Development and external validation of a risk prediction score (DASHI) for cardiovascular events following acute respiratory infections: derivation and validation retrospective cohort study
Joseph J. Lee, Constantinos Koshiaris, Cynthia Wright-Drakesmith, Jennifer A. Davidson, Charlotte Warren-Gash, F.D. Richard Hobbs, James P. Sheppard

TL;DR
Researchers developed and validated a tool called DASHI to predict cardiovascular risks in patients with acute respiratory infections within 28 days.
Contribution
The DASHI score is a new clinical prediction tool for short-term cardiovascular risk following acute respiratory infections.
Findings
The DASHI score includes five variables and showed good discrimination (AUC 0.85) and calibration.
It was validated in over 6 million patients from UK primary care electronic health records.
The tool helps clinicians estimate cardiovascular complication risks in patients with acute respiratory infections.
Abstract
Acute respiratory infections increase the short-term risk of myocardial infarction (MI) and stroke in primary care patients. Clinical guidelines for acute respiratory infections in primary care do not consider the risk of cardiovascular events, and CVD risk prediction tools target long-term risk. We aimed to develop and validate a prediction tool for the risk of cardiovascular disease events within 28-days of acute respiratory infection. The design was a retrospective cohort study using two different databases of routinely collected data from electronic health records from January 1999 to December 2019. We used Clinical Practice Research Datalink (CPRD) Aurum data to derive models, and CPRD GOLD data from a different population for external validation. This data is from UK primary care, with data linkage to Hospital Episode Statistics, Office of National Statistics mortality data, and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
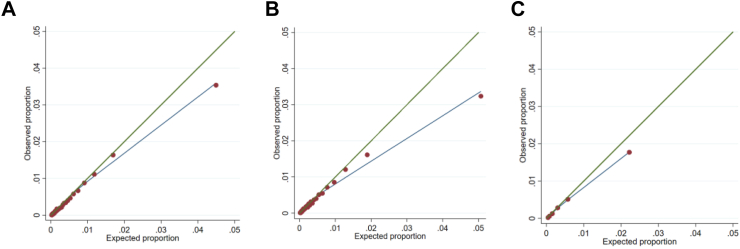 Figure 1
Figure 1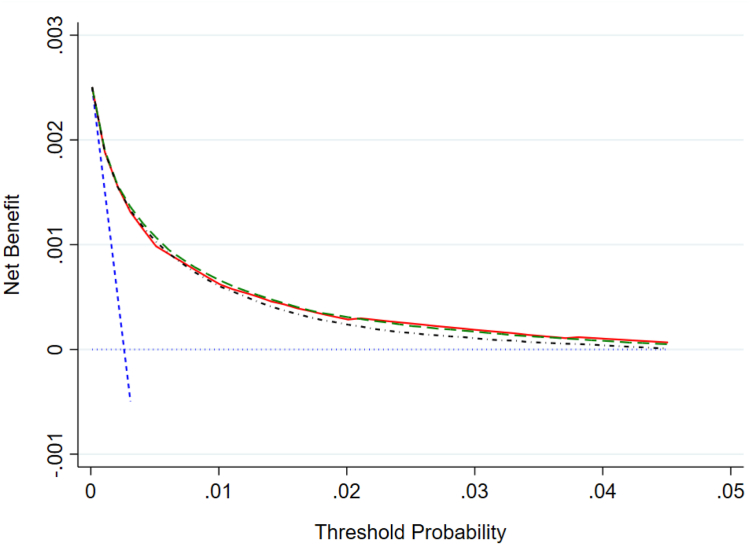 Figure 2
Figure 2- —10.13039/100010269Wellcome Trust
- —NIHR
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAcute Myocardial Infarction Research · Chronic Obstructive Pulmonary Disease (COPD) Research · Cardiac Health and Mental Health
Research in contextEvidence before this studyWe searched Medline from inception to August 9th 2024 with the terms ‘Acute respiratory infection’ AND ‘myocardial infarction OR stroke’ AND ‘prediction’. This returned 419 results. There were studies describing the association between infections and myocardial infarction and stroke, but none attempting to predict the risk of CVD events after acute respiratory infection.Added value of this studyWe have developed and validated the DASHI score to predict the risk of a primary cardiovascular event in the 28 days following acute respiratory infection, using data from 6.4 million patients. The DASHI score comprises five clinical variables: Diabetes, Age, Smoking, Heart failure, and Infection type.Implications of all the available evidenceRespiratory infections increase the risk of cardiovascular events. The absolute risk of primary CVD events is low. The DASHI score can help predict this risk, but the clinical utility is limited by low prevalence.
Introduction
Acute respiratory infections increase the short-term risk of myocardial infarction (MI) and stroke in primary care patients.1 Acute respiratory infection approximately quadruples the background risk of an acute cardiovascular event occurring in the following four weeks.2, 3, 4, 5, 6, 7 The risk is highest in the first few days. This relationship between cardiovascular disease (CVD) events and infections is well established.4
Post-infection CVD events are not restricted to a particular infectious organism. Considerable epidemiological evidence relates to undifferentiated acute respiratory infections, and there is evidence relating to a variety of organisms.5 COVID-19 also increases short-term CVD event risk, but most of the existing evidence predates this pandemic.3 Influenza and pneumococcal infections are both associated with CVD events, but other organisms are also implicated in the seasonality of CVD.8 There is evidence that preventing infection mitigates CVD risk, including trials that show influenza vaccine reduces CVD events and observational evidence of the same association for pneumococcal vaccines.9, 10, 11, 12
Whilst CVD events appear to be a serious complication of acute respiratory infection, at present clinical guidelines for acute respiratory infections in primary care do not consider the risk of CVD events.1^,^13 There may be an opportunity for intensifying CVD prevention during infections and for the weeks following infection. Informing patients of their risk could help conversations about primary prevention, safety netting, and future vaccinations.
There are also precedents for short-term risk modification at peaks of CVD event risk. High-risk transient ischaemic attack (TIA) or minor stroke also herald a short high-risk period for stroke.14 Long-term antiplatelets are not recommended for primary prevention, because the risk of bleeding outweighs the benefits.1 However, following TIA, dual antiplatelet therapy, plus a statin, for a few weeks reduces the risk of stroke without an unacceptable increase in the risk of bleeding.15 Investigating analogous strategies in infections is a research priority. To develop such evidence would first require a validated method to identify people with infections who are at increased risk of CVD events.
There are many CVD risk prediction models, but these typically aim to predict long-term or lifetime risk based on demographic and lifestyle factors, and chronic health conditions. None considers fluctuating short-term increases in CVD risk associated with acute respiratory infections.16 We therefore aimed to derive, and externally validate, a parsimonious prediction model for acute respiratory-infection related CVD event risk.
Methods
Aim
Our aim was to produce a clinically useful prediction tool for CVD event risk for people with acute respiratory infection.
Objectives
Our first objective was to derive a simple statistical prediction model; model one, comprising a small number of clinical variables. Objective two was to derive another more comprehensive model; model two, including all the predictors from model one with extra predictors. Our third objective was to externally validate models one and two. We then derived and validated a points-based clinical prediction score, and compared the score and statistical models with decision curve analysis.
Data source
We used two different retrospective observational cohorts to derive and validate the statistical models and prediction score.
The cohorts were derived from data in the Clinical Practice Research Datalink (CPRD) GOLD and Aurum databases. These are databases of UK primary care records from different electronic clinical records systems. These data were linked to Hospital Episode Statistics (HES) and Office of National Statistics (ONS) data. These were Index of Multiple Deprivation (IMD–an official measure of deprivation in England) and ONS mortality data from death certificates (Supplementary methods). The collection and classification of sex was out of our control, as these are routinely collected data provided by CPRD.
Ethics
The CPRD Independent Scientific Advisory Committee (ISAC) approved the pre-specified protocol (21_000380). This study was undertaken under CRPD’s generic ethics approval for observational studies that make use of anonymised data and have prior approval of the ISAC (Multiple Research Ethics Committee ref. 05/MRE04/87). CPRD has ethics approval from the Health Research Authority to support research using anonymised patient data under which this study was deemed exempt from obtaining informed consent (National Research Ethics Service Committee (NRES) ethics approval 21/EM/0265).
Population
The index date was the date of first diagnosis with acute respiratory tract infection (RTI) after age 40. There was no upper age limit. We followed patients for 28 days from the index date.
We chose to include people over the age of 40 years because of a low risk of events in people under this age. There is also precedent for using this cutoff—it was used in QRISK2–the clinical model most used for stratifying the primary prevention population in the UK.17 We used 28 days as this period has been consistently associated with an increase in risk following infections in primary care.5
It is possible that some patients had prior CVD, but this was not recorded. We suspect this would be minimal, as this misclassification would require no record in either primary care or secondary care records of an important event. This would reflect the information available to the GP at use of the model, and so clinical reality.
We identified acute respiratory infections by codes in the primary care record (https://github.com/Protocols-For-Research/CPRD-codes-CVD-infection-risk). We excluded infections likely to be chronic. We used three mutually exclusive categories of acute respiratory tract infection (upper, lower, and lower with pneumonia), plus influenza-like illnesses (ILI) which was not exclusive to the other three categories. We defined upper respiratory tract infections (URTIs) to include anatomical sites at or above the larynx. Lower respiratory tract infections (LRTIs) included any codes for acute infections below the larynx. Infective exacerbations of chronic obstructive pulmonary disease (COPD) we included as LRTIs. We defined LRTI with a diagnosis of pneumonia (pneumonia) as a LRTI with one or more codes identifying pneumonia. If a patient had codes for more than one category we allocated the more severe; pneumonia trumped LRTI and LRTI trumped URTI, making these mutually exclusive. Whilst we were able to identify codes for ILI, these overlapped the other categories. Some of the codes for influenza and ILI don’t indicate an anatomical site; other codes specify influenza causing an URTI or a pneumonia.
We excluded patients with a history of CVD events (defined as below) and those with less than 1 year at a practice, to avoid recording old CVD diagnoses as new, which could happen when patients register at CPRD practices for the first time.18
Outcome
The outcome was a composite of cardiovascular codes, occurring within 28 days of a diagnosis of acute respiratory infection. It included new myocardial ischaemia (myocardial infarction, angina, acute coronary syndromes, or ischaemic cardiomyopathy), new cerebrovascular events (stroke, and TIA), and deaths from these causes.
We used primary and secondary care clinical codes, and ONS mortality records to identify outcomes.
Outcome details
The outcome is a combination of cardiovascular events, within 28 days of the acute respiratory infection. This was a composite of new diagnoses of myocardial ischaemia, stroke, TIA, or deaths from these. We thought this approach came close to the ‘four point Major Adverse Cardiovascular Event (MACE)’ outcome used in trials of antidiabetic medications and largely caused by atherosclerosis.19 We could not use ischaemic stroke as an outcome, because stroke type is poorly differentiated in CPRD data.20 We did not include generic ‘heart failure’ diagnosis in the outcome, as it may be due to aetiology other than ischaemia, though we included specifically coded new ischaemic cardiomyopathy. We did not include peripheral vascular events such as limb ischaemia or claudication in the outcome. Instead, we included markers of peripheral arterial disease in the candidate predictors. Similarly, we did not include other chronic cardiac conditions in the outcome as they would not be triggered by a RTI (valve disease, congenital disease etc) and so included chronic heart disease as a predictor instead.
As we used routinely collected datasets there was no blinding of the outcome assessors—and no risk of this study biasing these clinicians’ historic assessments.
The outcome we derived from CPRD, ONS mortality and HES datasets. Hospital Episode Statistics data includes diagnosis data and procedure data.
CPRD recommend the use of search strategies rather than specific codelists.21 We searched CPRD code files using Stata. We aimed to make code lists specific, rather than over-sensitive. As an example, we did not use codes for referrals to chest pain or TIA clinics in the outcome, as many of these patients go on have CVD events ruled out.
Codes employed
CPRD codes do not map directly to ICD codes, and so we had to develop our own codelists. The type and site of infection is very likely prone to misclassification. In the UK primary care situation diagnosis is clinical, without test. For example, clinical risk scores for influenza have diagnostic performance that is moderately predictive.22 The imperfect data reflects the information that the clinicians would have and is likely a proxy for severity of infection. Misclassification would bias towards a lack of association between the misclassified variables and CVD, but despite this we have shown a strong association with outcomes, so it does not appear to have greatly impacted the validation results.
The CPRD codes we used can be found here: https://github.com/Protocols-For-Research/CPRD-codes-CVD-infection-risk. The ICD and OPCS codes used for the outcome are in the Supplementary materials.
Predictors
We identified predictors from previous publications and expert clinical review. We identified 54 clinical variables associated with CVD, severe acute respiratory infections, or both. Clinical variables included demographics, medications, laboratory tests and physical measurements. To prioritise variables for inclusion four general practitioners with an interest in cardiology assessed their perceived importance. The clinicians ranked the clinical variables in order of importance considering both association with CVD, and the accuracy of coding (Supplementary appendix).
In the absence of previously published models, we generated two statistical models to assess the trade-off between complexity and performance. We then chose a model to develop a risk score.
We included infection type in both models. There were three exclusive categories of infection type; Upper Respiratory Tract Infection (URTI), Lower Respiratory Tract Infection (LRTI), and LRTI with a diagnosis of pneumonia. We also included an additional binary variable for influenza diagnosis, which was not exclusive of the other infection types.
In model one we also included the top clinical variables as ranked by the clinical experts. Model two included additional clinical variables from further down the ranking and the lowest ranked were not included.
Predictor selection
We included infection type in all models. Four General Practitioners (GPs) with special interest in cardiology helped rank the other clinical variables. We asked them to rank the relevance of 54 variablesd from minus three to three. We asked them to consider the completeness of coding as well as clinical relevance. We standardised each GP’s ratings into Z scores to express the relative importance they gave each variable on the same scale, with a mean of zero and a standard deviation of one. We then combined these scaled scores by arithmetic mean across GPs to give a mean Z score. We used this overall mean ranking to order the variables. Model one included those variables with a mean Z score >1 and model two included variables with a mean Z score >0. Variables with a mean Z score of 0 or less were not included in models.
By ‘clinical variable’, we mean a diagnosis, demographic, or test, as ranked by the experts, rather than a term in a statistical model. For example, smoking status was a single clinical variable for clinicians to rank but is represented in the statistical models as multiple categorical variables. These represent people who have never smoked, ex-smokers, light smokers (<10 cigarettes per day), moderate smokers (10–19 cigarettes per day), heavy smokers (20+ cigarettes per day), and those who smoke an unquantified amount.
We derived all the predictors from the clinical records and linked datasets (we did not collect other data). We extracted covariates from the clinical record before the index date. We had to define a relevant time window before the infection to search for relevant codes. We used different time windows for different variables. For cholesterol to HDL ratio, BMI, and systolic blood pressure, we used the most recent record in the five years before the index date. Cancers also had a five-year limit. We took codes for other diagnoses, and family history, from the entire record prior to the index date. In order to better identify ex-smokers, and the amount people smoked, we used the two most recent smoking records. We defined smoking categories as: never smoked, ex-smoker, light (<10 cigarettes per day), medium (10–19 cigarettes per day), heavy (20+ cigarettes per day) and amount unknown.
Refinement of variables
Respiratory infections
The coding systems shaped the respiratory infection diagnosis variable. We were able to classify some respiratory infections into exclusive groups: upper respiratory tract infection (URTI), lower respiratory tract infection (LRTI), and LRTI with pneumonia diagnosis are categories without overlap codes suggesting infections from the trachea up we counted as URTI, those below this were LRTIs, and specific codes for pneumonia, or it’s complications, were used for pneumonia. Influenza was not an exclusive category—there are codes for influenza without specifying severity or site, but other codes for influenza associated with URTIs, LRTIs, and pneumonia. Influenza is therefore not an exclusive category. We classed exacerbations of Chronic Obstructive Pulmonary Disease (COPD) as lower respiratory tract infection, unless there were codes indicating the exacerbation was a pneumonia. To avoid collinearity COPD was not included as a separate variable.
Covariates
We refined, combined and dropped some of the clinical categories after the clinical experts had prioritized them. These were COPD, hypertension, dementia, diabetes subtypes, non-steroidal anti-inflammatories, erectile dysfunction, chronic kidney disease, peripheral vascular disease, cancer subtypes, family history of CVD, and vaccination status.
The top ranked variables for model one, before refinement into the final model were: Age, heart failure, diabetes, smoking status, chronic kidney disease, peripheral vascular disease and COPD. For initial model two, we included those in model one plus variables further down the ranking. The ranking continued: systolic blood pressure, sex, cholesterol to HDL ratio, BMI, atrial arrhythmias, dementia, anticoagulants, NSAIDS, antiplatelets, antihypertensives, rheumatoid arthritis, statin use, platelets, CRP, erectile dysfunction, other chronic heart diseases (including valve disease, congenital disease), IMD decile, haematological cancers, solid cancers, family history of CVD in first degree relative less than 60 years of age, and Pneumococcal vaccine.
We first defined family history of CVD as an event in a first-degree relative aged less than sixty, reflecting the definition used by QRISK3.17 Unfortunately, the coding systems do not include codes for this. Instead, we defined a high-risk family history as being a CVD aged less than 65 years if the first-degree relative was female, and fifty-five if male.
We simplified variables by combining rare and overlapping categories. We combined diabetes mellitus type one (which was rare), with type two diabetes and diabetes of other and unspecified types. We did not include the strongly correlated ‘glucose lowering medications’. Haematological cancers were uncommon, so we combined them with solid cancers. We also combined peripheral vascular disease with chronic kidney disease and erectile dysfunction. These three predictors were sparse, and are diagnoses that can have common cause in underlying atherosclerosis. Over the course of the study, the UK was introducing various pneumococcal vaccines against different serotypes, and for different populations (for over 65’s from 2003 for example), so we did not include pneumococcal vaccination as a predictor.23 Dementia was the only variable excluded on the basis of odds ratio, which was 1.00. No variable selection methods were used that rely on p values because we considered it likely the size of the dataset would lead to very small p values for every variable.
Statistics
We calculated baseline descriptive statistics in both cohorts including by outcome status. We estimated means and standard deviations for continuous variables, and numbers and percentages for categorical variables.
We calculated sample size calculations for model derivation before study protocol approval using methods by Riley et al.24 We based the calculation on preliminary counts in CPRD Gold data; this gave us a conservative outcome prevalence of 0.089%. We aimed for a global shrinkage factor of >0.995. We assumed a maximum of 50 candidate variables (including transformations and interactions). We also checked we would meet the criteria of an absolute difference of <0.05 in apparent and adjusted Nagelkerke’s R^2^, and a margin of error in outcome proportion estimates for null model <0.05. We calculated 61,198 patients would be enough to achieve these criteria.
We also performed a post-hoc sample size calculation for model validation. Derivation sample sizes tend to need to be larger than validation samples, so we relied on this in the protocol. In addition, at the point of writing the protocol we did not have the results from the derivation to use for the calculation. We used the user written Stata package pmvalsampsize, using estimates from internal calibration of the DASHI score.25 We specified a prevalence of 0.3%, a C statistic of 0.84, and a calibration slope of 1.07. We modelled the distribution of log predicted probabilities with the results from the development data: a skewed normal distribution with a mean of −7.074499 and a variance of 1.030443, skewness of 1 and kurtosis of 4. This returned a result of 115,597 patients being required, with estimating the calibration slope as the most data hungry calculation (observed to expected ratio required 5510 and the C statistic 20,525). Our dataset exceeded these numbers.
Missing data
We used the same methods in each cohort. If there were no codes for binary variables prior to the index date, we assumed the disease or prescription was absent.
For continuous and categorical variables with missing data, we used multiple imputation and missing indicator methods. We imputed continuous variables (total serum cholesterol to HDL ratio, systolic blood pressure and body mass index (BMI)) after log transformation. Smoking status and IMD deciles we imputed as ordinal variables. We used five imputations for model one, which had only one imputed clinical variable (smoking), and ten imputations for model two, which included all five imputed variables. We used multiple imputation chained equations (MICE), after ten burn-in iterations, with Stata command mi impute.26 We used ordinal logistic regression models for ordinal variables and linear regression for log transformed continuous variables. We assessed imputations for consistency by examining summary statistics and density plots for imputed data and the original dataset.
We also used missing indicator methods for recent blood tests. These were platelet count and C reactive protein. For these we used categorical variables, with missing indicators for unknown values. We categorised CRP results using thresholds used in clinical trials of point-of-care CRP testing: unknown, <5 mg/L, 5–19 mg/L, and 20 mg/L or more.27 We categorised platelet results by reference range into: unknown, thrombocytopaenia (<150 × 10^9^/L), within reference range 150 to (450 × 10^9^/L), and thrombocythaemia (>450 × 10^9^/L).
Model development
For both regression models, we excluded variables with odds ratios close to one in the initial modelling, and combined some variables, before fitting final models (Supplementary methods).
We used logistic regression, with fractional polynomials to model continuous variables, and did not use stepwise variable selection. We estimated apparent calibration and discrimination.
To choose a statistical model to convert to a clinical points score we considered diagnostic performance, and parsimony. This meant choosing the simpler model unless the more complex model gave a clinically important improvement in performance. To derive the score we specified a scaling factor based on age, so that two points in the score are equivalent to the risk from being 20 years older. We categorised age into 20 year periods, and used the midpoints to calculate risk. We then transformed the risk from other variables into points on this scale, rounding to the nearest point.28 We calculated predicted probabilities for the full range of possible scores. For context we calculated the ten-year risk that would achieve the equivalent 28 day risk each month.
External validation
We applied the models and score to the external dataset to estimate predicted probabilities. We used these predictions to estimate C statistics, expected/observed ratios, and draw calibration plots. We calculated measures in each imputed dataset and combined them with Rubin’s rules where appropriate. We report median predicted probabilities and expected to observed ratios over the imputed datasets.
Deriving C statistics had high time complexity (the computational time required increased non-linearly with the number of patients). To allow calculation of C statistics in these large datasets we divided each imputed dataset into 20 random subsets and derived the C statistic in each. We then used random effects meta-analysis to combine these results to get the overall C statistic for each imputed dataset (We did this as the default was random effects–there was no heterogeneity so the results would be identical with fixed effects models).
We examined the clinical utility of the statistical models and score using net benefit analysis across the range of predicted probabilities.29 Net benefit is calculated by subtracting scaled false positives from true positives, at each predicted probability. The scaling puts the false and true positives on the same scale. It is determined by the level of risk aversion. This is the amount of treatment that would be acceptable in false positives for each necessary treatment, so varies according to the treatment being considered. Different diagnostic strategies can be compared by plotting their net benefit against threshold probability. Net benefit analysis includes plotting the default strategies of treating everyone or no one, as well as comparing decision tools to each other.
Model performance at thresholds
We also calculated sensitivity, specificity, positive and negative likelihood ratios, and predictive values at probability and points thresholds. We applied probability thresholds as if they were to be used for a clinical decision, and calculated numbers of patients with true and false positives and negatives, above the threshold per 100,000 peopcaveatle.
To aid comparison within and between each of the logistic regression prediction models and the score, we calculated predictive performance in the external calibration population. As previous studies have concentrated on people with pneumonia as a high-risk group, we also evaluated the performance of this single covariate as a predictor of acute CVD events (Supplementary Table S4).30
We also calculated measures of diagnostic performance (sensitivity, specificity, negative and positive likelihood ratios and predictive values) at each point score for the DASHI (Supplementary Table S5).
We used Stata 17 and 18 for statistical analyses (Stata Corp. College Station Tx).
Patient and public involvement
This study was part of a larger project on infection-related CVD identification and prevention. We developed the project protocol with the input from PPI participants, who had been patients or carers for patients with experience of acute respiratory infection, cardiac disease, or both. They commented on the proposed work, and suggested changes that we incorporated in the final protocol.
Data source and linkages
The cohorts were derived from data in the Clinical Practice Research Datalink (CPRD) GOLD and Aurum databases. These are databases of UK primary care records from different electronic clinical records systems.
Aurum comes from practices in England that used EMIS® software (Egton Medical Information Systems, Leeds, UK), it covers about 13% of the population of England.31 GOLD data comes from different practices across the United Kingdom that used Vision® software (Cegedim Healthcare Solutions, London, UK).32 Gold covers about 7% of the population.32 The model development dataset came from CPRD Aurum. We used CPRD GOLD data for validation. We excluded patients from Aurum if they appeared in both datasets. Both datasets are representative of the wider patient population in terms of deprivation, ethnicity and age.31^,^32 They provide coded data, rather than free text. Clinicians code the data in the process of routine clinical care, so we are not able to identify the processes that lead to diagnoses.
We used data from 1st January 1999 to 31st December 2019. CPRD datasets are linked to Hospital Episode Statistics (HES) and Office of National Statistics (ONS) data from the start of 1999. The end of the period was the latest available data at the start of the project and preceded the start of the UK’s COVID pandemic. The ONS datasets were Index of Multiple Deprivation (IMD) and ONS mortality data from death certificates.
Data linkages
The Clinical Practice Research Datalink (CPRD) provided the primary care data (CPRD GOLD and Aurum from which we extracted the cohorts), to the Nuffield Department of Primary Care Sciences under a departmental licence. CPRD provided data linkages to the study population after extraction. These are person-level data, linked at that level.
Index of multiple deprivation
IMD is the official measure of relative deprivation in small areas in England.33 The areas have about 1500 people in them. ONS estimates deprivation using a measure that covers seven domains: income, employment, education, skills and training, health and disability, crime, barriers to housing and services, and living environment. They then rank areas by score; IMD is a relative, rather than absolute measure.
Aurum data were linked to IMD data except for 4% which were missing (154,961). GOLD data were linked to IMD data except for 50% which were missing (1,310,635). The discrepancy between these is mostly geographical—small area ONS data is applicable to England only, so patients living in Wales or Scotland are not linkable. Aurum data comes only from England, Gold data are from the whole of the U.K.
Mortality
All patients who died in the UK before the data cut was extracted would be included in ONS mortality data. In Aurum there were 110,691 patients who had died after the index date, mostly after the end of the study. Of these there were 1441 CVD deaths in the study period of 28 days post index date. In GOLD 48,689 patients died, and were linked to ONS mortality data. There were 252 CVD deaths in the study follow-up period in the GOLD cohort.
Hospital Episode Statistics
All hospital episodes of care are linked to CPRD. Initially patients were identified in CPRD data as having had no prior CVD, being over 40 years and presenting with an acute respiratory tract infection. Linkage to Hospital Episode Statistics data then allowed us to identify more patients with prior CVD, who we excluded (Supplementary Fig. S1).
Role of funding source
The funders had no role in study design, data collection, data analyses, interpretation, or writing of the report.
Results
Study population characteristics
The derivation dataset comprised 3,789,293 patients with first acute respiratory infections (Table 1). The mean age was 56.5 years (standard deviation, SD, 13.7). There were 11,996 cardiovascular events in the following 28 days (0.3%). The validation dataset had 2,636,981 patients. The mean age was 56.7 years (SD 13.6) and 6868 (0.3%) had outcome events. The majority of the populations were female (58%) but females made up 50% of those who had CVD events.Table 1. Characteristics of patients by CVD event outcome status in derivation and validation datasets.ContinuousDerivation datasetValidation datasetTotalNo CVDCVDTotalNo CVDCVDMeanSDMeanSDMeanSDMeanSDMeanSDMeanSDAge in years56.513.756.413.675.013.756.713.656.613.574.713.4Cholesterol: HDL ratio3.91.33.91.33.91.33.61.73.61.73.20.8Systolic BP mmHg131.217.1131.217.1138.020.2132.017.5132.017.5140.720.3BMI KgM^−2^27.85.827.85.827.06.227.75.727.75.727.05.9Categoricaln%n%n%n%n%n%Total3,789,293100%3,777,29799.7%11,9960.3%2,636,981100%2,630,11399.7%68680.3%Female2,185,25557.7%2,179,31657.5%593949.5%1,530,45458.0%1,527,01457.9%344050.1%URTI2,398,31263.3%2,395,64063.2%267222.3%1,669,85563.3%1,668,20063.3%165524.1%LRTI1,312,56934.6%1,305,94334.5%662655.2%918,98134.8%915,40834.7%357352.0%Additional pneumonia diagnosis78,4122.1%75,7142.0%269822.5%48,1451.8%46,5051.8%164023.9%Influenza189,5675.0%188,8515.0%7166.0%138,2165.2%137,8185.2%3985.8%Smoking status: Never smoked1,359,17935.9%1,355,72235.8%345728.8%875,67133.2%873,90833.1%176325.7% Ex-smoker860,96122.7%857,62922.6%333227.8%426,83716.2%425,60916.1%122817.9% Light smoker (<10/day)131,3703.5%130,8993.5%4713.9%118,4814.5%118,1754.5%3064.5% Moderate smoker (10–19/day)170,7014.5%170,2114.5%4904.1%184,0547.0%183,6457.0%4096.0% Heavy smoker (20+/day)122,4813.2%122,1023.2%3793.2%155,5095.9%155,1085.9%4015.8% Smoker, amount unknown285,5967.5%284,6847.5%9127.6%160,4156.1%159,8996.1%5167.5% Smoking data missing859,00522.7%856,05022.6%295524.6%716,01427.2%713,76927.1%224532.7%Diabetes300,9637.9%298,9057.9%205817.2%161,3976.1%160,4146.1%98314.3%Heart failure36,3251.0%35,3240.9%10018.3%27,9731.1%27,4081.0%5658.2%Chronic heart disease49,3481.3%48,7931.3%5554.6%30,6841.2%30,4381.2%2463.6%Atrial arrhythmia78,8072.1%77,4802.0%132711.1%50,8381.9%50,1811.9%6579.6%Markers of arterial disease289,6817.6%287,1027.6%257921.5%174,2046.6%173,0226.6%118217.2%Cancer123,6863.3%122,8753.2%8116.8%70,8392.7%70,4702.7%3695.4%Family history of CVD26,3700.7%26,2980.7%720.6%43390.2%43300.2%90.1%Anticoagulants65,7761.7%64,9001.7%8767.3%42,3571.6%41,9791.6%3785.5%Antiplatelets15,5720.4%15,1980.4%3743.1%10,8150.4%10,6230.4%1922.8%Antihypertensives747,89319.7%742,45719.6%543645.3%498,44118.9%495,54018.8%290142.2%Rheumatoid arthritis48,0981.3%47,7791.3%3192.7%34,2231.3%34,0401.3%1832.7%Statins424,84211.2%422,10711.1%273522.8%244,3129.3%243,1569.2%115616.8%Platelets x 10^9^/L Unknown platelets2,654,09870%2,647,46969.9%662955.3%2,023,12076.7%2,018,44976.5%467168% Thrombocytopaenia (<150)34,4870.9%34,1760.9%3112.6%18,2500.7%18,1080.7%1422.1% Platelets normal (150–450)1,078,15428.5%1,073,32528.3%482940.3%583,54322.1%581,59122.1%195228.4% Thrombocytosis (>450)22,5540.6%22,3270.6%2271.9%12,0680.5%11,9650.5%1031.5%CRP mg/L CRP unknown3,510,76692.6%3,500,12192.4%10,64588.7%2,481,34894.1%2,475,01193.9%633792.3% CRP < 5139,7853.7%139,3803.7%4053.4%76,9492.9%76,8182.9%1311.9% CRP 5 to <20109,4792.9%108,9432.9%5364.5%62,7262.4%62,4852.4%2413.5% CRP ≥ 2029,2630.8%28,8530.8%4103.4%15,9580.6%15,7990.6%1592.3%Index of multiple deprivation: Most deprived decile336,6558.9%335,2158.8%144012%92,3573.5%91,9713.5%3865.6% Deprivation missing97,9412.6%97,8102.6%1311.1%1,310,63549.7%1,307,71049.6%292542.6%CVD = people with a cardiovascular event outcome in the 28 days following respiratory infection. Respiratory Tract Infection (RTI) categorised into upper (URTI), lower (LRTI) and pneumonia. Influenza is a separate, non exclusive category and can be included separately in addition to LRTI (default for influenza, unless coded to another site). Heart failure includes all non-ischaemic diagnoses. Chronic heart disease incluses valvular disease, hypertensive disease and congenital disease. Atrial arrhythmias include atrial tachicardias, fibrillation, and flutter. Diabetes includes type i, type ii, and other/unrecorded type. Markers of arterial disease includes markers of possible atherosclerosis: chronic kidney disease, peripheral arterial disease, and erectile dysfunction. Cholesterol: HDL ratio is serum total cholesterol/serum HDL cholesterol. CRP id C Reactive Protein. BMI is Body Mass Index.
Model development
The regression models comprised the clinical variables detailed in Table 2 (for model equations see Supplementary materials). The variable with the strongest association with CVD in models one and two was pneumonia (Odds ratio 10.59, 95% CI 9.98–11.24, in model one and 9.82, 95% CI 9.21–10.46 in model two). Other variables strongly associated with CVD were lower respiratory tract infection (OR 2.59, 95% CI 2.48–2.71, and 2.50 95% CI 2.38–2.63, respectively) and age (OR for each year increase 1.07, 95% CI 1.07–1.07, and 1.06 95% CI 1.06–1.07 respectively). Some variables reduced the predicted probabilities: influenza diagnosis lowered predicted risk in both models (OR 0.84, 95% CI 0.78–0.91, and 0.85, 95% CI 0.78–0.92, respectively). In model two, CRP less than 5 mg/L reduced predicted risk, compared to the baseline of unknown CRP (0.86 (0.77–0.96)). In model two predicted risk was also increased by antiplatelets (OR 2.12 95% CI 1.03–2.38) and anticoagulants (OR 1.13 95% CI 1.03–1.24). Internal apparent performance and calibration results were similar between models (median C statistics 0.88, with good calibration for both models) (Supplementary results: Supplementary Fig. S2 and Table S1).Table 2. Variables included in models, and contributions to risk prediction.VariablesModelContinuousModel one OR (95% CI)Model two OR (95% CI)DASHI scoreAgea1.07 (1.07–1.07)1.06 (1.06–1.07)40–59 years = 0 points, 60–79 = 2 points, 80+ = 4 pointsCholesterol: HDL ratio1.10 (1.08–1.13)Systolic blood pressureb Term one3.67 × 10^−6^ (3.99 × 10^−8^–3.33 × 10^−4^) Term two406.59 (58.56–2822.97)BMIb Term one0.12 (0.07–0.12) Term two1.08 (1.06–1.11)Categorical or binary RTI diagnosis URTIBaselineBaseline0 points LRTI2.59 (2.48–2.71)2.50 (2.38–2.63)1 point Pneumonia10.59 (9.98–11.24)9.82 (9.21–10.46)4 points Additional influenza diagnosis0.84 (0.78–0.91)0.85 (0.78–0.92) Smoking status: Never smokedBaselineBaseline Ex-smoker1.24 (1.19–1.30)1.14 (1.08–1.20)0 points for never or ex-smokers Light smoker (<10/day)1.69 (1.54–1.87)1.48 (1.32–1.66)1 point for any current smoking Moderate smoker (10–19/day)1.70 (1.52–1.89)1.50 (1.36–1.65) Heavy smoker (20+/day)1.90 (1.70–2.12)1.60 (1.44–1.79) Smoker, amount unknown1.61 (1.50–1.74)1.44 (1.33–1.56) Diabetes1.49 (1.42–1.57)1.32 (1.25–1.40)1 point Heart failure1.92 (1.79–2.05)1.67 (1.55–1.81)1 point Markers of arterial disease1.21 (1.15–1.26)1.04 (0.99–1.10) Male sex1.43 (1.37–1.50) Chronic heart disease1.30 (1.18–1.43) Atrial arrhythmia1.19 (1.10–1.29) Cancer0.93 (0.86–1.00) Family history of CVD1.28 (1.00–1.65) Anticoagulants1.13 (1.03–1.24) Antiplatelets2.12 (1.03–2.38) Antihypertensives1.30 (1.24–1.36) Rheumatoid arthritis1.20 (1.06–1.36) Statins1.15 (1.09–1.22) Platelets x 10^9^/L Unknown plateletsBaseline Thrombocytopaenia (<150)1.23 (1.08–1.39) Platelets normal (150–450)1.10 (1.06–1.16) Thrombocytosis (>450)1.32 (1.14–1.53) CRP mg/L CRP unknownBaseline CRP < 50.86 (0.77–0.96) CRP 5 to <201.10 (1.06–1.16) CRP ≥ 201.32 (1.14–1.53) Index of multiple deprivationc Least derived decileBaseline Most deprived decile1.52 (1.40–1.66)Respiratory Tract Infection (RTI) categorised into upper (URTI), lower (LRTI) and pneumonia. Influenza is a separate, non exclusive category and can be included separately in addition to LRTI (default for influenza, unless coded to another site). Heart failure includes all non-ischaemic diagnoses. Chronic heart disease incluses valvular disease, hypertensive disease and congenital disease. Atrial arrhythmias include atrial tachicardias, fibrillation, and flutter. Diabetes includes type i, type ii, and other/unrecorded type. Markers of arterial disease includes markers of possible atherosclerosis: chronic kidney disease, peripheral arterial disease, and erectile dysfunction. Cholesterol: HDL ratio is serum total cholesterol/serum HDL cholesterol. CRP is C Reactive Protein.aAge in models = age in years −56.5. DASHI age points: 40–59 years = 0 points, 60–79 = 2 points, 80+ = 4 points.bVariable transformed with fractional polynomials, so not directly interpretable. BMI (Body Mass Index) term one is (BMI in KgM^−2^/10)ˆ0.5−1.66, BMI term two is (BMI in KgM^−2^/10)ˆ2−7.61, Systolic BP term one is (systolic BP in mmHg/100)ˆ0.5–1.14, systolic term two is (systolic BP/100)ˆ0.5∗ln (systolic BP/100)−0.31.cModel for each decile presented in Supplementary materials.
Prediction model score: DASHI
Due to the similarities in performance of each model, we derived the DASHI score from the simpler model one (Table 2). DASHI is an acronym of the five variables that confer points: Diabetes (1 point for diabetes mellitus of any type), Age (2 points for age 60–79, 4 points for 80+ years), Smoking (1 point for current smokers), Heart failure (1 point for a diagnosis), and Infection type (1 point for LRTI, 4 points for pneumonia). The variables influenza and subcategories of smoking dropped out in the derivation process because they conferred less than half of one point to the score.
The DASHI score predicts 28-day risks from 0.04% for zero points, to 35.6% for the maximum of 11 points (Supplementary Table S2). For context, this table also gives an illustrative ten-year risk that could give patients an equivalent 28-day risk.
Model performance
Each model demonstrated excellent discrimination with median C statistics of 0.86 (IQR 0.860–0.860) for model one, 0.85 (IQR 0.849–0.852) for model two, and 0.85 (IQR 0.848–0.849) for the DASHI score (Table 3).Table 3. External validation results.ModelConcordance statistic median (IQR)Observed to Expected ratio median (IQR)Model one0.86 (0.8599–0.8603)0.83 (0.83–0.83)Model two0.85 (0.849–0.852)0.78 (0.77–0.78)DASHI score0.85 (0.848–0.849)0.85 (0.85–0.85)
External calibration was also good. The median observed to expected ratio was 0.83 (IQR 0.83–0.83) for model one, 0.78 (IQR 0.77–0.78) for model two and 0.85 (IQR 0.85–0.85) for the DASHI score (Table 3). There was over prediction of risk of small magnitude at the highest predicted probabilities in all the models (O/E ratio for model one: 0.83 (IQR 0.83–0.83); model two: 0.78 (IQR 0.77–0.78); DASHI: 0.85 (IQR 0.85–0.85) Fig. 1, Table 3). The greatest magnitude overprediction was in model two. According to model two the expected proportion of events in the 2% of the population with the highest risk was ∼5%, but a little over 3% had outcomes.Fig. 1. External calibration plots: proportions expected and observed in groups of predicted risk (red markers). Green line—expected equals observed. Blue line—Cubic spline based on red markers. A) Model one, groups are 50ths of expected risk. B) Model two, groups are 50ths of expected risk C) DASHI score, groups are deciles of expected risk.
Decision curve analysis showed little difference in net benefit between the two models and DASHI score. They all outperformed the default options of assuming all or none of the patients would have CVD events (Fig. 2).Fig. 2. Decision curves for models one, two, and the DASHI score. Lines are net benefit for different strategies: blue dash: ‘treat none’, bold blue dash: ‘treat all’, solid red: DASHI score, green dash: model one, black alternating dots and dashes: model two. Net benefit = true positive proportion minus false positive proportion multiplied by threshold probability/1-threshold probability.
Discussion
We derived and validated the first prediction models and risk score for post-acute respiratory infection CVD event risk in a population of patients aged 40 years or older, using data from 6.4 million patients. The DASHI score incorporates five clinical variables: Diabetes, Age, Smoking, Heart failure, and Infection type. It showed excellent discrimination and good calibration upon external validation.
This score could be used in primary care to estimate cardiovascular risk in patients with acute respiratory infection to target adequate primary prevention.
We present a novel tool for predicting post-infection CVD events.16 Prior studies found variables associated with infection-related CVD, but these studies were not seeking to predict risk, and clinicians should not be tempted to use these associations to guide treatment decisions.
Causal relationships do not necessarily operate as predictors in the way one might expect. Antiplatelets and anticoagulants reduce CVD events.34 Clinicians should not be reassured if their patient is taking these medications–in model two these variables increase the predicted risk, because they are associated with higher underlying risk.
Pneumonia is an important variable in our models and is known to be associated with CVD events.30^,^35^,^36 An observational study examining the effect of aspirin on CVD events in pneumonia suggests a protective effect.30 However, a large proportion of post-infection CVD events occur in people with other diagnoses (78% and 76% of events in our derivation and validation data).
When studies have used prediction-modelling methods to estimate CVD risk, they have not targeted post-infection CVD, nor included infection-related variables.16 NICE guidance has not advised acute, infection-related risk prediction. Instead, they advise GPs in the UK to estimate overall ten-year CVD risk using the QRisk prediction models.37 These models were developed and validated in UK primary care datasets, with comparable methods to this study.
DASHI is the only CVD risk prediction tool that considers respiratory infections, it is simpler to use, and predicts shorter-term risk than most rules.
There are limitations in the data. Clinicians collected these data for a different purpose, over 20 years, during which there were changes in coding, patient behaviour, and clinical practice. However, these inconsistencies apply in both the derivation and validation datasets, and reflect the data that is available in primary care. We had to combine some categories of exposure, and impute some data. We have missed acute respiratory infections that did not present to primary care, or were not coded. This would reduce the size of the dataset, which has remained sufficiently large, but it means the results are only generalizable to presentations recorded in primary care, which is the population for which it is intended.
This study predates the onset of the COVID-19 pandemic in its conception, funding, and the data available at the time of analysis. A further analysis could alter the results because Covid has an association with CVD.3 On the other hand, so do many viral and bacterial infections.4^,^8 A simple explanation is CVD is triggered by the common inflammatory response or physiological disturbances rather than many different effects specific to many different organisms. Non-sterilizing influenza vaccines and Covid vaccines reduce the risk of CVD events, which also points to severity of the illness being important.38^,^39 As with the other variables, causation does not necessarily increase predicted risk–influenza is known to increase the risk of CVD but in our modelling, influenza first reduced the predicted risk in the regression models, then dropped out of the DASHI score completely, as the effect was too small to confer half of one point and was rounded to zero.
It is possible that DASHI would have performed differently in the first waves of the COVID-19 pandemic, as it might with any pandemic. The risks of CVD following Covid infection were not stable over time—we would expect the CVD risk to be lower now than in the early pandemic because the risk is reduced by covid vaccination, and there is evidence that CVD was underdiagnosed during the early pandemic.38, 39, 40 However, if the differences in CVD risk are driven by reductions in covid causing lower respiratory tract infections and pneumonia, which seems likely, DASHI may still perform well. We used diagnoses recorded in clinical records. We cannot tell how pneumonia was diagnosed, for example, but it is likely that some cases have been diagnosed following chest radiography. Patients with more severe infection are more likely to be assessed in hospital or ambulatory care settings, which may not be coded in the primary care record until discharge. They would then enter the cohort later than those with URTIs. It is also possible that patients with severe infections present sooner, compared to people with minor illnesses. Either way, the presentation to primary care is representative of the population in which the score should be used.
We selected variables with physicians’ expert opinion. This is necessarily a biased process, as clinicians bring their own subjective views and experiences. A strength is that it resulted in a score that is easily calculated, and has face validity with the target users, clinicians.
The calibration of the models and score is imperfect. It is worse at the higher ends of the predicted probabilities. For example, in the top 2% of the population by risk, model one over-predicts by less than one percent. This is small, applies to relatively few patients, and, as they would be high-risk anyway, is unlikely to make much difference in clinical use. The C statistic is of less utility for low prevalence outcomes, and so we have provided decision curve analysis, other diagnostic accuracy measures, and ratios of true and false results to aid interpretation.41
Deriving points scores necessarily loses information; they are in effect new models, and need separate validation, which we have done. This resulted in a simpler tool, and the validation shows it performs well. Scores are also easier to implement in clinical practice than statistical models.
Primary care clinicians can use DASHI to estimate and discuss primary CVD event risk. DASHI is valid for patients over the age of 40 presenting to primary care with an acute respiratory tract infection. Many high-risk patients will already be eligible for primary prevention. Clinicians should take the opportunity to offer routine primary prevention with statins to those who are eligible, and to check adherence and optimise the dose in people already prescribed them. As the risks from statins are very low, a low threshold would be appropriate to trigger this action; an equivalent to the 10% ten-year CVD risk used for statin prescriptions is one DASHI point.37^,^42
DASHI could be re-validated in post-COVID-19 pandemic populations, but researchers should consider the complexities of investigating the early waves and consider using data from after widespread vaccination. A clinician considering additional higher risk interventions, such as short prescription of antiplatelets, could apply a higher threshold. The predicted risk at three DASHI points exceeds the risk of major bleeding from short duration single antiplatelet therapy (about 0.3%).15 The CVD event risk at four DASHI points exceeds the risk of major bleeding with dual antiplatelet therapy (0.5%).15
Clinicians could also use DASHI to encourage vaccination to prevent cardiovascular events, though the vaccination itself would not be administered during acute illness.9^,^12 Meta-analysis of previous trials of antibiotics in stable coronary disease shows at best no benefit, and at worst increased mortality.43 Acute respiratory infection can be an indication for antibiotic prescribing, but clinicians should not prescribe antibiotics for CVD risk.
DASHI is a simple, validated score for predicting risk of primary CVD events in acute respiratory infections. It applies to primary care populations over the age of 40, presenting with respiratory infections.
This new tool is a way to identify individuals who are most likely to have an infection-related cardiovascular event. It enables research aiming to reduce CVD events in people with acute respiratory infections and may encourage uptake of primary prevention measures. An intervention trial of intensified cardiovascular prevention in patients with high DASHI score in the weeks following infection is warranted.
Contributors
Authors contributed to the following:
Study design and planning: JJL, CK, CWD, JAD, CWG, FDRH, JPS.
Conduct/analyses of the study, verification of datasets: JJL, CK, CWD.
Reporting, editing and writing the paper: JJL, CK, CWD, JAD, CWG, FDRH, JPS.
Guarantor: JPS.
All authors read and approved the final version of the manuscript. JJL and CWD have verified the underlying data. The corresponding author attests that all listed authors meet authorship criteria and that no others meeting the criteria have been omitted.
Data sharing statement
We are unable to share data, which is available from CPRD. Software is available commercially from StataCorp.
Declaration of interests
JJL and this study were funded by doctoral fellowship funding from the NIHR [NIHR300738]. JJL is partly supported by NIHR ARC OTV.
CK and JS declare support from the Wellcome Trust/Royal Society, NIHR School for Primary Care and NIHR Oxford Biomedical Research Centre.
James P. Sheppard receives funding from the Wellcome Trust/Royal Society via a Sir Henry Dale Fellowship (ref: 211182/Z/18/Z), the National Institute for Health and Care Research (NIHR) and from the British Heart Foundation (refs: PG/21/10341; FS/19/13/34235). JPS additionally declares payments from DoctorLink for critical reviews of their evidence synthesis exercises and payments for participation in the Data Safety Monitoring Board of the Hypertension Treatment in Nigeria Study sponsored by Northwestern University, US. He has an unpaid role as Secretary and Trustee of the British and Irish Hypertension Society.
CWD and JD declare no support for the present project. FRDH is chair of EPCCS and IPCCS. He declares occasional fees/expenses for advisory work or speaking for AZ, BI, BMS/Pfizer.
CWG is supported by a Wellcome Career Development Award (225868/Z/22/Z).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Visseren F.L.J.Mac HF.Smulders Y.M.2021 ESC Guidelines on cardiovascular disease prevention in clinical practice Developed by the Task Force for cardiovascular disease prevention in clinical practice with representatives of the European Society of Cardiology and 12 medical societies with the special contribution of the European Association of Preventive Cardiology (EAPC)Eur Heart J 4220213227333710.1093/EURHEARTJ/EHAB 48434458905 · doi ↗ · pubmed ↗
- 2Warren-Gash C.Hayward A.C.Hemingway H.Influenza infection and risk of acute myocardial infarction in england and wales: a CALIBER self-controlled case series study J Infect Dis 20620121652165910.1093/infdis/jis 59723048170 PMC 3488196 · doi ↗ · pubmed ↗
- 3Katsoularis I.Fonseca-Rodríguez O.Farrington P.Risk of acute myocardial infarction and ischaemic stroke following COVID-19 in Sweden: a self-controlled case series and matched cohort study Lancet 398202159960710.1016/S 0140-6736(21)00896-534332652 PMC 8321431 · doi ↗ · pubmed ↗
- 4Warren-Gash C.Smeeth L.Hayward A.C.Influenza as a trigger for acute myocardial infarction or death from cardiovascular disease: a systematic review Lancet Infect Dis 9200960161010.1016/S 1473-3099(09)70233-619778762 · doi ↗ · pubmed ↗
- 5Smeeth L.Thomas S.L.Hall A.J.Risk of myocardial infarction and stroke after acute infection or vaccination N Engl J Med 35120042611261810.1056/NEJ Moa 04174715602021 · doi ↗ · pubmed ↗
- 6Kwong J.C.Schwartz K.L.Campitelli M.A.Acute myocardial infarction after laboratory-confirmed influenza infection N Engl J Med 378201834535310.1056/NEJ Moa 170209029365305 · doi ↗ · pubmed ↗
- 7Barnes M.Heywood A.E.Mahimbo A.Acute myocardial infarction and influenza: a meta-analysis of case-control studies Heart 10120151738174710.1136/heartjnl-2015-30769126310262 PMC 4680124 · doi ↗ · pubmed ↗
- 8Pitman R.J.Melegaro A.Gelb D.Assessing the burden of influenza and other respiratory infections in England and Wales J Infect 54200753053810.1016/j.jinf.2006.09.01717097147 · doi ↗ · pubmed ↗