Semantic segmentation dataset authoring with simplified labels
Leo Uramoto, Yuichiro Hayashi, Masahiro Oda, Takayuki Kitasaka, Kensaku Mori

TL;DR
This paper introduces simplified labels to make it easier for non-medical people to help annotate medical images, improving dataset creation and multi-dataset training.
Contribution
The novel contribution is introducing simplified labels to reduce reliance on medical experts during dataset creation and enable multi-dataset training.
Findings
Including non-medical annotators improves dataset creation, though medical annotators are more effective.
Simplified labels allow multi-dataset training even when datasets have no overlapping classes.
Using simplified labels with non-medical annotators increases Dice scores by up to 6.9%.
Abstract
Semantic segmentation of laparoscopic images is a key problem in surgical scene understanding. Creating ground truth labels for semantic segmentation tasks is time consuming, and in the medical field a need for medical training of annotators adds further complications, leading to reliance on a small pool of experts. Previous research has focused on reducing the time to author datasets, by using spatially weak labels, pseudolabels, and synthetic data. In this paper, we address the difficulties caused by the need for medically trained annotators, hoping to enable non-medical annotators to participate in medical annotation tasks, to ease the creation of large datasets. We propose simplified labels, labels that are semantically weak. Our labels allow non-medical annotators to participate in medical dataset authoring, by lowering the need for medical expertise. We simulate authoring…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
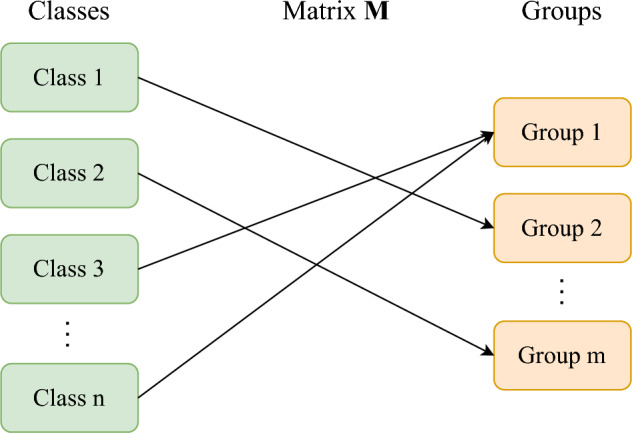 Figure 1
Figure 1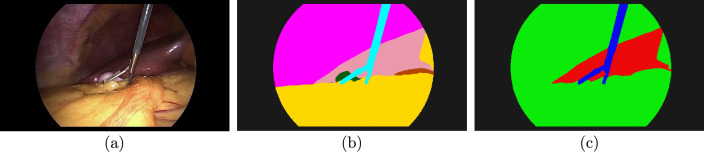 Figure 2
Figure 2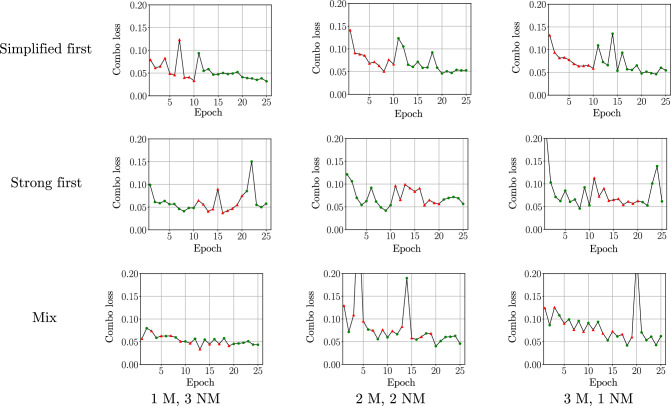 Figure 3
Figure 3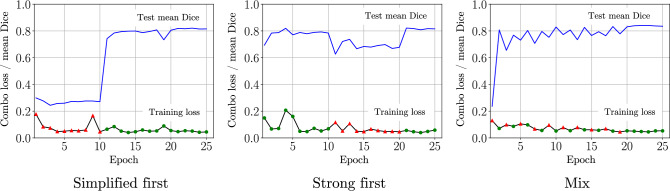 Figure 4
Figure 4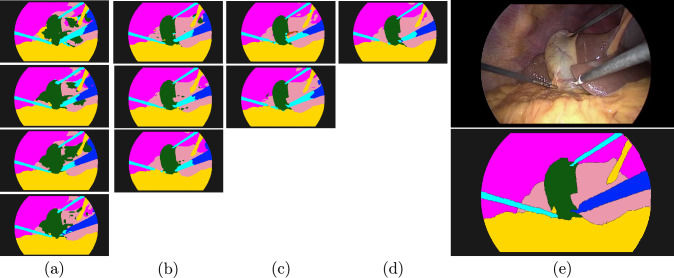 Figure 5
Figure 5- —http://dx.doi.org/10.13039/501100002241Japan Science and Technology Agency
- —http://dx.doi.org/10.13039/501100001691Japan Society for the Promotion of Science
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Radiomics and Machine Learning in Medical Imaging · Advanced Neural Network Applications
Introduction
Laparoscopic surgeries offer a minimally invasive option to open surgeries in abdominal and pelvic operations. In a laparoscopic surgery, surgical tools, including a camera system, are inserted into the operating area through small incisions. This approach can lead to faster recovery times, and reduced scarring and pain when compared to open surgery.
Laparoscopic surgeries can be performed with robotic assistance. In addition to providing more intuitive tool control, such robotic systems could offer various kinds of AI-based assistance to the surgical team, varying from guidance systems to automated evaluation and feedback.
Semantic segmentation is a key problem in the development of surgical assistance systems using computer vision, such as intraoperative guidance systems displaying anatomical structures, or safe dissection zones [1]. Surgical semantic segmentation can also act as a base for more complicated problems, like navigation assistance. Semantic segmentation requires a large amount of labeled data, and authoring such datasets is time consuming. A need for medical expertise poses an additional challenge for medical computer vision. Relying on a small pool of expert annotators leads to small datasets, potentially hindering model generalization. To alleviate this, we propose an approach that allows laypeople without medical expertise to participate in the authoring process.
Related work
There exist only a few large publicly available datasets on semantic segmentation of laparoscopic images. The largest segmentation dataset available at the time of writing is the Dresden Surgical Anatomy Dataset [2], consisting of 13,195 images, and covering 11 classes. However, this dataset does not contain dense annotations for everything in view, but instead contains one class per image. The largest densely labeled dataset we are aware of is the CholecSeg8k [3], containing 8080 images, and covering 13 classes. The frames in CholecSeg8k were sampled at 25 fps, meaning that the whole dataset consists of approximately 5.5 min of video, with at times very low variability. The training portion of the Endoscopic Vision 2018 Robotic Scene Segmentation Challenge dataset [4] (EndoVis2018) dataset consists of 4500 frames and their segmentation ground truths. The frames are sampled at 1 fps from 15 videos of porcine training procedures, performed with the daVinci system. Nephrec9 [5] is a large nephrectomy video dataset, consisting of 1262 clips, each containing 720 frames, for a total of 908,640 frames, each annotated with surgical steps. Instrument and anatomy presences were annotated based on their usage and appearance during steps.
Large datasets are a key to improving performance of machine learning models. Modern, increasingly complicated models are trained on massive amounts of data. One example is the Segment Anything Model [6], trained on over 1 billion masks on 11 million images. In medical imaging, three key areas of research can be identified: semi-supervised training, efficient dataset authoring, and multi-dataset training.
In semi-supervised learning [7], only a portion of the data is labeled. The unlabeled samples have been used as a background for procedurally created tools and their labels in a tool segmentation task [8], with CycleGAN used to make the synthetic samples more realistic. Using 300 annotated samples and 5665 synthetic samples, the authors were able to increase tool segmentation Dice score by 35.7%. Another approach is to create pseudolabels for unlabeled data, effectively extending the dataset during training. Using optical flow for creating pseudolabels [9], researchers were able to train their segmentation models on unlabeled frames as well. Using the labels for only parts of the data, they were able to increase the baseline Dice score by 5.4% when only 10% of the images were labeled, and by 3% when using 30% of the labeled images in a tool segmentation task. On a more complicated part segmentation task, the Dice scores improved by 2.6% with 10% and 3.2% with 30% of the data. When comparing their proposed approach to a model trained on the full training set, their model reached 96% of the performance of the baseline model in part segmentation, and in binary tool segmentation even surpassed it. While semi-supervised approaches have found success in the medical field [10], they do not offer the same level of reliability as fully supervised approaches. This can make them problematic in the medical field, where accuracy is of utmost importance. Training using semi-supervised learning is also sensitive to noise and images dissimilar to the labeled examples, leading to difficulties with creating pseudolabels and to unhelpful synthetic data.
Faster methods to authoring ground truth segmentation maps have been researched. Such labels are typically spatially weaker than dense segmentation maps. Examples of such approaches are bounding boxes [11], scribbles, lines, and points [12]. When comparing the efficacy of their EasyLabels [13] to traditional spatially dense labels, the performance of a model trained on EasyLabels achieved 97% performance on binary tool segmentation, and 90% performance on multiclass segmentation, when compared to a model trained on spatially dense labels. The method offers a significant annotation speed increase, with authors reporting annotation speeds of 428 s per image with normal annotations and 31 s per image with EasyLabels. Scribble annotations were found to take on average only 16 s per slice, box annotations 20 s, point annotations only a few seconds, and full annotations 200 s, when annotating COVID-19 infection lesions in CT images [14]. Class presence labels can be considered an extreme form of spatially weak labels, lacking spatial presence altogether.
The need for large datasets could be alleviated if it was possible to easily train models on multiple datasets. In practice datasets are often incompatible, due to as an example class differences. Multi-dataset training on incompatible datasets has been researched, and the proposed solutions typically use semantic hierarchies [15] and class relationships [16].
While improving both authoring efficiency of medical annotators, and learning from unlabeled data are important, these works overlook an untapped resource in non-medical annotators. We aim to design a segmentation dataset authoring scheme that allows for non-medical annotators to participate in the authoring process, in the hopes of assisting in the creation of larger datasets.
We introduced the preliminary idea of simplified labels in our presentation at CARS 2023 [17]. Simplified labels are a type of label that, in contrast to spatially weak labels, is weak semantically. Instead of reducing authoring time, the goal is to reduce the need for medical training in dataset authoring, allowing non-medical annotators to participate in the process.
In this work, we use the same core methods, but extend the work in multiple areas. We search for an optimal training strategy for the labels, finding a training strategy better than the one proposed in our previous work. We perform a wider range of experiments, adding an additional model to our experiments, showing that the approach is model independent. We also show that the proposed labels offer a simple formulation for multi-dataset training. This approach can be used to include additional training data in a wide variety of surgical image segmentation projects, with minimal effort. We show its feasibility by jointly training on a cholecystectomy dataset, and a porcine dataset, with no overlapping classes. While completely disjoint datasets make for an academically interesting case, differences in annotation granularity in large annotation projects offer a more practical problem solved by this method.
Methods
When authoring medical segmentation datasets, for problems excluding the simplest ones such as binary tool segmentation, it is necessary for the annotators to possess some level of medical expertise. Here, we define a medical annotator as an annotator capable of identifying all tools and tissue types correctly. In practice, this would correspond to annotators with special training on annotating surgical images, or medical experts. We also define a non-medical annotator as an annotator lacking the training required for annotating surgical images, but having experience in creating segmentation annotations.
Our goal is to build a simplified labeling scheme, in which anon-medical annotator can label basic structures, that can be recognized without medical training. As an example, identifying all different tools would be a difficult task for a non-medical annotator, but one could always recognize that these tools differ from organs and tissue. This information could provide valuable guidance to machine learning models, at a lowered authoring cost in terms of specialist hours. These simple structures can be thought of as groups, containing one or more classes.
Semantic segmentation problems are inherently linked to classification problems. In a classification problem, a single instance is labeled, while in semantic segmentation, each pixel in an input image is given a label. We build our proposed method by first considering a classification problem and then apply it to semantic segmentation.
In classification tasks, categorical variables are often encoded as probability vectors. In a problem with n classes, the categorical variable would be encoded as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} , a nonnegative vector of finite length n, such that the sum of the elements of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} equals 1.Fig. 1. Matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M}$$\end{document} encodes the relationships between classes and groups and transforms a probability vector denoting class to a probability vector denoting group
Simplified labels can be generated by grouping classes together. As an example, all tool classes could be collected into a “Tool” group. In a classification task with n classes, the classes can be assigned into m groups. The relationship between classes and groups, illustrated in Fig. 1, can be described with an \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m \times n$$\end{document} matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M}$$\end{document} , defined element-wise. The element at index i, j, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$m_{ij}$$\end{document} is defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} m_{ij} = \left\{ \begin{array}{ll} 1 & \text{ if } \text {class}\,\, \text {j is a member of group } \,\, i, \\ 0 & \text{ otherwise }. \end{array} \right. \end{aligned}$$\end{document}If each class belongs to exactly one class, and if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} is a nonnegative vector, then so is the transformed vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M} \textbf{y}$$\end{document} . Furthermore, when defining \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}' = \textbf{M} \textbf{y}$$\end{document} , the vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}'$$\end{document} have the same element-wise sum,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \sum _{i=1}^n y_i = \sum _{j=1}^m y'_j. \end{aligned}$$\end{document}As a special case, it can be seen that if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} is a probability vector, then so is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}'$$\end{document} . The vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} can be interpreted as containing a probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_i$$\end{document} for each class \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i=1,\dots ,n$$\end{document} . The simplified vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}'$$\end{document} can similarly be interpreted as having a probability for each group \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y'_j$$\end{document} for groups \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j=1,\dots ,m$$\end{document} . It can also be seen that if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} is a 1-hot encoded vector, then so is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}'$$\end{document} .
Due to these properties, simplified vectors are valid inputs for classification loss functions. Denote a true label with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} , a predicted probability vector with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\textbf{y}}}$$\end{document} , and a classification loss function with L. Calculating a loss on the transformed vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L(\textbf{M}{\hat{\textbf{y}}},\textbf{M}\textbf{y})$$\end{document} is a valid operation, calculating the dissimilarity of the vectors on the group level.
This idea can now be transferred to semantic segmentation. A strong label consists of a class-level ground truth for each pixel. A simplified label on the other hand consists of a group-level ground truth label, and a matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M}$$\end{document} describing the grouping. The difference between a strong label and a simplified label can be seen in Fig. 2. The strong labels require medical annotators recognizing all classes present in the image, while semantically weaker simplified labels could be authored by non-medical annotators as well. With slight abuse of notation, we skip the tensor notation for segmentation maps and instead use \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} as a representative of the probability vector of an arbitrary pixel, assuming that each operation is done in a similar way to all pixels. Similarly, the probability vector of an arbitrary pixel in a simplified segmentation map is denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}'$$\end{document} , and in the context of simplified segmentation maps, the simplification process \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}'=\textbf{M}\textbf{y}$$\end{document} is assumed to be performed for each vector in the segmentation map.
The workflow for authoring simplified labels would begin with a non-medical annotator first choosing an appropriate grouping for their skills. As an example, one could author labels with groups “Tissue” and “Non-tissue.” The author would then create dense simplified segmentation maps for input images they are responsible of labeling.
A simplified training sample is a triplet \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{\textbf{x}, \textbf{y}', \textbf{M}\}$$\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{x}$$\end{document} is an input image, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}'$$\end{document} its simplified label and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M}$$\end{document} a matrix built from the grouping the author used. Training on such a triplet is done by predicting a segmentation map \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\textbf{y}}}$$\end{document} for the input image \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{x}$$\end{document} , then simplifying the output \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\hat{\textbf{y}}}$$\end{document} to match the label, and comparing them in a loss function, namely
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {Loss} = L(\textbf{M}{\hat{\textbf{y}}}, \textbf{y}'). \end{aligned}$$\end{document}When \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M}=\textbf{I}$$\end{document} , this simplifies to regular supervised training on strong labels.
Experiments and results
Overview
To measure usefulness of the proposed simplified labels, we simulated their use in dataset authoring. To simulate a non-medical annotator, first a grouping was chosen, resulting in a transformation matrix. When a training sample was loaded, the ground truth label \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}$$\end{document} was first simplified by transforming it as described in Sect. “Methods” into a simplified label \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}'$$\end{document} . The input image \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{x}$$\end{document} , the label \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{y}'$$\end{document} , and the transformation matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{M}$$\end{document} formed then a training sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{\textbf{x}, \textbf{y}', \textbf{M}\}$$\end{document} that the models were trained on when using simplified data.
We performed three sets of experiments; we first aimed to find the optimal training strategy for the proposed simplified labels, then explored how useful they would be in practice, and finally showed that the proposed approach offers a simple formulation for multi-dataset training. We performed our experiments using the CholecSeg8k [3] dataset in all experiments and used the EndoVis2018 [4] as a secondary dataset in the multi-dataset experiment.
Model and datasets
The CholecSeg8k dataset contains 8080 endoscopic images with a resolution of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$869 \times 512$$\end{document} pixels, sampled from 17 cholecystectomy videos. Ground truth segmentation labels, covering 13 classes, are provided for all images. Some of the classes are rare, appearing in only few videos. We chose the 8 most common classes and used the 6210 frames consisting only of these 8 classes.
EndoVis2018 consists of porcine training procedures, performed with the daVinci system. The dataset consists of 15 videos, sampled at one frame per second, each containing 300 frames.
We designed an experiment for a training dataset split into four parts. Simulated authors, medical and non-medical annotators, forming teams of 1–4 members, labeled a dataset. Each team member could create labels for only one part of the dataset. Medical annotators created strong labels on the class level, and non-medical annotators simplified labels. The non-medical annotators were able to recognize basic structures, leading to a grouping defined in Table 1. This grouping was chosen due to the groups looking visually distinct from each other. Tools clearly form their own visual group, while organs have shapes and surfaces that make them distinct from the tissue group. As meaningful training requires at least some strong labels, only team compositions with at least one medical annotator were considered.Fig. 2. Comparing simplified labels and strong labels. It takes expert knowledge to label everything in the input image (a) correctly. A medical annotator can create a strong label (b), with grasper (light blue), gallbladder (dark green), liver (pink), gastrointestinal tract (brown), fat (yellow), abdominal wall (magenta), and background (black). A non-medical annotator could create a simplified label, labeling organs (red), tissue (green), tools (blue), and background (black)
In all of our experiments, we used fivefold cross-validation, repeating each experiment 5 times for a total of 25 samples. Fourfold was used as the training set, with each fold operated by a simulated author, and onefold as a test set.
We performed our experiments using two models. We chose the DeepLabV3 [18] model for its good performance with even small amounts of data, and the FCN [19] for its simplicity. We used ResNet [20] as the encoder for both models. We trained the models with the Adam [21] optimizer, with a learning rate of 0.0005. Due to class imbalances, we chose Combo Loss [22] as the loss function. Performance was measured with mean Dice score.
Our models were trained using an NVDIA A100 80GB GPU and an AMD EPYC 7402 CPU. The computational time required for one experiment varied from 9 h when using only onefold for training, to 32 h when using the full fourfold of training data available.
Training strategy
Table 1. Classes and groupings in the CholecSeg8k dataset, showing how the simulated medical annotators (class) and non-medical annotators (group) labeled the datasetClassGroupAbdominal wallTissueFatTissueGastrointestinal tractTissueLiverOrganGallbladderOrganGrasperToolL-HookToolBackgroundBackground Table 2. The three training strategies comparedStage 1Stage 2Stage 3Data typelrEpochsData typelrEpochsData typelrEpochsStrong firstStrong0.000510Simplified0.000510Strong0.0001255Simple firstSimplified0.000510Strong0.000510Strong0.0001255MixedMixed0.000510Mixed0.000510Strong0.0001255Data type shows the type of data used in a stage, lr the learning rate, and epochs the length of the stage. When mixed data is used, 5 epochs of both strong and simplified data are interleaved for a total of 10 epochs
Due to size mismatches, simplified and strong labels cannot be trained on in the same batch. Strong labels are tensors of size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H \times W \times n$$\end{document} , where H and W are the width and height of the image, and n the number of classes. Simplified labels on the other hand are of size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H \times W \times m$$\end{document} , where m is the number of groups. Due to the size mismatch, these tensors cannot exist in the same batch. As sampling the dataset in minibatches was not possible, it was necessary to create a training strategy for the simplified labels.
We trained our model in 3 phases, consisting of 10, 10, and 5 epochs. In the third phase, we lowered the learning rate from the initial 0.0005 to 0.000125. With this setting, 3 training strategies were considered: training first on the strong data, training first on the simplified data, and using a mixed approach. These training strategies are visualized in Table 2.
Strong first
In strong first training, the model was first trained on the strongly labeled data for 10 epochs, then for 10 epochs on the simplified data, and finally for 5 epochs on the strongly labeled data with a lowered learning rate. We hypothesized that training first on the strongly labeled data might allow the model to extract more meaningful information from the semantically weak labels.
Simplified first
In simplified first training, the model was first trained for 10 epochs on data with simplified labels, followed by 15 epochs on strongly labeled data, with the learning rate lowered for the last 5 epochs. This approach could be thought of as pretraining the model on the simplified data, in preparation for training on the strongly labeled data. Pretraining is often used in practice, which suggested this could have been a good approach.
Mixed
In a mixed approach, the simplified data and the strongly labeled data were interleaved for a total of 20 epochs, attempting to mimic minibatch training. After training the model on strongly labeled data for one epoch, the model was trained for one epoch on data with simplified labels. After these 20 epochs, the model was trained for 5 epochs on strongly labeled data with a lowered learning rate.
Experiment and results
Table 3. Results from the training strategy experiment with the DeepLabV3 and FCN modelsDeepLabV3FCN1 M, 3 NM2 M, 2 NM3 M, 1 NM1 M, 3 NM2 M, 2 NM3 M, 1 NMSimplified first \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.696\pm 0.042$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.753 \pm 0.047$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.804 \pm 0.039$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.701\pm 0.058$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.760 \pm 0.040$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.805 \pm 0.035$$\end{document} Strong first \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.722 \pm 0.048$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.758 \pm 0.045$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.808 \pm 0.041$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.721 \pm 0.046$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.765 \pm 0.044$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.794 \pm 0.038$$\end{document} Mix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.736} \pm 0.042$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.772}\pm 0.043$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.821}\pm 0.032$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.730} \pm 0.042$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.772}\pm 0.040$$\end{document}
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.810}\pm 0.037$$\end{document} The number of medical annotators is denoted with M, and the number of non-medical annotators with NMFor each column, the highest value is bolded
For the training strategy experiment, we used 3 representative team compositions: 1 medical and 3 non-medical annotators, 2 medical and 2 non-medical annotators, and 3 medical and 1 non-medical annotators. These samples covered imbalances favoring both strongly labeled and simplified data and a balanced sample. The results of the experiments are collected in Table 3.Fig. 3. Learning curves showing training losses of the training strategy experiment. The number of medical annotators is denoted with M and non-medical annotators with NM. Epochs with simplified labels are marked with red triangles, and epochs with strong labels with green dots
The results showed that the mixed strategy performed the best and was adopted as the training strategy for the other experiments.
To verify that the training had converged, we looked at learning curves, shown in Fig. 3, from our experiments with the FCN model. The losses seemed to converge reasonably well with all of the training strategies, settling near Combo Loss value 0.05.Fig. 4. Learning curves of the training strategy experiment with two medical and two non-medical annotators, showing also performance on the test set. The mean Dice on the test set is shown in blue, and the training loss in black. For training data, epochs with simplified labels are marked with red triangles, and epochs with strong labels with green dots
Seeking to better understand the differences between the training strategies, we performed an additional training run on 2 simplified and 2 strong folds, tracking the model’s performance on the test set through training. We chose FCN for this experiment as it was the simpler model. Figure 4 shows the mean Dice on the test set at the end of each iteration. In general, the performance on the test set falls immediately after an iteration on simplified data, but after training again on strongly labeled data, the performance immediately improves. With the mixed strategy, performance degrades less and less after epochs on simplified data, while performance after epochs on strongly labeled data improves. On the last 5 epochs, when using a lowered learning rate, the model trained with the mixed strategy learns to perform the best on the test set, at a higher loss value than the other two. At the end of the training, its final mean Dice value is 0.835, significantly higher than the maximum mean Dice scores of the simplified first (0.821) and strong first (0.822) over the whole training phase.
Measuring the impact of simplified labels
With the selected mixed training strategy, we explored the impact of the simplified data on performance, by collecting performance metrics for all 10 team compositions in Table 4 for FCN and Table 5 for DeepLabV3. Including simplified data was always useful for DeepLabV3, even when the amount of simplified data outweighed the strongly labeled data by a 3:1 ratio. For FCN, we found small amounts of data detrimental, with rest of the results agreeing with the trend of DeepLabV3 data. It is difficult to explain this result, but changing the number of epochs or the learning rate when using small amounts of simplified data could lead to better results with this model. For both models, even large amounts of simplified data could not replace strongly labeled data; one medical annotator was worth multiple non-medical annotators.Table 4. Full results of the main experiment for the FCN model1 M2 M3 M4 M0 NM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.703 \pm 0.058$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.764 \pm 0.041$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.812 \pm 0.031$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.839 \pm 0.026$$\end{document} 1 NM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.697\pm 0.043$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.760 \pm 0.034$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.809 \pm 0.028$$\end{document} –2 NM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.718\pm 0.040$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.772 \pm 0.042$$\end{document} ––3 NM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.736\pm 0.041$$\end{document} –––The number of medical annotators is denoted with M, and the number of non-medical annotators with NMTable 5Full results of the main experiment for the DeepLabV3 model1 M2 M3 M4 M0 NM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.696 \pm 0.064$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.761 \pm 0.044$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.813 \pm 0.038$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.847 \pm 0.030$$\end{document} 1 NM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.701\pm 0.043$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.765 \pm 0.044$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.821 \pm 0.034$$\end{document} –2 NM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.729\pm 0.046$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.774 \pm 0.042$$\end{document} ––3 NM \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.737\pm 0.039$$\end{document} –––The number of medical annotators is denoted with M, and the number of non-medical annotators with NM
Fig. 5A qualitative comparison with DeepLabV3. The input image and ground truth e show two graspers (light blue), and an electrocautery tool (dark blue) operating on a gallbladder (green), next to a liver (pink), and abdominal wall (magenta). Columns show 1 medical annotator and 0–3 non-medical annotators (a), 2 medical annotators and 0–2 non-medical annotators (b), 3 medical annotators and 0–1 non-medical annotators (c), and 4 medical annotators and 0 non-medical annotators (d)
Qualitatively, the impact of simplified data on DeepLabV3 can be seen in Fig. 5. All models segment the fat well, but with other classes results vary. Impact of the simplified labels can be seen most clearly on tools, where shapes are improved. With one medical annotator, the electrocautery tool improves significantly. The best result for the tool being with one medical and three non-medical annotators is most likely caused by the model seeing less strongly labeled data where only tool shafts were visible, which would have led to the model learning potentially unhelpful features. In general, adding simplified data led to more local consistency with a lack of noisy speckles, and improved shapes, especially on the right side of the image.
We concluded that the proposed simplified labels are a feasible approach to dataset authoring when the process is limited by access to medical annotators. Non-medical annotators provide meaningful assistance to dataset authoring.
Comparing the impacts of medical and non-medical annotator labels
Data found in Tables 4 and 5 can be used to compare the impacts strong and simplified labels have on performance. We measured the statistical significance of the performance changes using two-tailed paired Student’s t test. With one medical annotator, adding three non-medical annotators to the project resulted in mean Dice score increase of 5.8% for DeepLabV3 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p<.001$$\end{document} ), and 4.7% for FCN ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=.035$$\end{document} ), while adding one medical annotator resulted in an increase of 9.2% for DeepLabV3 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p<.001$$\end{document} ) and 8.6% for FCN ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p<.001$$\end{document} ). With two medical annotators, adding two non-medical annotators resulted in an increase of 1.8% for DeepLabV3 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=.004$$\end{document} ) and 1% for FCN ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p=.149$$\end{document} ), while adding one medical annotator resulted in 6.9% ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p<.001$$\end{document} ) and 6.3% ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$p<.001$$\end{document} ) increases for DeepLabV3 and FCN, respectively.
From these results, it can be seen that one medical annotator is worth multiple non-medical annotators.
Simplifying other datasets
The problem of small datasets could be combated by training on multiple datasets. However, in practice datasets are often incompatible, containing different classes. Simplified labels could be used to solve such incompatibilities, using a grouping that makes data from both datasets compatible.
We performed an experiment with an extreme example, using the EndoVis2018 dataset as the secondary dataset, aiming to improve the performance of our CholecSeg8k-targeted model. EndoVis2018 has a resolution of 1280 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times $$\end{document} 1024 pixels, making the images significantly larger than those of CholecSeg8k. To keep feature sizes on both datasets similar, EndoVis2018 images were scaled down to a resolution of 640 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times $$\end{document} 512 pixels. EndoVis2018 contains 8 classes for tools: 3 classes for parts of the daVinci system, ultrasound probes, suturing needles, suturing thread, suction devices, and surgical clips. There are 4 different types of tissue: kidney parenchyma, covered kidney, small intestine, and other tissue considered background. There is no meaningful overlap with the CholecSeg8k dataset; the EndoVis2018 tools and organs are different, and the subject is non-human. We simplified the classes in both datasets to “biological,” “non-biological,” and “CholecSeg8k background” and applied the simplified label workflow.
We trained both DeepLabV3 and FCN models on the 4 medical annotator folds of the CholecSeg8k dataset, included EndoVis2018 as simplified labels, and measured the performance on the remaining CholecSeg8k fold. We compared these results against the 4 medical annotator data from Tables 4 and 5 and collected the data in Table 6.Table 6. Mean Dice scores when training on 4 strongly labeled folds, with and without a simplified EndoVis2018 datasetDatasetCholecSeg8kCholecSeg8k + EndoVis2018DeepLabV3 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.847 \pm 0.030$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.855} \pm 0.030$$\end{document} FCN \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.839 \pm 0.026$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.845} \pm 0.028$$\end{document} For both rows, the highest value is boldedTable 7Dice scores for each class when training a DeepLabV3 model on 4 strongly labeled folds, with and without a simplified EndoVis2018 datasetDatasetCholecSeg8kCholecSeg8k + EndoVis2018Abdominal wall \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.928 \pm 0.036$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.930} \pm 0.032$$\end{document} Fat \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.916 \pm 0.031$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.919} \pm 0.030$$\end{document} Gastrointestinal tract \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.634} \pm 0.169$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.625 \pm 0.190$$\end{document} Liver \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.918 \pm 0.020$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.920}\pm 0.019$$\end{document} Gallbladder \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.830 \pm 0.068$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.854}\pm 0.049$$\end{document} Grasper \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.823 \pm 0.041$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.848}\pm 0.029$$\end{document} L-Hook \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.735 \pm 0.272$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.752} \pm 0.254$$\end{document} Background \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$0.993 \pm 0.003$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathbf {0.994}\pm 0.002$$\end{document} For each row, the highest value is bolded
Table 6 shows that both models benefited from additional data. It also shows that the DeepLabV3 model had a higher mean Dice value both with and without the secondary dataset, and it benefited more from the inclusion of the secondary dataset. As the better performing model, we selected DeepLabV3 for further analysis. We collected Dice scores of all classes to explore the impact of training on the secondary dataset and collected the data in Table 7 to see which classes benefited from the secondary dataset. Table 7 shows that including the EndoVis2018 dataset resulted in performance gains in almost all classes with the DeepLabV3 model, with the exception of gastrointestinal tract. The mean Dice improved by approximately 1% with both models.
We concluded that the proposed approach could be used to train on multiple incompatible datasets.
Discussion
Massive datasets have been a trend not only with language models, but also with recent segmentation models like the Segment Anything Model. The idea of creating similar large models in areas like semantic segmentation of laparoscopic images is challenging, as massive datasets are significantly more difficult to author. Creating one large dataset once would not suffice, as it could become outdated due to new technologies in cameras and tools.
Improving the efficiency of medical annotators is an important step toward larger datasets, but involving non-medical annotators in the authoring process could have its benefits. Creating large datasets covering a wide variety of different images could be realized by crowdsourcing help from non-medical annotators around the world. In annotation projects with a limited number of medical annotators, or projects with time limitations, non-medical annotator participation could help increase the number of annotated frames and help with achieving desired levels of accuracy. Simplified labels could be used in such situations.Table 8. Dice scores of gastrointestinal tract (GI tract) and L-hook from the CholecSeg8k 10 team experiment with DeepLabV31 M1 M 1NM1 M 2NM1 M 3NM2 M2 M 1NM2 M 2NM3 M3 M 1NM4 MGI tract0.2410.1630.2050.2140.2940.2850.2730.5140.5100.634L-hook0.5980.6090.6240.6180.5950.6210.6490.6770.7030.734The number of medical annotators is denoted with M, and the number of non-medical annotators with NM
The granularity of the simplified labels can be matched to the skill level of the author. We showed that even the weakest labels, consisting of groups “biological” and “non-biological,” with input images extracted from a different distribution, helped with training.
Semi-supervised approaches where data are created at training time can be challenging for quality control. Confirming the correctness of simplified labels on the other hand is easy, making the approach potentially more suitable for medical applications. We do want to emphasize that simplified labels do not have to fully replace semi-supervised approaches or directly compete with them, as it is possible to both use the simplified labels approach to authoring a labeled dataset, and to use semi-supervised methods like synthetic data and pseudolabels on the remaining unlabeled data.
In all of our experiments, we found the Tool group benefiting the most from simplified labels. This might be due to tools differing the most from other classes, and even in semantically weak form offering meaningful supervision. Gastrointestinal tract stood out with its performance degrading as simplified data were added. Table 8 shows the Dice score L-hook improving, while the Dice score of gastrointestinal tract degraded, when simplified data were included in the training. In Table 7, it can be seen that the gastrointestinal tract was the only class to suffer from simplifying the EndoVis2018 dataset.
The poor performance of the gastrointestinal tract was difficult to explain. Rarity alone did not explain this finding, as the similarly rare L-hook improved with the addition of simplified data. The class appears to simply be difficult to learn, with performance degrading due to simplified data offering only weak supervision for the class.
If multiple difficult-to-learn classes were present, simplified labels might degrade the performance of all of them, making the labels counterproductive. As it is possible to imagine situations where simplified labels could offer no help, they should not to be considered a universal approach to dataset authoring. Even if simplified labels were not a universal approach, our simulations demonstrated their benefits, making them worth considering when designing a dataset authoring project.
Even very similar semantic segmentation datasets pose problems for joint training, by as an example containing different classes, or having different granularities. Authors of a dataset might have focused on specific organs or tools, worked at a granularity not desired by someone else, or have different tools in their images. Being able to include such incompatible datasets in a training pipeline is desirable. The multi-dataset training framework we have presented is easy to implement, and can be used with a multitude of different models and training pipelines. We have shown that this approach works even when there are no overlapping classes.
Conclusions and future work
In this paper, we introduced simplified labels. Unlike spatially weak labels seen in the literature, our labels are weak in their semantic contents. Instead of focusing on authoring speed, they offer a novel way of approaching the dataset authoring problem by allowing for authors with varying degrees of medical expertise to participate in authoring of medical segmentation datasets.
Due to tensor size incompatibilities, simplified and strong labels need to be trained on separately. We compared three possible training strategies, finding that a mixed strategy interleaving training on strong and simplified data worked the best. We explored the impact of simplified labels and found that they improved the performance of our models, but were unable to replace expert annotators completely. We also showed that simplified labels offer a simple formulation to multi-dataset training and found that including a secondary dataset as simplified data improved the performance of our models increased by 1%.
One issue not addressed by this study is the accuracy of the non-medical annotator labels. The authoring process was simulated from pre-existing medical annotator labels, and their accuracy could have been overestimated. It is possible for the non-medical annotators to make errors. In practice, this issue could be solved by having the non-medical annotators label only easy images. Still, measuring the accuracy of real non-medical annotators is worth exploring in future research.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Hong W-Y, Kao C-L, Kuo Y-H, Wang J-R, Chang W-L, Shih C-S (2020) Cholec Seg 8k: a semantic segmentation dataset for laparoscopic cholecystectomy based on cholec 80. Preprint at ar Xiv:2012.12453
- 2Allan M, Kondo S, Bodenstedt S, Leger S, Kadkhodamohammadi R, Luengo I, Fuentes F, Flouty E, Mohammed A, Pedersen M et al (2018) Robotic scene segmentation challenge. Preprint at ar Xiv:2001.11190 (2020)
- 3Peláez-Vegas A, Mesejo P, Luengo J (2023) A survey on semi-supervised semantic segmentation. Preprint at ar Xiv:2302.09899
- 4Uramoto L, Hayashi Y, Oda M, Mori K (2023) Semantic segmentation dataset authoring with simpler labels. Int J Comput Assist Radiol Surg 18(Suppl 1):26–2710.1007/s 11548-024-03314-9PMC 1205589240186718 · doi ↗ · pubmed ↗
- 5Chen L-C, Papandreou G, Schroff F, Adam H (2017) Rethinking atrous convolution for semantic image segmentation. Preprint at ar Xiv:1706.05587
- 6Long J, Shelhamer E, Darrell T (2015) Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3431–344010.1109/TPAMI.2016.257268327244717 · doi ↗ · pubmed ↗