Bio-Inspired Swarm Confrontation Algorithm for Complex Hilly Terrains
He Cai, Fu Ma, Ruifeng Ni, Weiyuan Xu, Huanli Gao

TL;DR
This paper introduces a new bio-inspired algorithm for swarms in games on hilly terrain, improving coordination and win rates over existing methods.
Contribution
The paper introduces a decentralized swarm algorithm inspired by animal hunting strategies for complex terrains in games.
Findings
The algorithm achieves a confrontation win rate exceeding 80% in complex hilly terrains.
It outperforms existing techniques in engagement efficiency and survivability.
Two novel performance indices are introduced to better assess algorithmic effectiveness.
Abstract
This paper explores a bio-inspired swarm confrontation algorithm specifically designed for complex hilly terrains in the context of electronic games. The novelty of the proposed algorithm lies in its utilization of biologically inspired strategies to facilitate adaptive and efficient decision-making in dynamic environments. Drawing from the collective hunting behaviors of various animal species, this paper distills two key confrontation strategies: focused fire for target selection and flanking encirclement for movement coordination and attack execution. These strategies are embedded into a decentralized swarm decision-making framework, enabling agents to exhibit enhanced responsiveness and coordination in complex gaming landscapes. To validate its effectiveness, extensive experiments were conducted, comparing the proposed approach against three established algorithms. The results…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
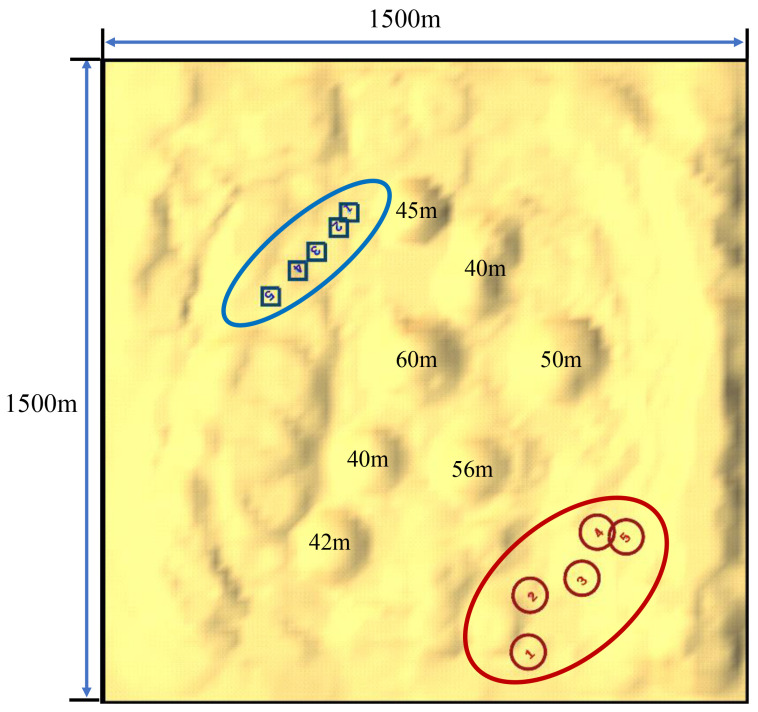 Figure 1
Figure 1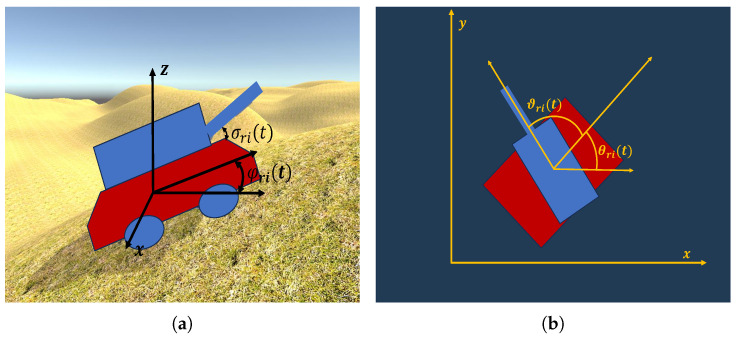 Figure 2
Figure 2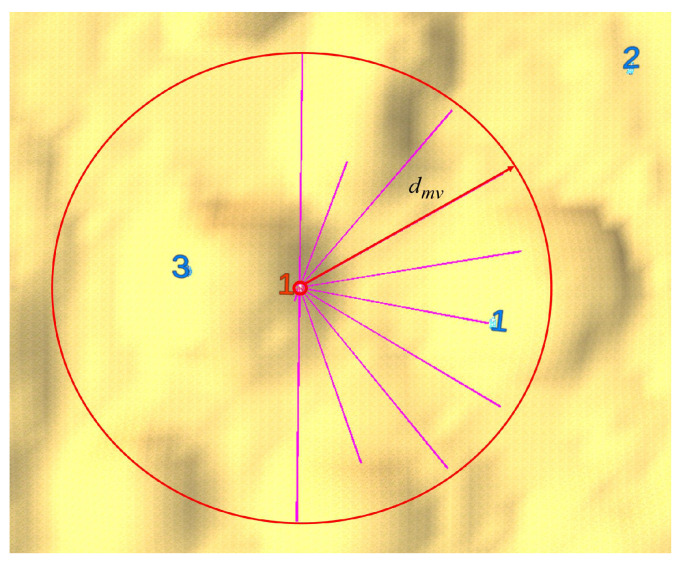 Figure 3
Figure 3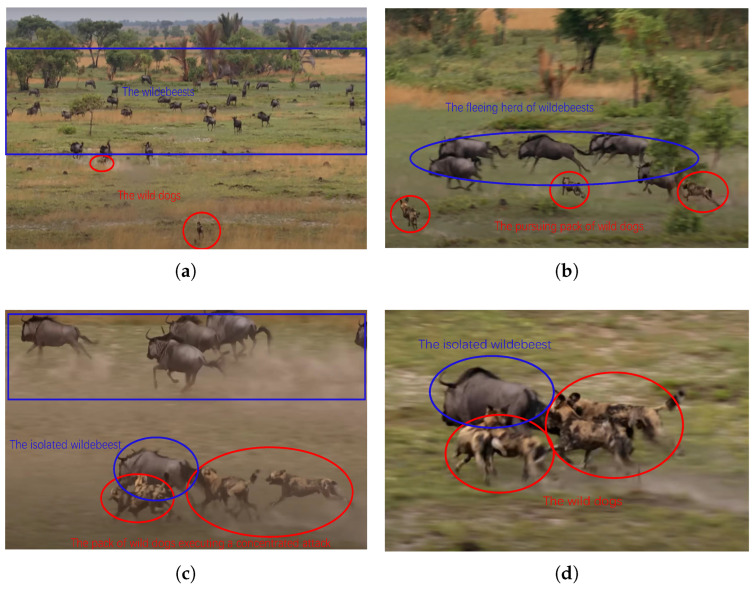 Figure 4
Figure 4 Figure 5
Figure 5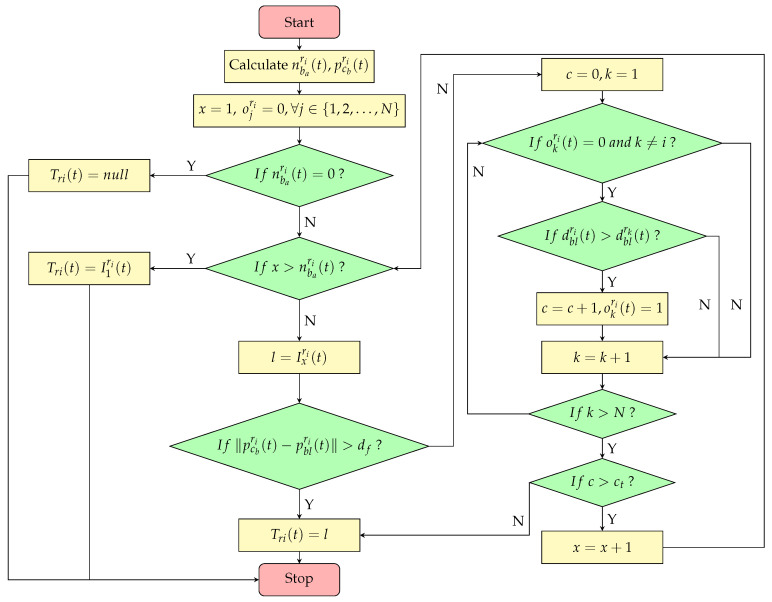 Figure 6
Figure 6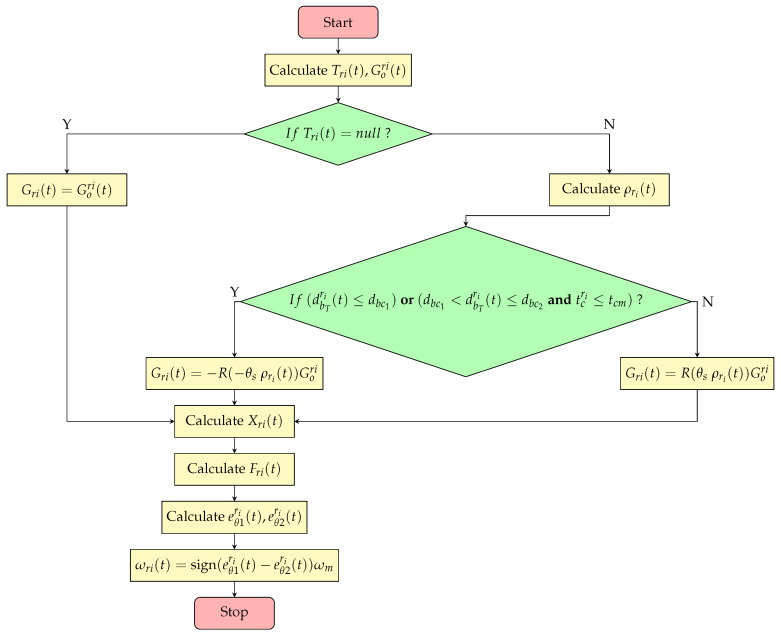 Figure 7
Figure 7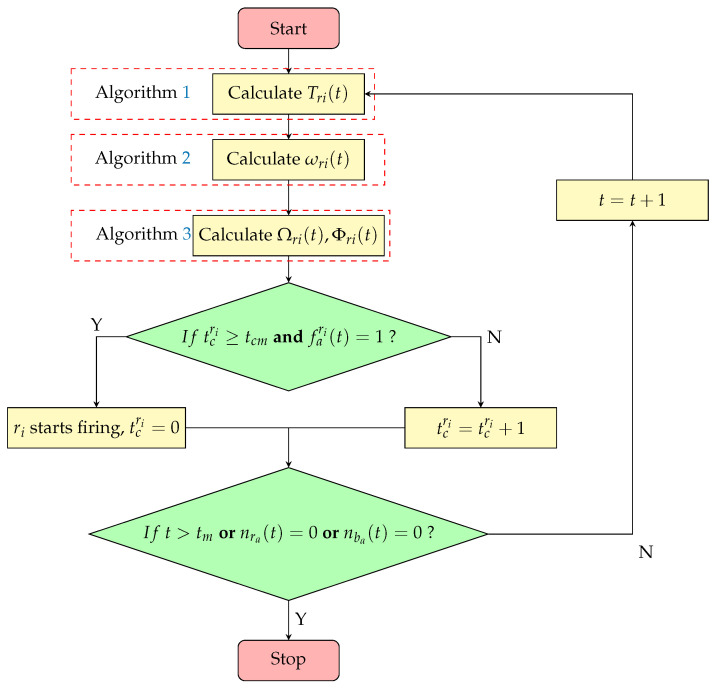 Figure 8
Figure 8 Figure 9
Figure 9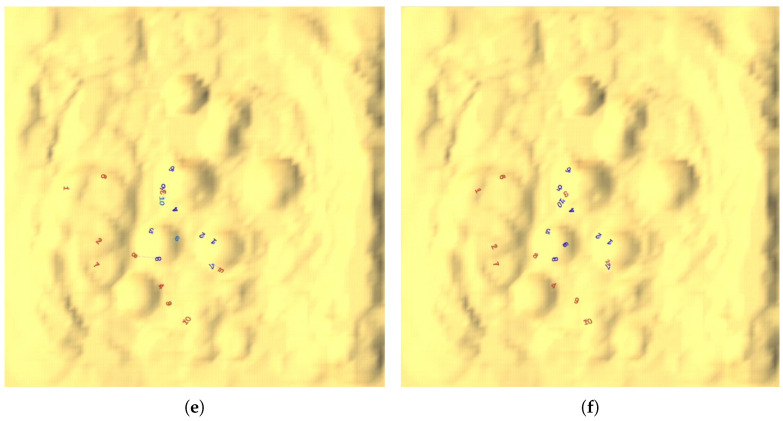 Figure 10
Figure 10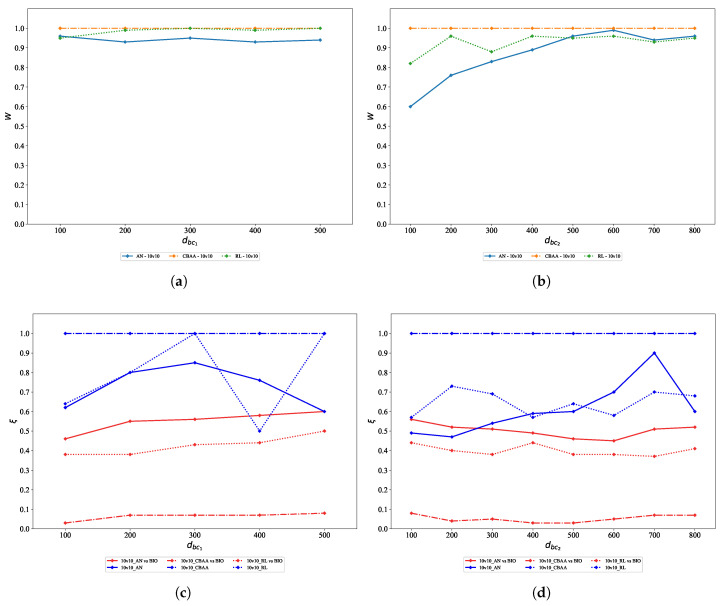 Figure 11
Figure 11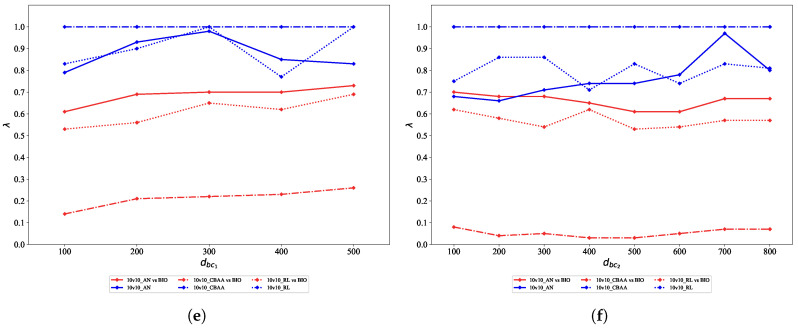 Figure 12
Figure 12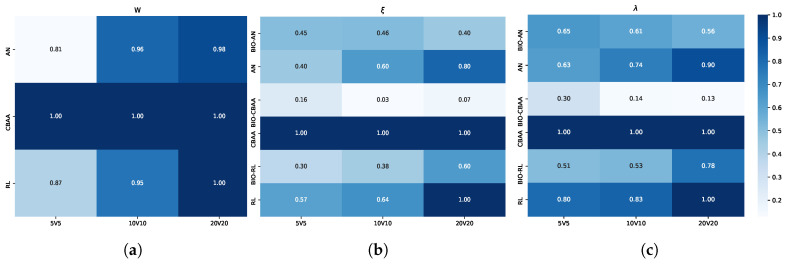 Figure 13
Figure 13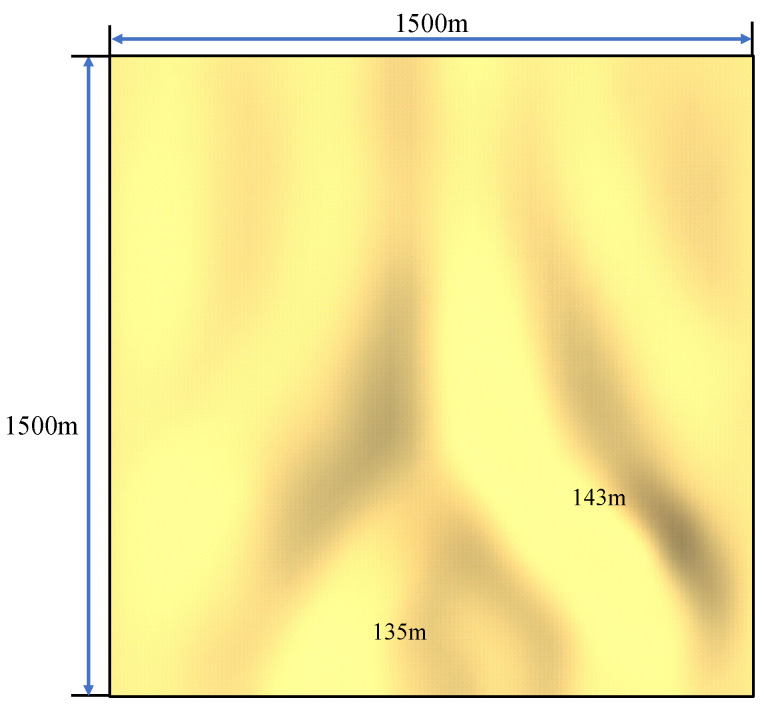 Figure 14
Figure 14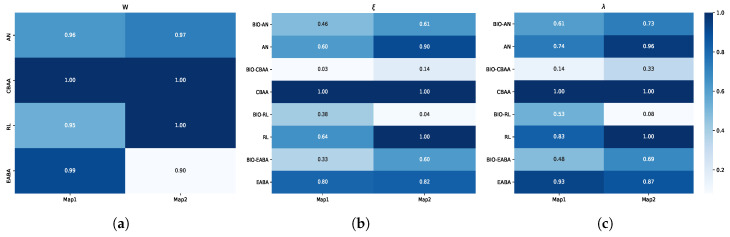 Figure 15
Figure 15- —National Natural Science Foundation of China
- —Fundamental Research Funds for the Central Universities
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsReinforcement Learning in Robotics · Artificial Intelligence in Games · Robotic Path Planning Algorithms
1. Introduction
With the advancement of technology, there is a growing demand for applications involving unmanned swarm cooperation and confrontational scenarios, not only in real-world robotics but also in virtual environments such as electronic games. Swarm confrontation represents a novel tactical paradigm that leverages the coordinated behavior of multiple unmanned aerial vehicles (UAVs) [1,2,3,4,5]. These algorithms have also found widespread application in gaming simulations, such as in StarCraft II [6], where complex agent coordination and strategic planning play a critical role in gameplay.
To enhance task execution efficiency and the success rate of agent swarms in complex and dynamic confrontational environments, a series of simulation methodologies for swarm confrontation strategies has been developed [7,8]. Evolutionary algorithms, such as particle swarm optimization and differential evolution, play a pivotal role in this research. These algorithms iteratively refine candidate solutions by emulating biological evolutionary mechanisms, including selection, crossover, and mutation, to converge toward optimal solutions. Multi-agent reinforcement learning (MARL), a subfield of reinforcement learning [9], focuses on developing strategies in environments where multiple agents coexist and interact. Each agent learns to perform optimal actions through collaboration or confrontation with other agents to achieve its objectives.
In recent years, swarm intelligence algorithms have seen substantial advancements [10] and have played a pivotal role in swarm confrontation. Reference [11] presented the mayfly algorithm, an optimization method inspired by mayflies’ behavior, combining swarm intelligence and evolutionary principles. Reference [12] presented a mathematical model that captures red fox behaviors such as foraging, hunting, population dynamics, and evading predators. By combining local and global optimization strategies with a reproduction mechanism, this model forms the basis of the red fox optimization algorithm. Reference [13] introduced the Flying Foxes Optimization (FFO) algorithm, drawing inspiration from the adaptive survival strategies of flying foxes in heatwaves. By incorporating fuzzy logic for dynamic parameter adjustment, FFO functions as a self-adaptive, parameter-free optimization technique. Reference [14] offered an innovative approach in swarm robotics, drawing inspiration from the foraging behavior of fish schools. By employing a bio-inspired neural network and a self-organizing map, the swarm replicates fish-like behaviors, including collision-free navigation and dynamic subgroup formation. Reference [15] explored the critical role of UAV swarms in the modern world, highlighting the urgent need for attack–defense-capable swarms. It introduced a bio-inspired decision-making method for UAV swarm confrontations using MARL, addressing the challenges of exponential training time as swarm size increases, drawing inspiration from natural group hunting behaviors.
This paper presents a bio-inspired confrontation algorithm aimed at improving success rates in swarm-based confrontations, particularly within the context of electronic games. Specifically, in a hilly environment, the undulating terrain obstructs the agents’ field of view, preventing them from fully acquiring real-time information about the opponent. Inspired by the hunting behaviors of various animal groups, such as lion prides and wild dog packs, two confrontation strategies are explored: the focused-fire strategy and flanking encirclement strategy. These strategies are integrated within hilly environments to develop a novel biomimetic swarm confrontation algorithm.
The contributions of this work are as follows:
- In contrast to purely 2D or 3D confrontation environments [15,16,17,18,19,20,21], this is the first time that a semi-3D confrontation environment, i.e., hilly terrain, has been considered regarding the swarm confrontation problem, which brings many challenges. First, the ability of the agent to gather information about opponents is limited. Second, virtual projectiles or actions executed by agents may be blocked by the terrain. Furthermore, the terrain constrains the agents’ postures, adding even more complexity to decision-making.
- Compared to agents that employ a particle model for movement [8,16,22,23,24], to suit the semi-3D confrontation environment, this paper adopts the unicycle model as a kinematic model of agents, which is more realistic yet complicated for confrontation scenarios. In addition, the rotating module responsible for targeting can freely spin on its supporting plane, while the elevation unit is capable of vertical adjustment. As a result, incorporating the additional degrees of freedom introduced by these rotational components leads to a more complex kinematic model compared to the standard unicycle model.
- Drawing on the behavioral characteristics exhibited by prides of lions and packs of wild dogs during their hunts, this paper proposes key algorithms suited to swarm confrontations. Compared with algorithms based on reinforcement learning or target-based assignment [15,25,26], the proposed approach focuses on specific behaviors throughout the confrontation, enhancing its interpretability and practical applicability—particularly in simulation-based environments such as electronic games. In direct comparisons against the aforementioned algorithms, the proposed method achieves a win rate exceeding 80%.
- For the evaluation of confrontation algorithms, in addition to traditional win rate assessment [24,25,27,28,29], two more performance indices are adopted, i.e., the agents’ quantity loss rate and the agents’ health loss rate. These two indices reflect the cost paid by the swarm confrontation algorithm to win from different perspectives, and the test results further highlight the superiority of the proposed bio-inspired swarm confrontation algorithm.
2. Related Work
2.1. Optimization Algorithms
In terms of evolutionary algorithms, reference [16] proposed an evolutionary algorithm (EA)-based attack strategy for swarm robots in denied environments, eliminating reliance on global positioning and communication. Each robot optimizes its movement using local sensing, evaluating threats and benefits through an EA-driven fitness function. With integrated collision avoidance, the swarm achieves effective collaboration and confrontation. Reference [30] introduced an evolutionary task allocation method for optimizing drone task distribution based on collaborative behavior, alongside a collaborative control method for UAVs to maintain formation during task execution. Reference [31] developed an optimized multi-UAV cooperative path planning approach for complex confrontation scenarios. A realistic threat model was developed, incorporating threat levels and fuel consumption constraints within a multi-objective optimization framework. Reference [32] proposed an evolutionary expert system tree for managing unexpected situations in aerial combat, while reference [33] introduced an enhanced particle swarm optimization algorithm that improves global search capabilities without adding computational complexity. Reference [34] examined strategic choices in a game-theoretic model of UAVs using a strategy evolution game, and reference [35] proposed an evolutionary optimization algorithm addressing the limitations of particle swarm optimization. Reference [36] expanded torch, a heterogeneous–homogeneous swarm coevolution method designed to enhance the evolutionary capabilities of swarm robots. Addressing the challenges of balancing evolutionary efficiency and strategy performance, torch employs a swarm coevolution mechanism to accelerate adaptation. A behavior expression tree is incorporated to expand the strategy search space, enabling more flexible and effective evolution. Reference [37] presented an improved differential evolution method based on Pareto optimal matching for multi-objective binary optimization problems. However, further optimization is required for complex environments with obstacles and multi-region challenges, and for integrating task allocation and collaborative control.
2.2. Multi-Agent Reinforcement Learning
MARL has seen significant advancements in recent years [38,39]. Reference [40] proposed the hierarchical attention actor–critic (HAAC) algorithm to enhance decision-making in large-scale UAV swarm confrontations. By integrating a hierarchical actor policy with a centralized critic network based on the hierarchical two-stage attention network, HAAC captures UAV interactions and optimizes coordination. It effectively reduces state and action space complexity, improving scalability and outperforming existing methods in large-scale scenarios. Reference [41] proposed a one-vs-one within-visual-range air combat strategy generation algorithm based on a multi-agent deep deterministic policy gradient (MADDPG). The combat scenario is modeled as a two-player zero-sum Markov game, incorporating a target position prediction method to enhance decision-making. To bypass the constraints of basic fighter maneuvers, a continuous action space is adopted. Additionally, a potential-based reward shaping method improves learning efficiency. Reference [42] introduced a learning-based interception strategy for UAV territorial defense against invaders from various directions and speeds. The initial state’s impact on interception success was analyzed to define viable defense boundaries. Given the continuous action and state spaces, conventional decision methods face dimensionality issues. To address this, a fuzzy logic-enhanced actor–critic algorithm was proposed, effectively reducing computational complexity. To manage group situational complexity, reference [43] proposed a multi-agent transformer integrated with a virtual object network. Furthermore, reference [44] established two non-cooperative game models within the multi-agent deep reinforcement learning paradigm, successfully achieving Nash equilibrium in a five-on-five drone confrontation scenario. Reference [45] validated task allocation and decision-making in a simulation environment with mobile threats and targets. Reference [28] proposed a MARL approach that integrates macro actions and human expertise for UAV swarm decision-making. By modeling the swarm as a multi-agent system and using macro actions to address sparse rewards and large state-action spaces, the method enhances learning efficiency. Human-designed actions further optimize policies, enabling superior performance in complex confrontation scenarios. Lastly, reference [46] explored pursuit–evasion using deep reinforcement learning, where multiple homogeneous agents pursue an omnidirectional target under unicycle kinematics. A shared experience approach trains a policy for a fixed number of pursuers, executed independently at runtime.
Compared to the aforementioned algorithms, the proposed algorithm seamlessly integrates behaviors observed in animal confrontations into the confrontation process. It eliminates the need for model training and complex iterative computations while still delivering high performance.
Notation: denotes the set of real numbers. For two vectors, a and b, and denote the inner product and cross product of a and b, respectively. For a nonzero vector a, is defined by
For , define the following rotation matrix :
3. Problem Description
In this paper, we consider the swarm confrontation problem of two swarms of agents in hilly terrain. In particular, the two swarms of agents have equal quantities and abilities. This setting is especially relevant to electronic game simulations, where agents frequently engage in symmetric confrontational tasks within terrain-rich environments. In this section, descriptions of the hilly terrain and the agent model are given first, which are then followed by a description of the swarm confrontation problem.
3.1. Confrontation Environment
A representative example of the hilly terrain used in this study for electronic game simulations is illustrated in Figure 1. Let and denote the length and width of the map, respectively, and let represent the maximum height of the terrain. Note that agents can only move along the surface of the hilly terrain, which brings three challenges that have never been faced before. First, the ability of the agent to gather information about opponents is limited, as the hills may block the agent’s field of view, as shown by Figure 1. Second, the shells fired by the agents may be blocked by the terrain. Third, the terrain constrains the agents’ posture, making it difficult to aim.
3.2. Agent Model
In this paper, agents are categorized into red and blue teams. Suppose each team consists of N agents. For , represents the ith agent on the red team, while represents the ith agent on the blue team. By default, the red team is equipped with the bio-inspired swarm confrontation algorithm, while the blue team is equipped with other existing swarm confrontation algorithms.
3.2.1. Kinematics
The kinematic equations for agent are given by
where represents the position of agent at time t; represents the linear speed; and represent the heading angle and angular velocity of the body, respectively; represents the pitch angle of the body, which is determined by the topography; and denote the heading angle and angular velocity of the rotating module, respectively, while and represent the pitch angle and angular velocity of the elevation unit, respectively; and denotes the sampling time. The various aforementioned angles are illustrated by Figure 2. Additionally, , , and denote the maximum rotational speed for , , and , respectively. In this paper, are considered to be the control inputs of agent . These control inputs will be specified later by the proposed bio-inspired swarm confrontation algorithm. At the onset of the confrontation, the initial parameters are configured as follows: , , , . Similarly, we can define for agent , and the details are omitted. Note that the agents of the blue team have the same linear speed v and maximal rotational speeds ( , , and ) as the agents of the red team.
3.2.2. Information Acquisition
During confrontation, an agent detects opponents by uniformly emitting rays, as shown by Figure 3. Define . The set of opponents whose information can be obtained by agent at time t is defined as follows:
where denotes the maximum detection range of the ray. Similarly, denotes the set of opponents whose information is accessible to agent at time t.
Note that on the one hand, the rays can only detect within the maximum detection range , and on the other hand, the rays can be obstructed by hills. For agent , it can acquire the following information at time t.
The positions of all the surviving agents of the red team at time t.The positions of all the surviving agents of the blue team belonging to the set .
The method of information acquisition for the agents of the blue team is the same.
3.2.3. Attack and Damage
Agents engage opponents by launching projectiles with an initial speed of , which subsequently follow a ballistic trajectory under the influence of gravity. The direction of the projectile is determined by the posture of the elevation unit. Each agent starts with an initial health point ( ), and once hit by a shell, the health point is reduced by . Let denote the health point of at time t. If , agent is considered destroyed. Moreover, the minimum firing interval between two attacks is , and the swarm confrontation algorithm will decide when to fire. Similarly, we can define for .
3.3. Winning of the Confrontation
At the beginning of the confrontation, the red and blue teams are positioned at opposite corners of the map. Winning is declared for the side that annihilates all the agents of the opposing side within the time limit . If all the agents are destroyed within , or neither team wins within , it is called a tie.
3.4. Algorithm Performance Indices
To assess the performance of the algorithm, three algorithm performance indices are considered in this paper, namely, the win rate, average agent quantity loss rate, and average agent health loss rate, which are detailed as follows. Consider a series of M matches between the red and blue teams. For the red team, let denote the number of matches won by the red team, and represent the initial health points of all members of the red team. For , define and as the number of agents lost by the red team and the total health points lost by the red team in the kth winning match, respectively. Then, the performance indices for the red team’s algorithm are established as follows:
- Winning rate :
- Average agent quantity loss rate :
- Average agent health loss rate :
The parameters , , and can be similarly defined for the blue team following the same approach.
4. Bio-Inspired Swarm Confrontation Algorithm Design
Based on biologically inspired algorithms, agents must primarily address two key issues during the swarm confrontation process: selecting attack targets and making decisions regarding movement during the confrontation. This chapter begins by analyzing animal group behavior, summarizing the corresponding confrontation algorithms, and then connecting these algorithms to real confrontation scenarios for implementation.
4.1. Bio-Inspired Rules
We employ the following analysis to address the problem of target selection during each agent’s confrontation process. As illustrated in Figure 4, a pack of wild dogs spots a group of wildebeests and swiftly closes in, attempting to scatter them. The wildebeests initially cluster together to confront the predators but soon become startled and begin to flee, with the wild dogs in pursuit. During the chase, a smaller, isolated individual emerges from the group, becoming the focus of the wild dogs’ attention. The pack then concentrates its efforts on launching an attack on the vulnerable wildebeest.
For the wild dogs, each individual is smaller in size and weaker in strength compared to a wildebeest. When the wildebeests cluster together, it becomes difficult for the wild dogs to inflict damage. Therefore, when an isolated individual appears within the wildebeest group, the wild dogs quickly shift their target, creating a situation where the many overpower the few, effectively completing the hunt. Drawing on the collective hunting behavior of a wild dog pack, agents in a hilly-terrain confrontation can switch attack targets based on the opponent’s position. If an opponent is far from its group, it becomes the priority target. This tactic results in a localized numerical advantage, allowing agents to eliminate the target quickly. We refer to this behavior as the focused-fire strategy.
Efficient confrontation algorithms must select targets judiciously and make real-time decisions during the confrontation, adjusting their movement direction based on the evolving situation. This section further analyzes the group attack behavior of animals. As shown in Figure 5, three lions seize the opportunity to attack a buffalo, approaching it in a triangular formation. The central lion confronts the buffalo head-on, while the lions on both sides maneuver to flank it, forming a pincer movement. After completing the encirclement, the lions launch their attack and complete the hunt.
If the lion pride were to attack head-on as a group, the buffalo, sensing danger, would likely counterattack or flee, which could result in casualties among the lions or allow the buffalo to escape. The pride increases its chances of a successful hunt by attacking from multiple directions. In an agent-based confrontation, if two or more agents target the same opponent, one agent can engage the opponent head-on while the others flank from the sides, efficiently neutralizing the target. We refer to this behavior as the flanking encirclement strategy.
4.2. Design of Swarm Confrontation Algorithm
After analyzing and adapting bio-inspired rules, these principles need to be applied to practical confrontation algorithms. The design of the confrontation algorithm is mainly divided into three parts: target selection, motion planning, and automatic aiming. Taking the red agent as an example, the following sections detail the design of these three components.
4.2.1. Target Selection
Inspired by the hunting behavior of wild dogs in nature, the target selection algorithm employs the focused-fire strategy. Define . Let represent the number of surviving opponents detectable by , and let denote the central position of these opponents. Let denote the label of the xth closest surviving opponent to , and let denote the label of the attack target chosen by . Let be a positive integer and be a positive real number. The target selection algorithm is described by Algorithm 1. Algorithm 1 Target Selection Algorithm
- 1:input: —the number of surviving opponents detectable by ,
- 2: —the central position of these detected opponents.
- 3:output: —the label of the attack target chosen by .
- 4:set
- 5:if then
- 6:
- 7:else
- 8:
- 9: set
- 10: while and do
- 11:
- 12: if then
- 13:
- 14:
- 15: else
- 16: set
- 17: while do
- 18: if is surviving and then
- 19: if then
- 20: if then
- 21:
- 22:
- 23: if then
- 24:
- 25: else
- 26:
- 27:
- 28: if then
- 29:
According to Algorithm 1, and serve as input parameters, while functions as the output parameter. The target selection algorithm follows a multi-level decision-making process. First, after obtaining , evaluates the spatial distribution of its opponents. If the distance between and the center of visible opponents within ’s range exceeds , is considered to have deviated from its team formation, and prioritizes attacking . Second, as indicated in steps 10 to 27 of Algorithm 1, these steps involve an iterative computation process, with playing a crucial role in the iteration. If is positioned closer to its own team, determines its relative ranking within the team based on proximity to . If ranks beyond , it must recalculate and repeat this process iteratively until its ranking falls within . This design helps prevent the excessive concentration of attack targets among red agents, thereby reducing resource overflow and minimizing wastage. Finally, if no opponent within ’s field of view meets the above conditions, selects the nearest opponent as its attack target, denoted as . As described above, the algorithm not only prevents an excessive number of agents from attacking the same target, thereby avoiding unnecessary concentration of launched projectiles, but also creates a local numerical advantage. This demonstrates the focused-fire strategy proposed in this paper, and a flowchart of the algorithm is shown in Figure 6.
4.2.2. Motion Planning
Incorporating the competitive behavior of biological swarms into an agent’s confrontation process primarily involves planning its trajectory. Given that the field is undulating and there are no complex obstacles, we implement the agent’s path planning using the artificial potential field method. Considering that the agent also needs to avoid obstacles presented by teammates in the environment, the agent’s direction of movement can be decomposed into the sum of two vectors.
(1) Consider the motion planning of in the absence of obstacles. When , selects the nearest hilltop, denoted as , as its movement target to facilitate opponent searching. Conversely, when , selects as its movement target. Here, denotes the position of the opponent labeled , which has been assigned according to Algorithm 1. The movement direction toward the target is defined as follows:
In a hunt, a pride of lions typically attacks prey from multiple directions. The lions at the front often feint to distract the prey while the lions on the flanks wait for an opportunity to strike. Inspired by this behavior, agents can employ a flanking encirclement strategy during confrontations by setting different movement directions.
The following section introduces the method for determining the relative position of within the team. Let represents the relative position of within the friendly team that shares the same opponent. When , is in the middle; when , is on the left side; and when , is on the right side. The method for obtaining is presented as follows:
where represents the position of the agent closest to among the group of agents sharing the same attack target. Meanwhile, denotes the projected offset of within the team, and is the reference value used to determine the position interval. denotes the unit direction vector along the z-axis. The actual movement direction of in an obstacle-free environment is obtained by multiplying by the rotation angle and applying the resulting rotation matrix to . In the case where , is directly equivalent to .
(2) Calculate the vector between teammates and within the obstacle avoidance range . Since closer teammates require stronger obstacle avoidance force, the resulting vector should be larger. Therefore, it is necessary to normalize the vector and apply weighting. This algorithm selects as the weight for each vector, and finally, the sum of all vectors, denoted as , is obtained:
Since the influence of each vector on the agent’s movement is different, each vector needs to be normalized and weighted to obtain the final direction of movement :
where and denote the weight coefficients assigned to each vector.
Let represent the time elapsed since fired its last shell. represents the maximum distance threshold for to execute a retreating flanking encirclement strategy, while represents the minimum distance threshold for to execute a flanking maneuver during an advance, as well as the minimum retreat distance for flanking when . represents the distance for avoiding teammates. represents the heading angle of . and denote the deviation angles between the current movement direction and the final target direction in the clockwise and counterclockwise directions, respectively. The detailed implementation is presented in Algorithm 2. Algorithm 2 Motion Planning Algorithm
- 1:input
- 2:output
- 3:if then
- 4:
- 5:else
- 6: calculate the by Equations (9)–(11)
- 7: if then
- 8:
- 9: else
- 10:
- 11:calculate the by Equations (12) and (13)
- 12:calculate the by Equation (14)
- 13:
- 14:
According to Algorithm 2, when detects opponents, it first computes and then determines its relative position among teammates that share the same attack target. Based on , adjusts the direction of . If is positioned on the right side of the formation, is rotated clockwise by degrees; if it is on the left side, the rotation is counterclockwise by degrees. If is centrally positioned within the formation, its movement direction remains unchanged. In scenarios where only two red agents share the same attack target, it suffices to determine the relative position of the agent positioned farther from the target and assign it the appropriate movement direction. When is within a distance of from the attack target, or if its firing cooldown is active while being within , its movement direction is set to retreat. Based on the previous steps, agents can be assigned to either direct confrontation or flanking maneuvers, enabling them to attack opponents from multiple angles. This approach is referred to as the flanking encirclement strategy. The critical steps of this strategy are outlined in steps 6 to 10 of Algorithm 2. As a result, is determined. Then, incorporating the obstacle avoidance vector yields the final movement direction . The corresponding flowchart of the algorithm is shown in Figure 7.
4.2.3. Automatic Aiming Algorithm
In the following, taking as an example, the motion process of the rotating module and the elevation unit after determining the attack target is introduced. Upon identifying , adjusts and , based on the relative angle between the target and its position, thereby achieving target aiming. When calculates the vector from itself to the opponent, it then computes the angle between and the rotating module’s direction vector in the plane, rotating the rotating module left or right to make approach 0. Additionally, determines the angle between and the unit direction vector of the elevation unit , simultaneously rotating the elevation unit up or down to make approach 0. denotes the deviation range between the target angle and the actual angle. serves as a flag indicating whether is actively aiming at an opponent. The specific implementation process is shown in Algorithm 3. Algorithm 3 Automatic Aiming Algorithm
- 1:input
- 2:output
- 3:if then
- 4:
- 5:
- 6:
- 7:
- 8: if then
- 9:
- 10:
- 11: if and then
- 12:
- 13: else
- 14:
- 15: else
- 16:
4.2.4. Bio-Inspired Swarm Confrontation Algorithm
At the beginning of the confrontation, each agent determines its attack target using Algorithm 1. Then, it calculates its actual movement direction using Algorithm 2. Finally, Algorithm 3 is executed to precisely align with the target. During movement, the agent continuously assesses whether the conditions for firing are met and proceeds with the attack when appropriate. If all opponents are eliminated, the confrontation ends. Otherwise, Algorithms 1–3 are re-executed to recalculate the strategy.
By integrating the algorithm designs discussed above, the final pseudo-code and a flowchart of the bio-inspired swarm confrontation algorithm are established, and are presented in Algorithm 4 and Figure 8. and represent the total number of surviving agents for the red and blue teams, respectively. Additionally, the entire process is carried out sequentially within time step t. Algorithm 4 Bio-inspired Swarm Confrontation Algorithm
- 1:for step t do
- 2: execute Algorithm 1
- 3: execute Algorithm 2
- 4: execute Algorithm 3
- 5: if and then
- 6: agent starts firing
- 7:
- 8: else
- 9:
- 10: if or or then
- 11: algorithm terminates
- 12: else
- 13:
4.3. Algorithm Complexity Analysis
The bio-inspired confrontation algorithm presented in this paper consists primarily of three components: target selection, motion planning, and automatic aiming. The computational complexity of the automatic aiming algorithm is , while the complexities of the other components are as follows:
(1) Target selection: Calculating the closest opponent to the agent has a complexity of . Recalculating the opponent based on local principles has a complexity of , where m represents the number of recalculations required, . Calculating the centroid of opponents within the agent’s field of view has a complexity of .
(2) Motion planning: Determining the agent’s position relative to the same opponent group has a complexity of . Calculating the combined vector for teammate obstacle avoidance also has a complexity of . Similarly, calculating the combined vector for opponent obstacle avoidance is .
The overall algorithmic complexity is (best case) to (worst case).
5. Result Analysis
Comparative algorithms within the current environment must be introduced and adapted to evaluate the effectiveness of the swarm confrontation algorithm proposed in this paper. The comparative algorithms selected are the MARL Based on Biomimetic Action Space algorithm [15], the Consensus-Based Auction (CBA) algorithm [25], and the Assign Nearest (AN) algorithm [26].
5.1. Results Analysis for a Single Match
To more intuitively demonstrate the bio-inspired algorithm of agents during the confrontation process, this paper uses the AN algorithm as the opponent and selects a 10V10 confrontation scale for a detailed analysis of the confrontation process. The sequence of events is depicted in Figure 9.
In Figure 9d, blue agent becomes separated from the rest of its team during the confrontation, prompting red agents , , and to prioritize launching coordinated attacks on . This process exemplifies the focused-fire strategy employed in the bio-inspired approach. Similarly, in Figure 9e, blue agent is also isolated, leading red agents , , and to direct their attacks toward it in accordance with the same focused-attack strategy.
In Figure 9a,b, without knowledge of the opponent’s positions, the red team disperses its formation in preparation for launching attacks from multiple directions. In Figure 9c–f, the red agents in different positions exhibit varying retreat directions, forming both a frontal containment and flanking maneuvers. Additionally, the red agents actively move to flank the opponent, as seen with agents and in Figure 9c,d, and agents and in Figure 9d,e. These coordinated attacks from different directions demonstrate the flanking encirclement strategy.
5.2. Analysis of Results Under Different Scenarios
The confrontation scenarios in this paper are constructed using the Unity platform, a widely adopted development tool in the electronic gaming industry. A total of 100 simulation tests are conducted against three opponents under varying algorithm parameters, confrontation scales, and map configurations to comprehensively evaluate the performance of the proposed algorithm. Before the confrontation begins, the environmental parameters are initialized with values of , , , , , , , , , , , , , , , , , and . After each confrontation, the win rates and indices are recorded and analyzed to assess the impact of different parameter values on these outcomes.
5.2.1. Analysis of Results Under Different Algorithm Parameters
The algorithm in this study includes two critical parameters, and . Here, represents the minimum distance for maneuvering and containment; if the distance between an agent and an opponent is less than , the agent will immediately maneuver backward. represents the minimum distance for flanking during advancement and the maximum trigger distance for retreating and flanking maneuvers. When the distance between an agent and an opponent exceeds , agents on both sides will implement a flanking encirclement strategy. If the agent is in a firing cooldown state and the distance is less than , it will maneuver backward based on its position.
First, when both teams are in close proximity, agents may become overly clustered, leading to teammates obstructing the line of sight to opponents and diminishing the effectiveness of localized focused fire. This issue is further exacerbated when destroyed agents remain stationary at their last positions, increasing occlusion and reducing overall combat efficiency. To mitigate this, a minimum retreat distance threshold is introduced to ensure adequate spacing between agents and opponents, thereby facilitating the execution of confrontation strategies. Second, since projectiles require a cooldown period after each attack, agents are temporarily unable to inflict damage on opponents. To enhance agent safety, a retreat trigger is activated based on the distance threshold , ensuring that agents maintain a safe distance from opponents while their attack systems are in cooldown. In summary, these two parameters play a crucial role in the proposed confrontation algorithm, balancing attack efficiency and spatial positioning to optimize engagement outcomes.
When , is varied from to in increments of . Conversely, when , is varied from to in increments of . The confrontation win rates and indices for varying are shown in Figure 10a–c. The win rates and indices for varying are shown in Figure 10d–f.
First, we discuss the parameter . As shown in the figure, the algorithm’s win rate consistently exceeds 90%, indicating that variations in the value of have little effect on the algorithm’s win rate. However, indices and increase with the growth of , which indicates a decline in the algorithm’s performance. The agent’s backward maneuvering behavior is closely related to . When , the agent retreats when it is still far from the opponent, leading to a more dispersed formation. Even if the agent is in a favorable attack position, it cannot quickly regroup to eliminate the opponent and may become isolated, resulting in concentrated enemy fire.
Next, we analyze . The win rate graph shows that significantly impacts the algorithm’s performance. This is primarily due to the fast shell speed of the agents—when is set to a smaller value, agents are more likely to engage in direct encounters, with a high probability of being hit. A smaller also leads to prolonged exposure in the line of sight, limiting the ability to fully leverage terrain for tactical maneuvering. As a result, the attack pattern often degenerates into direct firefights. However, as increases, the win rate improves. For example, against AN, the win rate increases from 0.60 at to 0.96 at . Both and initially decrease as rises within the range [100, 600] m, but increase again when . For instance, when facing AN, as increases from 100 m to 600 m, decreases from 0.56 to 0.45, while drops from 0.70 to 0.61. When an agent is positioned closer to an opponent, the duration of direct engagement increases, reducing the agent’s maneuverability and making it more susceptible to concentrated opponent attacks. An agent will initiate a retreat only when its distance to the opponent falls below and its attack system is in a cooldown state. When is relatively large, the retreat trigger zone falls within the interval , which may cause the team to become overly dispersed, thereby weakening the effectiveness of the flanking encirclement strategy. Although retreat-oriented behavior can help maintain a high win rate, agents become more likely to be targeted and defeated through focused opponent attacks, ultimately degrading the algorithm’s overall performance.
5.2.2. Analysis of Results Under Different Confrontation Scales
The results under different confrontation scales are shown in Figure 11. From the confrontations at different scales, it is evident that larger confrontation scales lead to higher win rates for the algorithm, a trend especially pronounced when the opponent is AN. In 5v5 scenarios, the total health of the team is relatively lower compared to larger scales, and fewer agents are involved in flanking and localized focused-fire maneuvers. As a result, even when a flanking formation is established, if an agent on one side encounters the opponent head-on and is in a disadvantageous position, it may be quickly eliminated, causing the flanking encirclement strategy to collapse. Consequently, the win rate in such cases is only 0.81. However, as the scale increases, the bio-inspired strategy allows for a more complete formation. The increase in the number of agents on each side improves the margin for error, provides more firing points, and enables the agents to eliminate targets more quickly. On a scale of 20v20, the win rate consistently exceeds 95%.
The indices of the algorithm also vary with the confrontation scale. When facing AN and CBAA, the algorithm’s indices improve as the confrontation scale increases. Both algorithms are based on target selection, making the flanking encirclement strategy proposed in this paper highly effective. An increased confrontation scale leads to a greater number of attack positions and dilutes the opponent’s offensive intensity, thereby accelerating the elimination of opponents and mitigating team losses. From 5v5 to 20v20, both and drop by over 10. However, when facing RL, the results for and increase by more than 30% from 5v5 to 20v20. This is because the RL algorithm defaults to targeting the nearest opponent, and once an attack target is locked, agents using RL tend to charge aggressively. Suppose agents equipped with the BIO algorithm fail to form a proper formation in time. This results in clustering, increasing agent and HP losses, thereby reducing the algorithm’s overall performance.
5.2.3. Result Analysis on Different Maps
In addition to the current confrontation map, we conducted tests on another map. Compared to the previous map, this one has a gentler slope, and the specific terrain is shown in Figure 12. Furthermore, an additional comparative algorithm, the Evolutionary Algorithm-Based Attack (EABA) Strategy [16], was introduced in the other map. The confrontation scale was 10v10, with and . The confrontation results are shown in Figure 13.
From the results, it can be observed that the win rate of the algorithm in this paper remains above 90%. When facing AN and CBAA opponents, both and show slight increases. For example, in the confrontation against AN, increases from 0.46 to 0.61, and rises from 0.61 to 0.73. Due to the flatter terrain, the probability of shells being obstructed by the ground during flight is lower, which increases the likelihood that red team agents may be hit by opponent shells while spreading out to form a flanking formation, resulting in higher losses for their team. Conversely, when facing RL, both and show a slight decrease, which can be attributed to the RL model’s weaker adaptability to the new map, leading to lower confrontation performance. When confronting the EABA algorithm, the proposed approach yields a lower , while both performance indices, and , show noticeable increases. This phenomenon primarily results from the flatter terrain, which improves the likelihood of acquiring opponent position information. With enhanced visibility, the EABA algorithm can better exploit its fitness function through iterative optimization, thereby strengthening its confrontation capabilities and negatively impacting the performance of the proposed algorithm. In summary, this paper’s algorithm maintains a high win rate on the new confrontation map and achieves better and results compared to its opponents, demonstrating the algorithm’s advantages in different environments.
6. Conclusions
From the perspective of electronic game scenarios, this paper explores a swarm confrontation algorithm designed for complex hilly terrains. A highly dynamic hilly confrontation environment is constructed, where intelligent agent swarms from both a red and a blue team possess equal numbers and identical capabilities, with each agent’s movements constrained by kinematic limitations. Drawing inspiration from the hunting confrontation behaviors of wild dog packs and lion prides in nature, two key strategies are proposed: a focused-fire strategy for target selection and a flanking encirclement strategy for motion planning. The former improves local performance by aggregating agent behaviors toward a shared objective, while the latter improves overall confrontation efficiency through coordinated movement and poditioning. To comprehensively evaluate the algorithm’s performance, the proposed approach is benchmarked against three existing confrontation algorithms. A total of 100 confrontation tests are conducted across different algorithm parameters, confrontation scales, and environmental conditions. The experimental results demonstrate that the proposed algorithm achieves a confrontation win rate exceeding 80% against baseline algorithms while maintaining lower average agent loss rates and a reduced average agent health loss rate. In conclusion, this biologically inspired confrontation algorithm not only offers a straightforward and practical solution but also exhibits superior performance in swarm-based confrontations.
For future work, we suggest an in-depth exploration of opponent searching in environments with denied information to enhance the algorithm’s confrontation capabilities under limited visibility. Additionally, examining the impact of communication constraints, such as delays and packet loss, on swarm coordination and overall performance will be essential. Developing robust algorithms to mitigate these challenges will be a key focus moving forward.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ayamga M. Akaba S. Nyaaba A.A. Multifaceted applicability of drones: A review Technol. Forecast. Soc. Change 202116712067710.1016/j.techfore.2021.120677 · doi ↗
- 2Day M. Multi-Agent Task Negotiation Among UA Vs to Defend Against Swarm Attacks Ph.D. Thesis Naval Postgraduate School Monterey, CA, USA 2012
- 3Kong L. Liu Z. Pang L. Zhang K. Research on UAV Swarm Operations Man-Machine-Environment System Engineering Long S. Dhillon B.S. Springer Singapore 2023533538
- 4Niu W. Huang J. Miu L. Research on the concept and key technologies of unmanned aerial vehicle swarm concerning naval attack Command. Control. Simul.2018402027
- 5Xiaoning Z. Analysis of military application of UAV swarm technology Proceedings of the IEEE 2020 3rd International Conference on Unmanned Systems (ICUS)Harbin, China 27–28 November 202012001204
- 6Vinyals O. Babuschkin I. Czarnecki W.M. Mathieu M. Dudzik A. Chung J. Choi D.H. Powell R. Ewalds T. Georgiev P. Grandmaster level in Star Craft II using multi-agent reinforcement learning Nature 201957535035410.1038/s 41586-019-1724-z 31666705 · doi ↗ · pubmed ↗
- 7Xia W. Zhou Z. Jiang W. Zhang Y. Dynamic UAV Swarm Confrontation: An Imitation Based on Mobile Adaptive Networks IEEE Trans. Aerosp. Electron. Syst.2023597183720210.1109/TAES.2023.3288077 · doi ↗
- 8Zhang L. Yu X. Zhang S. Research on Collaborative and Confrontation of UAV Swarms Based on SAC-OD Rules Proceedings of the 4th International Conference on Information Management and Management Science. Association for Computing Machinery Chengdu, China 27–29 August 2021273278