DA-IRRK: Data-Adaptive Iteratively Reweighted Robust Kernel-Based Approach for Back-End Optimization in Visual SLAM
Zhimin Hu, Lan Cheng, Jiangxia Wei, Xinying Xu, Zhe Zhang, Gaowei Yan

TL;DR
This paper introduces DA-IRRK, a new back-end optimization method for visual SLAM that improves robustness and accuracy by adapting to non-Gaussian errors.
Contribution
DA-IRRK introduces a data-adaptive, iteratively reweighted robust kernel approach for back-end optimization in VSLAM.
Findings
DA-IRRK shows adaptability across different VSLAM frameworks.
The method achieves significant improvements in trajectory accuracy on most dataset sequences.
DA-IRRK outperforms existing methods in handling non-Gaussian reprojection errors.
Abstract
Back-end optimization is a key process to eliminate the cumulative error in Visual Simultaneous Localization and Mapping (VSLAM). Existing VSLAM frameworks often use kernel function-based back-end optimization methods. However, these methods typically rely on fixed kernel parameters based on the chi-square test, assuming Gaussian-distributed reprojection errors. In practice, though, reprojection errors are not always Gaussian, which can reduce robustness and accuracy. Therefore, we propose a data-adaptive iteratively reweighted robust kernel (DA-IRRK) approach, which combines median absolute deviation (MAD) with iteratively reweighted strategies. The robustness parameters are adaptively adjusted according to the MAD of reprojection errors, and the Huber kernel function is used to demonstrate the implementation of the back-end optimization process. The method is compared with other…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
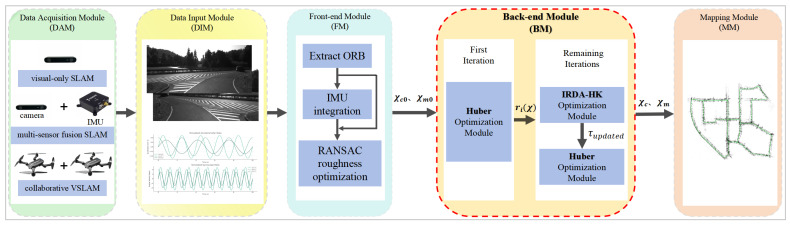 Figure 1
Figure 1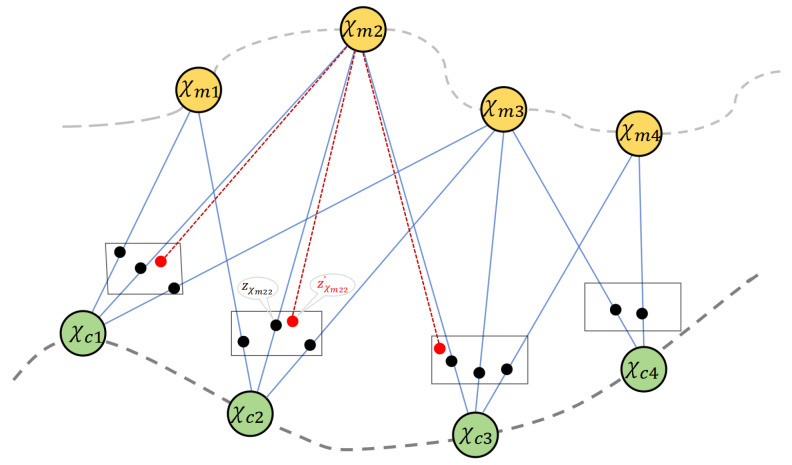 Figure 2
Figure 2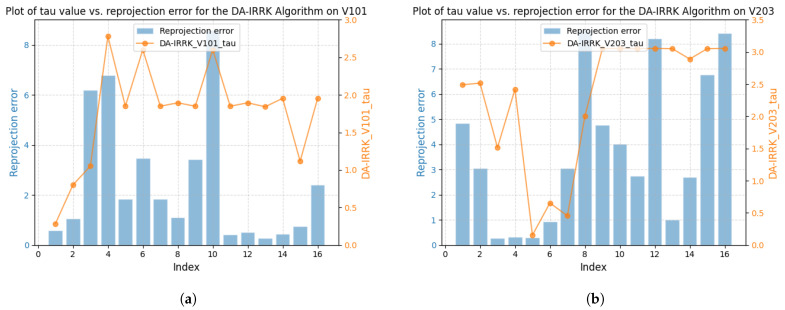 Figure 3
Figure 3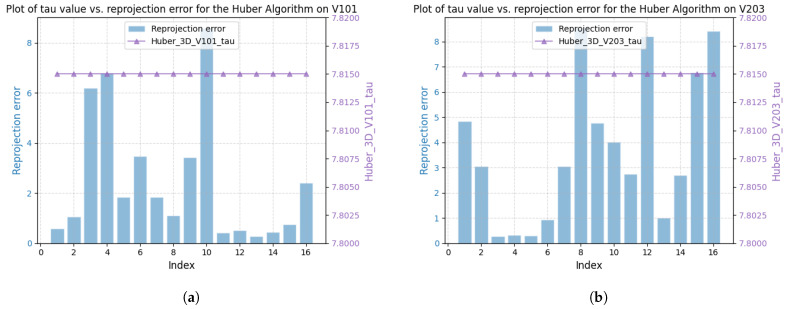 Figure 4
Figure 4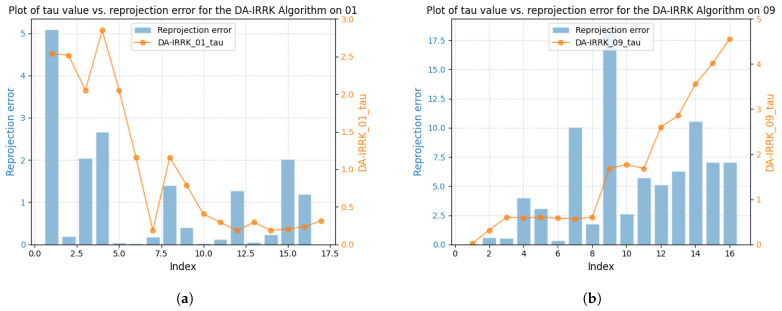 Figure 5
Figure 5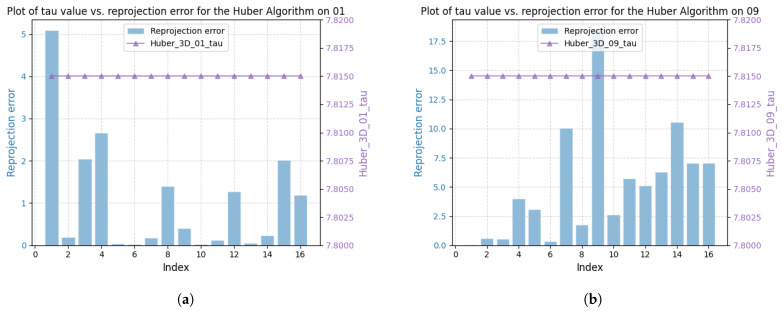 Figure 6
Figure 6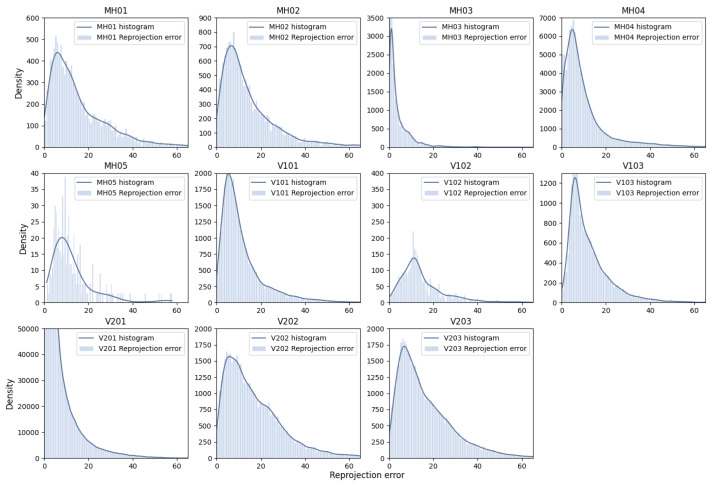 Figure 7
Figure 7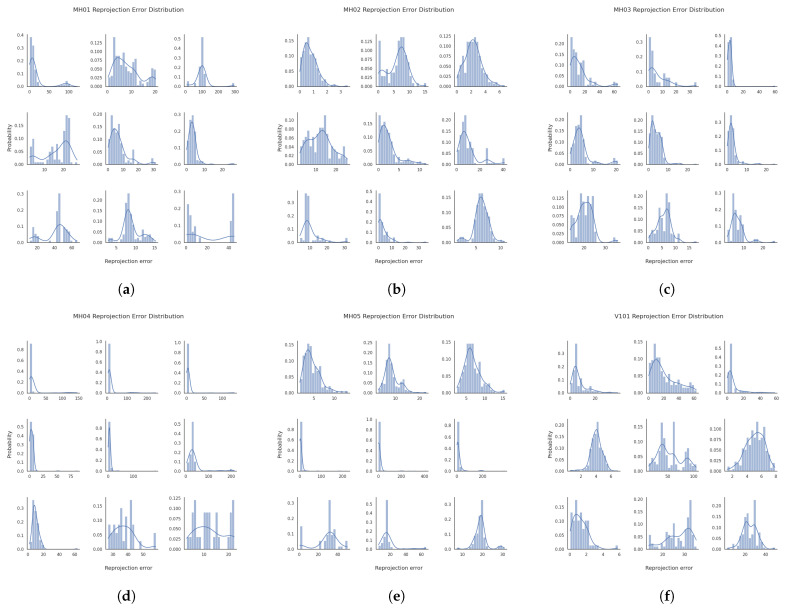 Figure 8
Figure 8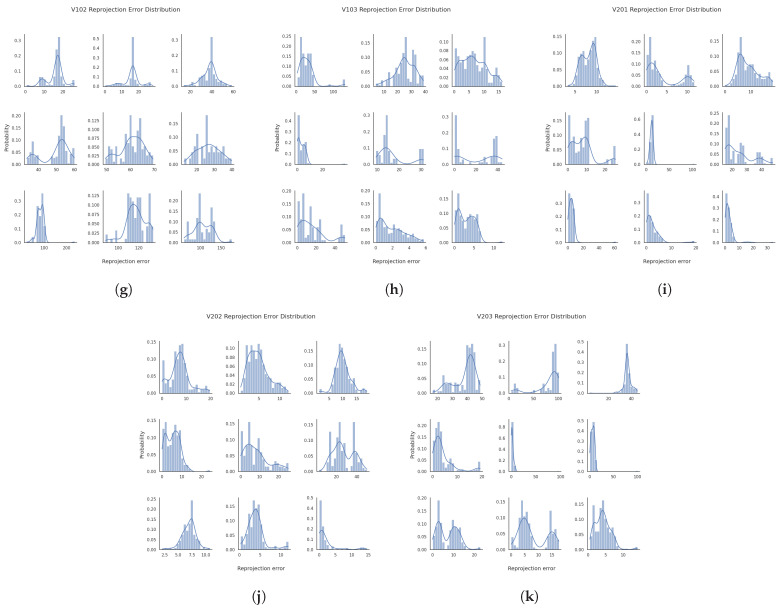 Figure 9
Figure 9 Figure 10
Figure 10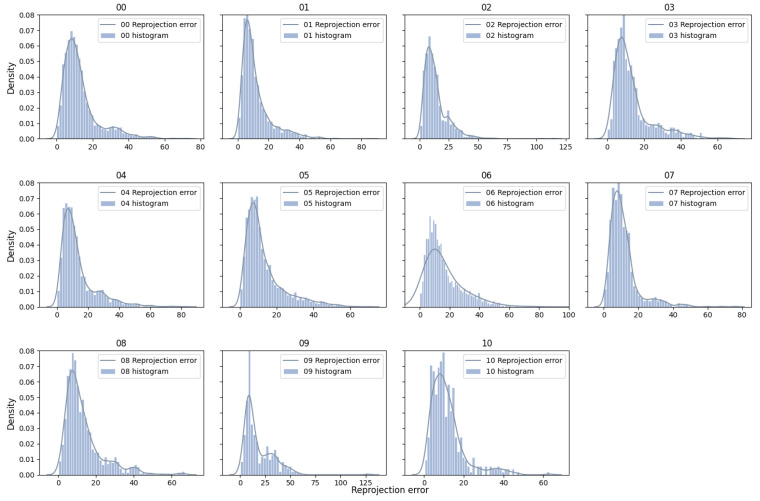 Figure 11
Figure 11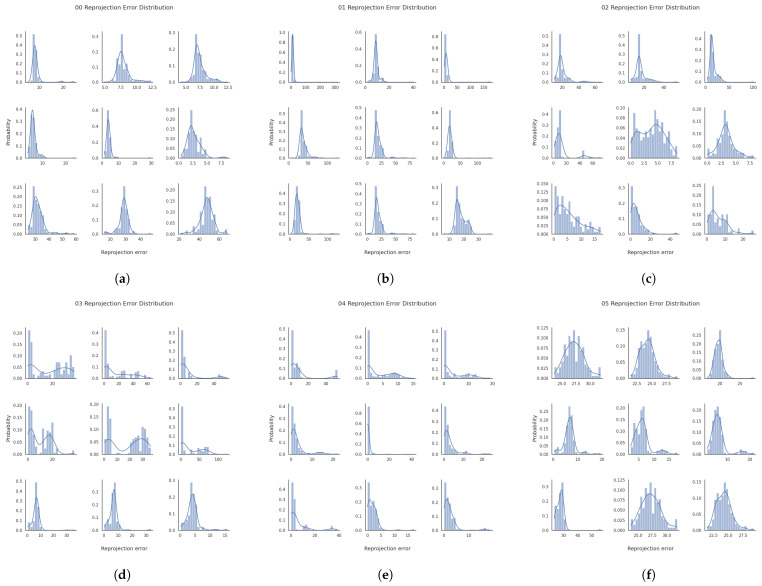 Figure 12
Figure 12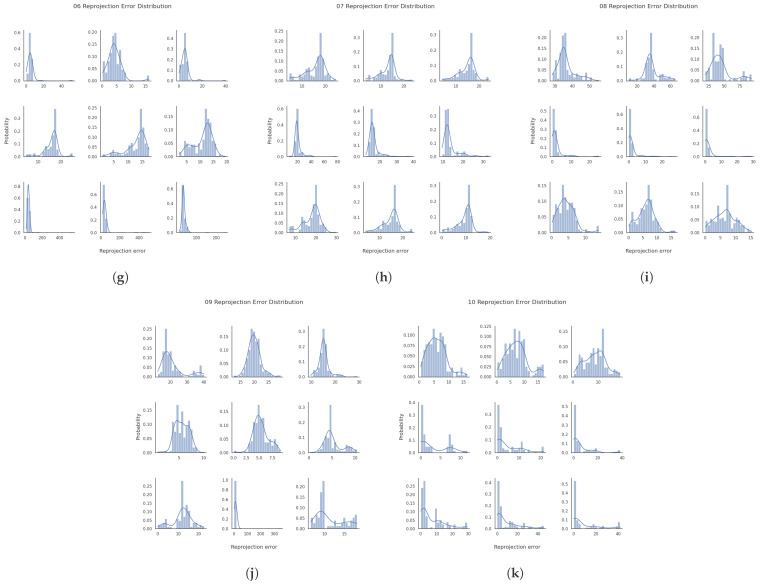 Figure 13
Figure 13 Figure 14
Figure 14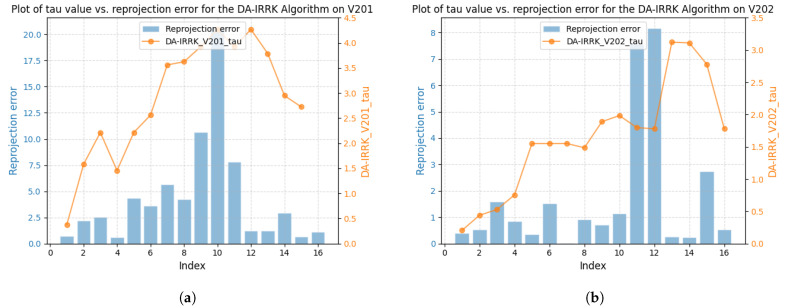 Figure 15
Figure 15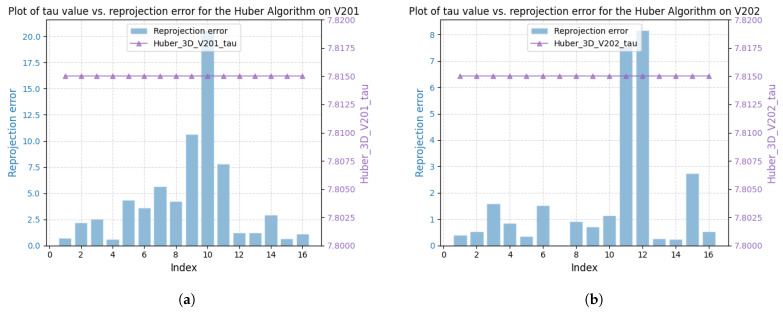 Figure 16
Figure 16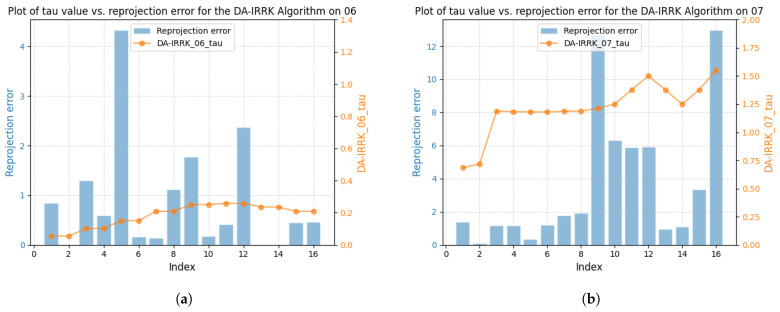 Figure 17
Figure 17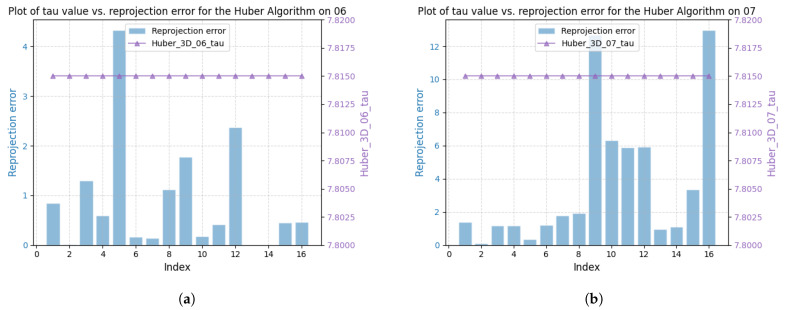 Figure 18
Figure 18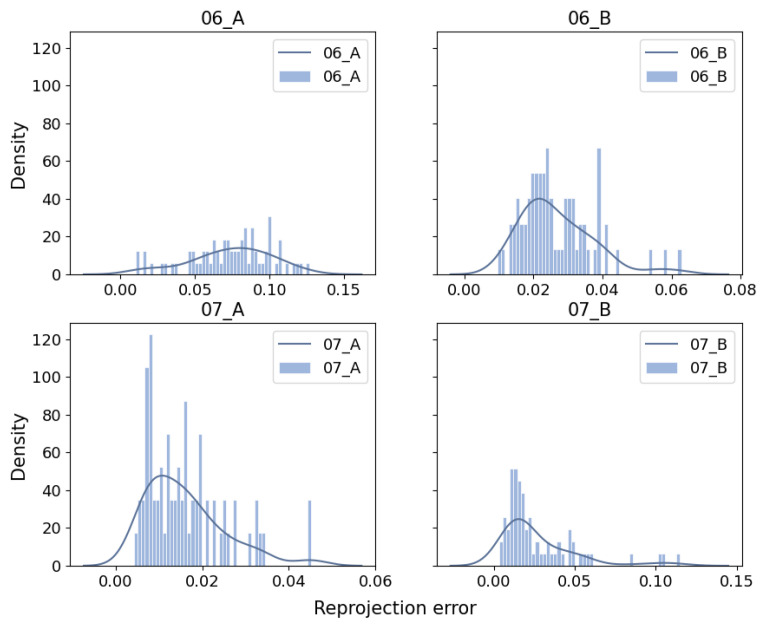 Figure 19
Figure 19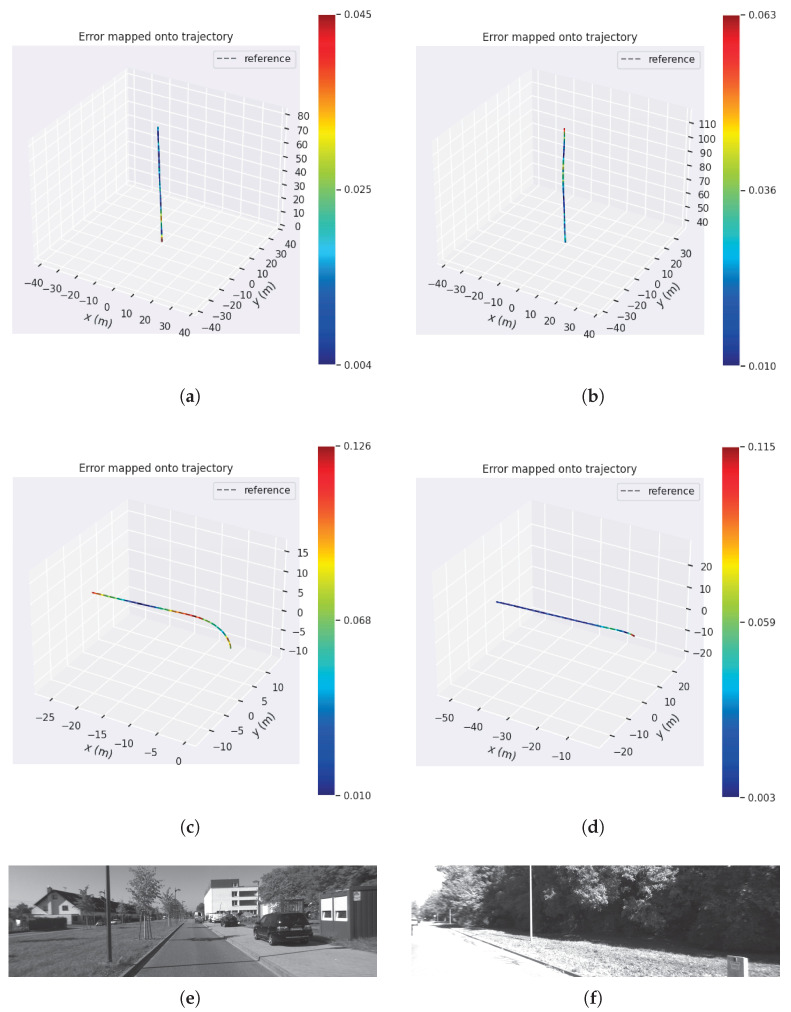 Figure 20
Figure 20- —National Natural Science Foundation of China
- —Natural Science Foundation of Shanxi Province
- —International Science and Technology Cooperation Program of Shanxi Province
- —Natural Science Foundation of Shanxi Province
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Remote Sensing and LiDAR Applications · 3D Surveying and Cultural Heritage
1. Introduction
The evolution of Visual Simultaneous Localization and Mapping (VSLAM) technology has been driven primarily by its widespread adoption in mobile robotics, autonomous navigation systems, and immersive reality applications [1]. However, real-world environmental complexities continue to challenge existing VSLAM approaches [2]. Key challenges include maintaining accuracy and robustness when processing noisy, incomplete data containing outliers.
Fundamentally, VSLAM solves state estimation by determining camera poses and reconstructing 3D environments from visual data. The technique’s dependence on visual features makes it vulnerable to motion artifacts and texture ambiguities [3]. Mismatched feature correspondences often generate outliers that compromise system accuracy [4].
Back-end optimization plays a pivotal role in refining VSLAM’s mapping precision. Pioneer VSLAM implementations predominantly utilized filter-based back-end optimizations. Such filters often fail to achieve global consistency while exhibiting outlier sensitivity [5]. Modern VSLAM systems like ORB-SLAM2/3 [3,6] predominantly leverage nonlinear optimization.These approaches formulate pose estimation and mapping as optimization tasks, minimizing cost functions through specialized algorithms.
Contemporary frameworks like ORB-SLAM3 and CCM-SLAM [7] enhance robustness through kernel-function-based optimization. Conventional implementations typically employ fixed-parameter kernel functions. Diverse kernel functions (Huber, Cauchy, Tukey, Geman-McClure) [8,9,10,11] have emerged for different scenarios. Kernel selection remains challenging, given environmental variability and limited function choices. Parameter estimation is further complicated by interdependent shape and scaling parameters. Moreover, few enhanced methods have been validated in actual VSLAM implementations.
To address the above issues, various recent studies have considered data adaptation methods. Ref. [12] proposed a generalized robust loss function for machine learning only. Ref. [13] proposed a new data-driven criterion to solve the robustness parameter of the Huber estimator, to achieve an adaptive Huber estimator and [14] applied the iteratively reweighted strategy to the adaptive robust parameter estimation to optimize the linear regression model problem.
Inspired by [13,14], we propose an iteratively reweighted robust kernel function method based on data adaptation to solve the VSLAM back-end optimization problem. Different from previous methods, the proposed method only needs to estimate the robustness parameter of the kernel function according to the reprojection error data in VSLAM, which can avoid the coupling problem of multi-parameter estimation. Furthermore, the robustness parameter can be adaptively adjusted according to the environmental changes to achieve better optimization results for different scenes. Our main contributions are as follows:
- (1)A data-adaptive iteratively reweighted robust kernel-based (DA-IRRK) method is proposed for back-end optimization in VSLAM. In this method, a kernel function is adopted as the objective function for the back-end optimization problem. The robustness parameter in the kernel function is adaptively updated according to the reprojection error, which is reflected through the median absolute deviation (MAD). The proposed method brings out robustness for different scenarios. In addition, the formulated back-end optimization problem is solved iteratively through a reweighted updating process.
- (2)The proposed method is implemented in different VSLAM frameworks, including ORB-SLAM3, JORB-SLAM, and CCM-SLAM, to demonstrate its effectiveness in visual-only SLAM, multi-sensor fusion SLAM, and collaborative VSLAM. The proposed method is tested on both indoor and outdoor datasets and compared with other robust kernel methods as well as the state-of-the-art MCMCC method.
- (3)The performance difference between the proposed method and other methods is analyzed from the perspective of reprojection error statistics, which provides insights into the VSLAM back-end problem in the context of adaptivity.
The remainder of the paper is organized as follows. Section 2 reviews related work on the VSLAM framework and back-end optimization. Section 3 describes the back-end optimization problem in VSLAM, presents the proposed DA-IRRK method, and takes the Huber kernel as an example to demonstrate the implementation of the DA-IRRK method. Section 4 shows experimental validation for three different modes of visual-only SLAM, multi-sensor fusion VSLAM, and collaborative VSLAM in different VSLAM frameworks, including ORB-SLAM3, JORB-SLAM, and CCM-SLAM. Section 5 draws conclusions and outlines future work.
2. Related Work
In this section, we focus on back-end optimization methods for VSLAM. Since different VSLAM frameworks use different back-end optimization methods, we first analyze different VSLAM frameworks and then investigate the existing back-end optimization methods. Finally, we discuss data-driven adaptive-based optimization methods.
2.1. VSLAM Frameworks
VSLAM frameworks can be classified into three categories: single-robot VSLAM, multi-robot VSLAM, and CNN-based VSLAM [15]. Single-robot VSLAM systems, such as ORB-SLAM3 [6], are extensively studied for their fast speed and promising accuracy in various scenarios. Multi-robot VSLAM frameworks, such as CCM-SLAM [7] and JORB-SLAM [16], use multiple robots to map complex environments and can address the problems of high individual cost and centralized computation faced by single-robot SLAM systems [17]. Advanced CNN-based VSLAM frameworks [18,19] have also been explored due to the performance improvement by Convolutional Neural Networks (CNN). However, CNN-based VSLAMs, often time-consuming and scenario-specific, need further performance enhancements for real-time applications. In this study, we adopt the single-robot SLAM framework ORB-SLAM3 and the multi-robot VSLAM frameworks CCM-SLAM and JORB-SLAM to demonstrate and verify the proposed method.
2.2. Back-End Optimization
Back-end optimization refines the preliminary estimates from the front end in VSLAM. Filter-based [5] methods and nonlinear optimization methods [20] are currently the most popular for back-end optimization. In early VSLAM implementations, filter-based methods, such as the Extended Kalman Filter (EKF) method, were prevalent. However, the EKF lacks an outlier elimination mechanism [21,22], and even a few outliers may significantly degrade the optimization performance. Furthermore, in large-scale VSLAM, the growing number of frames and map points slows the optimization process as it requires dynamic updates of both the mean and the variance, along with the state size. On the other hand, nonlinear optimization methods, such as bundle adjustment, which formulate the state estimation of the camera pose and map points as an optimization problem, dominate the mainstream SLAM frameworks (such as PTAM [23], ORB-SLAM3, and DSO [24]). Notably, most modern SLAM systems, including ORB-SLAM3, rely on general-purpose optimization back-ends like g2o [25] rather than implementing their own optimization modules. These frameworks usually adopt Gauss–Newton [26] or Levenberg–Marquardt (L–M) algorithms [27] to solve the optimization problem.
2.3. Robust Kernel Functions
Most nonlinear optimization methods aim to minimize the sum of squared error to counter mismatches. If the data samples are outliers, this approach tends to fail to identify incorrect data and cause estimation errors. Consequently, using robust kernel functions as the objective function has become a common practice to prevent errors on one edge from overshadowing others [28]. Refs. [4,29] applied these kernel functions to various estimation problems in computer vision and robotics. Ref. [30] analyzed popular robust kernel functions for alignment problems, offering suggestions for kernel function selection based on the application scenarios.
However, the abovementioned methods manually select different robust kernel functions depending on the situation, lacking flexibility and robustness for new scenes. Ref. [31] introduced a generalized adaptive robust kernel function, which makes the above robust kernel functions a special case of the generalized robust kernel function. By setting the shape parameter differently, the generalized adaptive robust kernel function can automatically select a suitable robust kernel function according to different situations. Ref. [32] improved the generalized robust kernel family based on [31] by adapting robust kernel shapes through the probability distribution of the generalized loss function and applying the improved method to nonlinear optimization problems. Ref. [33] associated the M-estimator with an elliptic probability distribution. They estimate hyper-parameters for each kernel type based on the residual distribution and perform model comparisons to determine the best kernel for the situation at hand. All of the above adaptive methods focus on estimating shape parameters and then finding a suitable robust kernel function.
2.4. Adaptive Methods
With the popularity of data-driven approaches, various recent works have reconsidered data-adaptive methods, giving rise to two fundamental parameter optimization paradigms: adaptive methods and self-learning mechanisms [34]. Adaptive methods (e.g., the M-estimator parameter adjustment proposed by [35]) primarily tune model parameters by analyzing real-time data distribution characteristics (such as reprojection errors), with [35] demonstrating that such adaptive methods significantly enhance robustness compared with static M-estimators across different data distributions. In contrast, self-learning mechanisms (as seen in recent path planning research) achieve continuous system self-optimization through built-in feedback loops.
Early ideas for adaptively choosing the tuning parameters of M-estimators are presented in [35] based on different data distributions. Recent studies by [13,36] have further validated the necessity of data-dependent adjustment for Huber estimator parameters to effectively suppress outliers, showing these adaptive parameters can be customized according to variations in sample size, dimensionality, and noise characteristics. Ref. [14] advanced this direction by combining iteratively reweighted least squares with adaptive algorithms for parameter estimation, successfully applying this methodology to linear regression model optimization problems.
In this paper, we propose a data-adaptive iteratively reweighted robust kernel-based (DA-IRRK) approach by drawing on the data-driven adaptive robust Huber kernel function method and iteratively reweighted strategy in [14,35], in which the robustness parameter of the robust kernel function is adaptively changed based on the distribution of reprojection error in the real environment, rather than a fixed robustness parameter in all cases. The proposed method can be implemented in the back end of any VSLAM framework.
3. Back-End Optimization Based on DA-IRRK
Figure 1 illustrates the general VSLAM framework that the proposed back-end optimization method applies to. We focus on the VSLAM back-end module. We elaborated the proposed method and its implementation following the preliminary work related to back-end optimization.
3.1. Back-End Optimization
State estimation in VSLAM involves determining the unknown parameters of the motion model based on noisy observations , which include camera position and map point , collectively termed . The state estimation problem can be viewed as a nonlinear least squares (LS) optimization problem in the back end. While Equation (1) presents the general formulation, practical implementations in frameworks like ORB-SLAM3 using g2o solve a modified version that accounts for additional engineering considerations [25]. Back-end optimization consists of both local and global optimization: local optimization refines the pose and map points of a few keyframes locally, while global optimization optimizes all keyframes after loop closure detection. The optimization problem is typically solved by minimizing the objective function of reprojection error, expressed as follows:
where i varies from 1 to N, and N is the number of frames; j varies from 1 to M, and M is the number of map points that can be seen from the position of the i-th frame. The reprojection error, denoted as refers to the discrepancy between the camera observation and the reprojected 3D map point onto the i-th 2D frame using the projection function . The weight represents the information matrix (inverse covariance ), encoding the uncertainty of observation under the Gaussian assumption . The observation represents in the i-th frame, typically in pixel coordinates. The importance of the i-th reprojection error is represented by its weight . Figure 2 illustrates the reprojection process in VSLAM. While is statistically optimal when the error of the observation in the i-th frame follows a Gaussian distribution, it may deviate from this optimal solution in cases involving non-Gaussian noises [11].
When follows a Gaussian distribution, the weighted LS problem shown in Equation (1) can be directly solved by the Gauss–Newton algorithm or Levenberg–Marquardt (L–M) algorithm. However, due to the non-convex characteristics of the image and the influence of environmental noises, typically follows a sub-Gaussian distribution or non-Gaussian distribution. The estimation results obtained using only the Gauss–Newton algorithm or L–M algorithm often deviate from the true value, leading to a decrease in localization and mapping accuracy in VSLAM.
3.2. DA-IRRK
In the field of VSLAM, heavy-tailed distribution data affected by sub-Gaussian or non-Gaussian noises are often observed in both datasets and real scene experiments, leading to results with large errors [37]. Robust kernel functions with specific robustness parameters are widely used in the field of VSLAM to solve the back-end optimization problem and improve mapping accuracy, as the robustness parameter can balance accuracy and robustness. According to [38], the robustness parameter should be adapted to the sample size, dimensionality, noise variance, and confidence level of the experimental data. While Equation (2) presents a general form of robust kernel formulation, practical implementations like ORB-SLAM3 properly incorporate the information matrix of measurements when applying the Huber kernel in their g2o-based optimization back-end. In VSLAM, Equation (2) shows the objective function based on the robust kernel function, where represents the robust loss or kernel.
In previous studies, the robustness parameter is typically set to a fixed value to adapt to specific scene noises. However, this approach requires re-determining the robustness parameter whenever the scene changes, which results in the designed back-end optimization algorithm having poor robustness and low mapping accuracy in practical applications. To address this issue, an adaptive back-end optimization algorithm is proposed that can adaptively adjust the robustness parameters according to different scenarios, thereby improving the robustness of the back-end and enhancing the mapping accuracy.
The Huber kernel function is a popular robust kernel function in VSLAM, which is widely used in mature VSLAM back-end optimization modules such as ORB-SLAM2 and ORB-SLAM3. Therefore, in the following algorithm presentation, the proposed method is demonstrated using the Huber kernel function as an example. The Huber kernel function and its corresponding first-order derivatives are presented in Equations (3) and (4), where represents the robustness parameter and e is the error.
Equations (3) and (4) demonstrate that plays a crucial role in determining the weight of the errors in the optimization process. When e is less than or equal to , the back-end optimization problem based on the Huber kernel function can be regarded as an LS problem, corresponding to the case where in Equation (1). On the other hand, when e exceeds , the influence of error samples on the optimization process is significantly suppressed. A comprehensive analysis provided by [20] concludes that the choice of determines the robustness and sensitivity of the back-end optimization algorithm. Therefore, we propose an adaptive tuning approach for in our back-end optimization algorithm based on the Huber kernel function. The aim is to solve the optimization problem shown in Equation (2) using an iteratively reweighted strategy.
To solve Equation (2), we utilize the adaptive method proposed by [39] and integrate it with existing back-end optimization algorithms, such as the L–M algorithm, which can be implemented in the following five steps:
- (1)Calculate the current reprojection error based on the camera pose and map points at the front end;
- (2)Determine the adaptive threshold according to Equation (6) after computing the MAD of reprojection errors using Equation (5), where represents the median of a set of data and represents the i-th sample in the set. The MAD strategy is preferred over standard deviation due to its higher breakdown point (50% vs. 0%) for outlier resistance [40], which is crucial for handling outliers in SLAM. The coefficient 1.4826 in Equation (6) equals , where is the inverse standard normal CDF. This scaling ensures matches the standard deviation for normally distributed data, maintaining compatibility with Gaussian kernels [41]. This adaptive mechanism enables automatic adjustment of the robustness parameters based on real-time sensor data characteristics, representing a key advantage over traditional fixed-parameter methods like MCMCC. These computations are performed in the tangent space of the manifold, which provides a vector space approximation for the nonlinear optimization problem while maintaining the geometric properties of the original space. It is worth noting that the MAD strategy may not be sufficiently robust for data distributions containing a larger number of large outliers;
- (3)Calculate the robustness parameter in the Huber kernel function using Equation (7), where c represents the scaling factor. The scale factor corresponds to 95% confidence. is the vector form of ;
- (4)Solve the objective function iteratively through a reweighted updating process;
- (5)Utilize the L–M algorithm to update the camera pose and map points.
After completing the previous three steps, it is necessary to find the derivative of before performing the subsequent steps, which are represented as Equation (8), and the iteratively reweighted strategy is used for further simplification, as in Equation (9). The iteratively reweighted strategy has also been used in [42] to achieve reweighting in the optimization equations, and experimental results show its effectiveness.
where the first-order derivative of is defined as , represents the influence function and is the weight function. After simplifying Equation (2) using the iteratively reweighted strategy described above, the optimization of Equation (2) can be further achieved by the L–M algorithm.
In the L–M algorithm, the projection equation is firstly Taylor expanded (Equation (10)), then Equations (11) and (12) are solved sequentially, and finally, the matrix form of the solution to Equation (12) is expressed as Equation (13), which is the update vector of the L–M algorithm after adding the damping coefficient (Equation (14)).
where is treated as a diagonal matrix.
During the iteration process, when approaches zero, it signifies that the L–M algorithm behaves similarly to the Gauss–Newton method. Conversely, a high damping coefficient aligns the update vector with the direction of the gradient, making the L–M algorithm a compromise between the Gauss–Newton algorithm and gradient descent. The implementation of the proposed method DA-IRRK is summarized in Algorithm 1.
It is worth noting that is updated in each iteration, which is also why we name our method an iterative reweighted method. As the iteration carries on, the weight reflects the importance of each with better and better accuracy, leading to the approaching of the global solution. Algorithm 1 DA-IRRK-based back-end optimization.Require: Camera pose and map point , denoted as in the algorithm; Ensure: Updated model parameters and ;
- 1:Initialization: Set the initial camera pose and map point . Define the robustness parameter of the robust kernel and set the parameter of the DA-IRRK method to zero;
- 2:for to N do
- 3: if then
- 4: Calculate the using , update using Equation (2);
- 5: Compute and according to Equations (5)–(7);
- 6: Define the updated as , which is passed into the DA-IRRK algorithm;
- 7: else
- 8: With the incoming and updated , compute of the DA-IRRK method using Equation (7);
- 9: Substitute the obtained into Equations (3) and (4);
- 10: The objective function of Equation (2) is derived using Equations (8)–(10) to obtain the update quantity ;
- 11: Equation (13) is deformed into Equation (14) and and are updated iteratively using the L–M algorithm;
- 12: end if
- 13:end for
4. Experiments
We evaluate the proposed DA-IRRK method along with other robust kernel function-based back-end optimization methods on both indoor and outdoor datasets in different VSLAM frameworks, including ORB-SLAM3, CCM-SLAM [7], and JORB-SLAM [16]. The EuRoC dataset is utilized for indoor testing, while the KITTI dataset is used for outdoor validation to assess the accuracy and robustness of the DA-IRRK method. Eigen3 [43], G2O [25], PCL [44], Pangolin [45], and OpenCV [46] are employed for implementing the proposed method. All experiments are conducted on a laptop with an Intel Core i5 12400F CPU and 16 GB of RAM running Ubuntu 18.04. Here, we present the detailed implementation of the DA-IRRK method for visual SLAM back-end optimization, specifically realized within the Edge and Solver modules of the G2O library.
Adaptive Edge Module: New EdgeSE3-DAIRRK class implements the following:
- Dynamic kernel parameter computation (Equations (5) and (6)).
- Real-time robust kernel selection (Equation (7)).
- Information matrix weighting mechanism. Solver Module: Enhanced LinearSolverEigen features the following:
- Optimized sparse matrix storage pattern.
- Improved marginalization strategy.
4.1. Experimental Datasets
The DA-IRRK method was evaluated across two distinct environments: indoor scenarios using the EuRoC dataset [47] and outdoor settings with KITTI [48]. EuRoC captures three environment types: ETH Zurich’s machine halls (MH01-MH05), calibration chambers (V101-V103), and standard rooms (V201-V203). Based on feature availability and UAV flight dynamics, EuRoC sequences are categorized by difficulty:
- Simple: MH01 (80.6 m), MH02 (73.5 m), V101 (58.6 m), V201 (36.5 m).
- Moderate: MH03 (130.9 m), V102 (75.9 m), V202 (83.2 m).
- Challenging: V103 (79.0 m), V203 (86.1 m), MH04 (91.7 m), MH05 (97.6 m).
The KITTI dataset includes urban, residential, rural, and highway scenarios. The primary data acquisition equipment includes a 64-beam Velodyne laser scanner, four cameras, and a GPS/IMU unit. We select 11 sequences (00–10) to verify the proposed method in the outdoor environment. The sequence lengths are as follows: sequence 00: 3724.187 m; sequence 01: 2453.203 m; sequence 02: 5067.233 m; sequence 03: 560.888 m; sequence 04: 393.645 m; sequence 05: 2205.576 m; sequence 06: 1232.876 m; sequence 07: 694.697 m; sequence 08: 3222.795 m; sequence 09: 1705.051 m; sequence 10: 919.518 m.
4.2. Experimental Frameworks and Evaluation Benchmarks
4.2.1. Experimental Frameworks
We evaluate the robustness of the proposed method by implementing it in ORB-SLAM3 for single-robot applications and in JORB-SLAM and CCM-SLAM for multi-robot systems.
ORB-SLAM3 is a single-robot VSLAM framework that supports multiple cameras and offers visual, visual-inertial, and multi-map SLAM for various applications. It is regarded as the most advanced VSLAM framework to date and is widely used as a benchmark for both indoor and outdoor testing. Notably, the DA-IRRK method is evaluated in ORB-SLAM3 for both single-robot VSLAM and multi-sensor fusion-based VSLAM, as the framework supports both visual-only and visual-inertial modes.
JORB-SLAM is a feature-based multi-robot VSLAM framework that extends ORB-SLAM2 to multiple agents, focusing on rapid map fusion and improved coverage. The system includes multiple ORB-SLAM2 clients for local mapping and a central server for global map fusion. The DA-IRRK method is tested within this framework, as it enhances robustness by adding additional constraints to the AprilTag.
CCM-SLAM is a centralized collaborative multi-robot VSLAM framework based on ORB-SLAM2 that ensures agent autonomy while fostering cooperation through a central server for map fusion and optimization, maintaining efficiency despite potential data loss or delays. Unlike JORB-SLAM, where each agent runs a complete sub-map, CCM-SLAM is widely used as a comparative collaborative VSLAM framework for multi-agent applications, such as CORB2I-SLAM [49] and COVINS [50]. We implement the DA-IRRK method in each CCM-SLAM agent and verify the performance improvement after modification.
4.2.2. Evaluation Metrics
The Absolute Trajectory Error (ATE) [51] is a widely used metric in VSLAM evaluation, measuring the global consistency of the estimated trajectory by comparing it to the ground truth. The accuracy is expressed through the Root Mean Square Error (RMSE) of the ATE. In this paper, the EVO [52] tool is used to compute ATE, providing an assessment of the trajectory accuracy of the VSLAM system against the ground truth. EVO also offers data analysis and visualization for odometry and SLAM evaluation.
4.3. Case Study
4.3.1. Visual-Only SLAM
This section evaluates the proposed method in visual-only SLAM mode using ORB-SLAM3 with a single agent and a visual sensor. We compare it with three robust kernel-based methods (Huber, Tukey, and Cauchy, all using ORB-SLAM3’s default kernel parameters) and the state-of-the-art (SOTA) method, MCMCC [42], to assess the RMSE of ATE across different scenarios using the EuRoC and KITTI datasets. Monocular scale blur causes errors in ORB-SLAM3 in open environments, complicating comparisons. Therefore, we evaluate these methods solely in stereo mode, with results presented in Table 1 and Table 2, where the top performer is bolded and the second-best is underlined.
Table 1 demonstrates that the proposed DA-IRRK method achieves higher accuracy in most indoor sequences compared with other methods, while the MCMCC method outperforms ours on MH03, V103, V201, and V203. Table 2 shows that the proposed DA-IRRK method shows lower accuracy than the comparing methods in sequences 03, 06, 09, and 10 on the KITTI dataset. Meanwhile, the MCMCC method outperforms ours in sequences 03 and 10. The analysis method in Table 2 is the same as that in Table 1.
(a)Adaptive Robustness in DA-IRRK vs. Fixed-Parameter Huber Kernel
To further investigate these findings, we analyze sequences V101 and V203 for the EuRoC dataset and sequences 01 and 09 for the KITTI dataset as examples. As noted in Section 3.2, the DA-IRRK method adaptively adjusts the robustness parameter based on reprojection errors to minimize the impact of outliers on mapping accuracy, employing the MAD strategy for robust estimation of data distributions containing outliers (refer to Equations (5)–(7) in Section 3.2).
Figure 3 shows the correlation between reprojection error and robustness parameter for sequences V101 and V203 using the DA-IRRK method, while Figure 4 presents the same for the robust Huber kernel method. The Huber kernel’s robustness parameter is fixed at 5.99 for monoculars and 7.81 for stereo cameras, calculated using the chi-square test [41]. Unlike the Huber kernel, DA-IRRK’s parameter varies with reprojection errors, reflecting its data-dependent adaptation. However, the MAD-based estimation in DA-IRRK exhibits sensitivity to extreme outliers, leading to suboptimal performance in sequences like V203 with pronounced non-Gaussian noise (e.g., due to motion blur). Similarly, Figure 5 and Figure 6 show how robustness parameters and reprojection errors vary when applying DA-IRRK and the robust Huber kernel methods to ORB-SLAM3 on sequences 01 and 09. While DA-IRRK’s parameter varies with error, the Huber kernel’s remains constant. Sequence 09 exhibits larger reprojection errors, corresponding to higher robustness parameters. However, as is derived from the median error, its magnitude does not strictly correlate with error size—a limitation that occasionally compromises accuracy.
(b)Noise Distribution Analysis and MAD Strategy Efficacy
We assess the impact of the MAD strategy by visualizing the reprojection error distributions for both global and local keyframes in individual sequences from the EuRoC dataset, as shown in Figure 7 and Figure 8. The reprojection error distributions of global keyframes in each sequence show a non-Gaussian pattern. In contrast, local keyframes (Figure 8)—sampled at critical phases (initialization, motion bursts, and stable tracking)—reveal sub-Gaussian distributions for sequences MH01, MH02, MH04, MH05, V101, V102, and V202, while others (e.g., MH03, V201, V203) retain non-Gaussian traits. The MAD-based DA-IRRK method effectively suppresses sub-Gaussian heavy-tailed outliers, achieving superior accuracy in 7 of 11 sequences (Table 1). However, its performance lags behind MCMCC for non-Gaussian outliers (e.g., V203), highlighting a limitation in handling extreme noise. This instability warrants future improvement, as noted in Section 5. Specifically, Figure 7 shows that reprojection errors in sequence V101 are mainly concentrated in the range of 0 to 20, with fewer errors between 20 and 60. In contrast, for sequence V203, errors are concentrated in the 0 to 20 range, but more errors fall between 20 and 60, impacting mapping accuracy. It is important to note that the results presented are snapshots selected from local optimal optimizations at random instances. Reprojection error distributions vary across different instances.
To investigate the root reason for varying reprojection error distributions, we analyze the scenes of sequences V101 and V203. In Figure 9, sequence V101 features brighter scenes and sequence V203 displays blurred scenes caused by fast-moving UAVs. V101 is captured when the UAV flies slowly, resulting in clear scene graphs. On the other hand, sequence V203 is recorded when the UAV is fast-moving, leading to a blurred texture in the scene graph [47]. As a consequence, the front-end feature extraction and matching process of VSLAM produces more mismatches due to the blurred texture, thereby increasing both the number and magnitude of reprojection error outliers.
The reprojection error distributions of individual sequences from the KITTI dataset in global and local keyframes are shown in Figure 10 and Figure 11. The results indicate that reprojection errors of global keyframes tend to be non-Gaussian distributed, while those of local keyframes are prone to be sub-Gaussian distributed on sequences 00, 01, 02, 04, 05, 07, and 08, whereas on the other sequences, the reprojection errors tend to be non-Gaussian distributed, both in the global keyframes and the local keyframes. Combined with Table 2, we can see that the MCMCC method proves effective at suppressing outliers of non-Gaussian type with heavy-tailed distribution, leading to higher mapping accuracy for sequences 03 and 10.
Specifically, Figure 11 shows that most reprojection errors of sequence 01 are concentrated within the range of 0 to 20, with only a few error samples in the range of 20 to 60. In contrast, reprojection errors of sequence 09 reach a maximum of 125, and a large number of reprojection errors lie in the range of 25 to 75. The average error is larger than that on the other seven sequences, causing the degradation of the mapping accuracy.
Figure 12 shows that sequence 01 exhibits clearer and more static features with minimal lighting variations, while sequence 09 contains dynamic elements (e.g., a moving car) and displays obvious lighting variations. For sequence 09, the effects of lighting and dynamic features result in more and larger reprojection error outliers.
Based on the above analysis, the results on the KITTI dataset coincide with those on the EuRoC dataset, both demonstrating the effectiveness of the proposed DA-IRRK method for single-robot VSLAM applications with the visual-only case.
4.3.2. Multi-Sensor Fusion VSLAM
To test the proposed DA-IRRK method in a multi-sensor fusion VSLAM mode, we also consider using ORB-SLAM3 in stereo visual-inertial mode. We switch from the visual-only mode to the visual-inertial mode in ORB-SLAM3. In this experiment, we specifically integrate the DA-IRRK method into the g2o optimization library while keeping the IMU-related components unchanged in the backend processing pipeline. Evaluation of the EuRoC dataset is assessed using the RMSE of ATE. Since [42] did not test the proposed MCMCC method in visual-inertial mode, we only provide the results of the proposed DA-IRRK method and the robust Huber kernel method to avoid redundancy since Huber is the most widely used compared with other kernels, and it is only inferior to the proposed method and MCMCC according to Table 1 and Table 2. Detailed results are presented in Table 3, where the top performer is bolded. The third-row Impr_huber in Table 3 quantifies the improvement of the proposed method compared with the Huber function-based method.
Table 3 shows that mapping accuracy has been improved on 9 out of 11 sequences, with 6 sequences indicating an improvement of more than 10%. The highest accuracy improvement is seen at 26.29%. Only the accuracy of mapping on sequences V201 and V203 decreases but by less than 9.5%. This serves as evidence of the effectiveness of the DA-IRRK method in visual-inertial mode.
To analyze the reasons for the degradation of mapping accuracy on sequences V201 and V203, we conducted a comparative analysis using sequences V201 and V202 as examples. In accordance with Section 4.3.1, our analysis begins with the proposed DA-IRRK method. Figure 13 and Figure 14 show the relationship between reprojection error and robustness parameters for both methods on sequences V201 and V202. The results consolidate those in the visual-only SLAM case.
4.3.3. Collaborative VSLAM
In this subsection, the effectiveness of the DA-IRRK approach is tested in collaborative VSLAM frameworks such as JORB-SLAM and CCM-SLAM, with only two agents adopted. Specifically, as in [7,16], we also test the proposed method in JORB-SLAM on the KITTI dataset and CCM-SLAM on the EuRoC dataset. JORB-SLAM divides a trajectory segment into overlapping parts in its experiments to achieve mapping through multi-robot collaboration, while CCM-SLAM achieves mapping by multiple robots collaborating to run respective maps.
In the experiments with CCM-SLAM, sequences from EuRoC are paired together (e.g., MH01-MH02, where agent A runs MH01 and agent B runs MH02) with map fusion performed at a central station. Evaluation is based on the RMSE of ATE compared only with the most widely used robust Huber kernel to avoid redundancy. Results are detailed in Table 4 and Table 5. The third row, Impr_huber, in Table 4 and Table 5, quantifies the improvement of the proposed method compared with the Huber function-based method.
The rule is developed to evaluate accuracy within a collaborative framework: the accuracy of the final trajectory is considered improved if both agent A and agent B enhance their trajectory accuracy after running on the dataset; additionally, the accuracy of the final trajectory is also considered enhanced if only one agent (A or B) improves its trajectory accuracy after running on the dataset but with the improvement higher than the accuracy degradation of the other; conversely, in any other case, we consider the accuracy of the final trajectory decreased. Following the above stipulation, we can see from Table 4 that the mapping accuracy on sequences 04, 07, and 08 decreases, while the mapping accuracy on the other 7 sequences improves greatly, with sequences 01, 02, 03, 06, and 10 improving by more than 10.23%.
We take sequences 07 and 06 as an example to demonstrate the performance difference. From Figure 15 and Figure 16, the robustness parameter of the DA-IRRK method fluctuates with the reprojection error, whereas that of the robust Huber kernel method remains constant. We can also see that the robustness parameter of sequence 06 is smaller than that of sequence 07, and similarly, the reprojection error of sequence 06 is smaller than that of sequence 07, which demonstrates that sequence 06 has a better mapping accuracy, which is consistent with the results in Table 4. In the reprojection error analysis of the sub-sequences of sequences 06 and 07, as shown in Figure 17. It is worth noting that sequence 06 tends to be a sub-Gaussian distribution, while sequence 07 tends to be a non-Gaussian distribution, and according to [14], we can know that the proposed DA-IRRK method is more effective in suppressing the sub-Gaussian distribution of error data, and consequently, the mapping accuracy of sequence 06 is better.
The reprojection error is related to the actual environment, and different environments have different reprojection error distributions. As can be seen from Figure 18, the trajectory of sequence 06 is relatively simple, characterized by numerous trees and moderate lighting, which provides clearer feature points for optimal tracking. On the other hand, the scene of sequence 07 has strong lighting, resulting in unclear feature points and, consequently, more mismatches during tracking, thereby reducing mapping accuracy.
The experimental results in the CCM-SLAM framework are presented in Table 5. We can see a significant accuracy difference between the two agents on MH03-MH04 and MH04-MH05, with one agent showing a much larger improvement than the other. Table 5 reveals that the DA-IRRK method outperforms the robust Huber kernel method in terms of mapping accuracy within the CCM-SLAM framework. This unexpected result opens up new possibilities for future advancements in VSLAM collaboration by improving accuracy levels.
Summarizing the above analysis, we can conclude the proposed DA-IRRK method not only works properly in different visual collaborative SLAM frameworks but also shows better mapping accuracy, which proves the effectiveness as well as the robustness of the proposed method in collaborative VSLAM frameworks.
The experiments in Section 4.3 demonstrate that while the DA-IRRK method improves mapping accuracy over the robust Huber kernel, this comes with an increased computational cost. To evaluate real-time performance, we conducted timing analysis on the EuRoC V103 sequence using ORB-SLAM3 (Table 6, where the top performer is bolded.). Results show the DA-IRRK method maintains real-time capability (≤33 ms/frame at 30 Hz) in both visual-only and visual-inertial modes, with only marginal time increases (≤0.1 s) versus the Huber kernel. The visual-inertial mode’s reduced keyframe optimization further minimizes computational overhead. Our frame-rate compliance tests confirm the method’s practical suitability for real-time VSLAM applications.
5. Conclusions
In VSLAM, the robust kernel method is commonly used for back-end optimization, but its fixed robustness parameter limits performance in varying scenarios. To address this, we developed a data-driven, adaptive, iteratively reweighted robust kernel method to improve accuracy and robustness. Experiments in both indoor and outdoor environments show that our method outperforms robust Huber, Cauchy, and Tukey kernels, as well as state-of-the-art MCMCC methods, particularly when sub-Gaussian distributions occur during reprojection. Additionally, multi-sensor experiments reveal that our method surpasses the robust Huber kernel, with lower performance only in sequences with large reprojection errors. Furthermore, in the JORB-SLAM and CCM-SLAM frameworks, our method not only operates efficiently but also achieves higher accuracy. However, it shares a limitation with the robust Huber kernel in non-Gaussian environments, where it underperforms compared with the latest MCMCC method. Future work will focus on (1) developing data-adaptive methods for non-Gaussian features in VSLAM; (2) extending the approach to multi-modal sensor fusion applications; and (3) optimizing real-time performance for edge computing devices.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Jia Y. Yan X. Xu Y. A Survey of simultaneous localization and mapping for robot Proceedings of the 2019 IEEE 4th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC)Chengdu, China 20–22 December 2019857861
- 2Placed J.A. Strader J. Carrillo H. Atanasov N. Indelman V. Carlone L. Castellanos J.A. A survey on active simultaneous localization and mapping: State of the art and new frontiers IEEE Trans. Robot.2023391686170510.1109/TRO.2023.3248510 · doi ↗
- 3Mur-Artal R. Tardós J.D. Orb-slam 2: An open-source slam system for monocular, stereo, and rgb-d cameras IEEE Trans. Robot.2017331255126210.1109/TRO.2017.2705103 · doi ↗
- 4Zhang Z. Parameter estimation techniques: A tutorial with application to conic fitting Image Vis. Comput.199715597610.1016/S 0262-8856(96)01112-2 · doi ↗
- 5Chen S.Y. Kalman filter for robot vision: A survey IEEE Trans. Ind. Electron.2011594409442010.1109/TIE.2011.2162714 · doi ↗
- 6Campos C. Elvira R. Rodríguez J.J.G. Montiel J.M. Tardós J.D. Orb-slam 3: An accurate open-source library for visual, visual–inertial, and multimap slam IEEE Trans. Robot.2021371874189010.1109/TRO.2021.3075644 · doi ↗
- 7Schmuck P. Chli M. CCM-SLAM: Robust and efficient centralized collaborative monocular simultaneous localization and mapping for robotic teams J. Field Robot.20193676378110.1002/rob.21854 · doi ↗
- 8Huber P.J. Robust estimation of a location parameter Breakthroughs in Statistics: Methodology and Distribution Springer New York, NY, USA 1992492518