Bayesian Thurstonian IRT Modeling: Logical Dependencies as an Accurate Reflection of Thurstone’s Law of Comparative Judgment
Hannah Heister, Philipp Doebler, Susanne Frick

TL;DR
This paper introduces a Bayesian Thurstonian IRT model that accurately accounts for logical and stochastic dependencies in forced-choice data.
Contribution
The novel approach reduces computational effort by respecting logical and stochastic dependencies in Thurstonian IRT.
Findings
The Bayesian implementation respects both logical and stochastic dependencies in the Thurstonian IRT model.
A simulation shows a significant reduction in computational effort with the new approach.
The model ensures correct parameter estimation by eliminating impossible answer patterns.
Abstract
Thurstonian item response theory (Thurstonian IRT) is a well-established approach to latent trait estimation with forced choice data of arbitrary block lengths. In the forced choice format, test takers rank statements within each block. This rank is coded with binary variables. Since each rank is awarded exactly once per block, stochastic dependencies arise, for example, when options A and B have ranks 1 and 3, C must have rank 2 in a block of length 3. Although the original implementation of the Thurstonian IRT model can recover parameters well, it is not completely true to the mathematical model and Thurstone’s law of comparative judgment, as impossible binary answer patterns have a positive probability. We refer to this problem as stochastic dependencies and it is due to unconstrained item intercepts. In addition, there are redundant binary comparisons resulting in what we call…
Click any figure to enlarge with its caption.
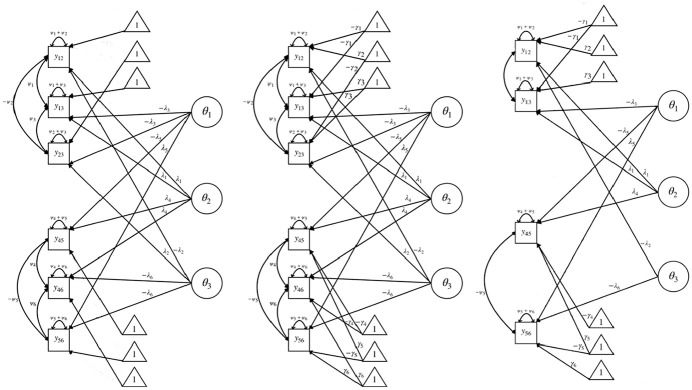 Figure 1
Figure 1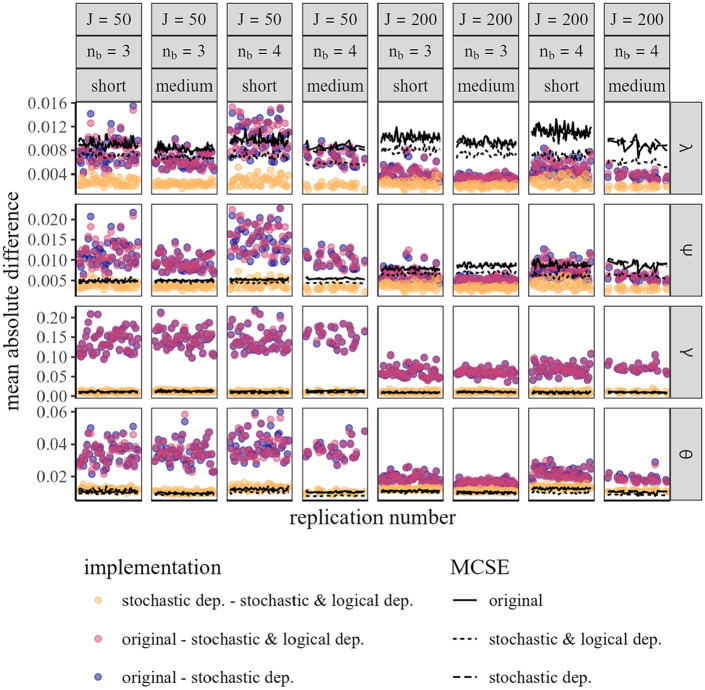 Figure 2
Figure 2 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSchool Choice and Performance · Psychometric Methodologies and Testing
Introduction
Personality questionnaires are ubiquitous in most areas of psychological assessment and education. Constructs like personality and motivation can explain variance in achievement beyond ability. However, an accurate scoring of responses to personality questionnaires is necessary for decisions based on them to be reliable and fair. The multidimensional forced-choice (MFC) format has become popular as a response format in personality questionnaires. In the MFC format, participants have to rank order items measuring different attributes. The MFC format avoids response biases such as, for example, halo effects (Brown et al., 2017) or extreme response style (Brown & Maydeu-Olivares, 2018). Furthermore, it reduces faking compared to rating scales (Cao & Drasgow, 2019; Wetzel et al., 2021).
The scoring of MFC data according to classical test theory results in ipsative scores. Ipsative scoring distorts correlation-based analyses (Clemans, 1966) and the scores should not be compared between persons (Closs, 1996; Johnson et al., 1988). Normative scoring of MFC data has become possible with advances in the computation of item response theory (IRT) models. Brown (2016) gives an overview of IRT models for forced-choice response formats. The most popular IRT model for MFC data is the Thurstonian IRT (T-IRT) model (Brown & Maydeu-Olivares, 2011). Thurstonian IRT scoring of MFC data results in normative scores (Brown & Maydeu-Olivares, 2013; Frick et al., 2023). Moreover, the Thurstonian IRT model is the most widely applicable IRT model for MFC data since it can accommodate various response formats and instructions (Brown & Maydeu-Olivares, 2018). To estimate the Thurstonian IRT model, the rankings are re-coded into pairwise item comparisons. Each possible combination of two items is considered once. Exemplary, this is illustrated for a block of length 3 with the realized ranking :
In the original implementation (Brown & Maydeu-Olivares, 2011, 2012), the intercepts for the pairwise comparisons are unconstrained, that is, a set of item intercepts that comply with them does not have to exist. However, since the data are indeed item rankings, they imply stochastic dependencies that this model specification does not account for, as we will show in the following.
In addition, in the original implementation, the person parameters were estimated with maximum likelihood or maximum a posteriori estimation. This person parameter estimation is based on the product of dependent normal distributions (for block sizes ) and therefore overestimates the precision and underestimates the standard errors (Brown & Maydeu-Olivares, 2011; Frick et al., 2023; Yousfi, 2020). The same applies to the Bayesian implementation in the R package thurstonianIRT (Bürkner et al., 2019). Based on the observation that ranking data can be correctly expressed using a multivariate distribution and considering only independent pairwise comparisons (Maydeu-Olivares, 1999), Yousfi (2020) proposed an alternative method for person parameter estimation that yields correct standard errors. We will term the dependencies that arise between redundant pairwise comparisons logical dependencies in the following.
This research aims to investigate the effect of considering logical dependencies, both analytically (for block size 3) and in a simulation (for block sizes 3 and 4). We show analytically that logical dependencies do not play a role as long as stochastic dependencies are considered. We propose a new Bayesian implementation of the Thurstonian IRT model using a multivariate distribution. In the following, we will first present the Thurstonian IRT model, then explicate our definitions of stochastic and logical dependencies and give an intuition of the related proof. The full proof can be found in the Appendix. Afterward, we will present a simulation that compares three implementations: considering both types of dependencies, neglecting logical ones, and the original that neglects both types of dependencies. We will end with a discussion on the implications of our investigation for item and person parameter estimation in practice.
The Thurstonian IRT Model
The Thurstonian IRT model is based on the law of comparative judgment (Thurstone, 1927), which states that test takers compare statements pairwise when ranking multiple options. This justifies that a person’s ranking can be viewed as a series of binary item comparisons. It is assumed that the rank of each statement within a block is determined by the test takers latent utility toward that statement. Next to statement-specific characteristics, a test taker’s utility toward a statement is influenced by latent traits , common factors ideally corresponding directly to psychological constructs. For test taker , the utility toward statement is expressed as the linear function:
where denotes the latent utility mean, the vector of factor loadings of the statement on the test taker’s latent traits , and the random error. The errors in each statement’s utility are assumed to be independent , while the latent traits can correlate. In the following, we assume that each statement only measures one trait (simple structure); therefore, has only one non-zero entry, denoted by . When test takers rank statements, the statements are ranked in order of their utility. The higher the utility, the higher the statement is ranked. The binary outcome for two statements and can therefore be expressed as:
Note that there is no further error term as the ranking is considered to be transitive. The probability of test taker preferring statement over statement can be calculated from the model parameters with:
where is the -th diagonal entry of .
To represent the full response pattern in a block of length , all binary comparisons are considered, although some could be redundant by transitivity. Each statement is compared with its subsequent statements in the indexing of statements. The compared statements are coded in a design matrix of the comparisons that determines which utility differences are computed. Each row of relates to one of the binary comparisons while each column corresponds to one of the statements. For a single block of length , the design matrix is therefore defined as:
When modeling multiple blocks instead of just one, becomes a block diagonal matrix with dimensions . The response model of the full questionnaire for test taker expands to:
where is the matrix of the factor loading with row vectors . The constraint is not imposed in the original model (Brown & Maydeu-Olivares, 2011), and an unrestricted is estimated. We will discuss the implications of this simplification in the next section. The vector of utility differences is multivariate normal,
and since the covariance matrix is not diagonal, dependencies between statement comparisons exist. In fact, we will discuss below that since does not have full rank, the normal distribution is degenerate with a singular covariance matrix .
Dependencies in the Thurstonian IRT Model
The Thurstonian IRT model utilizes that each ranking can be unequivocally decoded into a pattern of binary comparisons. The other way around, this does not hold true: By transitivity, out of all binary patterns, only can result from a ranking. This leads to dependencies in the binary pattern for a block length larger than two. Vividly, this can be illustrated by the pattern , which was already considered in the introduction. When we know about a block consisting of statements , that is ranked above and that is ranked below we can directly follow that is ranked below . Ranking below would be illogical. For all binary patterns, it holds true that only well-chosen comparisons are sufficient to derive the full pattern. The original Thurstonian IRT only partially considers those dependencies. We proceed by disentangling what we call stochastic and logical dependencies.
Stochastic Dependencies
In the T-IRT model, intercepts are not restricted, for example, maybe counter to what one might expect, must not hold true. Thus, the model does not fully account for dependencies on the item parameters, making the realization of illogical, intransitive patterns of binary comparisons theoretically possible. This can be illustrated by creating the intransitive pattern for test taker . For this, and must hold. When considering the sum of and , this results in:
The comparison with shows that the illogical pattern can only be realized if:
holds true. While this is possible, if are independently estimated, this is not possible, if the constraint is imposed. Imposing the constraint ensures that holds true. To avoid illogical patterns and to take the stochastic dependencies fully into account, has to be constrained. Only the model with constrained intercepts completely fulfills Thurstone’s law.
Logical Dependencies
Another concern is the fact that the information between considered binary comparisons is partially redundant which results in logical dependencies. To circumvent these dependencies, one can take only neighboring ranking comparisons into account, which results in independent comparisons per block (Maydeu-Olivares, 1999; Yousfi, 2020). This is sufficient to derive the full pattern, as long as stochastic dependencies are considered. The corresponding proof for block length 3 is in the Appendix. For larger block lengths, an analogous proof can be developed.
For an intuitive argument, assume , and correspond to the true test taker’s utility differences. Then, the probability density of realizing the utility difference corresponding to the full binary pattern is equal to the probability density of realizing the utility difference corresponding to the reduced binary pattern times the Dirac measure :
If stochastic dependencies are considered, the Dirac measure is always one and the density of the subset of utility differences is identical to the density of all utility differences. Hence, the density of can be defined as the density of a subset of utility differences. If stochastic dependencies are not considered, impossible patterns can have a non-zero probability. For block length greater than two, not every subset of comparisons is sufficient. It is the subset of neighboring comparisons that is sufficient for every block length.
More so, this subset is sufficient to derive the full answer pattern. Why would a different subset of size not suffice? This can be illustrated by the statements , where and . We cannot infer whether or has a higher utility. In other words, the most informative comparisons are needed to recover the answer pattern—the comparisons between statements with neighboring ranks. The closer the ranks, the lower the uncertainty about the utility differences and hence the latent variables. This becomes clear from an IRT perspective: When the probability of preferring over is , the binomial likelihood of the binary comparison implies that the Fisher information of the latent variable is the largest. An optimal probability of .5 practically means that data on utilities close to each other are more informative. Note that the best and worst-ranked statements hold less information about the absolute position of the corresponding than other statements. Which statements have a neighboring rank depends on the test taker’s answer pattern. Hence, in the following, the design matrix becomes a person-specific matrix which is only equal for persons with the exact same or the exact opposite ranking.
Conditional on other parameters, the answer pattern probabilities are products of the probabilities of single binary comparisons. The proposed estimation process directly uses the multivariate structure of the binary comparisons, accounting for logical dependencies in the process. This leads to a more economical use of data. While this could make the estimation process more efficient, it does not affect the estimated model, as shown in the Appendix.
To illustrate the theoretical implications of considering stochastic and logical dependencies, three path diagrams consisting of two blocks of length 3 are displayed in Figure 1. The left diagram shows the original T-IRT model, the one in the middle shows the version considering only stochastic dependencies and the right one shows the version considering both stochastic and logical dependencies, exemplary for the realized pattern . Apart from the statement intercepts, all three diagrams include the same parameters. They only differ in the amount of included equations. The two diagrams considering stochastic dependencies include the same parameters and are equivalent.
Path diagrams for the original T-IRT model (left), the version considering only stochastic dependencies (middle) and the version considering both stochastic and logical dependencies (left), for the answer pattern (2,1,3,1,2,3) . Correlations between θ are not displayed in the path diagrams for the sake of simplicity as they are identical for all possible T-IRT path diagrams.
Simulation Study
To compare the performance of these three T-IRT implementations, original, stochastic dependencies, and stochastic & logical dependencies, a simulation study is performed. To gain insight into the performance depending on the conditions specified by the test constructor, we vary the block length, the test length, and the sample size in two settings each. The block length is of particular interest because it controls the strength of the logical dependencies. Since dependencies only occur for block lengths greater than 2 and the cognitive load increases with block length (Brown & Maydeu-Olivares, 2011), we investigate block lengths and . To vary the test lengths, the length of the resulting full binary patterns is varied between 30 (short test) and 60 (medium test). For the different block lengths, this means that blocks for and blocks for are investigated. The sample size is chosen to be . These factors are evaluated in a fully crossed design. Each of the 12 settings is evaluated with 50 replications. To keep the number of varied parameters to a minimum, we chose to keep factors that do not affect the dependencies between items constant. Such factors are the correlation between traits and the proportion of negatively keyed items. For these parameters, we tried to mimic values commonly found in practice. The response model is the T-IRT model with , , , and . The simulated tests measure five traits with a trait correlation mimicking the “Big 5” from van der Linden et al. (2010). The proportion of unequally keyed items is kept at two-thirds. The models are implemented with weakly informative priors that should fit all common data. All parameters have a normally distributed prior with varying mean and standard deviation:
with being the set of factor loadings with positive item keying and the ones with negative item keying. For drawing correlated trait parameters , the Cholesky LKJ correlation distribution, a common default prior for covariance and correlation matrices, is used. With the distribution’s scale parameter being set to 1, the density over all correlation matrices is uniform. The intercept results from the sum , as intercepts are drawn per item, this leads to . According to Bürkner et al. (2019), these priors improve sampling efficiency and convergence while mildly influencing parameter estimates.
The simulation study and its evaluation are carried out using the software R (R Core Team, 2024) version 4.2.2. All implementations of the Thurstonian IRT model are implemented using Stan (Stan Development Team, 2024) software. The interface between R and Stan is established through the rstan package (Stan Development Team, 2022) version 2.26.1. The package mvtnorm (Genz et al., 2024) version 1.1-3 is used for data simulation,. The microbenchmark function from the package microbenchmark (Mersmann, 2024) version 1.4.10 was used to evaluate the computational time of each implementation. In addition, the package ggplot2 (Wickham, 2016) version 3.4.2 was used for visualization. The R-code for the simulation as well as the Stan-code of the three Thurstonian IRT model implementations are available on OSF https://osf.io/8fndw/.
Simulation Results
We compare deviations between estimates to evaluate the performance of the three implementations based on their parameter estimates. Figure 2 illustrates the differences between parameter estimates alongside the respective Monte-Carlo standard errors (MCSEs). It is visible that the parameters from the implementation stochastic dep. and stochastic & logical dep. share a higher similarity than the estimates resulting from the original implementation. This is expected behavior as we showed for block length 3 that these two implementations are equivalent. Differences between them are within or even below the MCSE. This strongly indicates that the equivalence holds true also for block lengths larger than 3. The intensity of difference between these two implementations and the original implementation depends on the simulation settings and the parameter group. For the factor loadings , differences between implementations are always within or below the MCSE. For the covariance of the errors , the differences are above the MCSE for the sample size 50 and within the sample size 200. For the intercepts and the latent traits , the difference is consistently above the standard error of the estimation. Since intercepts are defined differently in the implementations (constrained vs. unconstrained), these are expected to differ. This also affects the trait estimation, which is unexpected. However, the magnitude of those differences is small and therefore should have no practical relevance in use cases the authors envision.
Average absolute difference between estimates of the estimation methods (dots) and the average MCSEs (lines) per setting and replication.Note. MCSE = Monte-Carlo standard error.
Generally, differences between implementations decrease with increasing information, in the form of sample size and test length. When increasing the block length, the differences between the original implementation and the others increase. This behavior has two possible explanations. First, with increasing block length, dependencies increase, therefore ignoring them leads to a larger mismatch between the estimates. Second, since the number of full comparisons is held constant, the information contained in the test is smaller for larger block lengths, and therefore differences become larger.
The MCSE for the implementation stochastic & logical dep. is lower than for the other two implementations. This is an indicator that sampling is more efficient when considering stochastic and logical dependencies. This can be also seen when investigating convergence. While, according to the effective sample size and , all models converged for all investigated samples, the estimated effective sample size was often a bit larger for the implementation stochastic & logical dep. rather than the other two implementations. This phenomenon has been exemplary illustrated in the empirical example in Table 2. Since there seems to be a systematic difference in efficiency per Monte-Carlo iteration, it is of interest to see whether this is reflected in computation time, too. Table 1 contains the average (and standard deviation) computation time over all 50 replications per setting. These times were achieved on a cluster running 4 parallel chains for each model for 2,000 iterations, using 4 cores per model.
Table 1.: Average Run Times in Hours and Their Standard Deviations Over 50 Replications per Simulation Setting.
It is obvious that across settings, the required computation time is at least by the factor 10 smaller in the implementation stochastic & logical dep. than in the other two implementations. The difference between those is way smaller; however, the implementation stochastic dep. is always a bit faster than the original implementation. In addition, it is interesting to see that the ratio between implementations is stable for both sample sizes. This indicates that the larger the sample gets the greater the added value of the implementation stochastic & logical dep. Unsurprisingly, the longer the test, the higher the required computation time.
The computation time changes only mildly with the block length. However, an interesting phenomenon is observable. While computation time mildly increases with increasing block length for the two implementations stochastic dep. and original, it decreases for the implementation stochastic & logical dep. This behavior can be explained with the simulation setup. A larger block length leads to more dependencies between the statement comparisons if all binary comparisons are considered, this increases the computation time for those implementations. However, since the number of all binary compared statements is held constant, the number of independent comparisons decreases with block length resulting in a faster computation time for the implementation stochastic & logical dep.
Empirical Example
To demonstrate that all three versions of the Thurstonian IRT model implementation can be fitted to real-world data and to explore the practical implications of these implementations, the models were applied to data from a personality test. The test is a modified version of the Big Five Inventory-2 (BFI-2) in a forced-choice design, measuring the five personality traits openness, conscientiousness, extraversion, agreeableness, and neuroticism. Each of these traits is assessed with 12 statements, resulting in a total of 60 statements. The statements are presented in pairs of 3, resulting in 20 blocks. Each block consists of positively and negatively coded statements. The proportion of positively and negatively coded items is almost balanced, with 29 positively and 31 negatively coded statements. The test was administered to 1,031 participants, of whom 94 were excluded from the analysis due to missing values. The data were collected in the study by Kupffer et al. (2024). In this study, participants were asked to complete six questionnaires, one of which was the BFI-2. The data were collected in an online survey that was conducted over a 2-week period in September and October 2017. All participants were from English-speaking countries, with a mean age of 36 years (SD = 11), and 46% of the participants were male. More details about the data collection process and the test can be found in the original study documentation from Kupffer et al. (2024).
All the implementations of the Thurstonian IRT model converged when fitting them to the data. This can be seen in Table 2, as all values fall below the threshold of 1.1 and nearly all parameters have an effective sample size beyond 400. It is to see that and indicate better convergence for the implementation stochastic & logical dep. rather than the two competing implementations. This is also supported by differences in computation time. While the implementation stochastic & logical dep. already took 14 hr to run, stochastic dep. and original took 99 hr.
Table 2.: Effective Sample Size ( neff ) and R^ in the Empirical Example per Implementation.
When investigating the point estimates one can see, analogous to the simulation results, a high agreement between the parameter estimates of all three implementations, see Figure 3. One can see that the estimates of all models align nearly perfectly, which shows that the parameter recovery is not strongly affected by the choice of implementation.
Scatterplot of estimated model parameters for each implementation plotted against those resulting from the implementation stochastic & logical dep.
To see whether the small differences affect the model fit, we compare the widely applicable information criterion (WAIC) for the three models. As illustrated in Table 3, the implementation stochastic & logical dependencies should be preferred, as it resulted in the highest predictive accuracy. Followed by the implementation stochastic dependencies and original having the lowest predictive accuracy. However, part of the difference in fit is due to the difference in the constants of the multivariate normal distributions. As we note in Equation (A7) in the Appendix, the general density of a singular normal distribution is , where are the non-zero eigenvalues. Consequently, a three-dimensional multivariate normal with factor differs from the correct factor of a two-dimensional multivariate normal by a factor of Each multivariate observation hence changes the log-likelihoods by , which sums roughly to the magnitude of the observed differences in elpds. In addition, small differences can stem from differences in convergence and the Markov chain Monte Carlo (MCMC) sampling. Overall, the fit appears to increase slightly when using the implementation stochastic & logical dependencies. Although this only leads to small differences in the parameter estimates, the substantial reduction in computation time might be of interest to practitioners.
Table 3.: Estimated WAIC Values in the Empirical Example per Implementation.
Discussion
The objective of this study is to investigate whether the parameter estimates of the Bayesian Thurstonian IRT model are affected by the consideration of dependencies within blocks. In the originally defined Thurstonian IRT model, two types of dependencies occur. One are stochastic dependencies, resulting in illogical answer patterns, which can be avoided by constraining the utility intercepts. The other are logical dependencies at the test taker level due to redundant information in binary comparisons. These can be eliminated by considering only item comparisons with neighboring ranks. A theoretical comparison was made between the likelihoods of implementations that consider and neglect logical dependencies on the test taker level while considering stochastic dependencies. The comparison showed that for a block length of 3, the likelihoods are identical. Since both implementations are based on the same item and trait parameters with identical prior distribution, this results in equal posterior estimates. The authors assume that the proof generalizes to block lengths larger than 3.
To investigate the effect of constrained intercepts on parameter estimation, a simulation study was conducted. The study showed that accounting for stochastic dependencies leads to estimates that are as accurate, if not slightly more accurate, than those from the original T-IRT model. Since constraining the model has only been proposed by Brown and Maydeu-Olivares (2011) to enable person parameter estimation, there is no theoretical reasoning not to constrain the intercepts. Furthermore, by constraining the intercepts, the model adheres to Thurstone’s (1927) Law of Comparative Judgment. As such, it reflects the ranking process of individuals more accurately, as they cannot give intransitive rankings. Therefore, since current software enables us to consider stochastic dependencies, these should be considered in the Thurstonian IRT model.
The two implementations that consider stochastic dependencies but either consider or neglect logical dependencies are highly similar for all investigated settings. Especially interesting is that this similarity did not change with block lengths (3 and 4). While this supports the assumption of equivalent parameter estimates, the computational efficiency in the forms of convergence and computation time differs strongly between these implementations. When additional logical dependencies were considered, the computation time decreased drastically alongside a decrease in the MCSEs.
Therefore, considering both stochastic and logical dependencies in Thurstonian IRT model estimation has several advantages without any drawbacks. We recommended users utilize a T-IRT implementation that considers logical dependencies. For those interested in Bayesian model estimation, this paper provides the necessary code. The provided Bayesian implementation has the huge advantage that it can be easily extended. Researchers interested in extensions like multi-group models can adapt the stan code by changing only a few lines. Nevertheless, this idea can also be employed for frequentist estimation. Future research could implement this idea in frequentist models, to enable an even faster implementation.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Brown A. (2016). Item response models for forced-choice questionnaires: A common framework. Psychometrika, 81(1), 135–160. 10.1007/s 11336-014-9434-925663304 · doi ↗ · pubmed ↗
- 2Brown A. Inceoglu I. Lin Y. (2017). Preventing rater biases in 360-degree feedback by forcing choice. Organizational Research Methods, 20(1), 121–148. 10.1177/1094428116668036 · doi ↗
- 3Brown A. Maydeu-Olivares A. (2011). Item response modeling of forced-choice questionnaires. Educational and Psychological Measurement, 71(3), 460–502. 10.1177/0013164410375112 · doi ↗
- 4Brown A. Maydeu-Olivares A. (2012). Fitting a Thurstonian IRT model to forced-choice data using Mplus. Behavior Research Methods, 44(4), 1135–1147. 10.3758/s 13428-012-0217-x 22733226 · doi ↗ · pubmed ↗
- 5Brown A. Maydeu-Olivares A. (2013). How IRT can solve problems of ipsative data in forced-choice questionnaires. Psychological Methods, 18(1), 36–52. 10.1037/a 003064123148475 · doi ↗ · pubmed ↗
- 6Brown A. Maydeu-Olivares A. (2018). Modeling forced-choice response formats. In Irwing P. Booth T. Hughes D. (Eds.), The Wiley handbook of psychometric testing (pp. 523–570). Wiley-Blackwell. 10.1002/9781118489772.ch 18 · doi ↗
- 7Bürkner P.-C. Schulte N. Holling H. (2019). On the statistical and practical limitations of thurstonian irt models. Educational and Psychological Measurement, 79(5), 827–854.31488915 10.1177/0013164419832063 PMC 6713979 · doi ↗ · pubmed ↗
- 8Cao M. Drasgow F. (2019). Does forcing reduce faking? A meta-analytic review of forced-choice personality measures in high-stakes situations. Journal of Applied Psychology, 104(11), 1347–1368. 10.1037/apl 000041431070382 · doi ↗ · pubmed ↗