Bootstrap Confidence Intervals for Multiple Change Points Based on Two-Stage Procedures
Li Hou, Baisuo Jin, Yuehua Wu, Fangwei Wang

TL;DR
This paper introduces a two-step method to build confidence intervals for multiple change points in regression models using bootstrapping.
Contribution
A novel two-stage procedure combining variable selection and refinement with a valid bootstrapping method for multiple change points.
Findings
The orthogonal greedy algorithm consistently recovers the number of change points.
The sup-Wald-type test statistic accurately determines change point locations.
Bootstrap confidence intervals are asymptotically valid and perform well in simulations and real data.
Abstract
This paper investigates the construction of confidence intervals for multiple change points in linear regression models. First, we detect multiple change points by performing variable selection on blocks of the input sequence; second, we re-estimate their exact locations in a refinement step. Specifically, we exploit an orthogonal greedy algorithm to recover the number of change points consistently in the cutting stage, and employ the sup-Wald-type test statistic to determine the locations of multiple change points in the refinement stage. Based on a two-stage procedure, we propose bootstrapping the estimated centered error sequence, which can accommodate unknown magnitudes of changes and ensure the asymptotic validity of the proposed bootstrapping method. This enables us to construct confidence intervals using the empirical distribution of the resampled data. The proposed method is…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
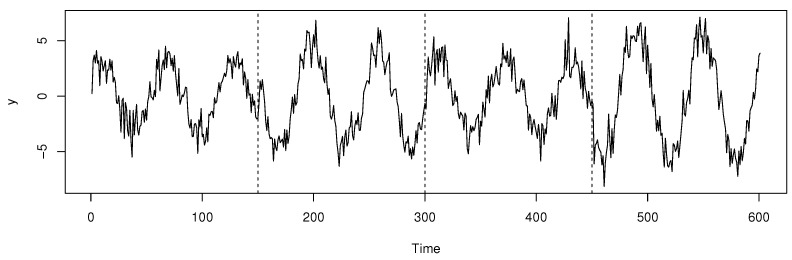 Figure 1
Figure 1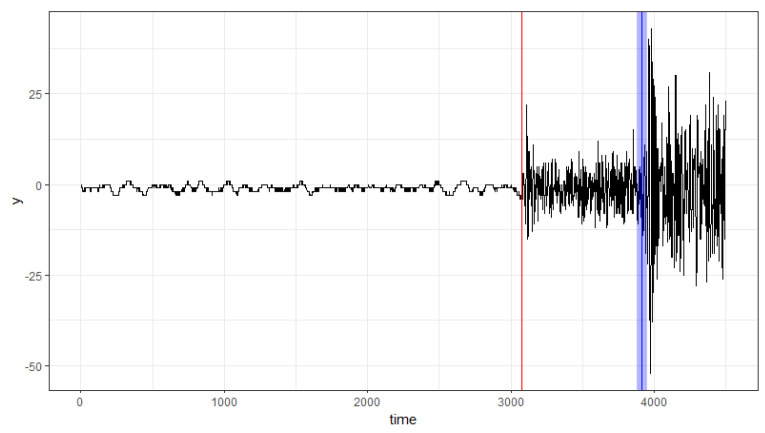 Figure 2
Figure 2- —National Natural Science Foundation of China
- —Natural Science and Engineering Research Council of Canada
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Advanced Statistical Methods and Models · Control Systems and Identification
1. Introduction
Multiple change point detection is common in many applications, such as signal processing [1], medical diagnosis [2], industrial control [3], and oceanography [4]. For example, in the case of the detection of changes in one’s heart rates, the accurate identification of the change points can decompose the data into stationary segments, allowing clinicians to identify the behavior of the heart and diagnose diseases. The detection of multiple change points has important practical implications, which has prompted extensive research in the statistical community.
Implementing appropriate hypothesis testing is an important method for detecting multiple change points. Here are some examples. Ref. [5] proposed sup-Wald-type tests to test the null hypothesis of no change against alternative hypotheses containing an arbitrary number of changes to identify multiple structural changes in linear models. At the same time, the null hypothesis of s changes against changes is tested to determine the number of breakpoints. Later, ref. [6] developed dynamic programming principles to estimate multiple change points in linear regression. Ref. [7] proposed a genetic algorithm for detecting multiple breakpoints. However, these methods are very time-consuming. There is another line of research on multiple change point detection that transforms the problem into a variable selection problem. For example, ref. [8] used LASSO [9] to estimate the locations of multiple change points in a one-dimensional piecewise constant signal observed in white noise. Ref. [10] introduced a two-stage procedure based on adaptive LASSO [11], SCAD [12], and MCP [13] regularization methods that can simultaneously detect multiple change points in linear models. In addition, the two-stage procedure has been extended to accelerated failure time (AFT) models [14].
Despite the aforementioned developments, research on the inference for multiple change points remains limited. Under the null hypothesis, asymptotic [15] or approximate [16] distributions of test statistics have been derived, which enables quantifying uncertainty in the number of change points. For many testing procedures in change point analysis, the computation of critical values often relies on the asymptotic behavior of the test statistic under the null hypothesis. However, the convergence of the test statistic to its limiting distribution is often slow, and in some cases, the exact form of this distribution remains unknown. It has been noted that the bootstrap method is a computer-based statistical inference technique that can provide answers to a variety of statistical questions without relying on formulas. For example, ref. [17] proposed a bootstrap method in which the estimated error sequence is resampled with replacement to obtain confidence intervals for change points. Ref. [18] introduced an asymptotically valid confidence region for a single change point through the inversion of bootstrap tests. Ref. [19] studied the application of a circular overlapping block bootstrap method in the context of an at-most-one-change time series model with an abrupt change in the mean and dependent errors. In the field of a single change point estimation, the bootstrap technique has emerged as a valuable tool for approximating unknown probability distributions and the characteristics of change point estimators. These methods make it possible for us to provide confidence intervals for multiple change points. Ref. [20] addressed this problem in mean shift models by proposing the bootstrap construction of pointwise and uniform confidence intervals for multiple change points based on a moving sum procedure.
This paper aims to construct confidence intervals for multiple change points. By [10], the multiple change point detection problem can be formulated as a model selection problem. Before using bootstrapping, it is important to ensure that the estimates of the number of change points and the estimates of the within-segment parameters are consistent. However, regularization methods such as the LASSO and SCAD may suffer from the bias problem inherited from the penalty function [12,21]. Specifically, LASSO may select more irrelevant variables, leading to an overestimation of the number of change points. To alleviate this problem, we consider adopting the -regularization method to achieve consistency between the estimates of the number of change points and their locations. Although the subset selection, while unbiased, is often computationally expensive, several optimization strategies and algorithms have been proposed to overcome the computational difficulties. For example, ref. [22] introduced an iterative algorithm called the orthogonal greedy algorithm (OGA) for high-dimensional regression models, which sequentially selects input variables to be included in the linear regression model and proposed a procedure named OGA + HDIC + Trim. OGA is a fast stepwise forward regression method that starts with a null model and adds predictors via component-wise linear least squares estimation. HDIC is a high-dimensional information criterion used to enter predictors into the model along the OGA path. The Trim method defines a subset to exclude additional irrelevant variables from OGA + HDIC. To construct confidence intervals for multiple change points, we proceed as follows. We first cut the data sequence into segments. Due to its model selection consistency and expected convergence properties, we apply OGA + HDIC + Trim to find data segments containing change points. We then utilize sup-Wald-type test statistics to locate them. Finally, we apply the bootstrap method to construct confidence intervals for multiple change points using the bootstrap estimated centered error sequence.
The main contributions of this paper are as follows. As described above, we first propose a two-stage procedure to detect multiple change points by using OGA + HDIC + Trim procedure and sup-Wald-type test statistics. In the first stage, we cut the data sequence into segments. In addition, we give the asymptotic distributions of the change point estimators under certain conditions. Based on this framework, we further explore the application of bootstrapping techniques in constructing confidence intervals for the change points and demonstrate the validity of the bootstrap method, i.e., the proposed bootstrap -confidence intervals asymptotically attain the coverage probability of for a given [20]. Last but not least, we illustrate the effectiveness and applicability of the proposed method through extensive simulation studies and a real data example, respectively.
The rest of this paper is organized as follows. Section 2 details the detection of multiple change points using the OGA + HDIC + Trim procedure and sup-Wald-type test statistics. Furthermore, Section 3 introduces the resampling bootstrap method for the change point estimators based on a two-stage procedure and Section 4 gives the theoretical properties of the proposed bootstrap method. Section 5 presents extensive simulation studies. Section 6 applies the proposed method to the seismograms of the 1982 Urakawa–Oki earthquake. Technical proofs of the main results are relegated to the Appendix A. In this paper, vectors and matrices are denoted in bold type.
2. Multiple Change Point Detection Based on Two-Stage Procedures
Assume that satisfy the following linear regression model with s change points located at as
where n is the sample size, is a sequence of q-dimensional predictors; is an unknown q-dimensional vector of regression coefficients; s is an unknown number of change points; are unknown change points; , are unknown changes in regression coefficient vectors at change points; and ’s are unobservable random errors.
The estimation of the regression coefficients and is hampered by the unknown parameters s, . In light of [23], we propose to replace s in (1) with a predetermined number of segments, denoted by , to facilitate the estimation of the regression coefficients. This replacement allows us to identify the total number of change points. Specifically, we partition the data sequence into segments, where as . This ensures that all segments excluding the first segment have length m, while the length of the first segment is . Let and . See (3) for more details on segmentation. We assume that for , so that each segment , for , contains at most one change point.
We denote the segment as if . This partitioning results in the following model:
where
and with ) . for all .
Remark **1.**By the definition of m, any two segments also contain at most one change point. From (2), it follows that
Based on the partition, we can obtain least-squares estimates for within each segment.
1. When , the change point coincides with the pre-specified cut-point and . The regression coefficients corresponding to the three segments are denoted by , and are equal to , , and , respectively. The segment that contains the change point can be identified by . 1. When , due to the existence of , the linear regression model is misspecified on , causing to converge to the pseudo-true value under model misspecification [24,25]. Since is different from both and , can be determined by the following: and .
According to Remark 1, we reformulate the change-point detection problem as a high-dimensional variable selection task by constructing differences between coefficients. Therefore, (2) can be rewritten in matrix form as follows:
where ,
and . In addition, the definitions of , , and represents the artificial n-dimensional error due to model misspecification, whose elements are equal to zero for all .
It can be seen that if or for . Let . It is important to note that is evident for all . Therefore, the estimation of comes down to identifying the non-zero elements from , which is the focus of the subsequent subsections.
2.1. Segment Selection
By the definition of m, each segment contains a change point. In this subsection, our goal is to select segments for . From the above statement, we can see that selecting all non-zero elements of can yield the estimation of effectively. Therefore, after the cutting stage, the problem of detecting multiple change points is reduced to a variable selection problem in high-dimensional scenarios. We use the OGA + HDIC + Trim method for the segment selection.
We rewrite the model (3) as follows:
where , are all the column vectors of , and . Without loss of generality, replace by and by . Define , where is the orthogonal projection matrix onto the linear span of . For convenience, denote . The proposed OGA+HDIC+Trim algorithm is outlined in Algorithm 1. Algorithm 1 OGA + HDIC + TrimRequire: response vector , regressor matrix . Initialzation: set , and . While do Compute and update ; Compute via , where ; Compute via . end Compute the minimum of HDIC via
return via
In this context, the value of denotes the maximum number of iterations, and the convergence rate theory of OGA in [22] shows that . The parameter satisfies the conditions and , where . Let be the estimate obtained by applying the OGA+HDIC+Trim procedure. Therefore, we derive an estimate of from as Denote
where . It is clear that if and , then and . Let . It only includes the change point since , and it ensures that no change point overlaps with the cut-point of . By following the steps outlined above and considering that the Wald test cannot detect the location of the change point at the partition boundary, we derive the following selected segments:
where .
2.2. Refining
By Theorem 1 in Section 4, converges to s as . Hence, we assume that for a large n, there exists such that . We now show how to estimate this change point. Note that for , we have
where and . Here, and and are unknown q-dimensional vectors of the regression coefficients on the line segment and , respectively. .
We compute the sup-Wald test statistics [26] and estimate by
where , , and . We also obtain the estimates of by regressing on and , respectively. The limiting behavior of is given in Section 4.
Since the multiple change points are not dense in the data sequence, without loss of generality, we assume that , so that each segment contains at most one change point. Note that if m is too small, it leads to inconsistency in estimating the regression parameters and increases the computational time. Therefore, we need to avoid choosing too small a value for m. To address this issue, we define according to Theorem 2 in Section 3, where serves as a tuning parameter, and is the ceiling function. We study the range of values of on the interval . The final value of m is determined using the Bayesian Information Criterion (BIC) as follows:
3. Bootstrap Confidence Intervals for Multiple Change Points
In this section, we construct bootstrap confidence intervals for multiple change points. It helps us to study the behavior of multiple change points in a linear regression model. Obviously, the two-stage procedure inherently involves the quantification of uncertainty in the number of change points and their respective locations.
We define the estimated residuals and the centered residuals as follows:
where and . Let be independently and identically distributed (i.i.d.) random variables sampled from the empirical distribution function of . We then consider the bootstrap observations defined as follows:
where represents the bootstrapped version of the residuals. To obtain an approximation to the distribution of in (9), a bootstrap statistic of the estimate is defined as
where the number of change points and the are obtained by performing OGA on as in (6). The data sequence segmentation remains unchanged. In this case, , and represents the least-squares estimates obtained by regressing on and . Next, we describe the construction of bootstrap CIs for multiple change points.
1.We generate a bootstrap sample by randomly sampling residuals from the set as in (11);2.We apply the two-stage procedure and compute the local maximizer obtained as in (12) for each estimated segment;3.For a given bootstrap sample size B, we repeat Steps 1-2 B times and record , , where .
Therefore, the bootstrap-based approximation for the change point can be constructed. Generally, for any , the bootstrap confidence interval for the change point is given by the following:
where , and
If , then is an estimate of for . If some elements of are not in the set , then has no corresponding bootstrap estimate for some j. Hence, the bootstrap CI of is constructed using instead of in (13), which yields
where
and
4. Theoretical Validity of the Bootstrap Confidence Intervals
To investigate the performance of the bootstrap CIs for multiple change points, we make the following assumptions.
Assumption 1. If , then for Furthermore, if , then .
Assumption 2.
- is a sequence of independently and identically distributed random variables with and .*
Assumption 3.
- , where and is the ceilling function.*
Assumption 4.
- is stochastically bounded. is independent of the regressor for all i and j.*
Assumption 5.
- , and for some as .*
By Assumption 1, it follows that , i.e., there is at most one change point in each segment for a large n. Assumption 2 follows that the residuals are independent and identically distributed and justifies the use of bootstrapping to estimate the central error, helping generate the sample distribution of the change points. Assumption 3 assumes that the shift point is bounded from the endpoints for asymptotic purposes. Assumption 4 requires that there is enough data around the change point and at the beginning and end of the sample so that the change point can be identified. The asymptotic distribution of depends on various unknown quantities, with the magnitude of the change being the most significant. Assumption 5 is the minimum signal amplitude of the regression coefficient in the high-dimensional setting. The shift amplitude cannot be too small; otherwise, the change point will not be identified. Based on this, we give the necessary Assumption 5. Next, we establish the consistency of the number of change points and the change point estimator . The following theorem provides the consistency of the estimated number of change points.
Theorem **1.**Suppose that , , , and as . Under Assumptions 1–5, we have
where and are given in (6).
Theorem 1 extends Theorem 4 in [22] to the multiple change points detection case. The consistency and asymptotic distribution of change points estimators are given below.
Theorem 2. If as , under Assumptions 1–4, we have that when , and
where V is a strictly positive definite matrix, is a two-sided Wiener process, and is a fixed value or satisfies , as specified in Assumption 5.
Subsequently, we establish the validity of the bootstrap CIs in (14). For future reference, we define some notations here. Any symbol with a superscript ∗ denotes an object under the bootstrap probability measure, rather than the original measure used in some of the other sections. For example, denotes the conditional expectation with respect to the bootstrap probability measure conditional on the original data. Similarly, denotes the conditional probability under the bootstrap measure.
Theorem 3. Under the assumptions of Theorem 2, we have
The proofs of Theorems 2 and 3 are given in Appendix A.
Combining Theorem 3 with Theorems 1 and 2 establishes the validity of the bootstrap method for multiple change points.
Corollary 1. Under Assumptions 1–5, we have that, as ,
Since for each , by the Bonferroni correction, we have . The asymptotic validity of the proposed bootstrap CIs in (14) follows.
5. Simulation
In this section, we first present the simulation results for change point detection given in Section 2 and compare them with the two-stage multiple change point detection procedure involving LASSO (TSMCD_lasso_) by [10]. We also construct confidence intervals using the bootstrap method proposed in Section 3. We denote the CIs in (14) by bootstrap_oga,wald_.
5.1. Detection of Multiple Change Points
We consider the simulation setting where the change points , are, respectively, 150, 300, and 450, respectively, and generate data from the model
where are independent and follow the standard normal distribution. The simulated data are shown in Figure 1. In this model, represents a periodic autocorrelation sequence with a period of 30 and an autocorrelation order of 1.
We perform 1000 Monte Carlo simulations for multiple change point estimation in Table 1. According to [22], we take in (5), similar to AIC. We focus on counting the number of events for which . The percentage of the correct identifications of all change points, denoted as , reflects the proportion of replicates for which for all j. In addition, represents the proportion of replicates for which . The mean and standard error of the estimated change points are calculated for the replicates for which the difference between the estimated change points and the true value is less than or equal to 50 (i.e., ).
From Table 1, we can see that TSP_oga,wald_ generally outperforms TSMCD_lasso_ in terms of yielding a correct identification rate. It is noteworthy that TSMCD_lasso_ performs significantly worse than TSP_oga,wald_ in identifying all change points, especially at , as evidenced by the lower value. TSP_oga,wald_ and TSMCD_lasso_ show comparable estimation accuracy in terms of the mean and standard error (SE) of the estimated change points.
5.2. Bootstrap CIs
All results are based on 500 realizations in the simulation setting, and we use to give the corresponding bootstrap CIs. We assume the confidence level is . For each j, the coverage of the bootstrap CI is calculated as the proportion of simulated realizations where contains . For all j, the coverage of the bootstrap CIs is calculated as the proportion of simulated realizations, where contains all .
Table 2 confirms the effectiveness of our bootstrap method, as the empirical coverage probability for each is close to the nominal level. The overall coverage of the bootstrap confidence intervals for all j is slightly higher than the nominal level, which may be due to the complexity of multiple change point detection. The average computational time for the bootstrap_oga,wald_ procedure is 1.44 min per Monte Carlo replication, as measured on an Intel(R) Core(TM) i9-14900K processor (3.20 GHz) with 64 GB of RAM.
6. Empirical Application
In this section, we illustrate the proposed method by an application to the east–west component of seismograms, recorded at Iwanai station during the first foreshock of the Urakawa–Oki earthquake in 1982. This dataset has been previously studied by [27]. The time series data are analyzed using autoregressive models (AR) of an order of 5. The estimates and visualization of the 95% confidence level bootstrap CIs are presented in Table 3 and Figure 2, respectively.
It can be seen from Table 3 that change points are detected at 3074 and 3914. In [27], they found the estimated change points to be 3079 and 3929. It is noteworthy that [27]s’ results and ours are close. In geology, these two change points represent the arrival times of P-waves and S-waves, which are two types of seismic waves. From Figure 2, it is clear that the confidence interval (CI) of the first change point is narrower than that of the second change point.
This example demonstrates the applicability and effectiveness of our method in detecting change points in seismic data. By accurately identifying the locations of structural faults, we can gain insights into the underlying geological processes and improve our understanding of seismic events.
7. Conclusions
This paper effectively addresses the bias issues often encountered when using OGA for model selection and the estimation of segments containing change points in the cutting stage. The accuracy of multiple change point estimation is improved by applying sup-Wald-type test statistics in the refining stage. The proposed method successfully constructs confidence intervals for multiple change points by using a bootstrapping technique with a two-stage procedure to quantify the uncertainty of multiple change points. The reliable construction of confidence intervals makes this method a valuable addition to the field of change point analysis and regression modeling. The bootstrapping technique also guarantees asymptotic validity. Numerical studies demonstrate the statistical accuracy of the proposed method. Our method can also be applied together with block bootstrapping to the parameter changes of linear regression models with dependent errors.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Haynes K. Eckley I.A. Fearnhead P. Computationally efficient changepoint detection for a range of penalties J. Comput. Graph. Stat.20172613414310.1080/10618600.2015.1116445 PMC 699422632063685 · doi ↗ · pubmed ↗
- 2Picard F. Robin S. Lavielle M. Vaisse C. Daudin J.J. A statistical approach for array CGH data analysis BMC Bioinform.200562710.1186/1471-2105-6-27PMC 54955915705208 · doi ↗ · pubmed ↗
- 3Li J. Fearnhead P. Fryzlewicz P. Wang T. Automatic change-point detection in time series via deep learning J. R. Stat. Soc. Ser. B Stat. Methodol.20248627328510.1093/jrsssb/qkae 004 · doi ↗
- 4Killick R. Fearnhead P. Eckley I.A. Optimal detection of changepoints with a linear computational cost J. Am. Stat. Assoc.20121071590159810.1080/01621459.2012.737745 · doi ↗
- 5Bai J. Perron P. Estimating and testing linear models with multiple structural changes Econometrica 199866477810.2307/2998540 · doi ↗
- 6Bai J. Perron P. Computation and analysis of multiple structural change models J. Appl. Econom.20031812210.1002/jae.659 · doi ↗
- 7Davis R.A. Lee T.C.M. Rodriguez-Yam G.A. Structural break estimation for nonstationary time series models J. Am. Stat. Assoc.200610122323910.1198/016214505000000745 · doi ↗
- 8Harchaoui Z. Lévy-Leduc C. Multiple change-point estimation with a total variation penalty J. Am. Stat. Assoc.20101051480149310.1198/jasa.2010.tm 09181 · doi ↗