Testing for a General Changepoint in Medical and Psychometric Studies: Changes Detection and Sample Size Planning
Nicoletta D'Angelo

TL;DR
This paper introduces a new and simple method for detecting changes in data from medical and psychometric studies, which also helps in planning how much data to collect.
Contribution
The paper introduces a new change detection method using a pseudo Score statistic with known distributions for easy power and sample size calculations.
Findings
The proposed method outperforms existing change point tests in simulations with normal and binary data.
The method is applied successfully to genomic and SAT data, showing practical utility.
The new test is available as an R package and a Shiny App for user accessibility.
Abstract
This paper introduces a new method for change detection in medical and psychometric studies based on the recently introduced pseudo Score statistic, for which the sampling distribution under the alternative hypothesis has been determined. Our approach has the advantage of simplicity in its computation, eliminating the need for resampling or simulations to obtain critical values. Additionally, it comes with known null and alternative distributions, facilitating easy calculations for power levels and sample size planning. The paper indeed also discusses the topic of power analysis in segmented regression, namely the estimation of sample size or power level when the study data being collected focuses on a covariate expected to affect the mean response via a piecewise relationship with an unknown breakpoint. We run simulation studies showing that our method outperforms other Tests for a…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
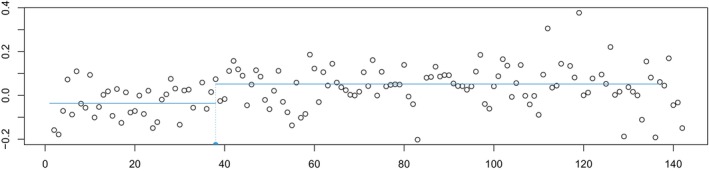 FIGURE 1
FIGURE 1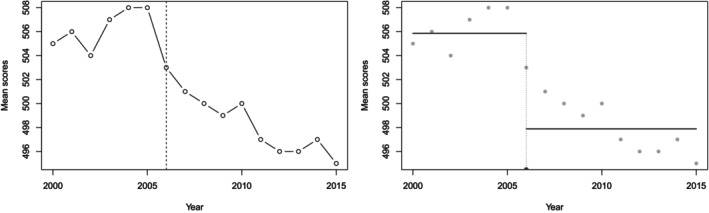 FIGURE 2
FIGURE 2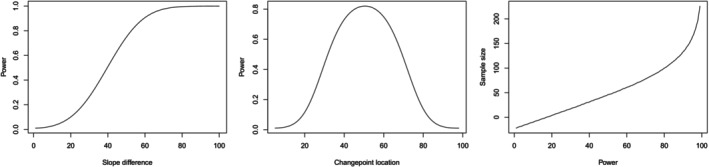 FIGURE 3
FIGURE 3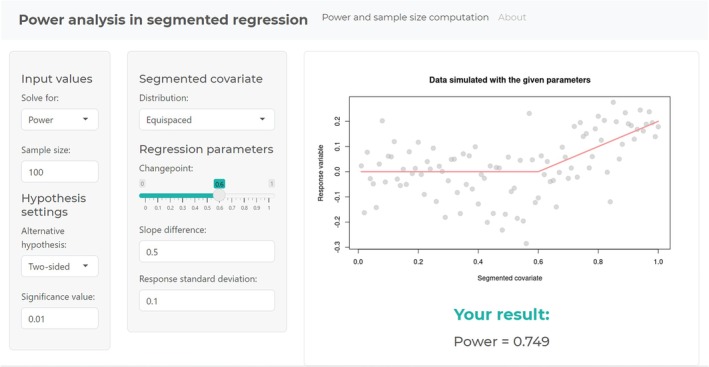 FIGURE 4
FIGURE 4|
| 0.10 | 0.05 | 0.01 |
|---|---|---|---|
| 10 | 3.14 | 3.66 | 4.93 |
| 15 | 2.97 | 3.36 | 4.32 |
| 20 | 2.90 | 3.28 | 4.13 |
| 25 | 2.89 | 3.23 | 3.94 |
| 30 | 2.86 | 3.19 | 3.86 |
| 35 | 2.88 | 3.21 | 3.87 |
| 40 | 2.88 | 3.17 | 3.77 |
| 45 | 2.86 | 3.18 | 3.79 |
| 50 | 2.87 | 3.16 | 3.79 |
| Normal data | Binary data | |||
|---|---|---|---|---|
| P. score | W | P. score | L | |
| 20 | 0.041 | 0.043 | 0.051 | 0.035 |
| 30 | 0.052 | 0.053 | 0.053 | 0.046 |
| 40 | 0.051 | 0.054 | 0.054 | 0.044 |
| 50 | 0.048 | 0.042 | 0.043 | 0.038 |
| Normal data | Binary data | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P. score | W | P. score | W | P. score | W | P. score | L | P. score | L | P. score | L | |
| 20 | 0.063 | 0.068 | 0.12 | 0.108 | 0.396 | 0.336 | 0.125 | 0.087 | 0.28 | 0.213 | 0.419 | 0.349 |
| 30 | 0.072 | 0.075 | 0.18 | 0.148 | 0.563 | 0.515 | 0.133 | 0.121 | 0.355 | 0.32 | 0.574 | 0.577 |
| 40 | 0.089 | 0.071 | 0.238 | 0.18 | 0.728 | 0.665 | 0.161 | 0.13 | 0.468 | 0.421 | 0.712 | 0.683 |
| 50 | 0.091 | 0.084 | 0.284 | 0.215 | 0.811 | 0.768 | 0.216 | 0.167 | 0.566 | 0.523 | 0.811 | 0.823 |
- —GRINS ‐Growing Resilient, INclusive and Sustainable project
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods in Clinical Trials · Statistical Methods and Inference · Statistical Methods and Bayesian Inference
Introduction
1
Segmented or broken‐line models are regression models where the relationships between the response and one or more explanatory variables are piecewise linear, namely represented by two or more straight lines connected at unknown values. These values are commonly referred to as changepoints or breakpoints. The main advantage of these models lies in the results' interpretability while also achieving a good trade‐off with flexibility, typically achieved by nonparametric approaches.
In medical research, many biological processes and clinical outcomes are characterized by heterogeneous behaviors that vary across subgroups of the population or over different ranges of a covariate. Traditional regression models often fail to capture abrupt changes or structural breaks in the relationship between covariates and the response variable. In this context, segmented regression models (also known as piecewise or broken‐line regression models) provide a flexible framework for identifying and modeling changes in the underlying data structure. These models allow for different regression parameters in distinct intervals, separated by unknown changepoints that are estimated from the data.
Segmented regression has found numerous applications in medical problems. For instance, it has been used to detect threshold effects of biomarkers, to evaluate the impact of clinical interventions over time [1], and to identify structural changes in disease progression or physiological measurements [2]. By explicitly modeling transitions in the relationship between predictors and outcomes, segmented regression offers valuable insights into clinically meaningful thresholds and mechanisms, enhancing interpretation and decision‐making.
Change detection refers to the task of estimating the changepoint locations, and possibly their number. A huge number of proposals for this task have been made in the literature; see [3] and [4] for a comprehensive review. Changepoint estimation and inference have also been studied from a Bayesian perspective [5, 6, 7]. In the single changepoint setting, estimation and inference for the location of the changepoint have been studied in the asymptotic [8, 9, 10, 11] and nonasymptotic [12] settings.
Despite the huge literature on estimation and inference in changepoint detection problems, there remains a gap between the procedures used by practitioners to estimate changepoints and the statistical tools to assess the uncertainty of these estimates: classical techniques to test for a single changepoint give (mostly) asymptotic results, which involve complicated limiting distributions that do not directly apply to the multiple changepoint setting. Only [13] considers testing the null hypothesis that there is no change in the mean around an estimated changepoint. However, their interest lies not in determining whether there is a change in mean at a precise location but rather whether there is a change in mean nearby.
Therefore, all the above‐mentioned approaches lack a known null and alternative distribution, introducing uncertainty, subjectivity, and challenges in both the interpretation of results and the design of robust, reproducible experiments.
Furthermore, conducting power analysis, essential for determining the ability of a test to detect true effects, becomes less reliable without a known distribution.
Borrowing terminology from the basics of Statistical Inference theory, the power of a study is the probability of detecting a significant covariate effect on the response. Roughly speaking, the power depends mostly on the sample size, the statistical test being used with fixed type‐I error probability, and some settings related to the specific problem and model under investigation.
For instance, the researcher has to specify the effect size via Cohen's d when the study involves the traditional mean comparisons between two groups or the expected correlation coefficients when the study focuses on the association between two variables [14].
From a practical point of view, the most important goal of power analysis is to estimate the sample size when a desired level of power is fixed. Namely, the investigator anticipates a certain effect size, sets a significance level α, and then specifies the amount of power they desire. Then, power analysis is used to determine the sample size n, which is necessary to meet their specifications. Having some, even rough, idea of power/sample size is crucial for better planning the study and efficient resource allocation, namely, avoiding waste of time and costs. Experimental results with too low statistical power will lead to invalid conclusions about the meaning of the results, and therefore, a minimum level of statistical power is commonly sought.
In addition to the traditional and well‐known mean comparisons or correlation, power analysis has been studied in different scenarios, including survival analysis in epidemiological studies [15], random effects and mixed models [16], and general power analysis methods in genetic studies [17]. Moreover [18], investigates the power needed to detect differential growth for linear–linear piecewise growth models.
However, to the best of our knowledge, there is no paper dealing with power analysis when the main relationship under investigation is segmented, namely a continuous covariate affecting the mean response via two straight lines connected at an unknown covariate value, the so‐called breakpoint or changepoint, where the effect changes abruptly.
In recent years, item‐level response time data has become more accessible due to computer‐based testing and online survey data collection methods [19]. This has led to a significant rise in interest within the field of psychometric research [20].
In parallel, Tests for a Change Point (TFCP) have emerged for their potential uses in psychometrics [21, 22]. Originating from the field of statistical quality control [23, 24, 25], TFCPs are methods intended to detect whether there has been any change in the parameters underlying a sequence of random variables. Specifically, TFCPs focus on finding the moment in time when the statistical model or its parameters underlying a sequence of observations have changed in some fashion [24]. These methods involve testing the null hypothesis of no change against the alternative hypothesis that a change has occurred after a certain observation.
TFCPs have been successfully applied to detect such unusual change, psychometric‐related problems. Some are worth mentioning [26]: used a TFCP to detect an unusual change in the mean score of a sequence of administrations of an international language assessment, and [27], which used a TFCP to detect speededness in nonadaptive tests.
Moreover [28], demonstrated how a TFCP can be used to detect an abrupt change in the test performance of examinees during a computerized adaptive test (CAT). By comparing the performances of the new statistics with those of four existing TFCPs, the author shows that the TFCPs appeared promising for the assessment of person fit for CATs.
More recently [19], proposed the usage of two test statistics based on changepoint analysis, namely the likelihood ratio test and Wald test employed by [26, 27], respectively, to detect test speededness. Indeed, one notable application of response time has been the detection of aberrant response behavior [29]. Conversely, to other common approaches to detect test speededness using response time data, the proposal of [19] does not examine how an individual response time pattern deviates from the group behavior or model‐implied behavior, but it concerns itself with intraindividual change during the test‐taking process. Finally [30], recently proposed a changepoint analysis procedure using response times to detect abrupt changes in examinee speed, which may be related to aberrant responding behaviors in the Bayesian context.
The differences in the type of data and test statistics employed leave no doubt about the great set of psychometric problems that TFCPs can solve.
In psychological/psychometric research, changepoint models and relevant applications have been discussed by [28] and [31] and more recently by [19] to detect test speededness using response time data.
Following up on such works, we propose an alternative to the most known TFCPs, based on the pseudo Score statistics proposed by [32] The aim of this research work is to propose a test that is simple to compute, without resampling or simulations requested to get critical values, and with known null and alternative distributions, which makes the computation of the power level and/or sample size planning straightforward.
The structure of the paper is as follows: First, in Section 2, we review the theory for TFCP analysis. Secondly, we introduce the pseudo Score statistic and illustrate how it can be used to test the existence of a breakpoint in segmented regression models in Section 3. In Section 4, we then assess the performance of our proposal through a simulation study in terms of rejection rates, comparing it to the performance of two TFCPs: the likelihood ratio and Wald tests. Furthermore, we carry out two analyses on genomic data and on real SAT critical reading data in Section 5, to show the applicability of the method. After having assessed its performance, Section 6 illustrates how to employ the proposed test statistics to conduct power analysis. Finally, we present the new R function available on the segmented package [33] of the Comprehensive R Archive Network (CRAN), and a Shiny App available from https://uy1z3u‐nicoletta0d0angelo.shinyapps.io/PowerSeg/, which implements the proposed methodology. Indeed, all the analyses are available from the GitHub repository https://github.com/nicolettadangelo/PowerSeg and carried out through the statistical software R [34]. The paper ends with some conclusions.
Tests for a Change Point
2
In this section, we review the Tests for a Change Point, henceforth called TFCP. We shall suppose that the data consists of the observations Y1,Y2,…,Yn, obtained at a sequence of time points i=1,2,…,n. We further assume that the Yi's come from an underlying statistical model, depending on some parameters. A TFCP is commonly employed to determine whether there exists a time point ψ such that the model parameter underlying the sub‐sequence Y1,Y2,…,Yψ−1 is statistically different from the one underlying the sub‐sequence Yψ,Yψ+1,…,Yn. The time point ψ is referred to as changepoint, or breakpoint.
Among the several formulations of TFCPs, we follow the most relevant to psychometric problems discussed in [35] as follows:
Formally, let Y1,Y2,…,Yn be independent random variables, with probability function fi(Yi;τ1,η) for i=1,2,…,ψ−1, and fi(Yi;τ2,η) for i=ψ,ψ+1,…,n. The parameters τ1 and τ2 are those of interest, while η is the nuisance parameter. The reason why the Xis have not been assumed identically distributed is that they could, for instance, denote the scores on items of the same examinee.
A TFCP typically tests either
or the alternative one‐sided hypothesis ℋ1:τ1>τ2 or ℋ1:τ1<τ2.
We address the most relevant problem in psychometrics, which is that of unknown τ1,τ2,η,andψ.
Next, we review the appropriate test statistics depending on the distribution of the fis, following the general overview of [31].
Normally Distributed Observations
2.1
The following method tests whether the means in two parts of a record are different (for an unknown changepoint). The test assumes that the data are normally distributed, with τ1 and τ2 as the means and η as the common variance, which is a common setting in TFCPs.
Therefore, the generalized Likelihood Ratio Test (LRT) of the hypothesis system (1) can be performed using the following test statistics:
where
See for example, [22, 24, 26], for papers dealing with LRT as a TFCP. The null hypothesis is rejected if Tmax,n is larger than an appropriately chosen critical value hn.
Non‐Normal Distributed Observations
2.2
If the Yis are assumed to follow a binary distribution, denoting, for instance, scores on binary items [35], and [36] show that one can use the following LRT statistics
where
And, for example, the log‐likelihood of Y1,Y2,…,Yj at τ1j is
The statistics (3) is employed to test the null hypothesis in (1) for all js versus the alternative of a change between items n1 and (n−n1). Indeed, to increase the stability of the test [35], recommends setting n1 to the nearest integer to 0.15n, which restricts the changepoints to roughly the middlemost 70% of the observations.
Also, in this case, one rejects the null hypothesis if Lmax,n is larger than an appropriately chosen critical value hn.
The Pseudo Score Statistic
3
We now introduce the terminology about segmented regression models and review the pseudo Score statistics proposed in this paper as a tool for performing changepoint detection, alternatively to the previously reviewed TFCP, and for conducting power analysis.
The segmented regression model with a single changepoint ψ in the covariate z is
where 𝔼[·] denotes the expected value, Y is the response variable, xiT is the possible vector of additional nonsegmented covariates related linearly to the mean response with associated parameter vector β, and z is the segmented variable with a piece‐wise linear relationship: that is, the z‐effect changes by δ at the unknown ψ in the covariate range [37]. φ is a generic function of both the segmented variable z and the changepoint ψ, which covers several cases. For discontinuous changepoint φ(xi,ψ)=I(xi>ψ), while for linear segmented φ(xi,ψ)=δzi−ψIzi>ψ. Other cases not addressed in this paper include the quadratic segmented modelling and the harmonic regression with unknown frequency. The expected value of the response is linked to the right‐hand side of equation (4), that is, the linear predictor, through a link function g(·), a monotone function that ensures admissible values of the predicted responses.
Note that this formulation allows, in addition to the inclusion of potential other nonsegmented covariates, for the segmented variable z not to necessarily be the sequence of time points observed for the Yis.
In general, zi could be any other variable external to the phenomenon under analysis. For instance [38], considered the number of university credits earned during the first year as a good predictor of the regularity of the career and, therefore, considered it as a potential segmented covariate, whose effects on the probability of getting the bachelor's degree within 4 years could change. Other examples of application fields include epidemiology, occupational medicine, toxicology, and ecology [39, 40]. In the context of changepoint detection, there are several cases covered by the function φ and, in turn, by model (4).
To parallel the cases considered by the TFCPs, we consider in this paper the segmented regression model with a single discontinuous changepoint ψ in the covariate z, also called jump‐points model, and no additional nonsegmented variables, as follows:
and include the only segmented covariate as the sequence of the time points observed for the Yis, that is, set zi=i. The link function g(·) will change depending on the distribution assumed for the fis.
Testing for the existence of a changepoint means to test for the following system of hypotheses ℋ0:δ=0 vs. ℋ1:δ≠0, where the alternative ℋ1 can also be unidirectional.
Using the setting of probabilistic coherence of de Finetti [32], proposes to use the following pseudo Score statistic
where In the identity matrix, y the observed response vector, and A is the hat matrix under the null hypothesis of no changepoint. φ‾=(φ‾1,...,φ‾n)T is the vector of the segmented term φ(zi,ψ) averaged over the range of Z that is, φ‾i=K−1∑k=1Kφ(zi,ψk) using K fixed values {ψk}k=1,…,K.
The expected value of (6) is zero under ℋ0, and its variance can be easily obtained, therefore the test statistic based on the pseudo Score (6) is
When the unknown variance σ2 is replaced by its estimate under the null or the alternative hypothesis or the response variable does not follow a normal distribution, the null distribution in (7) is asymptotically a standard normal, but convergence is very fast, and results are accurate even in modest sample sizes.
Simulation Study
4
This section is devoted to assessing the performance of the pseudo Score test (7) in terms of rejection rates and its comparison with benchmark TFCPs.
Normal Data
4.1
We simulated twelve different scenarios, generating normally distributed data with three different true values of the mean difference, namely δ={.25,.5,1}, and considering four different sample sizes n={20,30,40,50}. We include only one segmented covariate, taking equispaced values ranging from 0 to 1. The jump‐points model (5) used for the simulations is
considering the intercept β=2, the true changepoint ψ=0.5, identity link function g(·), and i.i.d. standard Gaussian errors. As for the hypothesis testing, we fix α=0.05.
As we are dealing with normally distributed data, we compare our proposal with the test in (2). Its critical values are provided in [41] for the equivalent test statistics Wmax,n=(n−2)0.5Tmax,n(1−Tmax,n2)0.5, and are reported in Table 1.
Binary Data
4.2
For non‐normal distributed data, we follow the simulation setup in [28], assuming a computerized adaptive test (CAT) with n dichotomous items being administered to an examinee whose true ability is denoted by θ. Let Yi,i=1,…,n be the dichotomous examinee's score obtained on the i‐th item. The probability of a correct answer on item i is denoted by Pi(θ). The simulated data are obtained from a three‐parameter logistic model
where ai,bi,andci represent the slope, difficulty, and guessing parameters on item i, respectively. Indeed, the data are simulated from a Rasch model [42], given by equation (8) with ai=1 and ci=0, making it basically a logit model, that is, Equation (5) with logit link function.
To compute the Type I error rates (that is, under the hypothesis of no changepoint), the true difficulty parameters bi are drawn from a standard normal distribution.
To compute the power (that is, under the hypothesis of the existence of a changepoint), the true abilities for the two halves of the CAT (denoted by θ1 and θ2) are obtained as follows: for each examinee, θ1 is simulated from a standard normal distribution, and θ2 is set as θ1+δ. In particular, we consider δ={1,2,3}, where, of course, positive values of δ indicate an improvement in the performance in the second half of the test.
For any test length, the rejection rate is computed on 1000 model‐fitting score patterns. In particular, we consider four levels of test length n, involving 20, 30, 40, and 50 items. The true changepoints are 11, 15, 21, and 25 for the four tests, respectively, similar to those in [31].
For this scenario, we compare our results with the test in (3). The critical value for Lmax,n is 8.85 for n1/n=0.15 and α=0.05 [35].
Results
4.3
Tables 2 and 3 report the results obtained over 1000 simulations each for the normal and binary data, respectively, in terms of type I error rates and power.
We denote by P.Score the columns with the results obtained from the application of our proposal (7) and by W and L those following the tests (2) and (3), respectively.
Under the null hypothesis, that is, in the absence of a change (δ=0), P.Score shows similar type I error rates compared to W. However, for binary data, it stays close to a 0.05 value, contrary to L, which appears to depend on the sample size n.
Moving to the alternative hypothesis, we find no differences in the power of P.Score and W when both the sample size and the mean difference δ are small. This behavior is observed for this case uniquely, while in general, P.Score always achieves slightly better power values compared to both W and L.
Overall, the performance of P.Score aligns with those of W and L. This means that reasonable type I error rates are observed, close to the chosen significance level of 0.05. It also means that, as expected, higher power values increase with the sample size and the magnitude of the mean difference of the change.
Note that similar analyses have been run with negative values of δ, showing no difference in the results and conclusions, and therefore are not reported here for brevity.
Real Data Analyses
5
Fibroblast Cell Line Dataset
5.1
Statistical analysis in biological research frequently deals with outcomes represented by quantitative measurements of gene expression levels. When these responses are ordered according to their genomic position, the resulting sequences often exhibit clusters of values with distinct empirical means, presumably reflecting underlying differences in mean expression levels. By exploiting such variations, the statistical analysis aims to detect chromosomal regions exhibiting “abnormal” (either elevated or diminished) mean levels. These shifts may be of particular relevance for various biological and clinical objectives, including the characterization of specific genomic loci, such as tumor suppressor genes and oncogenes, as well as the identification of structural genomic alterations that result in imbalances implicated in disease mechanisms or aberrant phenotypic manifestations [43] presents a computationally efficient method to obtain estimates of the number and location of the changepoints.
To illustrate the method's usefulness in the medical framework, we provide an application to a Fibroblast cell line dataset, reported in Figure 1.
GM01524 fibroblast cell line.
Data come from a single experiment on 15 fibroblast cell lines, conducted by [44], with each array containing over 2000 (mapped) BACs spotted in triplicate. The variable in the dataset is the normalized average of the log base 2 test over the reference ratio.
In particular, we analyze the cell line GM01524, for which [43]'s method selects a unique changepoint, indicated in Figure 1. We are interested in assessing the significance of such a changepoint. A p‐value of 0.001668 confirms the existence of the changepoint.
Mean Scores of SAT Critical Reading
5.2
In this section, we analyze the same data in [31], with the aim of estimating a changepoint in the mean scores on SAT Critical reading. We consider the 2015 total group profile report for College‐bound seniors published by the College Board, and available on the website https://secure‐media.collegeboard.org/digitalServices/pdf/sat/total‐group‐2015.pdf.
In particular, we analyze the mean scores on SAT Critical reading for the total group between the years 2000 and 2015, which are shown in Figure 2.
Mean scores on SAT critical reading for the total group between 2000 and 2014. Left panel: W; Right panel: P.Score.
We are interested in testing the null hypothesis of no change in the means of the Yi's against a two‐sided alternative hypothesis. Since they assumed the Yi's to be independent and to follow a normal distribution with unknown means and variance, they used the test statistic Tmax,n. The critical values at significance level α=0.05 are 3.34 for n=16. The value of Tmax,n for these data was found to be equal to 7.65, which is much larger than the critical value 3.34 at level α=0.05. Thus, the value of Tmax,n is statistically significant at level α=0.05, so it can be concluded that a statistically significant change occurred in the mean. The estimated changepoint is 2006 for both the W and the P.Score statistics. Particularly, the P.Score method yields a p‐value of 0.0005.
Therefore, we can conclude that in real data applications, our method's results are coherent with the standard TFCP procedures. In particular, several sources, such as CBS News, reported a sharp drop in the SAT scores in 2006, making the estimated changepoint reasonable to interpret and put into context.
Power Analysis
6
In this section, we present the applicability of the proposed test statistics to conduct power analysis, having already assessed its performance under both the null and alternative hypothesis of the presence of a changepoint.
Assume now a segmented regression model with a single nondiscontinuous changepoint ψ in the segmented covariate z, as follows:
Basically, we set φ(zi,ψ) of model (4) to δzi−ψIzi>ψ, denoted by δ(z−ψ)+ henceforth.
In order to conduct power analysis, we need to derive the sampling distribution of the pseudo Score test statistic (6) under ℋ1.
The scale (variance) and shape (Normality) are preserved under ℋ1, but when the changepoint ψ does exist, y=Xβ+δ(z−ψ)+ and therefore
Given the null and alternative sampling distributions of the pseudo Score statistic s0, it appears straightforward to carry out power analysis.
As usual, given the type I error probability α, the slope difference δ, and the changepoint ψ, computations just require the normal distribution function Φ(·).
The formula (9) reports the expected value under ℋ1: the larger the expected value, the farther the alternative distribution, and the higher the power. Looking at 𝔼1[s0], it appears clear that, as expected, higher power is obtained as δ increases (in absolute value) since the segmented relationship gets more clear‐cut. However, 𝔼1[s0], and the power, in turn, also depends on ψ, the segmented covariate distribution, and the design matrix X, namely possible additional covariates understood to affect the mean response.
In general, 𝔼1[s0] depends on the segmented covariate distribution. It decreases as ψ moves to the boundaries of the segmented covariate, and additional covariates are accounted for. These factors, along with n, δ and σ, affect the power of the segmented regression model.
Figure 3 reports the power of the test as a function of the slope difference (panel a) and changepoint location (panel b) for a simulated scenario. Figure 3c illustrates the estimated sample size as a function of the desired power for a simulated example.
Power of the test as a function of the changepoint location (a) and the effect size (b). Estimated sample size as a function of the desired power (c).
As expected, the power of the proposed test increases with the magnitude of the slope difference, reflecting its sensitivity to more pronounced structural changes in the underlying process. Notably, the test performs best when the changepoint is located near the center of the domain, where it is more easily distinguishable from boundary effects. Moreover, larger sample sizes generally lead to higher power, although the relationship is not strictly linear. In particular, increasing the power beyond 0.8 requires a substantially larger increase in sample size compared to increases at lower power levels.
Software Implementation
6.1
We devote this section to illustrating the implemented R code to perform power analysis based on the pseudo Score statistics.
Power analysis based on the score statistic in segmented regression can be carried out via the function pwr.seg(), which is included in the segmented package [33].
Power Computation
6.1.1
For some settings specified (ψ=0.6, δ=0.5, zi=i/n, σ=.1, and n=100), the power (assuming the default values alpha=0.01 and alternative=“two.sided”) is easily obtained by typing[Link], [Link], [Link], [Link], [Link], [Link]
The segmented covariate is specified in the argument z via a string indicating the known quantile function having 'p', 'n', and its parameter values as arguments. In addition to “1:n/n” (default), some examples are “qnorm(p, 2, 1.5)”, “qexp(p,2.5)”, or “qbeta(p,1,2)”. The psi value has to be within the covariate range. Yet another option is to pass a numerical vector representing the segmented covariate.
It is probably instructive to compare the above‐returned power of 0.749 with the actual power based on 1000 Monte Carlo replicates. Namely, for each simulated sample, we apply the Score test (6) via the function pscore.test() in the package segmented,
We then count how many times the null hypothesis is rejected at the 0.01 level,
which is, unsurprisingly, quite close to the 0.749 value obtained through pwr.seg().
Sample Size Computation
6.1.2
From the practitioner's viewpoint, it is probably more useful to compute the appropriate sample size corresponding to the specified power level. When the argument pow is filled in, the function returns the (rounded) sample size value. For instance, assuming a segmented variable having a normal distribution 𝒩(5,1.5), the sample size corresponding to the desired power of 0.85 is obtained simply via
Postexperimental Power Computation
6.1.3
The function pwr.seg() can also be used to compute the power corresponding to a fitted segmented model.
At this aim, we use the above simulated z and y values.
Confidence interval replicates can be drawn to build a 95% “confidence interval” for the power through the ci.pow argument.
The endpoints (0.158 and 0.998) have been obtained as the 95% quantiles of the power values obtained by using 500 values of slope difference and changepoint generated from a bivariate normal distribution with mean (δ^,ψ^) and corresponding covariance matrix Var(δ^,ψ^).
Shiny App
6.2
The above‐illustrated code is implemented with a more user‐friendly interface in a Shiny app available at https://uy1z3u‐nicoletta0d0angelo.shinyapps.io/power_seg/atthebeginningofsection6.2shouldbehttps://uy1z3u‐nicoletta0d0angelo.shinyapps.io/PowerSeg/.
The Shiny app represents a tool for carrying out power analysis and sample size calculation in the context of segmented regression models, allowing one to compute the power corresponding to the specified sample size or to compute the sample size corresponding to the specified power. Figure 4 shows the interface.
Shiny app interface.
First, the user should specify whether they want to obtain a sample size given a desired power value or the estimated power given a fixed sample size. Depending on the first choice, the desired power or sample size should be imputed.
The “Alternative hypothesis” box allows you to choose among the alternatives “Two‐sided” (the default), “Greater,” and “Less.”
Moreover, the significance value, set to a default of 0.01, can be changed.
The distribution of the covariate understood to have a segmented effect can be chosen among “Normal,”, “Uniform,”, and “Exponential.” The default is to “Equispaced” values in 0 and 1. The parameters of the selected distribution can be changed, but the changepoint value should be modified accordingly.
Finally, the slope difference and the response standard deviation should be imputed as desired (default to 0.5 for the normal distribution and 0.1 otherwise).
As a result, power or sample size is displayed, and a simulated dataset (using the set parameters) is portrayed.
Conclusions
7
The growing interest in psychometric problems that can be solved by TFCPs continues to motivate researchers to develop methods for changepoint detection.
This paper proposes an approach that relies on the pseudo Score statistics. The novel method is based on the pseudo Score statistics previously introduced in [32], for which the sampling distribution under the alternative hypothesis has been determined.
Through a simulation study, we proved that such a test statistic achieves better performance if compared to the standard TFCP methods for both Gaussian‐distributed and binary data, covering a wide range of possible applications in psychometry. In particular, we have found that, in general, changepoints are more easily identified with normal data, as proved by the increased slope differences we had to use in the simulations for binary data to achieve comparable results with the normal data. Also, we have found that, as expected, the power of the test clearly increases with the slope difference and reaches higher levels for changepoints in the middle of the covariate range values. Furthermore, the sample size increases with the power, with a markedly steeper growth observed beyond the 0.8 threshold.
Moreover, the proposed method benefits from further advantages: being simple to compute, without resampling or simulations required to get critical values, and with a known null/alternative distribution, making straightforward computation of the power level and/or sample size planning.
The knowledge of the alternative distribution of our proposed statistics allows us to deal with power analysis, which is crucial when the researcher needs to estimate either the sample size or the power level of a study where the data are assumed to exhibit a piecewise relationship with an unknown changepoint. Given those results, we advocate the use of the pseudo Score statistics to perform power analysis.
In particular, we implemented the method in an R function contained in the segmented package [33], as well as in a ShinyApp, covering the different scenarios, for instance, implementing the most common distributions that could be assumed for the data.
All in all, the proposal supports the well‐established idea that statistical power calculations can be valuable in planning an experiment. Nevertheless, as shown in the illustration of the codes, we also implemented the possibility of running postexperiment power calculations should this be used to aid in interpreting the experimental results.
Conflicts of Interest
The author declares no conflicts of interest.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1A. K. Wagner , S. B. Soumerai , F. Zhang , and D. Ross‐Degnan , “Segmented Regression Analysis of Interrupted Time Series Studies in Medication Use Research,” Journal of Clinical Pharmacy and Therapeutics 27, no. 4 (2002): 299–309.12174032 10.1046/j.1365-2710.2002.00430.x · doi ↗ · pubmed ↗
- 2E. Kontopantelis , T. Doran , D. A. Springate , I. Buchan , and D. Reeves , “Regression Based Quasi‐Experimental Approach When Randomisation Is Not an Option: Interrupted Time Series Analysis,” BMJ 350 (2015): 1–4.10.1136/bmj.h 2750 PMC 446081526058820 · doi ↗ · pubmed ↗
- 3C. Truong , L. Oudre , and N. Vayatis , “Selective Review of Offline Change Point Detection Methods,” Signal Processing 167 (2020): 107299.
- 4P. Fearnhead and G. Rigaill , “Relating and Comparing Methods for Detecting Changes in Mean,” Stat 9, no. 1 (2020): e 291.
- 5P. Fearnhead , “Exact and Efficient Bayesian Inference for Multiple Changepoint Problems,” Statistics and Computing 16 (2006): 203–213.
- 6C. F. Nam , J. A. Aston , and A. M. Johansen , “Quantifying the Uncertainty in Change Points,” Journal of Time Series Analysis 33, no. 5 (2012): 807–823.
- 7J. J. O. Ruanaidh and W. J. Fitzgerald , Numerical Bayesian Methods Applied to Signal Processing (Springer Science & Business Media, 2012).
- 8D. V. Hinkley , “Inference About the Change‐Point in a Sequence of Random Variables,” Biometrika 57 (1970): 1–17.