Analyzing Left-Truncated Samples with the Cox Model in the Presence of Missing Covariates
Omar Vazquez, Hayley M. Locke, Sharon X. Xie

TL;DR
This paper examines how to handle missing data in time-to-event studies with delayed enrollment, using methods like multiple imputation and AIPW.
Contribution
The study evaluates the performance of MI and AIPW in left-truncated samples with missing covariates through simulations.
Findings
MI and AIPW may be approximately unbiased when truncation is very low.
Biased estimation of the covariate distribution can cause MI to perform poorly.
AIPW may rely heavily on correct estimation of the probability of non-missing covariates.
Abstract
Delayed enrollment of subjects into a time-to-event study may result in a sample with biased outcome and covariate distributions. Additionally, missing covariate data may arise in these studies when information is difficult to collect due to patient burden or high testing costs. Some common missing data strategies, such as multiple imputation (MI) and augmented inverse probability weighting (AIPW), involve modeling the distribution of the missing covariate, which may be inaccurate with a left-truncated sample. Through simulation studies, we explore the performance of these methods in estimating Cox regression parameters under a variety of truncation and missing data scenarios. We find that MI and AIPW may be approximately unbiased when truncation is very low. Otherwise, biased estimation of the covariate distribution can cause MI to perform poorly. Similarly, AIPW may rely more heavily…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
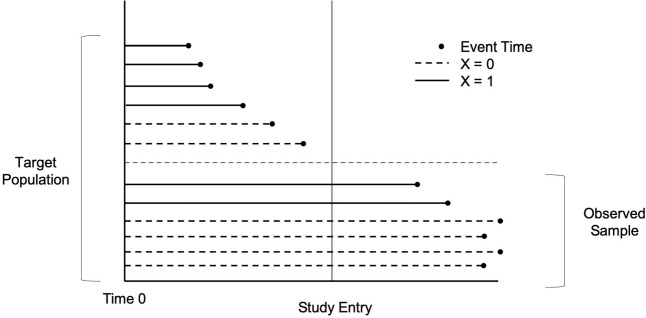 Figure 1
Figure 1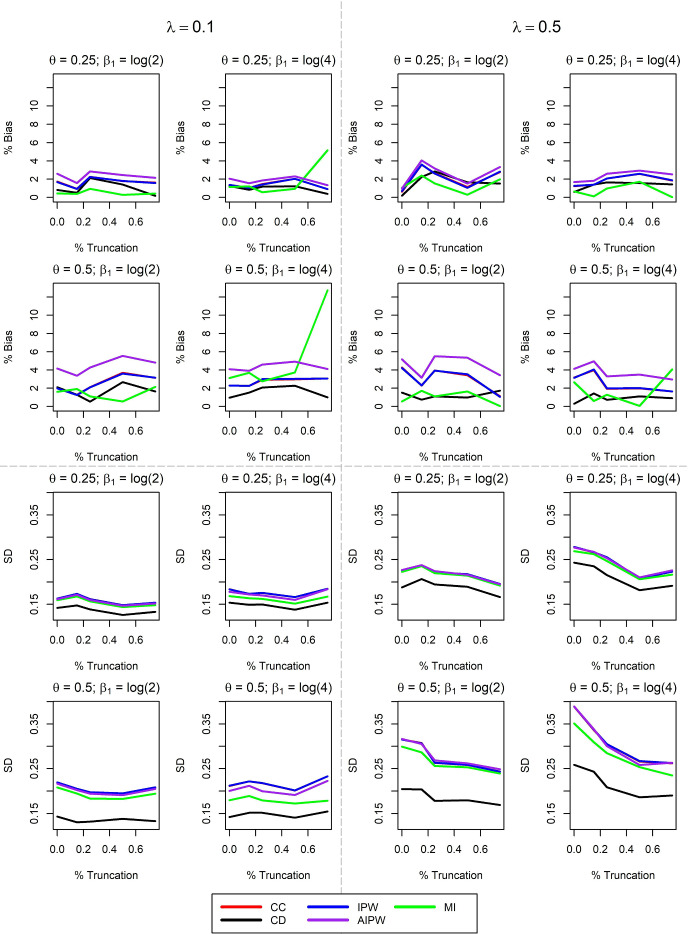 Figure 2
Figure 2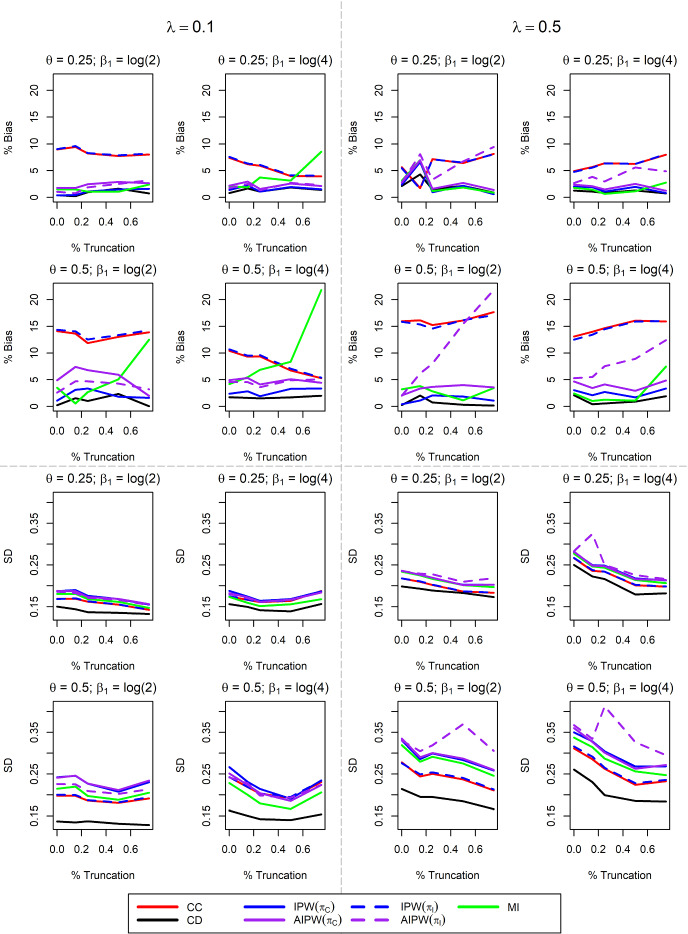 Figure 3
Figure 3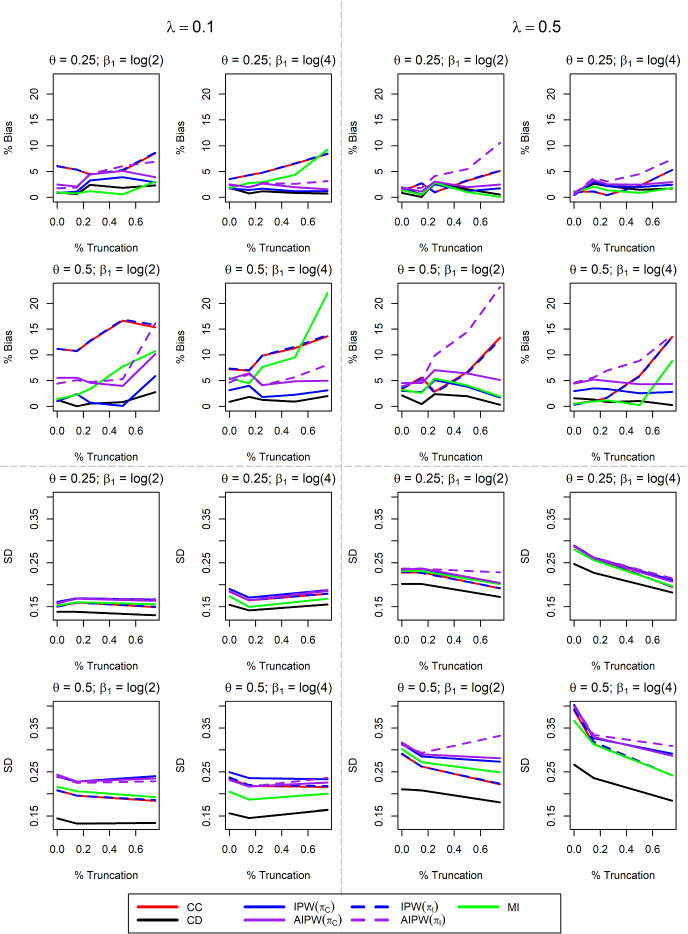 Figure 4
Figure 4- —http://dx.doi.org/10.13039/100000065National Institute of Neurological Disorders and Stroke
- —http://dx.doi.org/10.13039/100000049National Institute on Aging
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Bayesian Inference · Advanced Causal Inference Techniques · Statistical Methods and Inference
Introduction
Left truncation often arises in studies of chronic disease progression with time-to-event outcomes, which are defined as the time from some initiating event (time 0) to the event of interest. Under left truncation, subjects come under observation after time 0 by study design. For example, we consider a cohort study that aims to identify biomarkers associated with cognitive decline in Parkinson’s disease (PD). This study enrolled cognitively normal PD patients and followed them until they experienced cognitive symptoms. Time of PD diagnosis was selected as time 0 and was retrospectively ascertained. This design excludes any subjects who experience cognitive symptoms prior to when they would have entered the study. As a result, the sample is left truncated. To avoid truncation, one could select study enrollment as time 0. However, this outcome would be less clinically relevant and more difficult to interpret than time from PD diagnosis to cognitive symptom onset.
In the above example, patients who experience cognitive symptoms shortly after being diagnosed with PD are less likely to be eligible to participate in the study. As a result, larger event times are over-represented in the sample. The sample covariate distribution is similarly affected by left truncation, as it has a higher frequency of values associated with longer event times [4, 5]. Consequently, unadjusted estimation of the failure time and covariate distributions may be biased. A hypothetical example of this phenomenon with a binary covariate X is illustrated in Fig. 1. X = 1 is associated with shorter failure times. As a result, these subjects are less likely to be sampled. In the population, half of individuals have X = 1. However, the biased sampling scheme distorts this proportion so that only one-third of sampled subjects have X = 1.Fig. 1. Hypothetical Example of Covariate Bias Due To Left Truncation. Participants with a covariate value of X=1 tend to have shorter event times and are more likely to experience the event prior to study entry, making them ineligible for the study. As a result, there is a discrepancy between the sample proportion of X (1/3) and the underlying population proportion (1/2)
The analysis of left-truncated samples can be further complicated by missing covariate data. Baseline covariates may be missing purely due to chance or by study design, particularly if they are invasive or expensive to collect. Simply ignoring subjects with missing values can be inaccurate and inefficient when the complete case subset is not representative of the whole sample. A few general missing data methods are widely used and applicable to many types of outcome models. One strategy, referred to as inverse probability weighting (IPW) [19], is to weight each observation in the complete case subset to make this subset more representative of the larger sample. Alternatively, one may predict missing values directly, which is the main idea behind multiple imputation (MI) [17]. Augmented inverse probability weighting (AIPW) [16, 18] combines elements of MI and IPW to achieve greater robustness. While these approaches have been studied in the Cox model with right-censored data [23, 25], less attention has been devoted to left-truncated and right-censored data. Hu et al. [7] proposed IPW estimators for length-biased data, where entry times are assumed to be uniformly distributed. Shen and Cook [21] developed an EM-algorithm-based approach to address missing binary covariates in a left-truncated sample. This method accounts for the difference between the sample and population covariate distributions under the biased sampling scheme. It also requires specification of the baseline hazard with a fixed number of parameters. Currently, we are not aware of any studies that have explored IPW, MI, and AIPW when applied to the semiparametric Cox model [6] under left truncation with an unspecified entry time distribution.
In Cox regression with fully observed covariates, one accounts for left truncation by using a modified risk set definition [9]. In this paper, we aim to develop MI and AIPW estimation methods using risk set adjustment to account for left truncation in the presence of missing covariates. Through simulation studies, we evaluate and compare the performance of these two approaches together with complete case analysis and IPW. In particular, we highlight the impact of selection bias on estimating the missing covariate distribution in MI and AIPW. We focus on the case where the missing covariate is binary and complete variables are categorical. This scenario is of interest because the correct imputation model follows a standard distribution and can be exactly specified. With other data types, the imputation model must be approximated. By examining binary missing covariates and categorical fully observed covariates, we can eliminate poor imputation model approximation as a potential source of bias in MI. Any remaining bias can be attributed to the effect of left truncation on estimating the missing covariate distribution, allowing us to better understand method performance. The principles presented in this study will help guide researchers in selecting the appropriate missing data method for their studies.
The rest of this paper is organized as follows. In Sect. 2, we discuss several missing data approaches and their expected performance under left truncation. Simulation studies comparing these methods under a variety of truncation and missing data scenarios are presented in Sect. 3. In Sect. 4, we apply these missing data methods to a study of biomarkers for cognitive decline among Parkinson’s disease (PD) patients. Discussion and concluding remarks are given in Sect. 5.
Missing Data Methods Under Left Truncation
Consider a time-to-event study with n subjects. Let U and C be the times from time 0 to the event and censoring, respectively. The survival outcome is composed of the observed time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T = \text{ min }(U,C)$$\end{document} and the event indicator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta = I(U \le C)$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$I(\cdot )$$\end{document} is the indicator function. Further, let L be the time from time 0 to study entry. The analysis model is the Cox model shown in Equation (1), where X is a binary covariate and W is a set of binary or categorical fully observed covariates.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} h(t \vert \text {X},{{\textbf {W}}}) = h_0(t)\exp (\beta _1 \text {X} + \varvec{\beta }^T_2 {{\textbf {W}}}). \end{aligned}$$\end{document}In Equation (1), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_0(t)$$\end{document} is the unspecified baseline hazard. Other relevant quantities include the cumulative baseline hazard \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_0(t) = \int _0^t h_0(u)du$$\end{document} and the covariate-specific survival curve, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S(t \vert \text {X},{{\textbf {W}}}) = \exp (-H_0(t)e^{\beta _1\text {X}+\varvec{\beta }^T_2{{\textbf {W}}}})$$\end{document} . A central idea underlying Cox regression analysis is the risk set. In the usual right censoring case, subjects are at risk if they have not yet experienced the event. Specifically, the risk set at time t is the set of all subjects i for which \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Y_i(t) = I(t \le T_i) = 1$$\end{document} . To accommodate left truncation, the risk set is adjusted to include only those subjects who have already entered the study by time t, so that the at risk indicator at time t becomes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Y^*_i(t) = I(L_i < t \le T_i)$$\end{document} [2]. This allows for unbiased estimation of the log-hazard ratios \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }_2$$\end{document} under the conditional independence assumption \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$U \perp (L,C) \vert \text {X}, {{\textbf {W}}}, T>L$$\end{document} [10, 15]. We use the symbol \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\perp $$\end{document} to denote independence. For all missing data methods examined, the outcome model we consider is the Cox regression model using \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Y^*_i(t)$$\end{document} to account for left truncation.
We consider the case where X may be missing for some individuals, but W is observed for all in the sample. Let R be a binary variable that is equal to 1 when X is non-missing and 0 when X is missing. A key assumption in the analysis of incomplete data is the mechanism underlying missingness. The methods discussed in this study assume that the data are either missing completely at random (MCAR) or missing at random (MAR). Under MCAR, missingness is independent of any observed or unobserved variables in the study. When the data are MAR, missingness is related to the observed variables but is independent of unobserved data [11]. In a regression setting with missing covariates, a further distinction is whether missingness is related to the outcome. Since the analysis conditions on covariates, missingness related to fully observed covariates does not bias estimation of regression coefficients when using the complete case subsample [11]. Similarly, the Cox regression model under left truncation conditions on the value of L. As a result, MCAR mechanisms and MAR mechanisms related to fully observed covariates or study entry time have similar properties. For the purposes of this paper, we define MCAR as missingness that is independent of any variable or depends on W or L. Alternatively, MAR is defined as missingness that depends on the observed survival time T or the censoring indicator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} . Importantly, this does not include mechanisms that rely on either the failure time U or censoring time C. We consider U- or C-dependent missingness as missing not at random because U and C are not fully observed (C is only known for censored subjects, and U is only known for uncensored subjects). Missing not at random is a much more difficult situation to address and is beyond the scope of this article. MCAR missingness might occur if a covariate is measured on a random subset of subjects at baseline, perhaps by study design, while MAR may arise in some specialized study designs, such as case-cohort sampling [13].
Complete Case Analysis
The simplest missing data method is complete case analysis (CC), in which observations with unobserved values are excluded from analysis. If the data are MCAR, the non-missing subjects are a random subsample of the data, and inference is consistent. However, under an outcome-dependent MAR mechanism, the complete case subset is not representative of the larger sample, and hazard ratio estimation will be biased. Furthermore, removing incomplete observations from the data leads to inefficient inference.
Inverse Probability Weighting
Under the MAR mechanism, non-missing subjects are more likely to have specific outcome values, creating a biased complete case sample. This bias can be corrected by weighting complete observations in the Cox model according to the probability of X being non-missing, denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _i$$\end{document} for subject i [19]. The subscript i is removed when doing so does not cause ambiguity. This probability is commonly estimated using a logistic regression model with outcome \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R_i$$\end{document} . This model must be correctly specified to address bias induced by an MAR mechanism. Similar to CC, IPW ignores missing subjects in the final analysis, generally leading to inefficient estimates.
Multiple Imputation
Both CC and IPW do not directly incorporate missing subjects into the Cox regression analysis. As a result, some potentially useful information is ignored in the analysis, leading to larger standard errors. MI overcomes this inefficient estimation issue by predicting missing values directly, producing an imputed dataset with no missing values. Then, the Cox model with modified risk sets is applied as if there were no missing data. This procedure is repeated multiple times to account for the variability associated with predicting missing values, resulting in multiple imputed datasets. Rubin’s rules [17] are used to combine these estimates and perform inference.
The imputation process relies on having a closed-form representation for the distribution of X given the fully observed variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T, \delta $$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\textbf {W}}}$$\end{document} . This is the distribution from which imputed values will be drawn for missing subjects. In discussing conditional distributions of X, we use \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\cdot )$$\end{document} to denote the probability mass function of a categorical variable, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f(\cdot )$$\end{document} to denote the probability density function of a continuous variable, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P(\cdot )$$\end{document} to denote probability. White and Royston [25] provide a detailed study of MI to address missing covariates in the Cox model in the absence of left truncation. They demonstrate that if X is binary, W is categorical, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}})$$\end{document} is assumed to be a logistic regression model, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert T,\delta ,{{\textbf {W}}})$$\end{document} is also a logistic regression model with predictors W, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_0(T)$$\end{document} and the interaction between \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_0(T)$$\end{document} and W. If either covariate is continuous, approximations are required to obtain a closed-form imputation model. For example, if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f(\text {X} \vert {{\textbf {W}}})$$\end{document} is assumed to be normally distributed with mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _0 +\varvec{\eta }_1^T{{\textbf {W}}} $$\end{document} and variance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma ^2$$\end{document} , then \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f(\text {X} \vert T,\delta ,{{\textbf {W}}})$$\end{document} can be approximated by linear regression. However, this approximation fails if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1^2 \sigma ^2 H_0(T)$$\end{document} is large. We focus on the binary covariate situation so that any bias that arises is not due to poor approximation of the true imputation model, but potentially due to poor estimation of the imputation model parameters under left truncation. We assume the population distribution of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {X} \vert {{\textbf {W}}}$$\end{document} follows a logistic regression model, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$ \text{ logit } P(\text {X} = 1 \vert {{\textbf {W}}}) = \eta _0 + \varvec{\eta }_1^T{{\textbf {W}}}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _0$$\end{document} is the intercept and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\eta }_1$$\end{document} is the logistic regression coefficient for W. The first adjustment for left truncation is using the modified definition of the risk set, i.e., replacing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Y_i(t)$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Y^*_i(t)$$\end{document} in the Cox model. In addition, we consider the imputation model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert T, \delta , L, {{\textbf {W}}}, T > L)$$\end{document} in Equation (2).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} p(\text {X} \vert {{\textbf {W}}}, T, \delta , L, T>L)&\propto f(T,\delta \vert \text {X}, {{\textbf {W}}})p(\text {X}\vert {{\textbf {W}}}). \end{aligned} \end{aligned}$$\end{document}The imputation model has two components: \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}})$$\end{document} is the user-specified conditional distribution of the missing data X under no truncation, while the Cox model implies that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$f(T,\delta \vert \text {X}, {{\textbf {W}}}) = h(T \vert \text {X},{{\textbf {W}}})^\delta S(T \vert \text {X},{{\textbf {W}}})$$\end{document} . In the supplementary materials, we provide further details on how Equation (2) is derived. This involves two key independence assumptions on the truncation time L. The first is the previously mentioned standard assumption for Cox regression with left-truncated data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$U \perp (L,C) \vert \text {X}, {{\textbf {W}}}, T>L$$\end{document} , which allows for unbiased estimation of the Cox model parameters through the risk set adjustment. If the second independence assumption \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {X} \perp (L,C) \vert {{\textbf {W}}}$$\end{document} also holds, then \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}}, T, \delta , L, T>L)$$\end{document} reduces to the imputation model that is appropriate for non-truncated data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}}, T, \delta )$$\end{document} , which is proportional to the right side of Equation (2).
Although the target for the missing data component is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}})$$\end{document} , the observed data come from the selection-biased density \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}},T>L)$$\end{document} . Depending on the severity of selection bias, the population covariate distribution may be modeled poorly with a biased sample, causing the imputation model to be incorrectly estimated. As such, MI will perform well when applied to truncated data when X and L are conditionally independent and the population and sample covariate distributions are similar. When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}},T>L)$$\end{document} cannot approximate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}})$$\end{document} , MI will be biased due to the effect of selection bias on the sample covariate distribution.
It is important to note that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_0(T)$$\end{document} is unknown. White and Royston [25] recommend estimating this quantity with the nonparametric Nelson-Aalen estimator [1, 12] of the cumulative hazard, H(T). This works well when the hazard ratios are small, such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_0(T) \approx H(T) = H_0(T)\exp (\beta _1 \text {X}+\varvec{\beta }_2^T {{\textbf {W}}})$$\end{document} . Since we are working with all categorical covariates, the approximation could be improved by stratifying on different covariate combinations if the stratum-specific sample sizes are sufficiently large.
Augmented Inverse Probability Weighting
IPW and MI require that the user correctly specifies a model related to the missing data (i.e., the reason for missingness or the missing data itself). The AIPW framework, first proposed by Robins et al. [16], offers some robustness against model misspecification and potential efficiency gains over IPW. AIPW has been considered in Cox regression analysis under right censoring in the absence of left truncation [14, 23, 26]. We modify the AIPW score equation developed under right censoring only to account for left truncation by a risk set adjustment, i.e., replacing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Y_i(t)$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Y_i^*(t)$$\end{document} . The AIPW score equation is given in Equation (3).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} \frac{1}{n}\sum _{i=1}^n\left\{ \frac{R_i \delta _i}{\pi _i}\bigg [ \begin{pmatrix} \text {X}_i \\ {{\textbf {W}}}_i \end{pmatrix} - \frac{S_{AW}^{(1)}(\varvec{\beta }, T_i)}{S_{AW}^{(0)}(\varvec{\beta }, T_i)} \bigg ] + A_i(\varvec{\beta }) \right\} = {\varvec{0}}, \end{aligned} \end{aligned}$$\end{document}where
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} r_i^{(0)}(\varvec{\beta })&= \exp (\beta _1\text {X}_i + \varvec{\beta }_2^T{{\textbf {W}}}_i),\quad r_i^{(1)} (\varvec{\beta }) = (\text {X}_i, {{\textbf {W}}}_i^T)^T \exp (\beta _1\text {X}_i + \varvec{\beta }_2^T{{\textbf {W}}}_i),\\ S^{(m)}_{AW}(\varvec{\beta }, t)&= \frac{1}{n}\sum _{i=1}^n \bigg [\frac{R_i}{\pi _i} Y_i^*(t) r_i^{(m)}(\varvec{\beta }) + \left( 1-\frac{R_i}{\pi _i}\right) Y_i^*(t)E(r_i^{(m)} \vert T_i, \delta _i, {{\textbf {W}}}_i)\bigg ] \text{ for } m = 0,1,\\ A_i(\varvec{\beta })&=\left( 1-\frac{R_i}{\pi _i}\right) \int \bigg \{ E\bigg [\begin{pmatrix}\text {X}_i\\ {{\textbf {W}}}_i \end{pmatrix} dN_i(u)\vert T_i, \delta _i, {{\textbf {W}}}_i\bigg ]\\&\quad -\frac{S^{(1)}_{AW}(\varvec{\beta }, T_i)}{S^{(0)}_{AW} (\varvec{\beta }, T_i)}E(dN_i(u)\vert T_i, \delta _i, {{\textbf {W}}}_i) \bigg \}. \end{aligned} \end{aligned}$$\end{document}The conditional expectations in the augmentation term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A_i(\varvec{\beta })$$\end{document} rely on estimating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_0(t)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}})$$\end{document} . Estimation of the cumulative baseline hazard is accomplished through a Breslow-type estimator, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{H}}_0(t) = \frac{1}{n} \sum _{i=1}^n I(T_i\le t)\delta _i/S^{(0)}_{AW}(\varvec{\beta }, T_i)$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}})$$\end{document} is specified by the user. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\eta }$$\end{document} be the parameters governing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}})$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\psi _{\eta }}$$\end{document} be the score function for that model. Estimation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\eta }$$\end{document} is performed using the score equation given in Eq (4).
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \begin{aligned} \frac{1}{n} \sum _{i=1}^n \left\{ \frac{R_i}{\pi _{i}}\varvec{\psi _{\eta }} (\text {X}_i, {{\textbf {W}}}_i) + \bigg (1-\frac{R_i}{\pi _{i}}\bigg )E \bigg [\varvec{\psi _{\eta }}(\text {X}_i, {{\textbf {W}}}_i) \vert T_i,\delta _i,{{\textbf {W}}}_i\bigg ]\right\} = {\varvec{0}}. \end{aligned} \end{aligned}$$\end{document}AIPW estimates are unbiased if either \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} or \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}}$$\end{document} ) is correctly specified (the so-called double robustness property), making it a more flexible approach than other methods. When the data are MAR and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} are misspecified, AIPW will correct the bias of IPW so long as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}})$$\end{document} is correctly specified and consistently estimated. Under MCAR (or MAR with correct \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} ), AIPW may also offer increased efficiency over standard weighting methods [18].
We consider the score equation given in Equation (3) utilizing the imputation model derived in Sect. 2.3, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}},T,\delta ,L,T>L)$$\end{document} . We estimate the standard error using bootstrap resampling with 500 replicated datasets. Similar to MI, the proposed imputation model requires that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {X} \perp L \vert {{\textbf {W}}}$$\end{document} and that the parameters governing \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p(\text {X} \vert {{\textbf {W}}})$$\end{document} can be estimated well with the biased sample. In cases of extreme selection bias, the missing data model cannot be estimated correctly, so consistency of AIPW relies on the correct specification of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} .
Simulation Study
Through simulation studies, we aim to quantify the effect of truncation on missing data methods, particularly those involving modeling the missing covariate distribution. Simulation parameters were selected to mimic our motivating data example. We also varied these parameters to explore a variety of settings. We considered a sample size of n = 300, with results for n = 500 presented in the supplementary materials. We began by generating data for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\frac{n}{(1-q)}$$\end{document} observations, where q is the truncation rate. Study entry times, L, were generated from a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_1$$\end{document} Beta(6,1.5) distribution, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_1$$\end{document} was varied according to the truncation rate. We considered truncation rates of 0, 0.15, 0.25, 0.5, and 0.75. Binary covariates \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${{\textbf {W}}} = (W_1, W_2, W_3)^T$$\end{document} were generated from independent Bernoulli(0.5) distributions. The primary covariate of interest, X, was generated according to a logistic regression model with mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _0 + \varvec{\eta }_1^T{{\textbf {W}}}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\eta _0 = 0.5$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\eta }_1 = (\log (2), -\log (2),\log (1.5))^T$$\end{document} .
U followed a Cox proportional hazards model with hazard \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h(t \vert \text {X},{{\textbf {W}}}) = h_0(t)\exp (\beta _1\text {X} + \varvec{\beta }^T_2{{\textbf {W}}})$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_0(t) = \rho \kappa (\rho t)^{\kappa -1},\ \rho =0.1,\ \kappa =0.5,\ \varvec{\beta }^T_2 = (\log (2), -\log (2), \log (1.5))$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} values of both \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log (2)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\log (4)$$\end{document} were tested. Subjects with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L_i > T_i$$\end{document} were removed from the sample to produce a final sample of approximately size n. Finally, random censoring times were introduced. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_i'$$\end{document} was generated from a Weibull(4, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_2$$\end{document} ), where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$c_2$$\end{document} was chosen to produce the desired censoring rate. The censoring time was \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$C_i = c_1 + C_i'$$\end{document} , so that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P(C > L) = 1$$\end{document} . Censoring rates of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} = 0.1 and 0.5 were considered.
The final step of data generation occurred with introducing missingness in the covariate X. First, we implemented an MCAR mechanism in which \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _i$$\end{document} was constant across subjects. We tested missing data rates of 0.25 and 0.5. Under MCAR, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} can be trivially estimated by the sample proportion of observed data. As a result, misspecification of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} is unlikely in practice. Therefore, we studied IPW and AIPW with correctly specified \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} model, a logistic regression model with outcome R and predictor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_1$$\end{document} . We also tested CC, MI, and the complete data (CD) estimate, which applied the Cox model to the dataset with no missing values. For MI, 100 imputed data-sets were generated and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_0(T)$$\end{document} was estimated using the Nelson–Aalen estimator for H(T). The standard error for AIPW was computed using bootstrap sampling with 500 bootstrap replicates.
Simulation results for the MCAR mechanism under 10% censoring, 50% missing data, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1 = \log (4)$$\end{document} are shown in Table 1. As expected, CC and IPW are unbiased and have similar variability regardless of the degree of truncation. AIPW also has no bias, which can be attributed to the correctly specified \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} model. Under low to moderate truncation, MI is unbiased. The only method exhibiting bias greater than 10% is MI under 75% truncation due to the departure of the sample covariate distribution from the target population covariate distribution. The MI standard error estimator also performs worse as truncation increases, which can occur with a misspecified imputation model [8]. Figure 2 demonstrates the effect of altering \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} as well as missingness and censoring rates. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} refers to the proportion of subjects for whom X is missing, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} represents the proportion of subjects whose event time is censored. Similar to Table 1, CC and IPW are unbiased across all truncation, missingness, and censoring percentages. These methods also have similar standard deviations because \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\pi }}$$\end{document} is approximately constant under MCAR. AIPW is also unbiased with increasing truncation, due to the fact that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} is correctly specified. Under many circumstances, AIPW has similar efficiency to CC and IPW. When AIPW has an efficiency gain, this advantage decreases with moderate or large truncation. In many settings, there is an increase in bias of MI as truncation increases. In these simulations, bias is most extreme with larger \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} and lower censoring. MI often has smaller variance than other missing data methods, though it is important to note that small MI variance may be accompanied by larger MI bias. Very similar results were obtained using a larger sample size (n=500), which are presented in Figure S.1 in the supplementary information.Table 1. Simulation results with sample size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=300$$\end{document} , X regression coefficient \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1 = \log (4)$$\end{document} , 10% censoring, and 50% MCAR missingness. The nominal confidence interval coverage probability is 95% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma $$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^{1}$$\end{document} ValueCCCDIPWAIPWMI0Bias0.0320.0180.0320.059 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.043% Bias2.3261.3302.2844.236 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 3.098SD0.2270.1550.2270.2150.193mean(SE)0.2240.1550.2200.2250.223Cov. Prob0.9560.9500.9480.9520.9800.15Bias0.0290.0140.0290.051 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.053% Bias2.1240.9972.1183.670 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 3.842SD0.2360.1600.2360.2240.200mean(SE)0.2150.1490.2110.2150.221Cov. Prob0.9280.9260.9200.9220.9540.25Bias0.0370.0220.0370.064 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.040% Bias2.6701.5722.6924.587 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 2.854SD0.2030.1450.2040.1920.174mean(SE)0.2100.1460.2050.2080.219Cov. Prob0.9500.9420.9440.9500.9880.5Bias0.0530.0200.0540.072 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.047% Bias3.8491.4373.8645.216 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 3.390SD0.1990.1350.1990.1900.169mean(SE)0.2020.1400.1950.2000.217Cov. Prob0.9480.9540.9360.9500.9880.75Bias0.0370.0160.0380.053 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.176% Bias2.6981.1372.7273.842 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 12.716SD0.2230.1490.2230.2180.181mean(SE)0.2250.1560.2150.2240.270Cov. Prob0.9460.9580.9380.9460.976 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^1$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma $$\end{document} is the simulated truncation rate
Fig. 2. Extended Simulation Results for MCAR Missingness. The sample size is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=300$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} is the log-hazard ratio of the missing covariate X, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} is the censoring rate, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} is the proportion of data with X missing
Next, we compared these methods under an MAR mechanism in which R was related to the censoring indicator, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} . R was generated according to a logistic regression model with mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$a + \log (4)\delta $$\end{document} , where a was varied across parameter settings to consistently produce the desired missing data rate. Under the MAR mechanism, we compared IPW and AIPW with both correct and incorrect \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} models. When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} was correctly specified, it was a logistic regression model with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} as the only predictor. When it was incorrectly specified, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_2$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_3$$\end{document} were used to predict missingness. We denote methods using a correctly specified \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} model as IPW( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _C$$\end{document} ) and AIPW( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _C$$\end{document} ). Under incorrectly specified \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} model, these methods are referred to as IPW( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _I$$\end{document} ) and AIPW( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _I$$\end{document} ).
Simulation results for MAR data are presented in Table 2. Due to the MAR mechanism, CC is biased, though under the selected settings, this bias decreases as truncation increases. IPW addresses this bias well so long as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} correctly specified, regardless of percent truncation (illustrated by comparing the two IPW columns in Table 2). AIPW with correct \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} is also unbiased across all levels of truncation tested (though the bias reduction at high levels of truncation is low due to smaller CC bias). Notably, AIPW is more efficient than IPW when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} is correct and the data are not truncated, and this efficiency gain disappears with larger truncation. AIPW is expected to be more efficient than IPW when both the missingness and imputation models are correctly specified and consistently estimated. This is the case in our simulations with zero truncation, and we do see that the SD of AIPW \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\pi _C)$$\end{document} is consistently smaller than that of IPW for those settings, albeit by a small amount \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$<10\%$$\end{document} . The degree of expected efficiency gain depends on the distribution of the data, and happens to be small for the settings considered in this paper. Thus, our simulation results for AIPW \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\pi _C)$$\end{document} are consistent with general expectations. When left truncation is present, the covariate distribution in the imputation model is not estimated consistently due to the biased sample, so we cannot necessarily expect AIPW \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(\pi _C)$$\end{document} to have an efficiency advantage over IPW. AIPW with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} misspecified can effectively reduce bias when compared to CC with little or no truncation, but they perform similarly at high truncation rates. MI is unbiased with low truncation percentages and can become severely biased with more extreme selection bias.
Figure 3 explores the impact of altering various parameters of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} -dependent MAR simulations. CC is biased across most settings and truncation rates. IPW and AIPW successfully eliminate this bias when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} is correctly specified, and good performance does not rely on truncation percentage. When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} is misspecified, however, the relationship between the truncation proportion and the bias and variance of AIPW( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _I$$\end{document} ) under different truncation scenarios is complex and not necessarily monotone. Since both the missingness model and the imputation model are not estimated consistently when the truncation proportion is significant, the expected behavior of AIPW( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _I$$\end{document} ) is unknown. MI and AIPW( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _I$$\end{document} ) can become extremely biased when truncation is substantial. Notably, the performance of these methods relies on multiple factors, such as censoring rate, missingness rate, and hazard ratio of the missing variable. As such, predicting poor performance of MI and AIPW( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _I$$\end{document} ) can be difficult due to the complex nature of these data. These methods often have similar variabilities, with MI often having an efficiency gain with smaller truncation rates. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} -dependent MAR simulation results with a sample size of 500 are provided in Supplemental Figure S.2. Many of the same trends persist with larger sample size, and MI and AIPW( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _I$$\end{document} ) remain biased under some settings with high truncation. However, increasing n slightly decreases MI bias, while AIPW( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _I$$\end{document} ) bias is comparable between sample sizes.Table 2. Simulation results with sample size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=300$$\end{document} , X regression coefficient \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1 = \log (4)$$\end{document} , 10% censoring and 50% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} -dependent MAR missingness. The nominal confidence interval coverage probability is 95% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma $$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^1$$\end{document} ValueCCCDCorrect \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} Incorrect \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} MIIPWAIPWIPWAIPW0Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1410.0180.0350.074 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1460.063 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.053% Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 10.1841.3142.5355.307 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 10.5494.562 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 3.844SD0.2210.1570.2460.2300.2230.2190.212mean(SE)0.2160.1550.2430.2320.2140.2320.267Cov. Prob0.9000.9520.9400.9540.8940.9000.9820.15Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1380.0240.0350.066 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1410.056 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.078% Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 9.9531.7012.4994.734 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 10.2044.011 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 5.658SD0.2220.1540.2410.2310.2230.2250.204mean(SE)0.2070.1490.2290.2200.2040.2200.277Cov. Prob0.8700.9420.9240.9300.8560.8700.9840.25Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1300.0120.0130.047 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1350.041 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.113% Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 9.3940.8940.9603.373 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 9.7262.979 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 8.142SD0.2040.1370.2190.2030.2060.2010.187mean(SE)0.2010.1450.2180.2100.1980.2110.278Cov. Prob0.8880.9600.9420.9500.8820.8880.9900.5Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.0840.0220.0510.078 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.0890.075 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.115% Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 6.0781.5723.7085.596 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 6.3885.446 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 8.265SD0.2020.1500.2090.2020.2030.2050.177mean(SE)0.1960.1400.2060.1980.1920.1980.267Cov. Prob0.9360.9280.9300.9140.9180.9360.9960.75Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.0750.0240.0450.064 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.0760.072 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.304% Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 5.4001.7473.2794.644 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 5.4765.195 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 21.904SD0.2300.1640.2330.2290.2290.2300.205mean(SE)0.2200.1560.2220.2200.2110.2210.337Cov. Prob0.9300.9280.9240.9320.9200.9300.956 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^1$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma $$\end{document} is the simulated truncation rate
Fig. 3. Extended Simulation Results for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} -dependent MAR Missingness. The sample size is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=300$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} is the log-hazard ratio of the missing covariate X, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} is the censoring rate and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} is the proportion of data with X missing
Finally, we considered the case where R was related to the observed time, T. The true underlying missing data mechanism, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$P(R=1 \vert T)$$\end{document} , was a logistic regression model with mean \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha _0 - \alpha _1\sqrt{T}$$\end{document} . Because the distribution of T changes with the censoring rate, we chose \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha _1 = \log (1.25)$$\end{document} under 10% censoring and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha _1 = \log (3)$$\end{document} under 50% censoring. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha _0$$\end{document} was varied across parameter settings to consistently produce the specified amount of missing data. Similar to the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} -dependent MAR case, the correctly specified \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} model used only \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sqrt{T}$$\end{document} to predict R. The incorrect \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} model had predictors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_1$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_2$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_3$$\end{document} .
Results for the case with 10% censoring, 50% missingness, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1 = \log (4)$$\end{document} are provided in Table 3. Similar to the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} -dependent MAR case, CC is biased, though in this scenario, bias increases with larger truncation rates. IPW with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} incorrect is similarly biased. IPW and AIPW both reduce bias compared to CC when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} is correctly specified. AIPW with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} incorrect and MI both have bias exceeding 10% when truncation is extreme. Figure 4 displays additional simulation results altering the amount of censoring, rate of missing data, and hazard ratio. Again, MI and AIPW( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _I$$\end{document} ) are often biased with larger truncation rates. However, hazard ratio, censoring, and missingness rates all impact the effect of increasing truncation on the performance of these methods. Results for the larger sample size are presented in Supplemental Figure S.3. As previously noted, MI bias is slightly mitigated with larger sample size, though still substantial in many cases.Table 3. Simulation results with sample size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=300$$\end{document} , X regression coefficient \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1 = \log (4)$$\end{document} , 10% censoring, and 50% T-dependent MAR missingness. The nominal confidence interval coverage probability is 95% \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma $$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^1$$\end{document} ValueCCCDCorrect \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} Incorrect \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} MIIPWAIPWIPWAIPW0Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.0980.0180.0420.072 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1000.063 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.071% Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 7.0861.3123.0585.159 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 7.2124.570 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 5.097SD0.2290.1480.2490.2280.2310.2260.204mean(SE)0.2230.1550.2360.2350.2210.2360.248Cov. Prob0.9200.9580.9220.9340.9140.9200.9700.15Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1160.0170.0430.080 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1180.073 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.086% Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 8.3551.1943.1335.736 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 8.4845.248 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 6.236SD0.2160.1440.2370.2190.2170.2190.191mean(SE)0.2120.1490.2260.2220.2090.2230.256Cov. Prob0.9180.9660.9360.9320.8980.9180.9860.25Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1400.0190.0260.059 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1400.059 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.114% Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 10.0751.3641.8904.282 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 10.1124.274 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 8.253SD0.2110.1480.2300.2150.2130.2180.184mean(SE)0.2060.1450.2190.2150.2010.2150.258Cov. Prob0.8960.9500.9360.9360.8860.8960.9840.5Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1540.0220.0370.071 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1570.083 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.132% Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 11.0851.6062.6815.106 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 11.3285.990 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 9.557SD0.2090.1500.2300.2240.2120.2320.194mean(SE)0.1950.1400.2090.2030.1900.2030.249Cov. Prob0.8640.9200.9160.8980.8500.8640.9660.75Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1830.0350.0780.098 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.1870.141 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 0.325% Bias \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 13.2182.5275.6267.081 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 13.45510.192 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$-$$\end{document} 23.432SD0.2190.1530.2420.2250.2210.2370.202mean(SE)0.2110.1560.2260.2160.2020.2160.331Cov. Prob0.8580.9480.9160.8980.8180.8580.948 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$^1$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\gamma $$\end{document} is the simulated truncation rate
Fig. 4. Extended Simulation Results for T-dependent MAR Missingness. The sample size is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=300$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta _1$$\end{document} is the log-hazard ratio of the missing covariate X, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda $$\end{document} is the censoring rate, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\theta $$\end{document} is the proportion of data with X missing
Application to Parkinson’s Disease Cognition Research
We explore the performance of missing data methods when applied to a study evaluating associations between cerebrospinal fluid biomarkers and cognitive decline in PD patients. The study cohort was followed up by the University of Pennsylvania Parkinson’s Disease Research Center (PDRC). Cognitively normal PD patients were enrolled in the study. PD diagnosis (time 0) occurred prior to study entry for all participants, producing a left-truncated sample. Participants were followed until they developed the event of interest, defined as mild cognitive impairment (MCI) or dementia. The dataset contains 223 participants, of which 108 (48%) were censored. We use the method presented by Wang [24] to quantify the proportion of subjects in the population who experienced the outcome prior to study entry, which is estimated to be 45% for this dataset. In other words, the estimated left truncation rate is 0.45.
We aim to use Cox regression to evaluate the association between abnormal CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} on cognitive decline in PD, controlling for age at study entry and baseline cognitive score, measured through the Dementia Rating Scale (DRS). Abnormal CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} is a binary variable defined as a concentration of CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42} \le $$\end{document} 192 pg/ml [20]. Obtaining a CSF sample is expensive and invasive for the patient. As such, information on this variable was obtained for only a subset of the cohort. Further, CSF samples taken more than 8 months after study enrollment are considered not representative of baseline values and treated as missing. 133 subjects (60% of total cohort) did not have CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} information available. Among the complete cases, 12 (13%) had an abnormal concentration of CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} . We employ categorical versions of the age (younger vs. older) and DRS (lower vs. higher score) variables. The young group are all subjects with an age at baseline less than 67 years and the low DRS group are subjects with a baseline DRS score less than 139. These thresholds are selected because they are the median observed values in the sample.
AIPW and MI require a model for the conditional distribution of abnormal CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} to perform AIPW and MI. Since abnormal CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} is binary, we specify this distribution using a logistic regression model. At baseline, subjects undergo genetic screening for the APOE \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon _4$$\end{document} allele. Previous studies have demonstrated that presence of this allele is associated with decreased CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} [22]. As such, APOE \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon _4$$\end{document} information is an important explanatory variable in modeling missing CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} values. We also include binary age and binary DRS score as predictors of abnormal CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} . The MI imputation model uses the Nelson-Aalen estimate of H(T) and appropriate interaction terms as described by White and Royston [25]. We generate 100 imputed datasets. In AIPW, 500 bootstrap replicates are used to estimate the standard error.
To perform IPW and AIPW, we must specify a model to estimate the probability of observing CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} at baseline ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} ). We use a logistic regression model with outcome R to estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} . Model misspecification may occur when important information is left out of the model. Thus, we include all fully observed variables as predictors in this model. Binary L is defined as early vs. late entry, where subjects who enter late are those who came under observation more than 1562 days after diagnosis. Similarly, binary T is defined as early vs late event time, where late events occurred more than 3391 days after diagnosis. Again, these thresholds are selected because they are the median observed values. As a result, the final \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} model contains predictors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} , APOE \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon _4$$\end{document} , older age, higher DRS score, late L, and late T. To perform IPW and AIPW, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} is estimated using the fitted values of this model. We also use this model to assess possible missing data mechanisms for this data. Using Wald tests and nested likelihood ratio tests, we conclude that the only important predictors of missingness are age (p = 0.047) and DRS score (p = 0.001). Thus, the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} model suggests that missingness may be MCAR in this dataset.Table 4. Penn PDRC Data Analysis: Regression coefficient estimates for abnormal CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} Method \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\beta }}$$\end{document} Std. Errorp-valueCC0.9720.4210.02IPW0.9520.4280.03AIPW1.0650.4020.01MI0.6500.3280.05
Table 4 presents regression coefficient estimates for abnormal CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} obtained using a variety of missing data techniques. Using complete cases only, abnormal CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} is significantly associated with increased risk of MCI or dementia ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\beta }}_{\text {CC}}$$\end{document} = 0.972, p = 0.02). Results using IPW are very similar to CC ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\beta }}_{\text {IPW}}$$\end{document} = 0.952, p = 0.03). The point estimate of AIPW is comparable to CC and IPW ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\beta }}_{\text {AIPW}}$$\end{document} = 1.050). Under the assumed MCAR mechanism, it is expected that CC, IPW, and AIPW produce similar estimates, since \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} is usually correctly estimated under MCAR. MI results in a much smaller effect estimate and a p-value equal to the threshold for significance ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\beta }}_{\text {MI}}$$\end{document} = 0.650, p = 0.05). In addition, its standard error is smaller than the other three methods, due in part to the smaller magnitude of its coefficient estimate. The large difference in estimates obtained may be due to violation of either assumption made by the imputation model. The first assumption is that the missing covariate and entry times are independent conditional on other covariates. In this study, CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} value is not known prior to study entry. As such, it seems unlikely that the CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} value could influence the time from PD diagnosis to study entry, except perhaps through the influence of related risk factors. While the conditional independence assumption seems plausible, the estimated amount of truncation is moderate. In this case, it is plausible that the sample covariate distribution is not representative of the population. This would cause bias in estimation of the imputation model. Our scientific conclusion based on the above analyses is that abnormal CSF \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A\beta _{42}$$\end{document} is related to increased risk of conversion to MCI or dementia among PD patients.
Discussion
This study investigated how commonly used approaches for handling missing covariate data in the Cox model perform when the data are left-truncated. In particular, the biased sample complicates estimating the missing covariate distribution, even when it is modeled correctly (i.e., the parametric structure is correctly specified). In many practical settings, the estimated missing data model may be approximately unbiased, especially if truncation is very low. When the truncation scenario is more extreme, the biased covariate distribution can cause poor MI performance. AIPW may rely more heavily on correct estimation of the probability of having non-missing covariates when the data is MAR. Notably, poor performance of these methods relies on many factors and can be difficult to predict. This study motivates future research surrounding unbiased estimation of covariate distribution parameters under left truncation in the presence of missing data. Such a method could ensure unbiased results under many truncation scenarios, making it an attractive missing data method for left-truncated survival data.
We considered only the case where the missing covariate is binary, observed covariates are categorical, and the two are related through a logistic regression model. In this situation, it can be shown that the correct imputation model is also a logistic regression model. With other data types, the correct imputation model does not follow a standard distribution. Approximations to the true imputation model have been studied in the absence of left truncation [25]. As such, when truncation is introduced, it would be unclear whether observed bias could be attributed to poor approximation of the imputation model (due to continuous data types) or improper estimation of the imputation model parameters (because the sample covariate distribution is biased). Bartlett et al. [3] propose an MI procedure that can overcome this limitation of standard MI by generating random draws from nonstandard distributions. Another option for fitting the imputation model is through a nonparametric method such as random forests. Exploring the bias pattern of these methods in the context of left truncation would be an interesting future research direction.
Our simulation results demonstrate that predicting the performance of methods that require modeling the missing covariate distribution is complex. Regardless of other parameters, these models perform well when the amount of truncation is very small, perhaps 15% or less. In these cases, MI and AIPW will likely perform as expected under right censoring only, since the sample covariate distribution approximates the population distribution well. We recommend using MI and AIPW when truncation is very low due to increased efficiency over IPW.
When truncation is moderate or substantial, careful consideration is required to select an appropriate missing data method. When MCAR can be assumed, an investigator may choose CC, IPW, or AIPW to ensure unbiased results (since \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} is usually correctly specified under MCAR). Under MAR, there is no guarantee that any method will perform well. In particular, because the survival outcome is related to both the selection bias and missing data mechanism, altering parameters can have complex consequences on model performance. As an example, in our simulations, AIPW( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _I$$\end{document} ) was unbiased under \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} -dependent missingness, high truncation, and low censoring (Table 2), which is unexpected due to misspecification of both models. However, the censoring rate was very low, so omitting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta $$\end{document} from the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi $$\end{document} model did not have a large impact on estimation. Thus, AIPW( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _C$$\end{document} ) and AIPW( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _I$$\end{document} ) performed similarly in this specific scenario.
Due to the complexity of these data under MAR, selecting the appropriate method to address missing covariate data may be challenging. In general, CC is biased due to the non-representative complete case subsample. IPW and AIPW both require correct specification of the probability of missingness model. Practical guidelines for specifying this model are provided by Seaman and White [19]. Unless truncation is very small, MI modeling may also be biased even when the imputation model is correctly specified. When the probability of missingness depends on the survival outcome, we recommend using a variety of missing data methods and critically evaluating the assumptions of each.
Supplementary information
The online version of this article contains supplementary material available at the journal’s website. R code for CC, IPW, MI, and AIPW are provided in the supplementary materials.
Supplementary Information
Below is the link to the electronic supplementary material.Supplementary file 1 (pdf 1979 KB)