CVNet: Lightweight Cross-View Vehicle ReID with Multi-Scale Localization
Wenji Yin, Baixuan Han, Yueping Peng, Hexiang Hao, Zecong Ye, Yu Shen, Yanjun Cai, Wenchao Kang

TL;DR
CVNet is a lightweight network for cross-view vehicle re-identification that uses efficient modules to handle scale variations and improve performance on edge devices.
Contribution
The novel contribution is CVNet with MSL and DFC modules, and the release of the CVPair v1.0 dataset for cross-view ReID.
Findings
CVNet achieves state-of-the-art performance on CVPair v1.0, VehicleID, and VeRi776 benchmarks.
The MSL module effectively localizes salient regions and handles viewpoint variations.
The DFC module captures both unique and shared cross-view features efficiently.
Abstract
Cross-view vehicle re-identification (ReID) between aerial and ground perspectives is challenging due to limited computational resources on edge devices and significant scale variations. We propose CVNet, a lightweight network with two key modules: the multi-scale localization (MSL) module and the deep–shallow filtrate collaboration (DFC) module. The MSL module employs multi-scale depthwise separable convolutions and a localization attention mechanism to extract multi-scale features and localize salient regions, addressing viewpoint variations. DFC employs a dual-branch design comprising deep and shallow branches, integrating a filtration module optimized via neural architecture search, a collaboration module, and lightweight convolutions. This design effectively captures both unique and shared cross-view features, ensuring efficient and robust feature representation. We also release a…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
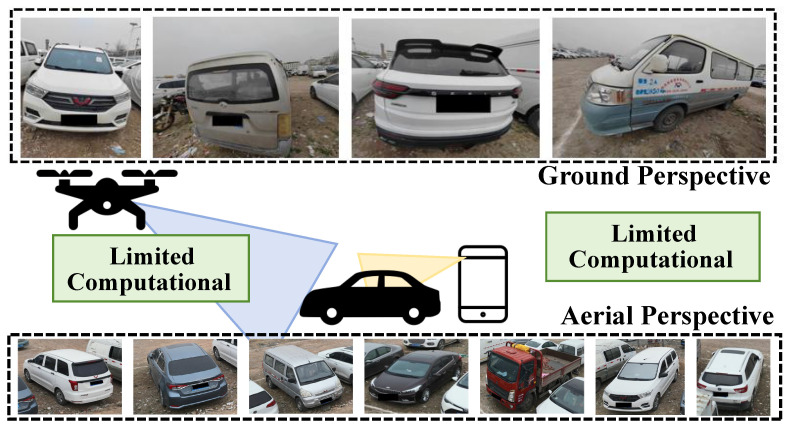 Figure 1
Figure 1 Figure 2
Figure 2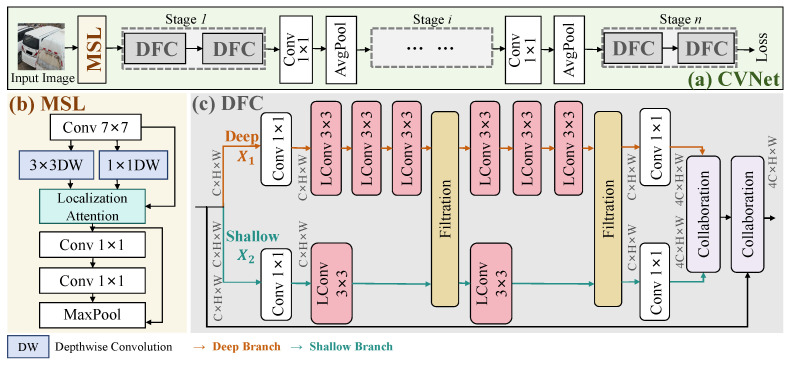 Figure 3
Figure 3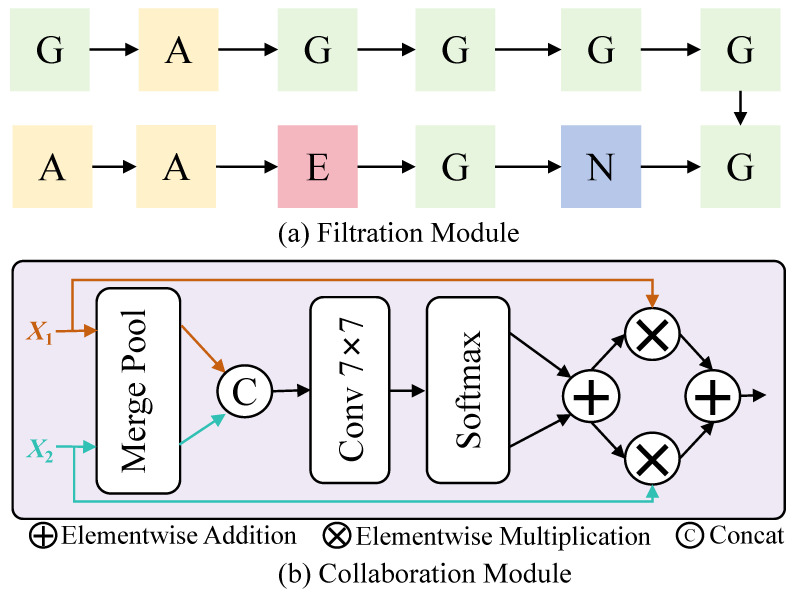 Figure 4
Figure 4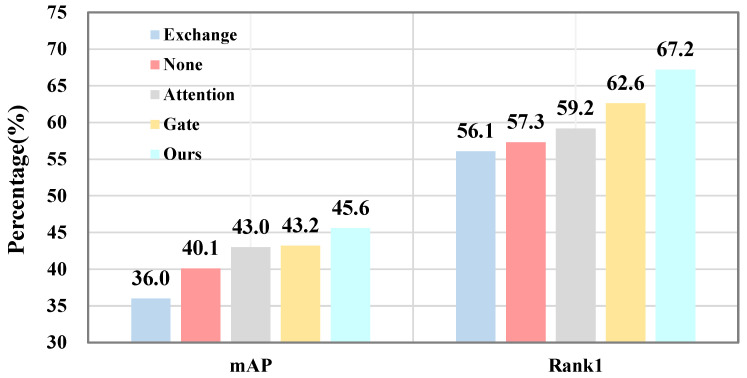 Figure 5
Figure 5 Figure 6
Figure 6- —Engineering University of PAP
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPhysical Unclonable Functions (PUFs) and Hardware Security · Modular Robots and Swarm Intelligence · Advanced Neural Network Applications
1. Introduction
The advancement of aerial photography has transformed road monitoring, creating new opportunities for vehicle ReID [1,2,3,4]. However, cross-view vehicle ReID between aerial and ground perspectives remains challenging due to differences in viewing angles, significant scale variations, and the limited computational resources of edge devices.
Vehicle ReID methods typically rely on backbone networks with classification heads. While convolutional neural networks (CNNs) have advanced feature extraction through global and local aggregation strategies, they face limitations. Global pooling layers dilute discriminative local features, and spatial division or part-based detection methods demand extensive annotations and high computational costs. To address these issues, studies have integrated CNNs [5] with graph neural networks (GNNs) [6] for improved feature relationship modeling. Transformers [7] enhance global and local feature learning but are constrained by high computational demands and limited adaptability to multi-scale, low-resolution inputs. Lightweight backbones [8] offer efficiency but struggle to maintain robust performance in cross-view ReID tasks. These challenges underscore the need for architectures that balance efficiency, multi-resolution input handling, and cross-view alignment.
As illustrated in Figure 1, several critical challenges hinder the advancement of cross-view vehicle ReID systems. First, aerial capture devices, such as Jetson Nano and other edge computing platforms, often suffer from limited computational resources, making it infeasible to deploy traditional heavy ReID models. This constraint underscores the need for lightweight architectures capable of balancing efficiency and accuracy, similar to recent advancements in efficient conditional generation frameworks [9,10]. Second, the inherent differences in image properties caused by heterogeneous capture devices—including drones, mobile phones, and ground surveillance cameras—introduce significant variations in scale, resolution, and viewpoint. These inconsistencies are further exacerbated by perspective changes, leading to vehicle images with diverse sizes, shapes, and aspect ratios. Existing multi-scale feature fusion methods like Feature Pyramid Networks (FPNs) [11] partially address this issue, but often struggle to preserve critical structural details in cross-resolution scenarios. To this end, robust feature extraction methods that can adaptively capture cross-view contextual information are essential, drawing inspiration from multi-level conditioning strategies in generative tasks [12,13]. Third, the lack of large-scale datasets specifically designed for cross-view vehicle ReID remains a significant bottleneck. Although person ReID has seen rapid progress driven by the availability of diverse cross-view datasets [14,15], vehicle ReID research is limited by limited resources. This gap hampers the development of models capable of handling perspective shifts, resolution discrepancies, and domain variations. Addressing this challenge may benefit from bipartite-aware similarity learning [16] and contrastive learning strategies [17], which have been proven effective in other cross-domain retrieval tasks.
To overcome these issues, we propose CVNet, a lightweight architecture specifically designed for cross-view vehicle ReID. CVNet incorporates two innovative modules: the multi-scale localization (MSL) module and the deep–shallow filtrate collaboration (DFC) module. The MSL module employs multi-scale depthwise separable convolutions alongside localization attention mechanisms to enable precise regional localization through multi-scale feature extraction and fusion. Meanwhile, the DFC module adopts a dual-branch design, leveraging lightweight convolutions discovered via neural architecture search (NAS) to extract both shared and unique features across perspectives. CVNet incorporates two novel modules: the MSL module and the DFC module. The MSL module leverages multi-scale depthwise separable convolutions and localization attention mechanisms to precisely extract regional features through multi-scale feature extraction and information fusion. The DFC module adopts a dual-branch structure with lightweight convolutions discovered through NAS to process cross-view images. This design enhances scene understanding and strengthens the robustness of deep and shallow feature representations. Additionally, we introduce CVPair v1.0, the first benchmark dataset tailored for cross-view vehicle ReID. CVPair v1.0 contains 14,969 images of 894 vehicle identities, offering results of traditional and lightweight methods. The main contributions of this work are as follows:
- We propose CVNet, a lightweight network with only 4.4M parameters, achieving state-of-the-art performance.
- We devise the MSL module, which enhances precise regional positioning through multi-scale feature extraction and fusion, tailored for complex scenarios.
- We develop the DFC module, designed to extract both shared and unique features across diverse perspectives, improving cross-view feature representation.
- We present CVPair v1.0, the first benchmark dataset for cross-view vehicle ReID, offering results of traditional and lightweight methods.
2. Related Work
2.1. Datasets for Vehicle ReID
Ground–Ground Vehicle ReID Datasets: As shown in Table 1, the VERI-Wild [18] and VehicleID [19] datasets are two prominent public repositories designed for the task of vehicle ReID. These datasets serve as valuable resources for researchers aiming to develop and evaluate vehicle recognition algorithms. The VehicleID [19] dataset comprises 221,763 images across 26,267 unique vehicle identities, whereas the VERI-Wild [18] dataset is substantially larger, encompassing 416,314 images of 40,671 distinct vehicle identities. The VehicleID [19] dataset is characterized by its simplicity and uniformity, with the majority of images featuring frontal or rear views of vehicles. In contrast, the VERI-Wild [18] dataset presents a more sophisticated challenge due to its inclusion of diverse perspectives and environmental conditions, such as varying lighting and instances of partial occlusion. This complexity introduces a layer of difficulty for researchers, particularly when addressing issues related to occlusion and viewpoint changes. The VERI-Wild [18] dataset’s enhanced authenticity and complexity render it particularly well suited for studies focused on real-world vehicle ReID scenarios. Its comprehensive nature provides a more robust platform for the development of algorithms that must contend with the variability and unpredictability inherent in field environments.
Aerial–Aerial Vehicle ReID Datasets: These are designed to align with scenarios where vehicle images are captured by multiple unmanned aerial vehicles (UAVs). Notable datasets within this domain include VRAI [20], VeRi-UAV [21], VRU [22], and UAV-VeID [23], each contributing unique attributes to the field of vehicle ReID. The VRAI [20] dataset stands out for its comprehensive annotations that extend beyond mere perspectives. It provides detailed part annotations for each vehicle instance, facilitating the distinction of specific vehicle features. This includes classifications for color (class 9), vehicle type (class 7), and the presence of a sunroof, bumper, spare tire, and luggage rack. The image resolution captured by the drones may vary due to fluctuations in altitude, leading to a broader range of resolutions compared to the VehicleID [19] dataset. The VeRi-UAV [21] dataset comprises a total of 81 videos, from which 2158 scene images with a resolution of 4096 × 2160 were meticulously screened. The dataset encapsulates 17,515 images of 454 vehicles, capturing a diverse array of weather and lighting conditions, and preserving natural settings. Each vehicle image is not only meticulously tagged with its ID and viewpoint but also enriched with spatio-temporal information, including video ID and scene sequence data. The UAV-VeID [23] dataset is distinguished by its realism, with drones operating at altitudes ranging from 15 to 60 m, yielding a spectrum of vehicle image proportions. The camera’s vertical angle varies from 40 to 80 degrees, introducing a variety of viewing angles. The images are collected under unconstrained, natural conditions, without artificial modification, thus defining a more authentic vehicle ReID task. Lastly, the VRU [22] dataset is an expansive compilation within this category, featuring footage from four flying drones. With an altitude range of 15 to 60 m, the dataset contains 172,137 images of 15,085 vehicles. It is structured into one training set and three distinct test sets—small, medium, and large—to accommodate varying scales of evaluation.
Aerial–Ground Vehicle ReID Datasets: The AG-ReID [14] and G2APS [15] datasets represent the current state of Aerial–Ground person ReID datasets. The AG-ReID [14] dataset comprises 21,893 images across 388 unique identities, offering a rich tapestry of data captured by two cameras situated in a bustling outdoor environment. Utilizing DJI drones, the dataset benefits from a dynamic range of altitudes between 15 and 45 m, providing a diverse array of perspectives and backgrounds through both aerial and fixed-camera footage. The G2APS [15] dataset, focused on personal identification, presents a substantial collection of 2644 individual identities and an extensive compilation of 260,559 bounding boxes. This dataset’s encompasses flight altitudes from 20 to 60 m, ground surveillance cameras positioned approximately 2.0 m above the ground, and a diverse set of perspectives, attitudes, and patterns captured by drones as they record individuals in various poses. The datasets simulate a wide spectrum of real-world conditions, characterized by significant view changes between query and gallery images, and enriched by complex environmental scenes.
However, to the best of our knowledge, there exists a notable absence of datasets dedicated to vehicle ReID across aerial and ground camera perspectives. Our work aims to take the inaugural step towards addressing this gap, paving the way for future research and technological advancements in the field.
2.2. Neural Architecture Search Task
NAS is increasingly favored by the computer vision community for its characteristics of automated architecture design and is usually composed of three main parts: search space, search strategy, and performance evaluation. The role of NAS is to automate the search for the optimal network architecture, which not only saves researchers a lot of time and effort but also helps to discover innovative network structures that human experts may overlook. With NAS, the network can be customized for specific tasks, improving the performance and efficiency of the model. Compared to traditional methods of designing network architectures by hand, NAS is able to quickly explore a large number of network possibilities and find an architecture that is better suited to a specific task. In the ReID task, NAS in particular shows its advantage. The ReID task requires the model to recognize and match pedestrians under different cameras, which requires the model to be able to capture robust and discriminating features. NAS can customize the network for ReID tasks and automatically search for network structures that are more suitable for capturing multiple scales, perspectives, and features, thus improving the accuracy and robustness of recognition.
At present, Progressive Neural Architecture Search (PNAS) [24] proposes a progressive search strategy to search architectures by gradually increasing the complexity of the network. Efficient Neural Architecture Search (ENAS) [25] optimizes network architecture through reinforcement learning, which significantly improves search efficiency. Differentiable Architecture Search (DARTS) [26] treats network architecture search as a differentiable process, allowing optimization using gradient descent methods. Search network architecture using neural architecture search with reinforcement learning (NASNet) [27] especially improves the efficiency of the network.
However, most of the current NAS strategies do not consider the special task of air–ground cross-view ReID, and the challenges such as view changes and resolution differences in the task are not fully considered in the NAS search process, so it is necessary to design or adjust the search strategy specifically.
3. CVPair v1.0 Dataset
To address the lack of datasets designed for cross-view vehicle ReID tasks, as shown in Figure 2, we release the CVPair v1.0 dataset, the first benchmark tailored for cross-view vehicle ReID. The dataset construction involved four key processes—collection, filtration, annotation, and split—ensuring both quality and relevance. CVPair v1.0 encompasses a diverse range of challenging scenarios, including open-air and underground environments, and provides a comprehensive evaluation benchmark for this underexplored task.
Collection. The CVPair v1.0 dataset, comprising 14,969 images of 894 vehicles, introduces a unique challenge in vehicle ReID by spanning both open-air and underground environments. It includes aerial and ground-level views, capturing diverse perspectives that significantly increase the complexity of air-to-ground ReID.
Filtration. During dataset construction, we implemented stringent filters to guarantee data quality and relevance. Our trained review teams removed irrelevant content like background noise and objects, as well as images with technical flaws like overexposure and blurriness.
Annotations. To boost vehicle detection accuracy in high-altitude aerial photos, we manually curated a dataset. Annotators extracted vehicle images from drone footage. We used a cross-annotation process with two annotators verifying each other’s work for accuracy. The dataset, CVPair v1.0, was divided into categories ‘A’ for aerial images and ‘G’ for ground images.
Split. The dataset is divided evenly, with 50% allocated for training and 50% for testing. The training set comprises 391 identities and 7448 images, while the test set includes 1006 query images and 6515 gallery images. Model performance is evaluated under two scenarios: aerial-to-ground (A2G) and ground-to-aerial (G2A).
Challenge. From Figure 2, the key attributes of our dataset are as follows: first, resolution variability, resulting from the different capture devices used for aerial and ground images; second, dynamic illumination, such as features observed in the underground garage scenario, where fluctuating lighting conditions blur vehicle images, creating real-world recognition challenges; finally, viewpoint disparity, with top-down images offering features distinct from ground-level perspectives.
4. Methodology
4.1. Overall
From Figure 3, we propose CVNet, a lightweight network with only 4.4M parameters, featuring the MSL and DFC modules. The network starts with a 0.09 M MSL module, which employs multi-scale depthwise separable convolutions and a localization attention mechanism to extract multi-scale features and localize salient regions. Image features are then processed through n stages, with average pooling between each to reduce complexity. Each stage contains two DFC modules, which refine features using a dual-branch mechanism to handle multi-perspective images. By combining the MSL’s extraction with the DFC’s filtrate collaboration, the network captures expressive features, improving accuracy for images from varying perspectives. This design boosts both parameter efficiency and enhances the model’s robustness to variations in perspectives.
4.2. Multi-Scale Localization
Traditional feature extraction methods struggle with images captured at varying perspectives, leading to performance issues. Increasing network depth to compensate adds a significant computational burden, especially on edge devices of limited computational resources. As shown in Figure 3, the proposed MSL module addresses this challenge by combining depthwise convolution (DW) with localization attention modules in a lightweight design. This module can be seamlessly integrated into any backbone for enhanced vehicle ReID. Initially, features are extracted via a convolution operation and split into three branches. The first branch applies a DW for cross-channel fusion, while the second employs a DW for deeper feature extraction. These multi-scale features, along with the third branch, are fed into the localization attention module, which adjusts weights based on input to overcome the limitations of standard convolutions.
The localization attention module encompasses a global average pooling operation, followed by a sigmoid activation function, and culminates in the multiplication of the resultant weights with the original feature maps. This architectural choice enhances the network’s representational capacity, enabling it to focus on the most significant features. After localization attention, two convolutional layers with max pooling reduce the feature map size while increasing displacement invariance. A residual structure ensures efficient gradient flow and prevents degradation. MSL’s combination of convolutions, DW, localization attention, and pooling structures offers an efficient, lightweight feature extractor. Positioned before the backbone, it enriches feature representation with minimal additional parameters, significantly boosting extraction capabilities.
4.3. Deep–Shallow Filtrate Collaboration
Our proposed DFC module, illustrated in Figure 3, incorporates convolution, filtration, and collaboration modules. The input feature is represented as , where C, H, and W denote the number of channels, height, and width, respectively. Input features are processed through deep and shallow branches with different receptive field scales. To minimize computational load, each branch employs a stack of and convolutions along multiple depth directions, with the deep-to-shallow branch ratio set at 3:1. The branches operate independently, except for the shared filtration module.
(1) Filtration Module. This module facilitates information exchange between the deep and shallow branches, and , offering four operational modes: None: No modification is applied, and the output remains ( , ). Exchange: The features of the two branches are swapped, resulting in ( , ). Gate: The input data are first entered into the first fully connected layer, which transforms them linearly through weights and biases, capturing the primary characteristics of the data. Subsequently, using Relu layers enables the model to learn and simulate more complex data relationships, alleviating the problem of disappearing gradients. This is followed by a second fully connected layer, which further extracts and combines features to form a more complex and abstract representation of features. After activating the function, each input data point is finally multiplied by its corresponding transformed output element by element. This operation not only retains some characteristics of the original data but also reweights them by the learned weights, thus enhancing the response-ability of the model to the input characteristics. Attention: First, Xa and Xb are rearranged into query and key. By matrix multiplication, we calculate energya between Xa’s query and Xb’s key, and energyb between Xb’s query and Xa’s key. Energy represents the strength of the correlation between the different feature maps. Secondly, the output takes the maximum value and subtracts the original energy value to suppress the non-maximum value, and the softmax function is applied to obtain the normalized attention weight. The weighted feature representation is obtained by multiplying the attention weight by the projected value of the input feature map. Finally, the output is scaled by a learnable parameter and then added to the original input feature map to form a residual join. Residual connections help avoid the problem of disappearing gradients in deep networks, making deep networks easier to train.
Ultimately, after the search process conducted by NAS, the optimal structure of CVNet, as depicted in Figure 4, is composed of the following: gate, attention, gate, gate, gate, gate, gate, none, gate, exchange, attention, and attention.
(2) Collaboration Module. After filtration, the deep and shallow branch features are fused through collaboration operations. Simple fusion methods, such as directly adding features, are prone to noise interference, making it difficult to achieve effective fusion. To address this, we propose a collaboration module for efficient feature fusion, illustrated in the purple area of Figure 4. Deep and shallow information is aggregated by merge pooling, which is composed of global average and max pooling. We concatenate the outputs of the two branches from the merge pooling to generate aggregated features. The aggregated features, meticulously selected through cross-validation, are passed through convolution layers to evaluate input feature weights in the channel dimension. We then apply a Softmax function to normalize these weights to ensure they sum to 1, helping identify the most representative features. These weights are then applied to the features via multiplication, effectively fusing them to provide richer, more refined representations. This process enhances the network’s ability to capture common and joint features, leading to a more comprehensive scene understanding.
4.4. Loss Function
We use a common ReID loss combining softmax loss and triplet loss to enhance the network’s discriminative power. The softmax loss, promoting class separation, is defined as
where N is the number of samples, C the classes, the label, and the logit for the i-th sample. The triplet loss ensures that an anchor is closer to positives than negatives:
where and are distances, and margin defines minimum separation. The total loss combines both
5. Experiment and Analysis
5.1. Implementation Details
The deep learning framework used in this work is PyTorch with FP16 training for enhanced computational efficiency. The model is trained for 350 epochs using a dual-optimizer configuration, where stochastic gradient descent (SGD) with a learning rate of 0.065 and momentum of 0.9 is employed for most parameters, while Adam with an initial learning rate of 0.002 is applied to specific components. A 10-epoch warm-up period is introduced to stabilize training by gradually increasing the learning rate. Images are uniformly resized to for consistency, and a weight decay of is implemented for regularization to prevent overfitting. A batch size of 64 is used to balance computational efficiency and effective model updates, with MSINet [28] serving as the baseline for all experiments.
5.2. Comparison with State-of-the-Art Methods
We perform extensive evaluations on the proposed CVPair v1.0 dataset, re-implementing both traditional and lightweight ReID methods, as shown in Table 2. Furthermore, we compare our approach on existing ReID datasets (VeRi-776 and VehicleID datasets), as detailed in Table 3.
CVPair v1.0 Dataset Results. We evaluate the performance of leading ReID models on the newly introduced CVPair v1.0 dataset, as shown in Table 2. For the A2G modality, our experiments report a mAP of 45.6% and a Rank1 accuracy of 67.2%, while the G2A modality achieves a mAP of 35.8% and a Rank1 accuracy of 53.9%. Compared to traditional ReID methods, CVNet, with only 4.4M parameters, outperforms the next-best model by 13.7% in mAP and 23.9% in Rank1 accuracy, demonstrating its remarkable efficiency in low-complexity scenarios. Furthermore, compared to lightweight methods, our approach achieves the best performance on CVPair v1.0. While it has slightly more parameters than StarNet-S1 + CH, the significant accuracy improvement underscores its competitiveness.
Existing Datasets Results. We evaluated state-of-the-art vehicle ReID methods on the VeRi-776 and VehicleID datasets, as shown in Table 3. Our method achieves Rank1 accuracies of 93.6% on VeRi-776 and 85.9% on VehicleID with only 4.4M parameters, outperforming all competitors. In comparison, Trans-ReID [32] (86.6M parameters) achieves 85.2%, while Vit-reid [38], GiT [39], and SOFCCT [37], with 57.3M parameters, achieve 80.5%, 84.7% and 77.8% on VehicleID, respectively. CAL [36] (23.8M parameters) achieves only 75.1%. These results highlight the superior efficiency and performance of our approach.
5.3. Ablation Studies and Analysis
Role of the MSL and DFC. We evaluate the contributions of the DFC and MSL modules on the CVPair v1.0 dataset by replacing them with ResNet50’s 7 × 7 convolutions (Res. 1) and Stage (Res. S), respectively. As shown in Table 4, incorporating DFC improves Rank1 accuracy by 1.9% and mAP by 1.2%, demonstrating its ability to bridge cross-view feature discrepancies by capturing both shallow and deep features. Its filtration mechanism enhances feature interaction, preserving feature richness and boosting robustness to perspective variations. Similarly, the MSL module improves Rank1 accuracy by 3.8% and mAP by 5.1% by integrating Inception layers, depthwise convolutions, and lightweight attention blocks to efficiently capture multi-scale features. With only 0.09 M additional parameters, MSL delivers significant performance gains with minimal computational overhead, making it ideal for resource-constrained scenarios.
Impact of NAS Strategies. Figure 5 compares filtration strategies in the DFC module, with “Ours” representing NAS-optimized operations. Strategies like “None” and “Exchange” perform poorly due to the lack of trainable parameters. Gating and attention operations improve performance by enhancing feature exchange, but CVNet achieves the best results by organizing interactions effectively. The NAS-optimized DFC achieves a 9.6% mAP gain and a 11.1% Rank1 improvement over “None”, demonstrating its effectiveness.
Impact of n. Table 5 shows that a stage ( ) configuration achieves the highest Rank1 and mAP scores. Fewer stages limit feature extraction, reducing the model’s ability to capture complex patterns, while more stages risk overfitting due to excessive parameters. The configuration strikes a balance between depth and computational efficiency, enabling effective learning of discriminative features. Therefore, this work adopts as the default setting.
Visualization Results. Figure 6 illustrates the top-5 retrieval results for both the baseline and CVNet models in the CVPair v1.0 dataset, highlighting CVNet’s superior accuracy and ability to capture fine-grained vehicle details. Compared to the baseline, CVNet demonstrates improved retrieval precision, correctly identifying subtle features that the baseline model often misses. Using MSL and DFC modules, along with multi-scale feature extraction and information fusion, CVNet enhances regional localization and scene understanding, leading to more accurate and robust vehicle differentiation across diverse perspectives.
6. Conclusions
We propose CVNet, a lightweight network designed for cross-view vehicle ReID, addressing challenges of scale variation and computational constraints. The MSL module extracts multi-scale features with localization attention, while the DFC module employs a dual-branch design to capture unique and shared cross-view features. Along with CVNet, we introduce CVPair v1.0, the first benchmark for cross-view ReID, featuring 14,969 images of 894 vehicle identities. CVNet achieves state-of-the-art performance on CVPair v1.0, VehicleID, and VeRi-776, advancing cross-view ReID research.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wang Z. Huang H. Zheng A. Li C. He R. Parallel augmentation and dual enhancement for occluded person re-identification Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)Seoul, Republic of Korea 14–19 April 202435903594
- 2Yang B. Chen J. Ye M. Top-k visual tokens transformer: Selecting tokens for visible-infrared person re-identification Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)Rhodes Island, Greece 4–10 June 202315
- 3Zhong X. Su S. Liu W. Jia X. Huang W. Wang M. Neighborhood information-based label refinement for person re-identification with label noise Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)Rhodes Island, Greece 4–10 June 202315
- 4Zhu W. Wang Z. Wang X. Hu R. Liu H. Liu C. Wang C. Li D. A dual self-attention mechanism for vehicle re-identification Pattern Recognit.202313710925810.1016/j.patcog.2022.109258 · doi ↗
- 5Khorramshahi P. Peri N. Kumar A. Shah A. Chellappa R. Attention Driven Vehicle Re-identification and Unsupervised Anomaly Detection for Traffic Understanding Proceedings of the CVPR Workshops Long Beach, CA, USA 16–20 June 2019239246
- 6Xu Z. Wei L. Lang C. Feng S. Wang T. Bors A.G. HSS-GCN: A hierarchical spatial structural graph convolutional network for vehicle re-identification Proceedings of the ICPR International Workshops and Challenges on Pattern Recognition Virtual Event 10–15 January 2021 Proceedings, Part V Springer Berlin/Heidelberg, Germany 2021356364
- 7Li Z. Zhang X. Tian C. Gao X. Gong Y. Wu J. Zhang G. Li J. Liu H. TVG-Rei D: Transformer-based vehicle-graph re-identification IEEE Trans. Intell. Veh.202384644465210.1109/TIV.2023.3292513 · doi ↗
- 8Chen J. Kao S.h. He H. Zhuo W. Wen S. Lee C.H. Chan S.H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Vancouver, BC, Canada 17–24 June 20231202112031