EML-SlowFast: A behavior recognition model for lion-head goose
Jinwei Wang, Zhiguo Du, Bin Wen, Zhihui Wu, Xudong Lin

TL;DR
This paper introduces EML-SlowFast, a new model for accurately recognizing the behaviors of lion-head geese, which helps improve their health and productivity in farming.
Contribution
The novel EML-SlowFast model improves behavior recognition accuracy and reduces computational complexity for lion-head geese.
Findings
EML-SlowFast achieved 92.06% average F1 score for recognizing five lion-head goose behaviors.
The model reduced computational complexity by 7.358 G FLOPs compared to the SlowFast model.
EML-SlowFast outperformed existing models in behavior recognition accuracy and efficiency.
Abstract
The behavior of lion-head goose has a significant impact on their health status, activity levels, and productivity. It is therefore important to monitor the behavior of lion-head geese to enhance their health status, reproductive performance, and overall productivity. However, there is currently no specific behavioral recognition method for lion-head goose, which presents a significant challenge in quickly and effectively identifying various behaviors. To address this issue, this study proposes a model called EML-SlowFast, which is an improvement based on SlowFast. The model is capable of distinguishing five basic behaviors of lion-head goose: feeding, resting, preening, standing, and walking. The Efficient Channel Attention Bottleneck (ECAbneck) module and the Large Kernel Global-Local Feature Extraction (LGLE) module are designed and incorporated into the model. By combining and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1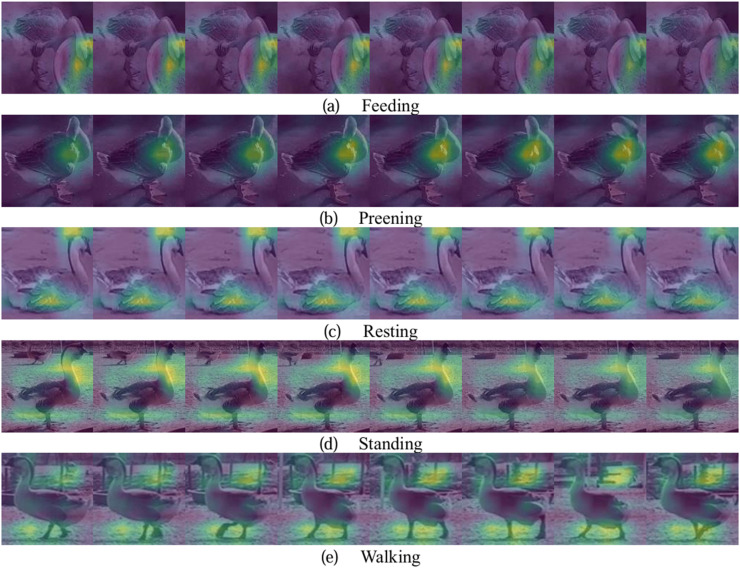 Figure 2
Figure 2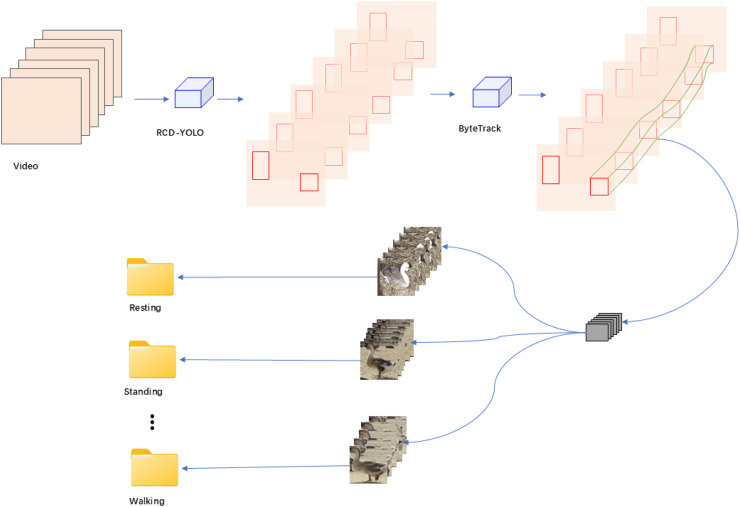 Figure 3
Figure 3 Figure 4
Figure 4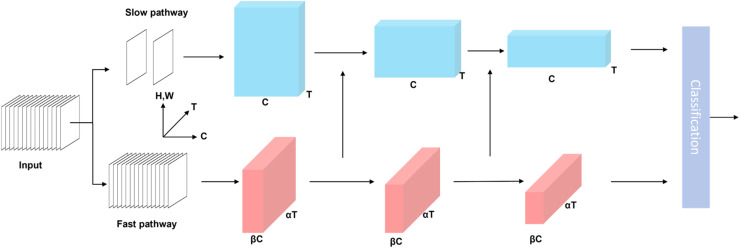 Figure 5
Figure 5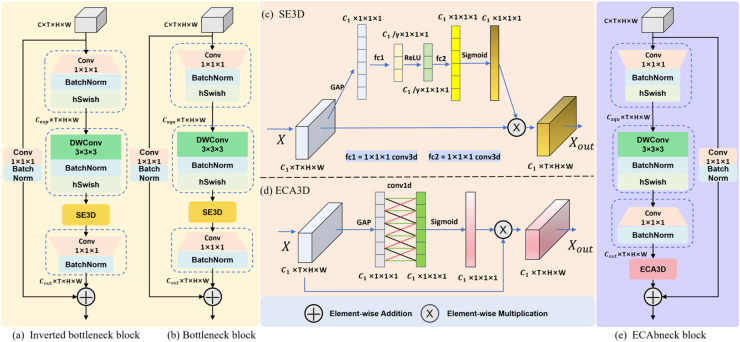 Figure 6
Figure 6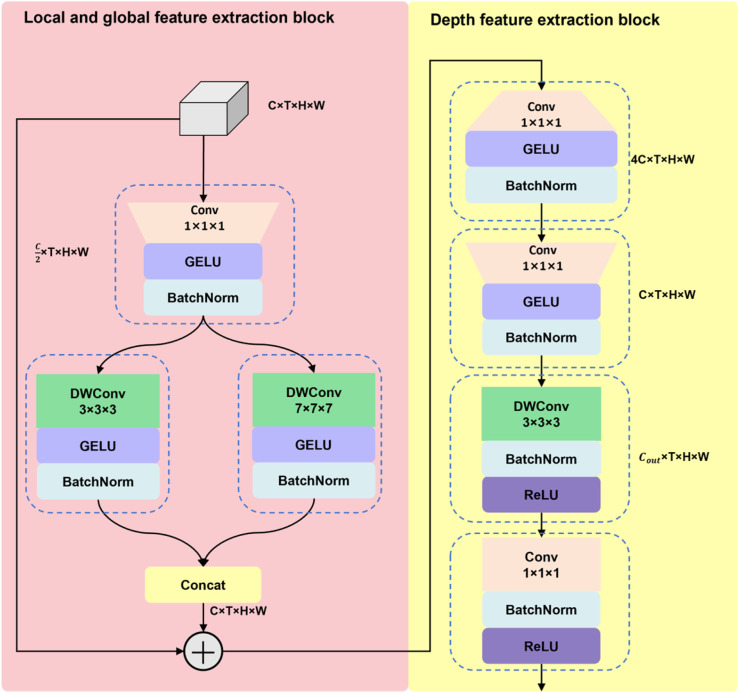 Figure 7
Figure 7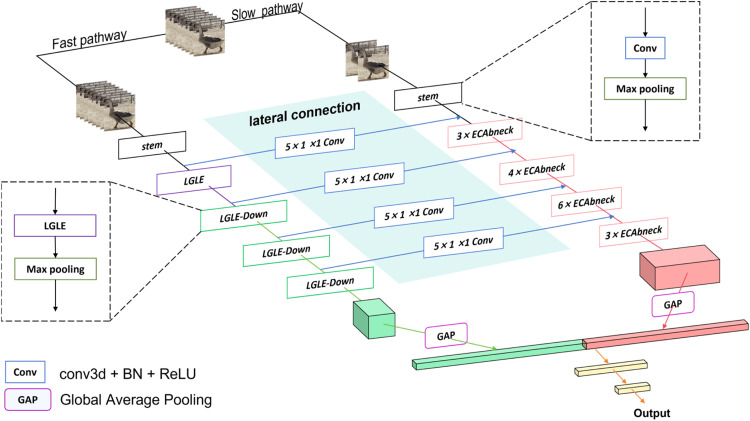 Figure 8
Figure 8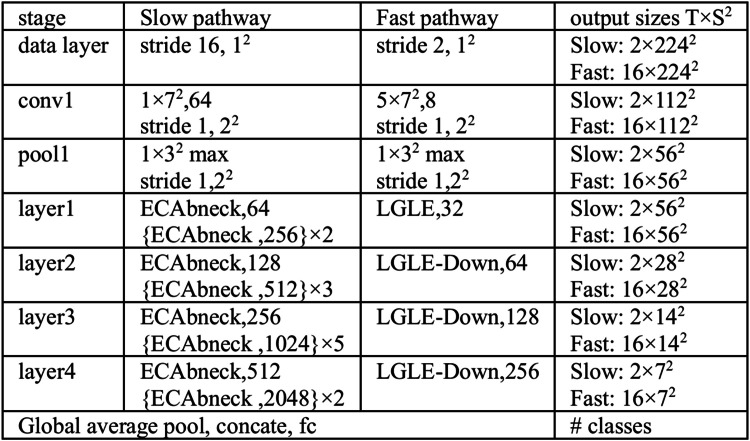 Figure 9
Figure 9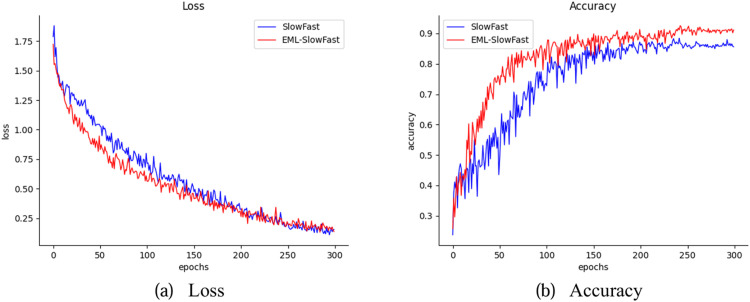 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBat Biology and Ecology Studies · Animal Vocal Communication and Behavior · Species Distribution and Climate Change
Introduction
One of the biggest meat goose breeds worldwide, the Lion-head Goose is a germplasm resource that is specifically protected at the national level. It comes from Raoping in Chaozhou, Guangdong Province (Chen et al., 2011). It is characterized by its big size, great roughage tolerance, rapid growth rate, robust resilience to stress, and high-quality meat, which brings good economic benefits to breeders and traders (Lin et al., 2019a). In 2021, the lion-head goose industry chain generated a value of over 3.5 billion yuan, becoming a model for the goose industry in China. By May 2022, the annual production of lion-head geese in Shantou City reached about 8.1 million, with a stable breeding population of about 3 million (Luo et al., 2024). Although the industrialization of lion-head goose farming shows a rapid development trend, the application of the intensive farming model and new technologies such as "pen spraying" has also brought about challenges in disease control. At the current stage, although diseases can be prevented and controlled using antibiotics and vaccines, lion-head geese's health and productivity are negatively impacted by the irrational use of antibiotics and the limitations of vaccine specificity. (Liu et al., 2021). Lion-head geese are not weak in disease resistance, but due to problems such as weak investment capacity of farmers and poor rearing conditions, this leads to difficulties in epidemic prevention and control, and prominent biosafety issues (Luo et al., 2024).
The behavior of animals can typically serve as an indicator of their overall health and well-being, whether directly or indirectly (Qi et al., 2009). When animals are afflicted with disease, experience discomfort, or undergo physiological phases, they display distinctive behavioral traits (Lin et al., 2022b). Consequently, the monitoring of animal behavior can facilitate the early detection and prevention of animal diseases (Martiskainen et al., 2009; Barwick et al., 2018). The initial approach to monitoring animal behavior was based on manual observation. However, this approach was not only susceptible to subjective interpretation errors but also proved laborious and inefficient, rendering it unsuitable for the requirements of large-scale breeding. From the perspectives of profitability and animal welfare, a well-designed automatic monitoring and recognition classification system can effectively replace manual monitoring of animal behaviors (Stott et al., 2005). The implementation of Internet of Things (IoT)-based monitoring systems enables automated behavioral monitoring in animals via sensors or wearable devices (Adrion et al., 2018; Jin et al., 2024). However, such a contact-based method may cause issues such as animal stress and the potential for the devices to fall off or become damaged. The integration of computer vision with deep learning for the monitoring and analysis of animal behaviors has drawn a lot of academic interest due to the quick development of both fields. Computer vision-based methods for monitoring animal behavior offer several advantages, including non-contact, stress-free, and high-efficiency characteristics, which have led to their gradual replacement of wearable sensors in precision livestock farming (Su et al., 2022) and play an important role in the assessment of animal behaviors (Nasirahmadi et al., 2019).
Some scholars have implemented improved strategies including data augmentation, attention mechanisms, improved loss function, and improved feature fusion based on You Only Look Once (YOLO) object detection models to recognize poultry behaviors in single-frame images (Yang et al., 2024; Liu et al., 2023; Gu et al., 2022; Wang et al., 2024a; Xiao et al., 2023). However, single-frame-based methods for poultry behavior recognition can only extract spatial features from static images, which overlook the continuity and temporal characteristics of behavior (i.e., motion information). The analysis of poultry behavior is dependent on the recognition of a series of continuous activities. The temporal information between consecutive frames is of particular importance in determining the category of behavior, particularly when differentiating between activities and non-activities such as walking and standing. However, defining or classifying these features based solely on static images may present challenges. Therefore, the integration of spatial-temporal features becomes essential to achieve accurate recognition of poultry behaviors.
To effectively utilize the temporal features of poultry behaviors, some scholars have adopted temporal sequence modeling approaches based on skeletal keypoints. Feature learning models are employed to extract poultry skeletal keypoints from continuous single-frame images, followed by sequential modeling using models like Long Short-Term Memory (LSTM) to learn the temporal dependencies between keypoints across different poses (Fang et al., 2021; Nasiri et al., 2022; Volkmann et al., 2022). However, this methodology requires precise body and limb annotations for keypoint localization, incurring substantial data labeling costs.
Video understanding models demonstrate the capability to extract both the spatial and temporal features from videos simultaneously. Hu et al. (2024) proposed an end-to-end method called the Broiler Behavioral Recognition System (BBRS), which integrates an improved YOLOv8s detector, a ByteTrack tracker, and a 3D-ResNet50-TSAM model. The 3D-ResNet50-TSAM model is capable of simultaneously extracting spatial and temporal features of broiler behaviors from videos. The BBRS identifies five basic daily behaviors of broilers in videos with an overall accuracy of 93.98 %. Lin et al. (2022a) proposed a dual feature-rates deep fusion convolutional neural network (DF2-Net) incorporating a transposed non-local module for video-based bird behavior recognition. Through multi-rate feature integration and spatiotemporal relationship modeling, DF2-Net achieves an overall accuracy of 81.35 % in identifying eight avian behaviors (fighting, perching, feeding, swimming, flying, walking, standing, and eating).
In summary, research on computer vision-based poultry behavior recognition has achieved notable progress. Nevertheless, the methods employed for the recognition of lion-head goose behavior are still in their infancy. To bridge this gap, this study proposes EML-SlowFast model, which is based on the improved SlowFast, for recognizing the behavior of lion-head goose in videos. By integrating ECAbneck module and LGLE module into SlowFast, the EML-SlowFast model enables robust identification of five behaviors of the lion-head goose: feeding, resting, preening, standing, and walking.
Materials and methods
Materials
Data acquisition The videos of lion-head geese were collected at two lion-head geese farms in Raoping, Chaozhou, Guangdong Province. The videos were collected from March 18, 2024, to July 12, 2024, at various times of the day, including mornings, afternoons, and evenings. The collection equipment consisted of multiple EZVIZ CS-C8b surveillance cameras. The videos were stored in MP4 format, and the camera resolution was 2304 × 1296 pixels with a frame rate of 15 FPS. The videos were collected from multiple different actual farming environments, as shown in Figure 1, enhancing the diversity of the data. The filming scenes included shelters and outdoor activity environments. In the shelter scenes, cameras were placed at the edges of the pens to ensure that the cameras could capture the lion-head geese's activity ranges as comprehensively as possible. The height varied according to the size of different pens. In outdoor activity scenes, cameras were placed in areas where the lion-head geese were frequently active. This study selected 191 usable videos from all the videos, with video durations ranging from 5 minutes to 20 minutes. These video data included various behaviors of lion-head goose.Fig. 1. The samples of Lion-head Goose farming environments.Fig 1
Dataset construction The dataset was constructed in accordance with the format of the public dataset UCF101 (Soomro et al., 2012). The production process is shown in Figure 2. First, the video was input into the well-trained RCD-YOLO (Wang et al., 2024b) lion-head geese object detection network, which is responsible for detecting the lion-head geese objects, followed by the tracking of the lion-head geese using the ByteTrack algorithm (Zhang et al., 2022). Then, the detected lion-head geese that belonged to the same object ID in the image frame sequence were cropped and saved. This achieved the purpose of containing only one object in a single piece of data, which was beneficial for the subsequent behavior recognition model training. Next, the lion-head goose data were manually classified by behavior, and the image frame sequences corresponding to each behavior were saved as an instance of data into the folder corresponding to that behavior. The dataset contains five different behaviors, as shown in Figure 3.Fig. 2. Dataset production flowchart.Fig 2. Fig. 3Examples of lion-head goose behaviors.Fig 3
After processing, a total of 2,966 pieces of data for five behaviors—feeding, resting, preening, standing, and walking—were obtained, with each piece of data containing the image sequence of 32 to 256 frames. The data were divided into a training set, a validation set, and a test set. Due to the varying activity levels of lion-head goose behavior, the distribution of lion-head goose behavior data was unbalanced, with the most data for standing behavior and the least for resting behavior. To achieve a balanced data distribution, data augmentation methods such as horizontal flip, vertical flip, invert color, Gaussian blur, and pepper noise were used to augment the training set. The specific dataset division is shown in Table 1.Table 1. Lion-head goose behaviors dataset information.Table 1behaviorNumber of instances of dataTrainingValidationTestoriginalafter augmentationFeeding301400121135Resting2524028299Preening327407132145Standing407407181195Walking323403116150
Methods
Overall In this research, EML-SlowFast, which was constructed based on the SlowFast architecture, the Efficient Channel Attention Bottleneck (ECAbneck) module, and the Large Kernel Global-Local Feature Extraction (LGLE) module, had been designed to recognize lion-head goose behaviors efficiently. EML-SlowFast is a lightweight and accurate lion-head goose behavior recognition model that introduces the ECAbneck module and LGLE module to improve static and dynamic feature extraction from lion-head goose behaviors. The EML-SlowFast effectively extracts both temporal and spatial features by considering the spatiotemporal features of video data, resulting in promising results in recognizing lion-head goose behaviors.
SlowFast SlowFast (Feichtenhofer et al., 2019) is a 3D Convolutional Neural Network (3DCNN) for behavior recognition, with its architectural design influenced by the structural organization of the primate retina. In primates, approximately 80 % of retinal cells operate at a lower frequency for detailed spatial and color information, while the remaining 20 % operate at a higher frequency to capture motion changes. The SlowFast network comprises a Slow pathway designed to capture spatial semantics at a low frame rate, and a Fast pathway that efficiently captures rapidly evolving motion features at a high frame rate.
The structure of SlowFast is illustrated in Figure 4. For the SlowFast network, with an input sequence length of t frames, the Slow pathway samples frames with a large τ (often 16), capturing spatial details. The Fast pathway samples αT frames with (often α = 8), capturing motion details. To balance computation, the Fast pathway has β times fewer channels than the Slow pathway (β is often ). The Fast and Slow pathways employ 3D ResNet blocks (Hara et al., 2018) as their backbone for spatiotemporal feature extraction. Additionally, through lateral connections, features extracted from the Fast pathway are fused into the Slow pathway, enhancing the interaction between static and dynamic behavioral features. Ultimately, the features extracted from both pathways are merged and utilized for prediction to produce classification results.Fig. 4. The structure of SlowFast.Fig 4
Lightweight feature extraction module The backbone of the Slow pathway in SlowFast is designed to extract static features using 3D ResNet blocks, which are inefficient and computationally complex. The Inverted Bottleneck (IB) block, originating from MobileNetV3 (Howard et al., 2019), is a lightweight 2D module. In this study, the IB block has been extended to a 3D module, as illustrated in Figure 5(a). The IB block employs an inverted bottleneck structure, which first expands the number of channels for the input feature map to using a 1 × 1 × 1 convolution. This expansion allows the feature map to contain more high-dimensional information. Subsequently, a depth-wise convolution (DWConv) is applied for the purpose of feature extraction. Subsequently, a Squeeze-and-Excitation (SE) module (Hu et al., 2018) is utilized, which is a channel attention mechanism that assigns different levels of importance to channels by compressing and then expanding the channel dimension through a squeeze-excitation process. DWConv is a lightweight convolution that reduces model complexity; however, it lacks inter-channel information interaction. So, after the SE module, a 1 × 1 × 1 convolution is immediately applied, serving two purposes: firstly, to facilitate inter-channel information interaction and secondly, to adjust the number of feature map channels to the output channels ( ). Finally, a shortcut connection is employed, which is a 1 × 1 × 1 convolutional layer used to adjust the number of channels in the feature map, adding the input feature map to the output feature map.Fig. 5. Lightweight feature extraction module.Fig 5
In SlowFast, due to the large number of channels for the feature maps within the Slow pathway, expanding the channels would significantly increase the computational complexity of the model. Therefore, we modified the IB block into a Bottleneck (bneck) block by altering the inverted bottleneck structure to the bottleneck structure, as shown in Figure 5(b). The compression of the number of input channels allows for the integration of high-dimensional channel information, enabling more efficient feature extraction. We used the bneck blocks to replace the 3D ResNet blocks within the Slow pathway, effectively reducing the complexity of the model. However, the model parameters increased significantly, and experiments revealed that this was due to the SE module. To address this issue, we improved the bneck module and designed a more efficient module called Efficient Channel Attention Bottleneck (ECAbneck), whose structure is illustrated in Figure 5(e). Firstly, the SE module is replaced with the Efficient Channel Attention (ECA) module (Wang et al., 2020) to learn the channel information and enhance the discriminability of features. The ECA module is an efficient channel attention; unlike the SE module, which employs 3D convolution for squeeze-excitation operations, the ECA module solely utilizes a 1D convolution to learn the information of channel dimension, thereby significantly reducing model parameters. The ECA module obtains the aggregated features by global average pooling (GAP), followed by generating channel weights by performing a 1D convolution, and then applying the channel weights to the input feature map to obtain the channel attention. This process can be computed by Equations (1)-(2):
where X is the input feature map of the ECA module, , GAP denotes global average pooling, Conv1d is a 1D convolution, σdenotes sigmoid activation function, denotes element-wise multiplication operation.
Subsequently, the position of the channel attention module and the last 1 × 1 × 1 convolution layer within the bneck block is swapped. The rationale behind this adjustment is that the channels contain richer information and are more interconnected in the 3D feature map. After feature extraction using DWConv, immediately applying a 1 × 1 × 1 convolution layer for inter-channel information interaction can strengthen the association between channels. Following this, applying the attention module to learn channel weights allows for a more effective extraction of the channel features.
In this study, the ECAbneck modules were used to replace the 3D ResNet blocks within the Slow pathway, effectively reducing the computational complexity of the model. By employing the bottleneck structure along with the ECA module, the extraction capability of the Slow pathway for static behavioral features was augmented, which subsequently enhanced the model's accuracy in recognizing the behaviors of lion-head goose.
Large Kernel Global-Local Feature Extraction module The Fast pathway of SlowFast has fewer channels and more temporal dimensions, primarily responsible for the extraction of dynamic features. We designed the Large Kernel Global-Local Feature Extraction (LGLE) module, which is comprised of a local and global feature extraction block, along with a depth feature extraction block. The structure of the LGLE module is shown in Figure 6. The LGLE module enhances the model's long-term modeling capability and depth feature extraction capability, so that the model can better mine the semantic information of the lion-head goose's behavior and improve the model's ability to model the long-term behavioral characteristics of the lion-head goose.Fig. 6. The structure of the LGLE module.Fig 6
Local and global feature extraction block. Firstly, the input feature map is processed through a 1 × 1 × 1 convolution layer, which squeezes the number of channels for the input feature map. The channel squeezing operation not only reduces the computational load by decreasing the number of channels but also facilitates the interaction of channel information, thereby benefiting the model's extraction of behavioral semantics from the lion-head goose. Subsequently, the feature map undergoes parallel processing with a 3 × 3 × 3 DWConv layer and a 7 × 7 × 7 DWConv layer. The 3 × 3 × 3 DWConv layer is employed for extracting local features, focusing on the detailed information within the lion-head goose's behavior, whereas the 7 × 7 × 7 DWConv layer is employed for extracting global features, thereby enhancing the module's long-term modeling capability. This enables the module to capture the correlations between information across longer temporal channels, which is beneficial for the capability of the model to learn the temporality of the lion-head goose's behavior. Subsequently, the local and global feature maps are fused and then subjected to a residual connection with the input feature map, after which the result is outputted. The expression of the local and global feature extraction block is shown in Equations (3)-(6).
where F is the input feature, , Conv and DWConv denote convolutional layer and DWConv layer, respectively, and the subscript represents the size of the convolutional kernel, denotes the GeLU activation function, BN denotes the Batch Normalization layer, denotes the concat layer, and is the output feature map for the local and global feature extraction block.
Depth feature extraction block. The output of the local and global feature extraction block serves as the input feature map for the depth feature extraction block. Initially, it passes through a 1 × 1 × 1 convolutional layer to expand the number of channels by fourfold, and then the number of channels is restored through another 1 × 1 × 1 convolutional layer. The "expand-and-compress" operation augments the interaction between channels, thereby facilitating a deeper integration of features within the feature map. Subsequently, a 3 × 3 × 3 DWConv layer and a 1 × 1 × 1 convolutional layer are applied to the feature map for further feature learning. The expression of the depth feature extraction block is shown in Equations (7)-(10).
where denotes the ReLU activation function, is the output feature map of the depth feature extraction block and is also the output feature map of the LGLE module.
The local and global feature extraction block employs a 3 × 3 × 3 DWConv layer and a 7 × 7 × 7 DWConv layer to capture both local and global features, which are beneficial for long-term temporal modeling. This effectively enhances the module's capacity to model the temporality of lion-head goose behavior. The depth feature extraction block fuses the feature map in a deep manner, thereby enabling the module to more effectively learn the spatial and temporal characteristics of lion-head goose behavior. In this study, the LGLE modules, consisting of the local and global feature extraction block and the depth feature extraction block, replace the 3D ResNet blocks within the Fast pathway of SlowFast network, effectively enhancing the model's long-term modeling capability. This modification strengthens the model's proficiency in learning the spatial and temporal features of lion-head goose behavior, ultimately improving the model's performance in classifying lion-head goose behavior.
EML-SlowFast Behavior Recognition Model In this study, the EML-SlowFast behavior recognition model based on SlowFast improvement was designed for recognizing the behavior of lion-head goose. The structure of the EML-SlowFast network is shown in Figure 7. Firstly, to enhance the static behavioral feature extraction capacity of the Slow pathway, the 3D ResNet blocks within the Slow pathway of SlowFast were replaced with the ECAbneck modules. The ECAbneck module establishes dependencies between spatiotemporal information and channel features, thereby generating more discriminative feature representations through the fusion of richer information. Secondly, the innovative LGLE modules were implemented as the replacement for the 3D ResNet blocks within the Fast pathway of SlowFast. The LGLE module incorporates the principles of large kernel convolution and bottleneck structures, enabling the effective extraction of both local and global features while enhancing the model's capacity for long-term spatiotemporal modeling. This enables the model to more effectively extract information from the temporal channels, thereby enhancing its ability to extract dynamic behavioral features in the temporal dimension. Concurrently, between the Slow and Fast pathways, convolutional layers were employed as lateral connections to fuse features extracted by the Fast pathway into the Slow pathway, thus enhancing the interaction between static and dynamic behavioral features.Fig. 7. The structure of EML-SlowFast network.Fig 7
The specific network information of the EML-SlowFast is shown in Figure 8. The values of τ, α, and β have been set to 16, 8, and , respectively. The input data is a 32-frame image sequence. In the Slow pathway, data is sampled at a low rate to obtain a 2-frame image sequence, while in the Fast pathway, data is sampled at a high rate to obtain a 16-frame image sequence. In the Slow pathway, the data initially undergoes feature extraction through a 3D convolution layer with a kernel size of 1 × 7 × 7 and a stride of 1 × 2 × 2, followed by max pooling for downsampling to obtain early feature maps. Subsequently, it passes through consecutive ECAbneck modules for feature extraction, and fusion with the feature maps from lateral connections, employing 3D convolution layers with a kernel size of 5 × 1 × 1, to obtain the output feature maps of the Slow pathway. In the Fast pathway, the data initially undergoes feature extraction through a 3D convolution layer with a kernel size of 5 × 7 × 7 and a stride of 1 × 2 × 2, followed by max pooling for downsampling to obtain an early feature map. Subsequently, the feature map passes through an LGLE module and three LGLE-Down modules to obtain the output feature map of the Fast pathway. Finally, the output feature map from both the Slow and Fast pathways undergoes a global average pooling, after which the features are then fused and input into a fully connected (fc) layer for classification.Fig. 8. The instantiation of the EML-SlowFast network. The dimensions of kernels are denoted by {T × S^2^, C} for temporal, spatial, and channel sizes. Strides are denoted as {temporal stride, spatial stride^2^}.Fig 8
Experimental platform and parameters setting
The experiments in our study were conducted on a computer equipped with an Intel Xeon Platinum 8481C CPU and an NVIDIA GeForce RTX 4090D GPU, running the Ubuntu 22.04 operating system. The network environment was a virtual environment created using Anaconda3, which included Python 3.10, PyTorch 2.1.0, and CUDA 12.1. The training parameters for the experiments are presented in Table 2.Table 2. Training parameter settings.Table 2. ParametersValueSize of input image224 × 224Batch size16Epochs300OptimizerStochastic Gradient Descent (SGD)Initial learning rate0.05Momentum0.9Weight decay0.0001
Evaluation metrics
To evaluate the recognition performance of the proposed model for different behaviors of lion-head goose in this study, Accuracy, Parameters, Precision, Recall, F1 score, and Floating Point Operations per second (FLOPs) are used as the performance evaluation metrics. Specifically, Precision is defined as the ratio of correctly predicted positive cases to all predicted positive cases. Recall is defined as the ratio of correctly predicted positive cases to all positive cases. Accuracy is the average of the precision rates for all behaviors. FLOPs and Parameters are used to measure the computational and spatial complexity of the network, respectively. The F1 score combines the discriminative capabilities of Precision and Recall to assess the model's overall performance. The calculations for Precision, Recall, Accuracy, and F1 score are shown in Equations (11)–(14).
where TP, FP, FN, and TN represent the number of true positive cases, false positive cases, false negative cases, and true negative cases, respectively.
RESULTS AND DISCUSSION
The Effect of EML-SlowFast on Behavior Recognition in Lion-head Goose
Figure 9 shows the loss and accuracy curves of the training process for SlowFast and EML-SlowFast. It can be observed that the loss curve of EML-SlowFast decreases earlier, and the accuracy curve of EML-SlowFast rises more rapidly, suggesting that the EML-SlowFast model approaches a state of fitting more swiftly.Fig. 9(a) Model loss comparison, (b) Model accuracy comparison.Fig 9
To validate the effectiveness of the improvement in this study, we conducted ablation experiments using the SlowFast network with backbone 3DResNet50 as the baseline. Table 3 displays the results of these ablation experiments. Following the replacement of the 3D ResNet blocks within the Slow pathway with the bneck modules an increase of 0.96 % in Accuracy was observed, accompanied by a decrease of 9.128 G in FLOPs. However, the network's parameters increased by 46.216 M, due to redundancy in the SE module within the bneck module. Further, the replacement of the 3D ResNet blocks within the Slow pathway with the ECAbneck modules resulted in a notable reduction in the network's parameters, when compared to the "SlowFast + bneck" method. This indicates that the ECA module, compared to the SE module, eliminates a considerable amount of parameter redundancy. Nonetheless, the Accuracy of "SlowFast + ECAbneck" method decreased by 1.24 % compared to "SlowFast + bneck" method. This is since while the ECA module enhances the Slow pathway's capacity to extract static features, it does not equally augment the Fast pathway's capacity to extract dynamic features. This leads the network to overly focus on static features, reducing the emphasis on dynamic features, thus hindering its effectiveness in capturing the temporal relationships of behavior. To explore the effectiveness of the LGLE module, the 3D ResNet blocks within the Fast pathway of SlowFast were replaced with the LGLE modules. Compared to the baseline, Accuracy increased by 2.07 % and the number of parameters of the model decreased by 0.174 M. This shows that the LGLE module effectively enhances the network's long-term modeling capabilities, enabling it to effectively capture the temporal relationships of behavior. For the "SlowFast + bneck + LGLE" method, replacing the 3D ResNet blocks in both the Slow and Fast paths with bneck modules and LGLE modules, respectively, resulted in a 2.76 % increase in Accuracy and a reduction of 7.348 G FLOPs compared to the baseline. This is due to the lower FLOPs of the bneck module, and its channel attention makes the network focus on important features, thus both reducing network computational complexity and improving static feature extraction for lion-head goose behavior. The LGLE block combines and learns from both local and global features, enabling long-term modeling capability that facilitates the network's ability to capture the temporal nature of the lion-head goose's behavior, thereby strengthening the model's capacity for dynamic feature extraction. However, this method comes with a relatively high number of parameters. Further, by replacing the bneck modules with the ECAbneck modules, the model achieved a 4.14 % increase in Accuracy, reaching 91.85 %, and a reduction of 7.358 G FLOPs, compared to the baseline. Although the number of parameters increased by 5.727 M, this increase falls within an acceptable range. The above results show that the ECAbneck module and the LGLE module for the improvement of SlowFast in this study can increase the accuracy and reduce FLOPs in the model.Table 3. Contribution of different modules to the EML-SlowFast model.Table 3bneckECAbneckLGLE#Params(M)FLOPs(G)Accuracy (%)×××33.57118.16587.71**√××79.7879.03788.67×√×39.4729.02787.43××√33.39719.94589.78√×√79.61210.81790.47×√√39.29810.807****91.85**
To validate the recognition performance of EML-SlowFast, an analysis of the confusion matrices obtained from experiments conducted on the test set for both SlowFast and EML-SlowFast is presented, with the results summarized in Table 4. The results indicated that the Precision, Recall, and F1 score of EML-SlowFast are greater than those of SlowFast, except for the Recall of walking behavior. The EML-SlowFast model achieved the F1 score of 96.68 %, 90.57 %, 91.22 %, 87.94 %, and 93.92 % for the classification of feeding, resting, preening, standing, and walking behaviors, which were higher than those of SlowFast model by 2.26 %, 4.57 %, 5.7 %, 6.56 % and 1.11 %, respectively. In terms of classification performance for walking behavior, the EML-SlowFast model achieved a Precision that was 4.18 % higher than that of the SlowFast model, but its Recall was lower than that of the SlowFast model by 2 %. This may be attributed to the enhanced feature discrimination capability of the EML-SlowFast model through integration of the ECAbneck and LGLE modules. This improvement leads to stricter classification criteria, causing partially ambiguous samples (e.g., instances with occluded leg regions of the goose where only partial motion patterns are observable in walking sequences) to be misclassified as negative cases, which explains the observed 2 % Recall decrease. Nonetheless, the EML-SlowFast model still achieved an impressive F1 score of 93.92 % for walking behavior classification, demonstrating superior comprehensive performance. Furthermore, for behaviors involving subtle movements such as feeding and preening, which rely on the model's static and dynamic feature extraction capability, the EML-SlowFast model exhibits even better performance. The EML-SlowFast model only exhibits lower Recall than SlowFast in the classification of walking behavior, while its performance in other classifications surpasses SlowFast. Furthermore, the average Recall, average Precision, and average F1 score of the EML-SlowFast model were 4.45 %, 3.79 %, and 4.03 % higher than those of SlowFast, respectively. This indicates that the overall performance of the EML-SlowFast model in recognizing the behaviors of lion-head goose is superior to that of SlowFast. Thus, the validity of the proposed model in this paper is confirmed.Table 4. Confusion matrix analysis results.Table 4. BehaviorSlowFastEML-SlowFastPrecision(%)Recall(%)F1(%)Precision(%)Recall(%)F1(%)Feeding94.7894.0794.4296.3297.0496.68Resting85.1586.8786.0084.9696.9790.57Preening83.5587.5985.5289.4093.1091.22Standing84.5378.4681.3892.1384.1087.94Walking91.0394.6792.8195.2192.6793.92average87.8188.3388.0391.6092.7892.06
Comparison with other behavior recognition models
To demonstrate the effectiveness of EML-SlowFast in recognizing the behavior of lion-head goose, it was compared with other commonly used convolutional networks in the field of video behavior recognition, including TSN, I3D, R(2 + 1)D, C2D and TSM, with the results presented in Table 5 (Wang et al., 2016; Carreira and Zisserman, 2017; Tran et al., 2018; Wang et al., 2018; Lin et al., 2019b). The EML-SlowFast model had Parameters, FLOPs, and Accuracy of 39.298 M, 10.807 G, and 91.85 %, respectively. Among all the comparative models, the EML-SlowFast model had the lowest FLOPs, and its Accuracy was only 0.28 % lower than that of the TSM model. Moreover, the FLOPs of the TSM model reached 42.939 G, which was 32.132 G higher than that of the EML-SlowFast model, making its deployment challenging in scenarios with limited computational resources. Achieving 91.85 % Accuracy with 10.807 G FLOPs, the EML-SlowFast model offers the best cost-performance ratio and is suitable for deployment in low computational resource scenarios. Overall, the EML-SlowFast model exhibits the best comprehensive performance, offers the highest cost-performance ratio, and can provide efficient and stable results for lion-head goose behavior recognition.Table 5. Comparison of different behavior recognition models.Table 5network#Params(M)FLOPs(G)Accuracy (%)I3D-3DResNet5027.23621.72879.28R(2 + 1)D-3DResNet3463.55710683.70C2D-ResNet5023.5250.78879.83TSN-ResNet5023.5242.93987.43TSM-ResNet5023.5242.93992.13SlowFast-3DResNet5033.57118.16587.71EML-SlowFast(Our)39.29810.80791.85
Analyzing the regions of interest of EML-SlowFast model for lion-head goose behavior recognition
The Gradient-weighted Class Activation Mapping (Grad-CAM) technique (Selvaraju et al., 2017) was used to visualize the regions of interest of the EML-SlowFast model for different behaviors, as shown in Figure 10. The brightly colored regions highlight the areas of interest identified by the model, where the features correspond to the lion-head goose's behavior. For feeding behavior, the model focuses on the feeding trough and the lion-head goose's head. For preening behavior, the model focuses on the area where the lion-head goose preens its feathers. For resting behavior, the model focuses on the lion-head goose's body and head, where stationary body and possibly moving head contribute to identifying resting behavior. For standing behavior, the model focuses on the lion-head goose's feet and head, where stationary feet and a possibly moving head contribute to identifying standing behavior. For walking behavior, the model primarily focuses on the lion-head goose's feet and the background, where foot movement and background changes in a sequence of frames determine walking behavior. In summary, the model's regions of interest align with the characteristics of lion-head goose behaviors, confirming the EML-SlowFast model's validity in behavioral cognition.Fig. 10. The regions of interest of the EML-SlowFast model visualization results of lion-head goose behaviors.Fig 10
Conclusions
Automated recognition of lion-head goose behavior can effectively reduce human resources, achieve refined and intelligent supervision and management of breeding farms, and improve the health level of lion-head goose, enabling timely detection and isolation of abnormal individuals. However, there are currently no available methods for the recognition of lion-head goose behavior. To bridge this gap, this study proposes a model termed EML-SlowFast for the automatic and accurate recognition of five lion-head goose behaviors (feeding, resting, preening, standing, and walking) in videos. In addition, we constructed a lion-head goose behavior dataset containing 2,966 behavioral sequence samples (32 to 256 image frames per sequence) covering five fundamental lion-head goose behaviors: feeding (n = 557), resting (n = 433), preening (n = 604), standing (n = 783), and walking (n = 589). This dataset was developed for training and validating the EML-SlowFast model, while also serving as a foundational resource to facilitate future research in lion-head goose behavior analysis.
To achieve the recognition of lion-head goose behaviors, this study improved the SlowFast network and proposed EML-SlowFast model. The specific approach includes replacing the 3D ResNet blocks within the Slow pathway with the ECAbneck modules, which utilize the channel attention ECA to construct spatial-temporal information and inter-channel dependencies. By combining richer information, the ECAbneck module creates more unique feature illustrations, improving the model's ability to extract static features. Innovatively, the LGLE module had been designed and utilized to replace the 3DResNet blocks within the Fast pathway. The LGLE module integrates the concepts of large kernel convolution and bottleneck structures, effectively extracting local and global features, and strengthening the model's capacity to model long-term spatial-temporal features. This allows the model to more effectively extract features from the temporal channels, enhancing its ability to extract dynamic features. The experiment results demonstrated the improvement effects of the ECAbneck modules and the LGLE modules on the SlowFast network and the enhancement of recognition accuracy. The EML-SlowFast model achieved the average F1 score, average Precision, Accuracy, and average Recall of 92.06 %, 91.60 %, 91.85 %, and 92.78 %, respectively, reflecting improvements of 4.03 %, 3.79 %, 4.14 %, and 4.45 % over the corresponding metrics of the SlowFast model. Furthermore, the FLOPs of the EML-SlowFast model was 10.807 G, which was a reduction of 7.358 G compared to the SlowFast model. Compared to commonly used behavior recognition models, the EML-SlowFast model has effective recognition of lion-head goose behaviors while maintaining low computational complexity, which is beneficial for deployment and use in scenarios with low computational resources.
In summary, the EML-SlowFast model effectively and accurately performs the task of lion-head goose behavior recognition.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Adrion F.Kapun A.Eckert F.Holland E.M.Staiger M.Götz S.Gallmann E.Monitoring trough visits of growing-finishing pigs with UHF-RFID Comput. Electron. Agric.1442018144153
- 2Barwick J.Lamb D.Dobos R.Schneider D.Welch M.Trotter M.Predicting lameness in sheep activity using tri-axial acceleration signals Animals 812018122932470010.3390/ani 8010012 PMC 5789307 · doi ↗ · pubmed ↗
- 3Carreira J.Zisserman A.Quo vadis, action recognition? A new model and the kinetics datasetproceedings of the IEEE Conference on Computer Vision and Pattern Recognition 201762996308
- 4Chen J.Peng X.Lu J.Sun J.Qiu J.Tang X.Zhang J.Anti-season farming technology of original lion head goose (in Chinese)Guangdong Agricult. Sci.10201110010110.16768/j.issn.1004-874x.2011.10.067 · doi ↗
- 5Fang C.Zhang T.M.Zheng H.K.Huang J.D.Cuan K.X.Pose estimation and behavior classification of broiler chickens based on deep neural networks Comput. Electron. Agric.1802021105863
- 6Feichtenhofer C.Fan H.Malik J.He K.Slowfast networks for video recognition Proceedings of the IEEE/CVF international conference on computer vision 201962026211
- 7Gu Y.Wang S.Yan Y.Tang S.Zhao S.Identification and analysis of emergency behavior of cage-reared laying ducks based on Yolo V 5Agriculture 1242022485
- 8Hara K.Kataoka H.Satoh Y.Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?Proceedings of the IEEE conference on Computer Vision and Pattern Recognition 201865466555