A Mallows-like criterion for anomaly detection with random forest implementation
GaoXiang Zhao, Lu Wang, Xiaoqiang Wang, Jie Zhang, Jie Zhang, Jie Zhang

TL;DR
This paper introduces a new method for detecting anomalies by improving random forest algorithms with a Mallows-like model averaging technique.
Contribution
The novel contribution is a Mallows-like criterion using focal loss for model averaging in anomaly detection.
Findings
The proposed method outperforms classical anomaly detection algorithms on benchmark datasets.
It surpasses conventional model averaging techniques in accuracy and robustness.
The approach effectively handles data imbalance challenges.
Abstract
Anomaly detection plays a crucial role in fields such as information security and industrial production. It relies on the identification of rare instances that deviate significantly from expected patterns. Reliance on a single model can introduce uncertainty, as it may not adequately capture the complexity and variability inherent in real-world datasets. Under the framework of model averaging, this paper proposes a criterion for the selection of weights in the aggregation of multiple models, employing a focal loss function with Mallows’ form to assign weights to the base models. This strategy is integrated into a random forest algorithm by replacing the conventional voting method. Empirical evaluations conducted on multiple benchmark datasets demonstrate that the proposed method outperforms classical anomaly detection algorithms while surpassing conventional model averaging techniques…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
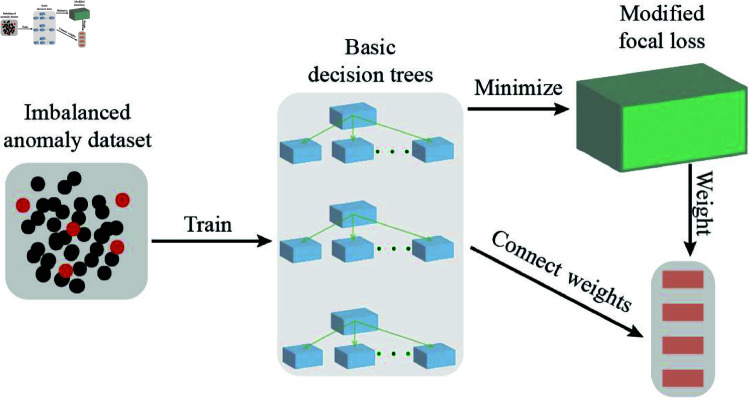 Fig 1
Fig 1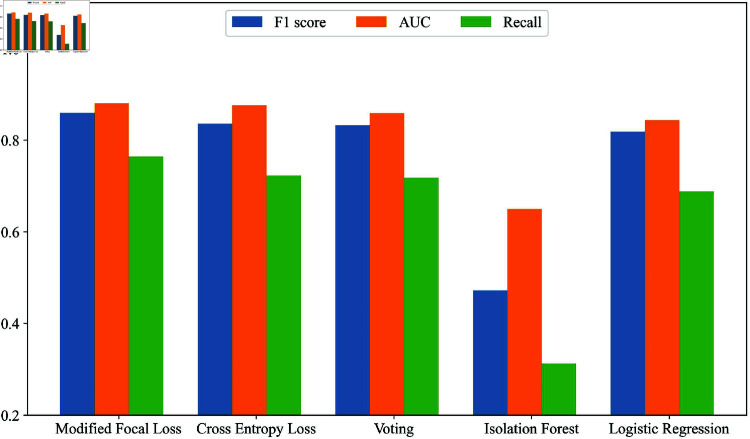 Fig 2
Fig 2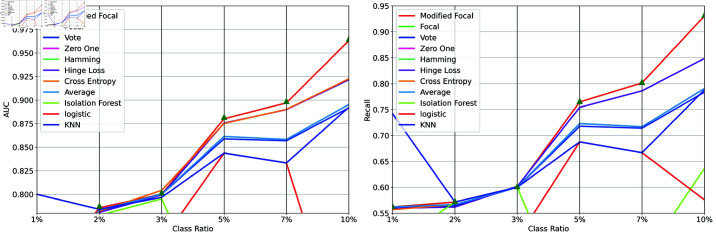 Fig 3
Fig 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAnomaly Detection Techniques and Applications · Time Series Analysis and Forecasting · Network Security and Intrusion Detection
1 Introduction
Anomaly Detection (AD) [1–3] aims to identify anomalies from observed data. Its applications include financial analysis [4], cybersecurity [5], and paramedical care [6]. Traditional anomaly detection methods, such as Isolation Forest (IF), the Local Outlier Factor (LOF), and Gaussian Mixture Models (GMMs), often assume that anomalies are outliers or low-probability points, and they distinguish anomalies by attributes based on statistical properties and distance density [7].
These assumptions can be subject to two types of limitations. First, the inherent uncertainty associated with any single model can cause fitting issues. Second, detection is confined to a singular type of anomaly, which can be inefficient, especially when the true anomaly type differs significantly from that of the method.
Ensemble methods can account for different types of data and models, but conventional vote or mean approaches may prove inefficient for extremely imbalanced data. Model average methods [8–10] have been confirmed to improve overall prediction performance by combining the prediction results of multiple base models. Such methods are based on a minimum loss function [11, 12], and some are Bayesian [13]. Focal loss variational autoencoders have been combined with the XGBoost method, and this combination has achieved promising results when applied to imbalanced network traffic datasets. Other work has focused on feature selection methods for intrusion detection, as well as deep learning approaches and lightweight designs tailored for intrusion detection systems. Some researchers have intensively investigated model averaging methods for high-dimensional regression problems by removing weight constraints or handle the problem in the presence of responses missing at random, while others have investigated the improvement of Bayesian model averaging methods, such as combining a Bayesian model with the selection of regressors, to enhance interpretability and efficiency of Bayesian model averaging estimation. Some researchers have also explored the application of model averaging in the field of deep learning and proposed an efficient protocol for decentralized training of deep neural networks from distributed data sources, which has achieved good results in several deep learning tasks. In the model averaging method based on minimizing the loss function, the loss function is usually selected by choosing the logarithmic loss function, the squared loss function, and the cross-entropy loss function. [14–17]. The focal loss function [18] addresses class imbalance, particularly in object detection and image segmentation. It can assign different weights to samples or classes, but its application to model averaging, specifically in assigning weights to base models, has not been explored. Model averaging using Mallows’ criterion is known for its asymptotic optimality in linear regression problems and has been extended to some machine learning models, such as the random forest. However, model averaging has primarily focused on regression problems, with the goal of predicting continuous outcomes. While this has improved prediction accuracy and stability in regression tasks, it has seen little application to classification problems. This is problematic for datasets that show significant class imbalance. We aim to extend model averaging methods to better meet these challenges. Specifically, we adapt the Mallows criterion by substituting the conventional cross-entropy loss function with a focal loss function. This enables our ensemble of submodels to learn more effectively from minority classes without compromising performance on majority classes.
We propose optimizing the weights in model averaging by integrating a focal loss function into the Mallows criterion. Specifically, within a random forest framework, we introduce a complexity penalty term to the focal loss function, akin to Mallows averaging [19], and determine the weights for sub-decision trees by minimizing a Mallows-like criterion. This approach enhances performance on highly imbalanced datasets through the use of the focal loss function, which improves anomaly detection accuracy. It also controls model complexity and boosts generalization by incorporating a regularization term into the loss function and leverages model averaging to amalgamate the strengths and performance of various base models, assigning them distinct weights. Consequently, this method facilitates the development of a more precise anomaly detection model.
The proposed Mallows-like focal loss approach is compared with anomaly detection methods based on minimizing other loss functions, as well as commonly employed anomaly detection methodologies. The proposed methodology is evaluated using the AUC to assess binary classification performance, ARI to assess clustering algorithm performance, and the recall metric to assess the percentage of outliers that are detected. Evaluated on the KDDCup network intrusion dataset, the proposed approach shows a improvement in the F1-score over the suboptimal model averaging method based on minimizing the cross-entropy loss function and a improvement of the recall metric. Our approach also shows superior performance to several common anomaly detection methods. Public benchmark datasets were also employed, with results indicating improved accuracy and stability in anomaly detection and extremely imbalanced data classification.
The main contributions of this paper are summarized as follows:
We propose a Mallows-like averaging criterion to optimize the weights in the aggregation of multiple models; in particular, the focal loss function is instrumental in enhancing the performance of anomaly detection;Utilizing Mallows-like focal loss (MFL), we introduce a variant of the random forest algorithm, tailored for anomaly detection, within the framework of model averaging for optimal weight selection.
2 Proposed method
We consider anomaly detection as a binary supervised classification problem. We summarize the training sample as a set, , where is a vector of predictors of dimension p; the response variable Yi = 1, , indicates that the i-th sample is abnormal, and otherwise its value is zero. The relationships between all variables can be formulated as
where is unspecified, or even nonparametric. We suppose that all the residual errors are independent and homogeneous, with
Notice that in Model (1), the p predictors can be randomly selected, thereby generating diverse models. Model averaging involves the weighted ensemble of models corresponding to each variable selection, i.e.,
followed by the minimization of a penalized loss function to optimize the selection of optimal weights within the unit simplex,
The focal loss is initially designed to address the object detection scenario for extremely imbalanced data, adding a modulating factor to the standard cross-entropy criterion,
where is the estimated probability for the class with label Y = 1. Incorporating focal loss into the ensemble method, we propose a Mallows-like criterion to determine the optimal weights. This Mallows-like criterion is achieved through a random forest algorithm. Fig 1 shows the framework of the proposed method, which is a model averaging structure based on minimizing the MFL criterion.
Schematic diagram of proposed model averaging method.This minimizes the MFL criterion to allocate weights to base decision trees, mitigating the effects of data imbalance while controlling model complexity.
2.1 Mallows-like focal loss criterion
Hansen first investigated the Mallows criterion in least squares model averaging, selecting the weight vector as
where is an unknown parameter to estimate, and Pm is the projection matrix in linear regression for the m-th model. The term is defined as the effective number of parameters, i.e., the weighted average of the number of predictors in each submodel. The optimized function has two terms, the first measuring the fitting error of the weighted model, and the second penalizing model complexity.
By substituting the first term in the Mallows criterion with focal loss (4), we realize a criterion for anomaly detection,
where km is the number of predictors in the m-th base model. Depending on the implemented algorithm, can be relaxed to a function of the number of predictors in each base model.
Considering the random forest method and Least Squares Support Vector Classification (LSSVC), in the random forest, km is the number of internal nodes within the m-th trained decision tree, and in LSSVC, it measures the magnitude of support vector weights. For the m-th classifier, km takes the form
where the matrix H represents the two-dimensional mapping of support vectors relative to the entire sample set via the kernel trick, and indicates the strength of regularization.
Note that the unknown parameter in (6) represents the variance of the model in the Mallows criterion, which is replaced by in practice.
2.2 Random forest with MFL criterion
The random forest is a popular classification method due to its flexibility and accuracy, where the voting mechanism is frequently utilized for data classification. By contrast, the first term in the MFL criterion (6) measures the fitting error of the weighted random forest in the training sample. The second term in (6) penalizes the complexity of trees in the forest, where is the weighted number of leaf nodes of all trees.
Utilizing the MFL criterion (6), we realize this algorithm as follows. We establish M decision trees, , and apply the Mallows-like criterion to optimize the weight, which is denoted by . The weighted base models are linearly combined to form the overall model. Algorithm 1 shows the steps of the model averaging method.
Algorithm 1. Random forest with Mallows-like focal loss criterion.
There are two hyperparameters, α, γ, in focal loss function (4), and there are M subtrees in the random forest algorithm. We adopt Bayesian hyperparameter estimation methods [20] to expedite training and optimize the results. As the focal loss function represents a nonlinear constrained optimization problem, we employ sequential least squares [21] to optimize the modified focal loss function, thereby controlling complexity and computational costs.
3 Experiments
3.1 Main result
Anomaly detection typically addresses the issue of severe imbalance, where there is often no clear definition regarding the proportions of positive and negative samples. To expedite training and improve the positive-to-negative sample ratio for validating model effectiveness in anomaly detection, we employed simple random sampling for the minority class while controlling the ratio of positive to negative samples to be 0.05.
We first consider the publicly available KDDCup network intrusion dataset, which is used in the field of anomaly detection, whose 125, 870 records each have 41 features. We proportionally extracted 1, 089 records, where anomalies accounted for . Bayesian hyperparameter optimization was employed. We used this strategy with maximizing the AUC metric as the objective and sampled a subset of the data with a fixed size for each experimental run. Hyperparameters , , and w were tuned within the respective ranges of (1, 3), (0.5, 1), and (0.01, 0.05). Subsequently, in the MFL method, , , and w were set to 2.22, 0.61, and 0.049, through Bayesian hyperparameter optimization. To validate the effectiveness of the proposed method on the random forest, we compared it with ensemble methods such as voting, model averaging based on minimizing cross-entropy loss, and commonly used methods such as isolation forest and logistic regression. The dataset was divided into training and test sets in a 70:30 ratio, and the model was trained 60 times. The proposed method was evaluated using the AUC, F1-score, and recall.
Fig 2 illustrates the performance of the model averaging anomaly detection method based on minimizing the MFL criterion on the test set, with average AUC, recall, and F1-score values of 0.8801, 0.7646, and 0.8598, respectively. On the network intrusion dataset, our proposed method achieved the best performance among the tested methods in all metrics, with respective improvements of , , and over the second-best values of AUC, recall, and F1-score, respectively.
Results of different models.Model averaging methods show no significant differences in AUC. Mallows-like method performs well on F1-score and recall, indicating effective detection of outliers.
To further validate the method’s effectiveness in anomaly detection, we selected nine imbalanced datasets from UCI, spanning various domains such as medicine, industrial production, agricultural production, and image classification, and utilized all their features. Simple random sampling was applied to control the ratio of positive to negative samples at 0.05. The datasets were split into training and test sets at a 70:30 ratio. We compared model averaging criteria that minimize different loss functions, along with commonly used outlier detection algorithms such as GMM, Density-Based Spatial Clustering of Applications with Noise (DBSCAN), and LOF [22, 23]. The proposed method was evaluated based on AUC, F1-score, and recall. We performed Bayesian hyperparameter tuning. Table 1 presents the results of hyperparameter optimization for the primary outcomes of the model.
Table 1: Hyperparameters of different datasets.
Table 2 compares the AUC values of the proposed MFL method and other anomaly detection algorithms. Our model achieves up to an 18.31% improvement over the second-best model across different datasets, and a 9.50% improvement in the mean across nine datasets, which demonstrates its strong data fitting capability. Note that some methods have lost their capacity to effectively distinguish between classes due to the limitations of the methods employed and the severe imbalance in the data. Model averaging methods that use default parameter settings tend to achieve similar fitting performance, highlighting the importance of Bayesian hyperparameter tuning to enhance model performance. Table 3 compares the recall of the MFL method and other anomaly detection algorithms. Recall is the proportion of detected anomalies out of the total number of actual anomalies and hence is crucial in anomaly detection. Compared with commonly used model averaging methods and conventional anomaly detection techniques, our method achieves a 29.17% improvement in the mean recall and demonstrates a clear advantage in most scenarios.
Table 2: AUC scores of anomaly detection algorithms.
Table 3: Recall scores of anomaly detection algorithms.
Table 4 presents the F1-score value of our proposed method and the comparison models, which serves as a balanced measure of precision and recall. Our approach demonstrates superior performance across most scenarios, highlighting its robust predictive capability with imbalanced datasets.
Table 4: F1-scores of anomaly detection algorithms.
In the above experiments, we employed simple random sampling to control the positive-to-negative ratio at 1:20. To further demonstrate the applicability of our method and its ability with extremely imbalanced data classification, we conducted experiments on the impact of the positive-to-negative ratio using a network intrusion dataset. Several points were selected, with positive-to-negative ratios ranging from 1:10 to 1:100. The evaluation was based on AUC and recall.
We first analyzed the impact of the positive-to-negative ratio on AUC and recall. Fig 3 shows the results of experiments conducted with ratios of 0.01, 0.02, 0.03, 0.05, 0.07, and 0.10. Model averaging methods generally outperform individual anomaly detection models. When the ratio is between 0.05 and 0.10, our proposed method shows a significant advantage in AUC and recall. For ratios of 0.02 and 0.03, all model averaging methods perform approximately the same. We speculate that the performance advantage is due to the tree structure of the base models. As the ratio further decreases, logistic regression fails to effectively distinguish between classes. Overall, our proposed method performs well under highly imbalanced conditions.
Impact of class imbalance.A: AUC; B: recall. Mallows-like loss function demonstrates superior predictive performance across multiple scenarios, indicating significant advantages of model averaging methods based on this loss function.
3.2 Synthetic data experiment
In this experiment, we employed a data sampling method to control the proportion of sample points. However, such an approach may lead to distribution shifts in the data, thereby reducing the reliability of results. To address this issue, we utilized Adaptive Synthetic Sampling [24] to regenerate data points from the sampled data. Using the classic Spambase dataset as an example, the primary performance metrics of various models based on both original and augmented data are summarized in Table 5.
Table 5: Experimental results after data augmentation using ADASYN.
Through the application of the ADASYN method, it is observed that the performance of most models has been enhanced. This indicates that ADASYN effectively synthesizes valuable data points, thus improving model performance. It is worth noting that, despite a reduction in the margin by which our model leads, it still achieves the best performance among the tested methods, which suggests that the improvements in our approach stem from innovations in the model architecture rather than shifts in data distribution and also that our method can robustly handle such distributional shifts.
4 Conclusion and future work
We proposed a Mallows-like model averaging criterion for anomaly detection based on the focal loss function. This criterion was implemented in a random forest algorithm to address the occurrence of extremely imbalanced data. We compared our method with other ensemble models, as well as commonly used anomaly detection methods, on public benchmark datasets. The results indicated the superior performance of our method in terms of anomaly recall and classification accuracy.
In the future, a Mallows-like focal loss criterion in heteroscedasticity could be investigated, possibly replacing the variance term in the Mallows criterion with the residuals for each sample. The performance of the proposed approach is constrained by the selection of hyperparameters in focal loss. A possible future research direction involves the design of efficient hyperparameter tuning methods tailored for anomaly detection algorithms and theoretical support for classification asymptotic optimality.
5 Supporting information
S1 TableHyperparameters of different datasets(PDF)
S2 TableAUC scores of anomaly detection algorithms.(PDF)
S3 TableRecall scores of anomaly detection algorithms.(PDF)
S4 TableF1-scores of anomaly detection algorithms.(PDF)
S5 TableExperimental results after data augmentation using ADASYN.(PDF)
S1 FigSchematic diagram of proposed model averaging method.(TIF)
S2 FigResults of different models.(TIF)
S3 FigImpact of class imbalance.(TIF)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Feroze A, Daud A, Amjad T, Hayat MK. Group anomaly detection: Past notions, present insights, and future prospects. SN Comput Sci. 2021;2(3). doi: 10.1007/s 42979-021-00603-x · doi ↗
- 2Fernandes G Jr, Rodrigues JJPC, Carvalho LF, Al-Muhtadi JF, Proença ML Jr. A comprehensive survey on network anomaly detection. Telecommun Syst. 2018;70(3):447–89. doi: 10.1007/s 11235-018-0475-8 · doi ↗
- 3Thudumu S, Branch P, Jin J, Singh J. A comprehensive survey of anomaly detection techniques for high dimensional big data. J Big Data. 2020;7(1). doi: 10.1186/s 40537-020-00320-x · doi ↗
- 4Hilal W, Gadsden SA, Yawney J. Financial fraud: A review of anomaly detection techniques and recent advances. Expert Syst Applic. 2022;193:116429. doi: 10.1016/j.eswa.2021.116429 · doi ↗
- 5Tuor A, Kaplan S, Hutchinson B, Nichols N, Robinson S. Deep learning for unsupervised insider threat detection in structured cybersecurity data streams. In: Workshops at the 31st AAAI conference on artificial intelligence; 2017.
- 6Xiang T, Zhang Y, Lu Y, Yuille AL, Zhang C, Cai W, et al. SQUID: Deep feature in-painting for unsupervised anomaly detection. In: 2023 IEEE/CVF conference on computer vision and pattern recognition (CVPR). IEEE; 2023. p. 23890–901. doi: 10.1109/cvpr 52729.2023.02288 · doi ↗
- 7Suri N, Murty M, Athithan G. Outlier detection: Techniques and applications. Springer Nature; 2019. p. 3–11.
- 8Mallows CL. Some comments on Cp. Technometrics. 2000;42(1):87–94.