How do Design Characteristics Affect Respondent Engagement? Assessing Attribute Non-attendance in Discrete Choice Experiments Valuing the EQ-5D-5L
Peiwen Jiang, Deborah Street, Richard Norman, Rosalie Viney, Mark Oppe, Brendan Mulhern

TL;DR
This study examines how design choices in discrete choice experiments affect how engaged respondents are, using health-related quality-of-life data.
Contribution
The study introduces modified Fedorov designs with attribute overlap to reduce non-attendance and improve engagement in discrete choice experiments.
Findings
Designs with attribute overlap increased full attendance rates from 22.3–28.4% to 28.2–54.2%.
Modified Fedorov designs (Ngene or SAS) had higher full attendance rates than other designs.
Attribute non-attendance analysis revealed significant changes in attribute importance before and after data exclusion.
Abstract
Discrete choice experiments (DCEs) are increasingly applied to develop value sets for health-related quality-of-life instruments, but respondents may adopt various simplifying heuristics that affect the resulting health state values. Attribute level overlap can make these DCE tasks easier and thereby increase respondent engagement. This study uses choice tasks involving EQ-5D-5L health states to compare designs with and without overlap, constructed using different methods (generator-developed design, Ngene, SAS, and Bayesian D-efficient design) to assess respondent non-attendance to attributes. A multi-arm DCE using the EQ-5D-5L was conducted in the Australian general population. The performance of designs with various properties was compared using the level of respondent engagement. Respondent engagement was quantified through the inferred attribute non-attendance (ANA) estimated by…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
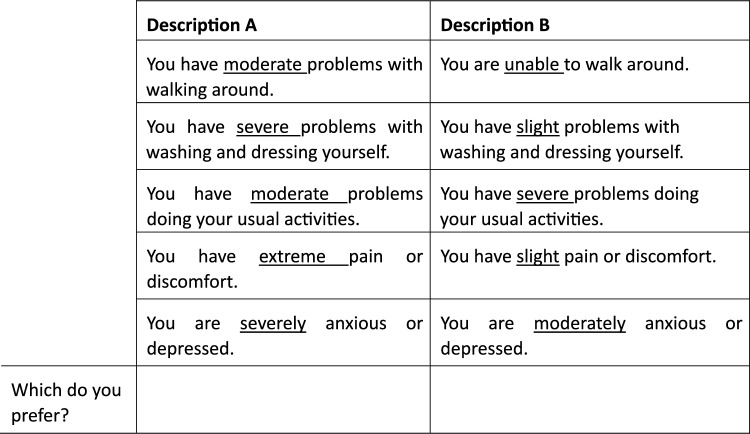 Figure 1
Figure 1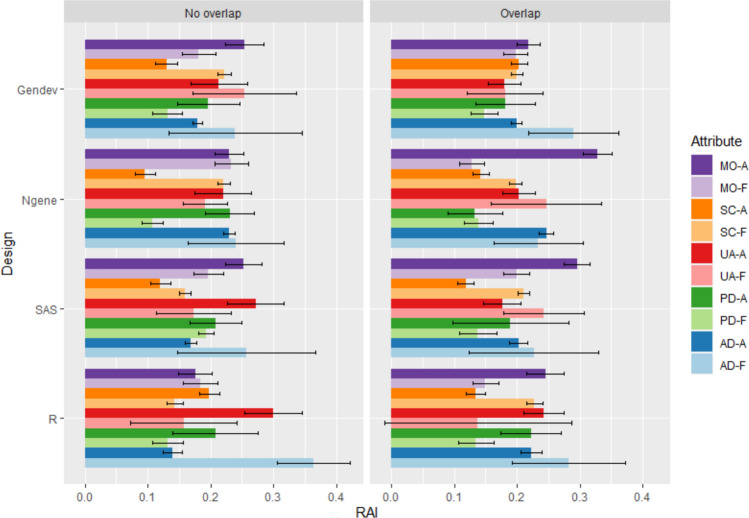 Figure 2
Figure 2- —http://dx.doi.org/10.13039/501100006419EuroQol Research Foundation
- —http://dx.doi.org/10.13039/501100000923Australian Research Council
- —University of Technology Sydney
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEconomic and Environmental Valuation · Health Systems, Economic Evaluations, Quality of Life · Healthcare Policy and Management
Key Points for Decision Makers
Modified Fedorov designs implemented in Ngene or SAS with attribute overlap are recommended to reduce attribute non-attendance (ANA) and enhance respondent engagement in discrete choice experiments (DCEs).ANA models can be used to exclude respondents who did not attend to any attributes and to identify partial attenders for further robustness checks, improving the quality of the data for analysis.Future research should focus on developing advanced models capable of disentangling the effects of preference heterogeneity and attribute attendance.
Introduction
Attribute non-attendance (ANA) is a phenomenon in discrete choice experiments (DCEs) whereby respondents consider only one or a few attributes presented in a choice task [1]. ANA can arise for two main reasons. First, it may reflect genuine preferences: some respondents may ignore certain attributes simply because they do not consider them relevant to their decision-making. In this case, ANA is an indication that those attributes are not important and do not meaningfully influence their choices. Second, ANA can occur as a decision heuristic, where respondents actively ignore attributes, not because they are unimportant but as a strategy to simplify complex tasks.
Heuristic-driven ANA is particularly likely to occur in highly complex choice tasks where respondents are required to consider multiple attributes presented at different levels at the same time. Design construction methods in DCEs are specifically developed to optimise the statistical efficiency of the experiment, aiming to maximise the information obtained from respondents’ choices while minimising the required sample size. However, there is a trade-off between behavioural efficiency and statistical efficiency.
Despite this need for balance, most studies evaluating DCE design methods have focused on statistical efficiency alone, with limited attention to the behavioural implications of different construction techniques [2–4]. The choice of construction method—such as orthogonal designs (which maintain attribute level independence) or efficient designs (which relax orthogonality constraints to optimise information yield)—can influence the rate of ANA [1, 5]. A study focusing on preferences of healthcare providers compared ANA between orthogonal and efficient designs using the equality constrained latent class (ECLC) model [5]. They found higher levels of ANA in efficient designs than in orthogonal designs and a more pronounced difference among illiterate respondents than among literate respondents. Another study on threatened species in New Zealand also adopted ECLC models to evaluate behavioural efficiency between orthogonal, generator-developed, and efficient designs [6]. Their results showed that the orthogonal design resulted in the lowest rate of full attendance and the D-efficient design achieved the highest level of full attendance. These contrasting findings suggest that construction methods may affect ANA differently.
In light of the increasing importance placed on respondent efficiency, attribute overlap has been recognised as a useful strategy to improve attribute attendance [7, 8]. Various design methods have included this feature in the construction of DCE designs [9–11]. Attribute overlap refers to the practice of setting a subset of attributes at the same level across options within the choice task. Jonker et al. [8] employed a Bayesian D-efficiency design to compare designs with no overlapping attributes and those with three of six attributes overlapped, using the EQ-5D-5L as the descriptive system. Their study showed that designs with attribute overlap significantly improved attribute attendance, increasing the number of attended attributes from two to three of a total of five.
Both studies comparing DCE construction methods—one focused on healthcare provider preferences and the other on threatened species—used designs without attribute overlap [5, 6]. Despite this similarity, their findings differed significantly, suggesting that construction method alone may not fully explain variations in ANA. Attribute overlap has been proposed as a potential way to enhance both respondent efficiency and attribute attendance, potentially playing a more influential role than construction method alone. This highlights the need to examine both construction method and attribute overlap together to understand their combined effects on respondent behaviour.
The growing interest in integrating attribute overlap in DCEs has led to its incorporation into various DCE construction algorithms, such as Ngene [9], SAS macros [10], and generator-developed designs [11]. It is surprising that no investigation has yet explored the ANA among designs featuring level overlap, particularly those constructed via differing methods. Furthermore, there remains a notable gap in the realm of preference measures, with limited exploration of design methodologies and structures, except for the studies by Jonker et al. [8, 12]. The current study aims to fill this knowledge gap and contribute to the literature by comprehensively comparing various design construction methods while considering the impact of attribute overlap in the domain of preference measures.
Methods
Choice Experiment
The descriptive system used in this study is the most widely used health-related quality-of-life instrument, the EQ-5D-5L. It contains five attributes—mobility, self-care, usual activities, pain/discomfort, and anxiety/depression—each presented at one of five levels (no problems, slight problems, moderate problems, severe problems, and extreme problems/ unable to). Health states are described by the quintuples of levels, with 11111 denoting the best health state possible and 55555 representing the worst health state possible. There were two hypothetical situations within each choice task, and respondents were asked to choose which they preferred, as shown in Fig. 1.Fig. 1. Context and typical choice set. Please consider, and imagine living with, one of the two health states described below. Then tell us which description you would prefer to experience.
The study included a total of 19 designs constructed using six construction methods (Generator-developed design, modified Fedorov algorithm implemented in Ngene, modified Fedorov algorithm implemented in SAS, Bayesian D-efficient design, STATA, and modified coordinate–exchange algorithm implemented in Ngene), using zero and non-zero priors, and including attribute level overlap on two of the five attributes or on none (see Mulhern [13] for details). Each respondent was randomly allocated to one of the 19 designs, and a total of 21 choice sets were presented to these respondents. In this article, we focus on a subset of four construction methods capable of generating designs with attribute overlap and only on designs constructed using zero priors. We selected only these designs to ensure comparability because efficient designs can be affected significantly by misspecifications in the priors [3]. By exclusively considering designs with zero priors, we effectively eliminated bias and enhanced the validity of our comparisons.
The four construction methods included in this article are generator-developed design [11], Ngene [9], SAS macros [10], and Bayesian D-efficient design algorithm implemented in R by Oppe and van Hout [14] based on Rose et al. [15]. Each of these construction methods was used to generate one design with no overlap and another with two overlapping attributes out of five. This resulted in a total of eight designs, which are briefly outlined below.
The generator-developed design started with an initial set of profiles that form an orthogonal array for five attributes each with five levels, and a set of generators [11]. To obtain a 100% efficient design for zero priors for a design with no overlapping attributes, two generators are required. For each attribute, the two generators must between them have one entry that is 1 or 4 and one entry that is 2 or 3. In addition, our selection of generators was strategically aimed at minimising the number of dominant pairs within the design. Therefore, for the design with no overlapping attributes, the generators were (1,1,1,2,2) and (2,2,2,4,4). For the design with two overlapping attributes, we elected to again have two generators. To obtain attributes with equal levels in two of the attributes in the two options, a generator must have two elements that are equal to 0. We used the generators (1,1,1,0,0) and (0,0,2,1,1).
The modified Fedorov algorithm was used in both the Ngene software and the SAS macros to compare software implementations rather than to focus on different design algorithms. For designs with no overlap, the algorithm iteratively exchanges a profile in the design with one from all possible candidate profiles until no substantial improvement in the D-error value is observed. With regards to designs with overlap, a candidate set of choice sets consisting of all 40,000 pairs with two overlapping attributes was used in both Ngene and SAS. These choice sets then underwent iteration to identify the optimal design with overlap on two attributes.
The fourth construction method we included was the Bayesian D-efficient design algorithm implemented in R by Oppe and van Hout [14] based on Rose et al. [15]. Overlapping and non-overlapping designs were generated, subject to the constraints that no pair could be duplicated, choice sets could not include dominated options, and the designs needed to meet a specific requirement for level balance (see the electronic supplementary material [ESM]-A).
The survey consisted of several sections. It began with basic demographic questions (age, gender, and region) to ensure quota distribution, followed by survey details and consent. Participants then completed a self-reported EQ-5D-5L assessment before receiving instructions on the DCE tasks. This was followed by 21 DCE choice tasks. Finally, respondents answered follow-up questions regarding survey difficulty and additional demographic details.
Sample Recruitment
A total of 3365 respondents were recruited by an Australian online panel company, Pureprofile. The panel company gave a small incentive to respondents who fully completed the survey. The study sample was representative of the Australian general population in terms of age, gender, and region. As mentioned, 8 of 19 designs were selected for this study, so we used a subset of the sample (N = 1432). The quota allocation (age, gender, and region) was applied to each design to minimise the potential impact of these demographics on the results.
Attribute Non-attendance
The performance of the designs was compared by evaluating ANA. The ECLC model was used to identify the variations in ANA patterns to the dimensions of the EQ-5D-5L across these designs. Unlike the commonly used latent class model that focuses on preference heterogeneity, the ECLC model defines classes based on respondents’ behaviour regarding attribute attendance. A high membership probability in a class indicates a greater likelihood of engaging in the attribute attendance behaviour associated with that class. This model not only generates preference estimates but also provides information on the probability of each possible ANA strategy for each individual. When an attribute is ignored, its coefficient is assumed to be zero. For attributes that are considered, they are set to have the same values across all classes, assuming homogeneous taste parameters. However, information-processing behaviour is assumed to be heterogeneous.
There are 32 (= 2^5^) possible ANA strategies for the choice sets used, ranging from attending to each dimension to ignoring all dimensions of the EQ-5D-5L and choosing the preferred health state randomly. Other possible ANA strategies include nonattendance to one, two, three, or four of the five attributes. These strategies translate into 32 possible classes within the ECLC model. However, including all 32 classes simultaneously could result in issues of over-identification. To address this, a five-step approach was adopted to include and exclude ANA patterns. Classes with a membership probability below 5% were deemed insignificant and therefore excluded from the model, as suggested by Doherty et al. [16]. Only significant classes were retained in the ECLC model. The estimation of the ECLC model began with six classes, including one class representing full attendance and five classes featuring non-attendance to exactly one of the five dimensions. In the second step, nonsignificant classes from step one were removed and the next 10 = \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${C}_{2}^{5}$$\end{document} processing strategies where respondents ignored exactly two attributes were included in the model estimation. Similarly, the model in step three removed nonsignificant classes from step two and included the next 10 = \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${C}_{3}^{5}$$\end{document} classes representing respondents assumed to have ignored exactly three attributes. In step four, the model was re-estimated including significant classes from step three, along with five ANA patterns = \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${C}_{4}^{5}$$\end{document} where respondents considered only one dimension, and a class where all attributes were ignored. Finally, the resulting ECLC model, consisting only of significant classes, was used to generate estimates for the EQ-5D-5L.
Statistical Modelling
The multinomial logit (MNL) model was employed to analyse the choice data. The utility for respondent i associated with option j in choice task t is given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$U_{ijt} = x_{ijt} \beta + \epsilon_{ijt} .$$\end{document}where xijt is a vector of dummy coded attribute levels shown to individual* i* as option j in choice task t, and β is a preference vector for the effects of these attribute levels, assuming preference homogeneity. The error term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon_{ijt}$$\end{document} is assumed to have a standard type I extreme value distribution. The probability of respondent i choosing option j in choice task* t* under the MNL framework can be described as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_{ijt} \vee \beta = \frac{{e^{{\beta x_{ijt} }} }}{{\mathop \sum \nolimits_{j = 1}^{J} e^{{\beta x_{ijt} }} }}.$$\end{document}The MNL model assigns a weight to each dimension for every respondent, even if respondents might not engage with the dimensions. To address this issue, the ECLC model was used to explore different ANA patterns. In this model, individuals are classified into latent classes based on their ANA patterns, and the parameter of class c is denoted by βc. Across all classes, preference parameters are assumed to be the same except for the non-attended dimensions, and hence are the same as the MNL model. For non-attended dimensions, their parameters are set to be zero. The probability of observing the ANA pattern c for individual i choosing option* j* in choice task t can be written as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_{ijt} \vee \beta_{c} = \frac{{e^{{\beta_{c} x_{ijt} }} }}{{\mathop \sum \nolimits_{j = 1}^{J} e^{{\beta_{c} x_{ijt} }} }}.$$\end{document}Based on the ANA analysis, respondents who have attended all five attributes (full attenders) and those who did not attend all five (partial attenders) can be identified. To test for differences in estimates by full attendance status, the data were first analysed using the MNL model with main effects and interactions between a dummy indicating full attendance or not, and each attribute level.
In addition, separate MNL main effects models were estimated for all respondents and full attenders. This was conducted to compare the EQ-5D-5L coefficients before and after exclusion, employing ANA analysis as a quality check procedure. To compare MNL results across different models, the coefficients were anchored using the coefficient for the worst EQ-5D-5L state (55555). Furthermore, we examined the relative attribute importance (RAI) scores both before and after data exclusion. The RAI scores were calculated by dividing the sum of all coefficients for each dimension by the sum of all coefficients, as shown in Eq. 4.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$RAI_{k} = \frac{{\beta_{k} }}{{\beta_{MO} + \beta_{SC} + \beta_{UA} + \beta_{PD} + \beta_{AD} }}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\beta }_{k}$$\end{document} is the sum of all coefficients for each dimension of the EQ-5D-5L.
An external validity analysis was conducted to assess the extent to which the ECLC model’s attendance classifications align with respondents’ levels of engagement and attentiveness. Specifically, the presence of straightlining (i.e., selecting the same option repeatedly, e.g., AAAA … or BBBB …), completion times for both the choice tasks and the overall survey, and feedback question responses regarding task difficulty and consideration of the entire description were examined. These indicators were then compared across the three attendance classes (full attenders, partial attenders, and non-attenders) to determine whether the observed behaviours matched the expected pattern of decreasing attentiveness and engagement.
The ANA analysis was performed in Latent GOLD 5.1 [17], and the MNL models were estimated in R [18] and RStudio [19], using the gmnl package [20].
Results
Respondent Characteristics
The characteristics of the overall sample are similar to those of the overall Australian population in terms of age, gender, and region at the state and territory level. There is no significant difference between the subsamples at the 0.05 level by age, gender, or region for the overlap or non-overlap groups. This is also the case for most of the other demographic characteristics measured. However, the respondents are more highly educated than the overall Australian population. At the overall level, 47% of the sample reported having a long-term health condition, and 22% reported themselves to be in the best EQ-5D-5L health state.
ANA Probabilities
Table 1 presents estimated probabilities from the ECLC model. For designs without overlap, the generator-developed designs showed the highest probability of attending to all five EQ-5D attributes (28.4%), whereas the lowest estimated full attendance rate was observed in SAS designs (22.3%). The lowest probability of ignoring all attributes was found in Ngene designs (8.5%) and the highest in R designs (17.8%).Table 1. Estimated class probabilities from the final equality constrained latent class (ECLC) model for each designNo overlapOverlapClassAttributes non-attendedProb. (%)95% CIClassAttributes non-attendedProb. (%)95% CIGen-dev1None28.428.3–28.61None30.8****30.7–31.02PD+AD6.36.2–6.32AD21.221.1–21.43MO+UA+AD5.15.0–5.13MO+SC9.99.8–10.04MO+SC+UA+PD15.715.6–15.74PD+AD16.616.4–16.75MO+SC+UA+AD9.39.2–9.45MO+SC+UA+PD+AD21.5****21.4–21.66MO+UA+PD+AD8.28.1–8.27SC+UA+PD+AD12.112.0–12.18MO+SC+UA+PD+AD15.0****15.0–15.2Ngene1None24.624.6–24.91None54.2****54.2–54.42AD9.79.5–9.72PD+AD22.922.8–23.13MO+SC12.512.4–12.63MO+SC+UA+PD+AD22.9****22.7–22.94SC+PD+AD8.58.4–8.55UA+PD+AD8.68.5–8.76MO+SC+UA+PD14.314.3–14.47MO+UA+PD+AD8.98.8–8.98SC+UA+PD+AD4.34.3–4.49MO+SC+UA+PD+AD8.5****8.5–8.6SAS1None22.322.1–22.31None49.4****49.4–49.82SC9.89.7–9.92SC+UA14.314.1–14.33MO+SC+UA5.85.6–5.83UA+AD10.410.3–10.44UA+PD+AD16.816.7–16.94PD+AD8.28.1–8.35MO+SC+UA+PD12.912.9–13.05MO+SC+UA+PD+AD17.6****17.5–17.76MO+SC+UA+AD5.65.5–5.77SC+UA+PD+AD14.614.5–14.78MO+SC+UA+PD+AD12.3****12.1–12.3R1None22.622.4–22.71None28.2****28.1–28.32MO9.89.6–9.82AD8.78.6–8.83AD21.621.6–21.83MO+SC16.116.0–16.24MO+SC+UA6.16.0–6.24PD+AD15.415.3–15.55MO+SC+UA+PD9.49.3–9.45SC+UA+PD9.29.1–9.26SC+UA+PD+AD12.812.8–12.96SC+UA+PD+AD8.48.2–8.47MO+SC+UA+PD+AD17.817.6–17.87MO+SC+UA+PD+AD14.1****14.0–14.2Bold text indicates full attendance and non-attendance classesAD anxiety/depression, CI confidence interval, Gen-dev generator-developed designs [11], MO mobility, Ngene modified Fedorov designs constructed in Ngene [9], PD pain/discomfort, Prob. probability, R Bayesian D-efficient design algorithm implemented in R by Oppe and van Hout [14] based on Rose et al. [15], SAS modified Fedorov designs constructed in SAS [10], SC self-care, UA usual activities
More importantly, the inclusion of attribute overlap had a significant impact on the inferred attendance rates for all attributes, regardless of the specific design method employed. It is worth noting that Ngene and SAS designs had the most significant improvements. The attendance estimates for these two methods without attribute overlap were at 24.6% and 22.3%, respectively. When examining designs with attribute overlap, these rates increased to 54.2% and 49.4%, respectively. An intriguing observation is that attribute overlap not only increased the estimated rate of attendance to all attributes in the generator-developed, Ngene, and SAS designs but also increased the estimated rate of non-attendance (i.e., none of the dimensions being considered). However, this effect was not observed in the R designs.
Health State Valuation
Table 2 focuses on designs with overlap and presents estimates derived from MNLs with main effects and interactions between a dummy indicating whether or not the respondent considered all attribute levels (i.e., reflecting partial attenders and full attenders). The corresponding estimates derived from designs with no overlap can be found in Table 3. Most of the main effects of the dimensions were statistically different from zero. Several interaction terms were statistically significant, especially for levels 4 and 5 in each attribute. This suggests that attribute attendance influenced the decrements of these attribute levels. The number of statistically significant interaction terms ranged from 13 to 17 in designs with overlap and from 12 to 15 in designs without overlap. Furthermore, most significant parameter magnitudes were larger among full attenders than among partial attenders. For example, examining MO3 for the generator-developed design with overlap in Table 2, the decrements of MO3 for partial attenders and full attenders were significantly different, at − 0.427 and − 1.168 (− 0.427 to − 0.741), respectively. However, there was one exception: the magnitude of level 2 in the mobility dimension in the R design with overlap was larger in partial attenders than in full attenders.Table 2. Estimates from multinomial logit models with full attendance interactions for designs with overlapGendevNgeneSASRCoefSEPCoefSEPCoefSEPCoefSEPMO2− 0.2160.1210.074− 0.2460.1390.077− 0.2360.1390.089− 0.4140.1210.001MO3− 0.4270.1510.005− 0.2340.1510.122− 0.6010.147< 0.001− 0.2770.1160.017MO4− 0.9370.156< 0.001− 0.6650.168< 0.001− 0.6720.140< 0.001− 0.8000.129< 0.001MO5− 1.1970.132< 0.001− 1.1480.166< 0.001− 1.5360.156< 0.001− 1.0250.130< 0.001SC20.0270.1230.8240.0360.1410.800− 0.1980.1490.1830.0870.1290.498SC3− 0.3220.1520.0340.0590.1540.703− 0.1690.1460.2470.0140.1470.923SC4− 0.8260.154< 0.001− 0.4570.1500.002− 0.5750.151< 0.001− 0.3250.1500.030SC5− 1.1600.131< 0.001− 0.5910.137< 0.001− 0.7230.146< 0.001− 0.5960.144< 0.001UA2− 0.2360.0880.0070.2260.1360.0950.2110.1490.158− 0.1390.1370.312UA3− 0.4830.087< 0.0010.0830.1460.5690.0480.1400.731− 0.1020.1360.453UA4− 1.0520.091< 0.001− 0.0920.1340.4900.0980.1470.502− 0.2180.1400.119UA5− 1.3540.094< 0.001− 0.5450.140< 0.001− 0.3290.1390.018− 0.4860.1740.005PD2− 0.1990.1230.1060.0490.1560.7530.1140.1360.404− 0.1180.1290.360PD3− 0.2300.1540.1350.1470.1420.304− 0.3890.1360.004− 0.2550.1330.055PD4− 0.8290.158< 0.001− 0.0370.1540.808− 0.6910.131< 0.001− 0.6610.115< 0.001PD5− 1.0430.135< 0.001− 0.0960.1280.454− 0.8560.140< 0.001− 0.6010.146< 0.001AD2− 0.0380.1300.7700.1390.1820.4460.3640.1340.0060.2190.1680.194AD3− 0.1280.1550.407− 0.2770.1900.144− 0.0710.1340.595− 0.1710.1430.229AD4− 0.3410.1570.0300.4070.1850.028− 0.4070.1320.002− 0.8180.147< 0.001AD5− 0.4390.1350.0010.0500.1480.738− 0.6330.135< 0.001− 0.8630.132< 0.001Interaction with full attendance MO2− 0.1110.2640.673**− 0.6030.2090.004− 0.4430.2240.0480.0700.2810.802 MO3− 0.7410.3350.027− 0.6530.2310.005− 0.7770.2680.004− 0.3440.2900.236 MO4− 1.1210.3500.001− 1.2210.258< 0.001− 2.0130.277< 0.001− 0.8170.2890.005 MO5− 1.9040.316< 0.001− 1.4210.266< 0.001− 1.5130.311< 0.001− 1.2750.318< 0.001 SC2− 0.3090.2740.258− 0.1460.2250.5150.0020.2720.993− 1.3780.318< 0.001 SC3− 0.8410.3330.012− 0.5120.2490.040− 0.4770.2370.044− 0.9790.3360.004 SC4− 1.3150.343< 0.001− 0.6610.2450.007− 1.6520.277< 0.001− 1.9050.397< 0.001 SC5− 1.9360.313< 0.001− 1.0720.249< 0.001− 2.2930.299< 0.001− 2.8030.452< 0.001 UA2− 0.2840.2000.157− 0.2560.2020.2060.0840.2890.771− 0.3590.3050.239 UA3− 0.2350.2100.263− 0.9950.229< 0.001− 0.3410.2660.200− 0.3580.3010.234 UA4− 0.9030.248< 0.001− 1.0440.216< 0.001− 1.8740.252< 0.001− 1.5180.352< 0.001 UA5− 0.8790.225< 0.001− 0.8600.213< 0.001− 2.3210.256< 0.001− 1.5900.412< 0.001 PD2− 0.3280.2790.241− 0.5580.2420.021− 0.2800.2350.2340.0320.3230.921 PD3− 0.5180.3560.145− 0.9590.226< 0.001− 0.7400.2420.002− 0.8090.3020.007 PD4− 1.7820.407< 0.001− 2.0720.256< 0.001− 1.7960.256< 0.001− 2.5020.323< 0.001 PD5− 2.4030.358< 0.001− 2.6670.231< 0.001− 1.8640.286< 0.001− 2.9710.433< 0.001 AD2− 0.5870.3300.075− 0.2420.2950.412− 1.0270.250< 0.001− 0.6670.4190.112 AD3− 1.6400.390< 0.001− 0.7470.2760.007− 1.1030.240< 0.001− 1.2960.349< 0.001 AD4− 3.2530.405< 0.001− 2.5810.289< 0.001− 2.2620.289< 0.001− 3.4640.493< 0.001 AD5− 4.2470.429< 0.001− 2.6100.245< 0.001− 2.1500.319< 0.001− 2.9500.439< 0.001Significant interaction terms (n)13171614 AIC3941366634524164 BIC4189391337004411L L− 1930− 1793− 1686− 2042AD anxiety/depression, AIC Akaike information criterion, BIC Bayesian information criterion, Coef coefficient estimate, Gen-dev generator-developed designs [11], LL log-likelihood, MO mobility, Ngene modified Fedorov designs constructed in Ngene [9], Obs number of observations, P p-value, PD pain/discomfort, R Bayesian D-efficient design algorithm implemented in R by Oppe and van Hout [14] based on Rose et al. [15], SAS modified Fedorov designs constructed in SAS [10], SC self-care, SE standard error, UA usual activitiesSignificant interaction terms are in boldTable 3Estimates from multinomial logit models with full attendance interactions for designs with no overlapGendevNgeneSASRCoefSEPCoefSEPCoefSEPCoefSEPMO2− 0.2720.0850.001− 0.0830.0850.329− 0.1770.0850.0360.0310.1160.791MO3− 0.2140.0870.014− 0.1570.0880.075− 0.2760.0870.001− 0.0380.0960.690MO4− 0.5990.087< 0.001− 0.7230.093< 0.001− 0.8110.090< 0.001− 0.4470.108< 0.001MO5− 0.8530.089< 0.001− 0.9890.100< 0.001− 1.0990.090< 0.001− 0.6630.109< 0.001SC2− 0.1510.0840.074− 0.2450.0850.004− 0.1100.0860.200− 0.0070.1040.945SC3− 0.1910.0870.027− 0.1430.0880.104− 0.1040.0860.2240.0180.1010.860SC4− 0.4290.087< 0.001− 0.6810.092< 0.001− 0.3970.087< 0.001− 0.3640.100< 0.001SC5− 0.5970.090< 0.001− 0.6870.093< 0.001− 0.6580.087< 0.001− 0.6800.118< 0.001UA2− 0.1290.0850.1280.0550.0910.545− 0.1100.0850.198− 0.1520.1110.170UA3− 0.2100.0870.016− 0.0610.0950.518− 0.1360.0860.115− 0.0580.1110.601UA4− 0.2810.0870.001− 0.2380.0870.006− 0.1990.0870.022− 0.4180.099< 0.001UA5− 0.3840.089< 0.001− 0.3990.085< 0.001− 0.2670.0900.003− 0.6400.108< 0.001PD2− 0.1430.0830.084− 0.1310.0920.155− 0.0940.0860.2760.1100.1120.328PD3− 0.2950.0850.001− 0.2750.0920.003− 0.1240.0860.1510.0690.1270.587PD4− 0.4930.083< 0.001− 0.5170.092< 0.001− 0.4850.082< 0.001− 0.3750.092< 0.001PD5− 0.7060.087< 0.001− 0.6940.095< 0.001− 0.6020.085< 0.001− 0.5430.119< 0.001AD20.0470.0830.570− 0.1210.0860.160− 0.3060.084< 0.0010.1010.1060.342AD3− 0.1370.0830.100− 0.0810.0900.369− 0.3740.086< 0.001− 0.1820.1240.142AD4− 0.5820.083< 0.001− 0.7330.095< 0.001− 0.7930.090< 0.001− 0.6150.117< 0.001AD5− 0.5730.087< 0.001− 0.8300.090< 0.001− 0.8450.089< 0.001− 0.7730.109< 0.001Interaction with full attendance MO2− 0.2070.2270.3600.0830.2340.724− 0.3620.2620.167− 0.1530.3840.690 MO3− 0.7060.2460.004− 0.7090.2440.004− 0.0870.2980.771− 0.8850.2600.001 MO4−1.3690.276< 0.001− 0.8980.255< 0.001− 0.8820.3280.007−1.5260.381< 0.001 MO5−1.9950.273< 0.001−1.5170.290< 0.001−1.3240.325< 0.001−1.7880.367< 0.001 SC2− 0.2920.2210.185− 0.3820.2300.097− 0.3990.2820.156− 0.7850.3100.011 SC3− 0.1690.2530.506− 0.9730.226< 0.001− 0.4520.2840.111−1.2570.336< 0.001 SC4−1.2410.259< 0.001−1.4790.259< 0.001−1.9480.269< 0.001−1.9670.358< 0.001 SC5−1.7430.291< 0.001−1.4230.271< 0.001−1.9770.305< 0.001−2.1780.385< 0.001 UA2− 0.1050.2190.6310.0710.2410.768− 0.4390.2730.109− 0.0780.3240.809 UA3− 0.2170.2620.408− 0.1810.2610.488− 0.6030.2720.027− 0.3210.3130.305 UA4− 0.5450.2660.040− 0.9300.234< 0.001−1.6530.341< 0.001−1.3540.304< 0.001 UA5−1.3440.265< 0.001−1.1120.227< 0.001− 2.1910.363< 0.001− 1.5620.306< 0.001 PD20.1000.2120.637− 0.3240.2340.165− 0.1290.2660.629− 0.2590.3510.461 PD3− 0.0730.2170.736− 0.6410.2360.007− 0.2540.2830.369− 0.6110.3680.097 PD4− 1.0650.214< 0.001− 1.7000.263< 0.001− 1.2970.288< 0.001− 1.4850.329< 0.001 PD5− 1.7040.257< 0.001− 1.7180.278< 0.001− 1.9030.404< 0.001− 1.7610.364< 0.001 AD2− 0.1820.2140.395− 0.5320.2310.022− 0.8720.2670.001− 1.2930.337< 0.001 AD3− 0.5390.2180.013− 1.0280.247< 0.001− 0.6700.2360.005− 2.1080.407< 0.001 AD4− 1.5970.234< 0.001− 1.3130.278< 0.001− 2.0010.368< 0.001− 3.6380.477< 0.001 AD5− 2.2900.266< 0.001− 1.6190.270< 0.001− 1.5990.342< 0.001− 4.140**0.588< 0.001Significant interaction terms (n)12151315 AIC4112375238753999 BIC4360399941224247 LL− 2016− 1836− 1898− 1959AD anxiety/depression, AIC Akaike information criterion, BIC Bayesian information criterion, Coef coefficient estimate, Gen-dev generator-developed designs [11], LL log-likelihood, MO mobility, Ngene modified Fedorov designs constructed in Ngene [9],* Obs* number of observations, P p-value, PD pain/discomfort, R Bayesian D-efficient design algorithm implemented in R by Oppe and van Hout [14] based on Rose et al. [15], SAS modified Fedorov designs constructed in SAS [10], SC self-care, SE standard error, UA usual activitiesSignificant interaction terms are in bold
MNLs with main effects only were then fitted using data from both all respondents and full attenders only (unanchored and anchored MNL results can be found in ESM-B). Figure 2 shows the RAI scores derived from these MNL results. The RAI scores for self-care, usual activities, and pain/discomfort varied across designs, but there was no clear pattern. A notable observation was found when comparing RAI for all respondents versus full attenders, especially in the dimensions of mobility and anxiety/depression. Mobility consistently showed higher importance when using the data before exclusion as opposed to the data from only full attenders. Conversely, anxiety/depression had greater importance assigned to this dimension among full attenders than among their counterparts.Fig. 2. Relative attribute importance (RAI). A all respondents, AD anxiety/depression, F full attenders, Gen-dev generator-developed designs [11], MO mobility, Ngene modified Fedorov designs constructed in Ngene [9], PD pain/discomfort, R Bayesian D-efficient design algorithm implemented in R by Oppe and van Hout [14] based on Rose et al. [15], SAS modified Fedorov designs constructed in SAS [10], SC self-care, UA usual activities
External Validity of the ECLC Model
Table 4 summarises the indicators of external validity across the three attendance classes identified by the ECLC model. Respondents classified as non-attenders had the highest overall rate of straightlining (3.9%), whereas partial attenders showed moderate levels (1.2%) and full attenders the lowest (0.4%). Median completion times mirrored this pattern: non-attenders spent the least time on the choice tasks (3.2 min) and on the entire survey (7.6 min), followed by partial attenders (5.0 and 8.7 min, respectively), and finally full attenders, who spent the most time on both the tasks (6.3 min) and the survey (10.2 min).Table 4. Straightlining, completion time, and feedback questions across three attendance classesFull attendance (N = 493)Partial attendance (n = 705)Non-attendance (n = 234)Straightlining Left-most option2 (0.4)8 (1.1)6 (2.6) Right-most option0 (0.0)1 (0.1)3 (1.3) Total2 (0.4)9 (1.2)9 (3.9)Completion time DCE choice tasks6.35.03.2 Entire survey10.28.77.6Feedback question^a^ Task difficult^b^45 (9.7)87 (12.8)39 (17.3) Difficult to tell difference^c^52 (11.2)124 (18.3)60 (26.6) Difficult to imagine^d^84 (18.1)138 (20.4)51 (22.7) Consider whole description^e^386 (82.5)483 (71.3)125 (55.6)Data are presented as minutes or as N (%)DCE discrete choice experiment^a^These questions were optional, and the reported percentages were calculated only among respondents who provided answers^b^Percentage of respondents who selected ‘strongly agree’ or ‘agree’ for the question, "I found the tasks difficult"^c^Percentage of respondents who selected ‘strongly agree’ or ‘agree’ for the question, "I found it difficult to tell the difference between the descriptions"^d^Percentage of respondents who selected ‘strongly agree’ or ‘agree’ to the question, "I found it difficult to imagine the scenarios"^e^Percentage of respondents who selected ‘strongly agree’ or ‘agree’ to the question, "I considered the entire description"
Feedback question responses aligned with these differences in response behaviour. Non-attenders were more likely to report that the tasks were difficult (17.3% vs. 12.8% of partial attenders and 9.7% of full attenders) and to find it difficult to tell the difference between the options (26.6% vs. 18.3% and 11.2%, respectively). In addition, only 55.6% of non-attenders strongly agreed or agreed that they considered the entire description when making their choices, in contrast to 71.3% of partial attenders and 82.5% of full attenders. These findings provide strong evidence for the external validity of the ECLC model’s classification of full attenders, partial attenders, and non-attenders, reflecting correspondingly high, moderate, and low levels of engagement and attentiveness.
In addition, demographic characteristics across the three attendance classes are presented in Table 3 in ESM-B. Non-attenders were more likely to be male, younger, and single than both full or partial attenders. No apparent differences were observed in education, household income, or region among the three classes.
Discussion
Our analysis revealed significant variations in attribute attendance across diverse design construction methods. Moreover, the incorporation of attribute overlap yielded a significant enhancement in attribute attendance levels. In particular, modified Fedorov designs (implemented in Ngene and SAS) with attribute overlap had the highest attribute attendance rates, supporting the use of modified Fedorov designs with attribute overlap to enhance respondent engagement.
The ANA probabilities within designs without overlap in this study are in line with the results from the comparison study conducted by Iles and Rose [5] but inconsistent with the findings of Yao et al. [6]. Iles and Rose [5] found a higher percentage of ANA in answering efficient design surveys than with orthogonal designs, among both illiterate and literate respondents. However, Yao et al. [6] reported conflicting findings: that the likelihood of belonging to the class with full attendance was greater in efficient designs than in generator-developed designs. The disparate findings may be explained by the different levels of perceived difficulty of the survey. Iles and Rose [5] focused on preferences for healthcare providers among illiterate and literate respondents in India, whereas Yao et al. [6] recruited respondents from the general New Zealand population to answer questions about threatened species in planted forests. Several factors may contribute to the variance in full attendance rates, such as perceived difficulty levels, familiarity with the topic of the survey, and population characteristics. Exploring the impact of these factors on attribute attendance is a valuable potential area for future research.
Another important finding is that attribute overlap substantially enhanced the level of attribute attendance across the dimensions of the EQ-5D-5L, regardless of the methods employed in design construction. This finding aligns with the conclusions drawn by Jonker et al. [12], which suggested that attribute overlap leads to a rise in the average number of attended attributes from two to three. In our study, when examining the Ngene design, we observed that attribute overlap increases the full attendance rate significantly from 24.6% to 54.2%. This indicates that, even with the implementation of attribute overlap, approximately 50% of the respondents did not engage with at least one dimension of the EQ-5D-5L despite the use of attribute overlap. ANA analysis can serve as a useful quality-control tool for the inclusion and exclusion of respondents in data analysis. Ideally, the analysis should exclude respondents who did not attend to any attributes, as their choices are likely to be driven by heuristic decision-making rather than reflective of their true preferences. However, partial non-attendance may indicate either a lack of attention or a deliberate decision reflecting genuine indifference. Additional robustness checks may be warranted, particularly for respondents who focus exclusively on a single attribute.
The consideration of ANA has an influence on the coefficients of the EQ-5D-5L in health state valuations. This impact was more pronounced within the mobility and anxiety/depression dimensions. Upon ANA adjustment, the utility decrement in the mobility dimension decreased, whereas the decrements associated with anxiety/depression increased. Although this study did not directly test the order effects, it may be that respondents, especially partial attenders, prioritised dimensions presented earlier in the sequence of mobility, self-care, usual activities, pain/discomfort, and anxiety/depression. This possibility is supported by previous research indicating that the dimension order has some influence on the valuation of the EQ-5D-5L, using methods such as DCE_TTO_ [21], time trade-off (TTO) [22], and DCE [22]. In contrast, Mulhern et al. [23] observed no significant impact of dimension order in DCEs with duration. This discrepancy highlights the potential variability in how different preference-elicitation techniques may interact with dimension ordering. Therefore, further research is warranted to dissect the influence of dimension order on EQ-5D-5L valuations across various elicitation methods.
Preference heterogeneity is another possible explanation of the impact of ANA on the coefficients of the EQ-5D-5L. Within the framework of ECLC models, preference homogeneity among respondents is assumed. However, ANA may occur when respondents do not consider attributes because they are not important to them or arise from respondents simplifying choice tasks by ignoring attributes as a type of decision heuristic. Indeed, the impact of ANA on the valuation of EQ-5D-5L varied significantly between these two ANA assumptions [16]. A substantial impact of ANA on estimates was observed when assuming decision heuristics for ANA, whereas the impact was less pronounced under the preference-based explanation of ANA [16]. In our study, respondents placing lower importance on a particular attribute might be inaccurately classified as non-attenders. In alignment with a study by Hole et al. [24], the findings may reflect the upper limits relating to ANA within this dataset.
Conclusion
Attribute attendance varied across the different design construction methods, and the implementation of attribute overlap significantly improved attendance rates. Modified Fedorov designs implemented in Ngene or SAS with attribute overlap are recommended to reduce ANA and enhance respondent engagement in DCEs. ANA models can be used to exclude respondents who did not attend to any attributes and to identify partial attenders for further robustness checks, improving the quality of data for analysis.
Supplementary Information
Below is the link to the electronic supplementary material.Supplementary file1 (DOCX 58 KB)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Choice Metrics. Ngene 1.1.2 user manual and reference guide. Technical report, Australia, 2014. Retrieved from http://www.choice-metrics.com/. Accessed 20 Mar 2019.
- 2Kuhfeld W. Marketing Research Methods in SAS (Tech. Rep.). SAS. 2010. http://support.sas.com/techsup/technote/mr 2010.pdf. Accessed 25 Aug 2024.
- 3Mulhern B. Broadening the measurement and valuation of health and quality of life [Doctoral dissertation, University of Technology Sydney]; 2020. UTS Digital Thesis Collection. https://opus.lib.uts.edu.au/handle/10453/142429 info:eu-repo/semantics/open Access. Accessed 25 Aug 2024.
- 4Oppe M, van Hout B. The “power” of eliciting EQ-5D-5L values: the experimental design of the EQ-VT. Euro Qol Working paper 17003; 2017. https://euroqol.org/wp-content/uploads/2016/10/Euro Qol-Working-Paper-Series-Manuscript-17003-Mark-Oppe.pdf. Accessed 25 Aug 2024.
- 5R Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. 2023. https://www.R-project.org/. Accessed 10 Jun 2024.
- 6Posit team. R Studio: Integrated Development Environment for R. Posit Software, PBC, Boston, MA. 2023. http://www.posit.co/. Accessed 10 Jun 2024.