The Intrinsic Dimension of Neural Network Ensembles
Francesco Tosti Guerra, Andrea Napoletano, Andrea Zaccaria

TL;DR
This paper explores how different training strategies affect the variability and performance of neural network ensembles.
Contribution
The study introduces intrinsic dimension as a novel measure to quantify variability in neural network ensembles.
Findings
Random initialization causes more variability than data distortion, dropout, or batch shuffle.
Intrinsic dimension reflects the impact of training strategies on parameter space coverage.
Training choices significantly affect prediction accuracy and ensemble diversity.
Abstract
In this work, we propose to study the collective behavior of different ensembles of neural networks. These sets define and live on complex manifolds that evolve through training. Each manifold is characterized by its intrinsic dimension, a measure of the variability of the ensemble and, as such, a measure of the impact of the different training strategies. Indeed, higher intrinsic dimension values imply higher variability among the networks and a larger parameter space coverage. Here, we quantify how much the training choices allow the exploration of the parameter space, finding that a random initialization of the parameters is a stronger source of variability than, progressively, data distortion, dropout, and batch shuffle. We then investigate the combinations of these strategies, the parameters involved, and the impact on the accuracy of the predictions, shedding light on the…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
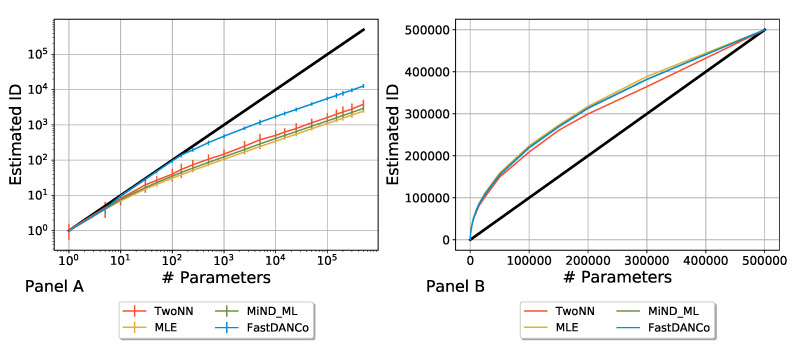 Figure 1
Figure 1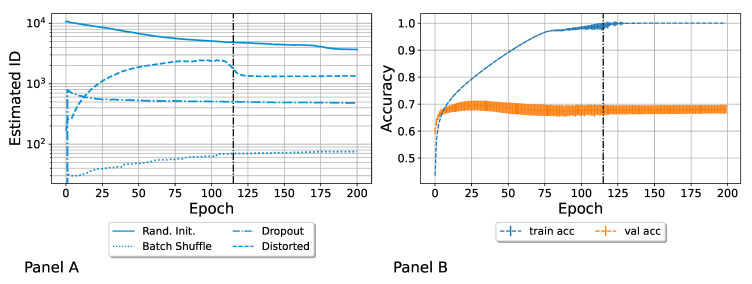 Figure 2
Figure 2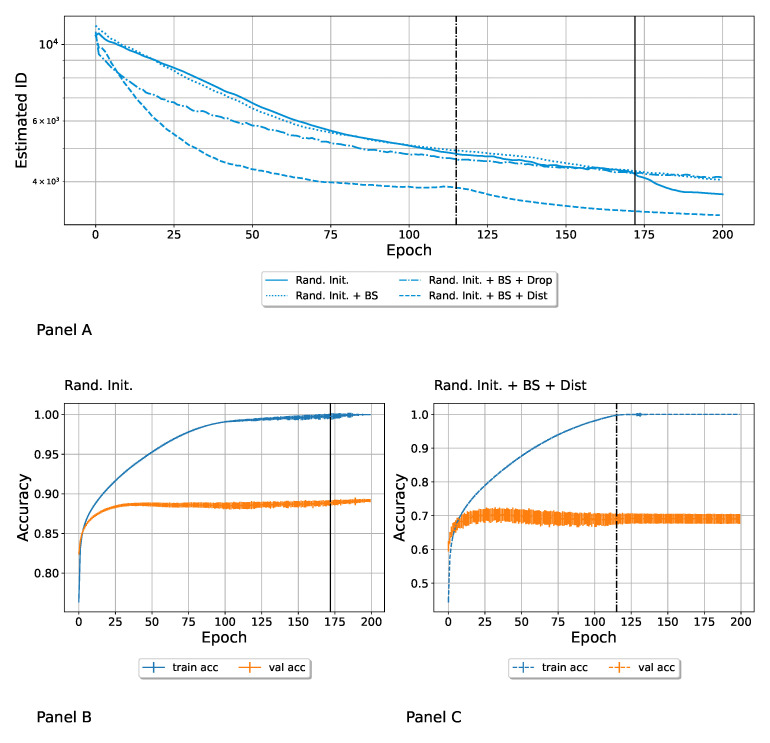 Figure 3
Figure 3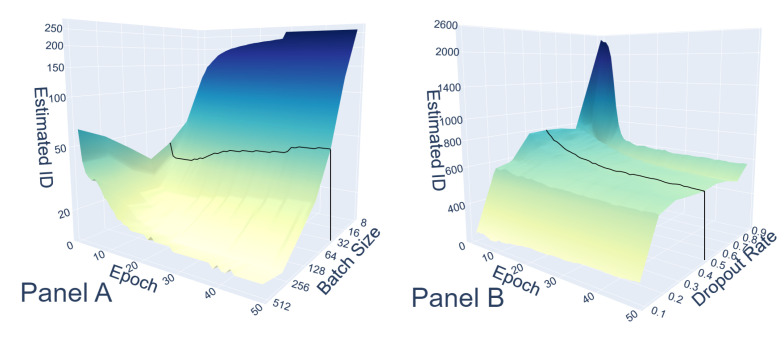 Figure 4
Figure 4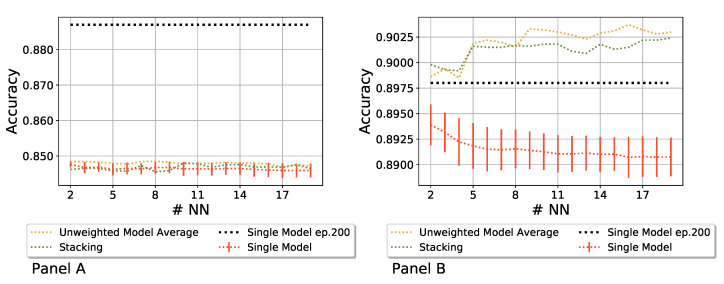 Figure 5
Figure 5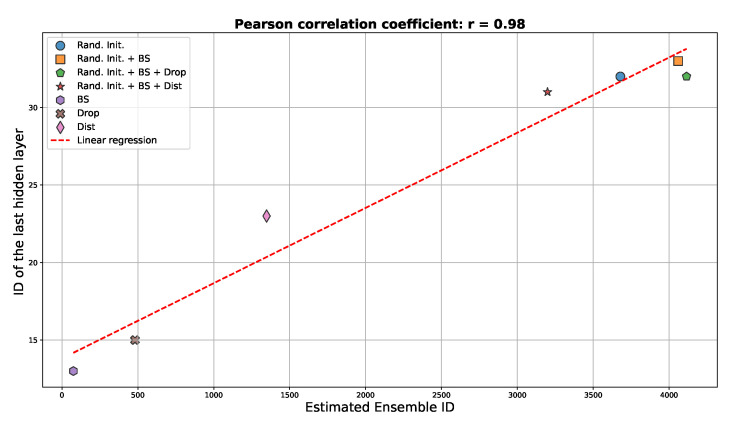 Figure 6
Figure 6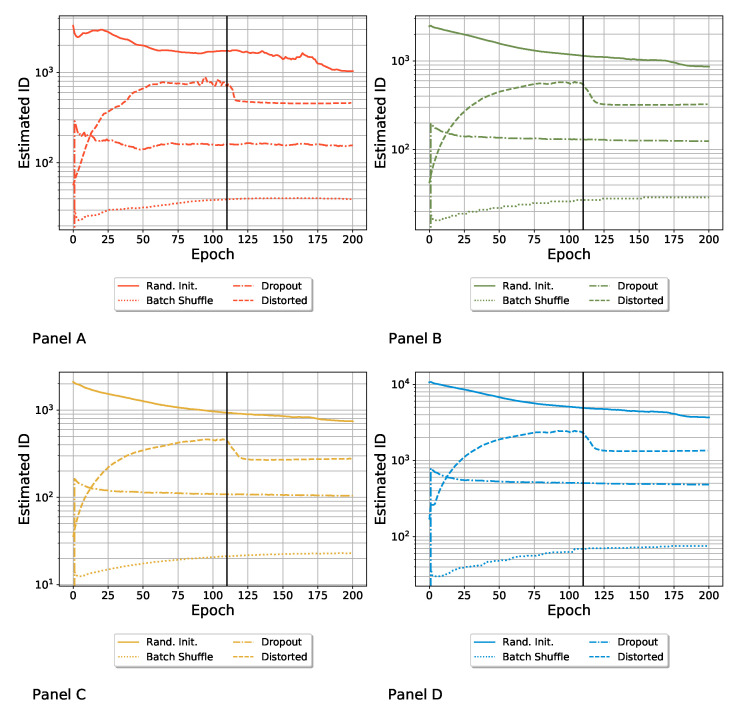 Figure 7
Figure 7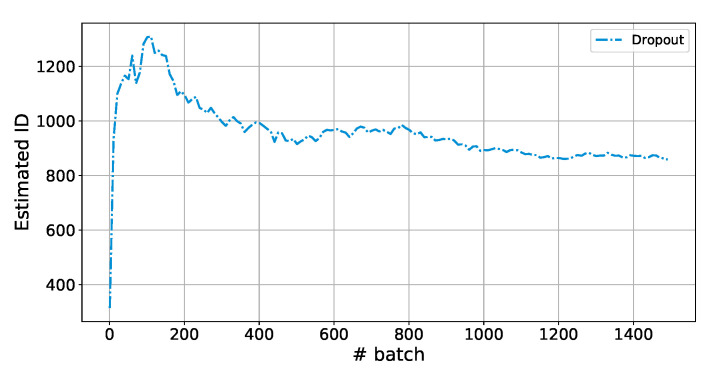 Figure 8
Figure 8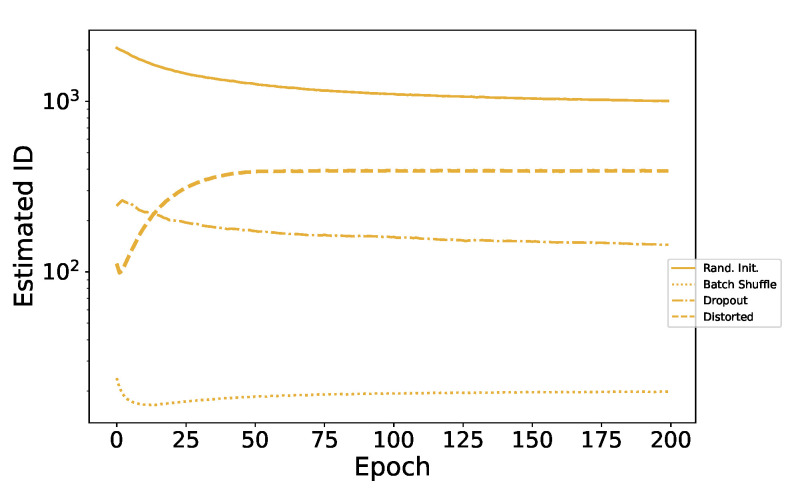 Figure 9
Figure 9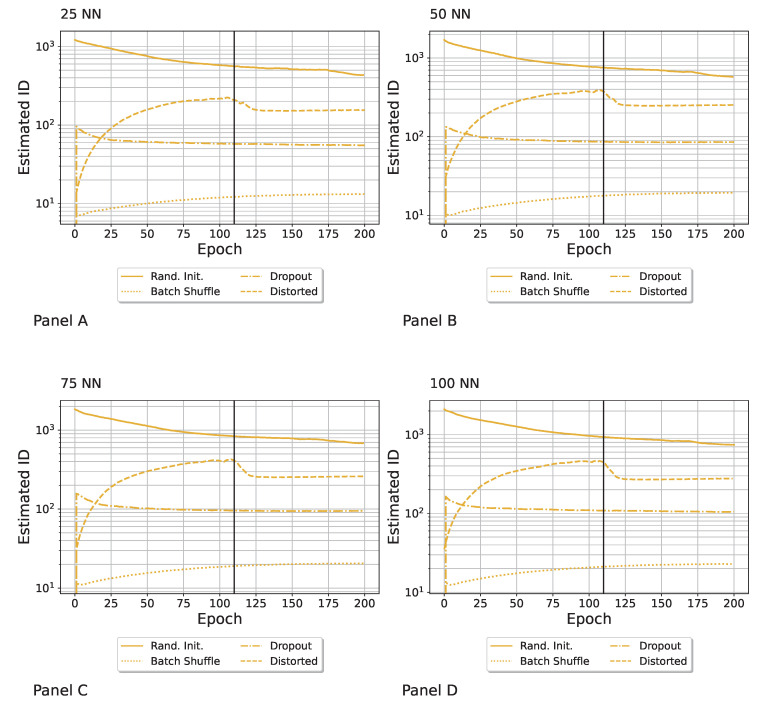 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNeural Networks and Applications · Model Reduction and Neural Networks · Generative Adversarial Networks and Image Synthesis
1. Introduction
Why do neural networks work? This is not an easy question to answer. During the last decades, there have been several breakthroughs in the art of crafting incrementally more efficient neural networks able to tackle problems ranging from computer vision [1,2] to automatic machine translations [3,4] and physics [5], creating different and independent fields of research. Nonetheless, even if there have been astounding advancements regarding what neural networks can do and regarding how to do it, progress about why neural networks can do what they do is harder to come by. Some have turned their interest to the model’s functioning to understand what the network has learned, why the model has made specific predictions, and how to interpret them [6]. In this article, we go down to a lower level to understand the role of parameters in defining the network. In this paper, we adopt the point of view of a natural scientist, and therefore, we decided to approach neural networks not as complex tools to solve problems, but as phenomena to study through experiments. So, rather than looking for novel architectures and more refined optimization strategies and settings, we take a step back and try to understand the causal connections behind the successful training of a neural network. This approach motivated our choices from the start, particularly our focus on fully connected feedforward neural networks. We aimed to remove the possible noise from complex human-biased architectures and start our investigation from the archetypal neural network that initiated this field; in this way, we had higher control over our subject of study. As a first step in our investigation, we introduced and studied the properties of the space where neural networks live, that is, the space explored by the possible neural networks when they are trained on the same dataset: various strategic options to train models exist, and such options generate different neural networks at convergence. We believe that the properties of the manifold generated by neural networks are connected to two open issues: the balance between over-parameterization and overfitting [7] and the representation of the loss landscape [8], which we briefly review in the following.
The loss function of a neural network is a high-dimensional, strongly non-convex function, with a dimension equal to the number of parameters used by the network. For this reason, it is not guaranteed that the training algorithm, usually the Stochastic Gradient Descent (SGD), is able to easily determine the global minimum, and, even if it does, it is not clear whether such success is attributable to the absence of local minima or to some property of the SGD [7]. Over-parameterization in neural networks, where the number of parameters (D) exceeds the number of training examples (N), allows the model to perfectly fit the training data. While this enables the network to learn the necessary patterns for prediction, it can also lead to the model fitting noise or errors present in the data, which compromise its ability to generalize [9]. Therefore, in the case of over-parameterization, a large generalization error is naturally expected. Conversely, in the opposite scenario where the training set is much larger than the number of parameters, the training algorithm forces the network to focus on the real patterns, thus avoiding overfitting. In real cases, neural networks are usually in the first of these two scenarios and yet show a great capacity for generalization [9]. Several authors have investigated this paradoxical situation. In [10], the authors show that in an over-parameterized network with ReLu activation functions, the minima of a standard mean squared error loss function are degenerate, thus making the job of the SGD easier; in [11], the authors introduce and discuss theorems on the role of over-parameterization in locating the global minimum of the loss function; in [12], the authors argue that an over-parameterization of the last layer of a neural network leads to its overfitting, while it is not detrimental to over-parameterize the previous layers; in [13], the relationship between over-parameterization and overfitting is explored through the introduction of the concept of bias-variance trade-off and double descent. Further investigations can be found in [14,15,16,17,18,19,20,21,22]. Another important field of research that can benefit from defining the space of neural networks is the analysis of the loss landscape. A graphic representation of the parameter space and the loss landscape defined therein is a valuable tool to understand the effectiveness of training algorithms and how regularization techniques impact them. In recent years, there has been a growing interest in developing precise and reliable visual representations. For example, in [23], the loss landscape of a deep convolutional neural network is analyzed in detail. In [24], the authors explore methods to generate accurate 2D and 3D visualizations of the highly multi-dimensional loss landscape, aiming to provide insights into the structure of the space and the behavior of optimization algorithms. Finally, in [8], the authors investigate the presence of multiple global minima and the convergence of the network towards different global minima given a slightly different initialization or by introducing noise in the early stages of training. They conclude that these global minima, even if corresponding to equal performance in terms of accuracy, describe different models.
We believe that a general conclusion we can deduce from this literature is that the process of training can lead to models that usually perform in a similar way and, thus, can superficially be considered similar but, on a deeper level, are very different from one another. Among the various approaches designed to enhance model accuracy and uncertainty estimation, ensemble methods play a key role. While this work focuses on analyzing the behavior of ensembles of independently trained neural networks, another widely adopted technique is Bayesian Neural Networks (BNNs). BNNs incorporate Bayesian inference to estimate a posterior distribution over network weights, providing a principled approach to uncertainty quantification. Methods such as ‘Bayes by Backprop’ [25] and dropout-based Bayesian approximation [26] offer alternative strategies to ensemble learning by treating neural network parameters probabilistically rather than relying on multiple deterministic models.
To further investigate these differences, we trained multiple instances of the same neural network archetype on the same dataset while exploring different training strategies. We considered such strategies as a source of heterogeneity among trained models and studied the space spanned by them. The first feature of this space we investigated is its intrinsic dimension, which, in our view, quantifies how much models trained for the same task actually represent different specimens of a broader population, as it measures the dimensionality of the space spanned by an ensemble of neural networks [27].
The concept of the intrinsic dimension of a set was rigorously defined in [28], and can be understood as the minimal dimension of the manifold spanned by its elements without any loss of information. In the context of neural networks, Li et al. [29] introduced one of the first operational definitions of ID, measuring the intrinsic dimension of objective landscapes by analyzing the parameter space explored during training. Their approach provides a foundational perspective on how high-dimensional loss landscapes can be effectively characterized using ID. Here, we extend this idea by focusing on ensembles of neural networks and examining how different sources of variability influence the dimensionality of the solution manifold. Several authors then came up with different strategies and algorithms to calculate it; see, for example, TwoNN in [30], the Levina–Bickel algorithm [31], MiND_ML_ in [32], or DANCo, and its faster version FastDANCo, in [33]. These algorithms have already been applied to the study of neural networks. In [34], the authors study how the effective dimension of the internal representation of input images changes layer after layer while they are processed by a convolutional neural network. Ansuini et al. [35] follow the evolution of the intrinsic dimension in a trained network, analyzing how the inputs are transformed at every layer. Another example is [36], where the properties of training sets and neural networks are analyzed in detail from multiple points of view. Recently, Baldassi et al. [37] explored the structure of the loss function, investigating how local minima arrange to form complex structures, their generalization properties, and how algorithms based on simple gradient methods are able to find them.
In this work, we shift our perspective from trying to tinker with a neural network to understand how it works to considering a neural network as a single unitary specimen belonging to a population, i.e., an ensemble of neural networks [27] generated using different sources of variability. We study the evolution of such ensembles during training to shed some light on their evolution. Several other sources of variation can generate different models, even if they are trained on the same data. For instance, even before the training starts, the random initialization of weights already defines a manifold with a non-trivial topology and an intrinsic dimension determined by the initialization. All usual operations performed during training (dropout, batch shuffle, data distortion) modify the structure of neural networks and, as a consequence, the ensemble manifold; this is reflected in the intrinsic dimension of the set of neural networks. The role of randomness in training has been widely studied: Altarabichi et al. [38] highlight how weight initialization and structured noise influence generalization, while Zhuang et al. [39] show that even tooling choices can introduce non-trivial variability in network behavior. These factors shape the ensemble manifold and its intrinsic dimension. To systematically assess their impact, we decompose the training procedure into its fundamental steps and study how each source of variability affects the evolution of the ensemble.
2. Methods
In our analysis, we make use of multiple tools, which are described in the present section. The ensemble comprises fully connected feedforward neural networks, trained on the Fashion-MNIST dataset. Such networks can be represented as high-dimensional arrays defined by the learned parameters (weights and biases). The set of such arrays defines a minimal manifold whose intrinsic dimension can be computed using different algorithms. This quantity is the dimension of the ensemble of neural networks. We find that a rescaling strategy to compare and correct the different algorithms’ behavior is needed, particularly for high intrinsic dimension values. In this section, we discuss these methodological issues in detail.
2.1. Neural Networks
The neural networks employed in this analysis are fully connected deep neural networks that were implemented in Python 3.8, making use of the Keras library (https://keras.io/) and trained on the Fashion-MNIST dataset (https://keras.io/api/datasets/fashion_mnist/) (both accessed on 14 April 2025). They were trained to perform a 10-class classification problem and take as input a flattened gray-scale image. For this reason, the input layer has 784 neurons, and the output layer is composed of 10 neurons. There are two hidden layers of 512 and 128 neurons, and they both use the ReLU activation function, which is a standard choice [40,41,42]). The training algorithm employed is the Stochastic Gradient Descent (SGD) with a batch size composed of 32 examples and the categorical cross entropy as a loss function as suggested in [43]. The hyper-parameters of the SGD algorithm were fixed at the Keras library default values. These neural networks were then differentiated using various variability sources, as described in Section 3.
2.2. Calculation of the Intrinsic Dimension
In this section, we propose a quick review of the different algorithms and strategies proposed by different authors to define and calculate the intrinsic dimension. We do not propose an original algorithm, but rather, we present to the reader the available literature in a compact and organized way to introduce the context in which we built our analysis. We believe the best starting point for this quick summary is [44], where the authors introduce a rigorous topological definition of the intrinsic dimension (ID). Given a set of N points , ref. [44] considers the manifold that the points span, embedded in a higher dimensional space through a proper (locally) smooth map . This is done under the assumption that the given dataset can be expressed as , where are independent identically distributed (i.i.d.) points drawn from through a smooth probability density function (pdf) . Ref. [44] defines the ID of the set of N points as the dimension d of the space where the manifold is embedded.
There are numerous approaches to estimate it and provide effective numerical strategies for real-world situations that hardly fall under the rigorous boundaries of exact analytical solutions. Ref. [30] describes some of them before introducing another methodology, which we will discuss in more detail later since it is the best strategy for our needs. Let us recap the other alternatives quickly: projection techniques [45,46,47] and fractal methods [48]), both of which require a large amount of points (the scale exponentially with the ID) to give reliable estimations; see [30] for an in-depth analysis.
We exclude altogether such strategies since we have to deal with very high-dimensional embedding spaces. On the contrary, Nearest Neighbors-Based ID estimators are a class of algorithms that are more suitable for this task since they require fewer points to work properly. In particular, they are based on the assumption that given a ball of radius r centered in a point x of a manifold , , for an r small enough, points uniformly extracted from approximate well enough the local structure of ; see [44] for the details.
We present some of the most common algorithms here, briefly discussing their assumptions and their points of strength, and then apply them to our use case and compare their performance. In the following, we will consider ensembles of N neural networks, each one defined by its own D-dimensional array , where D is the number of parameters of the neural networks, and is the unknown intrinsic dimension of this ensemble.
2.2.1. TwoNN
The TwoNN algorithm, proposed by Facco et al. [30], is based on the minimal hypothesis that only the distances of the two closest neighbors from any given point matter to estimate the intrinsic dimension of a set. The strength of this hypothesis is to make the estimation of the ID less sensible to the ensemble’s inhomogeneities, anisotropies, and irregularities. Let us consider an item , , of an ensemble of which we want to calculate the ID; let and be the Euclidean distances between the item and its first and second neighbors, respectively. Then, the ratio , with N numbers of items in the set, follows a Pareto distribution:
where is the dimension of the manifold spanned by the items of the set and is the characteristic function.
The TwoNN estimator treats the ratios ’s as independent, , and estimates the overall ID on the entire dataset, employing a least-squared approach. Ref. [30] proposes to consider the cumulative distribution of each , obtained by integrating Equation (1), given by , and to linearize it into . Then, a linear regression with no intercept is fitted to the pairs , where denotes the empirical cumulative distribution of the sample sorted by increasing order. To enhance the estimation, the authors also suggested discarding the last percentiles of the ratios ’s, usually generated by observations that fail to comply with the local homogeneity assumption. The requirement of local uniformity only in the range of the second neighbor is an advantage with respect to competing approaches where local uniformity is required at larger distances. In datasets characterized by sharp boundaries, such boundaries introduce a critical violation to the assumption of local uniformity. Consequently, the estimates are affected [30].
2.2.2. MLE
The MLE algorithm, one of the most cited estimators, proposed by Levina and Bikel [31], treats the neighbors of each point as events in a Poisson process and the Euclidean distance between the query point and its jth nearest neighbor as the event’s arrival time. Since this process depends on , MLE estimates the ID by maximizing the log-likelihood of the observed process [44]. In practice, a local ID estimate is computed as
Assuming that each item of the set belongs to the same manifold, the global ID can be written as:
where N is the number of items in the set. To remove the dependency from the parameter k, the authors suggest averaging over a range of values for the number of first neighbors to obtain a more robust final estimate of the ID:
MLE underestimates the ID for high ID values. This problem is shared by all dimensional estimators. Ref. [31] argues that one reason is that the MLE approximation is based on the assumption that enough points fall into a small sphere, but, to be true, the higher the ID, the larger the sample points taken should be. In some cases, there are also boundary effects to take into account, which are more severe for higher dimensions.
2.2.3. MiNDML
The MiND_ML_ algorithm, proposed by Lombardi et al. [32], exploits the pdf describing the distance between the center x of a ball , , and its nearest neighbor, where as function of can be shown to be . A maximum likelihood approach computes the ID estimator. Underestimation of the ID is still present for high ID values, i.e., an ID like in the MLE algorithm. Both [31,32] agree on a qualitative explanation of such bias: ID estimators based on nearest-neighbor distances are often founded on the hypothesis that the available data are unlimited, which is never the case in practical applications.
2.2.4. DANCo
Trying to overcome the drawbacks of MiND_ML_, Ceruti et al. [33], building on the work of [32], propose the DANCo algorithm, which reduces the underestimation effect by combining an estimator employing normalized nearest-neighbor distances with one employing mutual angles. To reduce the bias between the analytical pdf g and the estimated one , DANCo compares the statistics estimated on with those estimated on (uniformly drawn) synthetic datasets of known ID. The comparisons are performed by two Kullback–Leibler divergences applied to the distribution of normalized nearest neighbor distances , where , and the distribution of pairwise angles , is the von Mises–Fisher distribution [49] with parameters . Hence, the estimated ID is the one minimizing the sum of the two divergences:
The computation of the first k neighbors for each point of the synthetic -dimensional dataset for entails, especially for large values of D, high computational time. For this reason, Ceruti et al. [33] proposed a “fast” version of DANCo: FastDANCo. The acceleration is given by precomputing the variables that do not depend on the dataset, but only on N and : . Hence, given k, the variables are calculated for various values of and N and the dependence of each variable on and N is described using suitable fitting functions. Due to FastDANCo’s significant computational time advantage over DANCo and substantially equal accuracy, we will employ the “Fast” version compared to the other algorithms.
2.3. Rescaling the Algorithms
Before computing the ID of the ensembles, we tested the performance of the algorithms presented in the previous section and conducted a systematic comparison of the results they yielded. This was particularly important since such algorithms are usually applied in situations in which both the embedding and the intrinsic dimensions are much smaller than in our case. We built a synthetic dataset that gives us full control over the ID: a set of vectors with a variable embedding dimension. Each element was randomly generated with a uniform distribution, thus ensuring that the intrinsic dimension was equal to the embedding dimension by construction. In other words, by changing the number of elements of each vector, we can simulate different numbers of independent parameters to study the behavior of the algorithms for various values of the ID. We let the simulated embedding dimension range between 1 and 500,000 and repeated this analysis multiple times to estimate the mean and standard deviation of the calculated ID for every algorithm. The results are shown in Figure 1, the left panel. All the algorithms revealed a consistent underestimation of the intrinsic dimension. For this reason, we introduced a rescaling of the result of each algorithm, forcing the calculated ID to be equal to the actual ID when the real ID was equal to 500,000; see Figure 1, the right panel. The general rescaling transformation is represented in the following equation:
where is the rescaled estimated intrinsic dimension, n is the number of parameters that can range between 1 and = 500,000, is the intrinsic dimension estimated by the algorithm a before rescaling, and the label a indicates a specific algorithm.
For a greater number of vectors, the performance of all the algorithms used to calculate the intrinsic dimension increased: they were less prone to underestimate the ID and became more reliable; however, we chose to reflect the number of neural networks composing each ensemble, since training a larger number of models would be too computationally demanding. We point out that the rescaling procedure used in Figure 1 Panel B is not used in the rest of the paper, as it is solely adopted here to show the coherence between the different estimation approaches.
In the following analysis, we will focus on the FastDANCo algorithm, as it is the most reliable at higher dimensions, as shown in Figure 1 Panel A; moreover, it offers the best trade-off between accuracy and computational complexity.
3. Results
During the training of a neural network, many options and techniques are available to speed up convergence, reduce overfitting while increasing generalization, and optimize the search for a stable and reliable minimum in the loss landscape. The specific choice is left to the practitioner, their expertise, and the often a posteriori assessments in the literature. A different choice will result, at the end of the training, in a different model (that is, a different set of learned parameters). In this section, we focus our attention on the most common strategies and settings employed during a standard training procedure that result in different convergence models: the random initialization of weights, batch shuffle and batch size tuning, and dropout rate setting. All these sources of variability will produce different neural networks. The questions we want to answer are as follows: what is the impact of each one of said operations on the training? How do they compare to each other? What happens when we combine them? The intrinsic dimension of the manifold, spanned by an ensemble of neural networks trained with different sources of variability, offers us an objective instrument to shed some light on these questions. Indeed, the ID quantifies the size of the configuration space each method opens up: the larger the ID, the more the ensemble’s neural networks differ.
All possible training strategies were evaluated on ensembles of 100 neural networks with the architecture described in Section 2.1. All 100 networks of the ensemble were trained using one technique, or a set of techniques, at a time, while during training, we estimated the evolution of the ID. For instance, when we adopted dropout to train our networks, all the other sources of variability were fixed: all the networks were initialized with the same parameters, and batch shuffling and the different sources of variation were turned off. The ensemble of networks can be seen as a collection of 100 vectors and calculated the ID making use of the FastDANCo algorithm since the embedding dimension was huge. We checked that the main results do not change using different algorithms; see Appendix A for more details. To express a neural network as a vector, we followed a simple rule: at each epoch (an epoch being the number of training steps required to see the whole dataset, thus depending on the batch size) of the training, we went through the network layer by layer, we converted the weight matrix into a vector by flattening it, we concatenated the bias vector, and we moved to the next layer repeating the operation. In the end, for each neural network we obtained one vector of elements. So, the neural networks were defined in a space equal to the embedding dimension D; we aimed to calculate the ID of the manifold they spanned, which, naturally, evolved during the training.
3.1. Computation of the ID Induced by Different Variability Sources
We aimed to understand the effect of the single strategies of learning, each of which can be seen as a variability source. So, we generated one ensemble of neural networks activating only one variability source at a time: random initialization, batch shuffling, dropout, or random data distortion. Unless otherwise specified, all models were initialized with the same set of parameters (thus spanning a manifold of intrinsic dimension 0). Furthermore, they were trained with the original (not modified) images, with a fixed batch size of 32 images and in a fixed batch order. Lastly, the dropout rate was set to zero. In this way, we could test how the ID increased and evolved during training by turning on a particular strategy at a time. In particular, we tested the effect on the ID of the following variability sources:
- Random parameter initialization. Each network was initialized with random parameters. Note that in this case, the starting (i.e., epoch zero) ID was the highest possible, and it was equal to the embedding dimension D. We refer to this ensemble as “Rand. Init.”;
- Random shuffling of the batches during the training. The order in which the SGD saw batches of the training set was random for each network. We refer to this ensemble as “Batch Shuffle”;
- Random exclusion of neurons during the training. We applied a dropout with a dropout rate of . We refer to this set as “Dropout”;
- Random distortion of the training set images. The images of the training set were randomly distorted, so each model was trained on slightly different data. We refer to this ensemble as “Distorted”, as was done by Ciregan et al. in [50]. See Appendix B for more details.
Each variability source generated an ensemble. Each neural network was trained for 200 epochs, and the ID of the ensemble was calculated at each epoch. The resulting evolution is depicted in Figure 2, Panel A, where each line corresponds to a variability source, and the corresponding ID as a function of the epoch is reported. The first point to notice is that each ensemble had a characteristic order of magnitude for its intrinsic dimension; the random initialization led to a higher ID, followed by training data distortion and dropout. The random shuffling of the batches during the SGD was the only strategy that led to a monotonic increase in the ID, even if the induced heterogeneity was very low. The random initialization, as expected, immediately generated a very heterogeneous ensemble, which spanned a high dimensional manifold, whose ID was already decreased by a factor of ∼15 in the first epoch. This decrease continued because of the training; however, the ID was always higher than the one relative to the other ensembles. On the contrary, we found a steep growth of the ID from epoch 0 to epoch 1 for the “Distorted” and the “Dropout” configurations, which started from identical parameters (which led to ID = 0). In the case of “Dropout”, the first epoch was sufficient for the ID to reach its characteristic order of magnitude. In Appendix C, we report a focus of the first epoch, where we followed the evolution of the ID batch by batch. In the case of randomly distorted trained images, the ID first increased and then it started to decrease. We marked the epoch when this drop happened with a vertical dark line. In Panel B, we show that this happened right before the average accuracy of the distorted ensemble in the training converged to 1. This drop also appeared in the Rand. Init.; the scale of Figure 2 makes this difficult to notice, so please refer to Figure 3, where this behavior is more apparent. Our tentative explanation is that the drop in ID marks a transition to an overfitting regime. In Figure 3, we focus on the random initialization scenario and also turned on the other variability sources to evaluate the impact of applying both. This particular order of adding variation sources is the reason for the popularity of the techniques adopted. Randomly initializing network parameters and randomly resampling dataset subsets are perhaps the most commonly used methods to create model variation in members of neural network ensembles [51]. In particular, we added the following ensembles to the “Rand. Init.” case:
- Random initialization + Batch Shuffle. Each network was initialized with random parameters, and the order in which batches were presented was randomized for each network differently. We refer to this ensemble in the figure as “Rand. Init. + BS”;
- Random initialization + Batch Shuffle + Dropout. Each network was initialized with random parameters, the batch order was random, and the dropout rate equal was 0.5. We refer to this ensemble as “Rand. Init. + BS + Drop.”;
- Random initialization + Batch Shuffle + Distortion. Each network was initialized with random parameters, the batch order was random, and the images were randomly distorted (for each network in a different way). We refer to this ensemble as “Rand. Init. + BS + Dist.”;
In Panel A of Figure 3, we compare the evolution of the IDs at different epochs. Adding other techniques accelerated training and converged more quickly to the solution. The intrinsic dimension decreased since the networks were more similar in the minima. Note that all four of these configurations started from the highest possible value of the ID by construction, and decreased during learning. Among all the strategies proposed, presenting randomly distorted images during training had the biggest impact in reducing the ID of the manifold spanned by the neural networks, thus making them more similar to each other faster. Moreover, we found a steep drop in the ID, noticeable in the “Rand. Init.” scenario. In Panel B of the figure, we show that, again, this happened right before the accuracy on the training set reached 1, thus reinforcing the hypothesis that such a steep drop in the ID marked the passage into an overfitting regime where the networks started learning random noise in the training set rather than a meaningful signal. In Panel C, we can observe that the “Rand. Init. + BS + Dist.” ensemble experienced the same regime change around epoch 115, i.e., a transition to an overfitting region. In both panels B and C, we show the error bars corresponding to the standard deviation over the network ensemble.
We note that even if the distortion of images usually improved the generalization capacity of the models, in our case, we wanted to show a specific effect on the ID of the ensemble; consequently, we used a relatively high distortion factor. This allowed us to clearly show the effect of this factor on the ensemble ID estimation but caused a drop in the prediction accuracy.
Thereafter, we wanted to evaluate the relative intensity of the possible sources of variability and the dependence from the specific value of the involved parameters. This allowed for a visual representation of the function linking the ID to the various parameters. In Figure 4, we shift our attention on the impact of different values of the batch size with random batches and no dropout, Panel A, and other values of the dropout rate with fixed batches of 32 images, Panel B, on the properties of the networks’ manifold. In both cases, the only sources of variation turned on were those characterizing the focus of the study: batch shuffle and dropout, respectively. Let us discuss the results: on the one hand, a smaller batch size implies longer epochs; longer epochs imply a more significant number of random batches, thus allowing networks to diverge more from each other and span a manifold with a greater ID that keeps increasing epoch after epoch. On the other hand, a high dropout rate implies that, at each time step of every epoch, there is a large number of randomly deactivated neurons, so it is natural to expect high diversity between individual networks for higher values of the dropout rate. The peak that we see in Panel B at the beginning of the training is due exactly to this effect; at each step, only of neurons were active, thus adding extreme variety in the network manifold. As the training went on, the regularizing effect of the dropout helped the networks converge to optimal solutions, and the ID decreased. It is interesting to notice that as the dropout ranged from 0.1 to 0.9, at the beginning of the training, the ID did not increase monotonously but displayed a local minimum between the dropout rate of 0.7 and 0.8, probably because such values offered the best regularization effect right from the beginning.
3.2. Accuracy of Heterogeneous Ensembles
After exploring different strategies to train neural networks and disentangle their effect as variability sources on the evolution of the networks’ manifold, we wrapped up the analysis by studying the relationship between the ID and the possible benefits of making predictions with an ensemble of neural networks. To provide a fair comparison between ensembles and single neural networks, we trained the latter for more epochs to simulate two scenarios with roughly similar computational effort. Moreover, we compared two ensembles with different IDs by changing the batch size, following the results obtained in the previous section. We trained an ensemble formed by a variable number of networks for 50 epochs and averaged their predictions through the Unweighted Model Average [52,53] and the Stacking [54,55] techniques, and compared the performance with a single network trained for 200 epochs and with the average performance of the single networks forming the ensemble, so without combining their predictions into a unique consensus score. In particular, we tested two configurations, whose results are shown in Figure 5: the “Batch Shuffle” ensemble with a batch size of 512 (panel A, ID = 15) and the “Batch Shuffle” ensemble with a batch size of 8 (panel B, ID = 251), both trained for 50 epochs. These figures show the prediction accuracy as a function of the number of neural networks in the ensemble. In panel A, we show that the low-dimensional ensemble performance was always lower than the single network; in panel B, the single models in the ensemble had, on average, a better performance than in the previous scenario and, more importantly, combining them in a high-dimensional scenario consistently outperformed the benchmark model trained for 200 epochs, even if only by a small amount. We can conclude that similar networks form ensembles with a small ID, and combining them does not improve the overall performance because there is insufficient heterogeneity. On the contrary, a higher ID denotes more variety among networks, each with different strengths; thus, combining them, even if trained for a shorter time than traditional models, can offer a better prediction performance. However, even if a high ID suggests that the ensemble will likely perform better than a single network, it is not a sufficient condition for improved performances. While a high ID allows for a broader exploration of the solutions space, each network still needs to capture specific, complementary aspects of the database so that by combining them, one obtains an improved prediction.
In real application scenarios, where regularization techniques are combined meaningfully and not isolated, this test shows how one can use the ID to keep track of the evolution of the ensemble and possibly define new training strategies. A sketch of a possible ensemble training procedure could be as follows:
- Identify the best architecture for a given problem;
- Build a suitable ensemble of networks for the analysis;
- Keep track of the evolution of the ID of the ensemble to fine-tune the training strategy to explore a large portion of the solution manifold and identify the optimal ID for the specific problem;
- Average the prediction of the network ensemble and compare its accuracy to a benchmark, for example, a single model, and see if the ensemble forecasting outperforms single model forecasting.
We will explore such strategies in future works.
3.3. Comparison with Hidden Representation
After analyzing the intrinsic dimension (ID) of neural networks as atomic entities, we extended our investigation to examine the ID of the data processed by individual hidden layers, as previously reported in [35]. In this way, we could connect our analysis to the established literature and determine whether the patterns previously observed at the network level also appeared at the layer level.
We calculated the intrinsic dimension of hidden layer representations across four different ensembles using 20 images from Fashion MNIST. We examined the representations in a hidden layer across all 100 networks in each ensemble for each image and computed the ID. The results were then averaged across all 20 images for each ensemble.
In Figure 6, we show that the data hidden representation ID followed the same pattern observed for the complete networks, with a strong correlation coefficient of 0.98.
These results align with the ordering of curves presented in Figure 2A, confirming that the factors affecting the intrinsic dimensionality at the network level similarly influenced individual hidden layers [35].
4. Discussion
Training neural networks requires an educated balance between science and craftsmanship. On the one hand, multiple general training strategies and complex architectures that can be adapted to specific contexts have been developed; on the other hand, to obtain optimal results, a precise tuning strategy—strongly dependent on the problem at hand and the dataset available—is often required. This behavior contributes to the general conception that neural networks are potent yet mysterious black boxes that are difficult to interpret and explain. In the global effort to understand why neural networks work, some studies focus on the transformation that they induce on the training data layer by layer up to the output layer, and the dimension of the dataset is studied as it is processed. Other studies analyze the activation of specific areas of a trained network to produce a mapping between clusters of neurons and dataset properties. The common denominator of such studies is that neural networks are usually taken apart to study individual components’ behavior or single layers’ behavior. We wanted to contribute to this field by considering a neural network as an individual atomic element and studying their collective behavior. Trained neural networks live in a manifold embedded in the space of parameters suited, on the one hand, to reproduce the manifold of the training data, and, on the other, to generalize to new data without overfitting. All training strategies concur to project neural networks to an optimal manifold of the space of parameters that allows for generalization and grants the ability to make predictions and forecasts. Identifying and defining this optimal manifold is quite a daunting goal, but we can assume that a trained network that can successfully perform its tasks is close to it. When training an ensemble of networks, each specimen will converge to the optimal manifold and form a limited representation. We have shown how, through the intrinsic dimension, it is possible to obtain an idea of the size of the portion of the optimal manifold made available to the network ensemble by the training.
We note that several important aspects of the solution manifold remain to be explored in future work. One key question is whether the obtained manifold is locally or globally rugged, or instead forms a smoother structure where solutions are easily connected. Studies on loss landscapes suggest that different minima found by neural networks are often connected by low-loss paths, enabling efficient ensembling and reducing barriers between solutions [56]. Similarly, evidence from energy landscape analyses indicates that minima are not isolated but instead lie on relatively smooth, connected surfaces [57]. Investigating whether neural network ensembles exhibit similar connectivity, or whether training variability leads to more fragmented solution spaces, would provide valuable insights. Additionally, we plan to investigate how small perturbations affect model performance and solution stability. This analysis will quantify how far perturbations move solutions from the optimal manifold and test our hypothesis that models with lower intrinsic dimensionality are more susceptible to perturbations. Finally, examining the norm of the weights would provide insights into how the loss landscape is explored during training. By tracking how weight norms evolve and comparing across different initialization strategies, we can potentially explain why specific initializations perform better than others. These considerations remain speculative at this stage and will be empirically verified in future research to deepen our understanding of neural network solution spaces.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Voulodimos A. Doulamis N. Doulamis A. Protopapadakis E. Deep learning for computer vision: A brief review Comput. Intell. Neurosci.20182018706834910.1155/2018/706834929487619 PMC 5816885 · doi ↗ · pubmed ↗
- 2Khan S. Naseer M. Hayat M. Zamir S.W. Khan F.S. Shah M. Transformers in vision: A survey ACM Computing Surveys (CSUR)Association for Computing Machinery New York, NY, USA 2021
- 3Bahdanau D. Cho K. Bengio Y. Neural machine translation by jointly learning to align and translatear Xiv 20141409.0473
- 4Stahlberg F. Neural machine translation: A review J. Artif. Intell. Res.20206934341810.1613/jair.1.12007 · doi ↗
- 5Guidarelli Mattioli F. Sciortino F. Russo J. A neural network potential with self-trained atomic fingerprints: A test with the m W water potential J. Chem. Phys.202315810450110.1063/5.013924536922151 · doi ↗ · pubmed ↗
- 6Montavon G. Samek W. Müller K.R. Methods for interpreting and understanding deep neural networks Digit. Signal Process.20187311510.1016/j.dsp.2017.10.011 · doi ↗
- 7Mei S. Montanari A. Nguyen P.M. A mean field view of the landscape of two-layer neural networks Proc. Natl. Acad. Sci. USA 2018115 E 7665 E 767110.1073/pnas.180657911530054315 PMC 6099898 · doi ↗ · pubmed ↗
- 8Fort S. Hu H. Lakshminarayanan B. Deep ensembles: A loss landscape perspectivear Xiv 20191912.02757