An Integrated Spatial-Spectral Denoising Framework for Robust Electrically Evoked Compound Action Potential Enhancement and Auditory Parameter Estimation
Fan-Jie Kung

TL;DR
This paper introduces a new two-stage denoising method to improve ECAP signal quality and auditory parameter estimation in noisy conditions.
Contribution
A novel integrated spatial-spectral denoising framework called PECAP-TSPD is proposed for ECAP enhancement.
Findings
PECAP-TSPD achieved the lowest average RMSE for ECAP magnitudes and neural patterns under impulse noise.
The method outperformed CNN-based and median filtering approaches in correlation and structural similarity metrics.
Results were validated using simulated and experimental noise models.
Abstract
The electrically evoked compound action potential (ECAP) is a crucial physiological signal used by clinicians to evaluate auditory nerve functionality. Clean ECAP recordings help to accurately estimate auditory neural activity patterns and ECAP magnitudes, particularly through the panoramic ECAP (PECAP) framework. However, noise—especially in low-signal-to-noise ratio (SNR) conditions—can lead to significant errors in parameter estimation. This study proposes a two-stage preprocessing denoising (TSPD) algorithm to address this issue and enhance ECAP signals. First, an ECAP matrix is constructed using the forward-masking technique, representing the signal as a two-dimensional image. This matrix undergoes spatial noise reduction via an improved spatial median (I-Median) filter. In the second stage, the denoised matrix is vectorized and further processed using a log-spectral amplitude…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
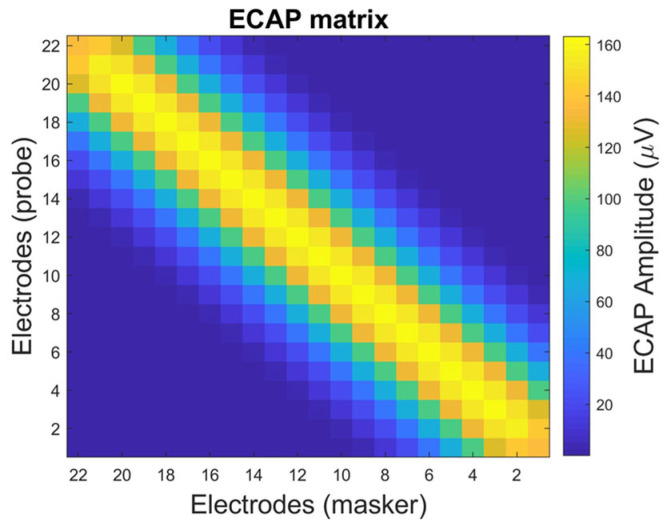 Figure 1
Figure 1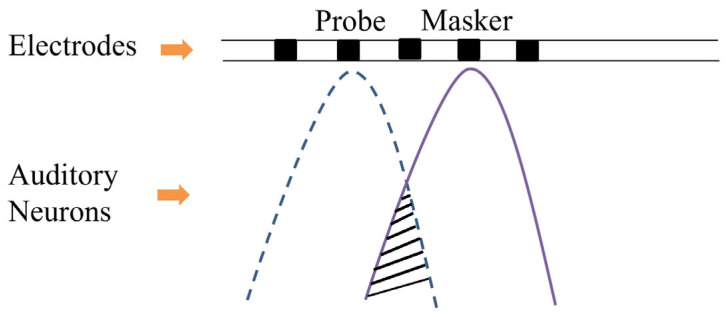 Figure 2
Figure 2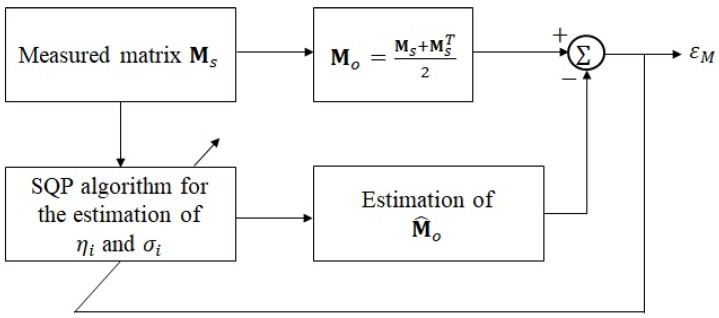 Figure 3
Figure 3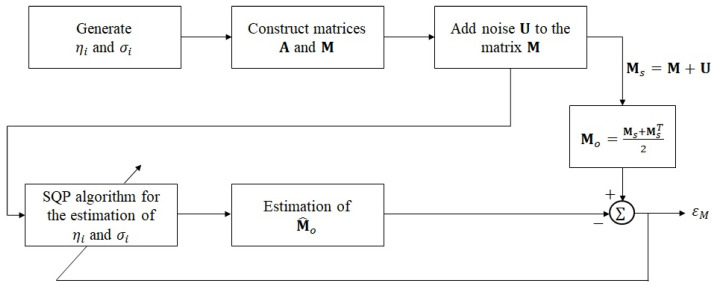 Figure 4
Figure 4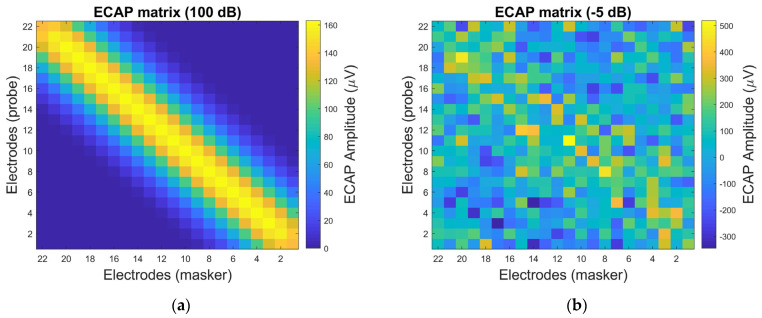 Figure 5
Figure 5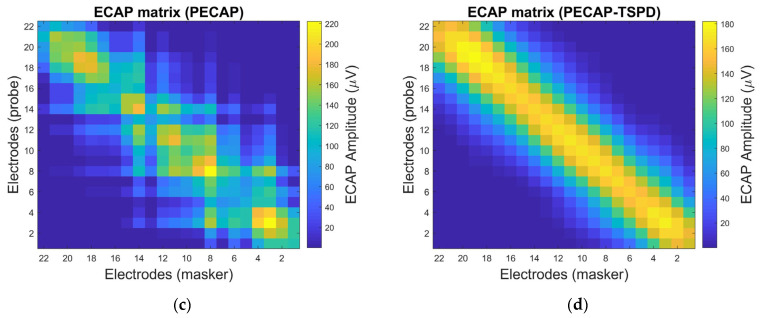 Figure 6
Figure 6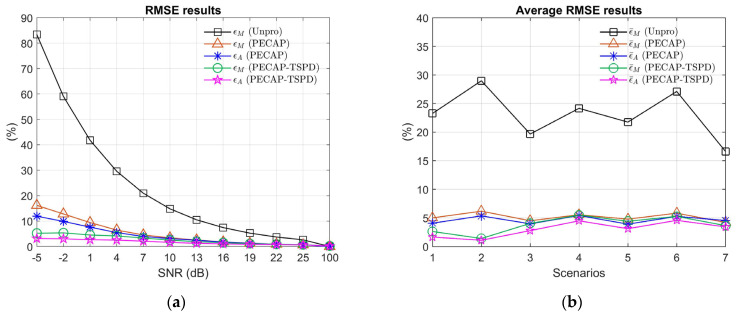 Figure 7
Figure 7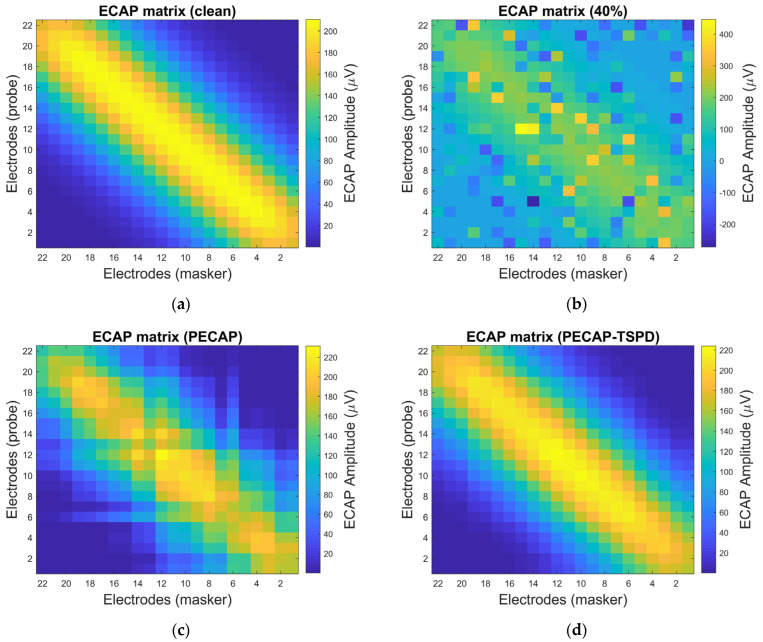 Figure 8
Figure 8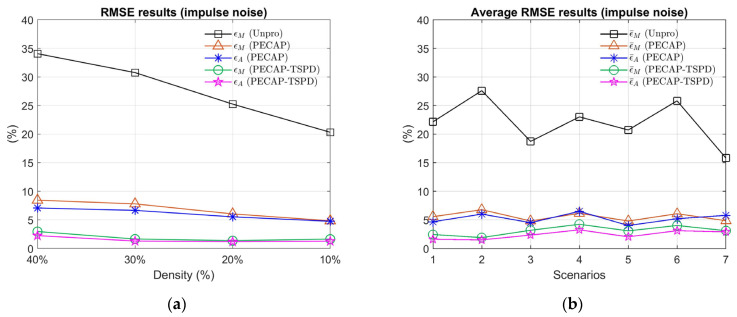 Figure 9
Figure 9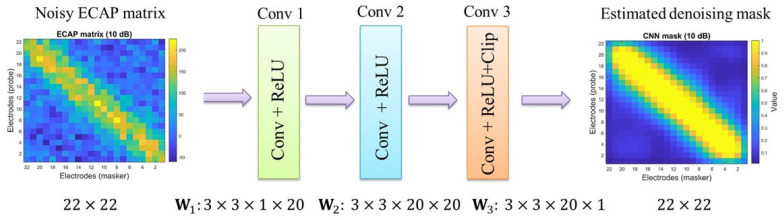 Figure 10
Figure 10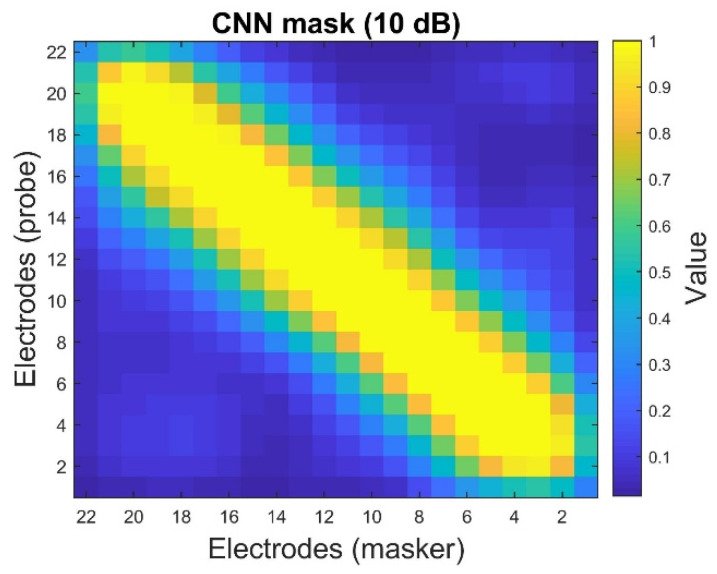 Figure 11
Figure 11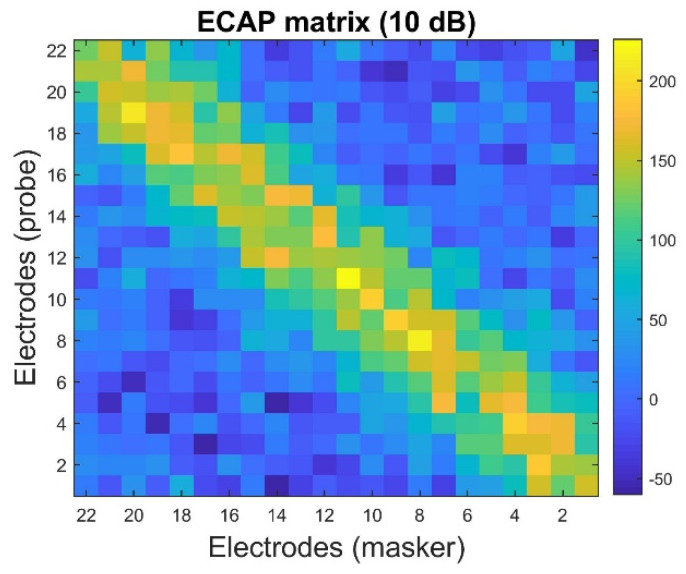 Figure 12
Figure 12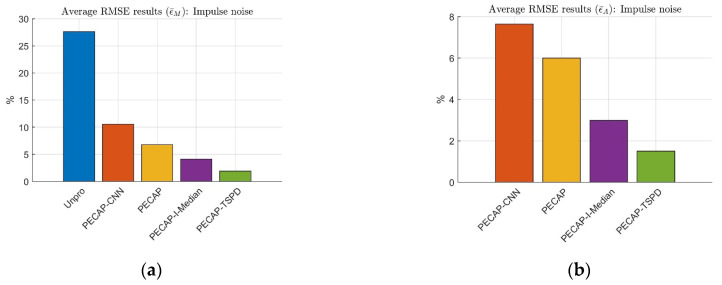 Figure 13
Figure 13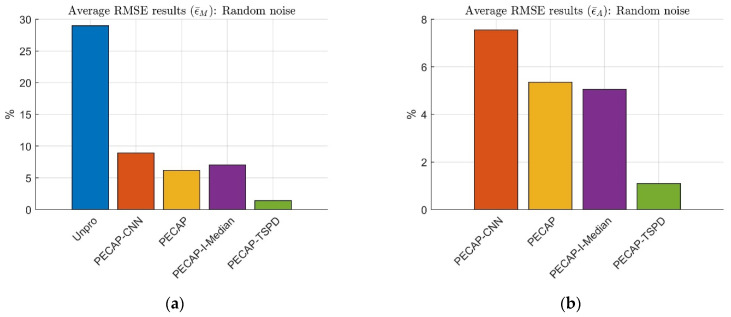 Figure 14
Figure 14 Figure 15
Figure 15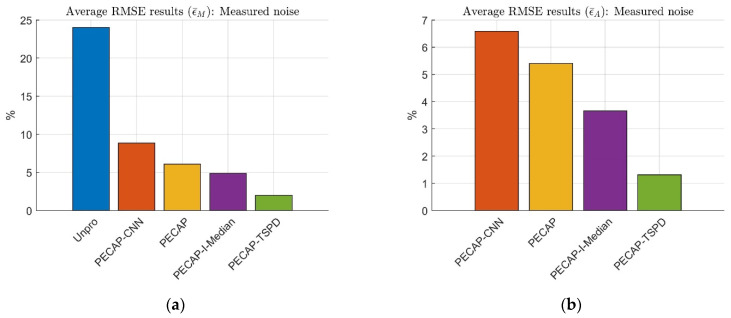 Figure 16
Figure 16- —National Science and Technology Council (NSTC) of Taiwan
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBlind Source Separation Techniques · Neural dynamics and brain function · Speech and Audio Processing
1. Introduction
The electrically evoked compound action potential (ECAP) is the combined response of auditory nerve fibers to electrical stimulation by a cochlear implant (CI) [1,2]. The ECAP is a critical signal for clinicians to evaluate the functionality of a patient’s auditory nerve fibers after CI surgery [3,4]. In the absence of feedback from CI users, the ECAP model can be of great value to clinicians in terms of assessing the hearing performance of CI users [5,6]. ECAP magnitude can be computerized and estimated using temporal or spatial methods [7,8,9]. The ECAP matrix can be constructed by measuring the ECAPs generated by the different electrode positions of the masker and probe stimuli. Such a method is referred to as the forward-masking technique [10]. Regarding the panoramic ECAP (PECAP) method [11,12], it has been shown that using a clean ECAP matrix can approximate auditory activity patterns and ECAP magnitudes [11,12], further assisting clinicians in evaluating a patient’s speech perception. Nevertheless, noisy ECAP matrices—particularly when the signal-to-noise ratio (SNR) is less than 10 dB—can introduce inaccuracies in estimating auditory activity patterns and ECAP magnitudes [11,12].
The abovementioned issue necessitates the implementation of noise reduction techniques on ECAP matrices before estimating the auditory activity patterns and ECAP magnitudes. These techniques can be classified into three primary categories: spatial filtering, temporal filtering, and spectral filtering. In spatial filtering, the mean and median filters represent well-established examples of spatial filtering [13,14,15]. The mean filter is a linear estimator employed to mitigate the adverse effects of image noise by eliminating random fluctuations. The principal disadvantage of the mean filter is that it results in image blurring, particularly at low SNRs. The median filter, which demonstrates superior noise removal performance compared to the mean filter, is a nonlinear estimator [16]. The median filter’s masking size tends to increase with elevated noise levels, which can result in the loss of information from the original images. To alleviate image distortion and achieve moderate noise reduction, an improved median filtering algorithm (I-Median) [17] has been developed, combining the advantages of mean and median filters to achieve superior denoising in adverse environments. Specifically, if the current pixel value is less than the average of the mask, the pixel value is replaced with the median of the mask. Otherwise, the pixel value keeps its original value [17].
In the field of time-domain signal analysis, adaptive filtering (AF) can be used to minimize noise. The AF method primarily uses algorithms such as least mean square (LMS) [18] and recursive least squares (RLS) [19] to iteratively adjust the weights, thereby reducing the adverse effects of noise on the signal. The advantage of AF methods is their near real-time implementation [20]. However, a critical aspect of these methods lies in the reference signal source, as clean signals—such as speech—are almost nonexistent in specific real-world scenarios. In addition, the choice of step size and filter order directly affects the error convergence rate, which is an important issue to address [21]. Finding the right balance is essential for noise reduction when AF is used.
Wiener filtering is an effective noise reduction technique in spectral domain signal analysis [22,23]. It estimates the noise’s power spectral density (PSD) to enhance the signal. However, at low SNRs, the accuracy of the estimated noise PSD may decline, directly impacting the noise reduction performance. To address this issue, a Wiener-based noise reduction algorithm known as log-spectral amplitude (LSA) Wiener filtering [24,25,26] has been developed to minimize the mean square error of the logarithmic spectrum. This approach helps to alleviate musical noise and improve the quality of speech signals under low-SNR conditions.
Deep learning techniques have recently been applied in the context of speech enhancement [27,28,29,30]. One such technique is the end-to-end convolutional recurrent neural network (CRN) [31], which enables near real-time implementation using a single microphone. This CRN algorithm can suppress noise under adverse conditions, such as a −5 dB SNR. However, the main drawback of these learning-based approaches is the substantial amount of data acquisition and preprocessing required [27,28,32], which can be both time- and resource-intensive. Because deep learning techniques are based on nonlinear approaches, the resulting distortion may be greater than that of the aforementioned linear approaches. Additionally, the noise reduction performance may degrade when encountering unseen scenarios.
Given the compromised estimation of auditory neural activity patterns and ECAP magnitudes when using PECAP under low-SNR conditions, this work proposes a method that combines PECAP with a two-stage preprocessing denoising algorithm (TSPD), referred to as PECAP-TSPD. Specifically, the ECAP signals are first denoised via TSPD and then used to estimate the neural parameters via PECAP. In the first stage of TSPD, the I-Median algorithm is used to reduce the random noise of an ECAP matrix, since the ECAP matrix can be considered an image. In the second step of TSPD, the denoised ECAP matrix is expanded and rearranged as a vector, where is the total number of electrodes. The rearranged vector can then be used as the input of the one-dimensional signal to LSA Wiener filtering for residual noise reduction. The PECAP-TSPD algorithm improves the accuracy of the estimates for key parameters, such as neural health and current spread. Simulated and measured noise are mixed into clean ECAP matrices to emulate the real ECAPs. This method can potentially assist in neural diagnosis, which warrants further validation using clinical ECAP data in future studies. The normalized root mean square error (RMSE), two-dimensional correlation coefficient (TDCC) [33], and structural similarity index (SSIM) [34,35] are employed as objective measures in this work to evaluate the performance of the unprocessed ECAP, processed ECAP signals by PECAP, PECAP with convolutional neural network (CNN)-based denoising mask (PECAP-CNN), PECAP with I-Median filtering (PECAP-I-Median), and PECAP-TSPD under various SNR conditions, noise densities, and scenarios.
The main contributions and insights of this study are as follows:
- This study proposes a novel two-stage framework that combines spatial and spectral filtering for noise reduction in ECAP matrix signals.
- A reordering technique is introduced to estimate the noise in the ECAP matrix, based on the physiological ECAP measurements obtained using the forward-masking technique [10].
- A three-convolutional-layer neural network is proposed for denoising mask estimation. This network serves as one of the baselines, and is used to validate the noise estimation effect achieved by the proposed reordering technique.
- The reordering ECAP vector is treated as a speech-like signal and further denoised in the second stage using LSA Wiener filtering.
The remainder of this article is organized as follows. Section 2 introduces the panoramic ECAP method. Section 3 describes the proposed method. Section 4 explains the settings and results. Section 5 concludes the study and outlines future work.
2. Panoramic ECAP Method
The panoramic ECAP (PECAP) method consists of two procedures: the forward-masking method and neural parameter estimation using sequential quadratic programming (SQP) [10,11,12]. The forward-masking method uses a probe and a masker to stimulate auditory neurons, generating the ECAP signal and reducing artifacts. This process constructs a matrix in which each element represents the measured ECAP signal from each pair of probe and masker positions, as illustrated in Figure 1. In Figure 1, the x-axis represents the position of the masker, and the y-axis represents the probe’s position. Figure 1 shows the simulated ECAP signal, illustrating the inverse relationship between the amplitude of the ECAP and the distance from the probe to the masker. When the positions of the probe and the masker are closer, the amplitude of the ECAP signal is larger. Conversely, when the probe and masker are farther apart, the amplitude of the ECAP signal is smaller. This phenomenon is explained in Figure 2 [6], where the neural activity pattern is assumed to follow a Gaussian distribution. The ECAP signal can be regarded as the overlapping area between two Gaussian distributions, corresponding to the neural activity patterns stimulated by the probe and masker. The overlap is maximized when the probe and the masker positions coincide. In contrast, the overlap is minimal when the probe and the masker positions are distant.
The auditory neural activity pattern is assumed to be a Gaussian distribution, defined as follows:
where denotes the -th electrode; is the position along the cochlea; and are the auditory neuron amplitude and neural health of the -th electrode, respectively; is an exponential function; and represent the mean and standard deviation (also referred to as current spread [10] in physiological signals) of the Gaussian pattern for the -th electrode, respectively. In this work, and is prior information. Under the assumption that the ECAP signal is the overlap between the two auditory neuron responses of the probe and masker stimuli, the ECAP signal can be formulated as
where is the index indicating that the -th electrode is stimulated by the probe, is the index indicating that the -th electrode is stimulated by the masker, and is set to (the total number of electrodes) in this work. Equation (2) can also be expressed in matrix form as a clean ECAP matrix [12]:
in which is an auditory neural activity pattern matrix for each auditory neuron vector . Because is a symmetric matrix, the matrix of the ECAP signal in Equation (3) is also a symmetric matrix. The measured ECAP matrix can be represented as
where denotes a matrix that contains noise.
The random noise part can be alleviated using the following equation:
where represents the denoised matrix of the ECAP signal. To further estimate and , the SQP, a large-scale constrained optimization algorithm, is utilized. Computerization of the parameter estimation of the ECAP matrix is illustrated in Figure 3.
In Figure 3, , which denotes the root mean square error between and estimated denoised ECAP matrix , is formulated as
where and represent the -th entry of and , respectively. In this work, different SNR and density conditions are also introduced to assess the parameter estimation capability using SQP.
Figure 4 depicts a structure designed to test the noise resistance performance using the SQP algorithm. The above procedures can eliminate most of the noise. However, in low-SNR scenarios, the distortion increases due to the error estimation of and . Therefore, the preprocessing algorithm is developed below.
3. Proposed Method
The proposed method involves two stages for noise reduction. The first stage of the denoising process is described below.
3.1. First Stage of Noise Reduction Processing
In light of the detrimental effect of noise on the estimation of neural parameters, this work proposes a two-stage preprocessing denoising (TSPD) algorithm for the ECAP matrix before the PECAP algorithm. First, the ECAP matrix is treated as an image. In the first stage of TSPD, the improved median (I-Median) filtering algorithm is applied to reduce noise, as shown in Equation (7).
where and denote the processed values using the median and mean filters at positions , respectively. denotes the processed result obtained using I-Median filtering. This work sets the kernel sizes of median and mean filtering to . Equation (7) describes that if the ECAP value at positions is less than the mean filter processing value, the ECAP value is considered noise and can be replaced by the median filter processing value. Conversely, if the ECAP value is greater, it is retained. The processed ECAP matrix is expressed as
The I-Median algorithm is suitable for removing low-to-medium-density noise from an image. In some cases, however, the noise is distributed across all pixels of an image. To further deal with this noise, LSA Wiener filtering is employed after I-median filtering by expanding into a vector. The following reordering procedure is important because LAS Wiener filtering uses the first few time frames as the noise component to estimate the initial noise PSD to reduce noise recursively. Therefore, selecting which elements of the ECAP matrix have high probabilities of being noise is a critical step. The following reordering rule not only expands into a vector, but also selects which elements of are most likely noise based on the physiological characteristic of the ECAP matrix, as described in Section 2. The reordering rule for transforming the ECAP matrix into the ECAP vector is as follows:
- Calculate the absolute value of index minus index
where is an index matrix that records the absolute value of the position difference between and 2. Record for each element in and concatenate each row into a long vector.
where is the -th entry of . 3. Order in descending order and record the descending order index.
where represents the descending order operation, is a vector based on the descending order of the results of , and is the index vector corresponding to . 4. The desired vector can then be obtained using the following equation:
where is a row vector containing both noise components and noisy ECAP signal components. The noise, where the ECAP signal is weak, is placed in the first part of the vector, while the target signal, where the ECAP signal is stronger, is placed in the last part of the vector. The reordering process is part of the second stage of TSPD, which employs LSA Wiener filtering for improved noise reduction, as stated below.
3.2. Second Stage of Noise Reduction Processing
In the second stage of TSPD, LSA Wiener filtering is utilized to address the residual noise in the vector , which is treated as a discrete-time series input. The first step is to transform into a short-time Fourier transform (STFT) domain, as shown in Equation (13).
where denotes the fast Fourier transform (FFT) operator. is the STFT signal of . and denote the time frame and frequency indices, respectively. is the hop size. is the window of length for short-time signal analysis. The signal segment is zero-padded to a length of to ensure adequate frequency resolution without aliasing. The LSA Wiener filter aims at minimizing the log-spectral amplitude
where is the cost function to minimize the mean square error of log-spectral amplitudes and . and are the clean signal and estimated clean signal spectra, respectively. The optimal solution is [24,25,26]
where is the prior SNR with being a clean signal PSD and being a residual noise PSD. with representing the posterior SNR. can be estimated using the decision-directed approach as described below:
where is a forgetting factor. can be estimated and updated using the following log-likelihood ratio criterion:
where
is the conditional probability density function (PDF) of given that the event ( ) of the ECAP signal occurs.
is the conditional PDF of assuming only noise occurs at event . . If is less than a small value , the noise PSD can be updated using the following recursive averaging.
The estimated clean ECAP signal can be obtained using the following equation:
The complete LAS Wiener filtering procedures used in the second noise reduction stage are listed in Table 1.
In Table 1, is the number of time frames used to estimate the initial noise PSD. Next, the processed row vector is converted into the inverse STFT, the time domain signal , which can be reconstructed into the matrix format, as described below:
where is defined in Equation (11), with being a range from to In this work, the mean filter is applied in if the SNR value is below 4 dB, to leverage the advantage of random noise removal at low SNRs [15]. The simulation arrangement, experimental settings, and results are provided in Section 4.
4. Settings and Results
The simulation arrangement and results are described below.
4.1. Simulation Arrangement and Results
Two types of noise—random noise and impulse noise—are used to evaluate the performance of the proposed PECAP-TSPD algorithm. Twelve SNR levels (−5 dB, −2 dB, 1 dB, 4 dB, 7 dB, 10 dB, 13 dB, 16 dB, 19 dB, 22 dB, 25 dB, and 100 dB—representing the clean ECAP signal situation for the random noise case) are used in the random noise. Four densities—10%, 20%, 30%, and 40%—are used in the impulse noise. The normalized RMSE is used as an objective quality measure to calculate the error between the ground truth and the estimated results (auditory neural activity pattern and ECAP amplitude). The two-dimensional correlation coefficient (TDCC) [33] and structural similarity index (SSIM) [34,35] are used to evaluate the similarity between the clean ECAP matrix and the reconstructed ECAP matrix. The STFT parameter settings in this work are as follows: A rectangular window with a length of 22 is used. The FFT size is 44. No overlap for each segment ( ). In Table 1, , , and . Seven different combinations of neural health and current spread are listed in Table 2. The results of the ECAP matrices before and after processing at −5 dB of SNR are shown in Figure 5. The simulation software used in this study is MATLAB 2018b.
In Figure 5b, the ECAP matrix is filled with random noise, making it challenging to observe the pristine measured ECAP data, as depicted in Figure 5a. The PECAP and PECAP-TSPD methods can mitigate the detrimental effects of boisterous environments to recover the clean ECAP matrix shown in Figure 5c,d. The TDCC results for the noisy ECAP matrix, the PECAP matrix using PECAP, and the PECAP matrix using PECAP-TSPD are 0.4049, 0.8950, and 0.9960, respectively. Meanwhile, the SSIM results for these matrices are 0.0723 for the noisy ECAP matrix, 0.6526 for the processed PECAP matrix using PECAP, and 0.9681 for the processed PECAP matrix using PECAP-TSPD. The results of TDCC and SSIM are greater than 0.96, further indicating the satisfactory performance of PECAP-TSPD under adverse noisy conditions.
The results of the normalized RMSE of the ECAP magnitude ( ) and auditory neural activity pattern ( ) are depicted in Figure 6.
where is the maximum absolute value of . is computed as
where is the maximum absolute value of . and denote the -th entry of and , respectively. is the estimated auditory neural activity pattern. Figure 6a shows the normalized RMSE of the unprocessed ECAP signals, ECAP signals processed by PECAP, and PECAP-TSPD algorithms for different SNRs in Scenario 1. The normalized RMSE of the magnitude of the unprocessed ECAP signals at −5 dB SNR increases to 83.39%, which is comparably higher than those of the processed ECAP signals by PECAP (16.17%) and PECAP-TSPD (5.23%), indicating the need for ECAP signal processing. When comparing the between PECAP and PECAP-TSPD processing ECAP signals, the values of by PECAP-TSPD are all smaller than those by PECAP, except the 100 dB SNR case, where are 0.0043% and 0.1885% for PECAP and PECAP-TSPD, respectively. The RMSE results of for PECAP and PECAP-TSPD under 16, 19, 22, and 25 SNRs are shown in Table 3. Table 3 shows that the PECAP-TSPD algorithm decreases the RMSE when the SNR values are below 25 dB. The difference in RMSE remains approximately the same when the SNR is increased to 22 dB. The above results indicate that it is unnecessary to use TSPD before PECAP when the SNR is 25 dB or higher. Figure 6b shows the curve of the average normalized RMSE, denoted as and for the ECAP magnitude and auditory neural activity, respectively. Compared to the unprocessed and processed ECAP signals, the maximum values of average normalized RMSE are 6.17% and 5.48% for PECAP and PECAP-TSPD, respectively. In contrast, the maximum value of the unprocessed ECAP signals is 28.97%, showing the noise resistance capabilities of the PECAP and PECAP-TSPD algorithms. The performance of the PECAP-TSPD algorithm is superior to that of the PECAP algorithm, as the values of and obtained with PECAP-TSPD are lower than those obtained with PECAP. The average of from Scenarios 1 to 7 can be ranked as PECAP-TSPD (3.83%), PECAP (5.14%), and unprocessed (23.07%). The averages of from Scenarios 1 to 7 for PECAP-TSPD and PECAP are 3.01% and 4.64%, respectively.
Next, the impulse noise is added to the EACP matrix to evaluate the performance of PECAP-TSPD under four different densities. Figure 7 illustrates the results of the ECAP matrices before and after using the PECAP and PECAP-TSPD algorithms at the 40% density of the impulse noise.
The impulse noise with 40% density heavily contaminates the original ECAP matrix (Figure 7a), as shown in Figure 7b, emphasizing the importance of signal processing. The ECAP matrices processed using the PECAP and PECAP-TSPD algorithms are depicted in Figure 7c,d, where the impulse noise is most reduced. When comparing Figure 7c with Figure 7d, the restored ECAP matrix in Figure 7d shows more resemblance to that in Figure 7a than to that in Figure 7c, indicating the satisfactory performance of PECAP-TSPD under adverse noisy environments.
The normalized RMSE results of the ECAP magnitude and neural activity pattern of the impulse noise case are depicted in Figure 8.
Figure 8a presents the and curves at four distinct densities in Scenario 2 for the unprocessed, PECAP, and PECAP-TSPD approaches, all of which increase as the impulse noise density increases. In the case of 40% impulse noise density, the values for unprocessed, PECAP, and PECAP-TSPD are 34.07%, 8.44%, and 2.96%, respectively, displaying the effectiveness of PECAP and PECAP-TSPD in adverse noisy environments. The average normalized RMSE results are depicted in Figure 8b. The maximum values of for the PECAP and PECAP-TSPD algorithms are 6.77% and 4.22%, respectively. For the unprocessed ECAP matrices, the maximum value of is 27.59%, which suggests that PECAP and PECAP-TSPD are robust against noise. The PECAP-TSPD algorithm performs better than the PECAP algorithm because the values of and calculated by PECAP-TSPD are lower than those estimated by PECAP. The mean values of from Scenarios 1 through 7 can be arranged in ascending order as follows: PECAP-TSPD (3.13%), PECAP (5.57%), and unprocessed (21.97%). The mean values of from Scenarios 1 to 7 for PECAP-TSPD and PECAP are 2.39% and 5.23%, respectively. To validate the proposed reordering technique for noise region estimation of ECAP matrices, a three-convolutional-layer neural network for denoising mask estimation is proposed as follows.
4.2. CNN-Based Denoising Mask Estimation
The schematic of the denoising mask estimation of the CNN-based network is presented in Figure 9.
The schematic of the proposed three-convolutional-layer neural network for the denoising mask estimation is inspired by [31,36]; that is, training the two-dimensional kernels as feature maps, which can match the image property, such as the ECAP matrix in this work. Second, learning a mask between 0 and 1 for the CNN-based structure is easier than training on the clean image. The sizes of the input and output data are . The three training weights are denoted as , , and .
The kernel size is set to . The rectified linear unit (ReLU) is used as the activation function for each convolutional layer. The clip operator is used in the third convolutional layer to ensure the output value is between 0 and 1. The data size for each convolutional layer is stated in Table 4. The loss function is described in the following equation:
where denotes the hyperparameters. denotes the total number of training sample pairs in this work. is the i-th clean ECAP matrix and is the i-th noisy ECAP matrix. is the training denoising mask. is the Hadamard product operator [37]. is the Frobenius norm [38]. The results are shown in Figure 10.
Figure 10 shows that the values of the CNN mask are close to one when the probe and the mask’s positions approach the diagonal term (i.e., the same electrode position). The values of the CNN mask become smaller, even reaching zero, if the probe and the mask’s positions are distant. These indicate that the theoretical assumption above can be validated. The neural health and current spread settings in Figure 10 correspond to Scenario 1 in Table 2. The noisy ECAP matrix at 10 dB SNR under the same neural parameter settings is depicted in Figure 11.
The results of the clean ECAP matrix (Figure 5a) suggest that the CNN-based denoising mask (Figure 10) can approximately estimate the signal and noise components from the noisy ECAP matrix (illustrated in Figure 11). TDCC [33] and SSIM [34,35] are used to evaluate the similarity between the CNN-based denoising mask and the clean ECAP matrix, and compare it to that of the noisy ECAP matrix. TDCC and SSIM can be implemented using the corr2 and ssim functions in MATLAB R2018b. The results are described below.
Table 5 shows that the estimated CNN mask is more similar to the clean ECAP matrix than the noisy ECAP matrix. The TDCC and SSIM results offer an empirical justification for the reordering procedure. The low-SNR components are distributed in the off-diagonal region of the noisy ECAP matrix. The high SNR components are distributed in the diagonal region of the noisy ECAP matrix. The above theoretical assumption and the empirical results explain why this study utilizes the descending order operator to select the maximum value of . Then, the corresponding value of -th position of the noisy ECAP matrix can be regarded as the noise to insert the first position of the reordering ECAP vector for further noise reduction using the LSA Wiener filter. The following section discusses the performance with and without LSA Wiener filtering after I-Median filtering.
4.3. LSA Wiener Filtering Improvements After I-Median Filtering
This work explains the importance of applying LSA Wiener filter processing after I-Median filtering in situations involving impulse noise. The results are shown in Figure 12.
In Figure 12, PECAP-CNN refers to the method that integrates the proposed CNN-based denoising mask with PECAP. The PECAP-I-Median method incorporates I-Median filtering into PECAP. In contrast, PECAP-TSPD combines the two-stage preprocessing denoising (TSPD) algorithm with PECAP. Figure 12a shows that the four preprocessing approaches can reduce the RMSE by 16% compared to the unprocessed ECAP data (Unpro). Although the CNN-based denoising mask can estimate the dominant signal and noise regions of the noisy ECAP matrix, directly multiplying the noisy ECAP matrix with the estimated CNN-based denoising mask produces more distortion than the other three preprocessing approaches. That is because the deep learning technique belongs to the nonlinear-based approach. PECAP-I-Median is slightly superior to PECAP, suggesting the effectiveness of the I-Median filtering under impulse noise conditions. PECAP-TSPD performs better than PECAP-I-Median, which indicates that the benefit of LSA Wiener filtering comes when used after the I-Median filtering. The rank is as follows: PECAP-TSPD (1.905%), PECAP-I-Median (4.141%), PECAP (6.779%), PECAP-CNN (10.550%), and Unpro (27.590%). For the auditory neural activity pattern analysis in Figure 12b, the RMSE results of can be ranked as PECAP-TSPD (1.503%), PECAP-I-Median (2.986%), PECAP (6.002%), and PECAP-CNN (7.638%). In addition, this work evaluated the mentioned preprocessing algorithms using TDCC and SSIM. The results are described in Table 6.
Table 6 shows the same trend as Figure 12; that is, the average TDCC and average SSIM rank performances are PECAP-TSPD, PECAP-I-Median, PECAP, and PECAP-CNN. The above results show that the proposed TSPD-PECAP algorithm performs better than PECAP-I-Median in impulse noise situations. This work evaluated the aforementioned preprocessing approaches under random noise conditions. The results are presented in Figure 13.
Figure 13 shows that PECAP and PECAP-I-Median have almost the same performance. For ECAP matrix magnitude analysis, the average RMSE of for PECAP and PECAP-I-Median are 6.172% and 7.031%, respectively. For auditory neural activity pattern analysis, the average RMSE of for PECAP and PECAP-I-Median are 5.347% and 5.055%, respectively. These results indicate that I-Median filtering has a limitation in dealing with various SNR random noise conditions. It emphasizes the necessity of LSA Wiener filtering. The rank is as follows: PECAP-TSPD (1.400%), PECAP (6.172%), PECAP-I-Median (7.031%), PECAP-CNN (8.910%), and Unpro (28.970%). Similarly, the rank is as follows: PECAP-TSPD (1.091%), PECAP-I-Median (5.055%), PECAP (5.347%), and PECAP-CNN (7.551%). TDCC and SSIM are also used to assess the performance of preprocessing approaches. The results of TDCC and SSIM are listed in Table 7.
The results in Table 7 show a similar trend to Figure 13, in that the rank performance in terms of average TDCC is PECAP-TSPD, PECAP-I-Median, PECAP, and PECAP-CNN. The rank performance in terms of average SSIM is PECAP-TSPD, PECAP, PECAP-I-Median, and PECAP-CNN. The proposed PECAP-TSPD algorithm performs robustly in random noise cases with various SNRs.
The window length affects the sensitivity of this proposed method; a shorter window length results in lower frequency resolution, whereas a longer length can lead to a decline in noise power spectral density (PSD) estimation accuracy. The results of the two-dimensional correlation coefficient (TDCC) [33] and the structural similarity index (SSIM) [34,35] with different window sizes are shown in Table 8.
The neural health and current spread settings in Table 8 align with Scenario 2, as detailed in Table 2. The TDCC and SSIM results for a window length of 22 are slightly better than those obtained with a window length of 11. However, when the window length increases to 44, the SSIM value drops significantly, from 0.9920 to 0.5521. Therefore, the window length is set to 22 in this work.
To emulate the real ECAP measurements, the clean ECAP matrix is mixed with measured noise as provided in the following section.
4.4. Experimental Results
This work utilizes the PreSonus Studio 1824c audio interface and the Earthworks Audio M23 omnidirectional measurement microphone to record noise, emulating a real-world ECAP recording scenario. The experimental equipment is shown in Figure 14.
The clean ECAP matrix is mixed with the measured noise at densities of 10%, 20%, 30%, and 40%. The average RMSE results are shown in Figure 15.
Figure 15a shows that the above preprocessing approaches can reduce RMSE by 15% compared to the unprocessed ECAP data (Unpro). The nonlinear-based denoising mask estimation employed by PECAP-CNN results in larger distortion than the other three preprocessing algorithms. The performance rankings of the experimental results are consistent with those shown in Figure 12. The rankings for are as follows: PECAP-TSPD (2.000%), PECAP-I-Median (4.890%), PECAP (6.113%), PECAP-CNN (8.850%), and Unpro (24.030%). For the neural activity pattern analysis presented in Figure 15b, the RMSE results for can be ranked as PECAP-TSPD (1.311%), PECAP-I-Median (3.657%), PECAP (5.405%), and PECAP-CNN (6.585%). The results of TDCC and SSIM are described in Table 9.
Table 9 shows a similar trend to that in Figure 15, where the average TDCC performance ranking is as follows: PECAP-TSPD, PECAP-Median, PECAP, and PECAP-CNN. The average SSIM rank performance is as follows: PECAP-TSPD, PECAP-I-Median, PECAP-CNN, and PECAP. From Figure 12 and Figure 15 (i.e., the simulated and experimental results), the average RMSEs of ECAP magnitudes and auditory neural activity patterns can be ranked as follows: PECAP-TSPD (1.952%, 1.407%), PECAP-I-Median (4.515%, 3.3215%), PECAP (6.446%, 5.7035%), and PECAP-CNN (9.700%, 7.111%). Similarly, the average TDCC and SSIM from Table 6 and Table 9 can be ranked as follows: PECAP-TSPD (0.9988, 0.9931), PECAP-I-Median (0.9949, 0.9470), PECAP (0.9859, 0.8997), and PECAP-CNN (0.9766, 0.8832). These results show that the proposed TSPD algorithm performs well under random noise conditions (Figure 13 and Table 7) and has robust impulse noise resistance.
5. Conclusions
The PECAP-TSPD algorithm, which integrates an improved spatial median filter, the log-spectral amplitude Wiener filter, and the PECAP framework, was developed to reduce noise in ECAP data and enable more accurate estimation of ECAP magnitudes and auditory neural activity patterns from severely corrupted ECAP matrices. A reordering technique was proposed based on the physiological characteristics of ECAP signals to assist LSA Wiener filtering in the second denoising stage, aiming to estimate the noise region of the ECAP matrix. The effectiveness of this estimation was verified using the proposed CNN-based denoising mask. Quantitative evaluations using normalized root mean square error (RMSE) for ECAP magnitude ( ) and auditory neural activity pattern ( ) revealed that both PECAP and PECAP-TSPD significantly reduce error metrics compared to unprocessed data across various signal-to-noise ratios (SNRs), noise densities, and test scenarios. PECAP-TSPD consistently outperformed PECAP in terms of both and . For ECAP matrices contaminated by random noise, the average values across seven scenarios and twelve SNR levels were as follows: PECAP-TSPD (3.83%), PECAP (5.14%), and unprocessed (23.07%). Under impulse noise, the corresponding values were as follows: PECAP-TSPD (3.13%), PECAP (5.57%), and unprocessed (21.97%). Similarly, the average under random noise was 3.01% for PECAP-TSPD and 4.64% for PECAP, while, under impulse noise, the values were 2.39% and 5.23%, respectively. The simulated and experimental results also showed that the proposed TSPD algorithm performs best in terms of RMSE ( 1.952%, 1.407%), TDCC (0.9988), and SSIM (0.9931), when compared to the baselines (PECAP, PECAP-I-Median, and PECAP-CNN). Future work will include validating the proposed PECAP-TSPD algorithm using clinical ECAP data to assess its robustness and practical applicability in real-world auditory diagnostic contexts.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Liebscher T. Hornung J. Hoppe U. Electrically evoked compound action potentials in cochlear implant users with preoperative residual hearing Front. Hum. Neurosci.202317112574710.3389/fnhum.2023.112574737850038 PMC 10577430 · doi ↗ · pubmed ↗
- 2He S. Teagle H.F.B. Bunchman C.A. The electrically evoked compound action potential: From laboratory to clinic Front. Neurosci.20171133910.3389/fnins.2017.0033928690494 PMC 5481377 · doi ↗ · pubmed ↗
- 3Hughes M.L. Fundamentals of Clinical ECAP Measures in Cochlear Implants: Part 1: Use of the ECAP in Speech Processor Programming (2nd ed.)Available online: https://www.audiologyonline.com/articles/fundamentals-clinical-ecap-measures-in-846(accessed on 13 February 2025)
- 4De Vries L. Scheperle R. Bierer J.A. Assessing the electrode-neuron interface with the electrically evoked compound action potential, electrode position, and behavioral thresholds J. Assoc. Res. Otolaryngol.20162223725210.1007/s 10162-016-0557-9PMC 485482626926152 · doi ↗ · pubmed ↗
- 5Choi C.T.M. Wu D.L. Electrically evoked compound action potential studies based on finite element and neuron models IEEE Trans. Magn.202258750140410.1109/TMAG.2022.3175938 · doi ↗
- 6Garcia C. The Panoramic ECAP Method: Estimating Patient-Specific Patterns of Current Spread and Neural Health in Cochlear-Implant Users Ph.D. Dissertation University of Cambridge Cambridge, UK 202210.1007/s 10162-021-00795-2PMC 847670233891218 · doi ↗ · pubmed ↗
- 7Dong Y. Briaire J.J. Stronks H.C. Frijns H.M. Speech perception performance in cochlear implant recipients correlates to the number and synchrony of excited auditory nerve fibers derived from electrically evoked compound action potentials Ear Hear.20234427628610.1097/AUD.000000000000127936253905 · doi ↗ · pubmed ↗
- 8Takanen M. Strahl S. Schwarz K. Insights into electrophysiological metrics of cochlear health in cochlear implant users using a computational model J. Assoc. Res. Otolaryngol.202425637810.1007/s 10162-023-00924-z 38278970 PMC 10907331 · doi ↗ · pubmed ↗