Enhanced nuclear information fusion and visual transformer for pathological breast cancer image classification
Qinyi Zhang, Honglei Gao, Wenhao Li, Zhipeng Xu, Ting Ouyang, Zongyun Gu

TL;DR
This paper introduces a new method for classifying breast cancer images using enhanced nuclear information and a vision transformer model, achieving high accuracy.
Contribution
The novel approach combines enhanced nuclear information with a wavelet position embedding in a vision transformer for improved breast cancer classification.
Findings
The method achieves 94.61% accuracy and 99.07% AUC on the BreaKHis dataset.
Wavelet position embedding in the EVT model improves classification performance.
Nuclear information enhancement contributes significantly to the model's effectiveness.
Abstract
Breast cancer poses a significant threat to women’s health. Early diagnosis using pathological images is crucial for effective treatment planning. However, the low resolution of pathological images poses significant challenges for the extraction of valid information, while their high complexity greatly increases the difficulty of image analysis. To address these challenges, this paper introduces an innovative classification method for breast cancer histopathological images, combining enhanced nuclear information with an Enhanced Vision Transformer (EVT) model using wavelet position embedding. The quintessence of the proposed method resides in its capacity to efficiently extract both biological and foundational image features from pathological images. This is accomplished by initially enhancing nuclear information through the application of segmentation models and sophisticated image…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
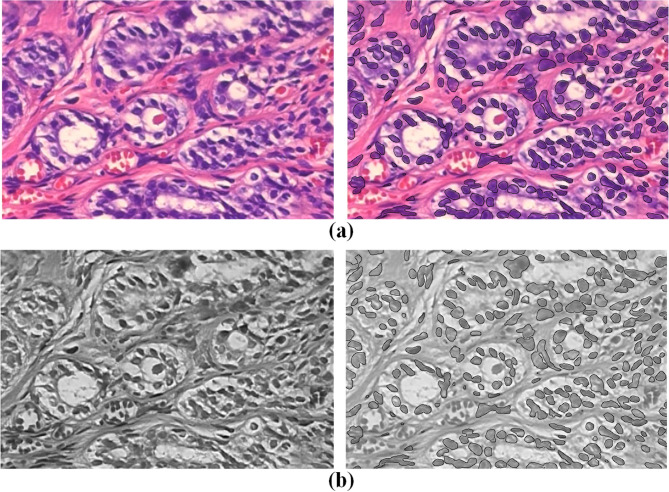 Figure 1
Figure 1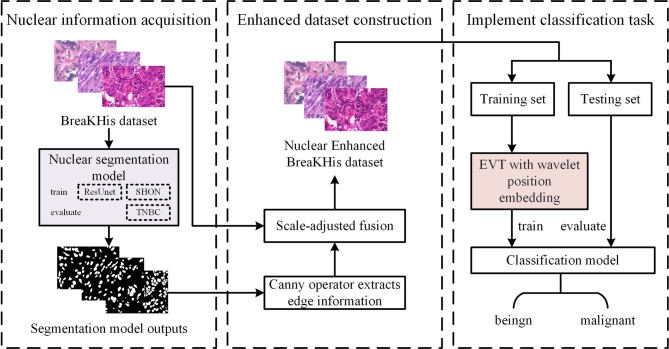 Figure 2
Figure 2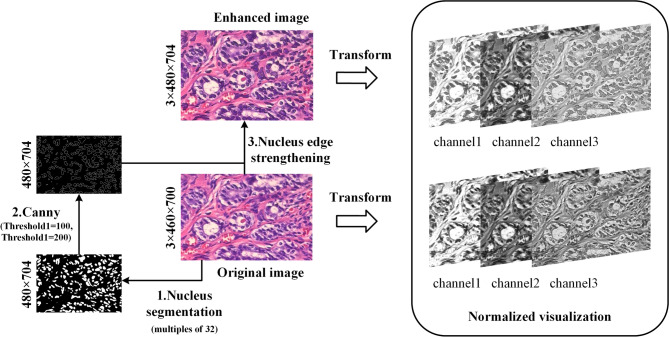 Figure 3
Figure 3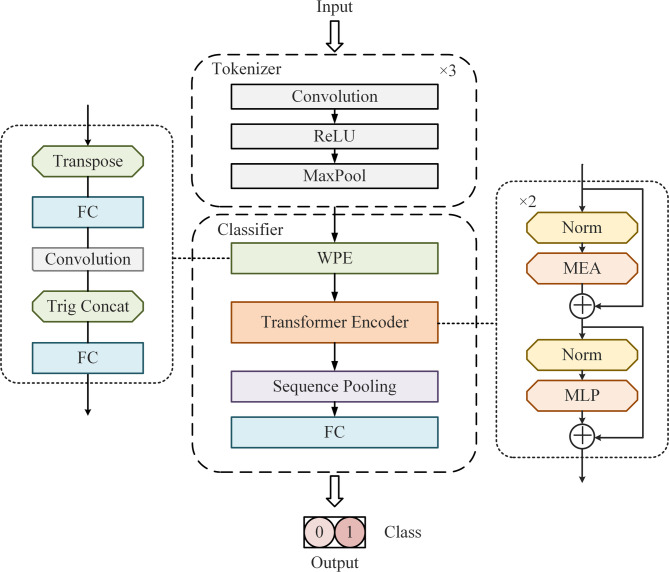 Figure 4
Figure 4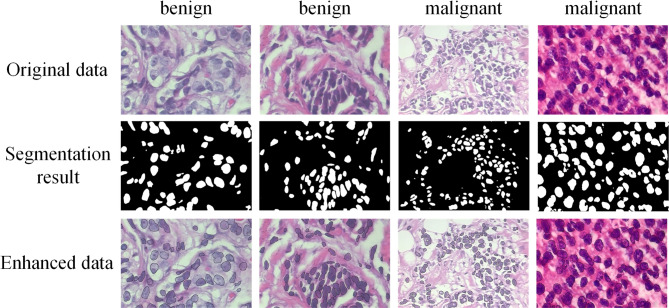 Figure 5
Figure 5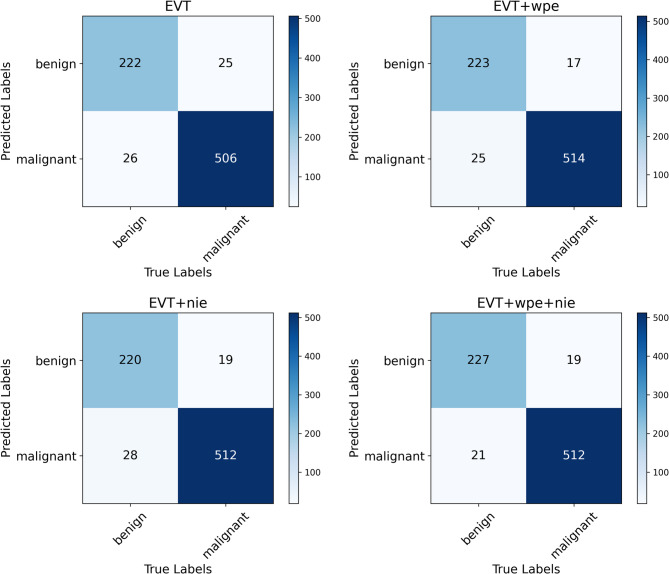 Figure 6
Figure 6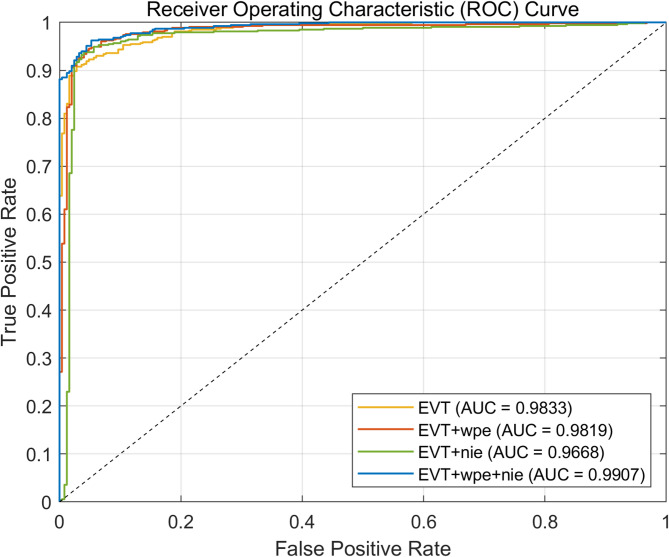 Figure 7
Figure 7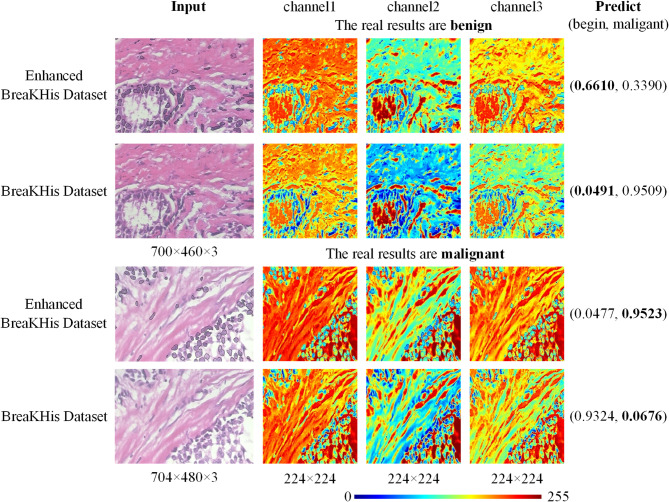 Figure 8
Figure 8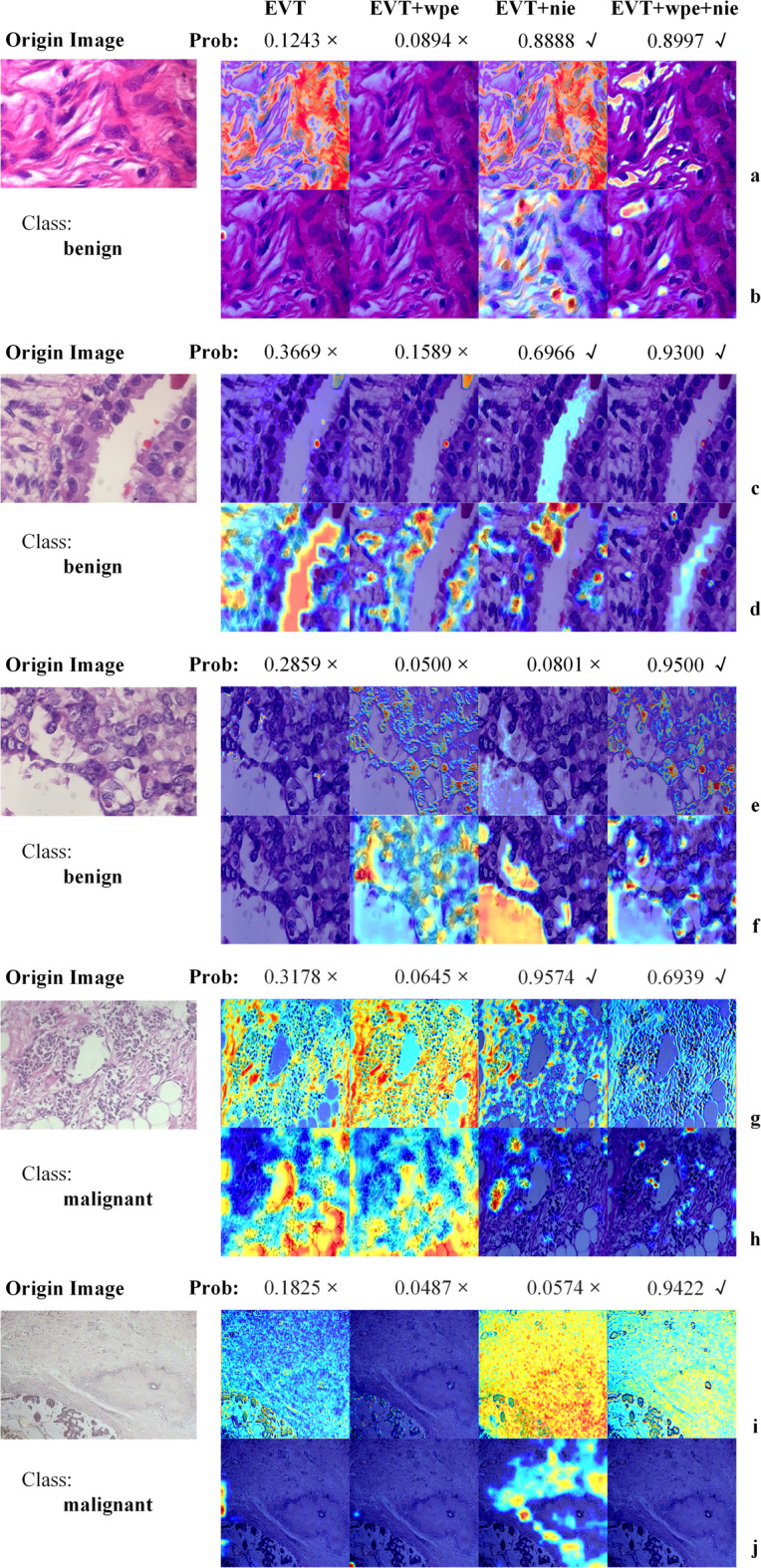 Figure 9
Figure 9- —the Major Natural Science Research Projects of the Anhui Provincial Department of Education
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAI in cancer detection · Radiomics and Machine Learning in Medical Imaging · Advanced Image Fusion Techniques
Introduction
Breast cancer is the most prevalent cancer among women globally, with significant incidence and mortality rates that pose a substantial threat to women’s health. Statistics indicate that annually, approximately 2.3 million new breast cancer cases are reported worldwide, with a slow yet consistent upward trend observed over the past 50 years^1^. In contemporary breast cancer management, precise diagnostic stratification and individualized treatment survival prediction are pivotal. However, this process largely hinges on the manual interpretation of pathological slides, which is not only time-consuming but also exhibits considerable observer-to-observer variability^2^.
The advent of microscopic image classification technology offers a new pathway to enhance the efficiency of breast cancer diagnosis. In recent years, the research significance of artificial intelligence (AI)^3^ in the medical field has become increasingly evident, with deep learning^4^ has been widely applied because of the diversity of its network structure. Among these, the convolutional neural network (CNN) has played an important role in medical image analysis, particularly in detection, classification, and segmentation tasks^5,6^. For instance, Jabeen et al. proposed to significantly improve the classification accuracy of breast lesions in ultrasound images by combining EfficientNet and ResNet deep network approaches using interpretable artificial intelligence techniques^7^. Nevertheless, the CNN’s local receptive field restricts its ability to directly capture long-range pixel relationships. Drawing inspiration from the success of a Transformer in natural language processing (NLP), Dosovitskiy et al.^8^ introduced the Vision Transformer (ViT), which possesses a crucial capability to establish long-term dependencies within the medical image receptive field^9^. However, the downsampling operation in ViT may lead to the propagation of erroneous information, thereby inducing aliasing effects^10^. To address this issue, Ding et al.^11^ proposed an enhanced wavelet position embedding vision transformer and applied it to the study of pathological image classification.
With the progression of AI, research on digital pathological images is surging, and high-resolution data has emerged as the cornerstone of such investigations. In practical applications, the processing of low-resolution images is equally important. Feature extraction^12^, a vital step in deriving useful information from images, reducing data dimensionality, and enhancing model generalization capability, holds particular significance in pathological image analysis. Primary strategies encompass learning general image features and detecting important biological components, such as the nucleus, while quantitatively characterizing their abundance and spatial organization^13^. As foremost biological element in the tissue section, the precise definition of the nucleus is indispensable for enhancing diagnostic accuracy. Compared with the machine learning algorithm, the segmentation model employed for nucleus extraction can delineate nuclear boundary with greater stability and precision, mitigating the impact of image noise, as illustrated in Fig. 1.Fig. 1. Shows the comparison of details, with raw data on the left and enhanced data on the right. (a) Differences before and after image enhancement. (b) The difference of channel 3 after normalization before and after image enhancement.
The purpose of this study is to achieve automatic classification of pathological images utilizing deep learning technology, thereby enhancing diagnostic efficiency and accuracy. Enhanced nuclear data furnish biometric features for the network, and we introduce the enhanced wavelet position embedded vision transformer (EVT_wps) to process these image features, aiming to attain precise classification of breast cancer pathological images. The key contributions of this study are as follows:
- A novel automatic classification framework for pathological images in low-resolution scenarios is constructed, significantly improving the classification accuracy of breast cancer images.
- An innovative nuclear information enhancement strategy is proposed and integrated into the baseline model, effectively enhancing the classification performance by highlighting nuclear features.
- EVT technology based on wavelet position embedding is introduced for breast cancer image classification, and its superiority in combination with nuclear information enhancement for processing complex pathology images is experimentally verified.
Related works
Analysis of pathological images of breast cancer
Breast cancer is an epithelial malignancy that originates from the terminal ductal lobular unit of the breast. Its histological morphology is exceptionally complex and can be broadly categorized into two types: non-invasive cancer and invasive cancer. Among these, invasive ductal carcinoma is the most prevalent form of breast cancer, accounting for up to 70% of cases. For a considerable period, changes in nuclear morphology have served as a crucial indicator in cancer pathology^14^. In breast cancer cells, nuclei typically exhibit enlargement and significant alterations in shape, which are observed throughout the clinical progression of the disease^15,16^.
In the study of breast cancer pathological images, there exists a close correlation between morphology features and underlying molecular characteristics^17^. This observation holds significant implications for the application of AI technology in breast cancer research. Specifically, the underlying molecular changes and biological properties can be inferred from the image features. The success of this inference process heavily relies on the quality of the image, particularly their resolution^18^. High-resolution images enable clear visualization of the microstructure and characteristics of breast cancer tissue, including nucleus shape, cellular arrangement, and blood vessel distribution, which are vital for accurate analysis and inference by AI models^5^.
However, in practical applications, obtaining images of sufficient resolution can be challenging due to various factors, such as technical limitations, sample processing issues, or storage conditions. Under such circumstances, the significance of low-resolution images becomes particularly evident. Although low-resolution images may not provide the same level of detail as a high-resolution one, they still contain valuable information^19^. Extracting key features from low-resolution images, such as specific textures, colors, shapes, etc., is equally crucial for the diagnosis and classification of breast cancer. Consequently, effectively utilizing image information in the case of low resolution has emerged as a critical challenge that needs to be addressed.
Deep learning of breast cancer
The rapid advancement of deep learning technology has enabled the practical application of computer-aided histopathological image classification in cancer diagnosis and prognosis prediction, attracting significant attention from researchers. As is well known, CNNs have demonstrated remarkable performance across various computer vision tasks^20^.
Digital pathology advances have also produced valuable datasets for precision medicine and disease research. Fatima et al. proposed a method for segmentation and classification of breast lesions based on U-Net significance estimation and interpretable residual convolutional neural networks^21^.. Recent work by Ortega-Ruíz et al. introduced DRD-UNet, an enhanced UNet variant for precise breast cancer segmentation in pathological images^22^. A new contrast enhancement technique was introduced to improve the quality of the original image. Ding et al. contributed a large-scale SHOW dataset, employing a standardized workflow and a ready-made image generator and kernel annotator^23^. Their experimental validation confirmed that ResUnet exhibits high adaptability on the SHOW dataset, achieving commendable segmentation results.
Spanhol et al. introduced the BreaKHis dataset, focusing specifically on pathological images of breast cancer^24^. They investigated the performance of 24 combinations of four classifiers in classification tasks, integrating support vector machine (SVM) with artificially designed texture features, such as adjacency threshold statistics. Their results indicated an accuracy range of 80% to 85% in distinguishing between benign and malignant breast tumors, establish in an important benchmark for the field.
On this basis, Seo et al. developed a scalable multi-instance support vector machine (SVM) framework for breast cancer detection on the BreaKHis dataset, achieving robust performance in histopathological image analysis^25^. Xiao et al. proposed a convolutional neural network (CNN) framework for breast cancer classification using cytopathology images, demonstrating its effectiveness in automated cancer diagnosis^26^. Simonyan et al. proposed a CNN-based approach for histopathological breast cancer classification, achieving an accuracy of 91.37% on the BreaKHis dataset^27^. Their results demonstrate the potential of deep learning in improving diagnostic precision for breast cancer.
Despite the widespread application of CNNs in breast cancer pathological image classification and the repeated validation of their effectiveness using the BreaKHis dataset, there remains a need for further accuracy improvements. A comprehensive performance assessment should incorporate multiple complementary metrics including the F1-score, Youden’s index, and the area under the ROC curve (AUC) to provide a more rigorous evaluation of model robustness^28^.
Transformer of pathological images
In recent years, Transformers^29^ have become a cutting-edge technology in the field of deep learning, capable of achieving robust results in a variety of computer vision tasks. Atabansi et al.^30^ pointed out that CNNs have limitations in modeling telematic and spatial dependencies, posing numerous challenges. In contrast, the Transformer architecture has demonstrated excellent performance in pathological image processing. In the field of histopathological imaging^31^, Transformer methods have been widely used in multiple aspects such as image segmentation^32^, classification^33,34^, detection^35,36^, representation^37,38^, cross-modal retrieval^39,40^, image generation^41,42^, survival analysis^43,44^, and survival prediction^45,46^.
Sriwastawa and Arul Jothi conducted a comparative study of vision transformers for breast cancer histopathology classification, reporting a top accuracy of 92.12% in their experiments^47^. Spangenberg et al.^48^ conducted a comprehensive benchmark test on five commonly used pathology datasets, comparing the latest Vision Transformer (ViT), CNNs, and their hybrid models, to evaluate the effectiveness of different classification models in histopathology image classification. They tried to incorporate convolution operations into the ViT architecture and explored two ways to combine them: one to introduce convolution in the initial phase, and the other to embed the convolution layer into each Transformer block. The experimental results demonstrate that regardless of the adopted combination strategy, the fusion of CNNs and ViT exhibits significant advantages. However, as pointed out by Qian et al., convolution blocks in the feature extraction process are prone to generating discontinuous information, which may cause confusion once it flows into the Transformer module^49^.
To address this issue, inspired by the work of Ding^11^, this paper adopts an innovative solution, the EVT incorporating wavelet position embedding technology. Wavelet position embedding is not only excels representing smooth and low-frequency components of feature maps but also in accurately capturing fine details and high-frequency parts. By incorporating wavelet position embedding, the EVT effectively addresses the aliasing phenomenon, demonstrating superior performance in processing pathological images and efficiently managing feature information.
Methods
Overview
The automatic classification scheme proposed in this research is depicted in Fig. 2, which specifically covers the following three core steps:Fig. 2. The overall flow of the method. The framework consists of three main stages: (1) Nuclear information acquisition, where the BreakHis dataset is processed by a segmentation model (2) Enhanced dataset construction, where the segmented nuclei are refined via scale-adjusted fusion and (3) Classification task implementation, where the enhanced data is.
Firstly, the edge information of the nucleus is extracted. The nuclear segmentation model was trained using the SHOW data set and ResUnet architecture. This trained model is then employed to successfully extract the edge information of nuclei from pathological images.
Secondly, an enhanced breast cancer pathology image dataset is generated. The classification data set is input into the segmentation model, and the segmentation image is fused with the original image through data processing technology, to construct a data set with significantly enhanced nuclear information.
Lastly, the classification task is executed. Leveraging the enhanced dataset obtained in Step 2, the EVT embedded with wavelet position is integrated to train.
Nuclear information enhancing
Given that diagnostic pathologists diagnose malignant tumors based on the morphological abnormalities of nuclei^50^, it is plausible that incorporating enhanced nuclei information into the training data could enhance the model’s ability to recognize and interpret the morphological features of nuclei, potentially improving its performance in screening for malignant tumors.
Consequently, this study aimed to label the nuclei in pathological images prior to inputting them into the classification network, thereby enriching the nuclear information within the images. We trained a ResUnet model on the SNOW dataset. During training, domain discrepancies between synthetic and real-world data were mitigated through data augmentation techniques such as rotation, flipping, and intensity variation. A hybrid BCE-Dice loss function was employed to ensure robust model convergence, while the StepLR scheduler was utilized to prevent the model from becoming trapped in local optima.
To enhance nuclear information for subsequent classification, this study implemented a preprocessing pipeline involving precise nuclear segmentation followed by edge augmentation. The workflow (Fig. 3) comprises four key stages:Fig. 3. Schematic diagram of nuclear fusion method. The pipeline processes histopathology images through nucleus segmentation, canny edge detection and edge strengthening.
First, we trained a ResUnet segmentation model on the SNOW dataset, employing rotation, flipping, and intensity variation augmentations to bridge the synthetic-to-real domain gap. The model’s convergence was stabilized using a hybrid BCE-Dice loss function with StepLR scheduling to avoid local optima.
For each input image, we initially resized it to a 32-divisible dimension before feeding it to the trained segmentation model. The nuclear masks are the segmentation results obtained using the ResUnet model. And the nuclear masks, rather than the original images, served as the basis for Canny edge detection. The Canny algorithm extracts edges by retaining pixels with gradient intensities between 100–200. This critical distinction ensures morphological boundaries are extracted exclusively from segmented nuclei regions. The resulting contours were then multiplicatively fused with corresponding original images to create enhanced representations that emphasize diagnostically relevant nuclear features.
Finally, the augmented images were normalized using the standard ImageNet parameters ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$mean=[0.485, 0.456, 0.406]$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$std=[0.229, 0.224, 0.225]$$\end{document} ) and converted to 3-channel tensors for classification model training and validation.
Upon examining the third channel of the transformed enhanced image, it becomes evident that the nuclear boundary is prominently highlighted, while the surrounding tissue appears relatively subdued (Fig. 1). Canny edges were multiplicatively fused with the original image to enhance nuclear morphology. This step allowed the EVT model to place relatively greater emphasis on diagnostically relevant features. This demonstrates that the method effectively retains the surrounding tissue information while emphasizing the nuclear boundary in the image, which holds significance promise for in-depth analysis of the nucleus and its surrounding environment.
An EVT with wavelet position embedding
The EVT_wpe^11^ is an end-to-end trainable architecture comprising a marker, a wavelet position embedding module, a transformer encoder, a sequence pooling layer, and a full convolution (FC) classifier module. The core innovation of this architecture lies in the introduction of wavelet transform for position embedding tasks, aiming to reduce aliasing effects during downsampling. Unlike fixed sinusoidal embeddings, WPE adapts to image patches’ spectral properties via discrete wavelet transform (DWT), minimizing aliasing artifacts during tokenization (Fig. 4). This is critical for pathological images where nuclear boundaries are high-frequency signals.Fig. 4EVT structure. The network processes input through tokenization blocks (convolution/ReLU/pooling), parallel branches (transpose/FC/attention), and a classifier with wavelet position embedding, ultimately outputting binary classification results.
In this study, we applied EVT_wpe architecture to train a breast cancer pathological image classification model, using nuclear-enhanced image data to achieve image feature extraction and classification. As depicted in Fig. 4, the tokenizer consists of three convolution blocks, each comprising a convolution layer, an activation layer, and a MaxPool layer. One of the wavelets transform technique (WPE) module processes can be expressed as follows: First, the input data is adjusted. Next, a proportional value is obtained by linear computation, then the data is convolved. A new value is computed by a trigonometric function, and then these values are combined. Finally, the processed results are merged with the original data. This process combines operations such as linear computation, convolution, and trigonometry, which are combined with augmented kernel data to extract and update features in the data. In addition, The Transformer Encoder module primarily consists of multiple multi-head attention (MHA) modules and MLP (multi-layer perceptron) modules.
The workflow of the model is as follows: Initially, the input image is processed by the tokenizer module to obtain the low-dimensional representation of the histopathological image. Subsequently, the feature-mapped WPE serves as the input to the transformer, enabling the extraction of long-range information from image patches. The Sequence information generated by the transformer encoder is then pooled using sequence pooling layer. Finally, the FC classifier output the classification results.
Experimental results and discussion
Datasets
In this work, we utilized three distinct breast cancer pathological image datasets for the training and classification experiments of the nuclear segmentation model: SNOW^23^, TNBC^13^, and BreaKHis^24^, as detailed in Table 1. both SNOW and TNBC datasets have an image resolution of 512 × 512 pixels. The SNOW dataset was randomly partitioned into a training set and a verification set in a 95:5 ration. The TNBC dataset was used to do the testing and evaluation of the segmentation model, which is a subtype of breast cancer with unique imaging characteristics and complex pathological and imaging manifestations that make it ideal for validating the effectiveness of the segmentation algorithms and the potential for clinical applications^51^. On the other hand, the BreaKHis dataset comprises benign and malignant images of breast cancer pathology, with the objective of automatically classifying these images into two categories. Specifically, within the BreaKHis dataset, it was randomly divided into training, validation, and test sets in a 7:2:1 ratio. The test set was kept consistent for the test-contrast phase, containing 248 benign and 531 malignant samples.Table 1. Data set description.DatasetCharacteristicSample sizeExperimental useSHOWA large-scale dataset of Synthetic pathology images, combined with annotations for nuclear semantic segmentation, called the Synthetic Nuclei and annOtation Wizard20,000Training of nuclear segmentation modelsTNBCFrom 11 patients with Triple Negative Breast Cancer, the dataset represents variability between patients with the same cancer type, with numerous cells documented in detail in the dataset4022Test and evaluate segmentation modelsBreaKHisFrom 82 patients, including benign and malignant images77835304 (malignant samples)2479 (benign samples)Training and validation of classification models
Evaluation metrics
We evaluated the performance of the nuclear segmentation model using the Dice score, Jaccard score, and Hausdorff distance. The Dice score, presented in Formula 1, is used to measure the similarity between two samples, calculated by doubling the intersection inter to increase its weight and dividing by the sum of the predicted region, target region, and smooth terms. The Jaccard score, shown in Formula 2, reflects the degree of overlap between the predicted and real region. The Hausdorff distance, as described in Formula 3, is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A$$\end{document} distance parameter between two subsets in a metric space, for each point in a point set a, its maximum distance to the nearest point in another point set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$B$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d(a,b)$$\end{document} represents the distance between points \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$b$$\end{document} .
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{array}{c}dice=\frac{2*inter+smooth}{su{m}_{pred}+su{m}_{targ}+smooth}\end{array}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{array}{c}jaccard=\frac{inter+smooth}{su{m}_{pred}+su{m}_{targ}-inter+smooth}\end{array}$$\end{document}In the above two equations, the prediction result tensor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$pred$$\end{document} matches the shape of the comment label tensor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$targ$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text{inter}={\text{sum}}_{\text{pred}\times \text{trag}}$$\end{document} is the global sum obtained after calculating the multiplication \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$pred\times targ$$\end{document} , represents the sum of the product of all elements in the two tensors and represents the intersection between the prediction region and the target region. The smooth value is set to 1/1e32 to avoid division by zero. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$su{m}_{pred}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$su{m}_{targ}$$\end{document} represent the sum of the tensors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$pred$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$targ$$\end{document} , respectively.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{array}{c}\hbox{Hausdorff}=\text{H}\left(\text{A},\text{B}\right)=\underset{\text{a}\in \text{A}}{\text{max}}\left\{\underset{\text{b}\in \text{B}}{\text{min}}\left\{d\left(\text{a},\text{b}\right)\right\}\right\}\end{array}$$\end{document}To evaluate the classification effect on the BreaKHis dataset, this study adopted a few technical indicators, including Accuracy, Youden index, Precision of various categories, Recall, and F1 scores, to comprehensively evaluate the performance of the classification model in the screening of breast cancer pathological images. In addition, an in-depth comparative analysis of data augmentation and wavelet position transforms was performed in EVT by calculating AUC and Kappa coefficients.
In the test sample, accuracy is defined as the proportion of samples that the model correctly classifies. The F1 score is the harmonic average of the accuracy rate and the recall rate, calculated as shown in Formula 4. In this study, there may be inference errors in the model, such as false positives or false negatives in a broad sense, which can be considered diagnostic errors or incorrect identification of positive samples. Therefore, the Youden index, as a comprehensive evaluation index combining Sensitivity and Specificity, was suitable for evaluating the performance of a specificity model, and its calculation was included in Formula 5.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{array}{c}{F}_{1}=2\times \frac{Precision\times Recall}{Precision+Recall}\end{array}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{array}{c}Youden=Sensitivity+Specificity-1\end{array}$$\end{document}The AUC is a quantitative representation of the area under the ROC curve used to evaluate the overall performance of a classification model. The horizontal coordinate of the ROC curve represents the false positive rate, that is, the probability that benign is incorrectly predicted as malignant. The ordinate represents the true positive rate, which is the likelihood that malignant is correctly predicted as malignant. Kappa is a measure of classification accuracy and is often used for consistency testing, which is calculated through the confusion matrix, as shown in Formula 6. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${p}_{0}$$\end{document} has the same meaning as accuracy, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${p}_{e}$$\end{document} is the sum of the product of actual and predicted quantities corresponding to all categories divided by the square of the total number of samples.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{array}{c}kappa=\frac{{p}_{0}-{p}_{e}}{1-{p}_{e}}\end{array}$$\end{document}Experimental details
In the training process of the nuclear segmentation model, we utilized the Adam optimizer in conjunction with a StepLR scheduler to adjust the learning rate based on the iteration step length. Specifically, the learning rate was multiplied by 0.1 every 30 iterations. Additionally, we set the random seed to 21, 42, 84 (to ensure reproducibility), the number of epochs to 100, and employed a loss function that combine binary cross-entropy loss (BCE) and Dice scores in a 1:1 ratio.
For the comparison experiment, we selected typical methods with proven performance on ImageNet as the control group, including VGG16, AlexNet, GoogleNet, ResNet34, MobileNetv2, and ViTb/16. To enhance computational efficiency, we resize the image to 224 × 224, noting that this may be result in pixel loss. Select the best model weights for inference on the test set and observe the convergence trend.
Regarding the optimization strategy, the Adam optimizer was for the first five models, whereas the stochastic gradient descent (SGD) method was employed for the ViTb/16 model. The ViT-B/16 model has a very large parameter space and SGD may be more effective in this case to avoid falling into local minima. To clarify, epochs were consistently set to 100 for all models. It is worth mentioning that the EVT_wpe model was also trained using the Adam optimizer with the hyperparameters listed in Table 2 (100 epochs, 5 warm-up steps, batch size of 2, initial learning rate of 0.001, and weight decay of 0.0001).Table 2. Common hyperparameter configurations for EVT model training.ParameterDescriptionValueEpochsTotal training rounds100WarmupWarmup steps5Batch sizeSamples per training iteration2lrInitial learning rate0.001Weight decayL2 regularization factor1e-4
It is worth noting that during the inference phase of the ablation experiments, we employed CPU-based computation and disabled all stochastic operations (including but not limited to random initialization and random sampling). Additionally, we ensured batch consistency by fixing the batch size to 1 and performing sequential inference in a predetermined order. These measures effectively mitigate the influence of random factors on the inference results, thereby guaranteeing the reproducibility of the findings.
Effect of trained nuclear segmentation model
Before extracting nuclei from pathological images of breast cancer, it is essential to construct a segmentation model suitable for pathological images. Inspired by the work of Kexin Ding^23^ et al., we utilized the SHOW dataset, which features a diverse set of breast cancer pathology images, in conjunction with the ResUnet network to train our segmentation model. This model was then validated on the TNBC^13^ dataset. The detailed description of relevant datasets are provided in Table 1.
The results of the evaluation are shown in Table 3, and it is worth noting that we did not use ImageNet as pre-training data in our work. Through observation and analysis of the data in the table, it can be found that the Dice of all models exceeds 0.75, which indicates that they all can segment the nucleus. Especially, when the seed of model weight saving is 42, the model has the best comprehensive performance in image segmentation.Table 3. Results of the training stage of the segmentation model.ModelSeedDiceJaccardHausdorff210.786490.658487.30393ResUnet420.792940.666427.30142840.779850.652197.17857Significant values are in [bold].
Therefore, we selected the model with the seed of 42 for further image processing and randomly chose four images with widely distributed nuclei for display. The segmentation results of these selected images are presented in Fig. 5, which fully satisfies the requirement for improved nuclear segmentation in the images.Fig. 5. Comparison of original data, nucleus segmentation results, and enhanced data for benign and malignant cases.
The performance of the classification models
Comparison reference model
Aiming at the classification task of breast cancer pathological images, this paper conducted a detailed experimental analysis, compared the performance of various network structures, and summarized the results in Table 4. In view of the significant influence of network depth on model convergence speed, to fully harness the performance potential of each model, we introduced pre-training weights for GoogleNet, ResNet34, MobileNetV2 and ViTb/16, aiming to use the advantages of transfer learning to accelerate the model training process and improve the final classification performance.Table 4. Summary table of the test performance of each model on the original data and enhanced data. If the accuracy, F1 score and Youden result are improved by more than 1% compared with the results of origin data, they are marked with ↑; otherwise, they are less than 1%, marked with ↓.ModelDate TypeAccClassPreRecF1YoudenVGG16Original0.8930Benign0.8470.810.8280.742Malignant0.9130.9320.922Enhanced0.9008Benign0.8540.83↑0.842↑0.764Malignant0.9220.9340.928AlexNetOriginal0.8892Benign0.8210.8340.8270.749Malignant0.9220.9150.918Enhanced0.8802Benign0.7990.835↓0.817↓0.737Malignant0.9210.9020.911GoogleNetOriginal0.9330Benign0.8950.8950.8950.846Malignant0.9510.9510.951Enhanced↑0.9472Benign0.9080.927↑0.917↑0.884Malignant0.9660.957↑0.961ResNet34Original0.8866Benign0.7990.8630.8300.761Malignant0.9330.8980.915Enhanced↑0.8995Benign0.8660.810.837↓0.751Malignant0.9140.941↑0.927MobileNetv2Original0.9059Benign0.8630.8390.8510.777Malignant0.9250.9380.931Enhanced0.9021Benign0.8570.8290.843↓0.765Malignant0.9220.9360.929DenseNetOriginal0.9422Benign0.9320.8830.9070.853Malignant0.9470.970.958Enhanced0.9448Benign0.960.8630.9090.846Malignant0.9390.9830.960ViTb/16Original0.8299Benign0.7960.6290.7030.553Malignant0.8410.9240.881Enhanced0.8299Benign0.8050.6170.6990.547Malignant0.8380.930.882EVT_wpeOriginal0.9461Benign0.9290.8990.9140.867Malignant0.9540.9680.961Enhanced0.9487Benign0.9230.9150.919↑0.879Malignant0.9610.9640.962Significant values are in [bold].
The BreaKHis dataset has significantly more malignant samples than benign samples, and this imbalance makes it difficult for the traditional accuracy (Acc) metric to fully reflect the model’s ability to classify the minority class (benign samples). Therefore, this study focuses on Recall (Rec), F1 Score and Youden Index, which are metrics that can more comprehensively measure the model’s performance when dealing with imbalanced data. Recall measures the model’s ability to recognise positive samples, the F1 score combines precision and recall, and the Youden index is used to assess the model’s balance and effectiveness in classification tasks. These metrics are particularly important when assessing the model’s ability to detect minority classes (benign samples).
As can be seen from the tabular data, the EVT_wpe model performs particularly outstandingly on the augmented dataset. For the malignant samples, the recall rate of EVT_wpe reaches 0.964, and the F1 score is 0.962, demonstrating its superior performance in handling the majority class (malignant samples). Meanwhile, for the minority class (benign samples), the recall rate of EVT_wpe is 0.915, and the F1 score is 0.919. The Youden index reaches 0.879, showing its ability to effectively identify minority class samples while maintaining a high recall rate for the majority class.
In comparison, other models perform slightly less well on the augmented dataset. For example, VGG16 has a recall rate of 0.934 and an F1 score of 0.928 for malignant samples on the augmented dataset, with a Youden index of 0.764. Although its performance is good, the Youden index is significantly lower than that of EVT_wpe. AlexNet and MobileNetv2 both show a slight decrease in various metrics on the augmented dataset and are the least suitable models for nuclear data augmentation in this study.
Compared with other models, GoogleNet has a recall rate of 0.957 and an F1 score of 0.961 for malignant samples on the augmented dataset, with a Youden index of 0.884. Although its performance is close to that of EVT_wpe, it falls slightly short in identifying the minority class, with a recall rate of 0.927 and an F1 score of 0.917. ResNet34 has a recall rate of 0.941 and an F1 score of 0.927 for malignant samples on the augmented dataset, with a Youden index of 0.751. It performs well on the majority class but still has room for improvement in identifying the minority class. DenseNet has a recall rate of 0.983 and an F1 score of 0.960 for malignant samples on the augmented dataset, with a Youden index of 0.846. Although it achieves a very high recall rate for the majority class, its recall rate for the minority class is only 0.863, with an F1 score of 0.909, indicating its deficiency in identifying the minority class. Lastly, ViTb/16 has mediocre performance on the majority class and significant shortcomings in identifying the minority class on both datasets, making it the least effective model overall.
Considering recall, F1 score and Youden index together, EVT_wpe performs well on the augmented dataset, especially when dealing with unbalanced data, and can effectively balance the ability to recognise the majority class (malignant samples) and the minority class (benign samples).
Ablation experiment
In the ablation experiments of this study, we have deeply explored the effects of nuclear information enhancement (nie) and wavelet position transform (wpe) modules on the performance of EVT models, aiming to reveal their key roles.
The experimental results are shown in Table 5, which verifies that the wpe module extracts the position information in the image by wavelet transform and enhances the model’s ability to capture the spatial structure features of the image. The experimental results show that after the introduction of the wpe module, the EVT + wpe model significantly outperforms the base EVT model in all indicators.Table 5. Ablation experiment results showing the impact of nie and wpe modules on EVT model performance, including accuracy, precision, recall, F1 score, Youden index, and Kappa coefficient.ModelAccClassPreRecF1YoudenKappaEVT0.9345Benign0.8990.8950.8970.8480.8489Malignant0.9510.9530.952EVT + wpe0.9461Benign0.9290.8990.9140.8670.8747Malignant0.9540.9680.961EVT + nie0.9397Benign0.9210.8870.9040.8510.8597Malignant0.9480.9640.956EVT + wpe + nie0.9487Benign0.9230.9150.9190.8790.8814Malignant0.9610.9640.962Significant values are in [bold].
The nie module focuses on enhancing the nuclear information features in the image, which enables the model to recognize and distinguish key nuclear structures in the image more accurately. The enhancement of the EVT + nie model is relatively small. However, when the nie module and the wpe module are jointly applied to the EVT model, the performance of the EVT + wpe + nie model is further improved, with an accuracy of 0.9487, a Youden index of 0.879, a Kappa value of 0.8814. We record the experimental of the confusion matrix, as shown in Fig. 6, and calculate the kappa value. The kappa value of the EVT + wpe + nie model has a significant increase, indicating a slight improvement in model consistency. We also plotted the ROC curves (Fig. 7), and the blue curve has the best classification cardinality up to 0.99, which is significantly higher than the other methods. This result further confirms the superiority of the synergistic effect of the two modules. The synergy of the two modules can mine image features more comprehensively, giving the EVT model a stronger classification capability when dealing with breast cancer pathology data exemplified by BreaKHis.Fig. 6. Confusion matrices comparing test data performance of EVT models with nuclear information enhancement and wavelet position transform.Fig. 7ROC curves and AUC values illustrating the classification performance of various EVT model combinations on test data.
Visual analysis
To explore the specific effects of the nuclear enhancement method, we focused on the behavior of the tokenizer, a component network architecture, during data processing. We obtain the tensors before the tokenizer’s last flattener operation, which can be crucial for the subsequent Classifier. To visually demonstrate the key areas that a particular layer focuses on when processing data, we first carefully processed the tensor: First, we normalized each channel to ensure data consistency. Next, we scaled the normalized data by multiplying it by 255 to enhance visualization. Finally, we applied colormap technology to transform the processed tensor into an easily observable visualization, as shown in Fig. 8.Fig. 8. The color map is displayed after normalizing the tensor before the last flattener operation in the tokenizer.
In two categories of begin and malignant, we selected images with incorrect prediction from the original data and images with correct prediction from the corresponding nuclear enhancement data for observation. We identified certain phenomena during network processing. Specifically, in the raw data, the tensor reflects a greater focus on the distribution of extracellular tissues across the three channels, while giving less weight to the nucleus, as shown by the blue areas representing the nucleus. This may hinder the network’s ability to recognize the nucleus and its related features, thereby reducing a classification accuracy. However, in the enhanced data, we found that the network not only continued to focus on the distribution of extracellular tissues, but also increased the weight given to the interior of the nucleus. This change allows the network to capture and identify the features of the nucleus, which is likely to be one of the factors contributing to the improved accuracy of classification. At the same time, we also noticed that a significant reduction in the network’s attention to the nuclear edge in the enhanced data. This suggests that the network may prioritize internal nuclear features over edge information due to the decreased weight assigned to the nuclear edge.
To better understand the role of cytosolic enhancement in EVT, we further used Grad-CAM (Gradient-weighted Class ActivationMapping) technique^52^ to visualize the key layers of the network. With Grad-CAM, we can visualize how much the network pays attention to different regions in the decision-making process, and thus observe the effect of nucleus enhancement on the network^48^. The specific visualization results are shown in Fig. 9. We chose two layers, model.tokenizer.conv_layers[0][0](Fig. 9acegi) and model.tokenizer.conv_layers[2][2](Fig. 9bdfhj), for visualization. The model.tokenizer.conv_layers[0][0] is the first convolutional layer in the network, which is responsible for extracting low-level features of the input data, such as edges and texture information, which are crucial for subsequent feature extraction and classification tasks. And the model.tokenizer.conv_layers[2][2] is the last maximum pooling layer in the tokenizer module, which serves to reduce the spatial dimensionality of the feature maps while retaining the key feature information, thus reducing the computational effort and enhancing the robustness of the features. The visualization results of this layer help to reveal the information processing and filtering mechanisms of the network before and after data enhancement at the end stage of feature extraction.Fig. 9. Network model visualization. The a, c, e, g and i is the model.tokenizer.conv_layers[0][0] layer, the first convolutional layer in the network. The b, d, f, h and j is the Model.Tokenizer.conv_layers[2][2] layer, which is the last maximum pooling layer of the tokenizer module.
In Fig. 9, by comparing EVT and EVT + nie network visualizations in subfigures b, c, d, e, g and h, it is evident that nuclear enhancement leads to a significant reduction in the weight of surrounding tissue. However, in subfigures f, i, and j, despite the application of data enhancement, the model failed to properly reduce the weight of the surrounding tissue, resulting in a decline in the accuracy of the predicted results. This phenomenon further confirms the necessity of appropriately reducing the weight of surrounding tissue to improve the accuracy of prediction in image analysis. When we combine nuclear information (nie) enhancement with wavelet position transformation (wpe) technology, as shown in subfigures e and g comparing EVT + wpe and EVT + wpe + nie network visualization, we can see that this combination can capture nuclear edge features more accurately. Further analysis of the results of EVT + nie and EVT + wpe + nie in subfigures e, f, i and j shows that, in some cases, when the model misunderstands some features, the nuclear boundary features can be obtained more clearly after combining the wavelet position transformation, and the weight of the surrounding tissue is relatively weakened, and the inference can be correct.
Convolutional Neural Networks (CNNs) primarily rely on local receptive fields (small kernel convolutions), inherently probably limiting their capacity to model in histopathology images (citation needed)^29^. It can be known from the Grad-CAM visualization (Fig. 9) that the EVT_wpe model based on NIE significantly reduces the attention to non-kernel regions (such as interstitium) in the decision-making process. As demonstrated in Table 4, a CNN (e.g., ResNet34) may misclassify benign regions with dense stromal texture as malignant (recall: 0.898) due to its inability to disambiguate local textural similarities, whereas the EVT_wpe model achieves superior recall (0.968) by leveraging global context. In summary, the results of this study show that the combination of nuclear enhancement and wavelet position transformation technology can effectively improve the localization of nuclear edge in image analysis and reduce the weight of extranuclear tissue, which has important theoretical significance for improving the accuracy of pathological image classification.
Conclusions
In this paper, we propose a segmentation model-based classification and processing framework for breast cancer pathological images, aimed at enhancing the accuracy of classification through data enhancement techniques. The introduced data processing framework, nuclear enhancement combined with wavelet position transformation, can more accurately locate nuclear boundaries in image visualization analysis, further weaken the weight of extranuclear tissue information, and thus optimize the pertinence and accuracy of feature extraction. This has a favorable influence on the model’s comprehensive analysis of the pathological image. Furthermore, we introduce an EVT utilizing wavelet position embedding and demonstrate its feasibility and effectiveness by comparing it with the baseline network structure on the BreaKHis dataset.
Currently, the high-performance networks are extensively utilized in medical image analysis, and our EVT, grounded in wavelet position embedding, offers robust support for breast cancer pathological image classification research and exhibits promising performance. However, it is important to acknowledge that our study still has limitations. For instance, the segmentation model used for nucleus extraction has considerable potential for improvement, and the classification performance may be further enhanced with more accurate segmentation. In the future, more advanced hyperparameter optimization techniques will be explored. In response to the criticism of our framework, the performance of the EVT model can be further improved by adjusting the intensity of nuclear information enhancement. It is noteworthy that, despite the nucleus segmentation model selected in this study having considerable potential for improvement, the classification effect still demonstrates a positive effect, even when the nucleus segmentation quality is suboptimal. Hence, it can be inferred that as the segmentation performance improves, the corresponding classification performance will also elevate. Breast cancer typically arises from intraductal carcinoma, where cancerous cells breach the ductal basement membrane and invade the stromal cells. To further improve tumor screening accuracy, future work could explore catheter-stromal interactions in pathological images. Additionally, the generalizability of our method should be validated across diverse datasets to ensure robust clinical performance.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Sung, H., Ferlay, J. & Siegel, R. L., et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA 71(3), 209–249 (2021).10.3322/caac.2166033538338 · doi ↗ · pubmed ↗
- 2Jabeen, K., Khan, M. A. & Hamza, A., et al. An Efficient Net integrated Res Net deep network and explainable AI for breast lesion classification from ultrasound images. CAAI Trans. Intell. Technol. (2024).
- 3Dosovitskiy, A. An image is worth 16x 16 words: Transformers for image recognition at scale. ar Xiv preprint ar Xiv:2010.11929, 2020.
- 4Sabottke, C. F. & Spieler, B. M. The effect of image resolution on deep learning in radiography. Radiol. Artif. Intell.2(1), 90015 (2020).10.1148/ryai.2019190015 PMC 801738533937810 · doi ↗ · pubmed ↗
- 5Fatima, M., Khan, M, A. & Shaheen, S., et al. Breast lesion segmentation and classification using U-Net saliency estimation and explainable residual convolutional neural network. Fractals 10, S 0218348 X 24400607 (2024).
- 6Ortega-Ruíz, M. A., Karabağ, C. & Roman-Rangel, E., et al. DRD-U Net, a U Net-like architecture for multi-class breast cancer semantic segmentation. IEEE Access (2024).
- 7Seo, H., Brand, L. & Barco, L. S., et al. Scaling multi-instance support vector machine to breast cancer detection on the Brea K His dataset. Bioinformatics 38(Supplement_1): i 92–i 100 (2022).10.1093/bioinformatics/btac 267PMC 923547535758811 · doi ↗ · pubmed ↗
- 8Xiao, M. X., Li, Y. & Yan, X., et al. Convolutional neural network classification of cancer cytopathology images: Taking breast cancer as an example. Proceedings of the 2024 7th International Conference on Machine Vision and Applications, 145–149 (2024).