Variational inference for microbiome survey data with application to global ocean data
Aditya Mishra, Jesse McNichol, Jed Fuhrman, David Blei, Christian L Müller

TL;DR
The paper introduces VI-MIDAS, a statistical framework for analyzing microbiome data, revealing patterns in marine microbial communities and their environmental associations.
Contribution
The novel contribution is the development of VI-MIDAS, a probabilistic modeling framework for joint estimation of microbial taxon associations and environmental covariates.
Findings
Marine microbial communities can be grouped into five modules with distinct environmental signatures.
Positive taxon–taxon associations are found in SAR11 and Rhodospirillales clades.
Negative associations are observed with Alteromonadales and Flavobacteriales classes.
Abstract
Linking sequence-derived microbial taxa abundances to host (patho-)physiology or habitat characteristics in a reproducible and interpretable manner has remained a formidable challenge for the analysis of microbiome survey data. Here, we introduce a flexible probabilistic modeling framework, VI-MIDAS (variational inference for microbiome survey data analysis), that enables joint estimation of context-dependent drivers and broad patterns of associations of microbial taxon abundances from microbiome survey data. VI-MIDAS comprises mechanisms for direct coupling of taxon abundances with covariates and taxa-specific latent coupling, which can incorporate spatio-temporal information and taxon–taxon interactions. We leverage mean-field variational inference for posterior VI-MIDAS model parameter estimation and illustrate model building and analysis using Tara Ocean Expedition survey data.…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
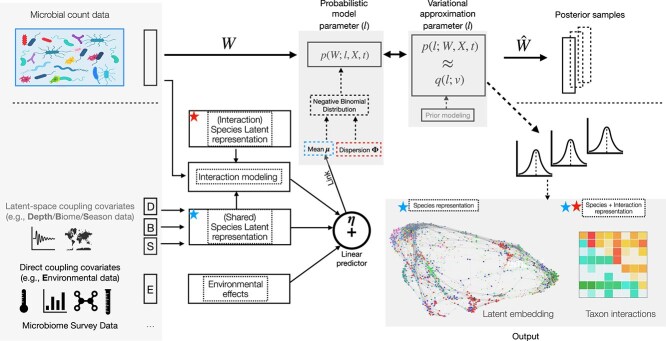 Figure 1
Figure 1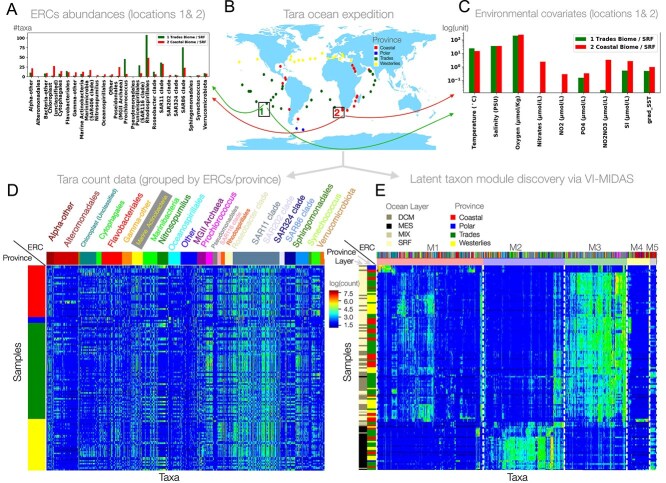 Figure 2
Figure 2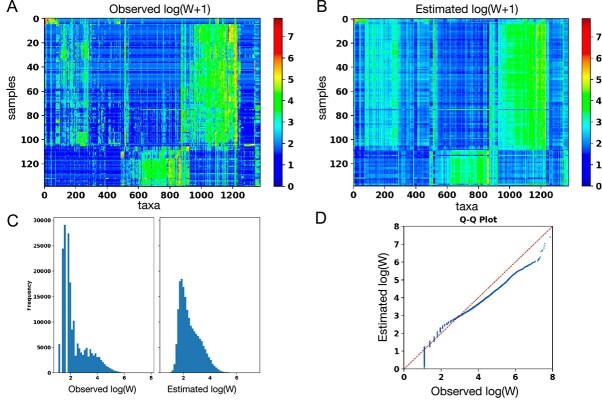 Figure 3
Figure 3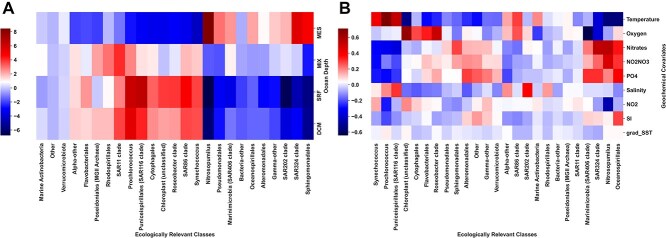 Figure 4
Figure 4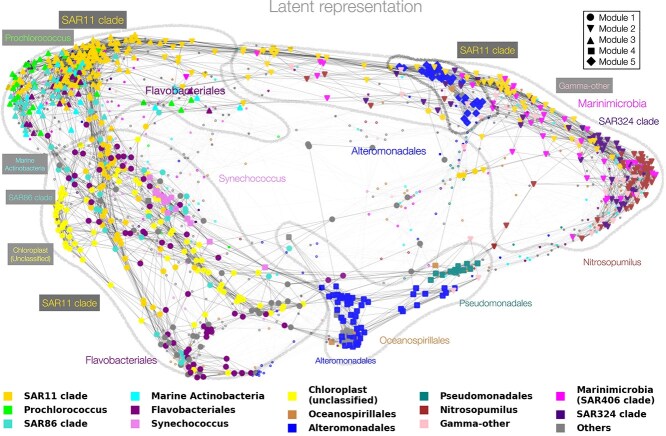 Figure 5
Figure 5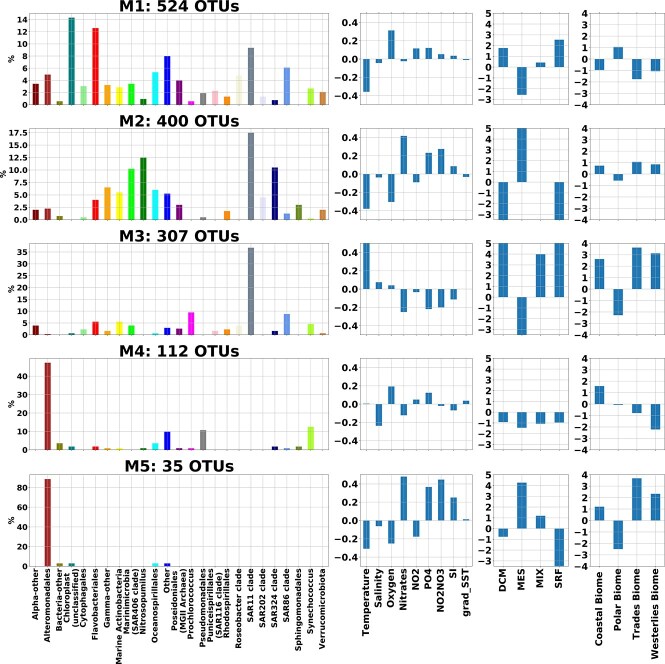 Figure 6
Figure 6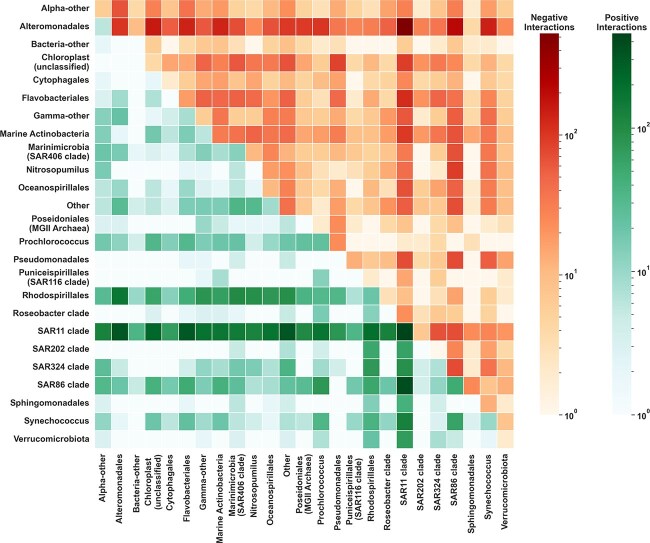 Figure 7
Figure 7| Model component | Variables | Description |
|---|---|---|
| Environmental | Environmental covariates | Sea surface temperature (and its gradient), salinity, chlorophyll, nitrate, nitrogen dioxide, phosphate, silicon, and oxygen concentration. |
| (Depth) | SRF | surface water layer; up to 5 m below the surface |
| Spatial | DCM | Deep chlorophyll maximum; approximately 17–188 m below the surface; region below the surface with maximum chlorophyll concentration |
|
| MIX | Subsurface epipelagic mixed layer; approximately 25–150 m below the surface |
| MES | Mesopelagic zone; approximately 250–1000 m below the surface | |
| Spatial | Polar biome | Polar region in the northern and southern hemisphere characterized by low taxonomic diversity at all trophic levels. |
| (Longhurst Province) | Westerlies biome | High-latitude region below the westerly winds |
|
| Trades biome | Low-latitude region below the easterly trades characterized by high taxonomic diversity |
| Coastal biome | Region in the upper part of the continental slope | |
| Seasonal | Q1, Q2, Q3, Q4 | Derived indicator of seasonal quarter when sample was taken (January to March; April to June; July to September; October to December) |
- —Flatiron Institute, Simons Foundation
- —National Science Foundation10.13039/100000001
- —Office of Naval Research10.13039/100000006
- —Simons Collaboration on Computational Biogeochemical Modeling of Marine Ecosystems
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsGut microbiota and health · Microbial Community Ecology and Physiology · Data-Driven Disease Surveillance
Introduction
Microbial species are an integral part of life on earth. Ecosystems, ranging from the human gut to the global ocean, harbor trillions of bacteria, archaea, viruses, and fungi that take on essential functional roles and have developed intricate ecological relationships within their respective habitat. Over the past decades, advances in amplicon and metagenomics sequencing techniques [1–4] and standardized experimental and bioinformatics workflows [5–7] have enabled the large-scale collection and dissemination of microbial survey data, including those from the seminal Human Microbiome Project [8], several gut-focused surveys [9–12], the Earth Microbiome Project [13], and the Tara Ocean Expedition [14]. These surveys have reached a level of maturity and complexity that ultimately allow the estimation of statistical associations between microbial abundances, typically represented as compositional counts of amplicon sequence variants (ASVs) or operational taxonomic units (OTUs), and habitat properties [14, 15], biogeochemical processes[16], and/or host health status [17, 18]. This, in turn, provides a starting point for deciphering and understanding the ecological and functional roles of different microbial clades in the ecosystem, nutrient and bio(geo)chemical dependencies, resource limitations of microbial growth, and the presence of ecological taxon–taxon interactions [19].
Conventional statistical methods for microbiome data largely focus on either statistical abundance modeling [20–25] or taxon–taxon associations [19, 26–29]. The complexity and interconnected nature of microbial ecosystems would, however, benefit from integrative approaches that go beyond estimating individual statistical associations or taxon–taxon associations. To fully capture the interplay between microbial abundances, host or habitat characteristics, and taxon–taxon interactions, it is essential to estimate their contributions within a unified model.
Here, we introduce such an integrative probabilistic modeling framework that is specifically tailored to microbiome survey data and enables joint estimation of habitat-dependent drivers and broad associations patterns of microbial taxa abundances (see Fig. 1). Our approach, termed VI-MIDAS (variational inference for microbiome survey data analysis), models the observed taxon abundances by simultaneously learning taxon-specific latent representations that leverage the effects of host or environmental factors and taxon–taxon associations via an item-item interaction modeling approach, originally proposed for market basket analysis [30].
Overview of the VI-MIDAS framework. (A) VI-MIDAS integrates microbiome survey data in form of microbial abundance data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}, host-associated, habitat or environmental data, and spatio-temporal information. (B) Different data sources are coupled directly or indirectly through a latent space \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} to a generative model. An additional latent space taxon interaction model is included. The generative probabilistic model (e.g. Negative Binomial (NB) model) integrates covariate data via a coupling model. (C) Variational approximation and mean-field estimation are used for Bayesian parameter estimation, resulting in posterior microbial abundance samples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} and model parameter distributions. (D) Model components, such as estimated latent representation and taxon–taxon interactions, can be used for data understanding, visualization, and downstream analysis.
VI-MIDAS uses the parametric structure of the negative binomial distribution [25, 31] to account for the overdispersed nature of the amplicon count data and comprises two main model components: (i) a component that allows for full adjustment of taxon abundances from a user-defined subset of covariates and (ii) taxa-specific latent vectors that incorporate, e.g. spatio-temporal or environmental covariates and taxon–taxon interactions, thus providing a marginal characterization of each taxon. We resort to mean-field variational inference for parameter estimation of VI-MIDAS’ intractable posterior distribution [32], thus complementing other recent variational approaches to microbiome data modeling, such as, e.g. Poisson principal component analysis [33], microbiome dynamics modeling [34], Dirichlet Multinomial modeling [35], multi-level modeling [36], and microbiome ordination [37].
To illustrate the complete workflow of the VI-MIDAS framework, we focus on integrative analysis of global marine microbiome survey data. The ocean microbiome is of fundamental importance for life on earth, being responsible for about half of all primary production (i.e. the production of chemical energy in organic compounds) and holds enormous potential for climate remediation [38]. Several initiatives such as the Tara Oceans Project [39] and the Simons CMAP [40] provide well-structured sequencing data, biogeochemical and environmental covariate data, and satellite-derived products that are amenable to statistical analysis. Here, we re-analyze Tara expedition data (http://ocean-microbiome.embl.de/companion.html), originally considered in [14] to study the structure and function of the global ocean microbiome. The expedition collected ocean water samples from 68 distinct geographical locations at varying levels of depth. We will make extensive use of this dataset to motivate and describe the details of the VI-MIDAS framework as well as the learned representations and associations of the global ocean microbiome.
We start with an overview of the Tara Oceans data under study, introduce the generative model components of VI-MIDAS, and show how different data types enter the modeling framework. We then give a high-level overview of the variational parameter estimation procedure, including the selection of VI-MIDAS’ hyperparameters, such as the choice of the priors and the dimensionality of the latent representation. Following model parameter inference, we illustrate how standard modularity analysis of VI-MIDAS’ learned latent representation of the Tara data identifies five distinct groups of microbial consortia. We analyze the inferred modules in terms of their composition of ecologically relevant clades and discuss the derived module-specific environmental and spatiotemporal signatures. Finally, we highlight the emerging interaction pattern among ecologically relevant clades and discuss the framework in the larger context of other microbiome survey data. Further methodological details are summarized in Supplemental material. Code for the presented VI-MIDAS workflow is available at http://github.com/amishra-stats/vi-midas) and requires minimal adjustment to analyze other microbiome survey data.
Materials and methods
Tara ocean data and ecologically relevant taxa re-classification
We consider the processed Tara expedition data, as provided at http://ocean-microbiome.embl.de/companion.html. The expedition collected water samples from 68 distinct geographical locations (Fig. 2B) across different depths, resulting in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} n=139\end{document} distinct samples. Across these samples, the original data comprises microbial taxa abundances profiles of more than 35 000 bacterial taxa in form of metagenomic OTUs (mOTUs) (derived using the miTAGS framework [41]).
Illustration of the Tara ocean data: (A) Taxon abundance profiles, agglomerated to expert-derived ERCs for two samples (marked as 1 and 2 in Fig. 2B). (B) Tara ocean sample locations. (C) Environmental features associated with the samples marked as 1 and 2 in Fig. 2B; (D) Abundance profiles \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} taxa at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} distinct locations with rows highlighting province of the sample and columns grouped by ERC. (E) Abundance profiles clustered into five modules (M1–M5) as identified by modularity analysis of the latent space \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} (see Section Modularity analysis for more details). The dashed vertical lines separate the latent modules. The five microbial modules (M1–M5) comprise 524, 400, 307, 112, and 35 taxa/OTUs, respectively. The first column shows ocean depth layer, the second column the province indicator.
Here, we focus on the most abundant taxa by taking the union of all mOTUs that, in each individual sample, contribute to 40% of the total library size. This filtering allows us to cover the abundance profiles of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q = 1378\end{document} taxa with the most significant variability and reduces the number of excess zero counts. To account for the highly variable sequencing depth across the samples, we normalize the abundance data with respect to the lowest library size via common-sum scaling [31]. Fig. 2D shows the log-transformed abundance profiles \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{W} \in \mathbb{R}^{n \times q}\end{document} . Since the original taxonomic affiliations of the miTAGS are difficult to interpret, we next developed a partitioning of the selected taxa into ecologically relevant classes (ERCs). The original full taxonomy strings are too long to understand at a glance, and parsing by taxonomic level is not a good option since taxa vary widely in the depth of their annotations. For example, cyanobacteria should be annotated at the genus level or higher, but many other abundant but less described taxa do not have any taxonomic information at that level. We manually curated the data to provide a short relevant taxonomic indicator that provides a rough indicator of the ecological niche of an organism while remaining short enough to be interpreted at a glance [42]. Some taxonomies have been altered to preserve the updated SILVA taxonomy (i.e. Betaproteobacteria is now Burkholderiales). New SILVA 138 [43] taxonomies have been used wherever possible (i.e. when the original ID was still in SILVA 138), but in cases where there was only the SILVA 108 taxonomic information, we have used our best guess. For example, if an organism had the same classification as other organisms in SILVA 108, we have often given it the same name as its counterparts in SILVA 138. We present all our findings in terms of these 29 ERCs.
Each Tara sample also contains environmental and spatiotemporal information, including geolocation, the derived Longhurst province (biome) indicator, sampling date, ocean depth information (depth from sea surface), environmental covariates, such as, e.g. sea surface temperature (SST), and biogeochemical features such as salinity, chlorophyll, nitrate, and oxygen concentration (see Fig. 2C for illustration). Table 1 summarizes the measured covariates and derived spatiotemporal indicator variables that are included in the VI-MIDAS framework and their corresponding mathematical representation.
Generative modeling in VI-MIDAS
We seek to model the abundance profiles of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q\end{document} microbial taxa where we denote a single sample by the random variable \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{w} \in \mathbb{R}^{q}\end{document} and the observed data from \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} n\end{document} samples by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{W} = [w_{ij}]_{n \times q} \in{\mathbb{R}}^{n \times q}\end{document} . For concreteness, we illustrate model building and analysis using the Tara abundance profiles (see Fig. 2D) of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q = 1378\end{document} taxa but the modeling strategy is applicable to any multimodal microbiome survey.
Distributional model
VI-MIDAS posits that the overdispersed microbial count data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{W}\end{document} are reasonably well modeled with the negative binomial distribution [18, 44, 45]. While other generative statistical modeling approaches are available, including the Dirichlet Multinomial (mixture) framework [20, 46], latent Dirichlet allocation [47], and Poisson distribution models [21, 24, 48], we found the negative binomial model to be an excellent choice for the Tara ocean data (see Fig. S1 B of the Supplementary material for the over-dispersion analysis). Using the negative binomial distribution with mean and dispersion parameterization [44], VI-MIDAS models the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} j\end{document} th taxa in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} th sample as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} &p(w_{ij}; \tau_{j} \mu_{ij}, \phi_{j}) = \text{NB}(w_{ij}; \tau_{j} \mu_{ij}, \phi_{j}) \notag \\ &= {w_{ij} + \phi_{j} -1 \choose w_{ij}} \Bigg( \frac{\tau_{j} \mu_{ij}}{\tau_{j} \mu_{ij} + \phi_{j}}\Bigg)^{w_{ij}} \Bigg(\frac{\phi_{j}}{\tau_{j} \mu_{ij} + \phi_{j}}\Bigg)^{\phi_{j}}.\end{align*}\end{document}Here, the mean parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \tau _{j} \mu _{ij}\end{document} is the product of a taxon-specific shape parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \tau _{j} \in (0,1)\end{document} and the entry-specific parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mu _{ij} \in \mathbb{R}^{+}\end{document} . The parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \phi _{j} \in \mathbb{R}^{+}\end{document} is the taxon-specific dispersion parameter. Let us denote the dispersion and shape parameters for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q\end{document} outcomes by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \Phi = [\phi _{1}, \ldots , \phi _{q}]\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \tau = [\tau _{1},\ldots ,\tau {q}]\end{document} , respectively. The shape parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \tau \end{document} accounts for the disparity in abundance among microbial taxa. The generative model (1) of VI-MIDAS implies \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \operatorname{{\mathbb{E}}}(w{ij}) = \tau _{j} \mu {ij}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathrm{Var}(w{ij}) = \tau _{j} \mu _{ij} + \frac{\tau _{j}^{2} \mu _{ij}^{2}} {\phi _{j}}\end{document} . This variance structure reflects the overdispersion characteristic of the negative binomial distribution , making this framework well-suited for modeling overdispersed count data.
Modeling strategy and model components
One novelty in VI-MIDAS is the combination of ideas from generalized linear modeling [44] and compositional data analysis [49] to associate the microbial relative count data with spatiotemporal, environmental, and taxa information. Specifically, we model the log-transformed mean parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \mu = [\mu {ij}]{n \times q}\end{document} of the generative model (1) with two components, a consistent zero-aware geometric mean estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} t_{i}\end{document} and a linear predictor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \eta = [\eta {ij}]{n \times q} \in \mathbb{R}^{n \times q}\end{document} as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} \log{\mu_{ij}} = \log{t_{i}} + \eta_{ij} \,.\end{align*}\end{document}The sample-wise parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} t_{i}\end{document} is estimated by a zero-aware geometric mean estimator, introduced in [50], which provides a principled approximation to the geometric means across all \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} n\end{document} samples in the presence of excess zeros. We detail the exact formulation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} t_{i}\end{document} and its approximation guarantees in Section 3.1 of the Supplementary material. Including \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{O} = [\log t_{1}, \ldots , \log t_{n}]\end{document} as an offset term in the model is necessary since we do not have access to absolute microbial abundance data, thus requiring transforming the compositional data appropriately. The second term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \eta \end{document} effectively models centered log-ratio (clr) transformed (rather than the original count) data and is the key component to couple habitat (or host) information to the microbial abundance profiles. VI-MIDAS introduces a novel decomposition of the component \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \eta \end{document} that allows the incorporation of three distinct coupling mechanisms: (i) a direct coupling term for covariates, (ii) an indirect coupling term for covariates via a latent space representation, and (iii) a latent taxon–taxon interaction term.
In our ocean application, the first component, denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \eta _{ij}^{[E]}\end{document} , includes all relevant environmental attributes (see first row in Table 1). All spatiotemporal features, i.e. the Longhurst province indicator, the depth information, and the seasonal indicator (see second to last row in Table 1) are handled by the latent coupling term and are denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \eta _{ij}^{[P]}\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \eta _{ij}^{[D]}\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \eta _{ij}^{[S]}\end{document} , respectively. Lastly, statistical associations among co-occurring taxa are included via a latent interaction term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \eta _{ij}^{[I]}\end{document} , leading to following model:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} \eta_{ij} = \eta_{ij}^{[E]} + \left(\eta_{ij}^{[P]} + \eta_{ij}^{[D]} + \eta_{ij}^{[S]}\right) + \eta_{ij}^{[I]} \,.\end{align*}\end{document}The following paragraphs detail the parametric form of each of the components, the nature of the underlying covariate data, and their biological relevance.
Direct coupling of environmental features
Let us denote the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p\end{document} covariates in the direct coupling term by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{X} = [\mathbf{x}{1}, \ldots , \mathbf{x}{n}]^{\mathrm{T}} =[x_{ij}]_{n \times p}\end{document} . VI-MIDAS models the direct component for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} j\end{document} th taxa in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} th sample via
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} \eta_{ij}^{[E]} = \mathbf{x}_{i}^{\mathrm{T}}\boldsymbol\gamma_{.j} \,.\end{align*}\end{document}with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \gamma = [\gamma {ij}]{p \times q} \in \mathbb{R}^{p \times q}\end{document} denoting the matrix of all coefficients. For the Tara data, we opted to model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \eta _{ij}^{[E]}\end{document} using following \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p=9\end{document} covariates: sea surface temperature (SST) (and its gradient grad SST), salinity, chlorophyll, nitrate, nitrogen dioxide, phosphate, silicon, and oxygen concentration. All variables are mean-centered prior to incorporation into the model. In the original Tara analysis [14], temperature and oxygen have been identified as key drivers of taxonomic compositions. The VI-MIDAS analysis will allow a refined picture of the these general tendencies.
Latent space coupling of spatiotemporal features
VI-MIDAS offers a second mechanism for including variables of interest through latent space modeling. We denote \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q\end{document} taxa-specific shared latent variables of size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k\end{document} by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \beta = [\beta {ij}]{k \times q} \in \mathbb{R}^{k \times q}\end{document} . The size factor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k\end{document} is an application-specific hyper-parameter that controls the expressiveness of the latent space. Features are then coupled to the latent space in a multiplicative fashion.
For the Tara data, we illustrate this mechanism by coupling all available spatial and temporal indicators to the latent space component. We first consider the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} r = 4\end{document} primary provinces (or biomes): polar, Westerlies, coastal, and Trades [51]. We denote the model matrix indicating the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} r\end{document} distinct regions of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} n\end{document} samples by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{R} = [\mathbf{r}{1}, \ldots , \mathbf{r}{n}]^{\mathrm{T}} \in {0,1}^{n \times r}\end{document} . Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{r}{i}\end{document} is a one-hot encoded vector, indicating membership of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} -th sample to one of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} r\end{document} provinces. The matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{R}\end{document} connects to the joint latent space via the coefficient matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\boldsymbol \alpha } = [\alpha ]{r \times k} \in \mathbb{R}^{r \times k}\end{document} , leading to
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} \eta_{ij}^{[P]} = \mathbf{r}_{i}{\boldsymbol\alpha} \boldsymbol\beta_{.j} \,.\end{align*}\end{document}Similarly, the Tara data include samples across \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} d = 4\end{document} ocean depths: surface water (SRF), deep chlorophyll maximum (DCM), the subsurface epipelagic mixed layer (MIX), and the mesopelagic zone (MES). We denote the depth indicator matrix of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} n\end{document} samples by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{D} = [\mathbf{d}{1}, \ldots , \mathbf{d}{n}]^{\mathrm{T}} \in {0,1}^{n \times d}\end{document} ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{d}{i}\end{document} is one-hot encoded vectors representing membership of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} -th sample in one of d ocean depth) and connect it to the joint latent space via the coefficient matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \delta = [\delta ]{d \times k} \in \mathbb{R}^{d \times k}\end{document} , leading to
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} \eta_{ij}^{[D]} = \mathbf{d}_{i}\boldsymbol\delta \boldsymbol\beta_{.j} \,.\end{align*}\end{document}Finally, by parsing the sampling dates at the different Tara locations, we can associate a temporal indicator with each sample. Here, we group the samples into \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} s = 4\end{document} seasons: the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 1^{st}\end{document} (Q1, January to March), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 2^{nd}\end{document} (Q2, April to June), \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 3^{rd}\end{document} (Q3, July to September), and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 4^{th}\end{document} (Q4, October to December) yearly quarter, and construct the season indicator matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{S} = [\mathbf{s}{1}, \ldots , \mathbf{s}{n}]^{\mathrm{T}} \in {0,1}^{n \times s}\end{document} , where each row \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{s}{i}\end{document} represents the membership of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} th sample to one of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} s\end{document} seasonal categories. The coefficient matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \vartheta = [\vartheta ]{s \times k} \in \mathbb{R}^{s \times k}\end{document} couples \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{S}\end{document} to the latent space \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \beta \end{document} , leading to
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} \eta_{ij}^{[S]} = \mathbf{s}_{i}\boldsymbol\vartheta \boldsymbol\beta_{.j}\,.\end{align*}\end{document}In summary, the coupling of the described features to a shared latent space via the coefficient matrices \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\boldsymbol \alpha }, \boldsymbol \delta , \boldsymbol \vartheta \end{document} allows to quantify to what extent spatiotemporal information influences each taxon’s (latent) abundance after discounting the contribution of the environmental component.
Latent modeling of taxon–taxon associations
It is well-established that the abundances of species in an ecosystem are not only driven by environmental or spatiotemporal factors but also by interactions among the species themselves [52]. While discovering detailed ecological interactions among taxa, such as, e.g. competition, mutualism, parasitism, or commensalism, is beyond the reach of coarse-grained statistical models, VI-MIDAS’ latent space modeling offers a principled mechanism to assess the influence of taxa co-occurrences on their respective abundances. We achieve this by borrowing recent ideas from market basket analysis and adopt the so-called SHOPPER utility model for interaction analysis [30]. In SHOPPER, Ruiz et al. [30] proposed a probabilistic model based on the basket data from a supermarket to learn about the latent characteristic of each item and exchangeable/complementary interactions among items. The approach uses item-specific latent variables to define an item–item interaction component. Following their setup, the “interaction,” or, in the biological context, association of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} j\end{document} th taxa with any \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} m\end{document} th taxa is given by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \rho _{.j}^{\mathrm{T}}\boldsymbol \beta {.m}\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \rho = [\rho ]{k \times q} \in \mathbb{R}^{k \times q}\end{document} comprises length- \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k\end{document} latent variables for each of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q\end{document} taxa. The entries of VI-MIDAS’ interaction component \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \eta ^{[I]}\end{document} for the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} j\end{document} th taxon in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} th sample are thus given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& \eta_{ij}^{[I]} = \begin{cases} 0, & w_{ij} = 0 \\ \frac{1}{a_{i}-1}\boldsymbol\rho_{.j}^{\mathrm{T}} \sum_{m \neq j} \mathbf{1}_{{w}_{im}\neq 0} \boldsymbol\beta_{.m}, & w_{ij} \neq 0 \end{cases},\end{align*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} a_{i} = \sum {m = 1}^{q} \mathbf{1}{{w}{im} \neq 0}\end{document} is the total number of taxa present in the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} th sample. Note that the interaction term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \rho ^{\mathrm{T}}\boldsymbol \beta \end{document} is not symmetric. Note that, while some ecological interactions, such as parasitism, are directed and asymmetric, thus making asymmetry biologically plausible, the model parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \rho \end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \beta \end{document} do not allow to estimate directionality. Consequently, following the SHOPPER model [30], we derive a symmetrized interaction matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{I} = [I{i,j}] \in \mathbb{R}^{q \times q}\end{document} with each entry being computed as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*}& I_{i,j} = \left(\boldsymbol\rho_{\cdot i}^{\mathrm{T}} \boldsymbol\beta_{\cdot j} + \boldsymbol\rho_{\cdot j}^{\mathrm{T}} \boldsymbol\beta_{\cdot i} \right)/2\end{align*}\end{document}This allows easier downstream network analysis of potentially positive (mutualistic) and negative (competitive) associations among the taxa, or in our case, among the ecologically relevant clades.
Variational inference in VI-MIDAS
The generality and flexibility of VI-MIDAS poses a considerable challenge for fast and accurate model parameter estimation. We introduce a variational inference framework that makes estimation in VI-MIDAS feasible and illustrate its performance and parameter sensitivities using the Tara data. For ease of presentation, we summarize the key ingredients below and refer to the extensive Supplementary information and the documented code base available at https://github.com/amishra-stats/vi-midas) for details.
Bayesian model and variational approximation
We begin by denoting all (latent) parameters in the VI-MIDAS framework by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \ell = { \boldsymbol \alpha , \boldsymbol \vartheta , \boldsymbol \beta , {\boldsymbol \gamma }, \boldsymbol \rho , \boldsymbol \tau , \boldsymbol \Phi }\end{document} (see Table S1 of the Supplementary material). Given the microbial abundance data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{W}\end{document} , the (direct) covariates \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{X}\end{document} , and the model parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \ell \end{document} , we integrate the generative model (1) into a Bayesian framework where the posterior distribution reads:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} p(\boldsymbol\ell; \mathbf{W}, \mathbf{X}, \mathbf{t}) = \frac{p(\mathbf{W}; \boldsymbol\ell, \mathbf{X}, \mathbf{t}) p(\boldsymbol\ell)}{p(\mathbf{W}; \mathbf{X}, \mathbf{t})},\end{align*}\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p(\mathbf{W}; \boldsymbol \ell , \mathbf{X}, \mathbf{t}) = \prod {i,j} p(w{ij}; \tau _{j} \mu _{ij}, \phi _{j})\end{document} denotes the likelihood of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{W}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p(\boldsymbol \ell ) = p({\boldsymbol \alpha })p(\boldsymbol \delta )p(\boldsymbol \beta )p({\boldsymbol \gamma })p(\boldsymbol \rho ) p(\boldsymbol \Phi )p(\boldsymbol \tau ) p(\boldsymbol \vartheta )\end{document} the prior distribution, respectively. To achieve good generalizabilty and interpretability of VI-MIDAS’ over-parameterized model, we place sparsity-inducing Laplace priors with scale parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \lambda \end{document} on each of the unconstrained latent variables in the set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\boldsymbol \alpha , \boldsymbol \delta , \boldsymbol \beta , \boldsymbol \gamma , \boldsymbol \rho , \boldsymbol \vartheta }\end{document} . For example, the prior on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\boldsymbol \alpha }\end{document} reads \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p({\boldsymbol \alpha }) = \prod _{i,j}p(\alpha _{ij})\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p(\alpha _{ij}) = \text{Laplace}(0, \lambda )\end{document} . Furthermore, we place an inverse-Cauchy prior on the dispersion parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \Phi \end{document} , i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p(\phi _{j}) = \text{inverse-Cauchy}(0,\upsilon )\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p(\boldsymbol \Phi ) = \prod _{j} p(\phi _{j})\end{document} , and a Uniform (1,2) prior for the shape parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \tau \end{document} , i.e. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \tau _{j} \sim \text{Beta(1,1)}\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p(\boldsymbol \tau ) = \prod _{j}p(\tau _{j})\end{document} . Choosing suitable hyperparameters for the priors will be discussed below.
In the high-dimensional setting, computing the posterior distribution is challenging because of the intractable form of the marginal distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} p(\mathbf{W}; \mathbf{X}, \mathbf{t})\end{document} and the non-conjugate priors on the model parameters. Markov Chain Monte Carlo (MCMC) sampling provides a helpful paradigm for obtaining samples from the posterior distribution in the Bayesian framework. However, since MCMC lacks computational efficiency in large/high-dimensional problems, we use mean-field Variational Inference (VI) [32, 53, 54] and approximate the posterior with a variational posterior distribution of the latent variable \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \ell \end{document} . Briefly, let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q(\boldsymbol \ell ;\boldsymbol \nu )\end{document} be the variational posterior distribution with parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \nu \end{document} . VI approximates sampling of the posterior by minimizing the Kullback-Leibler (KL) divergence,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} \min_{\boldsymbol\nu}\,\,\text{KL}(q(\boldsymbol\ell;\boldsymbol\nu) \, ||\, p(\boldsymbol\ell; \mathbf{W}, \mathbf{X}, \mathbf{t})) \end{align*}\end{document}such that \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \text{supp}(q(\boldsymbol \ell ;\boldsymbol \nu )) \subseteq \text{supp}(p(\boldsymbol \ell ; \mathbf{W}, \mathbf{X}, \mathbf{t}))\end{document} . It can be shown that the above optimization problem simplifies to maximizing the evidence lower bound (ELBO) given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{align*} {\mathcal{L}}(\boldsymbol\nu) &= \mathbb{E}_{q(\boldsymbol\ell;\boldsymbol\nu)}[\log{P(\mathbf{W}, \boldsymbol\ell; \mathbf{X}, \mathbf{t})}] - \mathbb{E}_{q(\boldsymbol\ell;\boldsymbol\nu)}[\log{q(\boldsymbol\ell;\boldsymbol\nu)}],\end{align*}\end{document}which is a lower bound on the logarithm of the joint probability of the observations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \log{P(\mathbf{W}; \mathbf{X}, \mathbf{t})}\end{document} [53]. Replacing the joint distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} P(\mathbf{W}, \boldsymbol \ell ; \mathbf{X}, \mathbf{t}) \end{document} with a product of likelihood and prior distribution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} P(\mathbf{W}, \boldsymbol \ell ; \mathbf{X}, \mathbf{t}) = P(\mathbf{W} ; \boldsymbol \ell , \mathbf{X}, \mathbf{t}) P(\boldsymbol \ell )\end{document} further simplifies the objective.
Model estimation, hyperparameter tuning, and posterior estimates
The non-convexity of the variational objective and the large number of model parameters require careful assessment of all aspects of model parameter estimation, hyperparameter tuning, and generalization capability. To estimate the parameters of the variational posterior distribution, we employ stochastic gradient descent within the automatic differentiation variational inference (ADVI) framework [55]. The key steps of ADVI are outlined in Algorithm 1 of the Supplementary material. A prerequisite for model parameter estimation is the identification of suitable model hyperparameters. In VI-MIDAS, the key hyperparameters are the scale of the sparsity-inducing Laplace prior, the scale of the inverse-Cauchy prior, and the intrinsic dimensionality \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k\end{document} of the latent space \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \beta \end{document} , respectively. VI-MIDAS tunes these parameters via random search (see Section 3.3 of the Supplementary material for details) where the out-of-sample log-likelihood posterior predictive density (LLPD) is used for assessing optimality of the hyperparameters [56]. Due to the non-convexity of the objective and the use of stochastic optimization in VI initialization, we further evaluate the suitability of hyperparameter setting across fifty random initializations and select the hyperparameter set leading to the best averaged LLPD (see Section 3.5 of the Supplementary material). The computational workflow is implemented in Python using the probabilistic programming language Stan [57] and is available in the GitHub repository (https://github.com/amishra-stats/vi-midas).
After hyperparameter tuning, we re-estimate the final model parameters on complete data. VI-MIDAS generates \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} m = 100\end{document} posterior samples of each of the latent variables in the set \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \ell \end{document} and estimates the model parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \ell \end{document} using the mean of the samples from the variational posterior distribution. The model fit is numerically evaluated using the posterior predictive check [56, 58] on the full data. The procedure requires generating \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} m\end{document} posterior samples, denoted by the random variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\mathbf{W}}^{rep} = [{w}{ij}^{rep}] \in \mathbb{R}{+}^{ n \times q} \end{document} , and then computing the p-value of the model fit as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \text{p-value}:=p(t({\mathbf{W}}^{rep}) < t(\mathbf{W})),\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} t\end{document} is the test statistic. In practice, we use the test statistics \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} t({\mathbf{W}}^{rep}) = \mathbf{E}(\log{p({\mathbf{W}}^{rep}|\boldsymbol \ell )})\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} t({\mathbf{W}}) = \mathbf{E}(\log{p({\mathbf{W}}|\boldsymbol \ell )})\end{document} .
Results
VI-MIDAS recapitulates broad statistical patterns of the observed species abundances
VI-MIDAS’ hyperparameter tuning revealed that the setting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k=200\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \lambda = 0.246\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \nu =0.10063\end{document} achieved the highest average LLPD of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} 3.332\end{document} on the Tara data (see Fig. S7 in Supplementary material). For this setting, a posterior predictive check on the generated samples achieved a \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {{P}-\mathrm{value}} = 0.53\end{document} . We thus fail to reject the null hypothesis that the posterior samples are different from the observed \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{W}\end{document} . Figure 3A and 3B shows the observed and estimated abundance profiles (averaged over \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} m=100\end{document} samples), respectively. Fig. 3C shows the count histograms of data and model (pooled across all samples and species), and Fig. 3D shows the Q–Q plot. We observe that, apart from the low-abundance tail of the distribution, VI-MIDAS broadly recapitulates the statistical abundances patterns across all samples and species.
Comparison of observed abundances and VI-MIDAS posterior samples: (A) Heatmap showing the abundance profile \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} of 1378 species for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} samples. (B) Expected value of the abundance using the hyperparameter corresponding to best model fit. (C) Histograms of observed and estimated species abundances. (D) Q–Q plot comparing the observed and estimated abundance profile of the species.
VI-MIDAS identifies depth and environmental features as main drivers
We next assessed the contribution of each model component toward explaining the species abundance patterns in the Tara data. The modularity of the VI-MIDAS framework facilitates an “ablation” study (see Section 3.4 of the Supplementary material) where each model component is excluded, followed by a re-evaluation of the out-of-sample LLPD. Table S4 (see Supplementary materials) shows the LLPDs of the full model and the model after ablation of the environmental (E), province (P), ocean depth (D), seasonality (S), and latent interaction (I) component, respectively.
Firstly, the ablation study confirmed that all components helped improve model generalization since every ablated model has reduced out-of-sample LLPDs. While the seasonality component(S) shows comparatively little influence on explaining the abundance pattern in the current model, as previously observed for this dataset [14], the out-of-sample LLPD is reduced the most when the ocean depth (D) component is ablated (LLPD = –3.3882). This reflects the well-known depth stratification of marine species between the sunlit ocean and aphotic deep ocean ecosystems. Figure S4 in Supplementary material illustrates the learned depth stratification across all taxa, as reflected in the component \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \delta \boldsymbol \beta \end{document} . The environmental component was identified as the second most important component with an LLPD reduction of -3.3554.
Figure 4 summarizes the estimated effects \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\boldsymbol \delta }\boldsymbol \beta \end{document} of the ocean depth features and the environmental effects \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\boldsymbol \gamma }\end{document} on the abundance of species aggregated into ERCs, respectively. The ocean depth summary (Fig. 4A) reveals three distinct sets of occurrence patterns for two different groups of ERCs. One group (right most in Fig. 4A) comprises ERCs such as Nitrosopumilius, Pseudomonadales, SAR 324 clade, and Sphingomonadales which thrive in the Mesopelagic (MES) zone. A second group includes species like Prochlorococcus, SAR 116 clade, and Synechococcus, which flourish within the ecosystem of the ocean’s deep chlorophyll maximum (DCM) and surface mixed layer (SRF) zones. The third group comprises marine Actinobacteria, Verrucomicrobiota, and others that show no dependence on depth. A summary of geochemical features highlights temperature (the top row in Fig. 4B) as the primary positive factor influencing the abundance of Synechococcus, Prochlorococcus, and Puniceispirillales (SAR116 clade). Oxygen concentration emerges as the main positive driver of abundance for Cytophagales, Flavobacteriales, and Roseobacter clades, while Nitrates, Nitrites, and Phosphate are identified as key drivers for the SAR324 clades, Nitrosopumilus, and Oceanospirillales (four right most columns in Fig. 4B). The estimated patterns broadly recapitulate known biology about ocean microbial ecosystems.
Summary of the estimated average effect sizes of the influence of (A) ocean depth (VI-MIDAS model component \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}) and (B) environmental covariates (VI-MIDAS model component \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}) on all ERCs.
VI-MIDAS reveals five latent microbial sub-communities
The generative model (1) of VI-MIDAS includes the taxon-specific latent variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \beta \in{\mathbb{R}}^{k \times q}\end{document} to integrate spatiotemporal features and taxon–taxon associations. For the Tara data, VI-MIDAS’ hyperparameter tuning scheme identified \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k = 200\end{document} as best latent dimension. After model estimation, the resulting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k-\end{document} dimensional latent vectors can be thought of as representing the hidden marginal characteristics of each of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q\end{document} taxa after discounting spatiotemporal and species-species association effects, and adjusted for environmental covariates. The latent space representation thus provides an excellent opportunity to partition the different taxa into coherent sub-groups (or modules) that likely reflect functionality or niche occupation in the global ocean, independent of environmental, taxonomic or phylogenetic relatedness.
To quantify similarity between microbial taxa in the latent space, we first computed cosine distances of all pairs of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q\end{document} latent vectors. This particular choice of distance allows us to bypass the non-identifiability issue of the parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \beta \end{document} . We used the resulting distance matrix to construct a k-nearest neighbors graph ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k_{\text{nn}} = 10\end{document} ). Figure 5 shows the latent space embedding using a force-directed layout of the k-nn graph. We next performed Clauset-Newman-Moore greedy modularity analysis of the nearest neighbor graph [59] and identified five distinct modules in the latent space (see M1-M5 in Fig. 5 with top five ERCs highlighted and color-coded). The latent space representation reveals several distinct microbial sub-communities, dominated by a few ERCs, including one sub-community dominated by Prochlorococcus and SAR11 clades and one dominated by Nitrosopumilus. Module 1 (M1) comprises Flaviobacteriales, SAR86 clades, and the Chloroplast class. SAR11 clade, SAR86 clade, and Flavobacteriales are heterotrophs with functional similarity in oxidizing carbon in the ocean [60]. Both SAR86 clade and SAR11 clade follow a similar seasonal pattern (in the Bermuda Atlantic Time Series oceanographic stations) and coexist in oligotrophic regions with less nutrient supply [61]. Module 2 (M2) includes Nitrosopumilus, Marinimicrobia, and SAR324 clades. Existing literature supports that SAR11 clade (a subgroup of a species), Marinimicrobia, and MGII Archaea are more abundant in deep sea water [62]. Module 3 (M3) comprises Prochlorococcus, SAR11, Marine Actinobacteria, and SAR86 clades, among others, all comprising dominant taxa of the sunlit ocean. The two smallest modules 4 and 5 (M4 and M5, respectively) are dominated by Alteromonadales and are separating M2 from M1 and M3. Interestingly, Module 4 also comprises Synechococcus species. This module thus hints at the known metabolic dependency of certain Alteromonadales taxa on Synechococcus (a photoautotroph) [63]. Although the latent representation does separate the majority of ERCs into distinct subgroups, we nonetheless observe that taxa of certain ERCs are spread out over the latent space, indicating different niche specialization. For instance, the SAR11 clade, one of the most abundant marine microbial taxa, is present in three different modules. Likewise, taxa in the SAR86 clade are present in both modules M1 and M3. For ease of identification, Table S3 in Supplementary material summarizes each module in terms of the composition of the ERCs and their abundance.
Low-dimensional embedding of the latent representation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} using a k-nearest-neighbor (\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}) graph of cosine distances. Modularity analysis reveals five distinct graph modules. We highlight 825 out of a total of 1378 taxa, comprising the top five ERCs in each of the five modules (see main text for further information).
Global associations between biogeography and latent microbial sub-communities
VI-MIDAS’ integrative model also enables a quantitative description of the identified microbial sub-communities in terms of the direct and indirect coupling covariates. Figure 6 illustrates how the compositions of ERCs in each of the five modules are related to the most important environmental and spatial covariates.
Global associations between biogeography and covariates: each row presents the average effect size of the association between the microbial abundances of taxa in a module (M1–M5) to the geochemical features and ocean depth (from left to right). A module (leftmost) is shown as the composition (in %) of the ERCs. Each module comprises different number of taxa {524, 400, 307, 112, 35}, respectively. Modules M1–M3 cover the majority of taxa, and M4–M5 two smaller Alteromonadales-dominated sub-communities.
Using the mean of the posterior sample from the VI-MIDAS model, we used the estimated \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\boldsymbol \gamma }\end{document} as the effect sizes of the environmental features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{X}\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \delta \boldsymbol \beta \end{document} as effect sizes of depth, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \alpha \boldsymbol \beta \end{document} as the effect sizes of the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} r\end{document} provinces, respectively Figure 6 reports the average effect sizes of association to the four modules.
The module M1 represents taxa coexisting in the SRF and DCM zone of the ocean. The abundance of taxa in the module is associated with a higher concentration of oxygen, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \text{PO}{4}\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \text{NO}{2}\text{NO}_{3}\end{document} and lower temperature and salinity. In addition to representing the taxa SAR11 clade, SAR86 clade, Chloroplast, and Flavobacteriales, the module also includes Synechococcus, Oceanospirillales, and Poseidoniales. Synechococcus is a unicellular prokaryotic autotrophic picoplankton that participates in the marine ecosystem as a primary producer via photosynthesis. Similarly, Chloroplast sequences are a signature of eukaryotic phytoplankton, though their host eukaryote is not identified in the TARA Oceans dataset. The presence of both taxa in M1 thus is consistent with environments that have higher oxygen concentrations due to photosynthesis and gas exchange with the atmosphere.
Module M2 mainly represents the species coexisting in the MES zone (200–1000 m) of the ocean (see Fig. 2(E)). M2 almost exclusively represents the ERCs Nitrosopumilus and SAR324 clade. The abundance of the species in the group is associated with a lower concentration of oxygen and temperature, and higher concentrations of nitrates, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \text{PO}{4}\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \text{NO}{2}\text{NO}_{3}\end{document} . In the oxygen-depleted environment, Nitrosopumilus survives by oxidizing ammonia to nitrite, confirming the observed association pattern [64]. Marinomicrobia (SAR406 clade) in groups M1 and M2 allow us to distinguish subgroups of species that can survive in both deep and shallow water [62].
Module M3 comprises the highest mean abundance of all taxa is highest, primarily representing the taxa SAR11 clade, SAR86 clade, and Prochlorococcus (cyanobacteria). The abundance of the species in the group is positively associated with depth indicators (and negatively associated with MES. Among the geochemical factors, temperature, salinity, and oxygen concentration are positively associated, whereas the concentration of nitrates, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \text{PO}{4}\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \text{NO}{2}\text{NO}_{3}\end{document} is negatively associated with the taxa.
Module M4 primarily represents Alteromonadales (Proteobacteria) and some Pseudomonadales (Proteobacteria) and Synechococcus. Their abundance is associated with factors such as lower salinity and higher oxygen concentration. Module M5 also primarily represents Alteromonadales. Based on its association with the ocean depth indicators and geochemical features, we conclude that these taxa can survive in a deep-sea environment characterized by lower temperatures and oxygen concentrations. Associative patterns of Alteromonadales in M4 and M5 differ significantly, suggesting distinct ERC sub-groups that populate different niches.
Positive and Negative interactions among ERCs
VI-MIDAS includes a mechanism for learning microbial interactions adjusted for direct (here, environmental) covariates. Contrary to prominent (partial) correlation-based methods [65, 66], VI-MIDAS follows the SHOPPER utility model [30] and quantifies pairwise interactions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf{I}_{ij}\end{document} between any two taxa \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} i\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} j\end{document} in terms of the latent variables \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \rho \end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \boldsymbol \beta \end{document} (see Eq. 9).
To get a high-level view of the estimated interactions, we aggregated the adjacency matrices of significant positive and negative interactions among taxa by ERCs (for a more detailed view of the most significant taxon-level interactions, we refer to Section 4 of the Supplementary Materials). Figure 7 illustrates the aggregated positive (lower triangle) and negative (upper triangle) interactions among ERCs. The diagonal entry highlights the maximum of the two types of interactions to avoid confusion (see also Section 4 of the Supplementary materials for the matrix of ratios between positive and negative interactions). We observe that SAR11 clade and Rhodospirillales form positive interactions with almost all other ERCs. SAR11 clade and Rhodospirillales belong to the Alphaproteobacteria phylum that play a critical role in carbon and nitrogen fixation [67, 68], potentially explaining the large number of interactions. However, members of the SAR11 clade also form many negative interactions with other ERCs. Alteromonadales exhibits primarily negative interactions with other ERCs (the strongest one with SAR11).
Summary of taxonomic interactions: The adjacency matrices of significant positive and negative interactions among taxa are grouped and aggregated by their ERCs type. Interactions summary by the ERCs types. Lower triangle reports positive interactions, the upper triangle reports negative interactions. Diagonal entries show the maximum of either (positive or negative) self-interaction.
Discussion
In recent years, multimodal and multi-omics microbiome survey data have emerged for a wide range of microbial habitats [14, 41, 69–72]. These data collections hold the promise to describe and understand the functional interplay between the underlying microbial ecology and the host or the environment the microbiota resides in. Learning interactions among species and habitat characteristics from observational data remains, however, a challenging problem. To this end, we have proposed VI-MIDAS, a flexible and efficient probabilistic framework for microbiome survey data analysis.
VI-MIDAS uses the negative binomial distributional framework in combination with a principled centering transformation to model overdispersed amplicon abundance data and comprises three mechanisms to integrate concomitant covariate data into the generative model: (i) a direct coupling mechanism, (ii) an indirect latent coupling mechanism, and (iii) a latent interaction term. These terms are linearly linked to the probability distribution’s mean parameter. Because of the intractable form of the marginal distribution of data, we apply mean-field variational inference framework to learn an approximate posterior distribution of the parameters.
VI-MIDAS is available in Python and uses the probabilistic programming language Stan [57]. The implementation is available on GitHub (https://github.com/amishra-stats/vi-midas). The repository also includes Python scripts and Jupyter notebooks for VI-MIDAS’ three-stage parameter estimation framework: hyperparameter tuning, component contribution analysis, and sensitivity analysis.
To illustrate the VI-MIDAS modeling and analysis workflow, we have used data from the global Tara expedition [14], connecting the available spatiotemporal and environmental characteristics with generative modeling of the amplicon count data. To ease interpretability, we also grouped the amplicon-derived taxa into expert-annotated ecologically relevant classes (ERCs) which may be of independent interest for the analysis of other marine sequencing data. Focusing on the \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} q=1378\end{document} most abundant taxa representing 23 ERCS, we integrated the geochemical data using the direct coupling mechanism, effectively removing influence of common environmental factors such as temperature, salinity, and elemental compositions on microbial abundances. The remaining spatiotemporal features, including season, ocean province, and depth, as well as species-species associations are integrated through the latent coupling and interaction mechanism, thus delivering a latent species representation, adjusted for the influence of all available covariates. The learned VI-MIDAS’ model thus not only provides a convincing generative count model for the Tara data but also allows integrated statistical analysis of covariate feature effects and taxa abundances.
Modularity analysis of the similarity network of VI-MIDAS’ latent species representation revealed that the majority of taxa ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} >1200\end{document} ) can be categorized into three global microbial communities (M1–M3 in Fig. 5), including a low-temperature/high-oxygen community (M1), dominated by Flavobacteriales and the Chloroplast ERC, a mesopelagic community (M2) dominated by SAR11, SAR324, and Nitrosopumilus, and a high-temperature community (M3) dominated by SAR11 and Prochlorococcus, the later of which is the most abundant clade in the oligotrophic subtropical and tropical oceans (see, e.g. [73] and references therein). Furthermore, our analysis suggests two distinct Alteromonadales-dominated communities that show different depth and province dependencies (M4–M5) (see Fig. 6 for further global associations overview). It is noteworthy that Alteromonadales also play a pivotal role in the latent interaction analysis, showing widespread negative associations with other ERCs. We posit that the potentially distinct role of Alteromonadales in the global ocean might be of interest for follow-up analysis on other data sets, including recent data on the global mesopelagic zone [74].
While our ablation study showed evidence that all VI-MIDAS components for the Tara data contribute to the quality of the generative model, the model is just one of several available alternatives. For covariate inclusion, we deliberately chose to directly adjust the microbial abundances for geochemical covariates to better carve out “hidden” relationships among the species. Nonetheless, the VI-MIDAS framework naturally enables other model constructions. For instance, one could have removed the direct coupling component and link all concomitant features to the latent space representation, or alternatively, remove the latent representation altogether and directly adjust for all covariates. We will explore such modifications in future studies. Moreover, while we chose the Negative Binomial model as base distribution for the most abundant taxa, the variational formulation lends itself to other statistical models for microbial count data, including zero-inflated or hurdle- type extensions of the Negative Binomial model [75] or the Dirichlet-Multinomial model [35, 76]. Finally, in its current state, VI-MIDAS is built on Stan [57] with tailored Python code for optimization, model selection, and analysis. The advent of extensive statistical packages in modern deep learning tools, such as Tensorflow distributions [77] or PyTorch [78], may enable efficient porting of VI-MIDAS into these general-purpose ecosystems. Paired with variational inference tools [79], would potentially allow for faster model adaptation and alternative optimization routines.
VI-MIDAS makes the explicit methodological choice to symmetrize the latent interaction structure, leading to the interpretation of positive (“mutualistic”) and negative (“competitive”) associations (see Eq. 9). While this approach precludes the representation of asymmetric (directed) interactions such as parasitism, it enables meaningful aggregation of the overall interaction structure across ERCs. In our future work, we aim to explore explicit modeling of directionality in microbial interactions, potentially leveraging approaches designed for directed networks.
The VI-MIDAS framework was designed to adapt model complexity to dataset size, ensuring applicability to presently available microbiome survey data. VI-MIDAS employed a random search strategy for hyperparameter tuning, sampling 50 parameter combinations for latent dimension ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} k\end{document} ), sparsity-inducing priors ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \lambda \end{document} ), and dispersion parameters ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \upsilon \end{document} ) (see Section 3.3 of the Supplementary material). Five-fold cross-validation based on out-of-sample (LLPD) identified optimal hyperparameter settings, with robustness further ensured through 50 random initializations to address non-convexity in ELBO optimization (see Section 3.5 of the Supplementary material). We also performed model ablation to evaluate the importance and contribution of specific model components by systematically removing them and assessing their impact on performance or interpretability. This three-pronged strategy—hyperparameter tuning, sensitivity analysis, and model ablation—effectively balances model complexity with sample size. In our experience, VI-MIDAS performs robustly with datasets of several hundred samples. For smaller datasets, we recommend to simplify the model by removing the latent taxon–taxon interaction terms to mitigate overfitting.
In summary, VI-MIDAS provides a novel probabilistic framework for learning environment- or host-specific feature associations, latent species characterization, and species–species interactions from microbiome survey data. With minimal adjustment, the framework is readily available for the analysis of other large-scale survey data, including gut microbiome surveys [12, 80, 81], thus representing a potentially valuable general-purpose tool for the integrated analysis of modern microbiome data collections.
Supplementary Material
vi-midas_supp_ycaf062
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Fox G, Woese C. Phylogenetic structure of the prokaryotic domain. PNAS 1977;74:5088–90. 10.1073/pnas.74.11.5088270744 PMC 432104 · doi ↗ · pubmed ↗
- 2Pace NR, Stahl DA, Lane DJ et al. The analysis of natural microbial populations by ribosomal RNA sequences. In: Marshall K.C. (ed.), Advances in Microbial Ecology, Vol. 9. Boston, MA: Springer, 1986, 1–55.
- 3Olsen GJ, Lane DJ, Giovannoni SJ et al. Microbial ecology and evolution: a ribosomal RNA approach. Ann Rev Microbiol 1986;40:337–65. 10.1146/annurev.mi.40.100186.0020052430518 · doi ↗ · pubmed ↗
- 4Tyson GW, Chapman J, Hugenholtz P et al. Community structure and metabolism through reconstruction of microbial genomes from the environment. Nature 2004;428:37–43. 10.1038/nature 0234014961025 · doi ↗ · pubmed ↗
- 5Schloss PD, Westcott SL, Ryabin T et al. Introducing mothur: open-source, platform-independent, community-supported software for describing and comparing microbial communities. Appl Environ Microbiol 2009;75:7537–41. 10.1128/AEM.01541-0919801464 PMC 2786419 · doi ↗ · pubmed ↗
- 6Callahan BJ, Sankaran K, Fukuyama JA et al. Bioconductor workflow for microbiome data analysis: from raw reads to community analyses. F 1000 Research 2016;5. 10.12688/f 1000 research.8986.1PMC 495502727508062 · doi ↗ · pubmed ↗
- 7Bolyen E, Rideout JR, Dillon MR et al. Reproducible, interactive, scalable and extensible microbiome data science using qiime 2. Nat Biotechnol 2019;37:852–7. 10.1038/s 41587-019-0209-931341288 PMC 7015180 · doi ↗ · pubmed ↗
- 8Turnbaugh PJ, Ley RE, Hamady M et al. The human microbiome project. Nature 2007;449:804–10. 10.1038/nature 0624417943116 PMC 3709439 · doi ↗ · pubmed ↗