Boosting 3D Object Detection with Adversarial Adaptive Data Augmentation Strategy
Shihao Li, Jingsong Li, Jianghua Fu, Qiuyue Chen

TL;DR
This paper introduces a new data augmentation strategy to improve 3D object detection in autonomous driving systems, making them more robust to environmental changes.
Contribution
The novel adversarial adaptive data augmentation strategy enhances 3D object detection robustness during image feature extraction.
Findings
The method improves detection accuracy on nuScenes-mini and KITTI datasets.
It demonstrates stronger stability against environmental changes and data perturbations.
Abstract
In real-world applications, autonomous driving systems need to handle a variety of complex scenarios, such as object occlusion and lighting changes. In these scenarios, accurately identifying various objects is crucial for perceiving the surrounding environment and making reliable decisions. In this context, the fusion of Lidar and cameras is vital for the accuracy of object detection. To this end, we propose an adversarial adaptive data augmentation strategy that introduces virtual adversarial perturbations during the image feature extraction process, effectively enhancing the robustness of 3D object detection methods and enabling them to maintain stable performance when facing environmental changes and data perturbations. Experimental results on the nuScenes-mini and KITTI datasets show that, compared with previous 3D object detection methods, our method not only improves detection…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
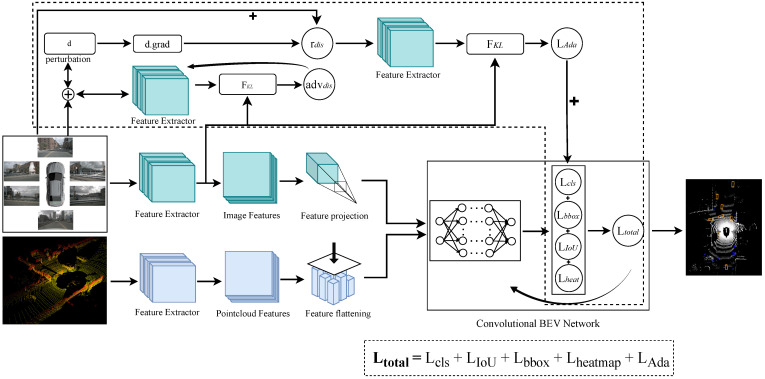 Figure 1
Figure 1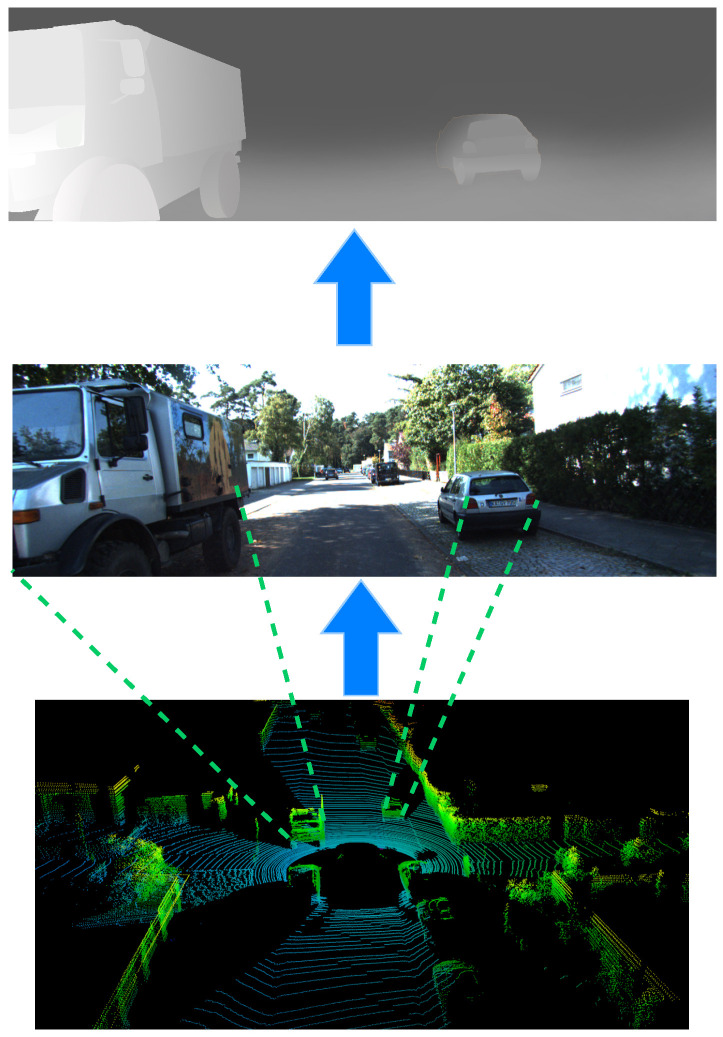 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Adversarial Robustness in Machine Learning · Autonomous Vehicle Technology and Safety
1. Introduction
Reliable 3D object detection plays a crucial role in autonomous driving, promoting the safety and dependability of the self-driving system. Existing 3D object detection methods can be categorized into two groups: unimodal approaches and multimodal approaches. Unimodal approaches rely solely on single type of sensor for object detection, which is easy to implement but suffers inherent limitations. For example, while cameras excel in capturing rich visual details, they are susceptible to variations in ambient light and weather conditions. In contrast, Lidar provides precise three-dimensional information about objects with higher robustness to illumination variations. However, it lacks the ability to discern detailed information. Different from unimodal approaches, multimodal approaches can fully integrate both sensors to exploit their complementary information for higher accuracy and robustness. Consequently, these methods outperform unimodal ones and are widely studied in the field of 3D object detection.
In the field of multimodal 3D object detection, the key to success lies in the fusion of multimodal data. In recent years, the increasing diversity of sensor data has made the integration of complementary information from different modalities more important. Methods based on the Bird’s Eye View (BEV) [1] perspective, such as BEVDet [2] and BEVFusion [3], can effectively address issues of scale and occlusion caused by different viewpoints, enabling more efficient information aggregation and thereby enhancing the accuracy and reliability of 3D object detection. Therefore, we adopt the BEV method to transform data from different sensors into a unified top–down perspective. Despite the significant progress made by BEV methods, there are still performance bottlenecks when dealing with issues such as object occlusion.
Motivated by the great success of adversarial training, in this paper, we proposed an adaptive data augmentation method to improve the robustness of BEV-based methods. Traditional static perturbations (such as CutMix [4] and Mixup [5]) usually increase sample diversity by mixing image regions and labels, but they rely on simple linear interpolation or region mixing, which limits their improvement concerning model robustness. In contrast, our method applies small perturbations to the input images in the convergent direction. These perturbations dynamically adjust with the training process, changing their intensity and direction in real time to adapt to the model’s changes. This adaptive perturbation can continuously identify the model’s vulnerabilities and conduct targeted training, effectively preventing the model from converging prematurely. In this way, the model can learn more robust feature representations when facing different environments and data distributions. This dynamic perturbation enhances the model’s consistency in feature learning, enabling it to maintain stable performance when confronted with complex changes in real-world application scenarios. Experimental results show that our method achieves 1.5% and 0.6% improvement in terms of mean Average Precision (mAP) and nuScenes Detection Score (NDS) against the baseline on the nuScenes-mini dataset, with a 0.8% mAP improvement on the Kitti dataset, which validates the effectiveness of our method.
Our main contributions are as follows:
- We propose an adversarial adaptive data augmentation strategy (AADA) to improve the robustness of 3D object detection. To the best of our knowledge, we present the first attempt to employ virtual adversarial training for adaptive augmentation.
- Extensive experiments show that our method significantly improves the performance of 3D object detection on the nuScenes-mini and Kitti datasets, demonstrating the effectiveness of our method.
2. Related Work
In this section, we first briefly review Lidar-based and camera-based 3D perception methods. Then, we present recent advances in multi-sensor fusion approaches.
2.1. Lidar-Based 3D Perception
Due to the disordered and uneven characteristics of point clouds, existing Lidar-based 3D object detection methods commonly project point clouds into Bird’s Eye View (BEV) or Range View (RV) to utilize well-studied 2D convolutional neural networks (CNNs). In early studies, Yang et al. [6] introduced an efficient single-stage detector without anchor boxes. Graham et al. [7] proposed flat point cloud features and detected them in BEV space. Liang et al. [8] proposed employing a 2D CNN to learn spatial features from the RV, and then obtained a 3D bounding box through a Region-CNN (R-CNN). VoxelNext [9] leveraged the sparsity of point clouds to directly extract and predict 3D detection boxes based on sparse features, without converting sparse features into dense feature maps. It relies entirely on 3D CNNs, eliminating the sparse-to-dense conversion step and the NMS post-processing step. Ref. [10] proposed an innovative method that enhances the accuracy and efficiency of 3D object detection by moving point cloud features between clusters. This method performed well in complex scenarios such as occlusion and sparse point clouds, significantly enhancing the model’s discriminative ability while reducing computational costs, demonstrating its potential for application in autonomous driving. SAFDNet [11] designed an adaptive feature diffusion strategy that effectively addresses the common issue of center feature loss in sparse feature detectors and reduces the computational cost for long-range detection, improving the computational efficiency of high-performance 3D object detectors in long-range detection. Despite great progress in Lidar-based 3D object detection, existing methods still suffer from limited accuracy for distant objects due to the loss of details.
2.2. Camera-Based 3D Perception
As 2D object detection methods are being widely investigated and continue to improve, image-based 3D object detection methods have been developed to achieve satisfactory performance at a relatively low cost. Chu et al. [12] first performed monocular depth estimation and lifted 2D pixels to pseudo-3D points. Then, they designed a novel neighbor-voting method that incorporates neighbor predictions to improve object detection from severely deformed pseudo-Lidar point clouds. Chen et al. [13] focused on generating 3D proposals by encoding object size prior, ground-plane prior, and depth information into an energy function. Li et al. [14] introduced additional branches after the stereo Region Proposal Network (RPN) to predict sparse keypoints, viewpoints, and object dimensions, which are then used to obtain coarse 3D object bounding boxes. Guo et al. [15] leverage high-level geometric representations from LiDAR point clouds to guide the stereo image detection and introduce an auxiliary 2D detection head to provide direct 2D semantic supervision. MonoCD [16] boosted detection accuracy and robustness by leveraging the complementarity of global depth cues and geometric relationships, without enhancing the precision of individual detection branches. OPEN [17], via Object-wise Position Embedding, effectively incorporated object depth information, thereby improving the accuracy of 3D detection. Although camera-based 3D object detection methods exhibit superior results under good weather conditions, they suffer from severe accuracy drops under significant weather condition variations.
2.3. Multi-Sensor Fusion
To address the limitations of the aforementioned methods using only a single type of data, multi-sensor fusion has been studied to combine the best of both worlds. Early research [18] focused on sensor feature fusion. For example, a multi-camera-based joint 3D detection and segmentation method was developed using a unified BEV representation to fuse multi-camera data [19,20]. Then, subsequent research continued to improve multi-sensor fusion detection from different perspectives [21,22]. Specifically, a BEV-based multimodal fusion 3D detection method [23] was proposed to aggregate Lidar, camera, and millimeter-wave radar data with BEV for 3D object detection. Overall, it has been widely demonstrated that combining BEV with multi-sensor fusion 3D detection can improve detection accuracy and robustness.
3. Methodology
In this section, we propose an adversarial adaptive data augmentation strategy to enhance the robustness of multimodal 3D object detection methods. As shown in Figure 1, our network takes multiview images and Lidar point clouds as inputs. In the image feature extraction branch, the generalization ability of the model is enhanced by applying adaptive pixel-level perturbations to the images. Following this, specific encoders are employed to extract features from both images and point clouds. Then, these multimodal features are merged into a unified Bird’s Eye View (BEV) representation to reduce occlusion and eliminate viewpoint differences, facilitating the fusion process. Finally, a customized task head executes the object detection task to produce the final results.
3.1. Feature Extraction
3.1.1. Image Feature Encoding
The input image is first cropped into patches and fed to the patch embedding layer to obtain feature vectors. Then, the resultant embeddings are passed to the subsequent Transformer layers in order to integrate a self-attention mechanism to capture long-range dependencies within the image. By integrating the hierarchical features produced by each Transformer layer, multi-scale image information can be aggregated such that the network’s ability can be enhanced. In addition, a hierarchical perceptual window mechanism is also employed such that features at different levels can be concentrated in perceptual windows of different sizes, which significantly improves the efficiency of the network in processing multi-scale information.
3.1.2. Point Cloud Feature Encoding
The input point cloud is first voxelized and then fed into the sparse point cloud encoder to obtain point cloud embeddings. Within the point cloud encoder, sparse 3D convolutional networks are employed for efficient point cloud feature extraction. Afterwards, the resultant sparse voxelized features are passed through the convolutional and encoder layers to generate the final features.
3.2. BEV Feature Transformation
To project the features of camera images and Lidar point clouds into a unified coordinate system, we construct a shared BEV plane, which effectively fuses multimodal features. This method helps to preserve geometric and semantic information while reducing efficiency bottlenecks in view transformation.
3.2.1. Image-to-BEV Transformation
As shown in Figure 2, after projecting the Lidar point cloud onto the image, we extract the depth information of each pixel to create a depth map. Subsequently, we employ a three-layer network to extract depth features from the depth map. Then, the resultant depth features are combined with the original image features and fed to another three-layer network for feature refinement. Afterwards, a softmax layer is adopted to generate the depth distribution. Next, we multiply the depth information with the features to aggregate image and depth information. After this series of processing steps, we map the pixel coordinates of the image depth features to the Bird’s Eye View (BEV) plane based on the extrinsic camera parameters, producing the coordinates and corresponding to each pixel, as shown in Equation (1).
where K is the internal camera parameter matrix and T is the transformation matrix.
3.2.2. Point Cloud-to-BEV Transformation
After point cloud feature encoding, each feature is associated with specific coordinates . To align these point cloud features with the BEV plane, a flattening transformation is conducted on the z-axis. This ensures accurate mapping of the point cloud features to their corresponding locations on the BEV plane.
3.3. Convolutional BEV Fusion
After converting the point cloud and image features extracted from the backbone into a unified BEV space, feature misalignment between the two modalities still hinders their fusion. To address this issue, we employ a Convolutional BEV Encoder. This encoder consists of a single-layer convolutional fusion module and the SECOND [24] network. The single-layer 3 × 3 convolutional fusion module is capable of extracting classification targets from bird’s-eye view images, effectively alleviating the local misalignment problem of multimodal features. Meanwhile, the SECOND [24] network can further extract deeper and more semantic features, enhancing the representation ability and highlighting key target information.
3.4. Adversarial Adaptive Data Augmentation
To enhance the generalization capability of 3D object detection methods, we propose an adversarial adaptive data augmentation strategy. By introducing minor perturbations to input images to hinder model convergence—perturbations that dynamically adapt during training—the model is trained to maintain stable predictions under these “adversarial” interferences, thereby achieving superior generalization performance.
The adversarial adaptive augmentation strategy is detailed in Algorithm 1. First, a softmax operation is conducted on to obtain :
Next, we randomly generate a perturbation with the same shape of and normalize to obtain . is then fed into the image feature extraction module along with to obtain , where the hyperparameter controls the intensity of the perturbation.
Algorithm 1: Adversarial Adaptive Augmentation Strategy Input: : Orignal image : Image feature extraction network : Against the size of the sample perturbation : The size of the antagonistic sample Output: : Local adversarial loss 1 2 Create a tensor 3 4 5 6 7 8 9 10
Afterwards, we evaluate the difference between and by calculating their similarity :
Subsequently, we compute the gradient with respect to the perturbation and optimize to obtain . is then combined with the hyperparameter to compute the adaptive perturbation , where the controls the maximum perturbation value. After that, is added to the original image , which is then fed into the image feature extraction module to obtain the perturbed image feature .
Finally, we compute the KL loss between and as the adaptive perturbation loss :
3.5. Loss Function
In our model, the total loss function , as shown in Equation (13), consists of the following components: The classification loss is used to evaluate the model’s classification accuracy by reflecting the differences between the predicted and ground-truth classes. The IoU loss measures the overlap between the predicted and ground-truth bounding boxes, and optimizing it can make the predicted boxes more accurately cover the targets. The bounding box loss calculates the coordinate deviations between the predicted and ground-truth bounding boxes, helping to precisely adjust the position and size of the boxes. The keypoint detection regression loss ensures the accurate positioning of keypoints. In addition, we introduce the adaptive augmentation loss to enhance the model’s robustness in different environments. The combined effect of these loss functions drives the model to achieve high accuracy and stability in the object detection task.
where is the predicted probability, is a weighting factor, is an adjustment factor, is used to adjust the weights in the loss function. and are the parameters of the predicted bounding box and the true bounding box, and denotes the weighted value of the loss.
4. Experiments
4.1. Datasets
To evaluate its effectiveness, we conducted experiments on the nuScenes-mini and KITTI [25] datasets. The nuScenes-mini dataset is a subset of the nuScenes [26] dataset, including ten scenes and 1000 samples. The mean average precision (mAP) and nuScenes detection score (NDS) are used to evaluate and compare the performance of different methods. The KITTI dataset provides 14,999 images and corresponding point clouds for the detection task, of which 7481 groups are used for training and 7518 groups are used for testing. The dataset is divided into three categories: easy, medium, and difficult according to whether the annotation box is occluded, the degree of occlusion, and the box height. The mAP is used to evaluate different methods.
4.2. Implementation Details
On the nuScenes-mini dataset, we set to 5, to 2, epoch to 12, and and to 1 and 0.1, respectively. The batch size was set to 4, the minimum learning rate was set to 0.0001, and a cluster equipped with four V100 GPUs was used for training. On the KITTI dataset, we used the same training parameters as the nuScenes-mini dataset. All experiments were conducted on a PC with four NVIDIA V100 GPUs.
4.3. Evaluation Results
4.3.1. Results on nuScenes-Mini Validation Set
A series of state-of-the-art 3D object detection methods were re-implemented for evaluation, including PointPillars [27], PGD [28], Centerpoint [29], DAL [30], UVTR [31], Sparsefusion [32], and BEVFusion [3]. As shown in Table 1, the number of training iterations was adjusted during re-implementation to ensure fair comparison. Detection results on the nuScenes-mini validation set are reported in Table 1, where our method is observed to achieve a 1.5% improvement in mAP and a 0.4% improvement in NDS compared to the baseline detector BEVFusion. Furthermore, superior performance over previous approaches is demonstrated, confirming the method’s effectiveness. Increased computational resources are limited to 14% relative to BEVFusion, with training time per epoch being extended by only 47 s, as indicated in Table 2.
4.3.2. Results on KITTI Validation Set
To further verify the effectiveness of the proposed method, additional experiments were conducted on the KITTI dataset. MVXNet [33] was selected as the baseline model, with the original image feature extraction network (ResNet [34]) being replaced by Swin Transformer [35]. The proposed AADA strategy was subsequently introduced to enhance model robustness. Experimental results are presented in Table 3.
As indicated in the results, the proposed method achieves a minimum improvement of 0.8% in mean average precision (mAP). Of particular significance is the observed performance enhancement in cyclist detection tasks, where superior results are demonstrated compared to the baseline detector across varying difficulty levels, with respective improvements of 3.4%, 2.6%, and 1.7% being achieved. These findings not only validate the method’s effectiveness, but also reveal its capability to consistently improve detection performance under different challenge conditions, particularly in the more demanding scenario of cyclist detection. The demonstrated improvements are considered to provide substantial evidence for the method’s practical application potential.
4.4. Ablation Study
This section analyzes the specific effects of hyperparameters and on method effectiveness, with particular focus on their impact on model performance. Ablation experiments are subsequently conducted through systematic comparison between the proposed adversarial perturbation and Gaussian noise.
4.4.1. Impact of ϵ
The hyperparameter determines the maximum perturbation magnitude during adversarial sample generation. Smaller values result in generated samples being closer to the original inputs. However, excessively small may compromise model robustness against real-world perturbations. Experimental investigation of values (Table 4) reveals optimal performance with = 2, where the proposed method achieves peak mAP and NDS scores. This configuration is consequently adopted as the default experimental setting.
4.4.2. Impact of ξ
Unlike , directly controls the magnitude of the input perturbation during training, which is proportional to . By appropriately increasing the input perturbation, the model is prone to be more robust to perturbations. Nevertheless, if is too large, excessive perturbation may negatively affect the model performance. Consequently, we conduct experiments to investigate the effects of and present the results in Table 5. As we can see, our model achieves the best performance in terms of mAP and NDS when is set to 5. This suggests that by carefully tuning the parameter, the model’s ability to adapt to input perturbations can be enhanced while maintaining its performance.
4.4.3. Comparison with Other Data Augmentation Methods
To highlight the superiority of our method, we conducted comparative experiments with baseline models and multiple perturbation strategies under specific experimental conditions. In the experiments, we selected the following three perturbation types: Gaussian noise, viewpoint transformation, and the dynamic data augmentation strategy PGD [36]. Gaussian noise was chosen as a common perturbation form due to its broad applicability and effective perturbation performance, with its mean and standard deviation set to 0 and 25, respectively, to ensure reasonable and effective perturbations. The viewpoint transformation method simulates image variations under different perspectives by adjusting angles and dimensions, where the rotation angle range is set between −5.4 to 5.4 degrees, and the scaling ratios for height and width are within 0.38 to 0.55 times, mimicking potential viewpoint changes encountered during real-world vehicle operation. For the PGD strategy, the perturbation norm is 0.015, the perturbation step size is 0.01, and the number of iterations is set to 10, ensuring controllability of perturbations and reproducibility of experiments. The experimental results are shown in Table 6.
As shown in the table, our method demonstrates significant advantages over static data augmentation approaches—Gaussian noise and view transformation. In comparison with the dynamic data augmentation strategy PGD, although our method exhibits a slightly lower mAP metric than PGD, the training time of PGD is approximately twice as long as that of our method. This indicates that our approach achieves high performance while substantially reducing training time costs, demonstrating superior efficiency and practical applicability.
4.5. Visualization Results
In Figure 3, we present 3D object detection results achieved on the nuScenes-mini dataset. As we can see, our method can effectively identify objects even in challenging scenes, such as occluded objects and close objects. As shown in Figure 3a, our method captures details that may be overlooked in natural scenes. In addition, as shown in Figure 3b, our method is also able to recognize objects without explicit labels. In Figure 4, we can see that our method has better recognition effect than MVXNet, which further demonstrates the effectiveness of our method.
5. Limitations and Future Research
5.1. Limitations
Despite the superior performance, our approach still has some challenges.
5.1.1. Poor Recognition of Small Objects
As shown in Figure 5, when objects are distant and small, their recognition becomes more challenging. This is primarily because these small, far-away objects occupy only a few pixels in the image. Our feature extraction network partitions the image into several non-overlapping local windows for self-attention computation. The division of local windows makes feature extraction in each window relatively independent, with limited information interaction across windows. Small targets may be scattered across multiple windows, making it difficult for the model to capture their global features and contextual information, which affects the accurate detection of small targets.
5.1.2. Limitations of Manual Hyperparameter Selection for AADA
The two key hyperparameters of AADA (perturbation size and number of perturbed samples) significantly affect the algorithm’s performance. Manually setting these parameters has limitations because they are difficult to adapt to different datasets and task requirements, necessitating extensive experiments for tuning, which is a cumbersome and time-consuming process. Moreover, the manually chosen parameters may no longer be applicable when the data distribution or environment changes, leading to unstable algorithm performance.
5.2. Future Research Trends
In response to the limitations of the current algorithm, our future work will focus on the following aspects:
- 1.Enhancing small-object extraction capability: We will consider dynamically adjusting the size and position of local windows in the image feature extraction network based on image content, focusing on feature extraction in small-object regions. Meanwhile, we will design feature extraction modules tailored for small objects to increase the model’s sensitivity and extraction efficiency for small-object features.
- 2.Diverse environment evaluation: We will conduct comprehensive environmental adaptability assessments of the proposed method. The performance of the method will be tested under various environmental conditions, including night driving and adverse weather, to analyze its limitations and optimize the algorithm in a targeted manner.
- 3.Automated hyperparameter tuning: We will develop automated hyperparameter adjustment methods to efficiently explore the hyperparameter space and identify better parameter combinations, thereby improving the overall performance and stability of the algorithm.
6. Conclusions
This paper proposes an adversarial adaptive data augmentation strategy to enhance the robustness of 3D object detection. Unlike traditional data augmentation methods that rely on simple linear interpolation or image region mixing, our AADA method introduces adaptive perturbations during training that can dynamically adjust their intensity and direction in real time to adapt to model changes and prevent premature convergence. These perturbations can identify model weaknesses and conduct targeted training, prompting the model to generate more consistent outputs, thereby achieving superior performance. Experimental results on the nuScenes-mini and KITTI datasets demonstrate the significant effectiveness and practicality of our method in 3D object detection.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Li H. Sima C. Dai J. Wang W. Lu L. Wang H. Zeng J. Li Z. Yang J. Deng H. Delving Into the Devils of Bird’s-Eye-View Perception: A Review, Evaluation and Recipe IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI)2023462151217010.1109/TPAMI.2023.333383837976193 · doi ↗ · pubmed ↗
- 2Huang J. Huang G. Zhu Z. Ye Y. Du D. BEV Det: High-performance Multi-camera 3D Object Detection in Bird-Eye-Viewar Xiv 202110.48550/ar Xiv.2112.117902112.11790 · doi ↗
- 3Liu Z. Tang H. Amini A. Yang X. Mao H. Rus D. Han S. BEV Fusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representationar Xiv 202210.48550/ar Xiv.2205.13542 · doi ↗
- 4Yun S. Han D. Oh S. Chun S. Choe J. Yoo Y. Cut Mix: Regularization Strategy to Train Strong Classifiers with Localizable Features Proceedings of the International Conference on Computer Vision Seoul, Republic of Korea 27 October–2 November 2019
- 5Zhang H. Cisse M. Oh S. Dauphin Y.N. Lopez-Paz D. mixup: Beyond Empirical Risk Minimization Proceedings of the International Conference on Learning Representations Vancouver, BC, Canada 30 April–3 May 201810.48550/ar Xiv.1710.09412 · doi ↗
- 6Yang B. Luo W. Urtasun R. PIXOR: Real-time 3D Object Detection from Point Clouds Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Salt Lake City, UT, USA 18–23 June 2018
- 7Graham B. Engelcke M. Laurens V.D.M. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Salt Lake City, UT, USA 18–23 June 20189224923210.1109/CVPR.2018.00961 · doi ↗
- 8Liang Z. Zhang M. Zhang Z. Zhao X. Pu S. Range RCNN: Towards Fast and Accurate 3D Object Detection with Range Image Representationar Xiv 202010.48550/ar Xiv.2009.002062009.00206 · doi ↗