An improved robust algorithms for fisher discriminant model with high dimensional data
Shaojuan Ma, Yubing Duan, Razieh Sheikhpour, Razieh Sheikhpour, Razieh Sheikhpour

TL;DR
This paper introduces a robust Fisher discriminant method for high-dimensional data that is less affected by outliers.
Contribution
The novel integration of the MRCD algorithm into the Fisher discriminant framework improves robustness and accuracy in high-dimensional settings.
Findings
The MRCD-Fisher discriminant outperforms existing methods in terms of robustness and accuracy.
It maintains high data cleanliness and computational stability even with outlier-contaminated data.
Abstract
This paper presents an improved robust Fisher discriminant method designed to handle high-dimensional data, particularly in the presence of outliers. Traditional Fisher discriminant methods are sensitive to outliers, which can significantly degrade their performance. To address this issue, we integrate the Minimum Regularized Covariance Determinant (MRCD) algorithm into the Fisher discriminant framework, resulting in the MRCD-Fisher discriminant model. The MRCD algorithm enhances robustness by regularizing the covariance matrix, making it suitable for high-dimensional data where the number of variables exceeds the number of observations. We conduct comparative experiments with other robust discriminant methods, the results demonstrate that the MRCD-Fisher discriminant outperforms these methods in terms of robustness and accuracy, especially when dealing with data contaminated by…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
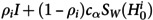 Fig 1
Fig 1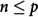 Fig 2
Fig 2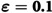 Fig 3
Fig 3 Fig 4
Fig 4 Fig 5
Fig 5- —National Natural Science Foundation
- —http://dx.doi.org/10.13039/501100018547Program for First-class Discipline Construction in Guizhou Province
- —http://dx.doi.org/10.13039/501100018533Major Scientific and Technological Special Project of Guizhou Province
- —http://dx.doi.org/10.13039/100020725Hubei Key Laboratory of Intelligent Geo-Information Processing
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Statistical Methods and Models · Spectroscopy and Chemometric Analyses · Face and Expression Recognition
1 Introduction
With the advent of the big data era, the challenges of data analysis, particularly the impact of outliers, have become increasingly prominent. Outliers can significantly distort the results of traditional statistical methods, especially in high-dimensional data settings [1–3]. Robust algorithms have demonstrated their significant role in handling outliers and enhancing system robustness in fields that require precise data analysis. For instance, in traffic signal control, robust algorithms optimize traffic flow by filtering out anomalous data, reducing congestion, and improving road safety [4]. In autonomous driving systems, outliers in sensor data can lead to incorrect navigation decisions, posing serious safety risks [5]. In satellite navigation systems, robust algorithms identify and exclude abnormal signals, significantly enhancing positioning accuracy and reliability, especially in complex environments such as multipath effects or interference [6]. In coal refinery techniques, robust algorithms ensure the stability of production processes and the consistency of product quality by handling anomalous data, thereby reducing resource waste [7]. In wireless communication systems, robust algorithms improve the accuracy of channel estimation and signal detection, enhancing the stability of communication systems, particularly in high-density communication scenarios such as 5G and the Internet of Things (IoT) [8]. Similarly, in financial data analysis, outliers can distort risk assessments and lead to flawed investment strategies [9, 10]. Overall, robust algorithms provide more reliable and efficient solutions by effectively managing outliers, significantly improving system performance and stability in these fields.
Common robust algorithms include M-estimation, least median square(LMS), genetic algorithm, minimum covariance determinant(MCD) method [11–13]. Due to its simple calculation principle and high accuracy, the MCD method was first proposed by Rousseeuw and Van Driessen [14]. Hubert and Debruyne introduced the equivariance, breakdown value and influence function of MCD estimator [15]. The MCD method has been widely adopted due to its ability to handle outliers effectively in low-dimensional data. However, as data dimensions grow, traditional MCD faces challenges, particularly when the number of variables exceeds the number of observations, leading to singularity issues in the covariance matrix.
To address these limitations, researchers have developed improved versions of the MCD algorithm. One direction focuses on combining MCD with other statistical methods to enhance its robustness. For example, Kimin Lee et al. [16] integrated MCD with linear discriminant analysis (LDA) to improve classification performance in the presence of outliers. Mutawa [17] applied MCD to state space models, effectively handling outliers in errors-in-variables (EIV) systems. Additionally, MCD has been incorporated into principal component analysis (PCA) to improve outlier resistance in constant false alarm rate (CFAR) detection [18]. Usman et al. [19] combined MCD with quantile regression to estimate population means in the presence of outliers.
Another direction focuses on optimizing the computational efficiency of MCD. Rousseeuw [20] proposed the FAST-MCD algorithm, which significantly improves the computational speed of the MCD method. Ella et al. [21] introduced a generalized MCD estimator based on the ranks of Mahalanobis distances, enabling the detection of intermediate outliers. Building on these advancements, Boudt et al. [22] introduced regularization into the MCD framework, resulting in the Minimum Regularized Covariance Determinant (MRCD) estimator. The MRCD method addresses the high-dimensional challenge by regularizing the covariance matrix, ensuring its positive definiteness even when the number of variables far exceeds the number of observations [23]. This makes MRCD particularly suitable for modern high-dimensional data analysis tasks.
In recent years, machine learning methods have gradually gained popularity, leading to the emergence of tests for the application of machine learning methods to high-dimensional data and discriminant analysis. JOHN et al. [24] define feature selection from the perspective of improving prediction accuracy as a process that can increase classification accuracy or reduce the feature dimension without compromising classification accuracy. In past research, feature selection has received extensive attention and exploration in the field of machine learning. The FSBRR algorithm proposed by ZHANG et al. [25] combines vertical and horizontal correlations along with mutual information to identify and remove redundant features, achieving remarkable results in biomedical data analysis. Similarly, the method proposed by GHADDRA et al. [26] based on iteratively adjusting the classifier vector norm bounds has demonstrated good performance in the feature selection problem of support vector machines, with low computational cost and error rate. On the other hand, QARAAD et al. [27] proposed a hybrid feature selection optimization model (ENSVM) based on cancer classification, which can more effectively reduce the number of features and improve classification performance compared to traditional methods. At the same time, TIAN et al. [28] proposed an Extreme Gradient Boosting (XgBoost) method based on Feature Importance Ranking (FIR), which has been successfully applied in high-dimensional complex industrial systems, achieving excellent fault classification performance.
In addition to these methods, some research has focused on improving traditional discriminant analysis algorithms. After more than a decade of development, many methods have been proposed from the aspects of improvement of discriminant analysis methods [29–32], discriminant problems in high-dimensional data [33–35], and the selection of discriminant models [36]. The primary contribution of this paper is the development of the MRCD-Fisher discriminant, which addresses several key limitations of traditional Fisher discriminant methods. Traditional Fisher discriminant analysis is highly sensitive to outliers, which can severely degrade its performance in high-dimensional settings. The MRCD-Fisher discriminant mitigates this issue by incorporating a robust covariance matrix estimation that is less influenced by outliers. This is achieved through the regularization of the covariance matrix, which ensures stability and accuracy even when the data dimension is much larger than the sample size.
Moreover, the MRCD-Fisher discriminant offers significant advantages over existing robust methods such as MVE, MCD, OGK, and RegMCD. For instance, while MCD-based methods are effective in low-dimensional settings, they often fail in high-dimensional scenarios due to the singularity of the covariance matrix. The MRCD-Fisher discriminant overcomes this limitation by employing a regularization technique that maintains the positive definiteness of the covariance matrix, even in high-dimensional contexts. This makes our method particularly suitable for modern data analysis tasks where the number of variables can be extremely large.
To demonstrate the superiority of the MRCD-Fisher discriminant, we conduct extensive comparative experiments with other robust discriminant methods. Our results show that the MRCD-Fisher discriminant consistently outperforms these methods in terms of robustness and accuracy, especially when dealing with data contaminated by outliers. For example, in a simulation study with 15% outliers, the MRCD-Fisher discriminant achieved an error rate of only 2.6%, compared to 3.7% for RegMCD and 5.1% for OGK. These findings highlight the practical importance of our approach in real-world applications where data quality is often compromised by outliers.
In summary, the MRCD-Fisher discriminant represents a significant advancement in the field of robust statistical analysis. By effectively addressing the limitations of traditional Fisher discriminant methods and outperforming existing robust techniques, our approach provides a reliable and efficient solution for high-dimensional data analysis. The broader impact of this work extends to various domains, including finance, healthcare, and autonomous systems, where accurate and robust data analysis is crucial for decision-making.
2 Fisher discriminant based on MRCD
To improve traditional Fisher discriminant methods, a robust algorithm must serve as a basis. The Minimum Regularized Covariance Determinant (MRCD) algorithm is a high-dimensional robust estimation method that addresses the limitations of traditional Fisher discriminant analysis, particularly its sensitivity to outliers. The MRCD algorithm enhances robustness by regularizing the covariance matrix, making it suitable for high-dimensional data where the number of variables exceeds the number of observations. This section provides a detailed description of the MRCD algorithm, its parameter adjustments, and its integration into the Fisher discriminant framework.
2.1 MRCD algorithm overview
The MRCD algorithm is an extension of the Minimum Covariance Determinant (MCD) method, which is known for its robustness against outliers. However, traditional MCD methods face challenges in high-dimensional settings because of the singularity of the covariance matrix when the number of variables exceeds the number of observations. The MRCD algorithm overcomes this limitation by introducing regularization, ensuring the positive definiteness of the covariance matrix even in high-dimensional contexts.
The MRCD algorithm involves the following key steps:
Data Preprocessing. The original data is preprocessed using quantile standardization. For each variable, the median is computed and stacked into a location vector . A diagonal matrix DX is constructed, where each diagonal element represents the quantile estimate for the corresponding variable. The standardized observations are then calculated as:
where xi represents the original data points.Regularized Covariance Matrix. The MRCD algorithm introduces a regularization step to ensure the stability of the covariance matrix in high-dimensional settings. The regularized covariance matrix K(H) is defined as:
where:
- T is a symmetric positive definite target matrix, defined as , with Jp being a matrix of ones and Ip the identity matrix.
- SU(H) is the original covariance matrix of the subset H, calculated as:
where h is the number of samples in the subset, and mi(H) is the mean of the subset.
- is the regularization coefficient, controlling the balance between the target matrix T and the original covariance matrix SU(H).
- ca is a consistency factor that ensures the robustness of the estimator.
Regularization Parameter Adjustment. The parameter c in the target matrix T plays a critical role in ensuring the positive definiteness of the matrix. It is typically chosen within the range , where p is the number of variables. This range ensures that the target matrix T remains positive definite, which is essential for the stability of the MRCD algorithm in high-dimensional settings. The target matrix T is spectral decomposed, , Q is the diagonal matrix composed of eigenvalues. Let , , then Eq (4) can be expressed as follows:
The value of c can be adjusted based on the data dimension and the desired level of robustness. In practice, cross-validation or grid search methods can be used to optimize c for specific datasets.Subset Selection and Iteration. The MRCD algorithm iteratively selects subsets of the data to minimize the determinant of the regularized covariance matrix. The subset HMRCD that yields the smallest determinant is chosen, and the corresponding mean mMRCD and covariance matrix KMRCD are used for further analysis.
2.2 Integration with Fisher discriminant
The MRCD-Fisher discriminant integrates the MRCD algorithm into the traditional Fisher discriminant framework to enhance its robustness against outliers. The key steps are as follows:
Robust covariance estimation. The MRCD algorithm is used to estimate the robust covariance matrix KMRCD and the mean mMRCD for each class. This ensures that the discriminant analysis is less sensitive to outliers.Mahalanobis distance calculation. The Mahalanobis distance is computed for each observation using the robust covariance matrix KMRCD and the mean mMRCD. The class center Mahalanobis distance D(X,Gi) is calculated for distance discrimination [37].Discriminant rule.The category of a sample X is determined based on the discriminant rule:
where W(X)i,j represents the discriminant score between classes Gi and Gj.
2.3 Workflow and implementation
To facilitate reproducibility and validation, the workflow of the MRCD-Fisher discriminant is illustrated in (Fig 1). The flowchart provides a step-by-step breakdown of the algorithm, including data preprocessing, subset selection, regularization, and discriminant analysis. This visual representation enhances the clarity and accessibility of the method.
Calculate the MRCD matrix flowchart.Selecting a subset from six candidate subsets that makes ρiI+(1−ρi)cαSW(H0i) with the smallest determinant and record it as HMRCD. Taking mMRCD and KMRCD into Mahalanobis distance and calculate the class center Mahalanobis distance D(X,Gi) for distance discrimination [38].
3 Model testing
3.1 Numerical illustration
In the simulation experiment, the model is independent of the specific correlation matrix by using the random number matrix calculation. To contaminate the data sets, let the outlier ratio to be either (clean data), or . A mixed distribution model with the 600 sample size which is generated randomly by R software in Equation (7)
where and obey p dimensional normal distribution. Generally, the dimension of high-dimensional data is greater than the sample size [39]. In order to distinguish the experimental results of high-dimensional data from non-high-dimensional data, p is taken as 10 or 50.
3.2 Robustness tests
In order to explore the applicability and robustness of the MRCD-Fisher discriminant, we compare the model with MVE, MCD, OGK and RegMCD robust algorithms.
The minimum volume ellipsoid estimator(MVE) of location approximate estimate provides the raw estimate of the location, and the rescaled covariance matrix is the raw estimate of scatter. The Mahalanobis distances of all observations from the location estimate for the raw covariance matrix are calculated, and the points within of the Gaussian assumptions pass the test.
Fisher discriminant analysis based on MCD (MCD-Fisher discriminant) improves the robustness of the model and reduces its sensitivity to outliers. As we all know that robust covariance matrix on multidimensional data can be obtained based on the MCD estimation [40]. However, it is worth noting that when the number of samples in the subset is less than the dimension, the determinant of the subset covariance matrix must be zero [41]. MCD-Fisher discriminant can improve the data quality, and increases the data dimension at the same time.
Based on the simple robust bivariate covariance estimator, the Estimation—Ortogonalized Gnanadesikan—Kettenring (OGK) method is proposed in the reference [42] and studied systematically by Devlin et al. [41]. Similar to the MCD estimator for a one-step re-weighting, The OGK estimator was improved by Todorov and Filzmoser [43] to process high-dimensional data. Because of ignoring the requirements for affine equivariance of the covariance matrix, OGK estimates can compete faster with high breakdown point.
The Regularized minimum covariance determinant (RegMCD) proposed by Gschwandtner and Filzmoser [44], its core idea is to maximize the penalty likelihood function. The sparsity of the algorithm is controlled by the penalty parameter. Possible outliers are dealt with by a robustness parameter, which specifies the observed measurement for maximizing the likelihood function. The results of the model largely depends on the values of penalty parameter and robustness parameter, but it is often difficult to find the most appropriate parameter in practical applications.
We used a comparative experiment to verify the robustness of MRCD-Fisher discriminant. Six groups of data with different dimensions and different pollution rates are used for simulation experiments. We repeat repeat each experiment 100 times. The MRCD-Fisher discriminant and other discriminants are calculated shown in Fig 2 based on the six groups of data. The sample category centers for the partial test set were calculated using the MCD-Fisher discriminant, OGK-Fisher discriminant, and MRCD-Fisher discriminant as shown in the supporting information 5.
Calculate the MRCD matrix flowchart.Different Fisher discriminants calculate variance of simulation data. When n≤p the robust covariance matrix based on MCD and MVE estimation cannot be calculated. Data 1(n=200,p=50,ε=0), Data 2(n=100,p=100,ε=0), Data 3 (n=200,p=50,ε=0.1), Data 4(n=100,p=100,ε=0.1), Data 5(n=200,p=50,ε=0.15), Data 6(n=100,p=100,ε=0.15).
From the above figures, we can find that when there are no outliers for the data, the calculation results of different algorithms are similar and the effects are same. As there are outliers for the data, with the exception of the MVE-Fisher discriminant method, several other robustness methods have a clear positive diagonal, which shows that they can avoid the influence of outliers. In the images of MCD-Fisher discriminant and MRCD-Fisher discriminant, the color of diagonals areas is obvious in Fig 2c and 2f which means the robust effect is more remarkable, but the former is not applicable to high-dimensional data. Compared with Fig 2d and 2f, there are outliers for the data, the robustness of MRCD-Fisher discriminant is also better than that of OGK-Fisher discriminant, which shows that MRCD-Fisher discriminant can be applied to high-dimensional data and the robustness is completely preserved. The results of RegMCD and MRCD have the highest similarity shown in Fig 2e and 2f, but there are still obvious differences in the off-diagonal region, the data cleanliness of MRCD algorithm is higher.
3.3 Discrimination effectiveness test
The sample mean and covariance matrix are important factors affecting the discrimination criterion which is an important aspect in Fisher discriminant. However, these two statistics are sensitive to outliers and can lead to a large deviation of the final conclusion. It is necessary to ensure the quality of the data using Fisher discriminant model, so the application of this model is greatly limited. Fig 3 shows the results of calculating the eigenvalue vector for the outlier data compared with traditional Fisher distribution.
Distance plot (a) and tolerance ellipse (b) of eigenvalue with ε=0.1.
It is well known that outliers are universal. Therefore, the traditional discriminant results will be deviated from the original results, and the overlap rate will gradually decrease. We can find from Fig 3, the tolerance ellipse of MRCD-Fisher discriminant excludes the interference of outliers and ensures the effectiveness of the algorithm. We perform traditional Fisher discriminant and above 5 Fisher discriminants with different simulated datas. Then, the calculated results of each observation are compared with the original types, and the counting the error proportion is shown as Table 1.
Table 1: Comparison of simulation data discriminant analysis error rate.
From Table 1, it is evident that the MRCD-Fisher discriminant consistently outperforms other methods in terms of robustness and accuracy, especially when dealing with data contaminated by outliers. For example, in the case of outliers , the MRCD-Fisher discriminant achieves an error rate of only 2.6%, compared to 3.7% for RegMCD and 5.1% for OGK. This demonstrates the superior robustness of the MRCD-Fisher discriminant in high-dimensional settings. Whether the data are high-dimensional or contain outliers, the MRCD-Fisher discriminant error rate is below , which is significantly lower than other discriminant analyzes. So, MRCD-Fisher discriminant has better effectiveness.
3.4 Efficiency and scalability
As above, we visually compare the five robust Fisher discriminant analyses constructed. From the perspective of the basic principle and calculation steps of the model, the algorithm of MVE and OGK has a shorter running time, the other three methods have a longer running time. In terms of solving outliers, RegMCD and MRCD have a better ability, but MRCD has a higher cleanliness to process outliers, and the robustness effect of MRCD is the best. When constant, the error rate of low-dimensional data is generally low, which is the same feature of the five robust algorithms. Even for the same algorithm, the error rate of high-dimensional data will increase significantly. From the comparison of several robust algorithms, it is easily found that the error rate of OGK, RegMCD and MRCD is low. Next, the effectiveness and robustness of different algorithms are tested and compared based on empirical data.
Although the MRCD-Fisher discriminant shows excellent robustness, it is important to discuss its potential limitations, particularly in terms of computational efficiency and scalability. The MRCD algorithm involves iterative subset selection and regularization, which can be computationally intensive for extremely large datasets. For example, when the number of variables p exceeds several thousand, the computational cost of the MRCD algorithm can become prohibitive. To address this, future work could explore parallel computing techniques or approximate algorithms to improve the scalability of the MRCD-Fisher discriminant.
To provide a clear overview of the performance of different robust discriminant methods, we summarize their key characteristics, advantages, and limitations in Table 2. This table highlights the robustness, computational efficiency, and scalability of each method, based on the experimental results presented in this study.
Table 2: Comparison of robust discriminant methods.
From Table 2, it is evident that the MRCD-Fisher discriminant offers the highest robustness to outliers and is well-suited for high-dimensional data. However, its computational efficiency is lower compared to methods like OGK and MVE, particularly for extremely large datasets. This trade-off between robustness and computational cost should be considered when selecting a discriminant method for specific applications.
4 Application to real data
4.1 Outlier detection and robustness
In this subsection we compare the performance of MCD-Fisher discriminant, OGK-Fisher discriminant and MRCD-Fisher discriminant using the financial financial enterprises database, which consists of 600 training data and 90 test data. Each sample includes 53 variables, such as operating income, profit and loss on asset disposal, cash flow from operating activities, cash received from disposal of fixed assets, net operating profit, etc. In addition, the operational status of financial companies is divided into 6 levels based on the balance sheet data of the past 5 years. In the training data, companies with severe losses accounted for , losses accounted for , normal operations accounted for , profits were , extraordinary profits were , and the maximum profit was .
It should be noted that we do not know whether there are outliers in the training data. The choice of subset size h is important because increasing h can improve the efficiency and reduce the robustness to outliers. In n iterations, our recommended default choice is to ensure the robust algorithms covariance estimate against up to of outliers.
In the distance detection between the data, we can determine the existence of outliers and find out the fuzzy position of outliers. In Fig 4, the red triangle marks suspicious outliers, Because the financial data change rule is not significant, there are a large number of suspicious outlier in the training data. The identified outlier points are samples numbered 1, 2, 6, 7, 494, 652, 672, 684, 686 respectively. The results of the discriminant analysis are presented in Table 3, which shows the error rates of different methods.
Distance data of outlier detection.
Table 3: Classification and abbreviation of enterprise operation status.
From Table 4, it is clear that the MRCD-Fisher discriminant achieves the lowest error rate (0.12001) compared to other methods, demonstrating its superior robustness in real-world applications. However, it is worth noting that the computational time of the MRCD-Fisher discriminant is longer than that of MVE and OGK, particularly for high-dimensional datasets. This highlights a trade-off between robustness and computational efficiency, which should be considered when applying the MRCD-Fisher discriminant to large-scale datasets.
Table 4: Comparison of financial enterprises data discriminant analysis results.
Due to significant dimensional differences in different variables, it is necessary to standardize the data before conducting robust calculations. Then, based on the distance center conclusion in Fig 4 and the comparison of the five models in Section 3, calculate the MRCD robust distance center points for each sample (normalized).The calculation results are presented in Tables 5 and 6 .
Table 5: Calculation of partial testing set sample class center by MRCD-Fisher discriminant method (2).
Table 6: Calculation of partial testing set sample class center by MRCD-Fisher discriminant method (1).
In Fig 5, the distance between each testing sample point of the robust discriminant and various centers is small. However, in the traditional discriminant algorithm, the center distance of testing sample points is much higher than 0.02 units. There will be a lot of fuzzy discrimination, which can lead to the wrong discriminant result. Next, based on the center distances and discriminated according to Fig 1, we obtain error proportion in the different model calculations, as shown in Table 5. This is a clear example that traditional Fisher discriminant affected by outliers is so strong, that the error rate of result is much highly.
Center distance data of traditional discriminant (a), MVE-Fisher discriminant (b), MCD-Fisher discriminant (c), OGK-Fisher discriminant (d), RegMCD-Fisher discriminant (e) and MRCD-Fisher discriminant (f).
Finally, we note that MRCD can be plugged into existing algorithms for variable classification, which avoids the limitation mentioned in Valentin et al. [31] that “a robust fit of the full model may not be feasible due to the numerical complexity of robust estimation when the dimension p is large or simply because p exceeds the number of cases.” The MRCD-Fisher discriminant could be used in such situations because it feasible in higher dimensions.
4.2 Limitations and future work
While the MRCD-Fisher discriminant offers significant advantages in terms of robustness, its computational complexity may limit its applicability to extremely large datasets. Future research could focus on optimizing the MRCD algorithm for scalability, potentially through the use of parallel computing or dimensionality reduction techniques. Additionally, the current implementation of the MRCD-Fisher discriminant requires careful tuning of the regularization parameter c, which may not be straightforward for users without a strong statistical background. Developing automated parameter tuning methods could further enhance the usability of the MRCD-Fisher discriminant.
5 Conclusions
Aiming at the phenomenon of outliers in social science data, this paper built an effective method that combined the MRCD algorithm with Fisher discriminant. The MRCD-Fisher discriminant algorithm can effectively overcome the shortcomings of mean and covariance matrix sensitivity to outliers. After verifying the accuracy of MRCD-Fisher, this method is used to discuss the operational status rating of financial enterprises.
After obtaining the robust discriminant algorithm, the effectiveness and robustness of the model are verified by simulation tests. Considering the data dimension, we generate data sets with sizes of , , and then add outlier data with different proportions. In low-dimensional data, the MRCD-Fisher discriminant performs asymptotically equivalently to the RegMCD-Fisher discriminant. Compared with the MRCD-Fisher discriminant and MVE-Fisher discriminant, it is found that the MRCD-Fisher discriminant is the most robust model and suitable for high-dimensional data. In the model application, we have demonstrated that the proposed robust discriminant can achieve superior performance when the data is corrupted by potential outliers, accurately rating the operational status of financial enterprises using 53 financial statement data from the past five years.
In this paper, five robust algorithms are embedded into the traditional principal component analysis, and the robust principal component analysis method suitable for high-dimensional data is constructed. The applicability and robustness of the MRCD-Fisher discriminant algorithm are better than other algorithms. This study fills the gap in the application of robust regularization estimation for high-dimensional data in discriminant algorithms. The MRCD estimator is computationally feasible for data on hundreds of variables, so the MRCD-Fisher discriminant expands the application scope of robust discriminant algorithms.
In the experiment in this paper, the setting of the parameters is based on the conventional standard of the existing references, so the setting of the regularization coefficient in the minimum regularized covariance matrix estimation can be further optimized. In future research, we want to try to use more robust algorithms to optimize the applicability of traditional statistical models. Additionally, future work could explore the application of the MRCD-Fisher discriminant in dynamic or streaming data scenarios, where data is continuously generated and requires real-time analysis. This extension could further enhance the method’s applicability in fields such as financial markets, and autonomous systems, where data streams are prevalent and require robust, real-time outlier detection and classification.
Supporting information
S1 TableCenter of sample class of the test set.Calculation of the center of sample class of the partial test set using MCD-Fisher discriminant, OGK-Fisher discriminant and MRCD-Fisher discriminant methods(PDF)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zheng H, Jin S. A multi-source fluid queue based stochastic model of the probabilistic offloading strategy in a MEC system with multiple mobile devices and a single MEC server. Int J Appl Math Comput Sci. 2022;32(1):125–38. doi: 10.34768/amcs-2022-0010 · doi ↗
- 2Zheng W, Xun Y, Wu X, Deng Z. A comparative study of class rebalancing methods for security bug report classification. Comput J. 2022;65:1189–99.
- 3Huan W, Qing G, Hao L. A structural evolution-based anomaly detection method for generalized evolving social networks. IEEE Trans Reliab. 2021;170:1–13.
- 4Zibin W, Tao P, Sijia W. A robust adaptive traffic signal control algorithm using Q-learning under mixed traffic flow. Sustainability. 2022;14:5751.
- 5Victor S, Receveur JB, Melchior P, Lanusse P. Optimal trajectory planning and robust tracking using vehicle model inversion. IEEE Trans Intell Transp Syst. 2022;23:4556–69.
- 6Lu J. Research on the RAIM algorithm of Beidou satellite navigation system based on robust estimation. In: 2022 4th International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 2022, pp. 777–80.
- 7Hua X, Shuqiang C, Prabhu M, Sahu AK. Coal refinery process absorbability index assessment against foot print of air pollution by usage of robust optimization algorithms: a novel green environment initiative. Adsorpt Sci Technol. 2021;320(6):15.
- 8Duy H, Dengy Y, Xueyz J. Robust online CSI estimation in a complex environment. IEEE Trans Wireless Commun. 2022;21:8322–36.