Sama: a contig assembler with correctness guarantee
Leena Salmela

TL;DR
This paper introduces Sama, a genome assembly tool that guarantees correctness by estimating misassembly probabilities in de Bruijn graphs.
Contribution
Sama introduces a novel model for estimating misassembly probabilities in genome assembly, incorporating missing data and providing correctness guarantees.
Findings
Sama produces contigs with correctness guarantees and estimates for each position.
At high k-mer coverage, Sama's contiguity matches state-of-the-art heuristic-based assemblers.
The model can be applied to downstream analysis of contigs or de Bruijn graph-based analyses.
Abstract
In genome assembly the task is to reconstruct a genome based on sequencing reads. Current practical methods are based on heuristics which are hard to analyse and thus such analysis is not readily available. We present a model for estimating the probability of misassembly at each position of a de Bruijn graph based assembly. Unlike previous work, our model also takes into account missing data. We apply our model to produce contigs with correctness guarantee and correctness estimates for each position in the contigs. Our experiments show that when the coverage of k-mers is high enough, our method produces contigs with similar contiguity characteristics as state-of-the-art assemblers which are based on heuristic correction of the de Bruijn graph. Our model may have further applications in downstream analysis of contigs or in any analysis working directly on the de Bruijn graph.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
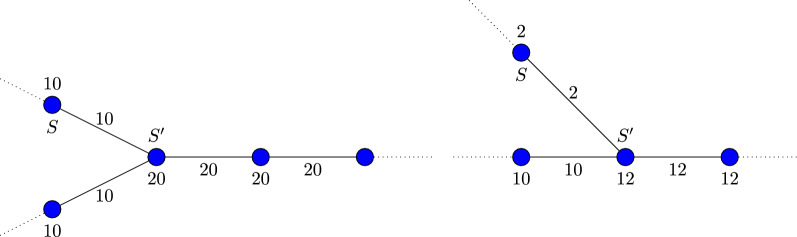 Figure 1
Figure 1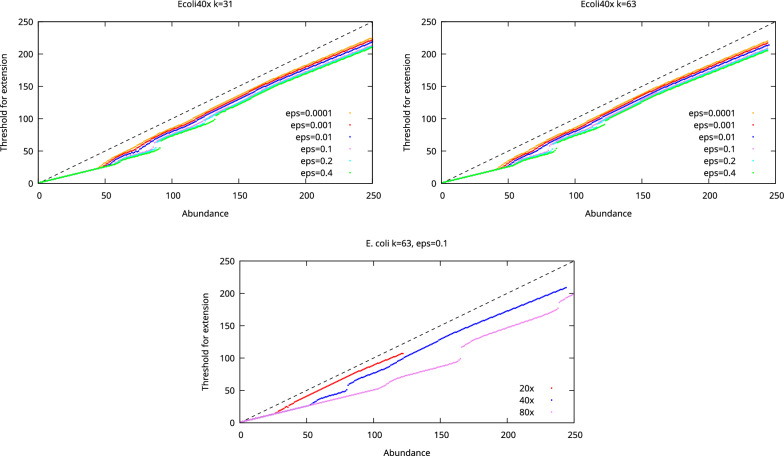 Figure 2
Figure 2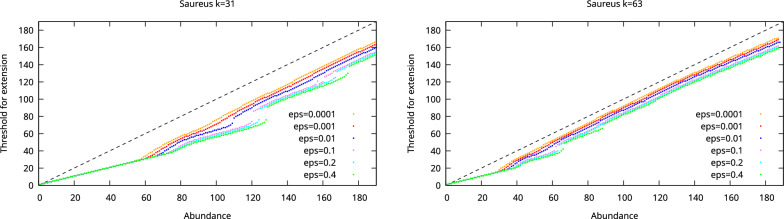 Figure 3
Figure 3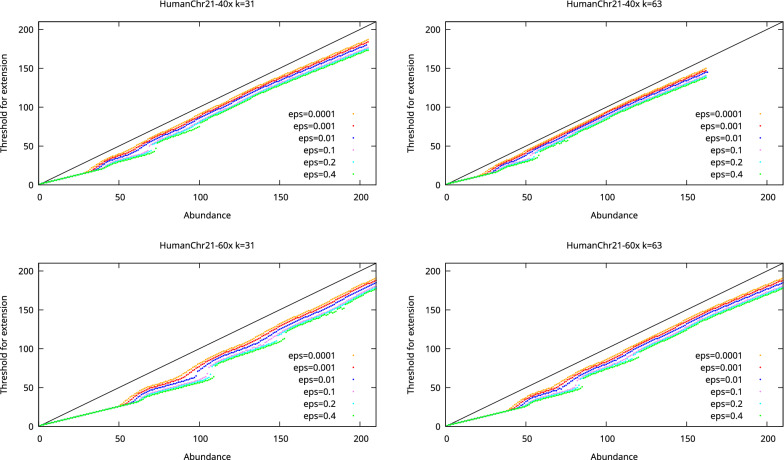 Figure 4
Figure 4- —Helsinki University Library
- —University of Helsinki (including Helsinki University Central Hospital)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAlgorithms and Data Compression · DNA and Biological Computing · semigroups and automata theory
Background
Genome assembly is a classical problem in computational biology where the task is to reconstruct a genome based on sequencing reads. Theoretically, genome assembly has been formulated as finding the shortest common superstring of the reads, finding a Hamiltonian path in a string graph, or finding a Eulerian tour in a de Bruijn graph. However, the solutions to these problems are almost never unique, and thus practical methods are instead based on heuristics. These heuristics are hard to analyse and thus such analysis is not readily available [1]. Furthermore, it has been shown that misassemblies are present in the output sequences due to not considering structural correctness properly [2].
Current solutions produce a set of sequences that are claimed to be substrings of the genome. Most assemblers are based on unitigs which are strings corresponding to nonbranching paths in a string graph or a de Bruijn graph and thus guaranteed to be substrings of the genome if there is no missing data, i.e. missing branches in the graph. A further theoretical development is to produce omnitigs [3] which are guaranteed to be substrings of each genome that could produce the string graph or de Bruijn graph but again it is assumed there is no missing data. In the presence of missing data, these approaches may report strings that are not substrings of the original genome.
Several works have previously investigated under which conditions a genome assembly is correct. It has for example been shown that if enough information is available, a unique and correct solution can be found in polynomial time [4, 5]. Enough information can be characterized as the solution being unique [5] or requiring that all repeat instances of the genome are spanned by some read [4]. However, the requirement for enough information essentially means that there can be no missing data and these approaches do not easily extend to estimating the probability of correctness for a given position in the assembly.
Probabilistic frameworks have previously been applied to genome assembly to produce longer contigs. Medvedev and Brudno [6] and Myers [7] have proposed to report the sequence with maximum likelihood given the reads as the assembled genome and Boža et al. [8] have developed a probabilistic framework to produce an assembly with high likelihood using simulated annealing. However, these approaches do not assign probabilities to misassemblies nor do they consider missing data. Howison et al. [9] have proposed to use a Markov chain Monte Carlo approach to providing posterior probabilities of assemblies but their approach is computationally expensive and thus they only applied it to the bacteriophage \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Phi$$\end{document} X174. Finally, the correctness of genome assembly has been studied in the context of validating the produced assembly [10, 11].
We present a model for structural correctness in de Bruijn graph based assembly. Our model estimates the probability of misassembly for each edge in the de Bruijn graph. We apply our model to de Bruijn graph based assembly to create an assembled genome with a correctness guarantee and a correctness estimate for each position in the assembly. We call the resulting assembler Sequence Assembly avoiding MisAssemblies (SAMA). Although here we apply the model to the genome assembly problem, the model can be of independent interest beyond assembly and could be useful for any downstream analysis based on the results of assembly or to any analysis performed directly on a de Bruijn graph. Our experiments show that when k-mer coverage is high enough for computing accurate estimates, our method produces as contiguous assemblies as a state-of-the-art assembler based on heuristic correction of the de Bruijn graph like tip and bulge removal [12]. Our method is also competitive in runtime and memory usage.
Methods
We will first give an overview of our method for de Bruijn graph based assembly with structural correctness guarantees and then we will explain the related analysis and the implementation details of the method.
Overview of the method
Given a set of reads, we first construct the de Bruijn graph of the reads. The de Bruijn graph contains a node for each k-mer occurring in the reads. An edge is added between two k-mers if they overlap by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k-1$$\end{document} characters and the resulting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k+1$$\end{document} -mer occurs in the reads. For each node we compute the abundance of the k-mer which is the number of occurrences of the k-mer in the read set. Similarly, we also compute the abundance of each edge.
Assembly in a de Bruijn graph is a set of paths where each path corresponds to a contig. Based on the abundances of nodes and edges, we will estimate for each edge the probability that using that edge in an assembly can result in a misassembly. In other words, we estimate the probability that an edge representing an extension of a k-mer to a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k+1$$\end{document} -mer is not a unique extension of the k-mer in the original genome. If the extension is not unique, using the edge in an assembly can result in misassembly. Finally, given a threshold for the probability of misassembly, we will produce contigs by finding all maximal paths in the de Bruijn graph such that the estimated misassembly probability of each edge in the paths is below the threshold.
Definitions and problem formulation
Let us consider a set of reads R from a genome G. We assume that the reads are sampled at random from the genome. We denote the abundance or frequency of a sequence S in the read set R by f(S). When we want to emphasize that the abundance is a constant we use a to denote the abundance of a sequence.
A k-mer is a sequence of length k. The k-mer spectrum of a read set is the set of all k-mers occurring in the read set. We construct the de Bruijn graph for a read set by enumerating its k-mer spectrum. Each k-mer occurring in the read set is a node of the de Bruijn graph. There is an edge between two k-mers \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S[1\ldots k]$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T[1\ldots k]$$\end{document} if they overlap by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k-1$$\end{document} characters, i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S[2\ldots k] = T[1\ldots k-1]$$\end{document} and the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k+1$$\end{document} -mer \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S[1\ldots k]T[k]=S[1]T[1\ldots k]$$\end{document} also occurs in the read set. An assembly in a de Bruijn graph consists of a set of paths. Each path \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_1S_2\ldots S_n$$\end{document} corresponds to a sequence consisting of the first k-mer in the path concatenated with the last characters of each of the remaining k-mers: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_1[1\ldots k] S_2[k] S_3[k] \ldots S_n[k]$$\end{document} .
Here we are interested in estimating the probability of missassembly for each edge in the de Bruijn graph. Let S be a sequence (a k-mer) which occurs as a substring in R a times, i.e. the abundance of S in R is a. Let us assume that also the sequence Sc (a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k+1$$\end{document} -mer), where c is a nucleotide, occurs as a substring in R. Now we are interested in whether Sc is a unique extension of S in G or not. If Sc is not a unique extension of S in G, we should not utilise the edge Sc in a de Bruijn graph assembly since the correctness of the edge depends on the context where Sc occurs and information about this context is not available in a de Bruijn graph. Note that Sc can be a unique extension even when S is a repeat in G. A unique extension then means that each repeat copy of S in G is followed by c or in other words the multiplicities of S and Sc are the same in G.
We thus need to estimate the following probability. If a k-mer S is a repeat and Sc is not a unique extension of S, what is the probability that Sc occurs with abundance at least \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell$$\end{document} in the read set. Therefore, we solve the following problem:
**Problem 1 **If S is a repeat in G, what is the probability that the abundance of Sc is larger than \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell$$\end{document} in R when S has at least two extensions in G, Sc and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Sc'$$\end{document} .
This probability estimate directly gives us an estimate for an edge Sc to cause a misassembly.
Below we will split our analysis based on the number of repeat copies of S in G. We denote the number of repeat copies by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} and call a repeat with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} occurrences in G an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} -repeat. Previous work exists to compute estimates for the proportion of k-mers that are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} -repeats based on the abundance histogram of k-mers. We will utilise the Detox [13] method to compute these estimates.
Probability of misassembly for repeated sequences
We assume here that all sequences that occur with frequency at least \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell _e$$\end{document} in the read set R are truly subsequences of the genome G. However, some of the subsequences of the genome G might not occur in R. We now want to analyse what is the probability of Sc not being a unique extension of S in G if the frequency of S and Sc are above some threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell \ge \ell _e$$\end{document} in R.
If the sequence S is not a repeat in G, then the probability that Sc is not a unique extension of S in G is 0 since there is a single occurrence of S in G. Next we will analyse the probability of an extension Sc of S not to be unique in G when S is a repeat and the frequency of S and Sc in R is above some threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell \ge \ell _e$$\end{document} .
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\alpha$$\end{document}α-repeats
The analysis given here is an adaptation of the analysis given in [14] for 2-repeats.
Let us assume that S is an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} -repeat and thus S occurs in G \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} times. S then has \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} occurrences and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} extensions in G: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Sc_1, Sc_2, \ldots , Sc_\alpha$$\end{document} . In the worst case \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha -1$$\end{document} of these extensions are equal and one is different, i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_1\ne c_2=c_3=\ldots =c_\alpha$$\end{document} . Since S is an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} -repeat, we require that its extensions occur \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell>\frac{\alpha -1}{\alpha } a$$\end{document} times in the read set, where a is the abundance of S in the read set. For a lower threshold we would be very likely to ignore at least one extension in G. Now the abundance of Sc, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c=c_2=c_3=\ldots =c_\alpha$$\end{document} , is distributed as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Binomial}(a,(\alpha -1)/\alpha )$$\end{document} and thus the probability that the abundance of Sc is at least \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell$$\end{document} is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} P(f(Sc) \ge \ell ) = \sum _{i=\ell }^a \left( {\begin{array}{c}a\\ i\end{array}}\right) \left( \frac{\alpha -1}{\alpha }\right) ^i \left( \frac{1}{\alpha } \right) ^{a-i} \end{aligned}$$\end{document}Using the right-tail upper bound by Ferrante [15], we get
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} P(f(Sc) \ge \ell ) \le \frac{1}{1-r\left( \frac{\ell }{a}, \frac{\alpha -1}{\alpha }\right) } \frac{1}{\sqrt{2\pi \frac{\ell }{a} \left( 1-\frac{\ell }{a}\right) a}} e^{-aD\left( \frac{\ell }{a} \parallel \frac{\alpha -1}{\alpha }\right) } \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$r\left( \frac{\ell }{a}, \frac{\alpha -1}{\alpha }\right)$$\end{document} is the odds ratio
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} r\left( \frac{\ell }{a}, \frac{\alpha -1}{\alpha }\right) = \frac{\frac{\alpha -1}{\alpha } \left( 1-\frac{\ell }{a}\right) }{\frac{\ell }{a} \left( 1-\frac{\alpha -1}{\alpha } \right) } \end{aligned}$$\end{document}and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D\left( \frac{\ell }{a} \parallel \frac{\alpha -1}{\alpha }\right)$$\end{document} is the Kullback–Leibler divergence between two Bernoulli random variables
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} D\left( \frac{\ell }{a} \parallel \frac{\alpha -1}{\alpha }\right) = \frac{\ell }{a} \log \frac{\frac{\ell }{a}}{\frac{\alpha -1}{\alpha }} + \left( 1-\frac{\ell }{a}\right) \log \frac{1-\frac{\ell }{a}}{a-\frac{\alpha -1}{\alpha }}. \end{aligned}$$\end{document}Since there are \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} possible extensions of S in G for which the above scenario could hold, then the probability that an extension of S has an abundance above \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ell$$\end{document} in R is
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \alpha P(f(Sc_1) \ge \ell ) \le \alpha \frac{1}{1-r\left( \frac{\ell }{a}, \frac{\alpha -1}{\alpha }\right) } \frac{1}{\sqrt{2\pi \frac{\ell }{a} \left( 1-\frac{\ell }{a}\right) a}} e^{-aD\left( \frac{\ell }{a} \parallel \frac{\alpha -1}{\alpha }\right) } \end{aligned}$$\end{document}Putting it all together
Now that we have an estimate for the proportions of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} -repeats for different \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} and the estimates for an extension of S not to be unique in G given that S is an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} -repeat, we can compute the total probability that an extension of S is not unique:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} P(f(Sc)\ge \ell ) =&P(\alpha =1) P(f(Sc) \ge \ell \mid \alpha =1) \\&+ \sum _{\alpha '=2}^{\infty } P(\alpha =\alpha ') P(f(Sc) \ge \ell \mid \alpha =\alpha ')\\ \le&\sum _{\alpha '=2}^{\infty } P(\alpha =\alpha ') \alpha ' \frac{1}{1-r(\frac{\ell }{a}, \frac{\alpha '-1}{\alpha '})} \frac{1}{\sqrt{2\pi \frac{\ell }{a} \left( 1-\frac{\ell }{a}\right) a}} e^{-aD\left( \frac{\ell }{a} \parallel \frac{\alpha '-1}{\alpha '}\right) } \\ \end{aligned}$$\end{document}Integrating the analysis in de Bruijn graph based assembler
We will now use the results of the above analysis to create a de Bruijn graph based assembly where the probability of misassembly at each position is bounded by a constant \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} . We call the resulting tool Sequence Assembly avoiding MisAssemblies (SAMA).
First we construct the de Bruijn graph using BCALM 2 [16]. We then use Detox [13] to estimate for each abundance level a and each \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} the probability that a k-mer appearing a times in the reads repeats \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} times in the genome. In practice, Detox limits the values of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} in the range [0, 5]. Now we have all that is needed for the analysis presented above.
Given a k-mer S that is a node of the de Bruijn graph, each edge originating at that node presents an extension of S by one character. The above analysis gives us the probability that such an extension is not a unique extension of S in the genome given the abundance a of S and the abundance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a_e$$\end{document} of Sc. We could compute these probabilities for each edge but instead we will use the following more efficient strategy. We can compute a lower bound for the abundance of an extension given the abundance of a k-mer such that if an extension has abundance at least equal to the lower bound, then the probability that the extension is not a unique extension is lower than the misassembly threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} . These lower bounds can then be applied to any k-mer with the given abundance. Hence the next step is to compute such thresholds for each abundance of a k-mer. We thus iterate over all abundances of k-mers and for each abundance we find the lowest abundance of an extension for which the probability of an extension not being unique is less than the parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} , our probability threshold for misassembly.
The final step is to generate contigs where each de Bruijn graph edge included in the contigs meets the abundance threshold. We note that an edge between two de Bruijn graph nodes S and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S'$$\end{document} can meet the abundance threshold in one direction but not in the other. This commonly happens at the boundary of repeats, where e.g. S is not a repeat k-mer but \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S'$$\end{document} is (see Fig. 1 left), and at the boundary of sequencing errors, where e.g. S is an erroneous k-mer but \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S'$$\end{document} is not (see Fig. 1 right). Then we can extend S towards \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S'$$\end{document} uniquely but we cannot extend \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S'$$\end{document} uniquely towards S. When generating contigs we only utilize edges which are unique extensions in both directions. We further note that the thresholds computed in the previous stage are always larger than half of the abundance of the node and therefore, at most one edge out of the node can meet the abundance threshold. Therefore, if using only such edges there is no branches to resolve.Fig. 1. Typical situations where the edge of the de Bruijn graph is a unique extension in one direction but not a unique extension in the reverse direction. In the left figure the node S is a unique k-mer in the genome but \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S'$$\end{document} is a repeat k-mer. Then S can be extended towards \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S'$$\end{document} uniquely but \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S'$$\end{document} cannot be extended towards S uniquely. Similarly in the right figure the node S is an erroneous k-mer that does not occur in the genome and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S'$$\end{document} is a unique k-mer in the genome. Now our analysis will denote the extension of S towards \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S'$$\end{document} as a unique extension but not the extension of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S'$$\end{document} towards S
We use the following procedure to traverse the paths of the de Bruijn graph to generate contigs. We ignore nodes with an abundance lower than five since these are likely to be results of sequencing errors. We start the traversal in some arbitrary node. We first traverse edges to the right from the chosen node as long as we find edges that meet the abundance threshold. Then we do a similar traversal to the left. During the traversal we mark each visited node to avoid producing duplicate contigs. When both traversals are complete, we produce a contig corresponding to the traversed path. We then iterate and start a new traversal from an arbitrary node that has not yet been marked (i.e. is not part of a previously generated contig). The contig generation finishes when all nodes have been marked.
Experiments
Datasets and methods
We ran experiments on real HiFi reads from E. coli and real Illumina reads from S. aureus. Both datasets were downsampled to the desired coverage levels. To investigate the performance of our model and other assemblers on different coverage levels, we produced three datasets of the E. coli dataset Ecoli20x, Ecoli40x, and Ecoli80x with coverages 20x, 40x, and 80x, respectively. The S. aureus was downsampled to 80x coverage. Additionally, The E. coli and S. aureus datasets have been downsampled to achieve the desired coverage we simulated two datasets on human chromosome 21 with Art [17]: HumanChr21-40x with 40x coverage and HumanChr21-60x with 60x coverage. The details of the datasets are in Table 1. Table 1. Details of the datasetsNameOrganismRef seqRef seqAccessionTechnologyCoverageTotal readlengthlength(Mb)(Mb)Ecoli20xE. coli K12NC_0009134.6SRR10971019HiFi20x92.0MG 1655Ecoli40xE. coli K12NC_0009134.6SRR10971019HiFi40x184.0MG 1655Ecoli80xE. coli K12NC_0009134.6SRR10971019HiFi80x371.3MG 1655SaureusS. aureusCP0260672.9SRR1955629Illumina80x230.5NRS153HumanChr21-40xH. sapiensCP06825745.1SimulatedIllumina40x1,803.6CHM13 chr 21HumanChr21-60xH. sapiensCP06825745.1SimulatedIllumina60x2,705.4CHM13 chr 21The human chromosome 21 datasets are simulated with ART [17]. The reference sequence lengths and total read lengths are given in millions of bases (Mb). E. coli S. aureus datasets have been downsampled to achieve the desired coverage
We compared SAMA to unitigs produced by BCALM 2 [16] and contigs produced by SPAdes [18] without error correction and before repeat resolution (which reuses the reads by mapping them on the de Bruijn graph using then the full read information to resolve repeats). BCALM 2 thus represents traditional unitigs and SPAdes contigs results of an assembly algorithm applying tip and bulge removal.
We ran all methods with two values of k, 31 and 63. We chose odd values because SPAdes and SAMA require k to be odd. Furthermore, 31-mers and 63-mers allow efficient representation of k-mers as 64-bit and 128-bit integers, respectively. Experiments shown in Supplementary Table 1 show that the continuity of assembly produced by SAMA gradually increases when k is increased. SAMA was run with six values for the misassembly threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} : 0.4, 0.2, 0.1, 0.01, 0.001, and 0.0001. BCALM 2 was run with three abundance thresholds: 5, 10, and 15. SPAdes was run with the –only-assembler option to disable error correction and the contigs saved in the before_rr.fasta file were analysed. We used QUAST [19] to produce statistics on the produced assemblies. All experiments were run on a computer with 32 GB of memory and 4 CPUs each with 2 cores.
Abundance thresholds
We first examined the abundance thresholds produced by our analysis. The thresholds as a function of k-mer abundance for the E. coli, S. aureus, and human chromosome 21 datasets are shown in Figs. 2, 3, and 4, respectively. These thresholds thus indicate what is the minimum abundance of a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k+1$$\end{document} -mer for it to be considered as a unique extension of a k-mer.
For low abundance k-mers the thresholds are close to half the abundance of the k-mers because these k-mers are likely to be unique in the genome and for the unique k-mers probability of misassembly in our model is 0. For the higher abundance k-mers, the thresholds are close to the abundance of the k-mers due to most of these k-mers originating from repeats and then a lot of evidence is needed to determine that the extension is likely to be unique. However, the threshold does not increase evenly which is due to the proportions of repeats with different number of occurrences changing when the abundance of k-mers increases. We also see that the thresholds increase when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} increases. When the probability of misassembly is set low, we find some k-mer abundances for which no abundancy threshold exist such that we could guarantee a low enough misassembly probability.Fig. 2. The threshold for extension as a function of k-mer abundance when the allowed probability for misassembly is varied (top) and when the coverage of the dataset is varied (bottom) in the E. coli datasets. The dashed line shows the maximum possible threshold. Missing dots indicate k-mer abundances where no threshold guaranteeing the desired misassembly probability can be foundFig. 3The threshold for extension as a function of k-mer abundance when the allowed probability for misassembly is varied for the Saureus dataset. The dashed line shows the maximum possible threshold. Missing dots indicate k-mer abundances where no threshold guaranteeing the desired misassembly probability can be foundFig. 4The threshold for extension as a function of k-mer abundance when the allowed probability for misassembly is varied for the HumanChr21-40x dataset (top) and Human Chr21-60x dataset (bottom). The dashed line shows the maximum possible threshold. Missing dots indicate k-mer abundances where no threshold guaranteeing the desired misassembly probability can be found
Comparison to other methods
We computed the following statistics on all the assemblies produced by SAMA, BCALM 2, and SPAdes:
- #contigs: The number of contigs longer than 100 bp in the assembly.
- NGA50: The contigs are first aligned on the reference genome. The alignments are then ordered from largest to smallest. The NGA50 metric is the length of the alignment where the cumulative length of the alignments exceeds half the genome length.
- Misassemblies: The number of misassemblies as reported by QUAST.
- Genome fraction: The percentage of nucleotides in the genome that are covered by at least one contig. Table 2 shows the statistics of the assemblies produced by the various methods on the E. coli datasets. Similarly, Table 3 shows the statistics of the assemblies produced by the methods on the Saureus and human chromosome 21 datasets.
We see that SAMA produces more contiguous assemblies, i.e. lower number of contigs, higher NGA50, and higher genome fraction, when we allow a higher probability for misassemblies. SAMA produces misassemblies only on the HumanChr21-40x and HumanChr21-60x datasets when the allowed probability for misassemblies is high. When the allowed probability of misassemblies is less than or equal to 0.01 there are no misassemblies on any of the datasets.
SAMA produces more contiguous assemblies than the unitigs produced by BCALM 2 when the allowed probability for misassemblies is set appropriately. When the coverage of the dataset is high enough for accurate enough probability estimates, SAMA produces assemblies with similar contiguity characteristics as SPAdes and with no misassemblies. When coverage is lower (Ecoli20x and Saureus datasets), SPAdes produces somewhat more contiguous assemblies. On the other hand, on the more complex human chromosome 21 datasets, SAMA produces more contiguous assemblies than SPAdes. It is worth noting that although the Saureus dataset has nucleotide coverage of 80x, the read length is only 101 bp, and so the coverage of k-mers is only 56x and 31x when k is 31 and 63, respectively. Table 2. Assembly statistics for the E. coli datasetsDatasetMethodParameters#contigsNGA50MisassembliesGenome( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ge$$\end{document} 100 bp)fraction (%)Ecoli20xSAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.446422,173097.5SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.248521,266097.5SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.149920,037097.5SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.0151520,037097.5SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.00153119,183097.5SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.000156916,972097.5SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.453860,614098.5SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.254860,614098.5SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.155560,614098.5SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.0157259,680098.5SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.00158857,852098.5SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.000164845,813098.5BCALM2k=31 a=574713,532097.6BCALM2k=31 a=101,10115,302096.3BCALM2k=31 a=154,1882,413078.4BCALM2k=63 a=587431,596098.7BCALM2k=63 a=101,66026,917097.1BCALM2k=63 a=156,231950077.2SPAdesk=3146922,175097.1SPAdesk=6325978,620098.2Ecoli40xSAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.446923,326097.6SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.247422,902097.6SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.147622,902097.6SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.0150122,173097.6SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.00150722,173097.6SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.000151021,793097.6SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.41,38578,618098.7SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.21,39178,618098.7SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.11,39778,618098.8SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.011,41073,700098.8SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.0011,43261,690098.8SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.00011,44357,852098.8BCALM2k=31 a=521124,082097.5BCALM2k=31 a=1057618,227097.6BCALM2k=31 a=1554121,235097.7BCALM2k=63 a=537515,702098.9BCALM2k=63 a=1058359,552098.7BCALM2k=63 a=1554263,602098.7SPAdesk=3148522,175097.8SPAdesk=6327478,620098.4DatasetMethodParameters#contigsNGA50MisassembliesGenome( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ge$$\end{document} 100 bp)fraction (%)Ecoli80xSAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.448823,334097.7SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.250123,326097.7SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.151222,902097.7SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.0151322,902097.6SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.00151422,902097.6SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.000151322,902097.6SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.46,66478,618099.1SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.26,67578,618099.1SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.16,69178,618099.1SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.016,71278,618099.1SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.0016,71678,618099.1SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.00016,71978,618099.1BCALM2k=31 a=58,019813095.4BCALM2k=31 a=101,4656,189097.5BCALM2k=31 a=1565316,190097.6BCALM2k=63 a=519,389986099.0BCALM2k=63 a=102,2759,466098.8BCALM2k=63 a=1572341,980098.8SPAdesk=3148522,175097.8SPAdesk=6326878,620098.3Table 3Assembly statistics for the Saureus and HumanChr21 datasetsDatasetMethodParameters#contigsNGA50MisassembliesGenome( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\ge$$\end{document} 100 bp)fraction (%)SaureusSAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.439224,807096.9SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.239223,869096.9SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.139423,768096.9SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.0139123,768096.8SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.00139023,768096.8SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.000139521,519096.8SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.442731,697098.1SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.243231,697098.1SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.143531,697098.1SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.0144631,697098.1SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.00145931,260098.1SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.000148531,028098.1BCALM2k=31 a=56879,337096.7BCALM2k=31 a=1048418,684096.8BCALM2k=31 a=1542222-009096.9BCALM2k=63 a=564317,374098.2BCALM2k=63 a=109068,882098.2BCALM2k=63 a=154,9651,350097.8SPAdesk=3145326,628097.1SPAdesk=6326439,224097.9HumanChr21-40xSAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.444,1751,446074.6SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.243,8771,439074.3SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.143,7501,434074.2SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.0143,6121,430074.2SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.00143,6351,426074.1SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.000143,6641,423074.1SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.437,6898,336190.0SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.238,3138,268189.9SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.138,6818,201189.9SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.0138,9798,158089.9SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.00139,0408,151089.9SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.000139,0838,131089.9BCALM2k=31 a=543,7961,351073.4BCALM2k=31 a=1044,0411,352073.5BCALM2k=31 a=1545,7531,220073.4BCALM2k=63 a=540,0517,687089.9BCALM2k=63 a=1041,4715,945090.0BCALM2k=63 a=1572,2221,166089.0SPAdesk=3138,6041,455074.1SPAdesk=6323,1258,187087.1HumanChr21-60xSAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.444,1231,448174.6SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.243,8681,440074.4SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.143,7151,436074.2SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.0143,6031,431074.2SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.00143,5971,430074.1SAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.000143,5961,429074.1SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.439,5868,300190.3SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.240,2328,230090.2SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.140,5268,194090.2SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.0140,8338,166090.2SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.00140,8568,164090.2SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =0.000140,8628,164090.2BCALM2k=31 a=543,6911,347073.3BCALM2k=31 a=1043,9741,352073.5BCALM2k=31 a=1544,0151,354073.5BCALM2k=63 a=541,0377,693090.0BCALM2k=63 a=1040,0257,693090.0BCALM2k=63 a=1540,0347,509090.0SPAdesk=3138,4041,455074.1SPAdesk=6322,9908,187087.1
Table 4 shows the runtime and peak memory usage of the tools. The statistics for SAMA include running BCALM 2 and Detox since they are part of the needed pipeline. The comparison against SPAdes is not entirely fair because it was not possible to disable running the repeat resolution code which uses a significant amount of resources. We see that SAMA is competitive in both runtime and memory usage. Table 4. Runtime and memory usageDatasetMethodParametersRuntime (min)Memory Usage (GB)Ecoli20xSAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =1e-010.891.28SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =1e-010.871.35BCALM2k=31 a=100.230.58BCALM2k=63 a=50.320.87SPAdesk=310.500.79SPAdesk=630.841.53Ecoli40xSAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =1e-011.171.46SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =1e-011.331.67BCALM2k=31 a=150.350.98BCALM2k=63 a=150.441.55SPAdesk=310.971.54SPAdesk=631.642.21Ecoli80xSAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =1e-011.921.94SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =1e-012.262.88BCALM2k=31 a=150.541.71BCALM2k=63 a=150.682.88SPAdesk=311.832.21SPAdesk=633.292.22SaureusSAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =1e-010.950.88SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =1e-010.750.81BCALM2k=31 a=150.280.76BCALM2k=63 a=50.280.76SPAdesk=310.901.34SPAdesk=630.661.45HumanChr21-40xSAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =1e-0120.7611.49SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =1e-01130711.78BCALM2k=31 a=102.863.23BCALM2k=63 a=53.323.34SPAdesk=31132.9318.79SPAdesk=6332.776.92HumanChr21-60xSAMAk=31 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =1e-0124.6812.79SAMAk=63 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varepsilon$$\end{document} =1e-0119.3412.91BCALM2k=31 a=153.784.17BCALM2k=63 a=54.284.30SPAdesk=31167.7825.62SPAdesk=6347.219.53
Conclusion
We have presented a model to estimate the probability of misassembly at each position of a de Bruijn graph based assembly. As far as we know, this is the first model that can assign such a probability to each position in the assembly also taking into account missing data. We applied our model to produce contigs with correctness guarantee and showed that this leads to a practical method. Here we applied the model to produce an assembly where the probability of misassembly at each position is bounded. However, this information has further potential applications in the downstream analysis of a genome and in any analysis method working directly on the de Bruijn graph. For example, the probabilities computed according to our model could be used to evaluate the confidence of structural variants or genome rearrangements detected in an assembly. Many analysis methods working directly on a de Bruijn graph align sequences to the graph. The probabilities computed according to our model could be used to assign confidence values to these alignments and possibly favor alignments that span edges with high probabilities of correctness.
Our current model is limited to single haploid genomes. It would be interesting to extend the ideas presented here to diploid genomes as well as viral and bacterial metagenomics.
Supplementary Information
Supplementary Material 1.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Díaz-Domínguez D, Onodera T, Puglisi SJ, Salmela L, Genome assembly with variable order de Bruijn graphs. bio Rxiv 2022 10.1101/2022.09.06.506758 https://arxiv.org/abs/https://www.biorxiv.org/content/early/2022/09/07/2022.09.06.506758.full.pdf