accurate signal recovery. For instance, in both ultrasound imaging and radar, the generative model of the sensory data is not exactly known due to the highly variable reflectivity of objects within the sensor’s line of sight and the presence of multipath propagation. Extracting a signal-of-interest from raw data is a challenging task for existing model-based techniques, e.g. due to the lack of modelling capacity, non-Gaussian (structured) noise or other undesirable sensing phenomena such as interference or aberration. Another challenge faced when dealing with sensory data is high data rates, for example in real-time imaging applications. Compressed sensing (CS) [7–10] has emerged as a powerful technique for reducing data rates by compressing the size of measurement vector necessary to recover the signal-of-interest , through intelligent design of the sensing matrix and exploitation of known signal statistics. A common application of CS is via subsampling, which aims to recover the full signal-of-interest from a subset of possible measurements, typically fewer than required by the Nyquist–Shannon theorem. This has been successfully applied to reducing data rates in many domains, such as ultrasound imaging [11–13], radar [14,15] and magnetic resonance imaging (MRI) [16].
Throughout this work, we refer to the following forward model:
where the observations are contaminated with structured noise and thermal noise , respectively. The thermal noise is assumed to be additive white Gaussian noise (AWGN), i.e. where represents its variance. In contrast, structured noise encapsulates all model errors (mismatch), including possibly nonlinear effects, distortions and multipath components in the observations . The nature of depends on the sensing scenario. In some applications, may be independent of , such as structured interference from external sources, commonly encountered in automotive applications of radar. However, in other scenarios, such as diffraction or multipath scattering in ultrasound imaging, is inherently a function of , e.g. . Explicitly modelling (and performing inference on) the true forward physics model of is often challenging. Given the complexity of capturing potential dependencies between and , we assume independence, i.e. and instead learn the marginal distribution in a fully data-driven fashion, as discussed in §3.
For our goal of inferring the underlying signal-of-interest from observations , we make use of the forward model in equation (2.1) combined with statistical priors. To establish these priors, we resort to deep learning (DL), which has been proven to be effective for tasks that require accurate statistical models learned from the data itself. While black-box approaches often fail when the trained networks are subjected to out-of-distribution data [17], recently, DGMs have shown exceptional capabilities when used in conjunction with Bayesian theory. By conditioning the generative process on observations, DGMs provide a robust framework for solving inverse problems, such as signal recovery in the presence of structured noise.
In the following, we provide a brief introduction to DGMs and their role in posterior sampling. We then highlight their growing use in various sensing applications, demonstrating their potential to enhance the accuracy and robustness of signal recovery in these challenging environments.
Deep generative models
(b)
Generative models try to understand and model the underlying distribution of data and have an effective way of sampling new data points from this distribution. DGMs are a class of generative models that have specifically gained traction due to their ability to model high-dimensional data. At the core of DGMs are general parameterized function approximators, usually neural networks. These networks are trained on many examples from a training dataset, representing the data distribution. DGMs are able to effectively capture the structure of the data manifold as they leverage the property that all data points lie on a lower-dimensional manifold embedded in the high-dimensional data space [18].
Nonetheless, modelling distributions with DGMs poses several challenges. Probability density functions are constrained to be non-negative and integrate to one, which limits the choice of neural architectures. Variational autoencoders [19] circumvent the intractability of density estimation by approximating it with a variational lower bound. Generative adversarial networks (GANs) [20] are another class of DGMs that learn the data distribution implicitly through an adversarial objective. Normalizing flows [21] take a different approach altogether by transforming a simple base distribution into the target distribution through a series of invertible transformations.
Here, we focus on a more recent development in the field of DGMs, namely, diffusion models (DMs). These models indirectly model the underlying distribution through the score function , which is the gradient of the probability density function with respect to the data itself. Unlike likelihood-based methods, this circumvents the need of directly modelling the probability density function. Furthermore, it leads to an interpretable denoising score-matching objective, which allows us to parameterize the score function with any neural network and train it as follows:
This effectively results in a function that points back towards the data manifold and can be used to sample from the data distribution . DMs model this sampling procedure through the reversal of a corruption process, also known as forward diffusion, which progressively adds increasing levels of AWGN until the sample is completely transformed from the original data distribution to a Gaussian noise sample , with diffusion time . This continuous forward process can be formalized using a stochastic differential equation (SDE):
where is a standard Wiener process, and are the drift and diffusion coefficients, which contribute to the deterministic and stochastic aspects of the SDE, respectively. Naturally, we are interested in the reversal of this process, which leads to the reverse diffusion process which has shown to result in a reverse-time SDE as follows [22]:
where and are now processes running backwards in diffusion time. Conveniently, the score function emerges from this reverse diffusion process and can accordingly be substituted with the learned score model from equation (2.2) to gradually remove noise and sample from . Moreover, to facilitate the training process, the score model is conditioned on the diffusion time step , resulting in a in a noise conditional score network which is able to jointly evaluate the score of all perturbed data distributions [23].
Posterior sampling
(c)
To reconstruct corrupted or incomplete incoming sensory data, according to equation (2.1), using generative models, we resort to a probabilistic framework with DGMs serving as foundation for inferring the underlying data. The act of posterior sampling centres around the idea of incorporating both prior information with incoming observations according to Bayes’ rule. Many posterior sampling algorithms have been proposed for various generative modelling architectures, for example the conditional Wasserstein GAN [24]. Here, however, we focus on posterior sampling with DMs to provide the necessary background for the methods to follow.
As DMs generate samples using gradients of probability density functions, we start by using Bayes’ rule to formulate the posterior score function:
This expression factorizes the posterior distribution into a prior distribution which we model with DGMs and a likelihood term, which is a known distribution given our understanding of the physical acquisition process of the observed sensory data , capturing how the true signal is corrupted by factors such as sensor noise, distortions and resolution limits. To achieve posterior sampling with pre-trained DMs, one can substitute the score function in equation (2.4) with the factorization of equation (2.5) leading to a conditional reverse-time diffusion process. The posterior score is then approximated as .
Unfortunately, the structured noise-perturbed likelihood is intractable, in contrast to the noiseless case . Various posterior sampling methods for DMs have been proposed to estimate this quantity [25–27]. A widely used approach is diffusion posterior sampling (DPS) [28], which leverages the posterior mean that is derived via first-order Tweedie’s [29]:
where represents the one-step denoising from diffusion step . The first approximation corresponds to the minimum mean-squared-error (MMSE) estimator for [30], while the second substitutes the score function with the trained noise conditional score network. Furthermore, we reparameterize the SDE in equation (2.3) using signal and noise rates, and , which can be derived from the noise scheduling , [22], as with . Finally, we approximate a tractable posterior score, by starting from equation (2.5) and substituting the approximate gradient of the log likelihood using equation (2.7) as follows:
The exact implementation of this posterior sampling framework varies based on the specific application. To illustrate this, we provide examples from ultrasound, radar and MRI in the following sections.
Model mismatch
Model mismatch is a critical challenge in inverse problems involving real-world sensory data, where the assumed forward model deviates from the actual, often more complex, data acquisition process. While we often assume a known and accurate forward process as described in equation (2.1), this assumption rarely holds in practice.
DGMs have demonstrated strong performance in inverse problems when the forward model is fully known. However, in sensory data, the acquisition process often involves unknown propagation effects such as multi-path scattering, or sensor-specific distortions; factors that are difficult to capture directly with a simple forward model or to learn directly from data using DGMs.
To close this gap, we discuss several key approaches. First, in §3a, we examine the concept of structured noise, where model errors are explicitly captured with a DGM, relaxing the reliance on a perfectly known forward model. Second, in §3b, we address the challenge posed by the HDR of raw sensory data, which can complicate the training and application of generative models. Finally, in §3c, we incorporate model-based score functions that leverage prior knowledge about the signal or sensing physics, enabling more robust guidance during inference. Throughout this section, the practical application of these concepts will be illustrated through two detailed examples in the domains of ultrasound imaging and automotive radar.
Structured noise
(a)
One approach to dealing with model mismatch and other sensing and imaging artifacts is to model these error terms as structured noise. Logically, the structured noise cannot be captured using parametric probability distributions (such as Gaussian). Therefore, we resort to DGMs to learn its structure from data. This approach can effectively mitigate model mismatch in ultrasound and radar applications as we show in the following section.
For radar interference mitigation and multipath dehazing, similar source separation techniques have been applied through the use of joint posterior sampling using DGMs [31,32]. The ill-posed problems are tackled by introducing two parallel generative processes that are conditioned on to create a joint posterior sampling process using DMs [33]. Using Bayes’ rule, samples are drawn from the joint posterior distribution to obtain estimates of both signal and structured noise components, and :
where is the likelihood according to our measurement model in equation (2.1) and and are prior distributions that can be modelled using score-based DMs with the objective in equation (2.2). The parallel posterior sampling (for both signal and structured noise components) is achieved by extension of equation (2.4), through substitution of the score with the score of the joint posterior distribution. This results in the coupled diffusion process described by the following reverse-time SDE:
We can again factorize the joint posterior using Bayes’ rule for scores as follows:
From this factorization, it follows that each separate reverse diffusion process (for both signal and structured noise) is entangled through the shared joint likelihood term . The prior score of the signal component can be either learned using a DM or have an analytical prior such as sparsity. The structured noise score is additionally learned using a separate DM due to its complex nature. Figure 1 provides a geometric overview of the method. For a detailed description of the algorithm, we refer the reader to [33]. In the following sections, we illustrate the practical application of these techniques addressing model mismatch, focusing on two major problems in the context of different sensing applications: ultrasound multipath scattering and radar interference.
Overview of the proposed joint posterior sampling method for removing structured noise using DMs. During the sampling process, the solutions for both signal and structured noise move towards their respective data manifold M through the score functions. At the same time, the data consistency term derived from the joint likelihood p(y|xτ,nτ) ensures solutions that are in line with the (structured) noisy measurements. Figure adopted from [33].
Example 1: ultrasound multipath scattering
(i)
Throughout this review, we will highlight several applications, demonstrating key techniques enabling the use of DGMs on sensory data. Each example is introduced with an information box, explicitly specifying the forward model and how DGM is applied within the given context. Moreover, a short overview of data rates and sizes is provided to offer insight into the variability and characteristics of different types of sensory data.
The first application we discuss is ultrasound imaging, a widely used modality in medical diagnostics due to its non-invasive and real-time nature. See Box 1 for a general overview of the application. Through the transmittance of high-frequency sound waves into the body, internal tissue structures can be reconstructed from the backscattered echoes. However, ultrasound signals are subject to a range of different noise sources that clutter the image and limit interpretability. One of the major origins for loss in image quality is caused by multipath scattering amidst layers of skin, fat and muscle between the transducer and the tissue being examined. These multipath reflections amount to a haze-like appearance on the image, dubbed simply haze. Specifically, cardiac ultrasound is sensitive to haze due to the small transducer footprint and the addition of the ribs in line of sight of the probe. To suppress the multipath clutter and retrieve the direct path contribution from the measured ultrasound signals we consider the forward model in equation (2.1) and explicitly model both components separately with DMs [32,33]. For this purpose, we perform denoising score matching, see equation (2.2), on (unpaired) training data samples of clean ultrasound , and multipath haze recordings to learn two separate score functions, conditioned on the diffusion time step :
Box 1Application: ultrasound imaging Data characteristics: A typical ultrasound probe comprises hundreds of individual transducer elements, each of which operates at sampling frequencies at the Nyquist rate, typically in the range of tens of megahertz (MHz), leading to fast-time samples per receive channel . Depending on the transmit sequence (focused, diverging wave, plane wave) several hundreds slow-time sequences are acquired. In regular two-dimensional (2D) brightness mode (B-Mode) imaging, at least several tens of frames per second can be expected, leading to raw data rates that can quickly amount to several hundreds or thousands gigabits per second (Gbit/s) . This problem is exaggerated in three-dimensional (3D) ultrasound, where matrix probes consist of thousands of elements [34]. Forward model: is the observed (and hazy) beamformed radio-frequency (RF) data; is the clean beamformed RF data with the same dimensions, but only containing the direct path contributions. All clutter and multipath components are modelled through structured noise component using a separate DGM. Application of DGMs: As both signal and haze contributions in the beamformed RF data are highly structured, DGMs can be fitted to both of these components.
Note that paired data of clean and hazy samples is not required to train these two generative models. This greatly reduces the difficulty of creating suitable datasets, as the structured noise can be acquired in isolation or simulated. See [32] for more details on the curation of the cardiac haze dataset. Moreover, learning each distribution with separate DGMs is more robust compared to a supervised method on paired data. The latter approach struggles with generalization due to the variability in paired samples and potential to overfit to specific instances of noise [32]. During inference, the two trained DGMs can be deployed within the joint-posterior sampling framework as seen in equations (3.3) and (3.4). The effect of a learned noise prior, compared to a traditional Gaussian prior on the problem of dehazing medical ultrasound data is illustrated in figure 2. The learned prior yields improved contrast and clearer structural details, whereas the Gaussian prior leaves residual noise with structured components, suggesting it inadvertently suppresses parts of the underlying signal.
Comparison between a structured noise DGM prior and a Gaussian prior for the task of dehazing in-vivo medical ultrasound data. Posterior estimates of the signal x^ and noise (haze) n^ are shown for each method, alongside corresponding gCNR [35] ( ↑ ) values, highlighting the improved performance of the structured noise prior. Figure adopted from [33].
High dynamic range
(b)
Unlike natural images, which typically have a relatively narrow range of pixel intensities, raw RF data in sensor applications often exhibits an HDR, meaning that the signal amplitudes can vary drastically, see figure 3. Besides these imposing constraints on the hardware side, requiring HDR analog-to-digital converters [36], this also presents challenges when training generative models such as DMs. The wide range of intensities can lead to numerical instability, with gradients either exploding or vanishing, and can cause the network to focus disproportionately on the stronger signals while neglecting weaker, yet important, components. In [32], the HDR of ultrasound signals is addressed through transformation of the RF data using a technique known as companding. This is an invertible operation that can compress and expand the dynamic range of a signal as follows:
(Left) RF signals and their companded versions, where the μ value is adjusted to align the distribution with that of typical image pixel intensities. (Right) Histogram comparison of RF, companded RF, and ultrasound image data, illustrating the HDR nature of RF signals. Naturally, the companded RF data exhibits a distribution more closely resembling that of image-domain data, facilitating more stable and effective training of DGMs. Figure taken from [32].
with , and where is a parameter that determines the amount of compression applied. This ultimately leads to the following likelihood score:
which can be used in combination with the two priors in equation (3.5) modelled with diffusion networks and to perform joint posterior sampling according to the framework in equation (3.2). Note that we use Tweedie’s formula from equation (2.7) to approximate equation (3.7) and introduce to group the constants as a result of the derivation of the data consistency term equation (3.8). These exact steps, including the companding technique, were used to generate the dehazed ultrasound images shown in figure 2.
Example 2: radar interference
(i)
As a second case study, we consider the growing problem of mutual interference in automotive radar, a domain where model mismatch arises from unpredictable signal interactions in increasingly congested environments. Mutual interference is becoming a major challenge in the automotive radar scene as more vehicles are being equipped with radar sensors, resulting in resource scarcity, i.e. time, frequency and space [37]. Although the de facto waveform currently implemented by the sensor manufacturers is a frequency-modulated continuous wave, whose chirp-like signals linearly increase or decrease its carrier frequency over time, there is currently no standardization present, leading to a free-for-all situation. A broad range of transmission schemes have been developed and implemented over time, i.e. up-down chirps, stepped-frequency and frequency-coded waveforms [38,39], resulting in a large variety of radar signals that can interfere with a victim radar. For more information see Box 2. This diversity burdens interference removal, causing simple existing mitigation strategies to become less effective. Model-based solutions [40], supervised neural networks [41–44] and model-based DL methods [45,46] have been proposed for interference removal. DGMs can learn a large variety of waveforms from training data to effectively remove interference signals; one implementation using posterior sampling is elaborated on below.
Box 2Application: radar Data characteristics: Every radar is required, as defined in ISO standards, to send updates to the car of the objects present in the sensing environment (typically every 40−100 ms, which includes the sensing time and the processing time of all downstream tasks). Therefore, real-time constraints are put on signal processing and deep learning solutions, such as interference mitigation, direction of arrival estimation, etc. Data rates in automotive radar can range from hundreds of Gbit/s to tens of Gbit/s, where a typical 3D fast-time data cube comprises receive channels, slow-time samples and fast-time samples. With the recent trend towards high-resolution automotive radars, data cubes can for example grow towards , putting more stringent requirements on data rates, memory and computational load in the post-processing stages. Forward model: is the observed interfered signal, is the complex-valued sparse signal containing the range information to all object reflections, and and are the interference-only signal and thermal noise, respectively, in the same domain as . Therefore, we consider the following forward model: , where we are interested in separating and from using a DGM. Application of DGMs: To mitigate interference, we use a model-based and data-driven score-based DGM to obtain estimates of and , respectively. It is applied using only fast-time samples, for all channels and slow-time samples independently.
Generally, radar-to-radar interference mitigation occurs on the raw data directly, i.e. fast-time data, prior to any post-processing to avoid the interference from leaking into the other dimensions. Therefore, radar interference can be seen as structured noise, in equation (2.1) and leads to model mismatch with the interference being uncorrelated or correlated, ultimately reducing the radar’s sensitivity or creating false positive detections. The authors in [31] have used DGMs by applying score-based diffusion for solving equations (3.3) and (3.4) to separate the target reflections and interference signals from the observation .
Model-based score function
(c)
In contrast to §3a, where two score functions are approximated using deep neural networks (see equation (3.5)), specific signal properties, e.g. sparsity, can be inferred using model-based priors throughout the diffusion process to reduce complexity. As radar signals are known to be sparse in the range, Doppler and angular domain, the authors of [31] exploit this domain knowledge in a model-based prior. Instead of having a deep neural network for approximating the score, , as defined in equation (3.5), an analytical model-based score function is calculated by rewriting equation (2.7) using Tweedie’s approach. Then, the score function for the target signals at time step can be analytically defined as
where denotes the posterior mean, which the authors opt to obtain using the following -norm minimization by promoting sparsity in :
Formally speaking, this is known as a denoising step that is readily implemented using soft thresholding as shown in equation (3.11) with being time step-dependent. Additional benefits are that complex-valued score functions are avoided, which are generally hard to implement.
Furthermore, the authors have opted for a data-driven approach for approximating the interference score function , for which the network has been trained using the denoising score-matching objective of equation (2.2). As explained earlier, the structured noise of the interference signals is challenging to analytically model due to its large waveform diversity, hence the use of conditional DGMs is favourable due to its generative ability. The distribution of the interference signals is learned in the raw data format directly.
Under the guidance of the likelihood scores, using DPS, estimates of the targets and interference signals and are obtained using the joint posterior scores, equations (3.3) and (3.4), respectively:
In figure 4, the interference mitigation capabilities are shown for DGMs in a single target scenario for which a large part of the raw data is recovered from interference as shown in figure 4a, resulting in a reduced interference-induced noise-floor in figure 4b. Next, we explain how the methods of Examples 1 and 2 can be accelerated to enable the application of DGMs for real-time ultrasound probing and radar sensing.
A semi-correlated interference scenario where a large portion of the raw data is contaminated, for which the capabilities of DGMs are shown. Figure taken from [31].
Real-time and high-data rates
In addition to complex noise sources that cause model mismatches and impede image quality, excessive data rates and real-time conditions in sensor systems are another stringent requirement that incentivize efficient sensing and inference algorithms. Nevertheless, while extremely effective, DGMs are not generally known for their inference speed. In this section, we discuss methods that either address this issue through development of accelerated methods that leverage DGMs in some way (§4a), or try to reduce data rates through active CS (§4b).
Acceleration
(a)
To bridge the gap between real-time inference of DGMs and high data rates of sensing applications, our initial focus will be on acceleration of current methods. To maximize throughput in applications with high data rates, efficient inference using DGMs is essential. Specifically, we discuss temporal inference (§4a(i)), deep unfolding (§4a(ii)) and knowledge distillation (§4a(iii)).
Temporal inference
(i)
The sequential and real-time nature of sensory applications can be both a blessing and curse. While indeed the high throughput of data requires low-latency inference, the temporal axis can be exploited to accelerate inference and even improve reconstruction of the raw sensory signals. One way to accelerate posterior sampling methods using DMs as discussed in §2c is to initialize a given diffusion trajectory conditioned on previous frames, effectively reducing the number of diffusion iterations necessary [47]. Formally, given a set of diffusion posterior samples of previous frames we would like to estimate with some transition model (such as a Convolutional LSTM (ConvLSTM) or Video Vision Transformer (ViViT)) such that the number of diffusion steps necessary is minimized with . Rather than starting each diffusion trajectory from scratch at with a Gaussian sample , we use an appropriate estimate based on past observations which we diffuse forward up to which leads to initialization of a shortened diffusion trajectory: . As shown in [47], this reduces inference times for cardiac ultrasound imaging using DMs by a factor of 25. Although in this case represents B-mode images, applying sequential posterior sampling to raw sensory data could offer even greater advantages, which we consider an intriguing direction for future work.
Deep unfolding
(ii)
Deep unfolding (or deep unrolling) is a method that utilizes iterative model-based algorithms, such as proximal-gradient methods, in combination with neural networks to solve inverse problems. By unrolling the iterative optimization algorithm as a feed-forward network, it takes the structure of the iterations and allows for learning the parameters of the algorithm in successive steps. This will essentially apply multiple iterations in a single forward pass, thus accelerating the iterative algorithm at the cost of higher memory usage. Deep unfolding has been used in many real-world inverse problems such as sparse-coding [48], sub-Nyquist sampling [49] and medical imaging [50] but typically rely on discriminative networks. While there are prior works that combine deep unfolding with generative models [51,52], there are none for high-data-rate sensing applications, which could be a fruitful avenue to explore.
Knowledge distillation
(iii)
Another powerful method to decrease inference time for efficient inference of DGMs is knowledge distillation, in which a new student model is trained to produce the same outputs as the original generative model using orders of magnitude fewer parameters. Knowledge distillation has been successfully applied to accelerate inference with both GANs [53] and DMs [54], among other architectures.
Active CS
(b)
While DGMs have been shown to produce excellent solutions to highly ill-posed CS problems in many domains, e.g. medical imaging [55,56], we focus here on active CS using generative models. Active CS [57] aims to sequentially design the sensing matrix in real-time as the measurements are acquired, further compressing the required measurement vector and therefore of particular interest in applications with high data rates. Active CS algorithms are considered ‘active’ in the sense that they iteratively choose which measurements to acquire next based on the measurements they have observed so far. In the case of subsampling, for example, this involves choosing which measurement locations, e.g. pixels, time instances, antennas or other degrees-of-freedom, to sample to optimally reconstruct . Active CS has a long history in various sensory applications, with existing works commonly using supervised DL [58] and reinforcement learning [59,60] to choose sampling locations. In the following, we review a number of recently proposed approaches to active CS using DGMs to jointly guide sampling and reconstruct target signals. In each case, the goal is to minimize uncertainty about , as measured by some uncertainty estimate derived from a set of posterior samples generated by the DGM. A challenging aspect in this paradigm is estimating the decrease in uncertainty that will result from choosing a particular sensing design, leading to a variety of distributional and parametric assumptions in the methods discussed.
Sanchez et al. [61] propose generative adaptive sampling, a method for active subsampling in which the regions of the measurement signal with the highest predicted variance are sampled next. This variance is computed by generating posterior samples of the full target signal and passing them through the measurement model to generate samples of the full measurement signal at time , yielding . The sample variance of this distribution over measurements can thus be computed directly from the posterior samples . The pixel or set of pixels maximizing this variance is then sampled at time , and the algorithm repeats. Note that, because the measurement noise is independent of the sampling location, choosing to sample the measurement location with the highest entropy will result in minimizing uncertainty about [62]. Variance is, however, only proportional to the entropy under certain distributional assumptions, e.g. isotropic Gaussian. Despite this assumption, generative adaptive sampling proves to significantly outperform variable-density sampling in reconstructing MNIST images using a Wasserstein GAN [63] as the DGM.
Van de Camp et al. [62] follow a similar approach to active subsampling, instead proposing the use of a Gaussian mixture model (GMM) to approximate the measurement posterior, i.e. , where is the number of posterior samples. The measurement locations with maximum entropy are then selected to be sampled next, estimating the GMM entropy via an approximation introduced by [64]. This entropy approximation is a function of the L2 distances between pixels across all pairs of posterior samples, leading to regions with high ‘disagreement’ among samples being assigned high entropy. Van de Camp et al. validate their sampling pipeline using two combinations of generative modelling architecture and posterior sampling technique to sample from . In particular, they use (i) a variational autoencoder trained on MNIST [65] images, with Markov chain Monte Carlo used to produce posterior samples in the latent space, which are decoded to generate full measurement samples , and (ii) a GAN trained on MRI images from the fastMRI [1] dataset, with annealed Langevin dynamics [23] for posterior sampling.
Elata et al. [66] propose AdaSense, an adaptive CS method using a diffusion restoration model [67] for posterior sampling. They propose using the mean squared error attained by the linear MMSE predictor as a measure of uncertainty. In the case where the values in can be freely designed, AdaSense uses the principle components of the posterior covariance as the rows of , leveraging that the principle components of the data covariance produce the linear MMSE predictor, thus minimizing uncertainty about . The algorithm proceeds iteratively by acquiring measurements using , generating new posterior samples, and then adding the top principles components as new rows to , and repeating. Low values for then result in highly adaptive sampling, and vice versa for higher values. In many real-world applications, however, is constrained by the measurement process and may not be freely designed. In these cases, AdaSense incorporates a new objective, aiming to minimize the linear MMSE when is constrained to a set of possible sensing matrices , leading to the objective . Here, is the Moore–Penrose pseudo-inverse of . For example, in MRI acceleration, the set might consist of all possible next masks, where each next mask adds a new k-space line. AdaSense is validated on MRI acceleration and natural image reconstruction tasks.
A limiting factor that is faced when using DMs to perform active sampling is the number of neural function evaluations necessary to perform posterior sampling, due to the iterative nature of the reverse diffusion process. This may be in the range of hundreds to thousands for high-quality image generation. Running an entire reverse diffusion process for each active sampling step may thus be infeasible for applications with high sampling rates. Nolan et al. [68] address this problem with active diffusion subsampling (ADS), which performs active sampling steps in a single reverse diffusion process consisting of steps, resulting in a significant speedup for applications with large . ADS uses DPS [28] as its posterior sampling engine, tracking an estimate of the posterior throughout the reverse diffusion process, and using it to select new measurement locations as it goes. This estimate of the posterior is computed using a set of partially denoised samples at reverse diffusion step , from which fully denoised samples are computed via Tweedie’s formula. ADS uses the GMM-based approximation for proposed by Van de Camp et al. [62] to select maximum entropy sampling locations, validating the method on MRI acceleration as well as natural image subsampling.
Example 3: Accelerated MRI
(i)
As the final application, we consider accelerated MRI, a well-established use case for active CS. For more context, see Box 3. Due to the relatively slow acquisition time in MRI, inference time for popular DGM architectures falls within real-time ranges, particularly when leveraging estimates of the posterior as in ADS or fast sampling algorithms such as the diffusion restoration model as in AdaSense. The active CS methods thus iteratively acquire k-space lines and update the subsampling matrix so as to select maximally informative next measurements, leading finally to a posterior distribution over fully reconstructed MRI images given the entire set of acquired measurements. This process is illustrated in figure 5.
Box 3Application:MRI Data characteristics: Of particular relevance regarding the data rate in MRI is the repetition time (TR), which measures the amount of time between successive pulse sequences on the same slice, and therefore determines the acquisition time for a single MRI slice. TR tends to range from hundreds to thousands of milliseconds. In the popular fastMRI [1], for example, knee slices are acquired using TRs in the range 2200−3000 ms. Forward model: A typical MRI scan images a 3D volume consisting of a set of stacked 2D slices. MRI measurements are taken in the Fourier-space representation of the image, referred to as the k-space, following the model , where is measurement noise, is the target image, and are the k-space measurements; k-space measurements are typically acquired by a series of pulse sequences for each slice, each of which provides a single line of points in the k-space. Given a full set of these k-space lines, the image can be recovered by the inverse Fourier transform. In accelerated MRI, the k-space lines are subsampled, leading to the model , where are the measurements selected until time by subsampling matrix , i.e. , with the goal of reconstructing image . Application of DGMs: For MRI reconstruction DGMs are typically fit on fully observed target images . The DGM may, for example, be fitted on complex-valued images [68], real images with a zeroed imaginary component [66], or other variants [58]. Then, given such a DGM, posterior sampling algorithms may be employed to recover full images from a subsampled k-space .
Illustrative example of an active CS step for MRI acceleration. The sensing matrix A=UF consists of a subsampling matrix U and DFT matrix F . See fastMRI [1] for more information about MRI acceleration.
It remains an open challenge to accelerate such methods further to achieve real-time active CS in domains with shorter acquisition times, such as ultrasound imaging, which may require a posterior inference time on the order of tens of milliseconds. However, with a combination of algorithmic and hardware advancements, this may soon be achievable.
Conclusion
DGMs are increasingly used to tackle problems involving high-dimensional data. However, their integration with active array sensing applications poses unique challenges due to the need for real-time processing of the complex and dynamic nature of sensory data. Despite these hurdles, the potential gains of using of DGMs to enhance signal reconstruction by accurately modelling the underlying sensory data is significant. In this work, we highlight several works that aspire to close the gap between current DGM capabilities and the demanding requirements of sensing applications, with the focus on two key areas: mitigating model mismatch through modelling of structured noise and addressing high-data rates and real-time processing through reduced inference times and active CS techniques. To this end, we showcase several illustrative applications that effectively apply DGMs for relevant problems in the domains of medical imaging and automotive radar. While the methods discussed in this review make substantial progress towards enabling real-time inference with DGMs, significant challenges remain in addressing the complexities of sensory data. Notably, applications involving extremely high data rates, such as 3D ultrasound and real-time radar systems, are not yet fully explored. To avoid a latency increase in the aforementioned real-time sensing applications, future work should optimize current methods by finding a balance between the powerful modelling capabilities of DGMs and the deployed acceleration techniques.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zbontar J et al . 2018 fast MRI: an open dataset and benchmarks for accelerated MRI. ar Xiv. (10.48550/ar Xiv.1811.08839) · doi ↗
- 2Sloun RJ , Cohen R , Eldar YC . 2019 Deep learning in ultrasound imaging. In Proceedings of the IEEE, vol. 108 , pp. 11–29, IEEE.
- 3Doris K , Filippi A , Jansen F . 2022 Reframing Fast-Chirp FMCW transceivers for future automotive radar: the pathway to higher resolution. IEEE Solid State Circuits Mag. 14 , 44–55. (10.1109/mssc.2022.3167344) · doi ↗
- 4Chung H , Ye JC . 2022 Score-based diffusion models for accelerated MRI. Med. Image Anal. 80 , 102479. (10.1016/j.media.2022.102479)35696876 · doi ↗ · pubmed ↗
- 5Rombach R , Blattmann A , Lorenz D , Esser P , Ommer B . 2022 High-resolution image synthesis with latent diffusion models. In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, pp. 10684–10695. IEEE. (10.1109/CVPR 52688.2022.01042) · doi ↗
- 6Dubey A et al . 2024 The llama 3 herd of models. ar Xiv. (10.48550/ar Xiv.2407.21783) · doi ↗
- 7Candes EJ , Tao T . 2006 Near-optimal signal recovery from random projections: universal encoding strategies? IEEE Trans. Inf. Theory 52 , 5406–5425. (10.1109/tit.2006.885507) · doi ↗
- 8Eldar YC , Kutyniok G . 2012 Compressed sensing: theory and applications. Cambridge, UK: Cambridge University Press.