Accelerated Method for Simulating the Solidification Microstructure of Continuous Casting Billets on GPUs
Jingjing Wang, Xiaoyu Liu, Yuxin Li, Ruina Mao

TL;DR
This paper introduces a fast GPU-based method to simulate the microstructure of continuous casting billets, improving accuracy and speed for industrial applications.
Contribution
A high-performance CA-DCSA method on GPUs is proposed, significantly accelerating microstructure simulations while maintaining accuracy.
Findings
The GPU-accelerated method achieved a 1430× speedup compared to the serial implementation.
Simulated results showed relative errors of less than 3% for key microstructure parameters in 65# and 60# steel.
The maximum temperature difference in 65# steel was 1.8 °C, validating the method's accuracy.
Abstract
Microstructure simulations of continuous casting billets are vital for understanding solidification mechanisms and optimizing process parameters. However, the commonly used CA (Cellular Automaton) model is limited by grid anisotropy, which affects the accuracy of dendrite morphology simulations. While the DCSA (Decentered Square Algorithm) reduces anisotropy, its high computational cost due to the use of fine grids and dynamic liquid/solid interface tracking hinders large-scale applications. To address this, we propose a high-performance CA-DCSA method on GPUs (Graphic Processing Units). The CA-DCSA algorithm is first refactored and implemented on a CPU–GPU heterogeneous architecture for efficient acceleration. Subsequently, key optimizations, including memory access management and warp divergence reduction, are proposed to enhance GPU utilization. Finally, simulated results are…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
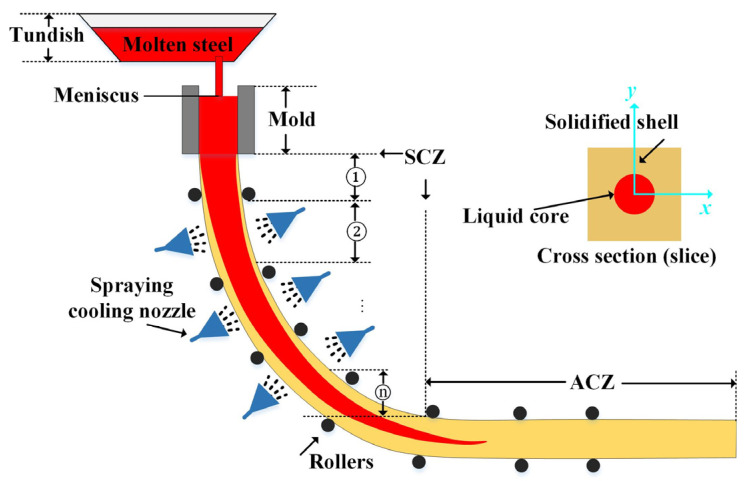 Figure 1
Figure 1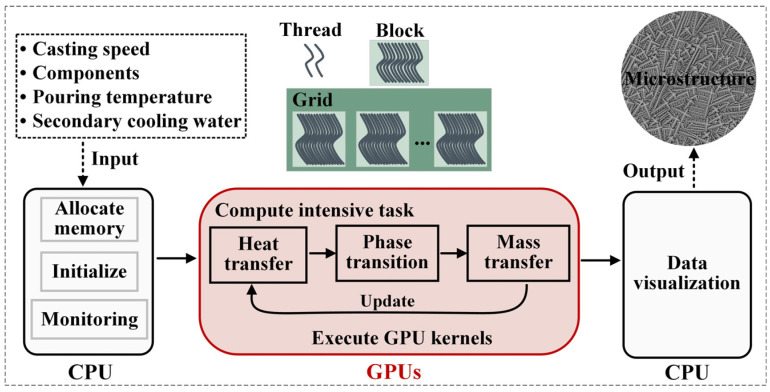 Figure 2
Figure 2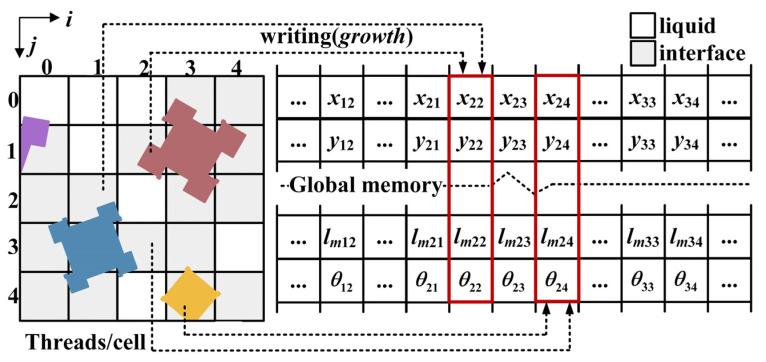 Figure 3
Figure 3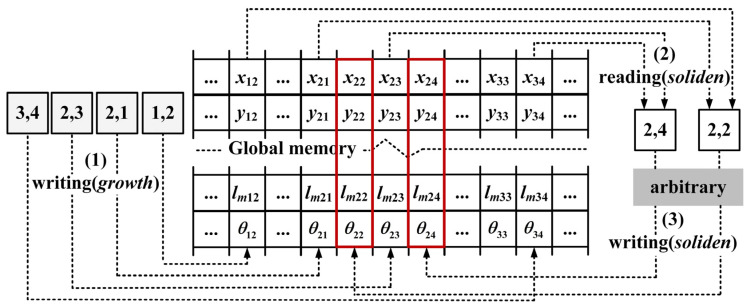 Figure 4
Figure 4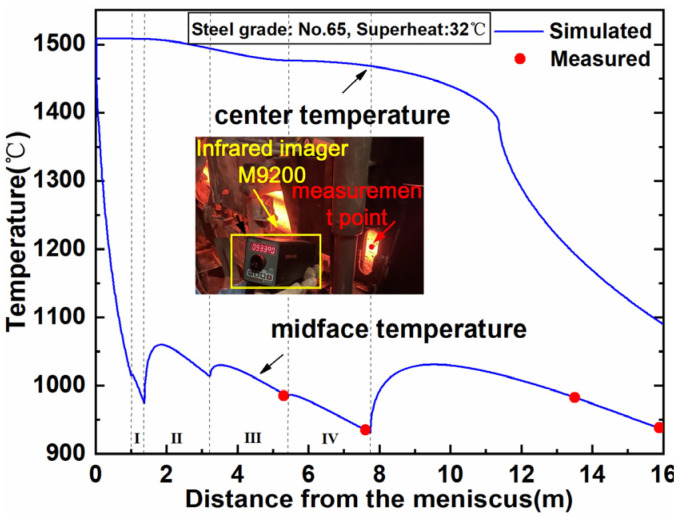 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7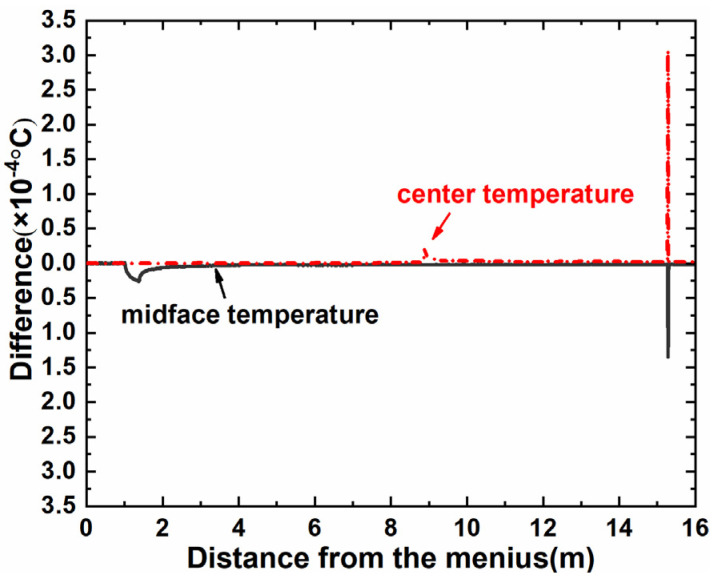 Figure 8
Figure 8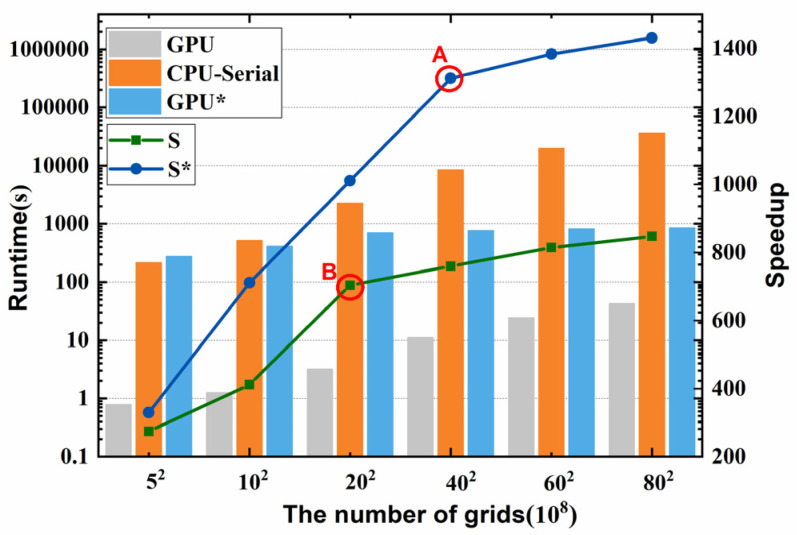 Figure 9
Figure 9- —National Natural Science Foundation of China
- —Postdoctoral Fellowship Program of CPSF
- —Fundamental Scientific Research Business of Central Universities
- —Doctoral Scientific Research Initiation Foundation of Liaoning Province
- —Research Startup Fund of Shandong Youth Political College
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMetallurgical Processes and Thermodynamics · Solidification and crystal growth phenomena · Manufacturing Process and Optimization
1. Introduction
The mechanical properties of castings heavily depend on the microstructure of billets, especially the ECR (Equiaxed Crystal Ratio) and the secondary dendrite arm spacing. Analyzing the solidification microstructure of billets plays a crucial role in optimizing process parameters and enhancing the performance of castings. Although various methods, such as dendrite corrosion, electron probes, and synchrotron radiation in situ observations [1,2,3], are available for detecting microstructures, their application in large-scale production is restricted due to their high costs and environmental constraints.
In recent decades, several numerical simulation methods have emerged for predicting the solidification microstructures of castings, including CA [4,5,6,7], PF (Phase Field) [8,9,10], and MC (Monte Carlo) [11,12,13], etc. Of these methods, CA and PF are the most widely adopted. The PF model is primarily used for simulating the local dendrite morphology of a casting due to its requirement of a large grid size. The CA model is known for its simplicity, ease of implementation, and high calculation efficiency, making it a popular choice for simulating the microstructures of continuous casting billets. However, the solidification structures [14,15,16] simulated using the CA method have a significant drawback, i.e., dendrites grow exclusively in the direction perpendicular to the solid wall, which contradicts the actual continuous casting process where dendrites grow in different orientations. This limitation stems from mesh anisotropy, which is caused by the fixed grid layout and capture rule. Various methods have been developed to address this issue, including the random zigzag capture rule [17], block cells [18], and DCSA [19,20]. However, the first two methods are limited by the fact that they can only simulate dendrites with the same orientation simultaneously. The CA model coupled with DCSA is effective for simulating dendrites with different orientations simultaneously by dynamically tracking the dendrite tip, and has been successfully used to simulate the growth of columnar and equiaxed dendrites [21,22,23]. However, existing studies have focused on simulating the growth of single or multiple dendrites, with no research yet on simulating the microstructure of continuous casting billets. The scarcity of research in this area stems from DCSA’s requirement of a precise grid size and the computational complexity introduced by dynamic changes in capture positions and conditions. Consequently, simulating the microstructure of continuous casting billets with this approach demands immense computational power, rendering it a time-consuming endeavor or altogether unfeasible on a CPU. Therefore, improving the calculation of efficiency is the key to establishing a CA model with a low grid anisotropy capable of simulating the microstructure of continuous casting billets.
In related research fields, several methods have been proposed to improve the calculation efficiency, including parallel computing with multi-core CPUs [24,25,26,27] and adaptive mesh methods [28,29]. However, these methods are based on CPUs, the speed of which is not ideal because the number of cores is limited by the hardware architecture and they incur significant overheads when launching multi-threaded processes [30]. Recently, GPUs have become increasingly popular for accelerating large-scale calculations, owing to their multiple-core architecture with a particularly high number of lightweight cores [31,32,33,34,35]. Moreover, the CA model is particularly suitable for parallel computations using a GPU because of its discrete time and space, and the homogeneous and asynchronous application of transition rules among cells [36]. The use of heterogeneous GPU–CA models has enhanced the performance of computational models in various fields [37,38,39,40].
To effectively address the challenges posed by grid anisotropy and computational efficiency in simulating the microstructure of continuous casting billets, this paper proposes a GPU-accelerated CA-DCSA method based on our previous GPU acceleration scheme [16]. In addition to porting the serial program to the heterogeneous architecture with a refactored parallel algorithm, we further optimized the memory access efficiency by changing the memory access mode and minimizing warp divergence. Compared to previous models, the present work can simulate more detailed microstructures with clear dendrite morphologies. Moreover, the simulation results agree well with industrial experimental data in both structure (ECR and the average secondary arm spacing) and temperature distribution. In addition, this accelerated model achieves a considerable increase in speed of 1430× compared to the serial CPU implementation, making it an invaluable tool for optimizing process parameters.
2. Model Description for Solidification in Continuous Casting
Figure 1 illustrates the continuous casting process, wherein the molten steel flows from the tundish to the water-cooled copper mold to form the initial shell.
Then, the solidifying shell moves down to the SCZ (Secondary Cooling Zone), where it is cooled by sprayed water or an air mist. Finally, the solid strand enters the ACZ (Air-Cooling Zone) and completes the solidification process gradually. This process involves complex multi-physics coupling, including heat transfer, mass transfer, and phase change, which results in the final solidification microstructure of the continuous casting billet. This paper utilizes the “two-dimensional slice tracking” method to trace the evolution of the microstructure from the meniscus to the end of the withdrawal straightener, where the FVM (Finite Volume Method) is utilized to solve the heat and mass transfer equations, and the CA method is used to describe the phase transition process.
2.1. Heat and Mass Transfer Model
The heat transfer process of continuous casting billets can be described by the heat conduction equation [18,41,42]
where is temperature, ; is time, s; is mass density, kg/m^3^; is equivalent specific heat; and is thermal conductivity. The Fe-C pseudo-binary phase diagram [43] is adopted to calculate the thermophysical properties. is the gradient heat flux determined by different boundary conditions which are set as follows:
In the mold-cooling zone, the gradient heat flux boundary condition is given by the modified Savage–Pritchard equation [41,44].
where A and B are coefficients that can be adjusted according to the industrial data related to heat transfer conditions (heat flux, surface temperature, cooling water flow rate, and other relevant parameters that influence the heat transfer efficiency), n represents the normal direction, which is perpendicular to the boundary surface.
In the SCZ, heat is taken away from the billet surface by cooling water and thermal radiation, where the boundary condition can be determined by [34,41]
where is the comprehensive heat transfer coefficient, the subscript denotes the section in SCZ, is the emissivity of strand surface, with a value of 0.8; is the Stepan-Boltzmann constant, equal to 5.67 × 10^−8^ (W/m^2^)K^4^; and are cooling water temperature and ambient temperature, respectively, both equal to 25 °C. There are two kinds of cooling in the SCZ, i.e., water sprays and air-mist sprays, for which the coefficient is defined by Equation (4), describing two conditions [34,41].
where is the water flow density, and is the machine-dependent calibration parameters that can be adjusted to minimize the difference between the simulated and industrial data. The specific application of air-mist cooling and water cooling needs to be determined according to the design of the continuous casting machine and the process’ requirements.
In the ACZ, heat is extracted through thermal radiation [34,41,42]
The solute diffusion is governed by [14,23]
where means the solute diffusion coefficient calculated by Equation (7), and is the concentration, the subscript represents two states, i.e., is liquid and is solid. The gradient solute flux boundary condition is 0.
2.2. Phase Transition Model
In the CA method, the calculation domain is uniformly divided into square cells. The nucleation density of a cell with respect to the melt undercooling is given by Gaussian function [14,23]:
where and are the average and standard deviation nucleation undercooling, and is the maximum nucleation density. The nucleation probability of a liquid cell is calculated by:
where is cell size.
To reduce the mesh anisotropy, the current CA model utilizes the DCSA rule to capture neighbors. If the of the cell labeled as “A” exceeds a randomly generated number (0~1), a nucleation event in cell “A” will be triggered. A square with a random orientation is subsequently placed in the center of cell “A”, and its state will be updated from liquid to interface. Then, the square will grow along the orientation with the velocity given by the KGT model [15]:
where and are growth coefficients [45]. The melt undercooling consists of thermal, solute, and curvature undercooling, which is calculated by [18,22,23]:
where and are actual and initial concentration, ; and are the melt and liquidus temperatures, and is the liquidus slope; is the Gibbs–Thomson coefficient; is the interface curvature; is the interface anisotropy function; is the interface normal angle; and is the preferential growth orientation.
As cell “A” grows, its corners penetrate the neighboring cells and convert them into interface cells, with new squares generated at the capturing points. The square, located in cell “A” will keep expanding until its solid fraction f_s_ reaches 1 and the state of cell “A” will change to solid. The nucleation, growth, and capture processes will continue until solidification is complete.
2.3. Analysis of Computational Intense
To accurately model the capture process, the DCSA requires a fine grid division. For the billet properties that possess four-fold symmetry, this paper performs dynamic simulation on a quarter section (80 mm × 80 mm) in the top right corner of the billet. In the case of a casting speed of 1.75 m/min, a grid-independent solution can be obtained when the slice is divided into 8000 × 8000 cells with the size of 10 μm. And, the time step dt is set to 0.0005 s to keep the calculation accuracy. As the casting process is 16 m long, there are approximately 1.1 × 10^6^ slices equating to 7.04 × 10^13^ cells. Furthermore, the dynamic monitoring of the four corners of each square within the interface cells during the intricate three-physics coupling reaction necessitates a substantial increase in computational speed. In a test of 1000 slices on Intel^®^ Xeon^®^ CPU E5-2680 v4 @2.4 GHz, the simulation process took 10.06 h. In this scenario, the whole simulation process would take about 485 days, which is unacceptable and infeasible. Therefore, improving the calculation efficiency is crucial to simulate the microstructure of continuous casting billets with a multi-orientation dendrite morphology.
3. GPU-Accelerated Method for CA-DCSA Model
Here, the GPU-accelerated method consists of two main components: parallelization and optimization. We begin with parallelizing the serial program using the reengineered CA-DCSA algorithm and porting it to a heterogeneous parallel architecture. Then, a series of optimization techniques is devised to enhance memory utilization and prevent divergence, thereby facilitating the effective utilization of GPU resources and enabling high-performance computations.
3.1. Parallelization with Redesigned Algorithm
3.1.1. Porting to the Heterogenous Architecture
The heterogeneous model is implemented on Compute Unified Device Architecture (CUDA), a general-purpose parallel programming model consisting of a CPU code and a GPU code. First, taking full advantage of the computational power of the GPU provided by thousands of processing cores, our implementation strategically assigns the computation-intensive tasks to the GPUs, while allocating memory, initialization, program flow monitoring, and post-processing to the CPU, as shown in Figure 2. The GPU functions as a coprocessor and processes tasks through a parallel thread execution of a set of instructions referred to as a kernel. CUDA has a two-level thread hierarchy decomposed into thread blocks and grids of blocks. Once a kernel is launched, all independent threads in a grid will execute the instructions concurrently. Since the communication between CPU and GPU is very expensive, we designed only two communications, i.e., before and after the computation-intensive task. Moreover, a GPU-friendly SoA structure with all variables stored in a linearized form was utilized to organize the data as it provided the best-coalesced access pattern. In addition, read-only data that pertain to material properties, such as constant parameters and boundary conditions, were cached in constant memory. This type of memory is accessible from all threads within a grid, which can significantly reduce the number of memory transactions and improve overall performance. By caching these data in constant memory, they can be quickly accessed by multiple threads without repeated memory transfers from the global memory, which can lead to a significant reduction in memory latency. After the aforementioned parallelization operation, the program can be ported to the heterogenous architecture.
The functions running on a GPU consist of three main parts, as shown in Figure 2, and each part is implemented by several kernel functions; the solution is shown in the following pseudocode:
This process will be repeated until the solidification is completed.
3.1.2. Redesigning the Capture Process
The simplest way to achieve a high computational efficiency is assigning each thread to a computational unit, built on the foundation of high parallelism. To achieve this, the explicit formulation is utilized for the heat and mass transfer equations. In addition, the data competition that exists in the DCSA capture process when there are multiple neighboring cells that satisfy the capture condition can lead to undefined errors if it cannot be handled reasonably, rendering acceleration ineffective. As shown in Figure 3, at a certain time, cells (3, 4) and (2, 3) have penetrated into (2, 4), and cells (2, 1) and (1, 2) have touched (2, 2). In this case, the threads mapping to cells (3, 4) and (2, 3) will write data onto the memory space of cell (2, 4), and the threads mapping to cell (1, 2) and (2, 1) will write data onto the memory space of cell (2, 2) simultaneously. The AtomicExch function provided by CUDA can effectively prevent race conditions among multiple threads, but it comes with the cost of sacrificing computational parallelism and efficiency.
To eliminate data competition without sacrificing computational parallelism, we redesigned the capture process. As shown in Figure 4, the new parallel CA-DCSA algorithm focuses on preventing threads from modifying data that belong to other threads by dividing the capture process into three primary steps:
- (1)Growth kernel: Interface cells grow and update their growth-related parameters in global memory. No neighbor capture occurs at this stage, even if the capture condition is met.
- (2)Soliden kernel: Liquid cells read the growth-related parameters from neighboring interface cells, and judge which neighbor satisfies the capture condition based on them. An arbitration mechanism resolves conflicts when multiple neighbors satisfy the capture condition for the same liquid cell. Also, it is crucial to determine which corner touches the current cell because different corners have different capture positions, as shown in Figure 3 where both corners of the square in cell (0, 1) can touch cell (0, 0).
- (3)Soliden kernel: Liquid cells update their growth-related parameters based on the arbitration results from the soliden kernel.
In this new algorithm, threads only modify their own data, which can fundamentally avoid data competition without affecting computational parallelism.
3.2. Optimizations
Preliminary analysis shows that the present model suffers from a low memory access efficiency caused by a large number of memory transactions and warp divergence. Thus, to address these two issues, optimizations are performed to maximize GPU utilization and achieve effective acceleration.
3.2.1. Managing Memory Accessing
Memory write operations typically incur a higher latency than read operations. This occurs because write operations require data transfer from processors/registers to memory, while read operations can directly fetch data from memory. In our implementation, a lot of variables need to be updated in the kernel “Update” after each time step, rendering it the most time-consuming part. Most of the updated variables are assigned by the solute redistribution process, which sets nine intermediate variables for each cell to store the amounts of excess solute being distributed to neighboring cells and the current cell, as shown in the naive algorithm of Algorithm 1 where dC is the total rejected solute by the current cell. After being used in the kernel “SoluteAdd”, these intermediate variables must be reset to zero to use the next slice, leading to a large number of memory writing transactions. To avoid writing memory frequently, the operation in soluteAdd is redesigned, which is noted as the redesigned version in Algorithm 1.
Algorithm 1. Two methods for solute redistribution at S/L interface.
In this new algorithm, we implement a logical expression : when the expression is evaluated to be true, it returns 1 (preserving the current time step’s value); otherwise, it returns 0 (forcing the value to zero). Therefore, the memory writing of is replaced by memory reading of . Furthermore, we optimize data reuse through instruction reordering, significantly improving memory access efficiency.
3.2.2. Avoiding Warp Divergency
GPUs organize threads into warps, where each warp comprises 32 threads executing in lockstep via an SIMT (Single Instruction Multiple Thread) architecture. However, warp divergence occurs when threads within a warp take different execution paths during conditional operations, severely degrading performance [46]. In this work, conditional operations occur when solving Equations (7) and (14) using an if statement in naive version of Algorithm 2. Thus, in order to remove if conditions, we combine conditions into computational statements in the redesigned version of Algorithm 2.
Algorithm 2. Two methods for solute diffusion coefficient and interface normal angle.
4. Results and Discussion
The GPU-accelerated CA-DCSA method was applied to simulate the microstructure of continuous casting billets from a certain steel plant. The simulation accuracy was validated against the industrial measurement data, including the ECR, the average secondary arm spacing, and the temperature. The relevant caster parameters and billet properties are listed in Table 1, while the chemical compositions of the reference steels are detailed in Table 2. In our case, the SCZ of the continuous caster is divided into four sections. The first two sections use water cooling, while the last two sections employ air-mist cooling.
4.1. Validation with Industrial Experiment
To validate model accuracy, we simulated billets 65# and 60# using a time step of 5 × 10^−4^ s and a grid resolution of 10^−5^ m. Given the critical relationship between microstructure and thermal history, temperature validation was prioritized. In order to validate the calculated temperature, a series of temperatures for steel 65# (superheat: 32 °C), were measured using an M9200 infrared imager. The temperature variation in the billet during the continuous casting process is shown in Figure 5, where the measurements are taken at the center of the arc surface. The predicted temperatures at the center of the inner arc surface show a significant reheating phenomenon in the transition cooling zone, which is caused by the differences in the boundary heat flux density due to different boundary conditions. The measured temperatures at 5.3, 7.6, 13.5, and 15.9 m away from the meniscus are 985 °C, 935 °C, 973 °C, and 941 °C, respectively, and the corresponding simulation results are 986.8 °C, 933.9 °C, 974.1 °C, and 940.2 °C. Thus, the calculated temperatures agree well with the measured ones with a maximum deviation of 1.8 °C, which is negligible compared to the temperature of the billet.
Moreover, the microstructures of continuous casting billets 65# and 60# were simulated and experimentally validated. To evaluate the method’s effectiveness, industrial billet specimens were etched using a picric acid–hydrochloric acid solution, producing low-magnification micrographs (Figure 6b,e). Also, the simulated structures of continuous casting billets from our previous work are displayed as Figure 6c,f, where all dendrites grow perpendicular to the solid wall and we hardly observed a dendrite morphology. Here, the present model can simulate a clear dendrite morphology with not only multi-orientation dendrites but also a secondary dendrite arm, as shown in Figure 6a,d, showing excellent agreement with experimental observations.
To quantitatively analyze the accuracy of this method, we first calculated the ECR at the macroscopic level and the average secondary arm spacing within a selected region at the microscopic level. The structure of the billets has a typical columnar crystal zone and an equiaxed crystal zone, which are distinguished by the average ratio α of the short axis to the long axis [47]. The ECR are calculated using
The ECRs of the microstructure are listed in Table 3, where ECRS is the simulated result, ECRE represents the experimental result, and RE is the relative error between them. It can be concluded that the simulated and experimental ECRs match well with the relative errors of 2.5% and 2.1%.
Moreover, to enhance the observation of microscopic dendrites, circular regions (radius = 6.46 mm) were selected and enlarged in Figure 6. Regions A1 and A2 are positioned 41mm from the upper boundary and 38.5 mm from the left boundary, B1 and B2 are located at a distance of 30.5 mm from the upper boundary and 30 mm from the left boundary, as depicted in Figure 6. It is clear that the dendrite morphologies in the simulation results are not exactly the same as the dendrites in the industry experiment, and these differences arise from natural randomness in both nucleation processes. Therefore, our analysis adopts a statistical comparison approach to compare the simulation result to the experiment result.
The experimental dendrite morphology exhibits a lower clarity compared to the simulations, and there are two main reasons for this. Two primary factors contribute to this: (1) experimental artifacts including localized corrosion defects; (2) image acquisition artifacts introduced during optical microscopy. To improve the clarity of the results, negative film processing and other adjustments were applied to the experimental images.
Comparisons will be conducted from the dendrite distribution and the average secondary arm spacing. Firstly, in the actual casting process, as shown in Figure 7b,d, dendrites are observed to be randomly distributed, lacking any discernible trend or directionality. This randomness can be attributed to the significant variability in nucleation positions and growth orientations. The simulated results, i.e., Figure 7a,c, exhibit a similar pattern of dendrite distribution, which matches well with the experiment result. Secondly, the secondary dendrite arm spacings are measured. For the 65# casting billet, the secondary arm spacing of the simulation result ranges from 273.9 μm to 314 μm with an average value of 291.6 μm, while the experiment result ranges from 280.2 μm to 321.4 μm with the average of 298.6 μm. For the 60# casting billet, the secondary arm spacing of simulation result ranges from 217.1 μm to 228 μm with the average value of 223.4 μm, while the experiment result ranges from 216.2 μm to 225.5 μm with an average of 221.8 μm. The relative errors in the average secondary arm spacing between the simulated and experimental values were 2.3% (65#) and 0.7% (60#). These results demonstrate that the proposed model can reproduce the microstructure of continuous casting billets with detailed dendrite morphologies, which agrees well with the experimental result.
4.2. Performance Analysis
In this section, a series of computation experiments are performed to evaluate the effectiveness of the proposed method. It is worth noting that the block size configured when launching the kernel function has significant impact on the computational performance, since the number of threads in a block generally influences the usage of the on-chip resources. So, before comparing the runtime for any case in this section, we manually adjusted the block size to obtain the optimal configuration for each kernel.
To ensure the computational reliability of the GPU algorithms, we first carry out a comparison of the temperatures calculated between the serial CPU algorithm and the GPU algorithms. Here, we have demonstrated that both GPU algorithms have the same calculation accuracy. Figure 7 depicts the temperature deviations at the center and midface of the billet throughout the continuous casting process, where the maximum difference is 3 × 10^−4^ °C, which can be considered negligible in comparison to the billet’s temperature. So, the temperatures calculated using the serial CPU algorithms and GPU algorithms can be considered to be equivalent.
Then, simulations with 1000 time steps on a different number of grids were executed with three different methods, i.e., the serial CPU algorithm, basic GPU algorithm, and optimized GPU algorithm. Note that the serial CPU algorithm is run on the Intel^®^ Xeon^®^ E5-2680v4 and GPU algorithms are implemented on the Tesla P100. Here, we chose the serial CPU algorithm as the baseline, and define the speedup as the ratio of the runtime on the baseline system to the runtime on the GPU system. In this section, the speedup is utilized to evaluate the computational performance of the GPU algorithms. Figure 8 shows the computational performance, including runtime and speedup. Here, CPU-serial, GPU, and GPU* represent the runtime of the serial CPU serial algorithm, basic GPU algorithm, and optimized GPU algorithm, respectively. Meanwhile, S and S* are the speedup of the basic GPU algorithm and optimized GPU algorithm.
As demonstrated in Figure 9, the runtime increases with the increase in the number of grids in all three algorithms. When the number of grids increases from 5^2^ ten million to 80^2^ ten million, the runtime of the serial CPU algorithm increases steeply from 214 s to 36,229 s, while the runtime of the basic GPU algorithm increases from 0.78 s to 42.74 s, and that of the optimized GPU algorithm increases from 0.55 s to 25.32 s. Moreover, the speedup of both GPU algorithms increases with the increase in the computation domain, and the speedup increases rapidly initially, but the growth rate gradually slows down after turning points “A” and “B”. This is because, as the workload increases, the GPU can more fully utilize its parallel computing capabilities, resulting in a higher speedup. However, as the workload further increases, certain limiting factors, such as memory bandwidth and computational power limitations, may come into play, gradually restricting the growth rate of the speedup. Moreover, simply porting the serial algorithm to a heterogeneous parallel architecture always makes it impossible to fully utilize the GPU resources due to the different memory architectures between CPUs and GPUs. In the optimized GPU algorithms, we improved the memory accessing efficiency by changing the memory accessing way and avoiding warp divergency (Section 3.2), which achieved a performance improvement of about 70% with an increase in speedup from 848× to 1430×. It is fascinating to note that turning point “A” occurs later than “B”. This is because, by increasing memory utilization, the GPU can more effectively utilize its memory bandwidth, reducing the limitations imposed by memory bottlenecks on the growth of speedup. This means that the GPU can handle more data and perform more parallel computations, thereby delaying the decline in the rate of performance improvement. Therefore, by optimizing memory utilization, the occurrence of the turning point can be postponed, allowing the GPU to achieve a better speedup at higher computational workloads.
5. Conclusions
The proposed GPU-accelerated CA-DCSA method achieves a breakthrough performance in simulating the dendritic microstructures of continuous casting billets, with three key advancements:
- (1)Computational efficiency: A 1430× speedup over serial CPU implementations enables microstructure simulations within practical timeframes, overcoming previous computational bottlenecks.
- (2)Morphological accuracy: The model resolves crystal zones, dendrite orientations, and secondary dendrite arm spacing with unprecedented clarity, surpassing prior CA methods in geometric fidelity.
- (3)Industrial validation: Experimental validation on steels 65# and 60# demonstrate robust agreement with measurement, with relative errors < 2.5% for equiaxed crystal ratio, secondary arm spacing, and temperature deviations less than 1.8 °C.
The successful implementation of the GPU-accelerated CA-DCSA method represents a significant advancement in microstructure simulation technology, offering valuable insights for optimizing industrial continuous casting parameters. The combination of computational efficiency and simulation accuracy makes it particularly suitable for practical applications in steel production and process development.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Liss K.D. Garbe U. Li H.J. Schambron T. Almer J.D. Yan K. In Situ Observation of Dynamic Recrystallization in the Bulk of Zirconium Alloy Adv. Eng. Mater.20091163764010.1002/adem.200900094 · doi ↗
- 2Wang T.M. Wei J.J. Wang X.D. Yao M. Progress and Application of Microstructure Simulation of Alloy Solidification Acta Metall. Sin.20185419320310.11900/0412.1961.2017.00428 · doi ↗
- 3Domitner J. Kharicha A. Grasser M. Ludwig A. Reconstruction of Three-Dimensional Dendritic Structures based on the Investigation of Microsegregation Patterns Steel Res. Int.20108164465110.1002/srin.201000083 · doi ↗
- 4Hashemi S. Kalidindi S.R. A machine learning framework for the temporal evolution of microstructure during static recrystallization of polycrystalline materials simulated by cellular automaton Comput. Mater. Sci.202118811013210.1016/j.commatsci.2020.110132 · doi ↗
- 5Dreelan D. Ivankovic A. Browne D.J. Verification of a new cellular automata model of solidification using a case study on the columnar to equiaxed transition previously simulated using front tracking Comput. Mater. Sci.202221511177310.1016/j.commatsci.2022.111773 · doi ↗
- 6Chen Z. Jin Y. Chen H. Hu S. Jiang Y. Wu M. Zhu B. Zhang W. Li W. Cellular automata simulation of pitting corrosion of stainless steel in marine environments Mater. Today Commun.20244111055510.1016/j.mtcomm.2024.110555 · doi ↗
- 7Liu A. Chen M.-S. Chen Q. Lin Y.C. Wang G.-Q. Cai H.-W. Li H.-B. A cellular automata model for recrystallization annealing of aged GH 4169 superalloy and its application Mater. Today Commun.20254211119110.1016/j.mtcomm.2024.111191 · doi ↗
- 8Zhang J. Li X. Xu D. Teng C. Wang H. Yang L. Ju H. Xu H. Meng Z. Ma Y. Phase field simulation of the stress-induced α microstructure in Ti–6Al–4 V alloy and its CPFEM properties evaluation J. Mater. Sci. Technol.20219016818210.1016/j.jmst.2020.12.085 · doi ↗