The impact of updated imaging software on the performance of machine learning models for breast cancer diagnosis: a multi-center, retrospective study
Lie Cai, Michael Golatta, Chris Sidey-Gibbons, Richard G. Barr, André Pfob

TL;DR
This study shows that updated imaging software can improve the performance of some machine learning models in diagnosing breast cancer.
Contribution
The study evaluates how updated imaging software affects machine learning models' performance in breast cancer diagnosis using multi-center data.
Findings
GLM and XGBoost models performed better with updated software data compared to original data.
MARS model showed worse performance with updated software data.
SVM model was not calibrated in the study.
Abstract
Artificial Intelligence models based on medical (imaging) data are increasingly developed. However, the imaging software on which the original data is generated is frequently updated. The impact of updated imaging software on the performance of AI models is unclear. We aimed to develop machine learning models using shear wave elastography (SWE) data to identify malignant breast lesions and to test the models’ generalizability by validating them on external data generated by both the original updated software versions. We developed and validated different machine learning models (GLM, MARS, XGBoost, SVM) using multicenter, international SWE data (NCT 02638935) using tenfold cross-validation. Findings were compared to the histopathologic evaluation of the biopsy specimen or 2-year follow-up. The outcome measure was the area under the curve (AUROC). We included 1288 cases in the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
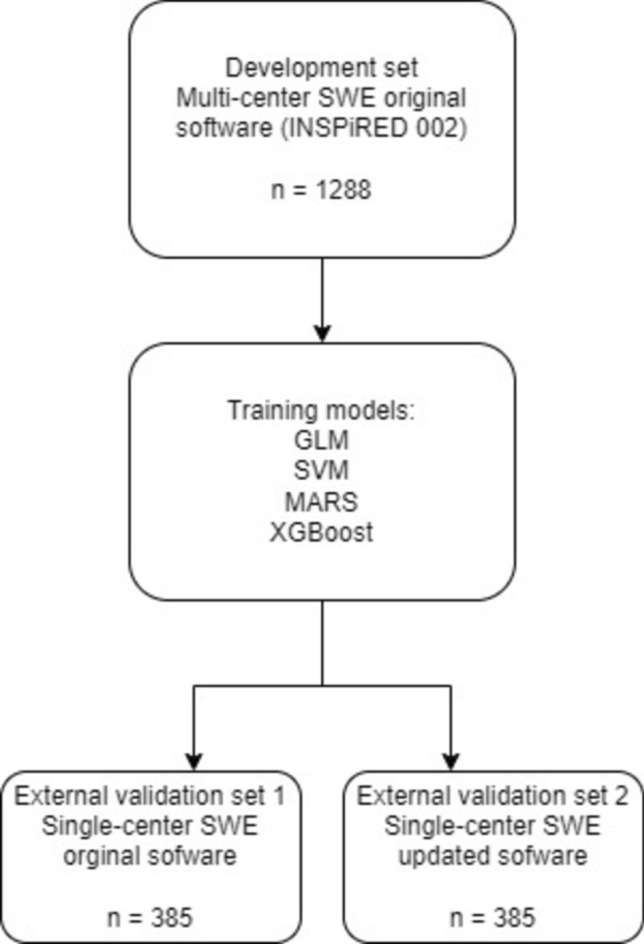 Figure 1
Figure 1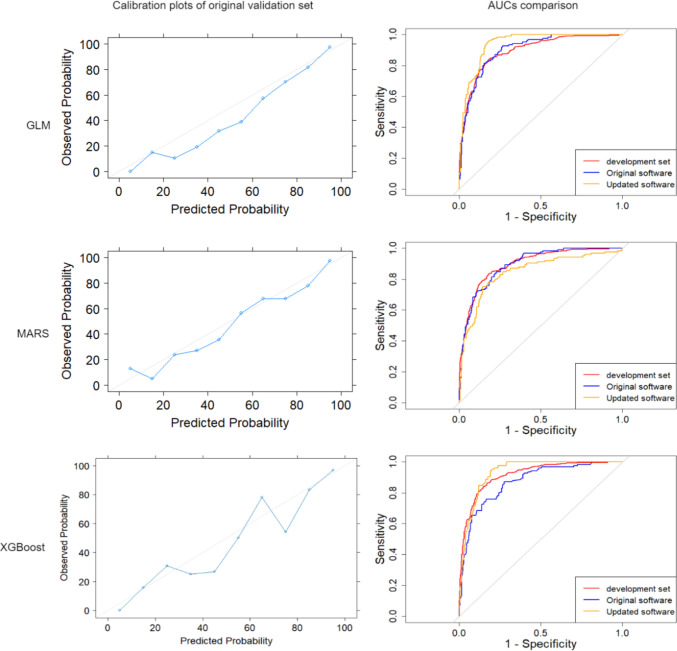 Figure 2
Figure 2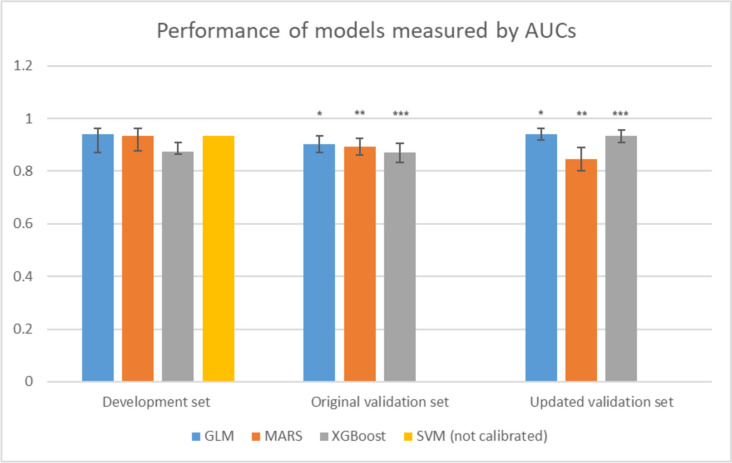 Figure 3
Figure 3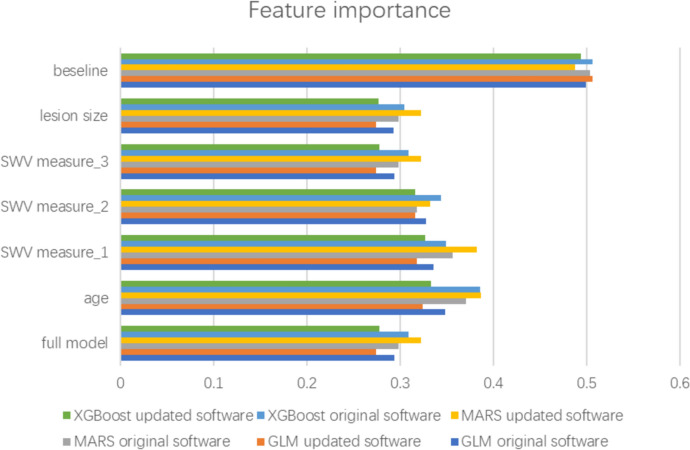 Figure 4
Figure 4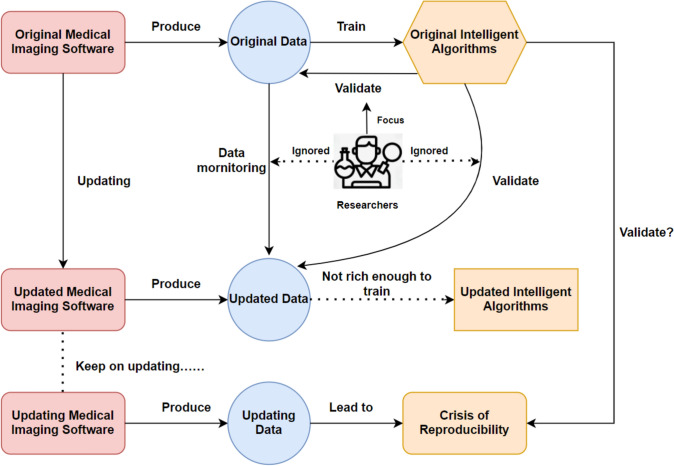 Figure 5
Figure 5- —HSO2 Fellowships
- —http://dx.doi.org/10.13039/100008658Deutsches Krebsforschungszentrum
- —Universitätsklinikum Heidelberg (8914)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsUltrasound Imaging and Elastography · AI in cancer detection · Radiomics and Machine Learning in Medical Imaging
What does this study add to the clinical work
When developing machine learning models using medical imaging data, the impact of data drift should be systematically evaluated to maintain model reliability over time. Some machine learning models demonstrated great potential to bridge the gap between original and updated software, whereas others exhibited weak generalizability.
Introduction
The U.S. Food and Drug Administration (FDA) has approved 692 artificial intelligence (AI) and machine learning (ML) algorithms (as of October 2023) [1]. AI has demonstrated great potential in medical diagnosis and treatment decision-making [2, 3]. However, the performance of robust AI models frequently decline, and in some cases, they fail during long-term prospective validation [4]. Beyond the classical limitations associated with these models, such as biases in data selection [5] and the lack of diversity in ethical and demographic representation [6], there exists a critical and often overlooked challenge that warrants further attention from researchers: while new AI imaging models are rapidly developed, the imaging software that generates the data is being updated frequently which may lead to data drift. However, the impact of updated imaging software on the performance of AI algorithms as well as the methods for monitoring such potential data drift is unclear [7].
Shear wave elastography (SWE) is an ultrasound technique measuring the stiffness of a mass to improve the diagnostic performance of B-mode ultrasound [8]. Recently, the FDA approved a new software for breast ultrasound SWE [9]. The new software generates substantially different data compared to the original software version, as it expands the range of shear wave velocity, which improves benign versus malignant lesion differentiation and the display of very stiff and very small breast lesions [9]. A previous study has shown that an intelligent SWE model based on imaging data generated by the old software can reliably classify breast lesions and reduce unnecessary biopsies [10]. Whether the performance of such models remains stable when using the new software version, is unknown.
We aimed to evaluate the impact of updated medical imaging software on data drift and the generalizability of AI models by developing machine learning models using the original SWE data to identify malignant breast lesions and validating them on external data generated by both the original and updated software versions.
Materials and methods
Study design
This multi-center, retrospective study was conducted in accordance with the Declaration of Helsinki and was approved by the Ethics Committee of Heidelberg University Medical Faculty.
In this study, we aimed to develop machine learning models using SWE data to identify malignant breast lesions and to test the models’ generalizability by validating them on external data generated by the original software version and an updated new software version. We used multi-center international SWE data (NCT 02638935) as the development set. Women aged 18 years or older who presented with a suspicious or indeterminate single breast mass of diameters between 0.5 and 5 cm in B-mode ultrasound from February 2016 to March 2019 were included in this study [10]. We used SWE data from a single-center study as the validation set. This observational study included patients scheduled for a screening or diagnostic breast ultrasound from April 25, 2019, to May 2, 2022 [9]. In the development set, shear wave velocity (SWV, in m/s) was measured three times consecutively by a board-certified physician using the original software at the area of highest SWV within the mass. In the validation set, SWV was measured two times using the original software and updated software separately by a board-certified physician. The third SWV measurement was generated by calculating the mean value of the previous two measurements.
Outcome and definitions
Pathological evaluation of the breast biopsy specimen or > 2-year follow-up served as the gold standard for the dignity of the breast masses. All malignant lesions were biopsy-proven.
Model construction and evaluation
For the algorithm development and reporting, we considered guidelines and best-practice papers on machine learning in medicine [11, 12], diagnostic tests [13], and multivariable prediction models [14]. A checklist informed by recent guidelines on machine learning in medicine is provided in the Data Supplement.
We chose logistic regression with the elastic net penalty (GLM), motivation, ability, role perceptions, and situational factors (MARS), support vector machine (SVM), and extreme gradient boosting (XGBoost) algorithms for model construction. tenfold cross-validation was used for the algorithm training and internal testing on the development dataset. A hypergrid search was performed to select the optimal hyperparameters for each algorithm. The area under the receiver operating characteristic curve (AUC) was considered the main measurement of model performance. Final models were then validated using the external validation set (Fig. 1).Fig. 1. Diagram of patient flow
We used the “DALEX” package in R to calculate the agnostic variable importance measure computed via permutation (e.g. computing the loss function for the full model and then computing randomized response variables’ loss function). We used decision curve analysis (DCA) to illustrate the benefits of the clinical application of the models [15]. Python (Version 3.11.5) and R (Version 4.3.1) were used for all analyses.
Statistical analysis
We performed a descriptive analysis to illustrate the distribution of the baseline characteristics of the development set and the external validation set. We used the Chi-square test for categorical data, and the *t *test for continuous data to compare differences in baseline characteristics between the development and validation set. We calculated AUC values and accompanying 95% CIs for the algorithms using 2000 bootstrap replicates stratified for the outcome variable (malignant and benign). The Venkatraman method tests were used to compare models’ performance [16]. Proportion test was used to compare the model’s diagnostic performance [17]. Calibration plots (observed vs. predicted probabilities) and Spiegelhalter’s Z statistics were used to evaluate model calibration [18, 19].
We considered p values < 0.05 to be statistically significant.
Results
Patient flow
We used an international, multicenter SWE study (NCT 02638935) [10] as the development set, which included 1288 patients and where data were obtained using the original imaging software. We used another single-center SWE study [9] as the external validation set, which included 385 patients and where data was obtained using both, the original software and the new updated software (Figs. 1, 2).Fig. 2. Models’ calibration plots of original software in the external validation set and AUC curves. AUC area under the curve, GLM logistic regression with elastic net penalty, MARS motivation, ability, role perceptions, situational factors, XGBoost extreme gradient boosting
Baseline characteristics
Of the 1288 patients in the development set, 28.6% (368 of 1288) had a malignant breast mass. In the external validation set. 32.2% (124 of 385) had a malignant breast mass. Patients in the external validation set were older (mean age, 54.81 vs. 46.49, p < 0.001) and had a larger lesion size (15.65 mm vs. 11.90 mm, p < 0.001) compared to the development set. The shear wave velocity measured in the external validation set was significantly different compared to the development set for both, the original software and the updated software (p < 0.001). Details regarding baseline clinical characteristics are shown in Table 1. Table 1. Baseline clinical characteristics comparison between the development set and external validation setCharacteristicsDevelopment set (n = 1288)Validation set (n = 385)pAge (SD)46.49 (16.05)54.81 (16.20) < 0.001Lesion, no. (%)0.169Malignant368 (28.6)124 (32.2)Benign920 (71.4)261 (67.8)Lesion size (SD)15.65 (7.31)11.90 (8.03) < 0.001Original softwarepUpdated softwarepShear Wave Velocity, measurement 1–m/s (SD)4.02 (2.08)2.95 (1.80) < 0.0014.80 (3.02) < 0.001Shear Wave Velocity, measurement 2–m/s (SD)4.04 (2.08)3.12 (1.80)5.06 (3.06)Shear Wave Velocity, measurement 3–m/s (SD)4.06 (2.15)3.03 (1.80)4.93 (3.04)SD standard deviation, SWV shear wave velocity*Statistical significance
Model calibration and performance
In the external validation set, the GLM and XGBoost models showed better performance using the updated software data compared to the original software data: AUC 0.941 (95% CI 0.917–0.961) vs. 0.902 (95% CI 0.872–0.933), p < 0.001, and AUC 0.934 (95% CI 0.909–0.956) vs. 0.872 (95% CI 0.833–0.906), p < 0.001). The MARS model showed worse performance using the updated software: AUC 0.847 (95% CI 0.802–0.890) vs. 0.894 (95% CI 0.862–0.924), p = 0.045) (Fig. 3).Fig. 3. Performance of models measured by AUCs. AUC area under the curve, GLM logistic regression with elastic net penalty, MARS motivation, ability, role perceptions, situational factors, XGBoost extreme gradient boosting, SVM support vector machine. *stands for statistical significance
Figure 2 shows the models’ calibration plots and AUC curves for the GLM, MARS, and XGBoost models. Spiegelhalter’s Z statistics showed that GLM (z = − 0.410, p = 0.341), MARS (z = 0.367, p = 0.357), and XGBoost (z = − 1.948, p = 0.026) were well-calibrated models, while SVM (z = 2.656, p = 0.004) was not calibrated (Figure S1). Of all well-calibrated models, the GLM showed the highest performance (AUC: 0.939, 95% CI 0.872–0.951).
Insights into model predictions
Figure 4 illustrates insights into the variable importance for the predictions made by GLM, MARS, and XGBoost models. The top 2 important variables were age and SWV measurement 1 among all models.Fig. 4. Insights into variable importance of GLM, MARS, and XGBoost models. The baseline represents the loss function when our response values are randomized and indicate the worst-possible loss function value when there is no predictive signal in the data. Feature importance was calculated as 1—mean dropout loss, between 0 and 1, the larger the more important. AUC area under the curve, GLM logistic regression with elastic net penalty, MARS motivation, ability, role perceptions, situational factors, XGBoost extreme gradient boosting
Figure S2 shows the decision curve analysis of GLM, MARS, and XGBoost models. Net benefits of these models and the default approaches of treating all (always act) patients or treating none (never act) patients are shown. From 0.19 to 0.61, and 0.67 to 0.89 threshold probabilities, the GLM model validated on the updated software data has a higher net benefit compared to validation on the original software data. From 0.14 to 0.71 threshold probabilities, the XGBoost model validated on the updated software data has a higher net benefit compared to the validation on the original software data. From 0 to 0.33, and 0.35 to 1.0 threshold probabilities, the MARS model validated on the original software data has a higher net benefit compared to the validation on the updated software data.
Discussion
In this study, we developed machine learning models using multicenter SWE data generated by the original imaging software [10], and externally validated their performance on data generated by both the original updated software versions [9]. All models showed great performance in the development set (AUCs ranging from 0.88 to 0.94), except the SVM model which was not calibrated. In the external validation set, the GLM and XGBoost models showed better performance when validated on the updated software data compared to the original software data. The MARS model showed worse performance when validated on the updated software data. To the best of our knowledge, this is one of the first studies to explore the impact of updated imaging software as a source of data drift and its effect on the generalizability of AI models.
Reproducibility concerns are an emerging topic of high importance in the field of medical AI (image) analyses. Presently, the research community predominantly concentrates on enhancing pre-processing techniques for medical images [20], refining algorithmic structures [21], and incorporating diverse global data spanning different ethnicities and continents, to improve model performance and generalizability [6, 22]. However, once a model is built, we lack monitoring mechanisms to continuously monitor algorithm performance. Data drift may occur over time, leading to impaired generalizability and performance of AI algorithms. Reasons for data drift can be changes in the underlying population (changes in ethnicity, disease stages, or socioeconomic status), changes in the medical standards (e.g. new therapies, diagnostic measures), heterogeneity of hospital information systems [23], and changes in the underlying data itself produced by medical devices (e.g. updated imaging software) [7]. Gulshan et al. developed a deep learning model for the detection of diabetic retinopathy [4], achieving impressive AUC values of 0.99 on two independent American validation datasets in retrospective settings. However, the model's performance declined when prospectively validated across 11 rural clinics in Thailand [24]. One potential explanation for this discrepancy is the difference in the versions of medical imaging software, with more advanced systems being utilized in developed countries compared to those available in rural areas. Hsu et al. developed an ensemble deep learning model for breast mammography screening [25] and validated its performance across the UCLA cohort, the Kaiser Permanente Washington cohort, and the Karolinska Institute cohort. Although the model demonstrated high performance for automated screening mammography interpretation within these specific cohorts, its performance did not generalize well to a more diverse screening population. Whether these varying cohorts utilized the same version of mammography imaging software remains unclear and may have contributed to the observed discrepancies. Prospective validation is to ensure models generalize well on unseen, real-world data, which may have new patterns, variations, and shifts that were not captured in the training data [26]. Concurrent updates in the medical software responsible for data generation have not received adequate attention, so far. Whether model performance remains stable when medical software (and thus the underlying data) is updated, is a knowledge gap that has to be addressed in a rapidly developing field like medical AI.
The interplay between AI algorithms, medical imaging software, and data is complex (Fig. 5). AI models are built and trained on data generated by medical imaging software. When updating the imaging software, the data generated by the updated software may differ from the original version. E.g., in this analysis, using the updated software compared to the old version resulted in a significantly higher SWV within the same breast mass. Thus, the performance of AI models may be severely influenced when updating medical software and changing the underlying data. As the U.S. spends about $200 billion on medical software each year, with further increase expected, this is not only relevant from a patient perspective but also from an economic perspective [27]. Besides influencing model performance, updating medical software can have a tremendous impact on users’ workflow as well [28].Fig. 5. Reproducibility crisis of medical intelligence algorithms
In this analysis, we observed statistically significant varying generalizability to the updated software for different models. The GLM model’s performance improved from an AUC value of 0.902 to 0.941 and the XGBoost model’s performance improved from AUC 0.872 to 0.934, whereas the MARS model’s performance dropped from AUC 0.894 to 0.847 and the SVM model was not calibrated upon validation. Possible reasons for the observed difference lay in the model structures themselves: GLM models use a link function to build a linear relationship between the response variables and predictors. They are known for the comparably non-complex structure allowing them to generalize well to new data [29]. XGBoost models repeat training and validating to improve models’ performance. They work well with large, complicated datasets by using various optimizing methods [30]. This may allow them to perform well across versions of software.
This study has limitations. First, this is a retrospective study, potential bias might have affected our findings [31]. Second, elastography measurements were performed on machines from one vendor, allowing conclusions with respect to the generalizability of updated software but not concerning different manufacturer’s machines. Third, the cause of the reproducibility crisis is complex, this study mainly discusses potential data drift because of updated imaging software, while other reasons for data drift, for example, a change in population of interest [6]; are not addressed in this study. This study does also not focus on data monitoring methods to capture data drift [5, 7].
Conclusion
Updated medical imaging software is a potential source of data drift and its impact on AI algorithms’ performance and generalizability must be considered. In this multicenter study using SWE data, some machine learning models demonstrated great potential to bridge the gap between original software and updated software, whereas others exhibited weak generalizability.
Supplementary Information
Below is the link to the electronic supplementary material.Supplementary file1 (DOCX 257 KB)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Pfob A, Sidey-Gibbons C, Barr RG, et al (2022) Intelligent multi-modal shear wave elastography to reduce unnecessary biopsies in breast cancer diagnosis (INS Pi RED 002): a retrospective, international, multicentre analysis. In: European Journal of Cancer. Elsevier Ltd, pp 1–1410.1016/j.ejca.2022.09.01836283244 · doi ↗ · pubmed ↗
- 2Cai L, Pfob A (2024) Artificial intelligence in abdominal and pelvic ultrasound imaging: current applications. Abdominal Radiology 10.1007/s 00261-024-04640-x PMC 1194700339487919 · doi ↗ · pubmed ↗