AnnSQL: a Python SQL-based package for fast large-scale single-cell genomics analysis using minimal computational resources
Kenny Pavan, Arpiar Saunders

TL;DR
AnnSQL is a Python package that uses SQL to enable fast and efficient analysis of large single-cell genomics datasets on regular computers.
Contribution
AnnSQL introduces a new computational framework using SQL and DuckDB to significantly speed up single-cell genomics analysis.
Findings
AnnSQL operations on a 4.4 million cell dataset ran in minutes on a laptop, while equivalent operations in AnnData or Seurat took ~700× longer on HPC clusters.
AnnSQL enables large-scale single-cell analysis on personal computers with minimal computational resources.
Abstract
As single-cell genomics technologies continue to accelerate biological discovery, software tools that use elegant syntax and minimal computational resources to analyze atlas-scale datasets are increasingly needed. Here, we introduce AnnSQL, a Python package that constructs an AnnData-inspired database using the in-process DuckDb engine, enabling orders-of-magnitude performance enhancements for parsing single-cell genomics datasets with the ease of SQL. We highlight AnnSQL functionality and demonstrate transformative runtime improvements by comparing AnnData or AnnSQL operations on a 4.4 million cell single-nucleus RNA-seq dataset: AnnSQL-based operations were executed in minutes on a laptop for which equivalent operations in AnnData or Seurat largely failed (or were ∼700× slower) on a high-performance computing cluster. AnnSQL lowers computational barriers for large-scale…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
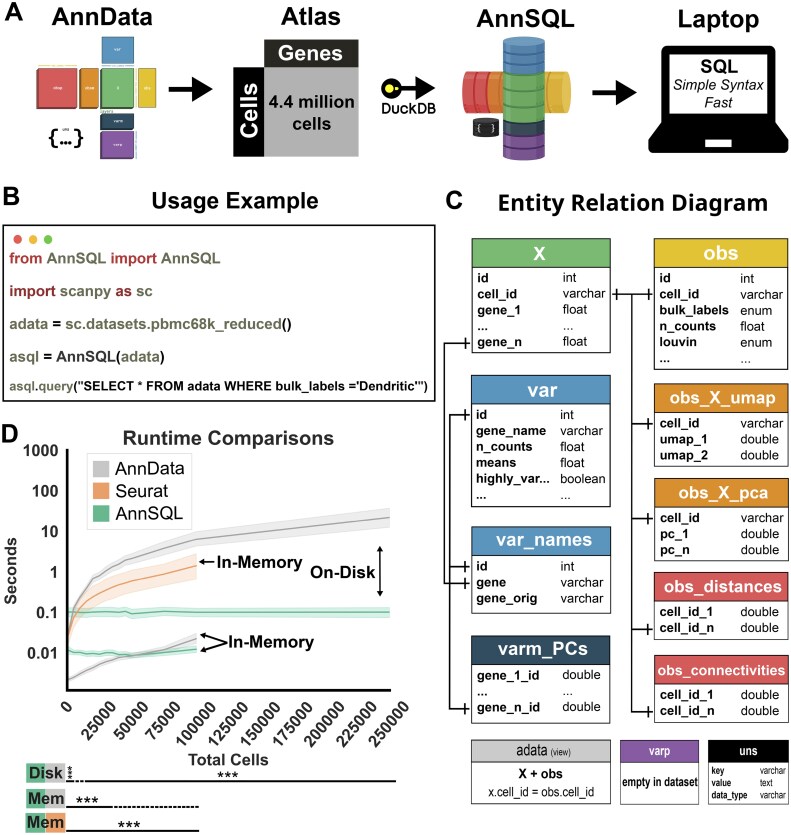 Figure 1
Figure 1| Procedure | Approach | Laptop | HPC (s) | ||
|---|---|---|---|---|---|
| Runtime (s) | Memory (Mb) | Runtime (s) | Memory (Mb) | ||
| Filtering | AnnSQL | 0.23 ± 0.01 | 147.3 ± 34.2 | 0.99 ± 0.14 | 321.6 ± 2.8 |
| AnnData (Backed) | 171.6 ± 11.3 | 89.6 ± 0.1 | 149.0 ± 17.5 | 788.6 ± 67.3 | |
| AnnData (Memory) |
| 9.6 ± 3.1 | 368 433.1 ± 165.2 | ||
| Seurat |
|
| |||
| Total Library Counts | AnnSQL | 257.4 ± 8.0 | 3799.4 ± 10.1 | 446.7 ± 8.3 | 4347.4 ± 52.7 |
| AnnData (Backed) |
|
| |||
| AnnData (Memory) |
|
| |||
| Seurat |
|
| |||
| Normalize Expression | AnnSQL | 3924.7 ± 59.3 | 29 407.8 ± 21.5 | 10 922.6 ± 178.2 | 56 965.9 ± 29.9 |
| AnnData (Backed) |
|
| |||
| AnnData (Memory) |
|
| |||
| Seurat |
|
| |||
| Log Transform | AnnSQL | 4057.4 ± 65.0 | 29 879.3 ± 21.7 | 12 739.6 ± 166.9 | 29 813.2 ± 124.6 |
| AnnData (Backed) |
|
| |||
| AnnData (Memory) |
|
| |||
| Seurat |
|
| |||
- —NIH Brain Initiative10.13039/100023835
- —Sloan Foundation, and Simons Foundation Autism Research Initiative
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSingle-cell and spatial transcriptomics · Genomics and Phylogenetic Studies · Cancer Genomics and Diagnostics
1 Introduction
Single-cell genomics technologies have emerged as transformative tools for discovering genome-wide RNA and chromatin landscapes of complex tissue at single-cell resolution in health and disease (Nayak and Hasija 2021, Wen et al. 2022, Heumos et al. 2023). Popular software tools have converged on data structures that facilitate storage, preprocessing, and myriad downstream analyses by prioritizing organizational clarity at the cost of computational performance. For example, Scanpy (Wolf et al. 2018) and the Scverse ecosystem (Virshup et al. 2021) use AnnData, while Seurat (Butler et al. 2018) uses Seurat objects. Now routine, “atlas-scale” descriptions of millions of cells based on tens of thousands to millions of genomics features strain software tools that use hierarchical structures (like AnnData) and often require high-performance computing clusters to execute. We were inspired to create AnnSQL for simple analysis of large datasets because in other contexts, SQL databases are a popular storage choice due to high transactional speed of row-oriented storage formats (Plattner 2009) and because no other SQL-based single-cell genomics analysis packages currently exist.
H5 hierarchical objects like AnnData have become standard storage for single-cell genomics software development in recent years (The HDF Group, 2020/2024). AnnData provides a convenient and compact structure for storing, organizing, and analyzing high-dimensional datasets. Applications can load AnnData entirely into system memory or, for large datasets, stream AnnData from disk using the “backed mode” parameter. Although AnnData allows faster statistical operations than traditional row-oriented databases, the backed mode often lacks support for aggregate functions.
Advances in SQL databases present new opportunities for single-cell genomics applications. Traditional SQL databases are limited because they often require technical knowledge for configuring and running databases as a background system process that requires connection to the service via the application, adding complexity that restricts the ease of data exploration. As an alternative, SQLite (Gaffney et al. 2022) operates in-process by creating a file-based database capable of direct application access yet a reliance on row-oriented transactions can restrict performance on statistical operations. To enable high-performance statistical functions and in-process queries, DuckDb (Raasveldt and Mühleisen 2019) was implemented as a column-based storage engine that operates using chunked vectors of column data. Strict in-process operation allows DuckDb data to be stored in a file and accessed in a memory-efficient manner using SQL via the Python API. These two database engines have recently been profiled for use with several genomic file formats, without exploring scRNA-seq data (Kioroglou 2025). We believe the features of DuckDb nominate it as a powerful storage and processing engine for cell-by-gene feature matrices.
We developed AnnSQL to bridge the gap between AnnData objects and SQL databases for single-cell genomics analysis. AnnSQL converts each layer of the AnnData hierarchical object into an equivalent SQL table, using the Python DuckDb API. AnnSQL supports both in-memory and backed modes of AnnData, enabling larger than memory databases to be built with minimal computational resources. AnnSQL-instantiated datasets can be fluidly queried using SQL syntax, allowing aggregate and statistical functions to be performed on larger than memory datasets with exceptionally fast run times.
2 Materials and methods
2.1 Package software structure
AnnSQL was built as an object-oriented Python package that parses the layer structure of typical AnnDataobjects into SQL tables (Fig. 1C) and provides flexible parameters. All functionality presented in AnnSQL v1, exists in 3 classes: (1) The BuildDb class is used to construct both in-memory and on-diskdatabases using the DuckDb Python client API. (2) The MakeDb class can be instantiated to create an on-disk database from a properly formatted AnnData object and stored with the “.asql” file extension. (3) The class AnnSQL is the main access point to instantiate and interrogate a dataset. The package has methods for queries, allows multiple return types, and contains extended functionality to help with data preprocessing.
*(A) AnnSQL workflow. AnnSQL converts AnnData objects using DuckDB to enable high-performance SQL queries. (B) Basic usage example using the pbmc68k reduced dataset provided with Scanpy. (C) The ERD of the database generated from the pbmc68k reduced dataset. (D) Runtime comparisons of six queries and filters (Supplementary Fig. S1A) for AnnSQL, AnnData (backed and non-backed modes displayed as on-disk and in-memory, respectively), and Seurat objects (in-memory) repeated six times for each of the six queries and filters at each library size. Shading represents 95% confidence intervals. Bottom lines represent statistical significance of each library size with respect to the comparison. Solid lines indicate significance and dashed lines indicate nonsignificance (**P < .001; paired t-test; Bonferroni corrected). Logos in Fig. 1A both have open source licenses. MIT and BSD-3, respectively.
2.2 Database construction
Each layer in a common single-cell AnnData object is a parameter in the AnnSQL and MakeDb classes. Both classes make calls to the BuildDb class to construct a relational database with the AnnData layers determined by the user (X, obs, var, var_names, obsm, varm, obsp, and uns). X is created as a table where each gene is a column cast as a FLOAT with the addition of a “cell_id” column to contain the cell barcode. The obs table structure is composed of columns for the “cell_id” and each obs property. The var table contains the vertical layer associated with the AnnData object where the auto incremented id represents the gene and each column represents var layer properties. Each obsm, varm, and obsp layer property is composed of a different data type or structure. To convert layers to SQL tables, we created a new table for each layer property. For example, the “X_pca” property of the obsm layer is translated into the table, “obsm_X_pca” containing the cell by PC matrix. Lastly, the uns AnnData layer is serialized and inserted into the “uns_raw” table. This table contains the property name defined by the key column, a serialized data value column, and the original “data_type” column, such that the data can be reconstructed. Lastly, a convenience view “adata” is created by joining the obs and X table. Developers can optionally bypass the view creation by using the “convenience_view” boolean parameter. Lastly, special characters in gene names or other table columns are stripped of non-sql safe characters and replaced with underscores.
2.3 Database query wrapper
The AnnSQL class contains several methods for updates, deletes, and queries. The class requires either a path to a previously built AnnSQL database or an AnnData object to load into memory. After instantiation, the query method interfaces with the database to return a pandas dataframe (default), AnnData, or Parquet file. The query_raw method opens a db connection and executes a SQL statement. Additionally, the methods show_settings and show_tables exist for convenience.
2.4 Extended functionality
AnnSQL contains functionality for basic preprocessing as methods within the AnnSQL class, which include the following: Total counts per library, counts per gene, data normalization, log transformations, gene expression variance calculation, PCA, UMAP, Leiden clustering, and differential expression, along with a variety of helper methods and plotting utilities; all documented at https://docs.annsql.com. To accomplish data total counts per library, calculate_total_counts iterates cells in chunks and adds the “total_counts” column to the X and then obs table. Calculating total gene counts is accomplished in the calculate_gene_counts method by adding a “total_gene_counts” column to the var table and using the internal SUM function. The expression_normalize method updates the X table in chunks by dividing gene counts by “total_counts” and then multiplying by the normalized value (default: 10 000). The expression_log method updates all values in the X table with the user-defined ln, log2, or log10 parameter options. Lastly, calculate_variable_genes uses the population variance function in DuckDb to calculate gene-specific expression and stores the result in the “variance” column of the var table. In chunk parameters, gene sample variance is calculated including Bessel’s bias correction. The calculate_pca method determines principal components (PCs) for the data stored in the specified table. This method uses the top variable genes to perform PCA. The PCA calculation is performed as a hybrid of SQL and Python to create a covariance matrix and compute eigenvalues and eigenvectors, which are used to determine PCs for each cell. The results are stored in the PC_scores table and can be queried. After reducing the data size using PCA, we opted to implement UMAP and Leiden clustering methods as wrapper methods to existing “umap-learn” and “scikit-network” pip packages, respectively. The results of these operations are stored in the umap_embeddings table and as the “obs.leiden_clusters” field. Detailed descriptions of additional functionality can be found at https://docs.annsql.com.
2.5 Runtime analysis
Runtime tests were performed on simulated and Mouse Brain Atlas data (Langlieb et al. 2023). Simulated AnnData objects contained random expression values and saved as h5ad files ranging from 1000 to 250 000 cells. Each file contained 10 000 genes and an obs layer with random cell type assignments. File queries and filters were compared (Supplementary Fig. S1A) and generated the runtime results (Fig. 1D). Additionally, a second set of in silico datasets were generated using Splatter, a sc/nRNA-seq simulator, with the same shapes as the randomly generated data. We applied the same analysis to these datasets and presented our findings in Supplementary Fig. S2A.
The Mouse Brain dataset was converted into an on-disk AnnSQL database using the MakeDb class and then queried and processed as described in Table 1. Filters are as follows:
AnnData
adata[adata[:,“ENSMUSG00000070880”].X > 0, “ENSMUSG00000070880”]
AnnSQL
asql.query(“SELECT ENSMUSG00000070880 FROM X
WHERE ENSMUSG00000070880 > 0”)
Runtime analyses were performed on an Ubuntu 24.04 laptop, containing 40 Gb memory, 1Tb SSD Drive, and a 12th Gen Intel^®^ Core™ i7-1255U × 12 CPU or a HPC single node containing 46 CPUS (Intel^®^ Xeon^®^ Gold 6542Y), 512 Gb memory and high-performance storage. Runtime scripts are in the “examples/analyses” repository.
3 Results
3.1 Package capabilities
The AnnSQL package enables SQL-based queries on AnnData objects, returning results as either an AnnData object, Pandas dataframe (McKinney 2010), or Parquet file (Vohra 2016), thus seamlessly supporting a variety of downstream analysis tools or pipelines. Functionally, AnnSQL captures the AnnData hierarchical H5 data structure and represents the data in a relational database using the in-process DuckDb engine (Fig. 1A). AnnSQL supports in-memory and on-disk database representations, useful for smaller or larger datasets, respectively. AnnSQL databases are built using the MakeDb class that supports AnnData inputs from both backed and non-backed modes. Once a database has been created and instantiated using the AnnSQL class (Fig. 1B and C), the AnnSQL package provides methods for querying, updating, and deleting cell or genome-feature data, as well as extended functionality to perform common single-cell manipulations or analyses, such as normalization, log transforms, determining library or gene counts, calculating feature variance, principal component analysis (PCA), and differential expression.
3.2 Runtime estimates
To systematically compare runtime differences across AnnData filters and AnnSQL queries, we generated six increasing complex queries of synthetic scRNA-seq data and stratified our analysis by in-memory or on-disk modes for each method (Fig. 1D and Supplementary Fig. S1A) (Section 2). In-memory comparison trials ranged from 1000 to 100 000 cells before reaching system memory limits, while on-disk trials ranged from 1000 to 250 000 cells. Each dataset contains a fully dense matrix (Section 2). Critically, AnnSQL runtimes were essentially unchanged across the full-range library sizes tested for both in-memory and on-disk. On-disk AnnData outperformed on-disk AnnSQL only for libraries <5000 cells, while queries of 250 000 cells were on average ∼400 times faster using AnnSQL (0.14 versus 57 seconds). In-memory AnnData outperformed in-memory AnnSQL only for libraries with <45 000 cells and both methods achieved <0.01 second runtimes with <75 000 cell libraries. Additionally, we repeated the same experiment using in silico datasets generated by the Splatter (Zappia et al. 2017) sc/nRNA-seq simulation tool. Runtimes of all comparisons decreased as each of these datasets contain sparser UMI counts (Supplementary Fig. S2A). These comparative runtime metrics illustrate the drastic speed improvements and size scalability of AnnSQL processing of large scRNA-seq datasets.
3.3 Querying and processing 4.4 million cells on a laptop
To illustrate AnnSQL runtime improvements, we analyzed a single-nucleus RNA-seq atlas of the mouse containing 4.4 million cells and annotations (Langlieb et al. 2023). First, we opened the atlas AnnData object in backed mode and created an on-disk AnnSQL database using the MakeDb class (Section 2). Next, we performed routine procedures (cell filtering, summing library feature counts, cell-count normalization, and cell-count log transformation) using either the original AnnData object (in-memory or on-disk/backed mode) or on-disk AnnSQL (using methods provided in our package) on both a laptop and a High-Performance Cluster (HPC) (Table 1 and Section 2). Building a Seurat object based on the atlas dataset failed due to memory errors, and for all procedures other than filtering, AnnData analysis failed on both the laptop or HPC due to a lack of support for backed-mode or memory errors. Equivalent procedures using AnnSQL completed between ∼4.28 and 67 min on a laptop and were up to 3× faster than on the HPC. While backed-mode (but not in-memory) filtering could be accomplished on a laptop using AnnData, this procedure was ∼746× faster using AnnSQL. The HPC did enable filtering using in-memory AnnData, but was still ∼42× faster on a laptop with AnnSQL. These data illustrate how AnnSQL performance enhancements allow users to access and manipulate atlas-scale scRNA-seq data from their personal computer with ease.
4 Discussion
Here, we introduce AnnSQL for analysis of single-cell genomics data using SQL syntax and showcase query and preprocessing performance using large datasets with minimal computational resources. AnnSQL uses the in-process DuckDb engine and provides extended functionality to showcase how vectorized queries of the column-based storage engine benefit single-cell genomics applications. In future releases, extended functionality methods can be further improved by utilizing DuckDb user-defined functions. Additionally, the DuckDb client API supports programming languages popular in genomics research and development (including Java, R, C++, Julia, and cmd libraries).
AnnSQL runtime comparisons highlight impressive performance improvements achieved that help democratize access to large-scale single-cell RNA-seq data, enabling laptop-based analysis of millions of cells datasets. The ease and clarity of SQL syntax, along with Python-based wrapper functions, further lowers the analysis barriers. We do note that for small-scale datasets (<45 000 cells), AnnData slightly outperforms AnnSQL operations, but minor differences in runtime (< 0.1 seconds) might be tolerated if users prefer SQL-based data access.
In developing AnnSQL, we intentionally mirrored the AnnData layered structure for interpretability. While an ideal H5-based structure, AnnData is a nonoptimal structure for a relational database (Codd 1970). Future work converting AnnData objects into an optimized normal formed database may further decrease runtimes (Kent 1983).
While the use of SQL for single-cell genomics data storage and analysis has yet to be extensively explored, our results indicate that SQL-based databases may be increasingly valuable as datasets continue to grow. We suspect this lack of attention was due to either the technical knowledge necessary for database configuration or the resources necessary to process a cell by genomic feature matrix in a typical implementation [such as SQLite or MySql (Oracle Corporation 2025)]. Our AnnSQL results suggest column-based SQL approaches for filtering or processing single-cell data should be considered when (i) fluid SQL syntax is preferred; (ii) dataset size exceeds system memory; or (iii) when minimal computational resources are desired for exploring large datasets without down sampling.
Supplementary Material
vbaf105_Supplementary_Data
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Butler A , Hoffman P, Smibert P et al Integrating single-cell transcriptomic data across different conditions, technologies, and species. Nat Biotechnol 2018;36:411–20. 10.1038/nbt.409629608179 PMC 6700744 · doi ↗ · pubmed ↗
- 2Codd EF. A relational model of data for large shared data banks. Commun ACM 1970;13:377–87. 10.1145/362384.3626859617087 · doi ↗ · pubmed ↗
- 3Gaffney KP , Prammer M, Brasfield L et al SQ Lite: past, present, and future. Proc VLDB Endow 2022;15:3535–47. 10.14778/3554821.3554842 · doi ↗
- 4Heumos L , Schaar AC, Lance C, Single-cell Best Practices Consortium et al Best practices for single-cell analysis across modalities. Nat Rev Genet 2023;24:550–72. 10.1038/s 41576-023-00586-w 37002403 PMC 10066026 · doi ↗ · pubmed ↗
- 5Kent W. A simple guide to five normal forms in relational database theory. Commun ACM 1983;26:120–5. 10.1145/358024.358054 · doi ↗
- 6Kioroglou D. Omilayers: a Python package for efficient data management to support multi-omic analysis. BMC Bioinformatics 2025;26:40. 10.1186/s 12859-025-06067-739915756 PMC 11800426 · doi ↗ · pubmed ↗
- 7Langlieb J , Sachdev NS, Balderrama KS et al The molecular cytoarchitecture of the adult mouse brain. Nature 2023;624:333–42. 10.1038/s 41586-023-06818-738092915 PMC 10719111 · doi ↗ · pubmed ↗
- 8Mc Kinney W. Data structures for statistical computing in Python. In: van der Walt S, Millman J (eds), Proceedings of the 9th Python in Science Conference, Sci Py 2010, Austin, Texas, June 28–July 3, (pp. 56–61). 2010. 10.25080/Majora-92bf 1922-00a · doi ↗