Medicinal plants of South India: A comprehensive dataset for species identification
Muthukumar Arunachalam, T. Gopu, K. Uma, Sabari Nathan

TL;DR
This paper introduces a new dataset of South Indian medicinal plants to improve AI-based species identification and conservation efforts.
Contribution
The novel contribution is the creation of SIMPD, a high-quality dataset for South Indian medicinal plants with detailed metadata for AI applications.
Findings
SIMPD includes high-resolution images of diverse medicinal plant species from South India.
The dataset supports machine learning tasks like classification and segmentation under real-world conditions.
It aims to bridge traditional ethnobotanical knowledge with modern computational methods.
Abstract
The identification and classification of medicinal plants are crucial for botanical research, traditional medicine, and AI-driven applications. However, the absence of a standardized, high-quality dataset limits advancements in automated species recognition. This study introduces SIMPD Version 1 (South Indian Medicinal Plants Dataset), a curated dataset comprising high-resolution images of diverse medicinal plant species native to South India. The dataset integrates detailed taxonomic classifications and metadata to facilitate precise species identification and biodiversity analysis. Images were acquired under real-world conditions, considering variations in illumination, pose, and environmental factors to enhance dataset robustness. SIMPD is designed to support machine learning applications, particularly in image-based plant classification, object detection, and segmentation tasks. By…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1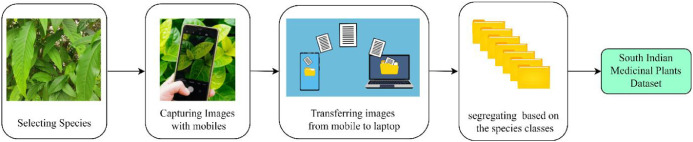 Figure 2
Figure 2 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEthnobotanical and Medicinal Plants Studies · Essential Oils and Antimicrobial Activity · Phytochemicals and Medicinal Plants
Specifications TableSubjectHealth sciences, Medical Sciences & PharmacologySpecific subject areaFocuses on advanced computational techniques for identifying and analyzing plant species.Type of dataImagesData collectionThe SIMPDVersion1 dataset comprises a meticulously categorized collection of high-quality images of medicinal plants native to specific regions in Tirunelveli, Tamil Nadu, South India. These images were manually captured using mobile cameras with varying resolutions, introducing significant diversity in pose, illumination, and resolution—enhancing the dataset's robustness for real-world applications. The dataset is thoughtfully curated to align with the traditional knowledge and practices of the local population, emphasizing the cultural and medicinal significance of these plants in South Indian daily life.To ensure high-resolution imagery, the dataset includes images captured in three distinct dimensions:
- •1156 × 650 pixels (76 MP camera)
- •2016 × 4480 pixels (74 MP camera)
- •2084 × 4624 pixels (86 MP camera) The medicinal plants were predominantly found in natural habitats, such as areas near water tanks, lakes, and ponds, reflecting their ecological significance. To account for environmental variations, images were taken at different times of the day—morning (7:00–9:00 AM) and evening (4:00–6:00 PM)—under diverse lighting conditions. By capturing the unique ecological context of South Indian medicinal flora, this dataset serves as a valuable resource for species identification, classification, and AI-driven plant analysis, fostering advancements in botanical research, biodiversity conservation, and machine learning applications.Data source locationCity : TirunelveliCountry: IndiaLatitude and Longitude for the collected samples/data: 8°45′16.2″N 77°43′32.3″EData accessibilityRepository name: Mendeley dataData identification number: 10.17632/9d89vjcghv.2Direct URL to data:https://data.mendeley.com/datasets/9d89vjcghv/2Related research articleNone
Value of the Data
1
- •Comprehensive Dataset: SIMPD Version 1 provides a systematically curated collection of high-resolution images of 20 medicinal plant species indigenous to South India, facilitating precise species identification and biodiversity analysis.
- •Enhancing AI Research: The dataset supports the development and benchmarking of machine learning models for plant classification, object detection, and segmentation. The inclusion of diverse imaging conditions enhances model generalizability for real-world applications [[1], [2], [3]].
- •Bridging Traditional Knowledge and Computational Science: SIMPD integrates ethnobotanical insights with computational methodologies, aiding researchers in preserving and digitizing traditional medicinal knowledge while enabling automated plant species recognition.
- •Application in Agriculture and Environmental Science: Insights derived from SIMPD can be extended to related fields such as agricultural monitoring, forestry, and environmental conservation. Moreover, the dataset supports research on medicinal plants used in traditional practices like Siddha and Ayurveda, bridging the gap between traditional knowledge and modern scientific advancements.
Background
2
Medicinal plants play a crucial role in traditional healthcare systems and modern pharmacological research. South India, known for its rich biodiversity, is home to a vast number of medicinal plant species used in ethnomedicine, including Siddha, Ayurveda, and Unani practices. However, the accurate identification and classification of these species remain a challenge due to the absence of standardized, publicly available datasets that capture plant variations under real-world conditions.
Existing plant datasets are often developed in controlled environments with plain backgrounds, limiting their effectiveness for real-world applications. Furthermore, variations in plant morphology, growth stages, lighting conditions, and background clutter introduce significant challenges for automated classification models. Current datasets also lack adequate representation of indigenous medicinal plants specific to South India, making it difficult for researchers to develop AI-driven solutions tailored to this region’s flora.
To address these gaps, we introduce SIMPD Version 1, a curated collection of 2503 high-resolution images covering 20 diverse medicinal plant species. The dataset captures images in natural habitats, considering varying environmental conditions, poses, and illumination levels. It is designed to support AI-driven plant identification, machine learning-based classification, and conservation research. By providing a robust dataset, this work aims to enhance automated species recognition, aid in biodiversity conservation, and bridge the gap between traditional ethnomedicine and modern computational research.
Data Description
3
Automated plant recognition in real-time, wild environments remains a significant challenge in both botanical taxonomy and computer vision. Existing medicinal plant databases are often designed for specific plant classes and are typically captured in controlled laboratory settings with plain backgrounds, limiting their real-world applicability. Traditional handcrafted feature engineering struggles to process large-scale, unconstrained datasets, making it inadequate for modern AI-driven plant identification [4]. Moreover, existing datasets lack mobile-based plant images captured in natural scenes, leading to inconsistencies due to variations in contributors, camera types, geographic locations, seasonal changes, and individual plant characteristics.
To bridge this gap, we introduce SIMPD Version 1 (South Indian Medicinal Plants Dataset), a carefully curated collection of 2503 high-resolution images covering 20 medicinal plant species indigenous to South India. The dataset was collected in outdoor environments under natural lighting conditions, ensuring realistic variability in illumination, shadows, and reflections. To capture the ecological context of the plants, images were taken in their native habitats, including areas near water bodies (ponds, lakes, and irrigation canals), agricultural lands, and forest patches. The complete details of existing datasets are summarized in Table 1.Table 1. Details of the existing plants databases.Table 1:Database NameCountryoriginNo of plant speciesTotal number of ImagesMemory sizeReferencesSwedish leafImage, table 1Sweden15 tree species11253.705 GBhttp://www.cvl.isy.liu.se/en/research/datasets/swedish-leaf/Flavia DatasetImage, table 1China32 plants19071 GBhttp://flavia.sourceforge.net/Image CLEF 11France71 tree species6436154 KBhttp://www.imageclef.org/Image CLEF 12Image, table 1France100 tree species11,572816 KBhttp://www.imageclef.org/Leaf SnapImage, table 1United States185 tree species23147977 MBhttp://leafsnap.com/dataset/Oxford Flower 17United Kingdom17 flower species1360218 MBhttps://www.robots.ox.ac.uk/∼vgg/data/flowers/17/Oxford Flower 102Image, table 1United Kingdom102 flower species8189329 MBhttps://www.robots.ox.ac.uk/∼vgg/data/flowers/17/ICLImage, table 1China220 plant species17,032-http://www.intelengine.cn/English/datasetMEWImage, table 1Europe153 species97451.33 GBhttp://zoi.utia.cas.cz/node/662MalayakewImage, table 1England44 Plant species2816383 MBhttps://web.fsktm.um.edu.my/∼cschan/downloads_MKLeaf_dataset.htmlSeveral publicly available datasets, such as those on Mendeley, Kaggle, and other research repositories, focus on fruit and general plant classification. However, these datasets often have significant limitations when applied to medicinal plant identification, particularly in real-world, unconstrained environments. SIMPD Version 1 addresses these gaps and offers unique advantages:
Region-Specific Medicinal Plant Dataset
3.1
Most publicly available datasets focus on general plant or fruit species from diverse regions, but they lack datasets tailored specifically for South Indian medicinal plants. SIMPD Version 1 is designed to support ethnobotanical research and traditional medicinal knowledge preservation, making it highly valuable for researchers working on Siddha, Ayurveda, and Unani practices.
Real-World Environmental Variability
3.2
Many existing datasets, such as the Flavia Leaf Dataset or Swedish Leaf Dataset, are captured in laboratory environments with plain backgrounds. SIMPD captures images in natural settings, including agricultural lands, water bodies, and wild vegetation, which introduces realistic lighting conditions, occlusions, and varying angles—enhancing model generalization for real-world applications.
High-Resolution Images with Diverse Capturing Conditions
3.3
Most existing datasets contain images captured under uniform conditions with a single camera type and resolution. SIMPD Version 1 provides images from multiple cameras (76 MP, 74 MP, and 86 MP) with resolutions ranging from 1156 × 650 pixels to 2084 × 4624 pixels. Captured under morning and evening light, ensuring illumination diversity to support deep learning models with robust training samples.
Inclusion of Full Plant Structures, Not Just Leaves or Fruits
3.4
Existing datasets such as LeafSnap or Fruit360 (on Kaggle) focus on isolated leaves or fruits, which may not fully represent a plant’s taxonomy. SIMPD Version 1 includes entire plant structures, such as stems, flowers, and leaves, to support comprehensive species identification.
Ethnobotanical Significance and Traditional Knowledge Integration
3.5
Unlike standard fruit or plant datasets that focus only on classification, SIMPD integrates metadata on medicinal applications, ecological significance, and local names, making it valuable for biodiversity conservation, herbal medicine research, and sustainable agriculture studies. This ensures that the dataset not only aids AI-based classification but also serves as a resource for scientific and cultural knowledge preservation.
Fig. 1 showcases all 20 different species and the details of the medicinal plants along with their colloquial name, Botanical name and the number of images are shown in Table 2.Fig. 1. Sample images of SIMPD v1 shown in .jpg format.Fig 1:Table 2. Details about each species in SIMPDv1.Table 2:Vernacular/Colloquial NameCommon NameSpecies CategoryNumber of ImagesAdathodaMalabarNutJustica adhatoda100Aagaya ThamaraiWater HyacinthEichhornia Crassipes192AamanakuCastor SeedsRicinus communis109AarangkeeraiEuropean water cloverTrifolium Repens100AavaraiAvaram sennaSenna Atriculata125AgathiWest India PeaSesbania grandiflora91ChembarathiHawaiian HibiscusHibiscus Rosasinensis113ElandhaiIndian JujibeeZiziphus mauritiana92Erukan ElaiCrown flowerCalotropis gigantea106ThulasiMint102ThuthiIndian MallowAbutilon Indicum165Idli PooFlame of woodsIxora coccinea114KalVaazhaiIndian ShotCanna indica149KannupeelaiMountainknot grassOuretlanata119KarisalankanniBhringarajEclipta prostrate208KaruvepilaiCurry leavesMurraya koenigii118KatralaiAloe veraAloe barbadensis miller145KeelanelliStone BreakerPhyllanthus amarus111ManjalTurmericCurcuma longa110PirandaiVeldt grapeCissus quadrangularis134
Challenges of the Dataset
4
Intra-Class Variability and Inter-Class Similarity
4.1
Plants with Similar Colored Flowers (Fig. a): Many species have flowers with identical colors but belong to different botanical categories. AI models trained solely on color-based features may misclassify them, requiring texture and shape-based feature extraction for differentiation.
Different Plants with Similar Leaves (Fig. d): Some plant species exhibit leaf structure similarities, making classification difficult. Deep learning models must rely on subtle vein patterns, margins, and surface texture rather than shape alone.
Environmental Variability Affecting Image Consistency
4.2
Lighting Variations (Fig. b): Images were taken under different illumination conditions, affecting contrast, shadow depth, and color accuracy. This may lead to inconsistent model predictions, requiring robust normalization techniques. Background Complexity and Clutter: Unlike laboratory-captured datasets with plain backgrounds, SIMPD images contain natural clutter, such as soil, surrounding vegetation, and overlapping plants, making it difficult for models to distinguish the primary plant from the background.
Species With Similar Structures But Different Attributes
4.3
Plants with Similar Leaves but Different Flowers (Fig. c): Some plants have almost identical leaf structures but exhibit different flower morphology. Models trained on leaf-based features may fail to distinguish such species unless flower characteristics are incorporated into the classification.
Different Plants with Similar Fruits (Fig. e): Certain medicinal plants produce fruits that resemble those of other species. Models relying on fruit-based classification must be trained with additional metadata (such as texture, size variations) to avoid confusion.
Experimental Design, Materials and Methods
5
Plants are essential to human survival and play a vital role in maintaining Earth’s ecological balance by providing sustenance, shelter, and contributing to a breathable atmosphere. The SIMP dataset was carefully curated under unconstrained environmental conditions, capturing images with significant variations in illumination, scaling, view angles, as well as the growth stages and age of the plants. Additionally, the dataset features a broad spectrum of image variations, including differences in camera resolution, lighting conditions, and angles, ensuring a diverse and robust collection for real-world applications. The data acquisition process, as illustrated in Fig. 2, involved capturing images in the field and then transferring them to a laptop for subsequent analysis. After processing, the images were systematically categorized into 20 distinct plant classes (see Fig. 3), allowing for organized, efficient classification and facilitating advanced machine learning models for plant identification and research [5].Fig. 2. Process of data acquisition.Fig 2:Fig. 3. Similarities and variations in plants.Fig 3:
Based on this, a study focused on classifying six medicinal plant leaves using machine learning on a dataset collected from The Islamia University of Bahawalpur has been proposed. The multi-layer perceptron classifier achieved the highest accuracy of 99.01 %, outperforming models like random forest and logit-boost. The research optimized feature selection using a chi-square method and extracted multispectral and texture-based characteristics for classification [2]. An automated real-time plant species identification system for medicinal plants in Borneo, utilizing an EfficientNet-B1 deep learning model has also been developed. The system integrated a computer vision model, a knowledge base, and a mobile application, achieving up to 87 % accuracy on test datasets. It also incorporated crowdsourced feedback and geo-mapping, enhancing real-time plant identification capabilities [3]. A deep learning-based study employed a CNN model to classify six plant species in real-time using IoT, achieving 99 % accuracy. The CNN model outperformed traditional machine learning models, such as logistic regression and random forest. Future work aims to extend this research by automating plant growth estimation [5].
Selection of Medicinal Plants
5.1
The case study documents the indigenous knowledge of Kani tribal healers in the Tirunelveli Hills, who rely on medicinal plants as their primary source of healthcare. Ethnomedicinal data were collected through interviews over four years and analyzed using quantitative indices. The research highlights the traditional use of medicinal plants for treating common ailments and underscores the importance of preserving this knowledge [6]. An ethnobotanical survey conducted in Kancheepuram, Tamil Nadu, documented 85 medicinal plant species used by traditional healers for treating various diseases. The Euphorbiaceae family was found to be the most dominant, with leaves being the most commonly utilized plant part. The study emphasizes the risk of traditional knowledge disappearing, as fewer young people continue to practice these traditional healing methods [7]. A study on traditional medical practices and the use of 67 ethnomedicinal plant species by Kani tribal healers in Karayar, Tamil Nadu, was analyzed. The plants were used to treat 31 ailments, with cough being the most common (7 plants), and Fabaceae having the highest species count (10). Leaves of 23 species were primarily used, offering valuable insights for researchers and conservationists [8]. Another study documented the traditional medicinal knowledge of healers in Thimmarajapuram, Tirunelveli, focusing on the importance and use of medicinal flora. A total of 45 plant species from 27 families were recorded, with leaves being the most commonly used part, often prepared as juice or paste. Gastrointestinal ailments were the most frequently treated conditions [9].
Building on insights from previous case studies and the historical knowledge of local elders, we have carefully analyzed the medicinal significance of various plants and selected specific species to ensure accurate interpretations and reliable conclusions.
Limitations
One major limitation of the dataset is its geographic concentration, as all images were collected from locations in and around Tirunelveli, South India, which may restrict its applicability to other regions. Variations in image quality, lighting conditions, and backgrounds introduce noise, posing challenges for automated recognition systems. Moreover, the dataset lacks detailed metadata, such as precise location coordinates, capture time, and plant health status, which could enhance contextual understanding. Addressing these limitations in future versions would significantly improve the dataset’s utility for broader applications in botanical research and computer vision
Ethics Statement
The authors have reviewed and adhered to the ethical standards necessary for publication in Data in Brief. They affirm that the present study does not involve human subjects, animal experimentation, or the use of data obtained from social media platforms.
CRediT authorship contribution statement
Muthukumar Arunachalam: Visualization, Investigation, Supervision. T. Gopu: Conceptualization, Methodology, Software, Validation. K. Uma: Data curation, Writing – original draft, Writing – review & editing. Sabari Nathan: Data curation, Writing – original draft, Software, Validation.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Chompookham T.Surinta O.Ensemble methods with deep convolutional neural networks for plant leaf recognition ICIC Express Lett.1562021553565
- 2O. A. Malik, N. Ismail, and B. R. Hussein, “Automated real-time identification of medicinal plants species in natural environment using deep learning models — a case study from Borneo Region,” 2022.10.3390/plants 11151952 PMC 937065135956431 · doi ↗ · pubmed ↗
- 3Mahajan S.Raina A.Gao X.Z.Pandit A.K.Plant recognition using morphological feature extraction and transfer learning over SVM and adaboost Symmetry (Basel)1322021116
- 4Singh S.Uday C.Singh P.Sharma U.Jain S.Classification of different plant species using deep learning and machine learning algorithms Wirel. Pers. Commun.1364202422752298
- 5Wodah D.Asase A.Ethnopharmacological use of plants by Sisala traditional healers in northwest Ghana Pharm. Biol.50720128078152247192010.3109/13880209.2011.633920 · doi ↗ · pubmed ↗
- 6Muthu C.Ayyanar M.Raja N.Ignacimuthu S.Medicinal plants used by traditional healers in Kancheepuram District of Tamil Nadu, India J. Ethnobiol. Ethnomed.220061101702676910.1186/1746-4269-2-43PMC 1615867 · doi ↗ · pubmed ↗