Random heterogeneous spiking neural network for adversarial defense
Jihang Wang, Dongcheng Zhao, Chengcheng Du, Xiang He, Qian Zhang, Yi Zeng

TL;DR
This paper introduces RandHet-SNN, a spiking neural network that improves robustness against adversarial attacks by mimicking biological neuron diversity.
Contribution
The novel contribution is introducing randomized time decay constants to create neuron-level diversity in spiking neural networks for adversarial defense.
Findings
RandHet-SNN significantly enhances adversarial robustness while preserving clean accuracy.
The method outperforms randomization techniques in artificial neural networks.
Neuronal heterogeneity and spiking variability improve network resilience.
Abstract
Spiking neural networks (SNNs) offer a biologically inspired alternative to artificial neural networks (ANNs) by mimicking neuronal information transmission mechanisms. However, similar to ANNs, SNNs remain susceptible to adversarial examples, raising concerns about their robustness in practical applications. To address this vulnerability, we propose the Random Heterogeneous Spiking Neural Network (RandHet-SNN), inspired by the heterogeneity and stochasticity observed in biological neural systems. This architecture strengthens the network’s defense against adversarial attacks by introducing neuron-level diversity through randomized time decay constants, allowing each neuron to acquire unique temporal properties at every forward pass. We evaluate RandHet-SNN’s performance through extensive experiments with various adversarial attacks. Results indicate that RandHet-SNN significantly…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
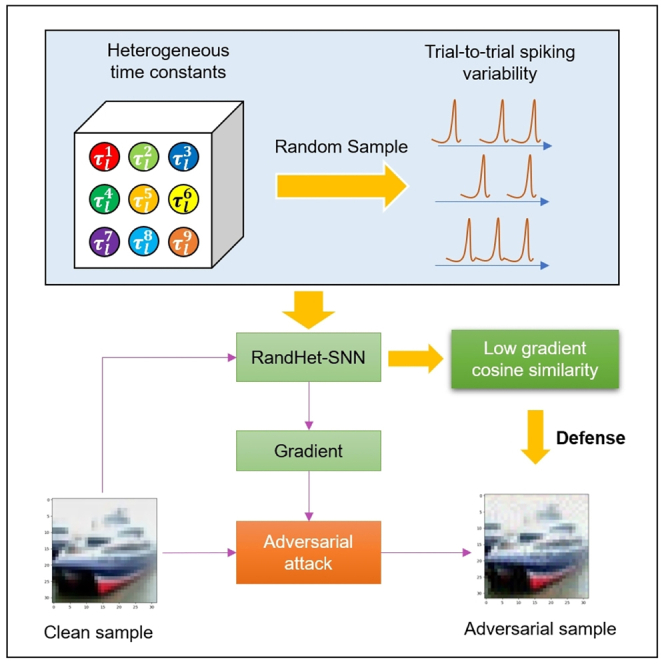 Figure 1
Figure 1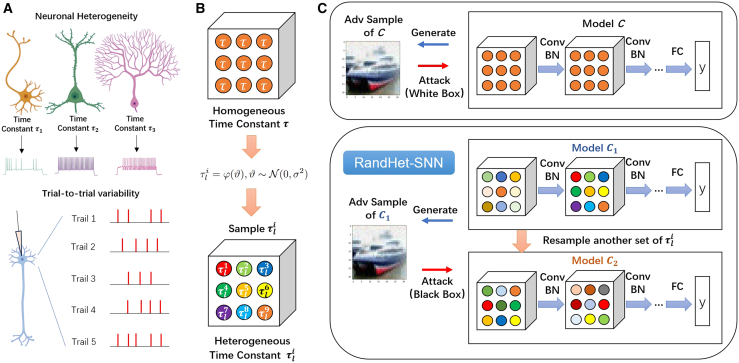 Figure 2
Figure 2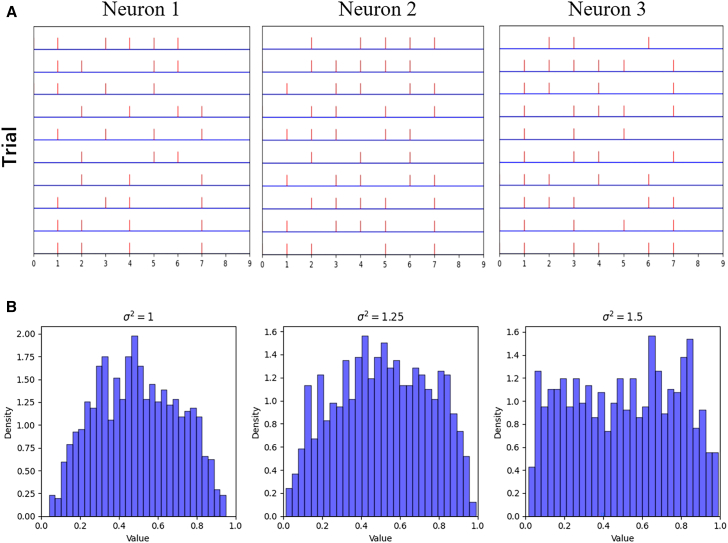 Figure 3
Figure 3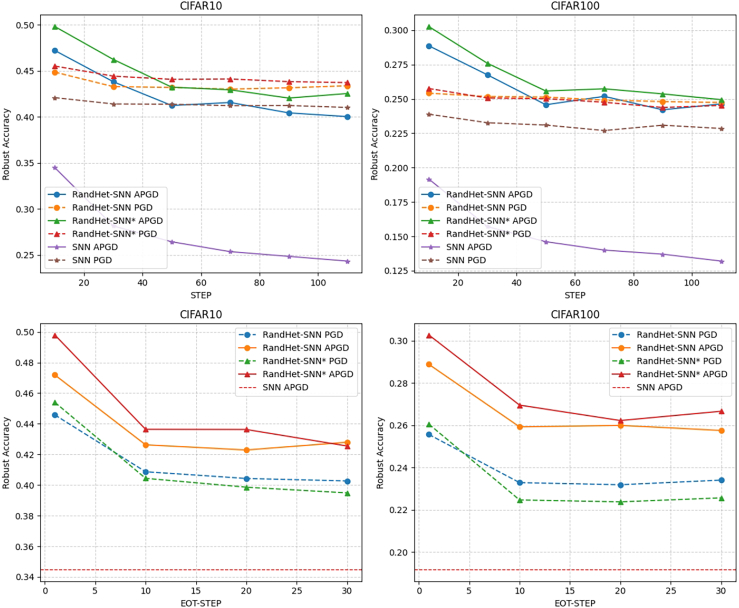 Figure 4
Figure 4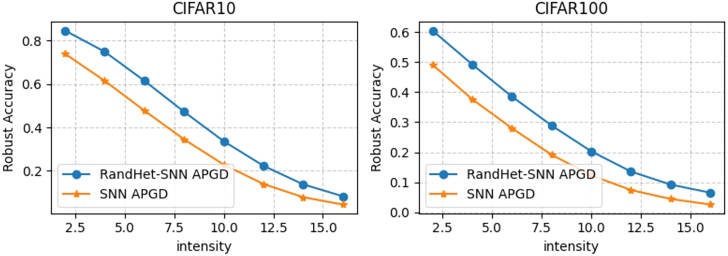 Figure 5
Figure 5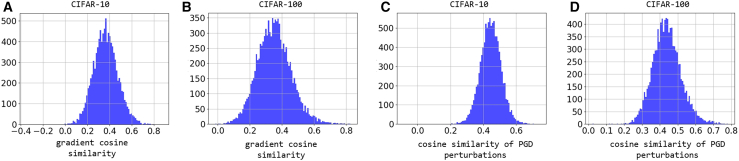 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Memory and Neural Computing · Adversarial Robustness in Machine Learning · Neural Networks and Reservoir Computing
Introduction
Deep neural networks have demonstrated remarkable success in processing high-dimensional data, enabling significant breakthroughs in areas such as computer vision and natural language processing.1^,^2 However, concerns regarding the robustness of DNNs, particularly their vulnerability to adversarial attacks, remain a major limitation.3^,^4 In image classification, for instance, adversarial attacks can introduce subtle perturbations that are nearly imperceptible to human observers yet cause models to misclassify inputs. This vulnerability critically undermines the reliability of DNNs in safety-critical applications, such as autonomous driving,5 highlighting a fundamental discrepancy between the perception mechanisms of DNNs and the human visual system.
Incorporating stochastic mechanisms is a promising approach to enhancing adversarial robustness in neural networks.6^,^7^,^8^,^9^,^10^,^11 Xie et al. demonstrated that preserving randomness in input padding and resizing during inference disrupts attack patterns, thereby improving resilience to adversarial perturbations.6 A widely adopted approach, randomized smoothing, adds Gaussian noise to the network inputs offering certified robustness against adversarial attacks.11 Dong et al. observed that adversarial attacks exhibit limited transferability across networks with different normalization methods, which led to the development of the Random Normalization Aggregation (RNA) approach. This method forces attackers to adopt black-box strategies, thereby strengthening defensive capabilities.8 Random Projection Filters (RPF) apply random projections within convolutional layers, enabling random sampling during both training and inference to boost robustness by increasing stochasticity in the network.9 Ma et al. introduced Constrained Trainable Random Weights (CTRW) to increase gradient variance during inference, which improved adversarial defense but also led to a trade-off in clean accuracy.10
Traditional artificial neural networks (ANNs) rely on floating-point values to represent neuron firing rates, whereas spiking neural networks (SNNs) model neural activity through discrete temporal spikes, closely mimicking biological neural behavior. This spiking mechanism allows SNNs to achieve higher energy efficiency on neuromorphic hardware, making them more suitable for power-constrained applications.12^,^13 Specifically, neurons in SNNs have binary activation states (0 or 1), allowing matrix multiplications in forward propagation to be executed with additions, thereby reducing energy consumption. Despite their advantages in energy efficiency and biological plausibility, SNNs are similarly vulnerable to adversarial perturbations.14^,^15 Various strategies have been explored to improve adversarial robustness in SNNs. Adversarial defenses in SNNs draw inspiration from methods used in ANNs while also leveraging the distinct characteristics of SNNs, including adversarial training,16^,^17 certified training,18 regularization-based methods19^,^20 and random smoothing method.21 Ding et al. examined biological principles related to stochastic gating mechanisms in synapses and introduced randomness into the input currents of neurons. This stochastic modulation of input currents was found to enhance adversarial robustness in SNNs by incorporating biological insights into synaptic variability.22
Notably, neural activity in the visual cortex of the biological brain exhibits substantial randomness,23 suggesting a potential link between stochastic information processing and robustness. In response to identical stimuli, neuronal activity in the nervous system varies due to intrinsic randomness, enabling the system to filter out environmental noise and focus on essential information.24
Additionally, unlike most ANNs and SNNs, which typically employ standardized activation functions or membrane potential dynamics, biological neural networks exhibit marked heterogeneity in their electrophysiological properties. The nervous system comprises diverse neuron types, and this variability contributes to system-level redundancy and fault tolerance. When certain neuron types are damaged, other neurons can partially compensate for their functions, enabling the system to maintain functionality.25 Research suggests that this diversity in neuronal parameters enhances network robustness.26^,^27
Previous works have primarily introduced random parameters in the weights, biases, or normalization layers of ANNs, rather than randomizing the parameters within the activation function, which does not highlight the heterogeneity of neurons in the network.6^,^7^,^8^,^9^,^10 To overcome these limitations, this paper presents the Random Heterogeneous Spiking Neural Network (RandHet-SNN), an architecture that incorporates stochasticity and heterogeneity in neuronal responses by randomizing neuron time constants within SNNs. The random time constants can introduce neuronal heterogeneity into the network, which is a potential factor for enhancing the robustness of the network’s information processing. We evaluate RandHet-SNN on CIFAR-10 and CIFAR-100 datasets28 under a range of adversarial attack methods. Experimental results demonstrate that RandHet-SNN provides substantial improvements in both adversarial robustness and clean accuracy, effectively complementing adversarial training techniques. Compared to previous works based on random parameters, RandHet-SNN shows better clean accuracy and robust accuracy under attacks based on Expectation Over Transformation (EOT). These findings suggest that incorporating stochastic and heterogeneous features within SNNs enhances their defensive capabilities against adversarial attacks while also improving baseline performance.
Results
Random heterogeneous spiking neural network
Randomness in information processing and neuronal heterogeneity are foundational characteristics of biological neural networks. Different types of neurons often exhibit distinct electrophysiological properties. Due to inherent randomness in the nervous system, neurons may display varied spiking responses to identical inputs, as shown in Figure 1A. In SNNs with leaky integrate-and-fire (LIF) neurons, the time constant is a crucial parameter that regulates each neuron’s membrane potential dynamics. Therefore, neuronal heterogeneity can be achieved through different neuron time constants .26 Building on this, we propose the RandHet-SNN, which incorporates both randomness and heterogeneity by randomizing neurons’ time constants. This design enables RandHet-SNN to emulate biological neural networks more effectively, introducing diversity in neuronal parameters and randomness in information processing.Figure 1A conceptual diagram illustrating the biological inspiration behind the RandHet-SNN, its overall architecture, and the adversarial defensive mechanism(A) Top: Biological neurons exhibit diverse electrophysiological properties. For the LIF model, neuronal heterogeneity can be achieved through different neuron time constants . Bottom: The spiking responses to the same input vary across different trials. This trial-to-trial variability is induced by randomness inherent in the nervous system.(B) In a vanilla SNN, all neurons have the same time constant, whereas in RandHet-SNN, each neuron independently samples its time constant during each forward pass, resulting in a heterogeneous network after sampling.(C) Diagram of the RandHet-SNN. Top: In vanilla SNNs, adversaries can generate white-box attacks on the model using network gradients. Bottom: RandHet-SNN samples random time constants to generate a specific set of network parameters, represented by model . The attacker uses the gradients of to create adversarial examples. However, when these adversarial examples are input into RandHet-SNN, the time constants are resampled, resulting in a new network denoted as model . Consequently, the adversarial perturbations generated based on may not remain effective against .
In RandHet-SNN, each neuron within every network layer is assigned an independent random variable as its time constant. During forward propagation, these time constants are sampled from a predefined distribution, allowing neurons across the network to exhibit both heterogeneity and randomness.
We define each neuron’s time constant as an independent random variable. In this paper, two sampling methods for the time constants are utilized. The first method involves independently sampling the time constants at each time step, while the second method samples the time constants at the beginning of each forward pass maintaining them as constant for all subsequent time steps.
RandHet-SNN uses the first sampling method by default and we use RandHet- to indicate that the model employs the second sampling method. Each neuron samples independently during each forward propagation, as illustrated in Figure 1B. This independent sampling mechanism allows each neuron to exhibit distinct dynamic characteristics during different forward propagation processes, thereby enhancing the network’s randomness and heterogeneity.
The Figure 2A shows the spike sequences of three neurons in RandHet-SNN under the same input across different trials. As seen in the figure, the random LIF neurons in RandHet-SNN exhibit strong trial-to-trial variability, which is consistent with the response characteristics of biological neurons.23^,^29Figure 2. The trial-to-trial variability and time constants distribution in RandHet-SNN(A) The spike trains of neurons across different trials under the same input. The figure shows that neuron responses with random time constants exhibit trial-to-trial variability.(B) Distribution of time constants for different variances . Each subfigure shows values (x axis) versus their probability density (y axis), with density calculated as , where is the sample count in the i-th bin and is the bin width.
We further examine the distribution of time constants under varying values of variance, as shown in Figure 2B. When the variance is set to 1.5, the distribution of time constants approximates a uniform distribution over the interval (0,1). As variance decreases, time constant values concentrate increasingly around 0.5.
The stochastic mechanism in RandHet-SNN disrupts an attacker’s ability to determine the network’s deterministic parameters, effectively transforming a white-box attack into a black-box scenario, as illustrated in Figure 1C.
Performance
Experimental settings
In this study, we evaluate the adversarial robustness of RandHet-SNN on the CIFAR-10 and CIFAR-100 datasets. The SNNs are implemented using the SEW-ResNet19 architecture,30 where neurons are modeled as LIF neurons with randomized time constants, a variance of , a threshold of , and a time step of . RandHet-SNN is trained for 100 epochs on each dataset.
To comprehensively evaluate the performance of RandHet-SNN when combined with different adversarial training methods, we use three adversarial training techniques for SNNs: standard adversarial training (AT), regularized adversarial training (RAT)16 and sparsity regularization(SR).20 Among these, the RAT and SR methods are well-established and effective techniques for training robust SNNs. For AT, we introduce regularization to enhance the network’s robustness, with a regularization coefficient of . For RAT and SR, the regularization coefficient is set to 0.004 and 0.001, respectively. Adversarial training samples are generated using the RFGSM method with a perturbation magnitude of , based on the -norm.
Adversarial attack settings
We evaluate RandHet-SNN’s robustness under multiple adversarial attack methods, including FGSM, PGD, AutoPGD (APGD), MIFGSM,31 and AutoAttack,32 with a perturbation magnitude of . and are used to denote PGD and APGD attacks with iterations, such as , where the step size per iteration is . For MIFGSM, the step size is 2/255 with a decay factor of 0.1 across 5 iterations.
To rigorously assess RandHet-SNN’s adversarial robustness, we address gradient obfuscation effects when generating white-box adversarial samples. In each attack iteration, we apply the EOT method33 to obtain more accurate gradient estimates. We use to represent the PGD attack with an iteration step size of n and EOT iteration count of m. This approach allows for a more precise evaluation of the model’s robustness against adversarial inputs.
Robustness against adversarial attacks
To evaluate adversarial robustness across multiple attack methods, we use the minimum robust accuracy (MRA) as the primary metric, as it provides the most rigorous assessment of the model’s resilience. The MRA captures the model’s performance under the strongest adversarial attacks, effectively reflecting its robustness in worst-case scenarios. This metric is thus crucial for a comprehensive evaluation of the model’s robustness across various adversarial settings. Table 1 summarizes the robust accuracy of RandHet-SNN and RandHet- trained with AT, RAT and SR, alongside that of vanilla SNNs with the same architecture, under different adversarial attacks. The numbers higher than the baseline are indicated in bold in the table.Table 1. Comparison of CIFAR-10 and CIFAR-100 performance across different adversarial attacksAttackCleanFGSMPGD_10_APGD_10_MIFGSMAutoAttackMRAaCIFAR-10SNN+AT86.3849.4841.1033.3145.2429.2929.29RandHet-SNN+AT87.3650.1341.79****47.6045.1248.59****41.79RandHet- +AT87.2952.5844.3350.6546.7350.3444.33SNN+RAT89.5552.2142.0934.4946.7630.3630.36RandHet-SNN+RAT90.2553.5344.8647.2047.4647.7644.86RandHet- +RAT89.8854.7446.0449.8048.1251.5746.04SNN+SR87.1350.4143.3536.0846.4232.9632.96RandHet-SNN+SR88.1150.9844.1947.5446.7647.4544.19RandHet- +SR88.1953.8247.3651.2649.3751.6147.36****CIFAR-100SNN+AT63.1325.0420.0815.9922.5912.7912.79RandHet-SNN+AT64.10****25.2719.9025.6422.0925.31****19.90RandHet- +AT63.5825.7921.07****28.3422.1927.22****21.07SNN+RAT68.1230.3323.8919.1726.7615.1415.14RandHet-SNN+RAT68.4531.8425.5628.8827.4527.1225.56RandHet- +RAT67.9631.9826.1930.2727.0330.13****26.19SNN+SR63.6025.7721.4717.0423.7113.8213.82RandHet-SNN+SR64.4626.3321.88****25.4623.0925.31****21.88RandHet- +SR65.0927.9323.2928.7324.8928.4423.29The data in the table represents the accuracy under the corresponding attacks.aMinimum Robust Accuracy (MRA).
As shown in Table 1, training vanilla SNNs with AT, RAT and SR methods yields limited adversarial robustness against APGD and AutoAttack. In contrast, RandHet-SNNs not only improve model accuracy but also significantly enhance robust accuracy under these attacks. Specifically, RandHet-SNN with the RAT method and RandHet- with the SR method achieve consistently higher robust accuracy across all attacks on both CIFAR-10 and CIFAR-100 datasets, with particularly notable improvements against APGD and AutoAttack. For the AT and SR method, although RandHet-SNNs show a slight decrease in robust accuracy on PGD and MIFGSM, the MRA still demonstrates a marked improvement in adversarial robustness compared to vanilla SNNs. These results demonstrate that both RandHet-SNN and RandHet-SNN∗ can be effectively integrated with various adversarial training methods to enhance the model’s robustness against a wide range of adversarial attacks. Models trained with RAT and SR methods exhibit similar performance, and outperform those trained with AT.
Since the RAT method requires fewer computational resources and less time than the SR method, we use the RAT approach by default for training the model in the subsequent analysis to further evaluate the performance of the RandHet-SNN. We compare the robust accuracy of RandHet-SNN, RandHet- , and vanilla SNNs across varying iteration step sizes for PGD and APGD attacks, as well as different EOT step sizes. Varying the PGD and APGD step sizes allows for assessing the model’s resilience under increasingly strong attacks, while adjusting the EOT step sizes helps mitigate the effects of gradient obfuscation in stochastic models.
In Figure 3, the first row illustrates robust accuracy on CIFAR-10 and CIFAR-100 under PGD and APGD attacks with different iteration step sizes. Dashed lines indicate the robust accuracy under PGD attack, while solid lines represent that under APGD attack. As the number of attack iterations increases, the robust accuracy decreases and stabilizes after the step size exceeds 50. Under both PGD and APGD attacks, RandHet-SNN and RandHet- demonstrate higher robust accuracy at each iteration step size compared to vanilla SNNs, with a more substantial improvement under APGD attacks.Figure 3. Robust accuracy of RandHet-SNN, RandHet- and vanilla SNNs under different attack settingsRobust accuracy of RandHet-SNN, RandHet- and vanilla SNNs under different PGD, APGD iteration step sizes, and EOT step sizes. Robust accuracy refers to a model’s classification accuracy on adversarial examples generated by corresponding adversarial attacks. Dashed lines indicate the robust accuracy under PGD attack, while solid lines represent that under APGD attack. The robust accuracy curves for RandHet-SNN are marked with “ ”, RandHet-SNN∗ uses “ ” markers, and SNN is marked with “ ”.
The second row shows the robust accuracy of both datasets across varying EOT step sizes. Since vanilla SNNs lack stochastic components, EOT testing is unnecessary for them. In the figure, the horizontal red dashed line represents the robust accuracy of the vanilla SNN under the attack. Notably, when the EOT step size exceeds 10, the robust accuracy of RandHet-SNNs stabilizes and remains consistently higher than that of vanilla SNNs. RandHet- is more affected by the EOT attack, with its robust accuracy slightly lower than that of RandHet-SNN under the PGD attack with large EOT step size.
Therefore, we conclude that the adversarial robustness of the two models is similar, with RandHet-SNN exhibiting greater robustness than RandHet-SNN∗ when trained with the RAT method. Consequently, we select RandHet-SNN for further analysis of its adversarial robustness under varying levels of perturbation intensity . As shown in the Figure 4, RandHet-SNN exhibits higher robust accuracy against the attack at various perturbation levels compared to the vanilla SNN.Figure 4. Robust accuracy of RandHet-SNN and vanilla SNN under varying levels of perturbation intensity The APGD robust accuracy curves with respect to on CIFAR-10 and CIFAR-100. The x axis represents the adversarial perturbation size in the pixel space, displayed in the 0–255 scale. RandHet-SNN are marked with “ ” and SNN are marked with “ ”.
To validate the generalization capability of the RandHet-SNN, we evaluate its performance on the more challenging TinyImageNet dataset.34 The results, shown in Table 2, indicate that both the MRA and clean accuracy of the RandHet-SNN outperform those of vanilla SNNs on this dataset, further demonstrating the effectiveness of our approach.Table 2. Comparison of the performance and adversarial robustness of RandHet-SNN and SNN on the TinyImageNet datasetAttackCleanFGSMMIFGSM MRASNN41.0624.4419.3216.397.947.94RandHet-SNN50.1728.0921.3311.1716.9911.17
Comparison with randomization methods in ANN
We compare the RandHet-SNN trained with the RAT method to comparable randomization techniques in ANNs (CTRW, RPF, and RNA) on CIFAR-10. All these methods require the generation of adversarial samples for training. To ensure a fair comparison, we control the adversarial sample generation process during training to be consistent across all four randomization methods. The results are shown in the Table 3. In the table, the Drop column represents the difference in robust accuracy between and . We find that the robustness accuracy of randomization methods in ANNs decreases significantly when subjected to EOT attacks, while the performance drop for the RandHet-SNN remains relatively small. Additionally, RandHet-SNN achieves both higher clean accuracy and higher robust accuracy under the attack compared to other ANN methods. This suggests that our RandHet-SNN is a more reliable randomization method.Table 3. Comparison of CIFAR-10 performance across different randomization methodsAttackClean DropaCTRW84.3765.5327.3138.22RNA89.4542.7226.3816.34RPF90.0140.1934.625.57RandHet-SNN90.1243.5040.15****3.35aDrop column represents the difference in robust accuracy between and
Sensitivity to variance
The primary enhancement of RandHet-SNNs over vanilla SNNs arises from the randomization of time constants in the LIF neurons. In the experiments above, we consistently set the variance for all layers of the network. We further analyze the adversarial robustness of networks with the random time constant mechanism introduced at different layers. In the SEWResNet19 structure we use, the network undergoes three down-sampling stages, dividing the network into three segments. We introduce the random time constant mechanism into each of these three segments separately, with , while the other parts of the network still use LIF neurons with deterministic time constants. We refer to the network with the random time constant mechanism introduced only in the i-th segment as RandHet- , and train it by RAT. The results are shown in the Table 4 below.Table 4. The performance of models with the random time constant mechanism introduced at different layersAttackCleanFGSMMIFGSM MRASNN89.5552.3346.7641.1326.4426.44RandHet- 89.6852.8047.0140.3838.6138.61RandHet- 88.5549.9744.8038.9536.5536.55RandHet- 88.9551.5645.8639.9131.4731.47RandHet-SNN90.1653.8547.5340.4038.6838.68
As shown in the table, introducing random time constants in the shallow layers of the network results in the most significant improvement in the model’s adversarial robustness compared to vanilla SNN. This highlights the importance of initial data processing for the model’s adversarial robustness. After randomizing all layers of the RandHet-SNN, although the model’s MRA does not show significant improvement, its clean accuracy is further enhanced.
Table 4 demonstrates superior performance when the random mechanism is applied across all layers, so we conducted additional experiments to analyze how the magnitude of random variance affects network performance under this configuration. We train RandHet-SNN with various variances using the RAT method and evaluated their robustness against attacks. The results are presented in Table 5.Table 5. Performance comparison on CIFAR-10 and CIFAR-100 across different variance settings under clean and attack conditionsDatasetCIFAR-10CIFAR-100AttackClean Clean 90.2538.7068.4123.64 90.4039.2267.8623.54 90.3338.9167.5824.71
The results indicate that RandHet-SNN is relatively insensitive to variations in the time constant’s variance. On CIFAR-100, while the network’s clean accuracy shows a slight decline as variance increases, robust accuracy demonstrates a marginal improvement. These findings suggest that the RandHet-SNN maintains stable performance across varying degrees of settings, thereby enhancing its adaptability and robustness.
Gradient cosine similarity analysis
The gradients of RandHet-SNN for the same input will vary due to the randomness in the model. Different time constant sampling results produce different gradients for the same input, and we analyze the cosine similarity of these gradient differences. We train RandHet-SNN on CIFAR-10 and CIFAR-100 by RAT and visualize the gradient cosine similarity distributions in Figures 5A and 5B. As shown, the cosine similarity of the gradients primarily clusters around 0.3, indicating that the transferability of adversarial attacks between models with different time constant samplings is relatively low.Figure 5. Cosine similarity analysis of gradients and adversarial perturbations(A and B) Distribution of the cosine similarity of gradients between models under different time constants sampling on CIFAR-10 and CIFAR-100.(C and D) Distribution of the cosine similarity of adversarial perturbations between models under different time constants sampling on CIFAR-10 and CIFAR-100. In each figure, the x axis represents the range of gradient cosine similarity values, while the y axis shows the count of samples falling within each corresponding interval.
Further, let represent the adversarial perturbation for model . We evaluate the difference between and by measuring their cosine similarity . We generate adversarial perturbations by PGD, and the results are shown in Figures 5C and 5D.
The figure shows that the cosine similarity of adversarial perturbations predominantly falls between 0.4 and 0.5, indicating that the stochastic mechanisms in RandHet-SNN introduce significant variability in the adversarial examples generated by models and . This variability effectively strengthens RandHet-SNN’s adversarial robustness, as attacks designed for one network instance are unlikely to transfer successfully to another due to inherent randomness in neuron parameters.
Moreover, for the RandHet-SNN trained with using RAT on CIFAR-10, we fix all other parameters and vary only the variance of the RandHet-SNN. We then analyze the influence of different random variances on the average gradient cosine similarity (AGCS). As shown in Table 6, larger random variance reduces the AGCS of the RandHet-SNN, while the model’s clean accuracy decreases due to increased randomness. However, the robust accuracy of the model under the attack increases as the AGCS decreases. This further demonstrates that the gradient differences induced by the randomness in the RandHet-SNN enhance the model’s adversarial robustness, while also leading to a trade-off between robustness and accuracy.Table 6. The influence of random variance on RandHet-SNN’s Average Gradient Cosine Similarity (AGCS), clean accuracy, and robust accuracyVarianceAGCSClean Acc Acc 0.419190.5827.66 0.365990.1638.70 0.309988.1238.74 0.256384.5940.53
Ablation study
We conduct further ablation experiments to test the adversarial robustness of SNNs when only neuronal heterogeneity is present. Following Xu et al.,35 we set the time constants of the neurons in the SNN as trainable parameters, allowing different neurons to learn heterogeneous time constants through training. We refer to this as heterogeneous SNN (Het-SNN). Furthermore, we compare the adversarial robustness of SNNs, Het-SNN, and RandHet-SNN trained with RAT, and the results are shown in Table 7.Table 7. Comparison of the performance of SNN, Het-SNN, and RandHet-SNN under different adversarial attacksAttackCleanFGSMMIFGSM MRACIFAR-10SNN89.5552.3346.7641.1326.4426.44Het-SNN89.3852.3846.8141.3426.5126.51RandHet-SNN90.1653.8547.5340.4038.6838.68****CIFAR-100SNN68.1230.4426.7623.2914.6114.61Het-SNN67.3630.1326.3522.8614.6014.60RandHet-SNN68.3631.6827.6723.2823.6423.28
As shown in the table, deterministic heterogeneous neuronal time constants do not improve the performance of the SNN. Therefore, we conclude that the key to the RandHet-SNN’s enhanced adversarial robustness lies in the uncertainty introduced by the random sampling of time constants.
Computational efficiency analysis
RandHet-SNN requires independent sampling of the time constants for all neurons in the network, which consumes more computational resources compared to a regular SNN. For a network with neurons and a time step of , a single forward pass of RandHet-SNN requires samples and additional memory to store the time constants for neurons. We analyze the extra time and memory consumption of RandHet-SNN during training and testing on the CIFAR-10 dataset, as shown in Table 8. In the Table 8, for the training phase, “Time” refers to the average time required to train one epoch, while for the testing phase, “Time” refers to the time required to complete testing on the test set. “Memory” indicates the memory usage during training or testing. All experiments are conducted on NVIDIA A100-PCIE-40GB GPU.Table 8. The additional time cost and memory usage required by RandHet-SNN compared to SNN during training and testingSNNRandHet-SNNAdditional consumptionTimeTrain464.12s501.18s7.99%Test12.0s15.0s25.0%MemoryTrain17786MB23959MB34.7%Test1719MB2125MB23.6%For the training phase, “Time” refers to the average time required to train one epoch, while for the testing phase, “Time” refers to the time required to complete testing on the test set. “Memory” indicates the memory usage during training or testing.
As shown in the Table 8, the training time increases by 7.99%, while the inference time increases by 25.0% compared to vanilla SNNs. In terms of memory usage, RandHet-SNN requires 34.7% more memory during training, while the memory overhead during inference is only 23.6% higher than that of standard SNNs. Therefore, we conclude that the additional computational overhead of the RandHet-SNN in practical applications remains within an acceptable range. RandHet-SNN achieves a relatively balanced trade-off between robustness and computational overhead.
The additional computation introduced by RandHet-SNN is limited to independently sampling the time constants for each neuron and does not involve any additional matrix multiplication operations. Therefore, it does not disrupt the original multiplication-free nature of SNNs and can be applied to neuromorphic hardware just like SNNs.
Additionally, we analyzed the sensitivity of the performance of RandHet-SNN and its computational overhead to the network time step. As shown in the Table 9, while the clean accuracy of RandHet-SNN decreases with shorter time steps, its adversarial robustness improves correspondingly. Overall, reducing the time step has a minor impact on RandHet-SNN’s performance but effectively lowers the computational cost during inference. Therefore, RandHet-SNN’s computational overhead can be optimized by appropriately decreasing the time step.Table 9. Comparison of CIFAR-10 performance and computational cost across different time stepAttackClean MRATimeMemoryT = 488.7440.3340.1340.1310.0s1570MBT = 689.2239.4038.7538.7513.0s1852MBT = 890.1640.4038.6838.6815.0s2125MB
Discussion
This work presents the RandHet-SNN, an approach that leverages stochastic variability in neuron time constants to enhance the adversarial robustness of SNNs. By introducing randomized time constants within LIF neurons, RandHet-SNN effectively emulates the intrinsic stochasticity and heterogeneity found in biological neural systems, resulting in notable improvements in both clean and robust accuracy under various adversarial settings. Extensive evaluations on CIFAR-10 and CIFAR-100 demonstrate that RandHet-SNN consistently outperforms vanilla SNNs, particularly under advanced adversarial attacks such as APGD and AutoAttack. The model’s low sensitivity to changes in variance further validates its stability across hyperparameter variations, emphasizing its resilience and adaptability.
RandHet-SNN also transforms white-box attacks into black-box scenarios, significantly reducing vulnerability to gradient-based attacks. RandHet-SNN demonstrates a marked increase in robust accuracy in conjunction with different adversarial training techniques, underscoring its effectiveness in adversarial defense. These findings suggest that RandHet-SNN holds significant potential for deployment in safety-critical applications, where robustness against adversarial threats is essential. Future work could explore applying similar stochastic mechanisms to other neural architectures and investigating optimal configurations of time constant distributions to further strengthen robustness.
To reveal the potential vulnerabilities of RandHet-SNN, we analyzed adversarial examples that successfully bypassed its defense mechanism. Our findings indicate that these adversarial samples exhibit strong transferability across models with different time constant distributions. Consequently, the randomized time constant mechanism fails to provide effective protection against such examples. To further enhance the adversarial robustness of RandHet-SNN, future work could integrate ensemble-based adversarial defense strategies36 to mitigate cross-model transferability of adversarial examples.
Limitations of the study
In this study, the variance is set as a fixed hyperparameter, and it remains the same across all layers in the experiments without varying degrees of randomness assigned to different layers within the network. Although experimental results indicate that RandHet-SNN is relatively insensitive to this hyperparameter, this approach prevents the variance from adapting according to the network structure or depth, limiting RandHet-SNN’s ability to achieve optimal performance across a broader range of network architectures.
We attempted to set as a trainable parameter for each layer, optimizing it via the backpropagation algorithm. However, we find that variance optimization based on the backpropagation algorithm causes the variance in each layer to approach 0, which significantly reduces the model’s randomness and weakens the adversarial robustness of RandHet-SNN. This issue is also mentioned in the work of Ma et al.,10 who pointed out that backpropagation tends to drive the learnable variance toward 0, making it unsuitable for adaptively learning the appropriate random variance. One possible solution is to constrain the upper and lower bounds of the variance in the optimization process. Future work could derive these bounds through appropriate approximations and assumptions, and design reinforcement learning or evolutionary strategies to optimize the variance.
Resource availability
Lead contact
Requests for further information and resources should be directed to and will be fulfilled by the lead contact, Yi Zeng ([email protected]).
Materials availability
This study did not generate new unique reagents.
Data and code availability
- •This paper analyzes existing, publicly available data. These accession numbers for the datasets are listed in the key resources table.
- •Code are available at https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Snn_safety/RandHet-SNN.
- •Any additional information required to reanalyze the data reported in this paper is available from the lead contact upon request.
Acknowledgments
This study was supported by the 10.13039/501100001809National Natural Science Foundation of China (grant no. 62406325), Beijing Natural Science Foundation (grant no.4252052).
Author contributions
J.W. and D.Z. designed the study under the supervision of Y.Z. and Q.Z. J.H. implemented the models, performed the experiments and created the figures. J.H. and D.Z. wrote the manuscript and analyzed the data. X.H. and C.D. helped set up the experimental environment. Y.Z. was the project administration and funded the project.
Declaration of interests
The authors declare no competing interests.
STAR★Methods
Key resources table
REAGENT or RESOURCESOURCEIDENTIFIERSoftware and algorithmsRegularized Adversarial Training(RAT)(Ding et al.16)Githubhttps://github.com/putshua/SNN-RATSparsity Regularization(SR)(Liu et al.20)Githubhttps://github.com/putshua/gradient_reg_defenseAdversarial attacksGithubhttps://github.com/Harry24k/adversarial-attacks-pytorchRandom Heterogeneous Spiking Neural Network(RandHet-SNN)This paperhttps://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Snn_safety/RandHet-SNNOtherCIFAR-10 and CIFAR-100Krizhevsky et al.28https://www.cs.toronto.edu/∼kriz/cifar.htmlTinyImagenetDeng et al.34https://www.image-net.org/
Method details
Adversarial perturbations
Adversarial perturbations are specifically crafted modifications to input data, designed to maximize a neural network’s misclassification rate while staying within a predefined perturbation bound. Given a model , a loss function , an input , and a corresponding label , adversarial perturbations can be obtained by solving the optimization problem in Equation 1:
In white-box attack scenarios, where the attacker has full access to the network’s parameters and gradients, this optimization problem can be solved to generate an adversarial example . A common approach is the Fast Gradient Sign Method (FGSM), which uses the sign of the network’s gradient to compute a single-step perturbation, optimizing as follows37:
The Projected Gradient Descent (PGD) method extends FGSM by performing multiple iterative steps to generate stronger perturbations, making it an effective first-order optimization method for solving Equation 138:
Here, denotes the iteration step, and the projection operator ensures that each adversarial example remains within the -neighborhood around .
For SNNs, adversarial attacks use the surrogate gradient method to approximate gradients of the spiking activation function. Using Backpropagation Through Time (BPTT), attackers can compute the gradients needed to create adversarial perturbations in SNNs.16^,^39
Spiking neuron model
SNNs commonly employ the LIF model as a nonlinear activation function due to its closer alignment with biological neuron dynamics, which we also adopt in this study. The behavior of the LIF model is governed by the Equation 4:
where and represent the membrane potential and spike firing state of neurons in the -th layer at time , respectively. denotes the weight matrix in the -th layer, and is the spike threshold for neuronal firing. is the Heaviside function, indicating that neurons fire (i.e., output an activation value of 1) when their membrane potential exceeds the threshold. The parameter is the membrane time constant.
Random heterogeneous LIF model
In RandHet-SNN, each neuron within every network layer is assigned an independent random variable as its time constant. The membrane potential dynamics of LIF neurons with randomized time constants are described in the Equation 5:
In this equation, and represent the membrane potential and spike firing state of neurons in the -th layer at time , respectively. denotes the weight matrix in the -th layer, and is the spike threshold for neuronal firing. is the Heaviside function, indicating that neurons fire (i.e., output an activation value of 1) when their membrane potential exceeds the threshold. represents the vector of time constant in -th layer, means the time constant of the -th neruon and is the the total number of spiking neurons in the -th layer.
RandHet-SNN independently sampling the time constants at each time step as shown in Equation 6, while RandHet- samples the time constants at the beginning of each forward pass, maintaining them as constant for all subsequent time steps as shown in Equation 7:
where represents the sigmoid function, constraining the value of between 0 and 1. The variable (or ) is a Gaussian random variable, with denoting its variance.
Defensive mechanisms
During the construction of adversarial attacks, RandHet-SNN samples random variables to generate a specific set of network parameters, represented by model . The attacker uses the gradients of to create adversarial examples. However, when these adversarial examples are input into RandHet-SNN, the random variables are resampled, resulting in a new network instantiation, denoted as model . Consequently, the adversarial perturbations crafted based on may not remain effective against .
Let denote the data distribution of , and let represent the adversarial perturbations for models :
The transferability of adversarial example between source model and target model can be defined as follows:
The above definition indicates that when both models and correctly classify clean samples but the adversarial samples successfully mislead both, the adversarial examples are considered successfully transferred.
Previous work has established an upper bound for this transferability,36 which we restate as Theorem 1. Theorem 1 Assume both model and are -smooth and their gradient magnitudes are bounded by . The adversarial perturbation . When is small enough, there is , then the transferability can be upper bounded by
where , and are the empirical risks of model and . is the upper loss gradient cosine similarity between model and .
Theorem 1 suggests that gradient cosine similarity is a key factor in limiting transferability. Lower cosine similarity implies poorer transferability of the attack, indicating a stronger defensive capability of the stochastic mechanism. We provide a detailed analysis of the gradient cosine similarity of RandHet-SNN with different random variances, as well as their influence on model performance in section gradient cosine similarity analysis.
Gradients approximation
To compute network gradients using BPTT, we employ a surrogate gradient method to approximate the gradients of the spiking activation function, as defined in Equation 11:
Here, is a hyperparameter that modulates the shape of the function. For the purposes of this study, we set .
Black-box adversarial training
To train RandHet-SNN, we employ black-box attacks for adversarial training, a technique that promotes improved convergence of the network while mitigating the loss in clean accuracy8:
In this formulation, and represent model instances obtained from two separate samplings of the time constants, while denotes the other trainable parameters within the network. Black-box adversarial training is achieved by resampling the model’s random variables after generating adversarial training samples, thus enhancing robustness through stochastic parameter variations.
Quantification and statistical analysis
Distribution histogram
We visualized the distributions of both time constants and cosine similarity using Python’s histogram plotting methods. The specific definition of the data are detailed in the legends of Figure 2 (time constants) and Figure 5 (cosine similarity).
Cosine similarity of gradient and adversarial perturbation
Figures 5A and 5B presents histograms of gradient cosine similarity values computed across all test samples. Specifically, we: (1) Fed each input sample through RandHet-SNN twice, (2) Computed the gradients for both forward passes, (3) Measured the cosine similarity between each gradient pair.
Figures 5C and 5D displays histograms of cosine similarity values between PGD adversarial perturbations across all test samples. Specifically, we: (1) Fed each input sample through RandHet-SNN twice, (2) Computed the adversarial perturbations for both forward passes by PGD, (3) Measured the cosine similarity between each adversarial perturbations.
The cosine similarity between two vectors and is calculated as:
Average gradient cosine similarity
In Table 6, Average gradient cosine similarity(AGCS) represents the mean cosine similarity of gradients across all test samples.
Robust accuracy
Robust accuracy measures the model’s classification accuracy on adversarial examples generated by applying adversarial attack(e.g., PGD) to the test set. All accuracy values reported in tables are expressed in percentage units (%).
Minimum robust accuracy
Minimum robust accuracy(MRA) quantifies a model’s worst-case performance by reporting the lowest robust accuracy observed across multiple adversarial attack strategies.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1He K.Zhang X.Ren S.Sun J.Deep residual learning for image recognition Proceedings of the IEEE conference on computer vision and pattern recognition 2016770778
- 2Dosovitskiy A.Beyer L.Kolesnikov A.Weissenborn D.Zhai X.Unterthiner T.Dehghani M.Minderer M.Heigold G.Gelly S.An image is worth 16x 16 words: Transformers for image recognition at scale International Conference on Learning Representations 2021 https://openreview.net/forum?id=Yicb Fd NT Ty
- 3Szegedy C.Zaremba W.Sutskever I.Bruna J.Erhan D.Goodfellow I.Fergus R.Intriguing properties of neural networks International Conference on Learning Representations 2014 https://openreview.net/forum?id=kklr_MTHMR Qj G
- 4Moosavi-Dezfooli S.M.Fawzi A.Frossard P.Deepfool: a simple and accurate method to fool deep neural networks Proceedings of the IEEE conference on computer vision and pattern recognition 201625742582
- 5Eykholt K.Evtimov I.Fernandes E.Li B.Rahmati A.Xiao C.Prakash A.Kohno T.Song D.Robust physical-world attacks on deep learning visual classification Proceedings of the IEEE conference on computer vision and pattern recognition 201816251634
- 6Xie C.Wang J.Zhang Z.Ren Z.Yuille A.Mitigating adversarial effects through randomization International Conference on Learning Representations 2018 https://openreview.net/forum?id=Sk 9yuql 0Z
- 7Fu Y.Yu Q.Li M.Chandra V.Lin Y.Double-win quant: Aggressively winning robustness of quantized deep neural networks via random precision training and inference International Conference on Machine Learning 2021 PMLR 34923504
- 8Dong M.Chen X.Wang Y.Xu C.Random normalization aggregation for adversarial defense Adv. Neural Inf. Process. Syst.3520223367633688