Bayesian Estimation of Hierarchical Linear Models From Incomplete Data: Cluster‐Level Interaction Effects and Small Sample Sizes
Dongho Shin, Yongyun Shin, Nao Hagiwara

TL;DR
This paper introduces a new Bayesian method for estimating hierarchical models with missing data and small samples, improving accuracy in patient-physician encounter studies.
Contribution
A compatible Gibbs sampler is introduced to directly impute missing values from exact posterior distributions in hierarchical models.
Findings
Existing Gibbs samplers may lead to biased hierarchical model estimates due to incompatible imputation methods.
The proposed compatible Gibbs sampler ensures unbiased estimation by directly sampling from exact posterior distributions.
The new method is validated through simulation and applied to longitudinal patient-physician encounter data.
Abstract
We consider Bayesian estimation of a hierarchical linear model (HLM) from partially observed data, assumed to be missing at random, and small sample sizes. A vector of continuous covariates C includes cluster‐level partially observed covariates with interaction effects. Due to small sample sizes from 37 patient–physician encounters repeatedly measured at four time points, maximum‐likelihood estimation is suboptimal. Existing Gibbs samplers impute missing values of C by a Metropolis algorithm using proposal densities that have constant variances while the target posterior distributions have nonconstant variances. Therefore, these samplers may not ensure compatibility with the HLM and, as a result, may not guarantee unbiased estimation of the HLM. We introduce a compatible Gibbs sampler that imputes parameters and missing values directly from the exact posterior distributions. We apply…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
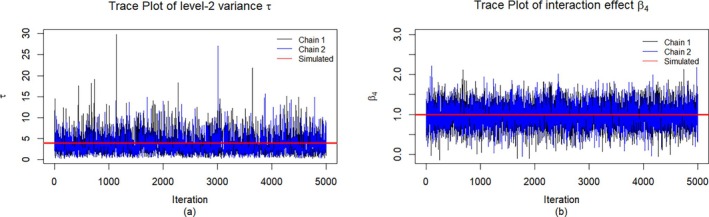 FIGURE 1
FIGURE 1| Simulated | CDML | GSExact | Blimp | ||||||
|---|---|---|---|---|---|---|---|---|---|
| %Bias (ASE) | ESE | Coverage | %Bias (ASE) | ESE | Coverage | %Bias (ASE) | ESE | Coverage | |
| 0.6 (0.84) | 0.85 | 0.95 | −2.5 (1.07) | 1.05 | 0.95 | 4.9 (1.13) | 1.07 | 0.95 | |
| 0.1 (0.92) | 0.88 | 0.95 | 0.8 (1.08) | 1.03 | 0.96 | 0.5 (1.08) | 1.02 | 0.96 | |
| −1.7 (0.58) | 0.58 | 0.95 | 0.2 (0.66) | 0.65 | 0.95 | 0.1 (0.67) | 0.65 | 0.95 | |
| −0.6 (0.26) | 0.26 | 0.95 | 0.0 (0.32) | 0.32 | 0.94 | −0.3 (0.32) | 0.32 | 0.96 | |
| 1.0 (0.33) | 0.34 | 0.94 | −0.3 (0.39) | 0.41 | 0.94 | −0.7 (0.40) | 0.41 | 0.94 | |
| 0.5 (0.37) | 0.38 | 0.94 | 0.5 (0.45) | 0.46 | 0.94 | 1.6 (0.46) | 0.46 | 0.94 | |
| −0.5 (0.11) | 0.11 | 0.95 | −0.1 (0.13) | 0.13 | 0.94 | −0.3 (0.14) | 0.14 | 0.95 | |
| Simulated | CDML | GSExact | Blimp | ||||||
|---|---|---|---|---|---|---|---|---|---|
| %Bias (ASE) | ESE | Coverage | %Bias (ASE) | ESE | Coverage | %Bias (ASE) | ESE | Coverage | |
| −0.2 (2.10) | 2.07 | 0.96 | −1.9 (2.54) | 2.00 | 0.95 | 25.9 (3.57) | 2.60 | 0.97 | |
| 0.2 (2.18) | 2.20 | 0.95 | 1.9 (2.57) | 2.49 | 0.94 | 2.5 (2.66) | 2.51 | 0.95 | |
| −3.5 (1.51) | 1.55 | 0.95 | 6.3 (1.89) | 1.84 | 0.97 | 4.1 (2.16) | 1.90 | 0.97 | |
| −0.8 (0.69) | 0.69 | 0.94 | −0.9 (0.90) | 0.88 | 0.97 | −4.7 (1.02) | 0.90 | 0.96 | |
| −0.3 (0.86) | 0.87 | 0.95 | −0.9 (1.13) | 1.13 | 0.96 | −5.9 (1.26) | 1.11 | 0.97 | |
| −1.1 (0.94) | 0.94 | 0.94 | −3.8 (1.19) | 1.20 | 0.97 | 8.9 (1.31) | 1.19 | 0.96 | |
| 0.3 (0.30) | 0.31 | 0.94 | 1.3 (0.40) | 0.39 | 0.96 | 0.3 (0.44) | 0.39 | 0.97 | |
| Simulated | CDML | GSExact | Blimp | ||||||
|---|---|---|---|---|---|---|---|---|---|
| %Bias (ASE) | ESE | Coverage | %Bias (ASE) | ESE | Coverage | %Bias (ASE) | ESE | Coverage | |
| = 4 | 0.0 (0.84) | 0.87 | 0.94 | −3.2 (1.08) | 1.13 | 0.93 | 4.4 (1.15) | 1.17 | 0.93 |
| = 16 | −0.2 (0.92) | 0.92 | 0.95 | 0.5 (1.08) | 1.08 | 0.95 | 0.2 (1.08) | 1.07 | 0.96 |
| = 1 | 1.7 (0.99) | 1.03 | 0.94 | 8.1 (1.17) | 1.22 | 0.93 | 10.7 (1.19) | 1.22 | 0.94 |
| = 1 | −0.8 (0.45) | 0.48 | 0.93 | −5.6 (0.54) | 0.58 | 0.92 | −6.5 (0.55) | 0.58 | 0.93 |
| = 1 | 0.0 (0.42) | 0.44 | 0.93 | −3.2 (0.51) | 0.53 | 0.94 | −3.9 (0.52) | 0.53 | 0.94 |
| = 1 | −0.3 (0.21) | 0.21 | 0.96 | −0.2 (0.25) | 0.25 | 0.96 | 0.3 (0.26) | 0.25 | 0.96 |
| = 1 | 0.3 (0.18) | 0.20 | 0.94 | 2.5 (0.22) | 0.24 | 0.92 | 2.5 (0.23) | 0.24 | 0.93 |
| Simulated | CDML | GSExact | Blimp | ||||||
|---|---|---|---|---|---|---|---|---|---|
| %Bias (ASE) | ESE | Coverage | %Bias (ASE) | ESE | Coverage | %Bias (ASE) | ESE | Coverage | |
| = 4 | 0.0 (2.10) | 2.06 | 0.96 | 1.2 (2.65) | 2.10 | 0.97 | 35.7 (3.88) | 2.89 | 0.96 |
| = 16 | −0.2 (2.17) | 2.15 | 0.95 | 1.5 (2.56) | 2.47 | 0.95 | 2.0 (2.66) | 2.48 | 0.95 |
| = 1 | −5.3 (2.67) | 2.78 | 0.94 | 10.6 (3.62) | 3.77 | 0.94 | 23.9 (3.98) | 3.70 | 0.96 |
| = 1 | 3.8 (1.27) | 1.33 | 0.94 | −9.0 (1.75) | 1.84 | 0.93 | −11.9 (1.93) | 1.81 | 0.96 |
| = 1 | 2.3 (1.17) | 1.23 | 0.94 | −8.1 (1.62) | 1.69 | 0.93 | −10.9 (1.78) | 1.66 | 0.95 |
| = 1 | −0.4 (0.54) | 0.55 | 0.95 | 1.0 (0.70) | 0.71 | 0.94 | 3.6 (0.77) | 0.71 | 0.97 |
| = 1 | −1.4 (0.54) | 0.57 | 0.94 | 5.0 (0.76) | 0.81 | 0.93 | 4.3 (0.83) | 0.80 | 0.95 |
| Simulated | CDML | GSExact | Blimp | ||||||
|---|---|---|---|---|---|---|---|---|---|
| %Bias (ASE) | ESE | Coverage | %Bias (ASE) | ESE | Coverage | %Bias (ASE) | ESE | Coverage | |
| = 4 | 1.0 (2.98) | 2.12 | 0.95 | 4.7 (2.73) | 2.21 | 0.97 | 39.4 (4.01) | 3.0 | 0.95 |
| = 16 | −0.2 (2.96) | 2.17 | 0.96 | 1.6 (2.63) | 2.49 | 0.95 | 2.1 (2.71) | 2.50 | 0.95 |
| = 1 | 0.1 (1.51) | 1.58 | 0.93 | 5.1 (1.91) | 1.90 | 0.95 | −5.4 (2.12) | 1.89 | 0.97 |
| = 1 | −0.9 (0.68) | 0.72 | 0.94 | −4.3 (1.00) | 1.01 | 0.94 | −1.4 (1.11) | 1.00 | 0.96 |
| = 1 | 1.1 (0.87) | 0.91 | 0.94 | 2.4 (1.13) | 1.16 | 0.94 | 5.5 (1.25) | 1.14 | 0.96 |
| = 1 | 0.7 (0.94) | 0.96 | 0.94 | 2.6 (1.20) | 1.21 | 0.94 | 10.1 (1.34) | 1.20 | 0.96 |
| = 1 | −0.2 (0.30) | 0.31 | 0.95 | 4.0 (0.47) | 0.47 | 0.94 | −0.5 (0.52) | 0.46 | 0.97‘ |
| Simulated | CDML | GSExact | Blimp | ||||||
|---|---|---|---|---|---|---|---|---|---|
| %Bias (ASE) | ESE | Coverage | %Bias (ASE) | ESE | Coverage | %Bias (ASE) | ESE | Coverage | |
| = 4 | −0.3 (2.17) | 2.17 | 0.96 | −0.2 (2.73) | 2.21 | 0.97 | 37.2 (4.01) | 3.0 | 0.95 |
| = 16 | 0.1 (2.18) | 2.17 | 0.95 | 1.6 (2.63) | 2.49 | 0.95 | 2.3 (2.71) | 2.50 | 0.95 |
| = 1 | −1.5 (2.07) | 2.21 | 0.94 | −1.9 (1.91) | 1.90 | 0.95 | 7.5 (2.12) | 1.89 | 0.97 |
| = 1 | 1.6 (1.06) | 1.10 | 0.94 | 2.2 (1.00) | 1.01 | 0.94 | −8.4 (1.11) | 1.00 | 0.96 |
| = 1 | −0.3 (1.23) | 1.30 | 0.94 | −3.6 (1.13) | 1.16 | 0.94 | −5.8 (1.25) | 1.14 | 0.96 |
| = 1 | −0.3 (1.71) | 1.79 | 0.94 | −0.3 (1.20) | 1.21 | 0.94 | 5.3 (1.34) | 1.20 | 0.96 |
| = 1 | 0.4 (0.48) | 0.52 | 0.94 | 2.4 (0.47) | 0.47 | 0.94 | 1.1 (0.52) | 0.46 | 0.97 |
| = 1 | −0.6 (0.57) | 0.62 | 0.94 | −2.3 (0.47) | 0.47 | 0.94 | 1.3 (0.52) | 0.46 | 0.97 |
| = 1 | 0.2 (0.42) | 0.45 | 0.94 | 1.3 (0.47) | 0.47 | 0.94 | 0.3 (0.52) | 0.46 | 0.97 |
| Parameters | Covariates | Estimates (se+) | CI++ (2.5th %ile, 97.5th %ile) |
|---|---|---|---|
| Intercept | 84.46(2.42)* | (79.71, 107.21) | |
| IPrej | −0.35(5.62) | (−11.29, 10.72) | |
| EPrej | −21.83(11.22)* | (−44.61, −1.49) | |
| CT | −0.65(1.81) | (−3.99, 3.24) | |
| IPrej EPrej | −78.24(52.36) | (−188.84, 14.82) | |
| Q2 | −9.58(2.65)* | (−14.99, −4.62) | |
| Q3 | −4.25(2.59) | (−9.30, 0.68) | |
| Q4 | −2.14(2.47) | (−7.10, 2.66) | |
| — | 4.57(5.07) | (0.57, 19.59) | |
| — | 80.89(12.48) | (59.33, 107.21) |
- —National Institute of Diabetes and Digestive and Kidney Diseases 10.13039/100000062
- —National Cancer Institute
- —National Institute of Nursing Research 10.13039/100000056
- —Institute of Education Sciences 10.13039/100005246
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Bayesian Inference · Statistical Methods and Inference · Bayesian Methods and Mixture Models
Introduction
1
Medical researchers frequently confront four challenges of interest in this paper. First, patients are repeatedly measured or nested within clusters, such as physicians, clinics and neighborhoods. A hierarchical linear model (HLM) is appropriate to analyze such data [1, 2]. Second, missing data commonly occur at the cluster level, posing a challenge to efficient and unbiased estimation of the HLM. Third, partially observed covariates may have nonlinear effects at the cluster level to make the estimation even more challenging. In particular, when two interactive cluster‐level covariates are partially observed, complete‐case analysis drops the clusters and all their nested units having either of the covariates missing. The resulting inference is inefficient and may be substantially biased [3]. Finally, small sample sizes constrain estimability of the HLM.
Hierarchical missing data are routinely handled by multiple imputation (MI) [4] under the assumption of data missing at random (MAR) [5]. A popular joint modeling approach conceives of the response and partially observed covariates as the outcomes in a multivariate HLM, estimates their joint distribution, and imputes missing values from the estimated distribution [6, 7]. Missing data may also be imputed from their conditional distributions by chained regressions, which is also known as fully conditional specification (FCS) [8, 9, 10, 11]. FCS fits each partially observed variable conditional on all other variables and imputes missing values from the fitted model. FCS is a Gibbs sampler if the chained regressions are compatible with an underlying joint distribution of all variables MAR, including the outcome [12, 13, 14, 15]. These approaches have been shown to work well when the joint distribution of partially observed variables are reasonably multivariate normal (MN) [14, 15, 16].
Given the nonlinear effects of covariates C on a response Y in a HLM, however, multivariate normality of (Y,C) is not possible even if the factorized conditional distributions are normal [17, 18]. A concern then involves the bias that can arise from the incompatibility or conflicting assumptions between the fully conditional distributions that generate the imputations and the assumed joint distribution of the observed data [14, 15, 17, 19, 20, 21]. Kim et al. [17, 22] developed a Gibbs sampler to impute missing values of a partially observed continuous covariate interactive with a known covariate in a single‐level regression model from the exact conditional distribution. Carpenter and Kenward [19] took a MN approach to handling continuous and categorical data MAR by joint normality of continuous variables and latent continuous variables underlying categorical ones. Goldstein et al. [23] imputed missing values of covariates having nonlinear effects on a continuous or binary outcome by the MN approach via the Gibbs sampler and Metropolis algorithm [24, 25]. Enders et al. [21] extended the MN‐Metropolis Gibbs sampler to handling categorical and continuous predictors MAR having nonlinear effects in two‐ and three‐level hierarchical models, and illustrated how FCS using its software MICE [10] may lead to an imputation model incompatible with the HLM to produce biased estimates.
Shin and Raudenbush [18] extended the joint modeling approach to estimation of a HLM with the nonlinearities from continuous data (Y,C) MAR. The HLM implied a compatible nonstandard joint distribution h(Y,C) such that the likelihood function L(θ) of the joint parameters θ is an integral with respect to high‐dimensional random effects (u,ν) given the observed data (Yobs,Cobs). They selected “provisionally known random effects (PKREs)” u such that h(Yobs,Cobs|u)=∫h(Yobs,Cobs,ν|u)dν is analytically tractable with respect to high dimensional ν and, then, L(θ)=∫h(Yobs,Cobs|u)g(u)du is approximated numerically with respect to low dimensional u by adaptive Gauss‐Hermite quadrature (AGHQ). They maximized the likelihood by the EM algorithm to produce the estimates θ^ at ML, and translated the θ^ to the ML estimates of the HLM. They illustrated efficient ML estimation of random and fixed interaction effects involving lower‐level covariates and their latent cluster means. Given the estimates θ^ and associated var(θ^) at ML, Shin and Raudenbush [26] generated MI of missing data, including random effects, from a nonstandard predictive model h(Y,C,ν,u|Yobs,Cobs,θ) by importance sampling via AGHQ, and estimated the HLM given the MI. These approaches within the maximum‐likelihood framework, however, are suboptimal given small sample sizes.
We now explain our contribution to the literature. Unlike existing samplers that sample missing values of a cluster‐level covariate having a nonlinear effect by a metropolis algorithm via a proposal normal density with a constant variance [21, 23], our Gibbs sampler samples missing data and parameters from their exact posterior distributions, which are derived via selected PKREs. Therefore, our Gibbs sampler is guaranteed to be compatible and, thus, to produce unbiased estimation of an analytic HLM with nonlinear effects of cluster‐level covariates. Either one or both of the interactive covariates may be partially observed and partially observed covariates are continuous. The results of the simulation study below reveal that our Gibbs sampler is particularly effective with comparatively small sample sizes.
Our motivating application is the analysis of racially discordant patient–physician medical interactions, focusing on pairs of patients and physicians from different racial groups during office visits. These visits were videotaped and coded to produce four repeated measurements of the outcome: a positive valence score measuring the physician's facial expression. Of interest are the main and interaction effects of continuous physician's implicit and explicit prejudices on the outcome that may be appropriately analyzed using a HLM. Three challenges motivated us to develop our Gibbs sampler. First, valence score is missing 20% of the values, and each of the two key physician covariates has 16% missing data at the cluster level. Next, the effects of partially observed physician prejudices include an interaction effect. Finally, due to the COVID restrictions, only 37 encounters were recorded from the small number of 6 physicians and 37 patients, posing a formidable challenge to the efficient and unbiased estimation of the HLM.
The rest of the paper is organized as follows. Section 2 introduces our general HLM with the nonlinear effects of cluster‐level covariates. Section 3 presents our Gibbs sampler. Section 4 evaluates our sampler by comparing our estimators with those by existing methods in simulated analyses. Section 5 illustrates analysis of real data from the racially discordant patient–physician encounters using our Gibbs sampler. Lastly, section 6 discusses limitations and future extensions of our approach.
Model
2
Our interest focuses on a two‐level HLM
where Yij is the outcome variable, Cj=[C1j…Cpj]T is a p‐by‐1 vector of partially observed cluster‐level continuous covariates having main effects βC, and Xij=[x1ijTx2jT] is a q‐by‐1 vector of fully observed covariates having main effects βX=[βx1Tβx2T]T for lower‐level or level‐1 covariates x1ij and cluster‐level or level‐2 covariates x2j. In addition, βXCs is the q‐by‐1 interaction effects of Xij and Csj, whereas βCCst represents the scalar interaction effect of Csj and Ctj for s≤t. Lastly, a level‐2 unit‐specific random effect uj∼N(0,τ) and a level‐1 unit specific random effect eij∼N(0,σ2) are independent, and a level‐1 unit i is nested within a level‐2 cluster j for i=1,…,nj and j=1,…,J. Here, the covariates Cj and the outcome Yij may be partially observed.
Compatible Gibbs Sampler
3
This section explains our Gibbs sampler based on the exact posteriors of parameters and missing data, unlike existing Bayesian approaches using rejection sampling of missing data by the Metropolis algorithm [21, 23]. To handle missing data efficiently, we assume the joint normal distribution of Cj conditional on known covariates to write our Bayesian joint distribution of Y=(Y11,Y12,…,YnJJ),C=(C1,C2,…,CJ) and θ given X=(X11,X12,…,XnJJ)
where p(θ) is the prior distribution of θ=(β,τ,σ2,α,T), as specified in the Gibbs sampler steps below, with β=(β0,βC,βX,βXC,βCC) for βXC=(βXC1,βXC2,…,βXCp) and βCC=(βCC12,…,βCC1p,βCC23…,βCC2p,…,βCC(p−1)p). Here f(Yij|Cj,Xij,uj,β,σ2) and f(uj|τ) are normal densities from the HLM (1), and
for a vector α of fixed effects, a p×p identity matrix Ip, a kronecker product A⊗B multiplying matrix B to each element of matrix A, and a p×p variance‐covariance matrix T. To derive the Gibbs sampler, we partition complete data Y=(Yobs,Ymis) and C=(Cobs,Cmis) into observed (Yobs,Cobs) and missing (Ymis,Cmis).
Exact Posterior Distributions of Cmis
3.1
Let p(A|·) denote the posterior, or exact posterior, distribution of A given all other unknowns. To find the key posterior distribution p(Ckj|·) for a missing element Ckj of Cj, we first derive a bivariate normal conditional distribution from Equations (1) and (3)
for C(−k)j=(C1j,…,C(k−1)j,C(k+1)j,…,Cpj), Mk|(−k)=E(Ckj|C(−k)j) and Tk|(−k)=var(Ckj|C(−k)j). Shin and Raudenbush [18] referred to missing values of C(−k)j as provisionally known random effects. The conditional mean E(Yij|C(−k)j,Xij,uj) has two parts, μ1ij excluding and μ2ij including Ckj, to facilitate derivation of p(Ckj|·):
for an indicator function I(B)=1 if condition B is true and 0 otherwise, βC partitioned into the coefficients βCk of Ckj and βC(−k) of C(−k)j, and ∑s≠k,s≥apAs=∑s=ak−1As+∑s=k+1pAs.
The joint distribution (2) then implies
where M˜kj=Mk|(−k)+Δkj−1σ−2μ2ij∑i=1njYij−(μ1ij+μ2ijMk|(−k)) and Δkj=Tk|(−k)−1+njμ2ij2σ−2.
Gibbs Sampler Steps Based on Exact Posterior Distributions
3.2
The joint distribution (2) implies the posterior distributions of u=(u1,…,uJ) and θ:
where we assume inverse gamma priors p(τ)∼IG(α0=1,β0=0.5) and p(σ2)∼IG(α0=1,β0=0.5), an inverse wishart p(T)∼IW(V0,S0−1) with V0=p+2 and S0=T^ (an estimated variance‐covariance matrix using complete cases), and noninformative priors p(β)=p(α)=1, following Schafer and Yucel [6], Hoff [27] and Enders et al. [21].
At cycle t, we update the current values of parameters θ=θ(t−1) and completed data Y=(Yobs,Ymis(t−1)) and C=(Cobs,Cmis(t−1)) from cycle t−1 in eight steps, as follows:
- Step 1:Sample uj(t) from
where XijT=1CjTXijTXijT⊗CjTvechTC(−1)jC(−p)jT, β=β0βCTβXTβXCTβCCTT and Δj=njσ−2+τ−1. Here, the operator vech(·):ℝr×r→ℝr(r+1)/2 stacks the upper triangular entries of an r×r square matrix into a column vector.
- Step 2:Draw τ(t) from
- Step 3:Draw β(t) from
- Step 4:Draw σ2(t) from
where N=∑j=1Jnj.
- Step 5:For Yij missing, impute eij(t) from p(eij|σ2=σ2(t))∼N(0,σ2) and set Yij(t)=XijTβ(t)+uj(t)+eij(t).
- Step 6:Draw α(t) from
- Step 7:Draw T(t) from
- Step 8:Repeat the following sub‐step as many times as the number of missing values in Cj. For each Ckj missing, define
that consists of (k−1) observed or imputed missing values at cycle t and (p−k) observed or imputed values at cycle t−1. We compose a bivariate distribution (4) given the imputed missing values or PKREs of C(−k)j(t):
to draw Ckj from the implied posterior distribution (5):
Simulation Study
4
We now assess our compatible Gibbs sampler based on exact posterior distributions (GSExact) using simulated data under four different scenarios: i) correctly specified distributions of the response, covariates and missing data mechanism; ii) misspecified distribution of a covariate; iii) violation of the MAR assumption; and iv) controlling for multiple partially observed interaction terms. The latter three cases evaluate GSExact in terms of robust estimation against a misspecified covariate distribution, a violated missing data mechanism, and additional partially observed nonlinear terms, respectively. The simulated data from HLM (1) will closely resemble real data that we analyze in the next section in terms of correlations, sample sizes and missing rates. In each case, we compare our estimators with those from: 1) the lme4 package in R [28] that estimates maximum‐likelihood estimates given complete data (CDML) and 2) software Blimp [29] that implements the Gibbs Sampler of Enders et al. [21]. We do not consider FCS, as it has been shown to be incompatible and produce biased estimates due to nonlinear effects of covariates MAR [14, 15, 16, 21]. However, we compare GSEsxact with imputations by predictive mean matching in terms of robust estimation in the Appendix. Because CDML estimators are estimated from complete data, whereas others are based on data MAR, a good method will produce estimates near CDML counterparts.
Correctly Specified Distributions of the Response, Covariates, and MAR Mechanism
4.1
We consider two cases where nj=4 units are nested within each of 1) J=36 clusters or a small sample and 2) J=200 clusters or a large sample. We validate the correct execution of the R code that implements GSExact given the large sample size and compare our estimators with the competing ones given the small and large sample sizes.
We simulate sequentially: i) Xj∼N(2,1); ii) C1j∼N(0.75+0.7Xj,1.25) and C2j∼N(−0.5+Xj,1) with T12=cov(C1j,C2j)=−0.5 in model (3); and iii) Yij∼N(1+C1j+C2j+Xj+C1jC2j,τ+σ2) for τ=4 and σ2=16 in HLM (1). The simulated coefficients of the HLM are all equal to 1 to facilitate the comparison.
Next, we simulate the missing values of Yij, C1j and C2j by a MAR mechanism that depends on the fully known Xj from Bernoulli(pj) where
We manipulate c0, c1 and δ to simulate 20% missing values for each of the following variables: Yij given c0=−1.9,c1=0.1 and δ=1, C1j given c0=0.8,c1=−1.5 and δ=0, and C2j given c0=−2.8,c1=0.5 and δ=0.
We repeated simulating data and estimating the simulated HLM 1,000 times to compute the % bias equal to (estimated‐simulated) * 100 / simulated, average estimated standard error (ASE), empirical estimate of the true standard error (ESE) over the samples and the coverage probability (coverage) of each estimator. Both Blimp and GSExact are based on 2,500 burn‐in and 2,500 post burn‐in iterations. Given each simulated data set, we run two separate Gibbs sampler chains given different initial values to evaluate the convergence by Geweke's method [30] and the potential scale reduction factor (PSRF) [31].
Table 1 summarizes the simulation results for the large sample size. Both GSExact and Blimp produce estimates close to those by CDML. All three approaches produce very accurate and precise estimates with biases < 2% except those of the τ estimates by GSExact (‐2.5%) and Blimp (4.9%), ASEs close to ESEs, and coverage probabilities near the nominal 0.95. The standard errors by GSExact and Blimp are comparatively inflated to reflect extra uncertainty from missing data.
Table 2 summarizes the results from the small sample simulation. Because the small sample size led to greater sampling variability compared with the large sample size, we ran 5,000 simulations to reduce this variability. The CDML estimates are consistently close to simulated values with bias < ‐3.5% in magnitude and small ASEs close to ESEs, achieving good coverages near the nominal 0.95. GSExact estimates are reasonably close to the CDML estimates with small biases < 2% in magnitude except two fixed effects. The estimator for the intercept β0 has a comparatively large bias of 6.3%, which is 2.8% larger in magnitude than the ‐3.5% bias of the CDML counterpart. Additionally, the effect of the known covariate Xj, on which the missing pattern depends, showed a ‐3.8% bias in the estimation. ASEs are small near ESEs with good coverages.
Blimp produces comparatively large biases overall. In particular, the biases in the main effects (β1, β2 and β3) are noticeably larger than those of GSExact, but the estimated interaction effect β4 is very accurate. The ASEs are near ESEs, and overall modestly inflated compared with those of GSExact. As a result, the coverages are good near the nominal level. The level‐2 variance estimate of τ is biased upward by 25.9%, the largest bias observed, which is larger in magnitude than the GSExact counterpart bias of ‐1.9%. Additionally, the ASE of the τ estimate is 3.57, which is 41% higher than the GSexact counterpart of 2.54. Therefore, small sample estimates differ noticeably between GSExact based on exact posterior distributions and Blimp based on a metropolis algorithm in sampling missing values of C1j and C2j from normal proposal densities with constant variances. Overall, GSExact and Blimp ASEs are again larger than the CDML counterparts, which reflects extra uncertainty due to missing data.
Convergence. We assessed convergence to a stationary distribution by both Geweke's method [30] and PSRF [31]. Geweke's statistic tests if the two means of an estimator, typically from the first 20% and the last 50% of post burn‐in iterations, are equal within a single Markov chain by the two‐sample normal Z test. On the contrary, the PSRF compares the within‐chain and between‐chain variances from multiple Markov chains—two in our case—to evaluate convergence. A PSRF value < 1.1 indicates convergence [32, 33]. We assess the convergence of GSExact as all 7 estimators of the HLM satisfying each convergence criterion and compare the results from both criteria.
Our simulation revealed that for the large sample, only 64.5% out of the 1,000 simulations satisfied the Geweke's convergence criterion, whereas 99% met the PSRF criterion. Similarly, for the small sample, 66.7% satisfied the Geweke's criterion, whereas 99% met the PSRF criterion. The converged and nonconvergent estimates based on Geweke's criterion revealed virtually no differences in terms of % biases, ASEs, ESEs, and coverages.
The Geweke's statistics seem to inflate the Type I error probability in multiple comparisons of the seven convergences. The rejection rates are quite close to the overall Type I error probability under the unrealistic assumption of independent estimators 1−0.957=0.301, implying that it is easier to reject convergence by the Geweke's statistics under the null hypothesis of convergence. Furthermore, the Geweke's statistics rely on a single MCMC chain and, thus, is based on the within‐chain variance only. Consequently, given small sample sizes where ASEs are expected to be comparatively high, we particularly expect the nonconvergence rates by Geweke's criterion to be also high. Therefore, we used the PSRF criterion to assess the convergence in real analysis below.
Additionally, we assessed convergence using trace plots from two chains with different initial values. Chain 1 initializes the missing data by predictive mean matching, using the MICE R package, whereas chain 2 imputes them by sample means. Next, both chains fit the HLM (1) to initialize the parameters. Each trace plot tracks the sampled values of a parameter from its posterior on the vertical axis, with iteration 1 through 5,000 on the horizontal axis. Figure 1 shows the trace plots for the level‐2 variance τ and the interaction effect β4 from one of the simulated small samples. See the Appendix for additional trace plots. Each plot exhibits evidence of convergence to a stable distribution with rapid random fluctuations around a stable horizontal band, no trends, and extensive overlap between chains, indicating exploration of the same posterior distribution.
(a) Trace plot for the level‐2 variance, τ and (b) trace plot for the interaction effect, β4.
Although the trace plot for τ in Figure 1a oscillates randomly around its mean, it also exhibits some large spikes to reveal considerable uncertainly in the estimation of τ from the small number of 36 clusters and high missing rates. Additionally, these spikes reflect the fact that the posterior inverse gamma distribution of τ, which is right‐skewed and heavy tailed, is more likely to produce large sampled values compared with the symmetric normal posterior distributions of fixed effects.
A Misspecified Covariate Distribution
4.2
To investigate the robustness of our estimators against violations of the normality assumption for covariates, we simulate: 1) Xj∼N(2,1); 2) C1j∼logNormal(0.5+0.1Xj,0.2),C2j∼N(1+0.1C1j+0.3Xj,1) and 3) Yij∼N(1+C1j+C2j+Xj+C1jC2j,τ+σ2) for τ=4 and σ2=16. The parameters of the log‐normal distribution are set to generate C1 with a mean of around 2 and variance near 1, and a skewness of 1.6. Therefore, the bivariate normality assumption of covariates in both GSExact and Blimp is violated. We again simulate 1,000 large and 5,000 small data sets, using the same missing rates as before.
Table 3 summarizes the estimated HLM for the large‐sample case. Because the CDML estimation given complete data does not depend on the distributional assumption of C1j, the CDML biases and ASEs near ESEs are small with good coverages. Both GSExact and Blimp result in reasonably small biases up to 4.4% in magnitude, except for the 8.1% and 10.7% biases in the intercept and the −5.6% and −6.5% biases in the effect β1 of C1j, respectively. They also produce reasonably small and similar ASEs and ESEs, with similar coverages near the nominal level. Overall, both GSExact and Blimp produce estimates that are quite robust against the violated normality assumption in the large‐sample scenario.
Table 4 summarizes the simulation results for the small sample size. Almost all biases, ASEs and ESEs are larger than those of the large‐sample results in Table 3. The CDML biases are still reasonably small up to −5.3% in magnitude with small ASEs near ESEs and good coverages. GSExact estimates result in biases of 10.6%, −9.0%, and ‐8.1% for the intercept β0, the effect β1 of C1j, and the effect β2 of C2j, respectively. Other estimates are reasonably accurate with biases up to 5%. ASEs are modestly distant from, but reasonably close to ESEs, with coverages near the nominal level. Blimp estimates produce higher biases than their GSExact counterparts overall. The biases for the intercept, the effect of C1j, and the effects of C2j are 23.9%, −11.9%, and −10.9%, respectively, which are noticeably higher than the GSExact counterparts. The τ estimator is biased by 37% and is the least inaccurate. Other biases are below 4.3%. ASEs are generally higher than ESEs and their GSExact counterparts. The coverages are near the nominal level. Therefore, GSExact estimators appear more robust than their Blimp counterparts overall under our scenario involving the violated normality assumption of a covariate and a small sample size.
Violation of the MAR Assumption
4.3
To assess the robustness of our estimators against violations of the MAR assumption, we designed a simulation that incorporates both MAR and MNAR (missing not at random) mechanisms [5]. After simulating sample data as in Section 4.1, we simulate the missing values of C1j and C2j using a Bernoulli(pj) under a MNAR mechanism that depends on the values of C1j (before simulating missing values) where
To simulate missing values, we set d0=−5 and d1=1.3 for C1j, and d0=−10.5 and d1=3 for C2j. These parameters are chosen to produce approximately 20% missing values for each covariate. This approach allows us to simulate data under a MNAR mechanism, as the missing pattern of C1j and C2j depends on the missing values of C1j. We maintain the MAR mechanism (7) to simulate the missing values of Yij, as described in Section 4.1. We evaluate our estimators under this combination of the MAR and MNAR mechanisms by simulating small sample sizes.
Table 5 summarizes the resulting estimates. The CDML estimates remain unaffected by the violation, resulting in accurate and precise estimates. In contrast, the GSExact biases for the fixed effects range from 2.4% to 5.1% in magnitude, which are comparatively larger than the CDML counterparts. Additionally, bias for the random effect τ is 4.7%, approximately four times larger than that of the CDML counterpart. The ASEs for GSExact are a slightly higher or lower than those of CDML, and are reasonably close to the ESEs. Coverages are near the nominal 0.95.
The Blimp biases for the variance τ and the effect β3 of Xj are 39.4% and 10.1%, larger than their GSExact counterparts (4.7% and 2.6%). Other biases are modest, up to 5.5%, and moderately larger or smaller than the GSExact counterparts. ASEs are reasonably close to ESEs, but noticeably larger than the GSExact ASEs, with coverages near the nominal level.
Overall, GSExact demonstrated comparative robustness, with most biases up to 5.1% under the simulated MNAR scenario. The Blimp estimators of τ, the main effect β2 of C2j and the main effect β3 of Xj were less robust than the GSExact estimators, whereas the remaining Blimp estimators exhibited comparable robustness to their GSExact counterparts when the MAR assumption was violated in small sample sizes. These findings, however, are based on a single MNAR mechanism we simulated. Investigating robust estimation under different violations of the MAR assumption is an important avenue for future research, which is beyond the scope of this paper.
Controlling for More Covariates or Nonlinear Terms
4.4
We now evaluate the performance of our estimators while controlling for additional covariates. In particular, we simulate data as in Section 4.1 with the HLM (1): Yij∼N(1+C1j+C2j+Xj+C1jC2j+C1jXj+C2jXj,τ+σ2), where τ=4 and σ2=16. This model includes two additional interaction terms, C1jXj and C2jXj, which are partially observed. We then generate missing values in Yij, C1j, and C2j based on the MAR mechanism (7). Again, we simulate the partially observed data with small sample sizes 5,000 times.
Table 6 summarizes the estimates. The CDML estimates are accurate and precise as before, with modestly increased ASEs from those in Table 2 to reflect more parameters estimated. The GSExact estimators are biased by up to ‐3.6% in magnitude, maintaining the accuracy of those in Table 2 despite the addition of two partially observed nonlinear terms. ASEs and ESEs are slightly increased comparatively, reflecting increased uncertainty due to additional partially observed interaction terms in the HLM, and coverages are good near the nominal level.
The Blimp bias for τ is 37.2%, higher than the 25.9% bias in Table 2, whereas other biases change less noticeably. The Blimp biases are noticeably higher than those of the GSExact estimators, except for the biases for the interaction effects, which are lower than their GSExact counterparts. Blimp ASEs are also modestly inflated compared with the GSExact ASEs.
These differences in accuracy and precision of GSExact and Blimp estimators highlight the importance of GSExact implementing exact posteriors and, thus, ensuring compatibility. In contrast, Blimp implements a Gibbs sampler using a Metropolis algorithm, which has not been shown to ensure compatibility. Confer Shin and Raudenbush [26] for a practical implication of compatibility.
Analysis of Racially Discordant Patient–Physician Interactions
5
We analyze data from racially discordant medical encounters between patients and physicians by GSExact. Investigators video‐recorded physicians' behavioral and facial expressions during medical interactions with patients in office visits, and coded physicians' communication behaviors from the recordings. Each physician completed a baseline survey on demographics and other characteristics including implicit prejudice measured by the Implicit Association Test [34, 35] and explicit prejudice measured by a symbolic racism test 2000 [36]. Each encounter lasted about 20 minutes, and the video‐taped physician's facial expression of each encounter was rated by a machine as a valence score at each of four consecutive time points. Due to the COVID‐19 restrictions, the investigators were able to recruit only 37 patients and 6 physicians, much less than planned.
Of interest are the main and interaction effects of two physician characteristics, implicit prejudice(IPre) and explicit prejudice(EPre), on their communication behavior or a positive valence score (Valence) that measures the intensity of positive facial expression during the medical encounter. These variables are partially observed. We also analyze a fully known physician's Communication Training(CT) covariate as the time elapsed since the last training on communication skills. Because a positive valence score is expected to be higher at the beginning and end (e.g., when greeting) than mid time points of the encounter (e.g., when talking about health issues), we also control for dummy variables indicating the second to fourth measurement time points of the outcome Q2, Q3, and Q4 with the first time point as a reference. To improve the interpretability of the intercept and reduce potential collinearity between the covariates and the interaction term, we center the covariates at their sample means and write the model
where occasion i is nested within the jth patient–physician encounter for i=1,…,4 and j=1,…,37. Here β0 is the expected positive valence score of encounters for physicians having average implicit prejudice (IPre), average explicit prejudice (EPre) and average level of communication training (CT) at occasion 1 (Q2=Q3=Q4=0). The fixed effects include the main effects β1, β2 and β3 of IPre, EPre and CT, respectively; the interaction effect β4 of IPre and EPre; and the mean differences β5, β6, and β7 from the mean positive valence of occasion one at occasions 2‐4, respectively, ceteris paribus. An encounter‐specific random effect uj∼N(0,τ) and an occasion‐specific random effect eij∼N(0,σ2) are independent. The valence score is missing 20% of the values, and one physician failed to report both Ipre and Epre such that 16% of their values are missing, respectively.
Table 7 shows the estimated HLM by GSexact. Each estimate and its associated standard error in parentheses are listed in column three followed by a 95% Bayesian credible interval in the last column. At a significance level 0.05, explicit prejudice is negatively associated with positive valence score (β2 = −21.83, standard error(se)=11.22), and the mean outcome at occasion two is 9.58 (se=2.65) units less than that at occasion one, controlling for other covariates in the model. Neither large antagonistic interaction effect −78.24 (52.36) of implicit prejudice and explicit prejudice nor the effect −0.35 (5.62) of implicit prejudice is statistically significant, ceteris paribus. The intra‐cluster correlation coefficient 4.57/(4.57 + 80.89)=0.05 implies that only 5% of the remaining total variance in the positive valence score has to be explained at the encounter level. Therefore, high explicit prejudice, measured on the symbolic racism scale, is associated with low positive valence score during patient–physician medical encounters on average. Additionally, the mean positive valence score at occasion 2 drops significantly from the mean initial score at occasion 1, controlling for other covariates in the model. Finally, we used 2,500 burn‐in iterations and 2,500 post burn‐in iterations. The PSRF statistic for each parameter was less than 1.1, satisfying the convergence criterion. The R package GSExact, available at https://github.com/shind10/GSExact, provides all simulation codes from Section 4, as well as the estimation in Table 7.
Discussion
6
We estimated a HLM with the nonlinear effects of cluster‐level covariates from partially observed data assumed MAR. Our Bayesian estimation by a Gibbs sampler consists of exact posterior distributions, which are derived via selected provisionally known random effect to ensure compatibility with the HLM [18, 26]. Our simulation results show that the sampler produces reasonably accurate and precise estimates given sample sizes as small as n=4 units nested within J=36 clusters and given partially observed outcome and cluster‐level continuous covariates having interaction effects. Our estimators were as accurate and precise as those of competing methods given large sample sizes (n=4,J=200), and more accurate and precise than completing ones given small sample sizes (n=4,J=36) in our simulation study.
We checked convergence to the posterior distribution by the PSRF and Geweke's criteria and found that the PSRF criterion was preferable to Geweke's criterion in our simulation scenarios. This preference was more apparent given additional partially observed covariates and smaller sample sizes.
In our simulation, we also assessed robustness of our estimators under three cases: i) a misspecified distribution of a partially observed covariate; ii) violation of the MAR assumption; and iii) multiple interaction terms of partially observed covariates. The simulation results reveal that our estimators are reasonably robust against these violations given large and small sample sizes in our simulation scenarios. An importance avenue for future research is to conduct extensive simulations under different misspecified models and missing data mechanisms.
Our simulation study is limited in the sense that the cluster size was fixed at n=4 units, as analyzed in our real data analysis, while the number of J clusters were varied. Valuable future research is to assess the impact of varied cluster sizes on our estimators.
In near future, we aim to extend our sampler to efficiently handle partially observed discrete covariates or a mixture of partially observed discrete and continuous covariates having interaction effects at the cluster level. We also plan to extend our method to models where partially observed lower‐level covariates have nonlinear effects. See Shin and Raudenbush [18, 26] for ML estimation of a HLM for covariates MAR with nonlinear effects.
Conflicts of Interest
The authors declare no conflicts of interest.
Supporting information
Supporting Information.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1S. W. Raudenbush and A. S. Bryk , “Hierarchical Linear Models: Applications and Data Analysis Methods,” 2002.
- 2H. Goldstein , Multilevel Statistical Models (John Wiley & Sons, Incorporation, 2011).
- 3R. J. A. Little and D. B. Rubin , “Bayes and Multiple Imputation,” in Statistical Analysis With Missing Data (John Wiley & Sons, 2002), 200–220.
- 4D. B. Rubin , Multiple Imputation for Nonresponse in Surveys (John Wiley & Sons, Incorporation, 1987).
- 5D. B. Rubin , “Inference and Missing Data,” Biometrika 63, no. 3 (1976): 581–592.
- 6J. L. Schafer and R. M. Yucel , “Computational Strategies for Multivariate Linear Mixed‐Effects Models With Missing Values,” Journal of Computational and Graphical Statistics 11, no. 2 (2002): 437–457.
- 7Y. Shin and S. W. Raudenbush , “Just‐Identified Versus Overidentified Two‐Level Hierarchical Linear Models With Missing Data,” Biometrics 63, no. 4 (2007): 1262–1268.17501944 10.1111/j.1541-0420.2007.00818.x · doi ↗ · pubmed ↗
- 8T. E. Raghunathan , J. M. Lepkowski , J. Van Hoewyk , and P. Solenberger , “A Multivariate Technique for Multiply Imputing Missing Values Using a Sequence of Regression Models,” Survey Methodology 27, no. 1 (2001): 85–96.