Enhancing Substance Use Detection in Clinical Notes with Large Language Models
Fabrice Harel-Canada, Anabel Salimian, Brandon Moghanian, Sarah Clingan, Allan Nguyen, Tucker Avra, Michelle Poimboeuf, Ruby Romero, Arthur Funnell, Panayiotis Petousis, Michael Shin, Nanyun Peng, Chelsea L. Shover, David Goodman-Meza

TL;DR
This paper shows how large language models can accurately detect substance use in medical notes, improving detection for clinical use.
Contribution
The novel contribution is a fine-tuned LLM, Llama-DrugDetector-70B, achieving high accuracy in detecting substance use from clinical notes.
Findings
Llama-DrugDetector-70B achieved F1-scores ≥ 0.95 for most substances.
The model scored F1=0.815 for opioid misuse and F1=0.917 for polysubstance use.
LLMs significantly enhance detection of substance use in clinical notes.
Abstract
Identifying substance use behaviors in electronic health records (EHRs) is challenging because critical details are often buried in unstructured notes that use varied terminology and negation, requiring careful contextual interpretation to distinguish relevant use from historical mentions or denials. Using MIMIC-III/IV discharge summaries, we created a large, annotated drug detection dataset to tackle this problem and support future systemic substance use surveillance. We then investigated the performance of multiple large language models (LLMs) for detecting eight substance use categories within this data. Evaluating models in zero-shot, few-shot, and fine-tuning configurations, we found that a fine-tuned model, Llama-DrugDetector-70B, outperformed others. It achieved near-perfect F1-scores (≥ 0.95) for most individual substances and strong scores for more complex tasks like…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
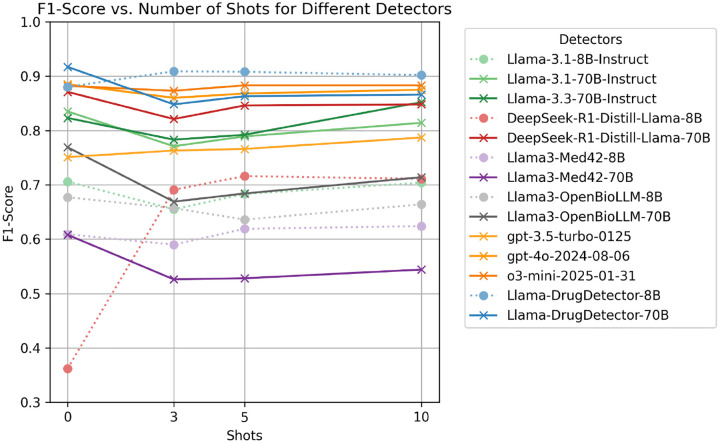 Figure 1
Figure 1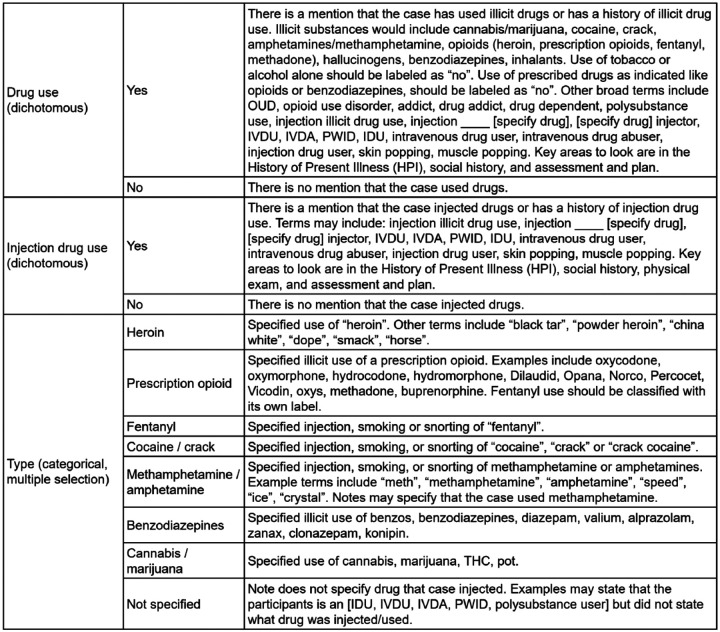 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBiomedical Text Mining and Ontologies · Topic Modeling
Introduction
Identifying persons who use drugs and understanding their related behaviors are critical for improving patient care. In electronic health records (EHRs), the detailed nuances of substance use are primarily documented within free-text notes, a domain of knowledge confined mainly to the direct care providers who interact with patients daily [1, 2]. While EHRs contain a wealth of data [3], this crucial information regarding substance use and related issues presents a significant challenge for researchers, hospital administrators, and public health agencies seeking to monitor broader usage trends and inform policy [4, 5]. The current landscape often leaves these higher-level stakeholders operating without a comprehensive, aggregated view of substance use patterns within their populations.
Natural language processing (NLP) offers a promising solution to bridge this gap by extracting actionable insights from the vast amounts of unstructured text data in EHRs [6, 7, 8]. As a subfield of artificial intelligence, NLP focuses on developing algorithms to understand and analyze human language [9]. These techniques have been applied to various tasks, such as classifying clinical notes, extracting patient information [10], and screening for potential future substance use [11]. In the domain of substance use disorders, NLP has demonstrated effectiveness in detecting opioid misuse [12, 13, 14], identifying people who inject drugs (PWID) [15], and recognizing substances involved in overdoses [16]. By transforming these detailed clinical notes into analyzable data, NLP could be used to monitor usage trends, allocate resources effectively, and develop targeted interventions for at-risk individuals.
Recent advances in NLP have led to the development of two prominent types of models: BERT-style encoders [17, 18, 19, 20] and GPT-style decoders [21, 22, 23], which have significantly improved our ability to process and generate human language [24]. These large language models (LLMs), extensively pre-trained on vast text datasets, can perform a wide range of tasks, often with little (few-shot) to no (zero-shot) task-specific data. This flexibility makes them particularly attractive for scenarios where labeled data is scarce, such as in clinical domains focused on substance use [25, 26, 27, 28, 29]. Despite their proven value, their applications to substance use detection in unstructured EHRs are under-explored. Therefore, this study aimed to evaluate the performance of contemporary zero-shot and few-shot NLP models in identifying substance use and related features from unstructured text in EHRs.
Methods
Dataset
2.1.
We performed a retrospective study to evaluate the performance of different LLMs at identifying reported substances used by patients within unstructured text from EHRs. As this analysis involved only de-identified, publicly available data, the University of California, Los Angeles Institutional Review Board (IRB) determined this study to be exempt from IRB oversight. We used the MIMIC dataset, a comprehensive publicly available repository of de-identified EHRs from patients admitted to Beth Israel Deaconess Medical Center. We included records from both MIMIC-III (2001–2012) [30] and MIMIC-IV (2008–2019) [31].
Substance Classes
2.2.
Given the prevalence of polysubstance use, we framed this task as a multi-label text classification problem to capture concurrent use. In our setup, the input was a medical note containing potential references to substance use. The output was a binary vector indicating the presence or absence of eight items of interest: heroin, cocaine, methamphetamine, illicit use of prescription opioids and benzodiazepines, cannabis, injection drug use (IDU), and general drug use (Any). Although fentanyl was also considered an item of interest, it was excluded from the final set due to its infrequency in our dataset.
Human Annotation
2.2.1.
We identified 1,151 notes containing keywords relevant to the eight drug classes. Five team members (AS, BM, SC, AN, TA) were trained to recognize both explicit and nuanced mentions of substances used based on a pre-specified annotator guide (Appendix A). For instance, while prescription opioids were frequently mentioned benignly in medical notes, identifying illicit use required careful contextual understanding. Annotators highlighted spans of one or more words and classified them under one of the drug classes. Each text span was assigned a single drug class, although multiple spans could be annotated within the same sentence or note.
All team members annotated the same set of 100 notes (10%), and kappa statistics [32] were computed to assess inter-annotator agreement. Upon achieving a kappa score above 0.80 for each class, indicating strong agreement [33], annotators proceeded to single-annotate a subset of the remaining notes. A final team member (AS) then reviewed all annotations for accuracy.
Data Preprocessing
2.2.2.
Due to the significant length of the original medical notes, which posed challenges for standard NLP techniques, we employed span-level annotations. This method breaks down the text into meaningful segments (spans) for individual analysis. While this initially allowed consideration of token classification models—assigning classes like drug names to each word [34, 35], the potential computational intensity of classifying every token led us to adopt a different strategy. We reframed the task as multi-label sentence classification, assigning multiple relevant labels (e.g., identifying both “cocaine” and “cannabis”) to each sentence, thereby capturing diverse information more efficiently than word-by-word analysis.
By tokenizing the annotated medical notes into sentences, we compiled a dataset of 274,602 rows, with only 3,948 containing drug mentions. To evaluate zero and few-shot model performance, we created class-balanced dataset splits for training, validation, and test splits with 10%:10%:80% data points, respectively. We distributed all instances of these classes across the dataset splits. However, some skew was inevitable due to the prevalence of these substances. For example, heroin and cocaine mentions were more common and are overrepresented relative to other drug classes, such as methamphetamine.
Detection Models
2.3.
We evaluated a range of NLP models for detecting substance use in medical notes. We considered key dimensions such as model architecture, pretraining specialization, and availability in a comprehensive, concurrent analysis. We compared smaller, more efficient BERT-style encoders with larger GPT-style decoders (commonly known LLMs), each offering distinct benefits in terms of processing speed, computational demands, and task performance. BERT-style encoders capture context bidirectionally, making them effective for understanding nuanced medical language, while GPT-style decoders process text sequentially, optimizing for fluent generation but lacking full bidirectional context.
We also assessed the impact of domain-specific pre-training, particularly in the medical field, to determine whether specialized training enhances the models’ ability to detect substance use accurately. Additionally, our selection included both open-source and proprietary models to address critical concerns like cost, accessibility, transparency, and privacy—factors that are especially important in medical applications. To further explore the impact of few-shot fine-tuning, we created Llama-DrugDetector in both 8B and 70B parameter versions, optimized for substance use identification tasks in electronic health records using only a limited number of examples (n = 804). A summary of the models we studied is provided in Table 1, with additional details on each model available in Appendix C, and a description of our fine-tuning process in Appendix D.
Detection Pipelines
2.4.
We developed custom detection pipelines to evaluate the performance of various model paradigms in detecting reported substances used and IDU.
For the BERT-style encoders, zero-shot analysis was not advisable because the added classification layers require at least some tuning to map inputs to outputs meaningfully. Therefore, we focused on few-shot fine-tuning, both with and without additional medical domain pre-training. This process involves updating the model weights based on errors observed in a small set of examples.
In addition to few-shot fine-tuning, LLMs support in-context learning (ICL) [41]. In this setting, the LLMs learn the task directly from a few examples provided within the context of the prompt, without requiring updates to the model itself. We evaluated the LLMs under zero-shot (no examples) and few-shot (few examples) configurations randomly drawn from the validation split of the dataset. This allowed us to characterize the performance of few-shot fine-tuning combined with few-shot ICL. For locally hosted LLMs, we implemented our prompting pipelines using guidance [42], a constrained decoding framework that enforces well-formed outputs. Since guidance requires access to token probabilities to function optimally and proprietary LLM providers do not provide this data, we instead implemented a separate pipeline for the GPT family of models in langchain [43].
Evaluation Metrics
2.5.
We compared the performance of all models to identify the best combinations of fine-tuning and prompting strategies. Using the held-out test split (n = 6443) of the DrugDetection dataset, we calculated diagnostic metrics including F1-score, accuracy, sensitivity (i.e., recall), positive predictive value (i.e., precision), specificity, and negative predictive value. The F1-score, which balances positive predictive value and sensitivity, is particularly useful in cases with an uneven distribution of positive and negative instances.^2^ We calculated 95% confidence intervals (CIs) via bootstrapped resampling. We bootstrapped the testing set with replacement 1000 times, running each test on 100 samples and calculating diagnostic metrics for each resample. The 2.5th and 97.5th percentiles were reported as the lower and upper ends of the CI, respectively, and the 50th percentile as the mean. Lastly, we performed a manual error analysis of the false-positive and false-negative predictions from the best-performing NLP model. All statistical analyses were performed using Python 3.12 software.
Error Analysis
2.6.
Lastly, we conducted several rounds of error analysis to identify specific weaknesses in model performance, categorizing and quantifying the most common errors. Based on these analyses, we iteratively refined our prompts to address these issues. The final prompt template we used for all LLMs is available in Appendix E.
Results
For simplicity of presentation, we focus on overall performance by model aggregated across all drug classes. Complete performance breakdowns by metric can be found in the Appendix F.
Dataset Statistics
3.1.
The text inputs in the DrugDetection dataset average 17.2 words each. These were derived from the original notes, which, prior to sentence tokenization, were substantially longer, averaging 239 sentences and about 2840 words per note.
Table 2 summarizes key statistics for each dataset split and for the full DrugDetection dataset. To better evaluate the precision of substance detection systems, we included medical notes unrelated to substance use (see the “None” column), making up roughly 50% of the overall dataset. Additional details, including substance co-occurrence patterns, are provided in Appendix B.
BERT-style Model Evaluation
3.2.
Table 3 compares four BERT-style decoder models on our DrugDetection dataset, including the general-purpose bert-base-uncased and three bio-clinical variants. Contrary to conventional expectations, the base model demonstrated competitive performance, achieving the highest accuracy (0.691, 95% CI: 0.679–0.701) and specificity (0.962, 95% CI: 0.959–0.964) among all models, along with superior precision (0.334, 95% CI: 0.290–0.378). While ClinicalBERT attained the highest F1-score (0.308, 95% CI: 0.298–0.318) and sensitivity (0.363, 95% CI: 0.356–0.371), its performance margins over the base model remain narrow, with overlapping confidence intervals in most metrics. The bio-clinical models showed mixed results: Bio_ClinicalBERT achieved marginally better accuracy (0.689 vs. 0.683) than ClinicalBERT but lower sensitivity, while biobert-v1.1 in F1-score (0.276) and precision (0.265). All models exhibit strong negative predictive value (NPV ≥ 0.966) and specificity (≥ 0.954), indicating robust identification of true negatives, but struggle with positive case detection (sensitivity ≤ 0.363).
Zero-shot LLM Model Evaluation
3.3.
Table 4 compares zero-shot performance of Llama-3 variants with and without bio-clinical adaptation. The base Llama-3.1–8B-Instruct maintained superior performance among 8B models, achieving the highest F1-score (0.706) and accuracy (0.716), though domain-adapted Llama3-OpenBioLLM-8B demonstrated exceptional precision (0.728) and specificity (0.987). Notably, Llama3-Med42–8B showed dramatic sensitivity (0.968) at the cost of precision (0.499), suggesting over-detection tendencies. For 70B models, the generalist DeepSeek-R1-Distill-Llama-70B remained dominant with peak F1-score (0.871) and accuracy (0.860). All models exhibited strong negative predictive value (NPV ≥ 0.946) and specificity (≥0.833), mirroring patterns observed in BERT-style detectors (Table 3), but LLMs demonstrated substantially higher sensitivity (recall ≥0.680 vs. ≤0.363 in BERT models). While domain adaptation showed potential in specific metrics (e.g., Llama3-OpenBioLLM-8B’s precision outperformed base models by 15.8%), the general superiority of base architectures motivated our selection of DeepSeek-R1-Distill-Llama for few-shot fine-tuning.^3^
Few-Shot Fine-Tuning and Few-Shot ICL
3.4.
Figure 1 illustrates the impact of incorporating few-shot examples within the context of the prompt before the main classification task. In 6 out of 15 instances, including few-shot examples led to an enhancement in F1-score compared to the zero-shot baseline. Notably, DeepSeek-R1-Distill-Llama-8B exhibited a substantial 35.4% improvement. On average, few-shot incontext learning resulted in a ~ 1.3% performance boost. Additionally, we observed that combining few-shot fine-tuning with few-shot ICL yielded significant benefits. Our best overall model, Llama-DrugDetector-70B, achieved the highest zero-shot performance (91.9%) but did not benefit from few-shot examples. However, Llama-DrugDetector-8B did benefit from few-shot examples and was the highest performing 8B model. This demonstrated the potential of few-shot ICL in enhancing model accuracy, particularly when integrated with fine-tuning strategies.
Comparing Best Overall Performance
3.5.
Table 5 compares model performance in the challenging polysubstance detection setting, where models must simultaneously identify all relevant drug classes (accuracy requires perfect multi-label classification). Our fine-tuned Llama-DrugDetector-70B achieved the highest F1-score (0.917), while its 8B counterpart (Llama-DrugDetector-8B) demonstrated exceptional accuracy (0.939) and specificity (0.994), suggesting particular strength in avoiding false positives across multiple substance categories. Proprietary models without fine-tuning show mixed performance: o3-mini-2025-01-31 achieved peak specificity (0.994) and competitive precision (0.893) but trailed in F1-score (0.883 vs. 0.917). The all-classes-correct requirement exacerbated architectural disparities, with 70B LLMs achieving 2.97× higher F1-scores than the best-performing BERT-style variants (0.917 vs. 0.308). Finally, fine-tuned open-source models consistently outperformed proprietary counterparts in critical metrics – Llama-DrugDetector-70B surpassed gpt-4o-2024-08-06 in F1-score (0.917 vs. 0.885).
Comparing Substance-Specific Performance
3.6.
The F1 performance for detecting substances individually is presented in Table 6, with similar tables for other metrics available in Appendix F. Detection complexity and performance varies substantially by substance class, and different models possess different strengths. For example, prescription opioid misuse proved most challenging (best F1: 0.830, Llama-DrugDetector-8B), while all other classes exhibited perfect or near-perfect detection (geq 0.95). Heroin detection peaked with o3-mini-2025-01-31 (0.985), while cocaine identification was strongest in Llama-DrugDetector-70B (0.994). Methamphetamine detection reached perfection (F1: 1.000) in Llama-3.3-70B-Instruct, though its narrow applicability is evident from lower scores in prescription opioid misuse (0.655).^4^
Error Analysis
3.7.
Table 7 presents the final error analysis for the best-performing model, our fine-tuned DrugDetector-70B. The most common issue was insufficient evidence, where the model made assumptions unsupported by the text – such as inferring heroin use from injection drug use (n = 126) or assuming illicit use of prescription opioids (n = 103). Another major category was simple failures to identify substances (n = 113), including missed mentions or negated statements. Additional errors stemmed from confusion, such as hallucinating drug use (n = 30), misattributing substance use to the patient rather than a family member, or misreading typos.
Discussion
This study rigorously evaluated the efficacy of various NLP models, ranging from traditional BERT-style encoders to decoder-only LLMs, in the critical task of detecting substance use mentions within electronic health records. Our findings demonstrate a paradigm shift in the potential of NLP for this domain, revealing that even with limited fine-tuning data, contemporary LLMs can achieve remarkable diagnostic performance, significantly surpassing previous benchmarks that relied on extensive training datasets [15, 14, 13]. Notably, our open-source model fine-tuned using a few hundred training examples, Llama-DrugDetector-70B^5^, achieved an F1-score of 0.919 for concurrent polysubstance use, while substance-specific F1 scores ranged from 0.815 for prescription opioid misuse to 0.994 for cocaine use. This exceptional performance, coupled with tighter confidence intervals compared to proprietary models like gpt-4o-2024-08-06, underscores the potential for enhanced clinical reliability and the feasibility of deploying such sophisticated tools in real-world healthcare settings. The ability of our model to identify both explicit and contextually nuanced substance references addresses a significant limitation of earlier rule-based systems [13], offering a more adaptable solution to the evolving landscape of clinical documentation.
A consistent trend throughout our analysis was the superior performance of LLMs over BERT-style encoders across a spectrum of metrics, particularly in the nuanced task of substance-specific detection. This advantage likely stems from the inherent capacity of LLMs to model complex language patterns and capture subtle contextual cues, which are crucial for accurately identifying drug use within clinical narratives [44, 45]. The observation that open-source LLMs often matched or even exceeded the performance of proprietary models like GPT-4o has significant implications for accessibility and deployment. Importantly, open-source models offer the advantage of being locally hosted, making them more suitable for production use in medical and clinical settings where data privacy is legally and ethically mandated [46].
Beyond the immediate clinical applications of improved drug detection, our findings have significant implications for public health surveillance and research. The ability to accurately and efficiently extract information about substance use from EHRs can provide valuable data for monitoring trends in drug use prevalence, which are often difficult to ascertain through traditional methods [47, 48, 49, 50]. By transforming unstructured clinical text into actionable data, our approach can facilitate a more comprehensive understanding of the evolving drug landscape and enable better-informed public health interventions and policy decisions at both the hospital-level and government-level. The potential for integrating insights from our models with other public health data sources, such as overdose statistics, could further enhance our ability to track and respond to the opioid crisis and other substance use challenges.
The error analysis conducted on our best-performing model, Llama-DrugDetector-70B, provided valuable insights into its remaining weaknesses. The prevalence of errors related to insufficient evidence, failures to detect substances, and confusion between similar terms highlights the challenges inherent in interpreting complex medical language and the need for further refinement in handling contextual nuances. These findings suggest that future work could focus on improving the model’s ability to reason about implicit information, handle negation and subtle linguistic cues, and better distinguish between substances with similar names. Techniques such as incorporating more sophisticated prompt engineering strategies or augmenting the fine-tuning data with examples specifically designed to address these error types might also be beneficial.
Limitations
This study has several important limitations. First, the reliance on data from a single medical center in Boston, spanning the years 2001–2019, may limit the generalizability of our findings. Drug use patterns have evolved over time, particularly with the shift from heroin to fentanyl and other synthetic drugs. Prior work [51, 52, 53] has shown that different regions of the US exhibit unique drug use profiles that continue to change. Second, we focused on analyzing short medical notes extracted from larger patient profiles. While this approach enabled us to target specific instances of drug-related language, it also introduced the possibility of losing critical context during sentence tokenization. The potential loss of context could result in the misinterpretation of drug-related language, particularly in complex cases where substance use is inferred from patient history rather than explicitly stated. Other sources of medical documentation could have been relevant to inferring drug use, such as lab results or other provider notes (e.g., social worker or nusring notes). Third, while LLMs offer superior performance in terms of accuracy and language understanding, they demand significantly more computational resources. For instance, BERT-style models process each input in approximately 0.002 seconds, whereas LLMs require between 0.3 to 20 seconds, depending on the model. This disparity becomes a substantial challenge when scaling up to process entire patient notes, which contained an average of 239 sentences in our dataset. Expanding the input size to encompass full patient profiles would necessitate advancements in processing speed for LLMs to make such an approach more viable in real-world applications. The significant computational demands of LLMs, contrasted with the faster but more limited BERT-style models, present a clear trade-off between accuracy and efficiency. One potential solution is to use LLM quantization techniques [54], which reduce model size, trading off some accuracy for increased speed. Future research should explore hybrid models that combine the contextual depth of LLMs with the efficiency of smaller models, potentially through innovative architectures or the application of LLM quantization techniques.
Conclusions
This study establishes that modern LLMs, when combined with few-shot fine-tuning, achieve near-perfect performance in detecting substance use within clinical narratives – surpassing both traditional NLP approaches and proprietary models. Our open-source Llama-DrugDetector-70B attained near-perfect accuracy for most substance classes (except prescription opioid misuse) using only a few hundred training examples, demonstrating that domain-specific performance no longer requires massive labeled datasets or restrictive proprietary systems. These advances carry immediate practical implications: Hospital administrators could deploy such models to flag systemic substance use risks in real time, while public health agencies might leverage them to detect emerging drug trends from unstructured EHR data. However, some challenges remain in minimizing over-interpretation errors (e.g., inferring heroin use from syringe mentions) and optimizing computational costs for clinical workflows. Future work should expand to emerging substances like synthetic opioids (e.g. fentanyl) and explore federated learning frameworks to enhance generalizability across healthcare systems. By open-sourcing our models and benchmarks, we aim to catalyze community-driven improvements in this critical area of clinical NLP.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Modi S., Feldman S. S., , The value of electronic health records since the health information technology for economic and clinical health act: systematic review, JMIR Medical Informatics 10 (9) (2022) e 37283.36166286 10.2196/37283 PMC 9555331 · doi ↗ · pubmed ↗
- 2King J., Patel V., Jamoom E. W., Furukawa M. F., Clinical benefits of electronic health record use: national findings, Health services research 49 (1pt 2) (2014) 392–404.24359580 10.1111/1475-6773.12135 PMC 3925409 · doi ↗ · pubmed ↗
- 3Menachemi N., Collum T. H., Benefits and drawbacks of electronic health record systems, Risk management and healthcare policy (2011) 47–55.22312227 10.2147/RMHP.S 12985 PMC 3270933 · doi ↗ · pubmed ↗
- 4Velupillai S., Suominen H., Liakata M., Roberts A., Shah A. D., Morley K., Osborn D., Hayes J., Stewart R., Downs J., , Using clinical natural language processing for health outcomes research: overview and actionable suggestions for future advances, Journal of biomedical informatics 88 (2018) 11–19.30368002 10.1016/j.jbi.2018.10.005PMC 6986921 · doi ↗ · pubmed ↗
- 5Tayefi M., Ngo P., Chomutare T., Dalianis H., Salvi E., Budrionis A., Godtliebsen F., Challenges and opportunities beyond structured data in analysis of electronic health records, Wiley Interdisciplinary Reviews: Computational Statistics 13 (6) (2021) e 1549.
- 6Wang Z., Shah A. D., Tate A. R., Denaxas S., Shawe-Taylor J., Hemingway H., Extracting diagnoses and investigation results from unstructured text in electronic health records by semi-supervised machine learning, P Lo S One 7 (1) (2012) e 30412.22276193 10.1371/journal.pone.0030412 PMC 3261909 · doi ↗ · pubmed ↗
- 7Assale M., Dui L. G., Cina A., Seveso A., Cabitza F., The revival of the notes field: leveraging the unstructured content in electronic health records, Frontiers in medicine 6 (2019) 66.31058150 10.3389/fmed.2019.00066 PMC 6478793 · doi ↗ · pubmed ↗
- 8Mahbub M., Dams G. M., Srinivasan S., Rizy C., Danciu I., Trafton J., Knight K., Decoding substance use disorder severity from clinical notes using a large language model, npj Mental Health Research 4 (1) (2025) 5.39915681 10.1038/s 44184-024-00114-6PMC 11802718 · doi ↗ · pubmed ↗