Accuracy of ChatGPT in answering cardiology board-style questions
Albert Andrew

Abstract
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
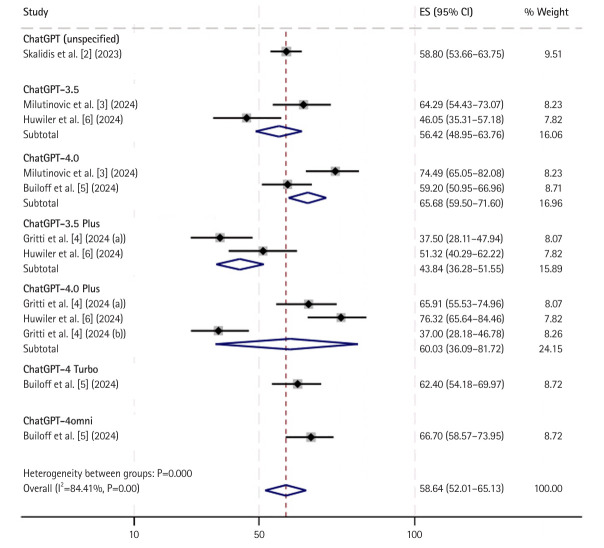 Figure 1
Figure 1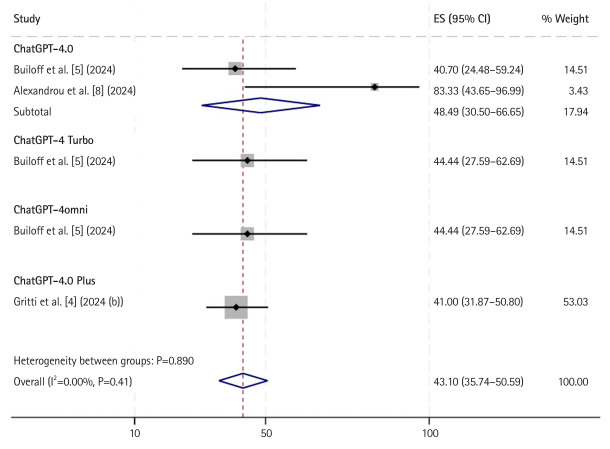 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Clinical Reasoning and Diagnostic Skills
Chat Generative Pre-trained Transformer (ChatGPT), a free generative artificial intelligence (AI) chatbot released by OpenAI, has sparked discussions about its potential in various industries, including medicine. In cardiology, it showed promise when tested on 25 cardiovascular questions based on clinical experience and guidelines [1]. It provided 21 appropriate responses on topics such as risk counseling, test interpretation, and medication details, as evaluated by preventive cardiologists [1]. A notable area of research has been evaluating ChatGPT’s accuracy in answering board-style questions for various specialist certification examinations. This mini-review with a meta-analysis examined ChatGPT’s performance on cardiology board-style questions in text and image formats across multiple versions, offering a clearer assessment of its impact on cardiology medical education.
A search for all published papers that reported ChatGPT’s performance on knowledge-based cardiology questions was conducted in PubMed/MEDLINE and EMBASE. The literature search was performed in December 2024 using the following search query: (“ChatGPT” OR “GPT-4” OR “GPT-3.5”) AND (“cardiology”) AND (“board” OR “certification” OR “specialty”). Studies were included in the analysis if they met all of the following criteria: (1) the article was written in English; (2) the study assessed ChatGPT’s accuracy on questions that were set at a level or retrieved from an appropriate resource representing board-style (specialist) cardiology certification examination questions; (3) the questions inputted into ChatGPT were either text-based, image-based, or a combination of both; and (4) the study provided data on the number of questions inputted into ChatGPT and the number (or percentage) of correct responses reported separately for each question format. Studies were excluded if they failed to meet any of the aforementioned inclusion criteria or did not disclose original data, such as review papers or descriptive replies/correspondence to previously published articles. Key study characteristic data from included studies were extracted and entered into a predefined data abstraction template. Statistical analysis pooled the reported accuracy from each study to calculate an overall pooled accuracy with a 95% confidence interval (CI), subgrouped by model version, using a random-effects model. The meta-analysis software used was STATA ver. 18.0 (Stata Corp.). P-values <0.05 were considered statistically significant. Heterogeneity was assessed using the I^2^ statistic.
Our initial search identified a total of 36 studies (25 from PubMed, 11 from EMBASE). After removing duplicates (n=9), all of the remaining 27 studies underwent full text screening. Applying the inclusion and exclusion criteria, 7 studies were ultimately included in the analysis. A summary of the key characteristics of each study is depicted in Table 1 [2-8]. The meta-analysis was divided into 2 parts: one analyzing the accuracy of text-based questions and the other for image-based questions. Accuracy was calculated using data from Dataset 1 and Dataset 2, with results further categorized by the ChatGPT version used in each study (Table 1).
For multiple-choice text-based questions (Fig. 1), data from 6 of the 7 studies were analyzed. The results showed that ChatGPT, across all versions, achieved an overall pooled accuracy of 58.64% (95% CI, 52.01%–65.13%; I^2^=84.41%, P=0.00). Among the versions, ChatGPT-3.5 Plus had the lowest performance, with an accuracy of 43.84% (95% CI, 36.28%–51.55%). In contrast, ChatGPT-4omini demonstrated the highest accuracy, achieving 66.70% (95% CI, 58.57%–73.95%). However, this result is based on a single study, limiting its representativeness in the subgroup analysis.
For multiple-choice image-based questions (Fig. 2), data from 3 of the 7 studies were included. The pooled accuracy for ChatGPT across all versions was 43.10% (95% CI, 35.74%–50.59%; I^2^=0%, P=0.41). ChatGPT-4.0 Plus performed the worst in this category, with an accuracy of 41.00% (95% CI, 31.87%–50.80%). In contrast, ChatGPT-4.0 achieved the highest accuracy for image-based questions, scoring 48.49% (95% CI, 30.50%–66.65%).
In our paper, ChatGPT’s performance was categorized into 2 areas: multiple-choice text-based and image-based questions. However, not all studies provided sufficient data for both categories. For example, Alexandrou et al. [8] included a breakdown of performance data (number of questions inputted and number of correct outputs) for image and video-based questions, but lacked similar details for text-based questions, preventing a complete assessment of ChatGPT’s performance in that area. This limitation may reduce the overall comprehensiveness and accuracy of our analysis.
The pooled accuracy of ChatGPT across all versions in this meta-analysis was 58.65% for text-based multiple-choice questions and 43.10% for image-based multiple-choice questions. Interestingly, there was a noticeable difference in performance for text-based questions between ChatGPT-3.5 and GPT-3.5 Plus, with accuracy of 56.42% and 43.84%, respectively, despite both versions being built on the same underlying training model (or architecture) [8]. While it is challenging to define a universal passing mark due to the variation in cardiology topics and difficulty levels across different examination jurisdictions, some studies have suggested that the minimum passing mark typically ranges from 60% to 73% [4,8]. Our meta-analysis suggests that ChatGPT, across all versions, is unlikely to achieve a passing score on cardiology board-style certification examinations for both text and image-based multiple-choice questions.
When ChatGPT’s performance on cardiology board-style certification questions was compared to that of successful human test-takers who had satisfactorily passed when faced with such questions, its accuracy was consistently inferior [3,6,8], with a difference in accuracy ranging from 5.5% to 12% [6,8]. This suggests that ChatGPT is not yet capable of performing at the level of human cardiologists on certification examinations and thus may lack the necessary clinical knowledge to make decisions as effectively as experienced cardiology clinicians.
Milutinovic et al. [3] also compared ChatGPT’s performance on board-style cardiology questions to that of trainee cardiologists, and non-cardiology-trained physicians. They found that, although ChatGPT may not have the same depth of knowledge as experienced cardiologists, it outperformed both trainee cardiologists and non-cardiology-trained physicians [3]. This finding is significant, as it suggests that ChatGPT, particularly the 4.0 version, could still be a valuable supplementary resource for medical students and cardiology trainees. It can help structure and apply cardiology knowledge in a systematic manner, assisting learners in understanding fundamental cardiology concepts by generating structured study aids, such as content maps for specific cardiology topics. This feature can be particularly beneficial for students and test takers, helping them organize complex information in a clear and systematic manner. Additionally, ChatGPT can support the creation of case-based learning materials and review articles, both of which are essential for continuous professional development [9]. Furthermore, examiners could use ChatGPT to generate clinical vignettes (or scenarios) for examination questions, making the process more cost-effective and less time-consuming compared to traditional methods. However, because ChatGPT lacks access to the latest clinical guidelines, it has a limited ability to generate accurate, up-to-date medical questions [10]. Manual adjustments may be needed to ensure the reliability and relevance of the generated scenarios and questions. Future studies should assess the completeness of ChatGPT’s responses to real-world cardiology cases and their relevance across different training systems and guidelines.
A key limitation of this review is the restricted search strategy, as only 2 databases were used. This may have led to the exclusion of relevant studies. Expanding the search to include additional databases and using more comprehensive keywords or search queries could have captured a wider range of literature, thereby strengthening the robustness of this analysis. In some studies that reported both text-based and image-based accuracy outcomes, there was often insufficient data to calculate one of the 2 outcomes. As a result, only one of the 2 results was included in our analysis for those studies. Moreover, significant heterogeneity was observed in ChatGPT’s accuracy on text-based questions (I^2^=84.41%). This indicates that effect sizes vary, reflecting inconsistencies in ChatGPT’s accuracy. Heterogeneity arises from factors such as question difficulty and language, as well as the phrasing of the input prompt, all of which influence how the model interprets and responds to queries. In contrast, no heterogeneity was observed in image-based questions, likely because they rely on more standardized visual features rather than variable linguistic inputs.
Nevertheless, beyond ChatGPT’s accuracy in answering cardiology board-style questions, the future of AI in medical education and assessment looks promising. Its impact extends widely across all areas of continuing medical education, influencing virtually every medical discipline [11]. A scoping review identified various AI applications in medical education, from basic uses like personalized learning and feedback platforms to more advanced innovations such as virtual trainers and simulators for assessment, as an alternative to human observation and feedback [12]. Interestingly, while physicians and medical students generally have a positive attitude toward AI in continuing education, relatively few medical students and clinicians have direct experience with its use and associated technologies [11]. Therefore, to address this, future research should focus on developing universal protocols that are capable of rigorously validating various AI tools available in the medical educational sphere, ensuring their effectiveness and usability for current and future medical professionals.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Sarraju A Bruemmer D Van Iterson E Cho L Rodriguez F Laffin L Appropriateness of cardiovascular disease prevention recommendations obtained from a popular online chat-based artificial intelligence model JAMA 2023329842844 https://doi.org/10.1001/jama.2023.1044 10.1001/jama.2023.104436735264 PMC 10015303 · doi ↗ · pubmed ↗
- 2Skalidis I Cagnina A Luangphiphat W Mahendiran T Muller O Abbe E Fournier S Chat GPT takes on the European Exam in Core Cardiology: an artificial intelligence success story?Eur Heart J Digit Health 20234279281 https://doi.org/10.1093/ehjdh/ztad 029 10.1093/ehjdh/ztad 02937265864 PMC 10232281 · doi ↗ · pubmed ↗
- 3Milutinovic S Petrovic M Begosh-Mayne D Lopez-Mattei J Chazal RA Wood MJ Escarcega RO Evaluating performance of Chat GPT on MKSAP cardiology board review questions Int J Cardiol 2024417132576 https://doi.org/10.1016/j.ijcard.2024.132576 10.1016/j.ijcard.2024.13257639306288 · doi ↗ · pubmed ↗
- 4Gritti MN Al Turki H Farid P Morgan CT Progression of an artificial intelligence chatbot (Chat GPT) for pediatric cardiology educational knowledge assessment Pediatr Cardiol 202445309313 https://doi.org/10.1007/s 00246-023-03385-6 10.1007/s 00246-023-03385-638170274 · doi ↗ · pubmed ↗
- 5Builoff V Shanbhag A Miller RJ Dey D Liang JX Flood K Bourque JM Chareonthaitawee P Phillips LM Slomka PJ Evaluating AI proficiency in nuclear cardiology: large language models take on the board preparation exam J Nucl Cardiol 2024 Nov 29[Epub]. https://doi.org/10.1016/j.nuclcard.2024.10208910.1016/j.nuclcard.2024.102089 PMC 1194949939617127 · doi ↗ · pubmed ↗
- 6Huwiler J Oechslin L Biaggi P Tanner FC Wyss CA Experimental assessment of the performance of artificial intelligence in solving multiple-choice board exams in cardiology Swiss Med Wkly 20241543547 https://doi.org/10.57187/s.3547 10.57187/s.354739465318 · doi ↗ · pubmed ↗
- 7Gritti MN Prajapati R Yissar D Morgan CT Precision of artificial intelligence in paediatric cardiology multimodal image interpretation Cardiol Young 20243423492354 https://doi.org/10.1017/S 1047951124036035 10.1017/S 104795112403603539526423 · doi ↗ · pubmed ↗
- 8Alexandrou M Mahtani AU Rempakos A Mutlu D Al Ogaili A Gill GS Sharma A Prasad A Mastrodemos OC Sandoval Y Brilakis ES Performance of Chat GPT on ACC/SCAI Interventional Cardiology Certification Simulation Exam JACC Cardiovasc Interv 20241712921293 https://doi.org/10.1016/j.jcin.2024.03.012 10.1016/j.jcin.2024.03.01238703151 · doi ↗ · pubmed ↗