Modeling eye gaze velocity trajectories using GANs with spectral loss for enhanced fidelity
Shailendra Bhandari, Pedro Lencastre, Rujeena Mathema, Alexander Szorkovszky, Anis Yazidi, Pedro G. Lind

TL;DR
This paper introduces a GAN-based method using LSTM and CNN to generate realistic eye gaze velocity data, improving on traditional models.
Contribution
A spectrally regularized LSTM-CNN GAN is proposed for high-fidelity synthetic eye gaze velocity trajectory generation.
Findings
The LSTM-CNN GAN with spectral loss best matches real data distribution and temporal dependencies.
Spectral regularization improves GAN stability and data fidelity for eye gaze modeling.
HMM-generated data shows significant statistical divergence from real data compared to the proposed GAN.
Abstract
Accurate modeling of eye gaze dynamics is essential for advancement in human-computer interaction, neurological diagnostics, and cognitive research. Traditional generative models like Markov models often fail to capture the complex temporal dependencies and distributional nuance inherent in eye gaze trajectories data. This study introduces a Generative Adversarial Network (GAN) framework employing Long Short-Term Memory (LSTM) and Convolutional Neural Network (CNN) generators and discriminators to generate high-fidelity synthetic eye gaze velocity trajectories. We conducted a comprehensive evaluation of four GAN architectures: CNN-CNN, LSTM-CNN, CNN-LSTM, and LSTM-LSTM–trained under two conditions: using only adversarial loss (\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy}…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
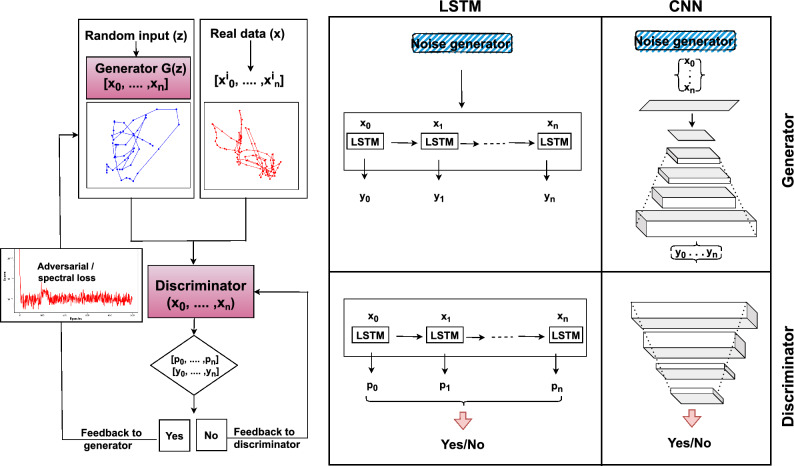 Figure 1
Figure 1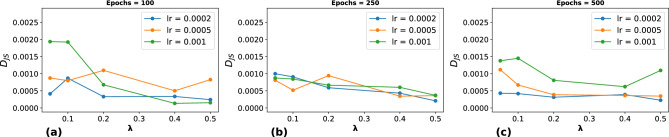 Figure 2
Figure 2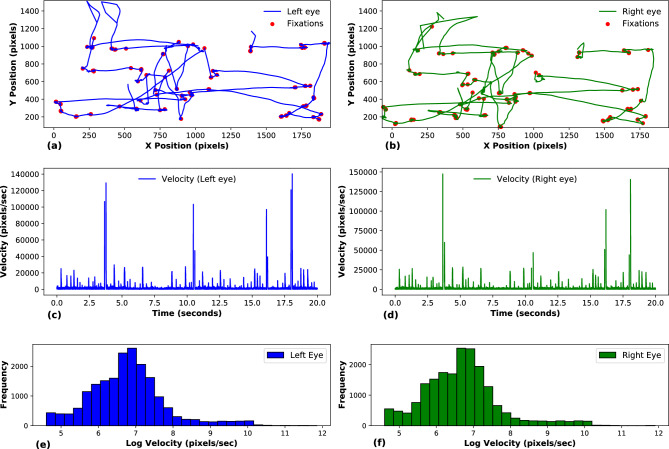 Figure 3
Figure 3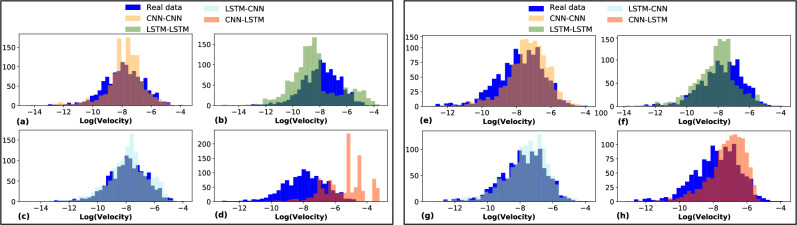 Figure 4
Figure 4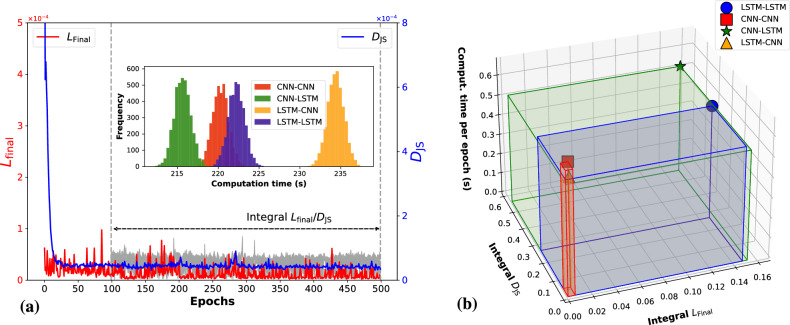 Figure 5
Figure 5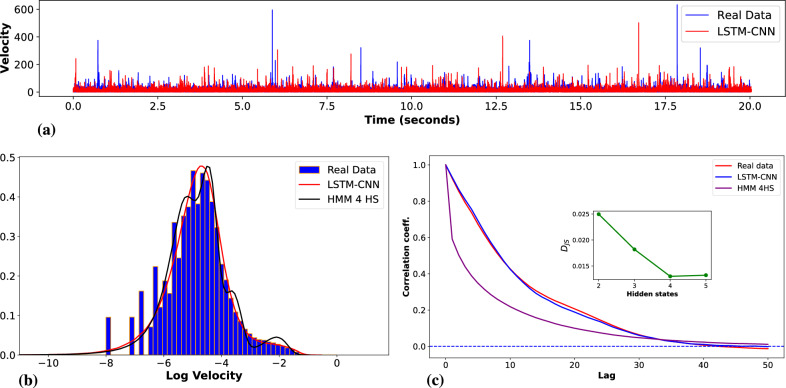 Figure 6
Figure 6- —OsloMet - Oslo Metropolitan University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGaze Tracking and Assistive Technology
Introduction
Eye gaze trajectories provide critical insights into human visual attention, perception, and cognitive processes^1,2^. Modeling the dynamics of stochastic processes, such as eye gaze trajectories, is a significant challenge with practical applications in fields like human-computer interaction, cognitive science, and artificial intelligence (AI). These trajectories are critical for understanding behaviors in tasks like reading, visual search, and interaction with computer systems^3^. The sequential nature and inherent stochasticity of eye movement patterns pose significant challenges for accurate modeling and prediction. Capturing these dynamics is not only important for advancing theoretical understanding but also has practical applications in areas like user interface design, psychological assessment, and marketing research^4^. Recent technological advances, such as wearable eye-tracking systems enabling synchronized multimodal data acquisition^5^, further underscore the need for robust modeling frameworks to interpret complex gaze dynamics.
Recent advancements in artificial intelligence (AI) and deep learning have spurred the development of various generative models, including variational autoencoders (VAEs)^6^, GANs^7,8^, and deep reinforcement learning (DRL)^9,10^. These models aim to learn underlying probability distributions of data for tasks such as image, video, and time-series generation^11–13^. GANs, in particular, have demonstrated remarkable success but also come with inherent challenges. The process of developing a robust GAN typically involves: training the generator and discriminator using real samples, and validating the generated outputs against a reference test set^14^. The key objective is to minimize the divergence between the real data distribution and the generated data distribution^15,16^. Despite their potential, GANs often face issues such as training instability, mode collapse, and difficulty in modeling rare events or complex temporal dependencies^17–19^.
Traditional approaches, such as Markov models, have been used to approximate the sequential dynamics of eye movement^20,21^, but often overlook the intricate interdependencies of human vision. These models often fail to account for interdependencies influenced by perceptual constraints, memory, and cognitive factors. HMMs have shown promise in ecological movement modeling^2,22–24^, with McClintock and Michelot^25^ providing foundational implementations. Despite their utility, HMMs remain limited in capturing the nuanced temporal dependencies of human gaze patterns, which share similarities with animal foraging behaviors in their stochastic exploration-exploitation strategies^26,27^.
Existing methods for generating human-like eye-tracking data can be broadly categorized into training-free statistical models and machine-learning approaches. Statistical models that synthesize eye movements have been used to to enhance the realism of rendered faces by generating physiologically plausible rotations^28,29^, natural gaze from head motion^30^, and even speech-driven head–eye coordination^31^. Other approaches simulate synthetic eye-region images^32^^32^ or produce saccadic and smooth pursuit sequences^33^, with some models further incorporating micro-saccadic jitter, noise, and measurement errors to better capture the dynamic properties of eye movements^34–37^. In contrast, machine-learning methods employ deep architectures–including CNN–LSTM networks^38^ and GANs^39^–as well as clustering and variational autoencoder techniques^40^, though these methods face limitations in terms of stimulus specificity and replicating fine-grained oculomotor details. In addition, a compact review of related work reveals that recent studies have attempted to adapt GAN-based architectures for modeling eye-gaze trajectories. Examples include Recurrent Conditional GAN (RCGAN), Time-series GAN (TimeGAN), Signature Conditional Wasserstein GAN (SigCWGAN), and Recurrent Conditional Wasserstein GAN (RCWGAN)^41^. These models, while innovative, have struggled to capture cross-feature relationships and the full spectrum of temporal correlations inherent in eye movement data.
In response to these limitations, our study introduces an LSTM-CNN GAN augmented with spectral loss regularization. This approach integrates spectral analysis into the adversarial training process, thereby enhancing the model’s ability to capture both global and local frequency characteristics of eye-gaze trajectories. Compared to existing GAN architectures and traditional HMM-based methods, our proposed model offers improved learning stability, better replication of distribution tails, and more accurate modeling of temporal dependencies.
The primary contributions of this work are threefold:
- We introduce spectral loss regularization to enhance GANs’ ability to capture both global and local frequency characteristics of eye-gaze trajectories, improving temporal dependency modeling and distributional fidelity.
- We conduct a systematic comparison of four lightweight GAN architectures (CNN-CNN, CNN-LSTM, LSTM-CNN, LSTM-LSTM) against HMM baselines, demonstrating that spectrally regularized GANs outperform traditional models in replicating stochastic gaze dynamics.
- We develop a computationally efficient framework that balances accuracy and complexity, providing a practical solution for synthetic eye-tracking data generation without requiring specialized hardware or complex architectures. By bridging the gap between GAN-based methods and classical mathematical models, our work advances the state-of-the-art in eye-gaze trajectory modeling and provides a robust tool for both theoretical investigations and practical applications in various domains.
Methods
Generative adversarial networks
A variety of probabilistic models describe animal movement by considering the position as an output of a deterministic function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G$$\end{document} applied to a sampler of random latent variables. For example, in correlated random walks (CRWs), let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s_t$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\phi _t$$\end{document} represent the step length and turning angle at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t$$\end{document} , then the CRW model can be formulated as^20^:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{pmatrix} (s_1, \phi _1) \\ \vdots \\ (s_n, \phi _n) \end{pmatrix} = \begin{pmatrix} \left( F^{-1}(Z_G^1 \mid \theta _F),\; H^{-1}(Z_H^1 \mid \phi _0, \theta _H) \right) \\ \vdots \\ \left( F^{-1}(Z_G^n \mid \theta _F),\; H^{-1}(Z_H^n \mid \phi _{n-1}, \theta _H) \right) \end{pmatrix} = G(z), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H$$\end{document} are cumulative distribution functions (CDFs) with parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _F$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta _H$$\end{document} , typically derived from log-normal and von Mises probability density functions, respectively. The variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z_G^n$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z_H^n$$\end{document} are random variables representing the latent space, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z$$\end{document} denotes the collection of these latent variables. The generative aspect of GANs applies the deterministic function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G$$\end{document} to latent variables sampled according to a specified distribution. GANs comprise two neural networks–the generator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G$$\end{document} and the discriminator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D$$\end{document} –trained concurrently. The discriminator learns to differentiate between data generated by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G(z)$$\end{document} and real data, enhancing the generator’s ability to effectively replicate the empirical data distribution.
The GAN framework we are using in this work consists of these two neural networks: the generator and the discriminator, as shown in Fig. 1. They are trained alternately. Consider a classical training dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X = \{x^0, x^1, \dots , x^{s-1}\}$$\end{document} drawn from an unknown time series distribution. The generator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G(z)$$\end{document} receives a random noise vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z$$\end{document} sampled from a prior distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_z(z)$$\end{document} and produces the generated sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G(z)$$\end{document} . The discriminator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D$$\end{document} is trained to distinguish between the training data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x$$\end{document} and the generated data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G(z)$$\end{document} . The parameters of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D$$\end{document} are updated in order to maximize^42^:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathbb {E}_{x \sim P_{d}(x)}\left[ \log D(x)\right] + \mathbb {E}_{z \sim P_{z}(z)}\left[ \log \left( 1 - D\left( G(z)\right) \right) \right] , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_d(x)$$\end{document} is the real time series distribution and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_z(z)$$\end{document} is the distribution of the input noise. The output \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D(x)$$\end{document} represents the probability that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D$$\end{document} classifies the sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x$$\end{document} as real. The goal of the discriminator is to maximize the probability of correctly classifying real and generated samples, making \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D$$\end{document} a better adversary so that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G$$\end{document} must improve to fool \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D$$\end{document} . Similarly, the parameters of the generator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G$$\end{document} are updated to maximize:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \mathbb {E}_{z \sim P_{z}(z)}\left[ \log D\left( G(z)\right) \right] , \end{aligned}$$\end{document}to convince \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D$$\end{document} that the generated samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$G(z)$$\end{document} are real. The goal of optimizing classical GANs can be approached from several perspectives. In this study, we adopt the non-saturating loss function^43^, which is also implemented in the original GAN publication’s code^16^. The generator loss function is given by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_G = -\mathbb {E}_{z \sim P_{z}(z)}\left[ \log D\left( G(z)\right) \right] , \end{aligned}$$\end{document}which aims to maximize the likelihood that the generator creates samples labeled as real data samples. In addition, the discriminator’s loss function is given by:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_D = \mathbb {E}_{x \sim P_{d}(x)}\left[ \log D(x)\right] + \mathbb {E}_{z \sim P_{z}(z)}\left[ \log \left( 1 - D\left( G(z)\right) \right) \right] , \end{aligned}$$\end{document}which aims at maximizing the likelihood that the discriminator labels real data samples as real and generated data samples as fake. The expected values are approximated in practice using mini-batches of size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m$$\end{document} . The generator’s loss becomes:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_G = -\frac{1}{m} \sum _{i=1}^{m} \log D\left( G\left( z^{(i)}\right) \right) , \end{aligned}$$\end{document}and the discriminator’s loss is:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_D = \frac{1}{m} \sum _{i=1}^{m} \left[ \log D\left( x^{(i)}\right) + \log \left( 1 - D\left( G\left( z^{(i)}\right) \right) \right) \right] , \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x^{(i)}$$\end{document} are samples from the real dataset \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z^{(i)}$$\end{document} are noise samples from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P_z(z)$$\end{document} .
Spectral loss
To enhance the training of the generator, we complement its loss function with additional terms, including an application-specific term and a regularization term known as the spectral loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {spectral}}$$\end{document} ^44,45^. Spectral loss is a novel loss function designed to enhance generative models by embedding frequency domain insights into the training framework. It leverages the Fourier transform \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F$$\end{document} , which decomposes a signal into its constituent frequencies, to compare the real data sequence \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(x_0, x_1, \ldots , x_n)$$\end{document} with the generated sequence \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\hat{x}_0, \hat{x}_1, \ldots , \hat{x}_n)$$\end{document} ^46^. We define the spectral loss incorporated into the generator’s gradient descent as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_{\text {spectral}} = \sum _{k=0}^{N-1} \left[ \log \left( \left| F(x)_k \right| \right) - \log \left( \left| F(\hat{x})_k \right| \right) \right] ^2, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$|F(x)_k|$$\end{document} is the magnitude of the Fourier transform of the real data sequence at frequency \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k$$\end{document} , and similarly for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F(\hat{x})_k$$\end{document} . Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{x}$$\end{document} are the real and generated velocity trajectories, respectively. The discrete Fourier transform \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F$$\end{document} of a one-dimensional time series \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x$$\end{document} of length \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$N$$\end{document} is defined as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} F(x)_k = \sum _{n=0}^{N-1} x_n \cdot e^{-2\pi i \frac{kn}{N}}, \end{aligned}$$\end{document}for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k = 0, 1, \ldots , N-1$$\end{document} . By applying the logarithm to the magnitude of the Fourier transforms, the loss function normalizes amplitude disparities, focusing on the relative spectral energy distribution. The squared term captures the spectral discrepancy between real and synthetic data, assigning higher penalties to more significant differences. The summation over all frequencies consolidates the error across the frequency spectrum into a single scalar value, quantifying the generated data’s spectral fidelity.Fig. 1. Overview of the GAN process for generating eye-tracking data, showing the interaction between the generator, discriminator, and adversarial/spectral loss feedback. Detailed architectures of LSTM and CNN-based generators and discriminators, illustrating possible combinations for generating and discriminating gaze trajectory data from noise input.
Spectral regularization is then defined by combining the generator loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_G$$\end{document} with the spectral loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {spectral}}$$\end{document} :
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} L_{\text {final}} = L_G + \lambda L_{\text {spectral}}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} is the hyperparameter that weights the influence of the spectral loss. Various deep-learning architectures can be employed for the generator and discriminator networks in GANs. Among the most popular, efficient, and widely used techniques are LSTM networks and CNNs^47^. LSTMs are designed with memory cells that capture temporal dependencies in sequential data, making them highly suitable for modeling the temporal patterns inherent in eye-tracking datasets. CNN, on the other hand, excels at capturing spatial and spatiotemporal features through convolutional layers, which is advantageous for analyzing the spatial characteristics of eye-tracking data^48^. In all models, training utilized vectors of length 256 with random noise uniformly distributed between 0 and 1 as input. The models underwent 500 epochs of training with a learning rate of 0.0002, optimizing the combined loss function described above. To assess performance, we calculated the mean squared error between the predicted and real logarithmic Fourier decomposition spectra, as defined by Equations (6), (7), and (8). In this study, we utilize two architectures for both the generator and discriminator: CNN-based and LSTM-based architectures (see Fig. 1). Below, we provide a concise overview of the purpose and functionality of these networks. For a more comprehensive introduction to deep networks, we direct the reader to Christin et al.^49^.
LSTM networks and CNNs
LSTM networks are sophisticated architectures within recurrent neural networks (RNNs), particularly adept at modeling time series data, including trajectory analyses. A distinctive feature of LSTMs is their ability to capture and leverage long-term dependencies using gating mechanisms^47^. These architectures are widely employed in GANs for tasks such as predicting pedestrian movements and generating medical time-series data^50,51^. In our study, the generator network incorporates an LSTM layer specifically configured to accept a unique random seed at each time step. This LSTM layer generates a sequence of hidden vectors, each consisting of 16 attributes that capture the state of the eye-gaze trajectory. Subsequently, a dense layer processes each 16-dimensional hidden vector at predetermined time intervals, converting them into corresponding horizontal and vertical displacements. These displacements, when divided by the time interval, represent the velocity components of the eye-gaze trajectory. By aggregating these incremental displacements, we compile a detailed time series of the eye-gaze velocity, as illustrated in Fig. 1. The LSTM architecture is also employed in our discriminator. This component processes a sequence of positions, symbolically representing points in the eye-gaze path rather than actual gaze coordinates. The LSTM transforms these positions into a higher-dimensional latent space. A subsequent dense layer assesses each point in the sequence for its probability of being a plausible part of a trajectory. The discriminator’s output is a mean probability value, which is used to evaluate the accuracy and realism of the predicted eye-gaze trajectory.Fig. 2 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} vs. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} , illustrating the impact of the spectral loss weight ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} ) on the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} across different learning rates (0.0002, 0.0005, and 0.001). Results are shown for (a) 100, (b) 250, and (c) 500 training epochs, respectively.
CNN architectures utilize convolutional layers and are at the forefront of technologies for a multitude of applications, notably in signal and image processing. They excel at extracting both low-level and high-level features from multidimensional tensors^47^. In GANs, CNNs are extensively utilized^52^. Our approach adopts the architecture proposed by Radford et al.^52^ for image generation tasks. The generator begins with a random noise vector, which serves as a latent representation of a comprehensive time series. This is followed by a sequence of fractional-strided convolutions that progressively transform the latent representation into a time series with an increasing number of points and a decreasing number of features, culminating in a two-dimensional vector of the specified length (refer to Fig. 1).
In our implementation, batch normalization and ReLU activations are applied after each fractional-strided convolution, except for the final output layer, which employs a hyperbolic tangent activation as recommended by Radford et al.^52^. It is important to note that this CNN framework does not perform explicit sequential modeling of trajectories, and the latent representations are not necessarily time-correlated. For the CNN-based discriminator, we employ a series of strided convolutions to progressively convert the initial trajectory into a time series characterized by shorter lengths and more features, eventually producing a latent vector that encapsulates the entire trajectory. Batch normalization and LeakyReLU activations enhance the functionality of each convolution. The culmination of this process is a dense layer equipped with a sigmoid activation, which translates the latent vector into a probability assessing the realism of the trajectory (see Fig. 1).
The hyperparameters of the model architecture are listed in Table 1. To further analyze the effect of key hyperparameters listed in Table 1, we conducted a study to evaluate the impact of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} on the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} across different learning rates and training epochs, as illustrated in Fig. 2. Our experiments show that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} decreases as training epochs increase, indicating improved model convergence over time. However, higher \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} values introduce a trade-off, where excessive spectral regularization can slow down convergence and lead to instability in earlier training stages. Based on these findings, we selected \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda = 0.1$$\end{document} as it provides an optimal balance between GAN loss and spectral regularization. Additionally, we found that a learning rate of 0.0002 consistently yielded stable training dynamics and the lowest \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} values across different epochs, confirming its suitability for our model.Table 1. Summary of hyperparameters for the GAN model.Hyperparameter****ValueSequence length200Batch size128Learning rate0.0002OptimizerAdam \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _2$$\end{document} 0.5, 0.999Input channels256Epochs500Spectral loss ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{spectral}$$\end{document} )Yes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda$$\end{document} 0.1
Markov models
This study employs HMMs to model and analyze eye-gaze velocity time series data. Markov models are statistical frameworks capturing dependencies between current and recent states (typically, the most recent) in a time series, enabling synthetic data generation that preserves the temporal patterns observed in the original dataset^53^. HHMs extend this concept by incorporating unobserved (hidden) states, making them powerful for modeling systems where the underlying process is not directly observable^54^. In the context of eye-gaze data, hidden states may represent different types of eye movements, such as fixations and saccades. At the same time, the observations (known as emissions) correspond to measured eye-gaze velocities. We used the Baum-Welch algorithm^55^, a specialized Expectation-Maximization (EM) algorithm, for parameter estimation. This iterative algorithm refines estimates of the initial state probabilities, state transition probabilities, and emission probabilities to maximize the likelihood of the observed data. Utilizing HMMs facilitates the inference of hidden states and the optimization of model parameters based on observed data, supporting a detailed analysis of eye movement behaviors. For detailed mathematical formulations of the Markov and HMMs employed in this study, refer to Supplementary Information.Fig. 3(a, b, c, d) X-Y positions and velocity plots for left and right eye movements. The top two plots show the eye movement trajectories (left and right eyes) in terms of X and Y positions, while the bottom two plots show the respective velocity profiles over time. (e, f) Log-scaled velocity distributions for left and right eye movements for one participant. The histograms represent the distribution of logarithmic velocity values for both eyes.
Data and the statistical measure
We used eye-tracking data (All data collected was anonymized and follows the ethical requirements from the Norwegian Agency for Shared Services in Education and Research (SIKT), under the application with Ref. 129768.) that was gathered at Oslo Metropolitan University utilizing the advanced Eye-Link Duo device^56^, capable of reaching up to 2000 Hz but was adjusted to 1000 Hz for this study. Participants were tasked with searching for specific targets within images from the book Where’s Waldo^57^?. The measurements were recorded in screen pixels, capturing the nuanced movements of both left and right eyes. Fig. 3 provides a comprehensive visualization of the collected eye-tracking data. Fig. 3 (a,b) display the X-Y position trajectories for the left and right eyes, respectively, illustrating the spatial patterns during the search task. The subsequent panels (Fig. 3 (c,d)) depict the corresponding velocity profiles over time, highlighting the dynamics of eye movements.
The data from eye-tracking measurements were preprocessed and utilized to train a GAN. Initially, the velocity data for both left and right eyes are calculated by finding the Euclidean distance between consecutive position points and then dividing by the time interval, set at one millisecond, to convert this distance into velocity. Fig. 3 (e,f) presents the log-scaled velocity distributions for one participant’s left and right eyes, respectively. These histograms emphasize the range and frequency of velocities encountered during the task. Subsequently, the dataset was normalized using a MinMaxScaler, scaling the values to fit within the operational range of 0 and 1, as recommended in^58^. This normalization is crucial for the GAN’s training stability and convergence. Finally, the normalized data were segmented into sequences of 200 data points, forming the training batches for the GAN. These sequences were supplied to the discriminator, which learned to differentiate between real eye-tracking data and the synthetic data generated by the generator. This adversarial training process enhanced the discriminator’s ability to accurately identify authentic samples, thereby improving the overall performance of the GAN.
The performance of the GAN and HMM model is evaluated using the metric Jensen-Shannon ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} ). The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} , a symmetrized version of the Kullback-Leibler (KL) divergence, provides a symmetric measure of distance between probability distributions^59,60^. The JS divergence^60^ is defined by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} D_{JS}(P | Q) = \frac{1}{2} D_{KL}(P | M) + \frac{1}{2} D_{KL}(Q | M), \end{aligned}$$\end{document}where P and Q are distributions, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M = \frac{1}{2}(P + Q)$$\end{document} . The KL divergence is standard for assessing distributional similarity, enhancing maximum likelihood estimates. While preserving these properties, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} is more intuitive as it assesses the approximation of synthetic distributions to empirical ones. Therefore, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} can be relevant for discriminators within GANs to distinguish synthetic data from the generator. This measurement is always non-negative and its value is bounded by [0,1] \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(0\le D_{JS}\le 1)$$\end{document} , a lower value indicating higher similarity between the distribution of real and the generated data.
Complementing the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} , the spectral loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${L}_{\text {spectral}}$$\end{document} introduces a frequency domain perspective to the evaluation of generative models^44,45^. By utilizing the Fourier transform, the spectral loss compares the frequency content of real and synthetic sequences, focusing on capturing the spectral fidelity of the generated data. The loss function emphasizes the alignment of frequency characteristics between datasets by normalizing amplitude disparities and penalizing significant differences across the frequency spectrum. This approach is particularly advantageous for data exhibiting spatial or temporal patterns, ensuring that the model’s output maintains the structural coherence essential for high-quality generation. By integrating the Spectral loss into the generator’s optimization process, we not only refine the generator’s ability to produce realistic samples but also improve the overall stability and quality of the GAN model’s outputs. Together, these metrics provide a comprehensive framework for assessing and enhancing the performance of GANs. Fig. 5 shows the performance comparison of different GAN models over 500 epochs. The top left panel illustrates the Spectral Score (in log scale), showing how CNN-based models achieve more stable and lower scores compared to LSTM-based models. The top right panel depicts \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} (in log scale), indicating that CNN-based models maintain a closer similarity to the empirical distribution. The bottom panels compare the integral scores (Spectral loss ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{final}$$\end{document} ) and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} ) against the average computation time per epoch, with the LSTM-CNN model achieving the best balance between accuracy and computational efficiency.
When quantifying how well the time dependencies are replicated, we evaluate the autocorrelation of the velocity magnitude \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Vert \textbf{v}\Vert$$\end{document} . The autocorrelation function (ACF) is defined as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} ACF(h) = \frac{\sum _{t=1}^{T-h} (X_t - \bar{X})(X_{t+h} - \bar{X})}{\sum _{t=1}^{T} (X_t - \bar{X})^2}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_t$$\end{document} represents the time series at time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$t$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\bar{X}$$\end{document} is the mean of the series, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T$$\end{document} is the total number of observations, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h$$\end{document} is the time lag. The \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ACF(h)$$\end{document} quantifies the similarity between the data and a shifted version of itself by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h$$\end{document} time steps. The values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ACF(h)$$\end{document} range from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-1$$\end{document} to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1$$\end{document} , where values closer to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$1$$\end{document} indicate stronger positive correlation at the corresponding lag.
We computed and plotted the autocorrelation coefficient \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ACF(h)_X$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ACF(h)_Y$$\end{document} between the real and generated data across multiple time lags to evaluate how well the temporal dependencies and patterns of the real data were captured by the GAN-generated data. Although gaze trajectories are not stationary stochastic processes, both the GANs and the HMMs create time-homogeneous trajectories. Therefore, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ACF(h)_X$$\end{document} (and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ACF(h)_Y$$\end{document} , computed similarly) assess the model’s ability to replicate the “average” dynamics of the given time series.
Results
Architecture selection experiment
Fig. 4 presents log-transformed velocity distributions for real data alongside synthetic data generated by four GAN models: CNN-CNN, LSTM-CNN, CNN-LSTM, and LSTM-LSTM. Each model was trained under two conditions: using only adversarial loss ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_G$$\end{document} , Fig. 4 (a-d)) and using adversarial loss combined with spectral loss ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{final}$$\end{document} , Fig. 4 (e-h)). In both conditions, the distributions for real data and generated data are shown, illustrating the alignment of each model’s generated data with the real data distribution. Among the models, the LSTM-CNN architectures exhibit the closest alignment to the real data distribution. Furthermore, models trained with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{final}$$\end{document} (right column) show enhanced alignment, particularly in the distribution tails, indicating that spectral regularization ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{final}$$\end{document} ) helps GAN models capture the true characteristics of the velocity distribution more effectively.Fig. 4. Comparison of velocity distributions for real data (dark blue) and synthetic data generated by GAN models (a-d) with adversarial loss as in Equation (6) and (e-h) with ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_\textrm{final}$$\end{document} ) as in Equation (8).
Among the four GAN architectures, marked variations in performance and computational efficiency were observed, as illustrated in Fig. 5. Fig. 5 (a) highlights the progression of the total loss ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {final}}$$\end{document} ) over epochs for the LSTM-CNN architecture. Specifically, the red trajectory corresponds to the spectral loss term ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {spectral}}$$\end{document} ), while the blue trajectory represents the performance metric \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} , which quantifies the alignment between real and generated data distributions. The integral calculation for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {final}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} is applied from epoch 100 to 500 (indicated by the dashed vertical lines). An inset within the same figure further illustrates the frequency distribution of computation times across the architectures, underscoring the computational efficiency of CNN-LSTM and LSTM-LSTM models. Fig. 5 (b) presents a 3D representation of the integrals of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {spectral}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} , and the average computation time per epoch across all architectures. In this multidimensional space, the LSTM-CNN model demonstrates a notable reduction in integral volume, indicative of its optimal balance between computational efficiency and loss minimization. These results suggest that the LSTM-CNN architecture optimally harmonizes the complexity of LSTM layers with the computational advantages afforded by CNN layers, establishing it as a robust candidate for high-fidelity synthetic data generation with minimized training overhead.Fig. 5. Comparison of neural network architectures (CNN-CNN, LSTM-CNN, CNN-LSTM, LSTM-LSTM) across performance and computational metrics. (a) Total loss ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {final}}$$\end{document} ) over epochs for LSTM-CNN, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {final}}$$\end{document} combine GAN loss and spectral loss. The red line represents the spectral loss component ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {spectral}}$$\end{document} ), and the blue line indicates the performance comparison metric \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} , quantifying the similarity between real and generated data. The integral calculation begins at epoch 100 (dashed line). The inset in the same figure is the frequency distribution of computation times across architectures. (b) A 3D representation illustrating the integral values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {spectral}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} , and the average computation time per epoch for each model. The LSTM-CNN model demonstrates the most favorable efficiency, achieving the lowest integral volume across loss, performance, and computation time metrics.
GAN versus Markov model experiment
In this study, we compared the performance of the best GAN architecture (LSTM-CNN) with that of a HMM for modeling eye gaze velocity trajectories. The CNN-LSTM GAN utilized a random noise vector of 256 samples drawn from a uniform distribution as input. The models were trained on eye gaze velocity data consisting of 200-step time series sequences. The training was conducted over 500 epochs with a batch size of 128 and a learning rate of 0.0002. To enhance the GAN’s capability to capture the spectral characteristics of eye gaze movements–particularly at fine temporal resolutions–and to stabilize the learning process, spectral regularization \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{final}$$\end{document} was implemented within the GAN framework. We applied an HMM to the same eye gaze velocity data for comparison. The HMM modeled sequences of stochastic eye gaze velocities with a transition matrix dictating state transitions, optimized via the Expectation-Maximization (EM) algorithm during model fitting. To determine the optimal number of hidden states, we evaluated models with two to five states by calculating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} between the real data and the HMM-generated data, as shown in Fig. 6 (c). We observed that the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} decreased from approximately 0.0249 with two states to 0.0131 with four states, but then increased slightly to 0.013245 with five states. Based on this analysis, we selected a model with four hidden states as a balance between model complexity and performance. The emission probability matrix related hidden states to observable eye gaze velocities, enabling the HMM to capture the dynamics of eye gaze trajectories effectively and allowing for a concise comparison with the GAN model.Fig. 6. Comparison of real and generated data using GAN and HMM models. (a): The time series plot shows the differences between real and generated data over time for the LSTM-CNN model. (b): The histogram (blue) represents the real data distribution while the red and black curves represent the LSTM-CNN model with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {final}}$$\end{document} and the HMM model respectively. The LSTM-CNN + \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {final}}$$\end{document} (red curve) shows closer alignment with the real data in terms of capturing the broader distribution, however, the HMM (black curve) is more concentrated, highlighting differences in model performance between the two. (c): Autocorrelation plot for real data (red) and generated data from LSTM-CNN with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {final}}$$\end{document} (blue), and HMM with 4 hidden states (brown). The inset on the same plot shows JS divergence ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} ) between real and HMM-generated data as a function of the number of hidden states (2 to 5).
Table 2 compares the statistics for real and generated eye gaze velocity data LSTM-CNN and HMM. The LSTM-CNN model exhibits the closest match to the real data, with a mean of 0.00204 and a standard deviation of 0.0029, while also showing relatively minimal deviation in skewness (4.865) and kurtosis (34.204). This model achieves the lowest average loss (0.0471) and JS divergence (0.000322), indicating its ability to generate data that closely mimics the distribution of real eye gaze velocity patterns. On the other hand, the HMM-generated data demonstrates significant divergence from the real data, with a higher mean (0.0498) and a higher standard deviation (0.0730). The higher JS divergence (0.00714) further underscores the challenge the HMM faces in capturing the true complexity of the eye gaze velocity patterns. These results highlight the superior performance of the LSTM-CNN model in replicating real-world eye gaze dynamics.Table 2. Comparison of real velocity data with GANs, and HMM statistics.StatisticReal DataLSTM-CNN****HMMMean0.00210610.00204100.0498Standard Deviation0.00295300.00296400.0730Skewness4.70954.86594.39038Kurtosis30.930734.204423.7580Average ** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{final}$$\end{document} ** score–0.0471601–Average ** \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} ** score–0.00032220.01244
Fig. 6 presents a comparative analysis of real and generated data distributions using GAN (LSTM-CNN) and HMM approaches. The figure showcases how each model captures the characteristics of the real data and provides insight into their strengths and limitations across multiple performance metrics. In Fig. 6 (a), we observe the log-scaled velocity distributions for real data, the LSTM-CNN model, and the HMM model. The LSTM-CNN model shows a closer alignment with the real data distribution, indicating that incorporating spectral loss helps capture more variability and nuances in the data. The HMM model with four hidden states shows a relatively good fit to the real data, although some deviations are visible. These deviations indicate that while the HMM can model certain aspects of the real data, it may still miss some of the finer details, such as the distribution’s tails, which the LSTM-CNN better captures with a spectral loss plot. Fig. 6 (b) shows autocorrelation coefficients for the real data and the generated data from two different models: LSTM-CNN, and HMM with four hidden states. LSTM-CNN models capture the overall trend in the autocorrelation function. The HMM-generated data shows more pronounced deviations, particularly in the early lags, suggesting that the HMM model struggles to replicate the temporal dependencies present in the real data. The inset in the same plot displays the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} between real and HMM-generated data as a function of the number of hidden states (from 2 to 5).
Discussion
Accurate modeling of eye gaze velocity trajectories is crucial for advancements in fields such as human-computer interaction, neuropsychology, and cognitive science. These trajectories exhibit complex temporal dynamics and spectral properties due to rapid and subtle eye moments, making them challenging to model accurately. In this study, we conducted a comprehensive evaluation of various GAN architectures, specifically CNN-CNN, LSTM-CNN, CNN-LSTM, and LSTM-LSTM, augmented with spectral loss ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_{\text {final}}$$\end{document} ), and compared their performance with Markov Model. Our findings indicate that the LSTM-CNN GAN architecture, when trained with spectral loss, significantly outperforms the Markov model in capturing the complex temporal and distributional characteristics of eye gaze velocity data. The LSTM-CNN model trained achieved the lowest Jensen-Shannon divergence ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS} = 0.00032$$\end{document} ), indicating an exceptional alignment with the real data distribution. This superior performance can be attributed to the architectural synergy where LSTM layers in the generator effectively model long-term temporal dependencies, and CNN layers in the discriminator capture local spatial patterns. The incorporation of spectral loss emphasizes the frequency components of the data, ensuring that both high-frequency and low-frequency elements are accurately modeled. The spectral loss not only improved the fidelity of the generated data but also contributed to a more stable and efficient training process. This is evidenced by the reduced integral volume in the three-dimensional evaluation space (Fig. 5), indicating consistent performance across multiple evaluation metrics.
GAN-based models have shown significant improvements in trajectory modeling across domains. Roy et al.^46^ applied GANs to foraging trajectories, where their CNN-CNN GAN achieved a spectral error of 0.08 for Peruvian seabirds and 0.07 for Brazilian seabirds, significantly outperforming HMMs (0.91 and 0.88). Similarly, SP-EyeGAN^61^ demonstrated superior performance in synthetic eye-tracking data generation, achieving JSD = 0.029 for velocity distributions and 0.214 for saccade amplitude, surpassing statistical models and VAEs. Our findings align with these results, showing that GANs with spectral loss outperform HMMs in capturing temporal structures of eye-gaze trajectories.
However, key distinctions exist between these studies. Roy et al.^46^ focused on spatial trajectory coverage, while SP-EyeGAN^61^ explicitly modeled fixations and saccades using contrastive learning. In contrast, our approach focuses solely on velocity distributions, without explicit segmentation of gaze events. Consequently, none of these models fully capture instantaneous direction changes or spatial gaze distribution, which are critical for dynamic scene perception. Addressing these limitations, future research should explore hybrid GAN-HMM models to improve gaze event segmentation and incorporate task-specific constraints for enhanced applicability in cognitive and human-computer interaction research.
While HMMs are adept at modeling sequences with clear state transitions, they are limited in capturing the intricate, non-linear temporal dynamics inherent in eye gaze trajectories. The statistical discrepancies observed–such as the significant deviation in mean and standard deviation (Table 2)–underscore the HMM’s limitations in replicating the nuanced patterns of eye movement data. Lencastre et al.^41^ reported that conventional GANs often struggle with capturing rare events and maintaining time continuity, leading to inadequate modeling of the distribution tails and temporal dependencies. Their study found Markov models to outperform GANs in replicating statistical moments and cross-feature relationships. However, our findings demonstrate that when enhanced with spectral regularization and an appropriate architecture design, GANs–specifically the LSTM-CNN model–can surpass the performance of the Markov model, effectively capturing both the global distribution and the temporal autocorrelation structures of eye gaze data.
Additionally, Quantum GANs (QGANs) have been explored for synthetic data generation^62^. Despite their theoretical advantages, QGANs exhibit a higher \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_{JS}$$\end{document} compared to classical GANs, indicating limitations in modeling real-world distributions, likely due to the early-stage development of quantum computing for practical applications. The superior performance of the LSTM-CNN GAN with spectral loss in our study highlights three key insights:
- Architectural synergy: The combination of LSTM layers in the generator with CNN layers in the discriminator leverages the strengths of both architectures, enabling the model to capture long-term dependencies and local features effectively.
- Spectral loss: Incorporating spectral loss helps the GAN focus on the frequency domain characteristics of the data, ensuring that both high-frequency and low-frequency components are accurately modeled. This is particularly important for eye gaze data, which exhibits complex spectral properties due to rapid and subtle movements.
- Computational efficiency: Despite the increased complexity, the LSTM-CNN GAN maintains computational efficiency, balancing training overhead with performance gains. This makes it a practical choice for applications requiring real-time or near-real-time data generation.
Conclusion
Our study demonstrates the potential of spectrally regularized LSTM-CNN GANs in generating high-fidelity synthetic eye gaze velocity trajectories. By effectively capturing the intricate temporal and spectral characteristics of real eye gaze data, the LSTM-CNN GAN outperforms the HMMs. It addresses some of the limitations identified in previous studies involving GANs and QGANs. These findings have significant implications for the development of simulation environments, training systems, and eye-tracking technologies that rely on realistic synthetic data. The results contribute to the broader goal of enhancing human-computer interaction by providing models that simulate naturalistic eye movement behaviors. As GAN architectures and training methodologies continue to evolve, their application in modeling complex biological signals holds promise for research and practical implementations across various domains.
Supplementary Information
Supplementary Information.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Pu, Y. et al. Variational autoencoder for deep learning of images, labels and captions. In Proceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, 2360–2368 (Curran Associates Inc., Red Hook, NY, USA, 2016).
- 2Goodfellow, I. J. et al. Generative adversarial networks (2014). ar Xiv:1406.2661.
- 3Gonog, L. & Zhou, Y. A review: Generative adversarial networks. In 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), 505–510, 10.1109/ICIEA.2019.8833686 (IEEE, Chaina, 2019).
- 4Brock, A., Donahue, J. & Simonyan, K. Large scale gan training for high fidelity natural image synthesis (2019). ar Xiv:1809.11096.
- 5Goodfellow, I. et al. Generative adversarial nets. In Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N. & Weinberger, K. (eds.) Advances in Neural Information Processing Systems, vol. 27 (Curran Associates, Inc., Cambridge, MA, 2014).
- 6Arjovsky, M., Chintala, S. & Bottou, L. Wasserstein gan (2017). ar Xiv:1701.07875.
- 7Lee, S. P., Badler, J. B. & Badler, N. I. Eyes alive. In Proceedings of the 29th Annual Conference on Computer Graphics and Interactive Techniques, 637–644 (2002).
- 8Duchowski, A. T. & Jörg, S. Modeling physiologically plausible eye rotations. In Proceedings of Computer Graphics International (2015).