Vector Flows That Compute the Capacity of Discrete Memoryless Channels
Guglielmo Beretta, Marcello Pelillo

TL;DR
This paper introduces a new continuous-time method to compute the capacity of communication channels, inspired by the Blahut–Arimoto algorithm and suitable for analog computation.
Contribution
A novel continuous-time dynamical system for computing channel capacity with proven convergence properties and an analog circuit implementation.
Findings
The proposed system is a continuous-time version of the Blahut–Arimoto algorithm with exponential convergence under certain conditions.
An analog circuit design is presented to implement the dynamics for estimating channel capacity.
The method bridges classical information theory with continuous-time computation and hardware implementation.
Abstract
One of the fundamental problems of information theory, since its foundation by C. Shannon, has been the computation of the capacity of a discrete memoryless channel, a quantity expressing the maximum rate at which information can travel through the channel. In this paper, we investigate the properties of a novel approach to computing the capacity, based on a continuous-time dynamical system. Interestingly, the proposed dynamical system can be regarded as a continuous-time version of the classical Blahut–Arimoto algorithm, and we can prove that the former shares with the latter an exponential rate of convergence if certain conditions are met. Moreover, a circuit design is presented to implement the dynamics, hence enabling analog computation to estimate the capacity.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
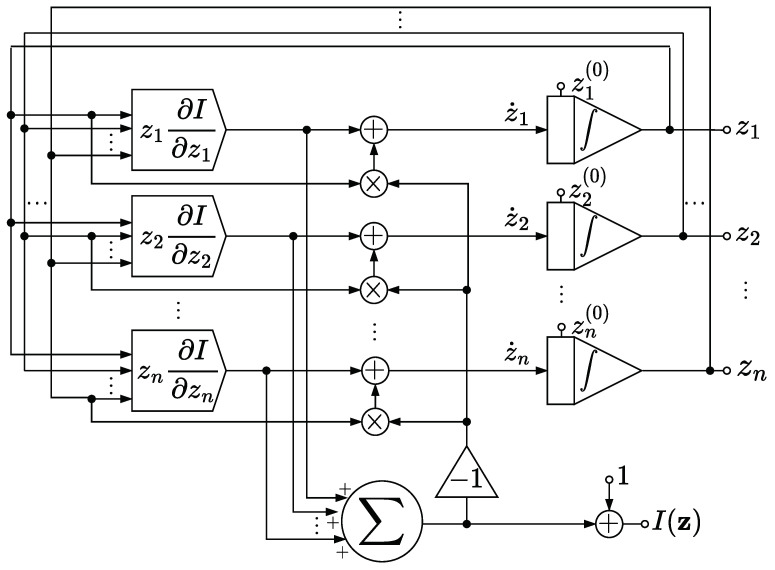 Figure 1
Figure 1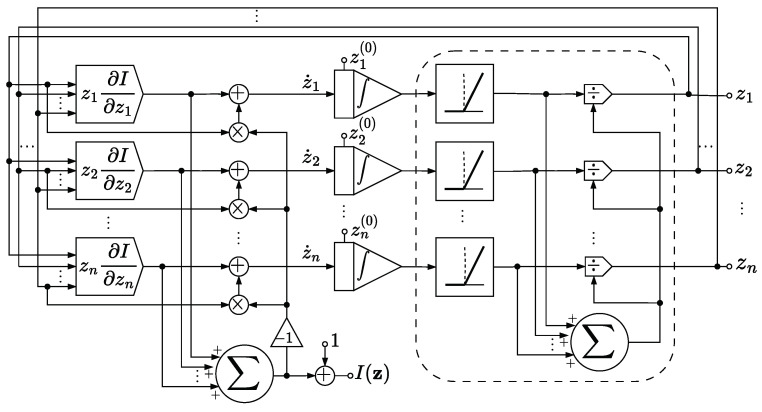 Figure 2
Figure 2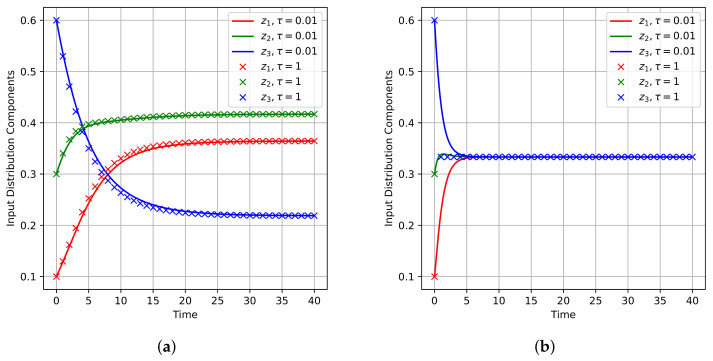 Figure 3
Figure 3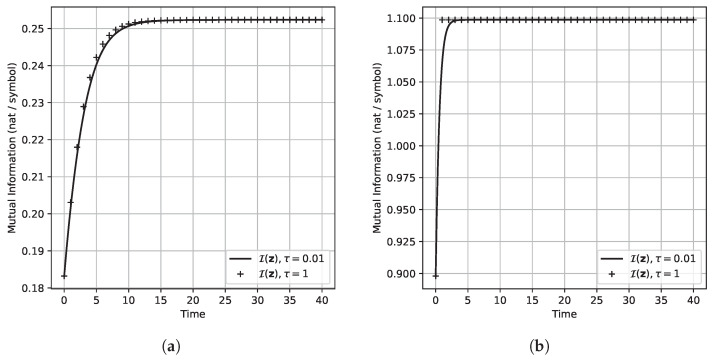 Figure 4
Figure 4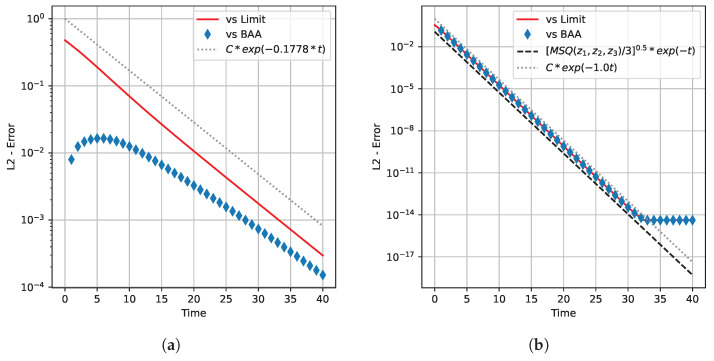 Figure 5
Figure 5- —Politecnico di Torino and Università Ca’ Foscari di Venezia
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsQuantum Computing Algorithms and Architecture · Cellular Automata and Applications · Neural Networks and Applications
1. Introduction
Estimating the capacity of a discrete memoryless channel (DMC) is a well-known problem related to the reliability of point-to-point communication systems, as a consequence of C. Shannon’s noisy-channel coding theorem [1,2,3]. A fundamental algorithm to address this problem is the classical Blahut–Arimoto algorithm (BAA), an iterative algorithm based on an alternating maximization procedure [4]. Named after S. Arimoto [5] and R. Blahut [6], who discovered it independently, the BAA requires only some mild conditions on the zero elements of the transition matrix and, unlike its antecedents, it is also applicable when the input alphabet and the output alphabet of the channel have different cardinalities. Notably, the BAA is still a subject of active research (see, e.g., Refs. [7,8,9,10]).
In contrast to the BAA, this paper describes a continuous-time dynamical system used to compute the capacity of a DMC. This dynamical system is obtained via the (forward) flow of a suitable ODE, and it can evolve a given distribution towards an optimal input distribution of the channel, hence enabling capacity computation. In studying this unconventional way to address capacity computation, we were inspired by the work by R. W. Brockett, who, as reported, e.g., in [11], provides a novel way, grounded in calculus, to approach problems traditionally addressed via algorithms [12]. Interestingly, the proposed capacity-computing ODE (denoted by CC-ODE in the sequel) has a connection with the BAA. Indeed, it can be regarded, in a sense, as a continuous-time version of the BAA. To support this claim, we leverage the notion of the multiplicative-weight-update (MWU) rule [13] and its connection to both the BAA (see Refs. [8,14]) and to some discretization techniques used, e.g., in evolutionary game theory [15,16].
The link between the BAA and the CC-ODE flow can be further extended when studying the convergence rates. By construction, the BAA generates a sequence of input distributions, and understanding the convergence rate of this sequence to an optimal input distribution has been central in the study of the BAA ever since its origin [5]. Remarkably, estimating an optimal input distribution for a generic DMC involves some issues affecting not only the BAA, but also any iterative algorithm running on a Turing machine, as recently shown in [10] via computability theory arguments. Despite this, some technical conditions on DMCs ensure exponential convergence of this sequence to an optimal input distribution [5,9]. We prove that under these conditions, in the formulation given in [9], the CC-ODE flow converges exponentially to an optimal input distribution, which can be shown thanks to some tools of Lyapunov’s stability theory [17]. The convergence rate can be further refined for a trivial family of DMCs, namely, the noiseless symmetric channels—see, e.g., Ref. [18] (p. 77). Even though a known formula exists for their capacity, we found it interesting that these channels are associated with a CC-ODE for which an explicit analytic solution is available, and we leverage this to produce a more precise asymptotic estimate of the flow.
Lastly, we propose a circuit design to implement the CC-ODE flow, thereby enabling analog computation of the capacity. Analog computation is an important alternative to digital computation [19], and is still a topic of active research—see, e.g., Refs. [20,21,22,23,24,25,26,27]. We speculate about how the proposed circuit could preserve its effectiveness even in the presence of noise, and we comment on its usage in association with the unavailability of some channel input symbols. See also Ref. [28] for a similar circuit design dealing with a labeling task.
This paper is a follow-up of [29], where the empirical usage of numerical methods applied to the CC-ODE was studied to compute the capacity. However, no mathematical proofs were given in [29], and except for a simplified version of Theorem 2, the results presented in this paper do not appear in [29]. To the best of our knowledge, no previous work has studied continuous-time dynamical systems to compute the capacity of DMCs.
Despite this, the CC-ODE can be regarded, under some technical conditions, as an instance of a class of ODEs discussed in [30], where smooth functions are optimized over polyhedra using some notions of Riemannian geometry. In addition to that, similar ODEs appear in the literature on convex optimization (see, e.g., Ref. [31]), as well as in some models pertaining to evolutionary game theory [16,32]. However, in contrast to [16,30,31], the objective function associated with the CC-ODE may be not differentiable on part of the boundary of the feasible set, and we provide the technical arguments that are required to adapt the existing results to the problem under discussion.
The subsequent sections of this paper are organized as follows. Notation conventions are established in Section 2, and Section 3 reviews the aforementioned class of ODEs that have been used in the literature to tackle optimization programs on a standard simplex. We also mention how relaxed hypotheses on the objective function may negatively affect trajectory convergence to stationary points, and in Lemma 1, we discuss some alternative conditions to overcome this issue. In Section 4, the reader is introduced to the problem of computing the channel capacity for DMCs and its formulation as a concave optimization program on a standard simplex. The main contributions of this paper are in Section 5, which deals with the CC-ODE, its properties, and its link with the BAA, and Section 6, where the convergence rates are discussed. The circuit designed to implement the CC-ODE flow is examined in Section 7. Some simulations are described in Section 8 so as to give more insight into how the CC-ODE flow behaves in comparison with the BAA. Section 9 contains some remarks on our results, and final considerations and future research directions are reported in Section 10.
2. Notations
In this paper, the information content is measured in nats, since this choice simplifies the theoretical computations involving mutual information, as mentioned, e.g., in [6]. For a conversion to bits, we recall that 1 nat equals bits [2]. In the sequel, we consider the expression as well defined and equal to 0 in case . For every integer , the standard simplex in is the set
its (relative) interior is the set
and its (relative) boundary is the set . For , the support of is the set . The canonical basis of is denoted by , … , and . Given , , we write for the usual dot product between and , whereas we write for the Euclidean norm of , so that denotes the Euclidean distance between and . In this paper, gradients are column vectors. Given , , …, and , we define
3. Optimizing Continuous-Time Dynamics
3.1. Preliminaries
We recall that a function is (globally) Lipschitz continuous on if there exists a constant such that for every , , whereas is locally Lipschitz continuous on if for every , there exists an open neighborhood of such that the restriction of to is Lipschitz continuous on . Global and local Lipschitz continuity play a fundamental role in the existence and uniqueness results concerning solutions of an ODE, as in Picard–Lindelöf theorem—see, e.g., Refs. [33,34]. Given an open , a function that is locally Lipschitz continuous on , consider the ODE
We will say that a non-empty set is invariant under (1) if for every , there exists that solves (1) and satisfies . Similarly, we will say that S is forward invariant under (1) if for every , there exists that solves (1) and satisfies . By the assumptions made on , note that for every there exists at most one solution of (1) such that . This is a trivial consequence of Picard–Lindelöf theorem.However, note that these assumptions do not guarantee the existence of such a solution—which is related to the problem of extending local solutions (see also Ref. [35] (Ch. 17.4))—and we remark that stronger assumptions are generally required to prove the existence, such as those reported in Appendix A. We also recall that a point is stationary for (1) if , i.e., if the constant function solves (1).
3.2. Optimizing Differential Equation on the Standard Simplex
A program of the form
is related, under suitable conditions on its objective function f, to the ODE
which can also be written in vector notation as
In particular, for , the ODE (3) is known as the Shahshahani gradient system associated with f—see, e.g., Refs. [16,32]. Many properties of (3) are discussed in the literature under the assumption that f admits a globally Lipschitz continuous gradient on , which guarantees the invariance of under (3) and that the function f increases strictly along any non-constant solution of (3) evolving on ; see, e.g., Refs. [16,30,31,32,36], and also Appendix B. Indeed, strictly speaking, the condition that is often assumed is that the gradient of f is locally Lipschitz continuous on some open superset of (see, e.g., Ref. [15]), which is a stronger assumption, as shown, e.g., in [35] (p. 400).
However, as we shall see in the following sections, we are interested in objective functions that can exhibit singularities on and so we cannot rely on the usual assumptions made in the literature. Crucially, if the function f is differentiable in but not on some points of , then forward trajectories of (3) may converge to one of these points, where (3) is undefined, and this may happen even in case additional hypotheses such as concavity are met, as in the example shown in Appendix C. By contrast, this cannot happen under the circumstances described in the next lemma, which we will apply in the sequel:
Lemma 1. Let admit a locally Lipschitz continuous gradient on some open . Suppose f is concave on some non-empty compact convex . Let be a solution of (3).
- (i) There exists and is a stationary point for (3);
- (ii) If , then is a KKT point for (2);
- (iii) If and f is concave and continuous on , then is a global solution of (2).
Proof. (i): We now make the following claim, whose technical proof is deferred to Appendix D:Claim 1(Convergence). There exists .Note that entails ; hence, is well defined and continuous in a neighborhood of . A standard argument can now be applied to show that is stationary for (3)—namely, since the -limit here does not escape , then the singleton is forward invariant under (3) as a consequence of Gronwall’s lemma—see, e.g., Ref. [16].(ii): We will use the following claim, which provides a known alternative description, for maximization programs over the standard simplex, of the KKT conditions: Claim 2(KKT points). A point in which f is differentiable is a KKT point for (2) if and only if there exists some such that for every , with equality for every . The interested reader may find a proof for Claim 2 in Appendix E. Assume , which entails for every by uniqueness of local solutions—see, e.g., Proposition A1.(iii). By (i), the point exists in . Define and set . Since is a stationary point for (3), it follows that for every . The proof is completed by reductio ad absurdum as in the proof of [15] (Prop. 3.5). In fact, let —i.e., let —and suppose also that . Then, by continuity, also for every sufficiently close to ; hence, for every sufficiently large, which contradicts . It follows that is a KKT point for (2) by Claim 2.(iii): If f is concave on , then every KKT point for (2) is a global solution for (2)—see, e.g., Ref. [37]; hence, (iii) follows by (ii). □
4. Problem Formulation
4.1. Discrete Memoryless Channel and Capacity
A discrete memoryless channel (DMC) is a communication system that can be described by a triplet , in which and are finite alphabets called the input alphabet and output alphabet, respectively, whereas is a stochastic matrix, called the transition matrix, where expresses the probability that the symbol is observed as output of the system whenever the symbol is sent to the system as input [3]. Without loss of generality, we will work under the following assumption: For every , there exists at least one such that . In other words, we are assuming that represents the minimal output alphabet required for a description of the DMC. In fact, this assumption ensures that for any selected symbol there exists a corresponding input distribution for which y occurs as output with positive probability.
Let X be the input variable of , i.e., the random variable with range in modeling the input of the channel, and let Y be the output variable of , i.e., the random variable modeling the output of the channel. Following [2], the mutual information between X and Y, denoted by , is a non-negative quantity measuring the reduction in uncertainty about X that results from learning the value of Y, and its formulation involves the notion of entropy, which for a generic discrete random variable D with range in a set is given by . The random variable Y and all the random variables obtained as appear, together with the input distribution , in the following expression for (see, e.g., Ref. [2]):
The capacity of is the maximum value C of over all possible choices for :
The capacity C provides a theoretical bound for the information content that can be transmitted through the channel [1,2,3].
4.2. Optimization Program for the Capacity
Consider a channel and set and . The maximization problem associated with the capacity admits a well-known formulation as a constrained optimization program over a standard simplex—see, e.g., Ref. [10]. We now show how to derive this program and, in so doing, we take the chance to define some auxiliary functions and parameters that we will extensively use in this paper.
Define the function , where is the linear function
If for every , then for every by the theorem of total probability; thus, and can be identified with the distributions of X and Y respectively, and it is possible to write as a function of . Indeed, it is sufficient to set
define the function
and observe that, for corresponding to , the equality holds. As a result, the capacity C of the channel satisfies
Following [10], we call optimal input distribution every global solution to (6), i.e., every such that .
5. Vector Flow for Capacity Computation
5.1. Flow Definition and Its Properties
The function , which is the objective function of (6), is continuous and concave on —see, e.g., Ref. [3]. Define the open set
and note that .
Proposition 1. Let . Then,
- (a)
- ;*
- (b)
- ;*
- (c)
- .*
Proof. See Appendix F. □
In particular, is well defined and continuous on , and so is locally Lipschitz continuous on . However, note that is singular on .
Now, consider the ODE
We will also refer to Equation (7) as the capacity computing ODE (CC-ODE for short).
Theorem 1(Forward invariance). The set is forward invariant under (7).
Proof. Let
It is easy to see that for every and every :
- If , then ;
- If , then if and only if , where the set is defined by .
For every , we define some the following objects:
- The vector ;
- The function given by
- The real number as a positive solution to the system of inequalities
where and C are defined as in (4), (6) (note that such an exists, since as and for ).
We make the following claim:Claim 3. Let and let . Then,
Proof **of Claim 3.**By Proposition 1, the definition of , and using that ,
and so
since entails both and for every J. If , then , and so, by (9) and (11), it follows that . □Now, let . We have to prove that a solution of (7) exists satisfying . We first make the following claim:Claim 4. There exists a convex compact such that , and K is forward invariant under (7). Proof **of Claim 4.**For every , set and define
By construction, . Note that K is a compact and convex polytope containing the elements that satisfy the following constraints:
- for every ;
- ;
- for every .
Therefore, for every , the tangent cone —see Appendix A or, e.g., Ref. [16]—is the set of such that
- (a) for every ;
- (b) ;
- (c)For every , if then .
Note now that for every . In fact, (a) and (b) are immediate to check, whereas (c) holds by Claim 3. The thesis follows by Theorem A1 in Appendix A. □By Claim 4, there exists a compact and a solution of (7) satisfying . □
By Theorem 1, we can define a continuous-time dynamical system on via the (forward) flow generated on by the CC-ODE, i.e., via the function
such that for every , the function is the unique solution of
Proposition 2(CC-ODE flow properties). Let and set .
- (a)The equality holds for every ;
- (b)Either is a stationary point for (7) or is strictly increasing;
- (c)There exists , and is a stationary point for (7);
- (d)The restriction of to the set attains its maximum in :
Proof. (a), (b): These properties hold for Shahshahani gradient systems trajectories, and similar proofs are valid in our setting by the uniqueness of local solutions of (7). For more details, see Appendix B.(c): This follows from Claim 4 and Lemma 1.(i).(d): Assume without loss of generality that only the first coordinates of are positive, where . Consider the injection given by , and define the function . Observe that by uniqueness of solutions, where solves
Since and by construction, the result follows by Lemma 1 applied to . □
In particular, Proposition 2 gives the following fundamental theorem:
Theorem 2(CC-ODE flow-attaining capacity). Let . Then exists and is an optimal input distribution. Either is a constant function, or is strictly increasing in t and converges to C as .
Proof. The proof follows directly from Proposition 2. □
5.2. Connection with Blahut–Arimoto Algorithm
The BAA is an iterative algorithm that can be described via a map , here called the Blahut–Arimoto map. Given an initial input distribution , Blahut [6] and Arimoto [5] proved that the sequence defined by satisfies as . It has been observed [8] that acts according to the MWU rule [13]:
where the weights , …, satisfy
Interestingly, there exists a numerical scheme used for approximating Shahshahani gradient systems that is also based on MWU, which is the following:
where is the stepsize and f must be sufficiently smooth. The recurrence described in (17) is well known in evolutionary game theory—see, e.g., the deduction of the discrete replicator-dynamics model [15]. One fundamental property of (17) is that if is an element of and the gradient of f is defined in , then (17) defines as an element of having the same support of , in agreement with the support invariance of the continuous-time dynamics—see also Appendix B. In particular, if and f is differentiable in , then the recurrence given by (17) can be used to produce a sequence with arbitrary length (even though, in numerical implementations, the recurrence initialized in could generate points on due to floating-point arithmetic, see also Ref. [29]).
We can now explain in the following theorem how the CC-ODE flow can be regarded as a continuous-time version of the BAA:
Theorem 3. The Blahut-Arimoto map coincides with the MWU rule (17) applied to defined as in (5) with stepsize .
Proof. Observe that
with defined as in (16); hence, satisfies the following:
□
6. Convergence Rate
6.1. Conditions for Exponential Convergence
Consider an optimal input distribution . We now present some conditions that ensure that the flow converges exponentially to . To this end, we will study a first-order approximation of
in the vicinity of . In our continuous-time scenario, this corresponds to what is examined in [9], where a truncated Taylor expansion of in is studied to investigate the rate of convergence of the sequence given by to , where . To this end, we consider a classification over introduced in [9] that involves the coordinates of and . Specifically, an index is classified as follows (note that the case is excluded by the KKT conditions):
- type if and ;
- type if and ;
- type if and .
In particular, we remark that the vector given by
satisfies if i is of type , and otherwise. As shown in the following proposition, this classification helps in the study of the first-order approximation of (19) near :
Proposition 3. Let . Then,
Proof. By Proposition 1,
and note that . □
By Proposition 3, if i is of type , then has a null gradient, and higher-order terms would be required to study in the vicinity of . Indeed, in order to obtain a non-singular linearization of (7) in a neighborhood of , we will make the following assumption:
- (N1)For some positive , the indices , …, are of type and the remaining indices are of type .
Similarly to what is done in [9], it is useful to introduce some additional notation to distinguish between indices of different types. To this end, for every , define and so that . Note that and . Moreover, let be the Hessian of in , and write the submatrix of containing its first rows as , where and .
Theorem 4. Assume (N1). Define , let , and let be the Jacobian matrix of in . Then for every , where is the upper-triangular block matrix
Proof. For every , the i-th row of is precisely . Apply Proposition 3, using the fact that . □
Before proving our main result on the convergence rate of the CC-ODE flow, we need the following additional assumption:
- (N2)The first rows of the transition matrix are independent.
Theorem 5(Exponential convergence rate). Suppose (N1) and (N2) hold. Then the maximum eigenvalue of is negative. Moreover, is the only optimal input distribution for the channel , and for every , there exists δ, such that for every , if , then
for every .
Proof. Consider first the matrix defined in (21), whose eigenvalues are the union, counting multiplicity, of the eigenvalues of and those of . The eigenvalues of are , …, , whereas those of are described in the following lemma, proved in [9] (Section III.C): Lemma 2(Nakagawa et al. [9]). The matrix is diagonalizable, has eigenvalues , and if and only if the first rows of the transition matrix are independent. By Lemma 2 and Assumption (N2), it follows that .The remaining part of the proof relies on a standard application of Lyapunov’s stability theory (see, e.g., Refs. [17,38]), combined with the application of Theorem 4. Given , the matrix has only real negative eigenvalues by construction. Consequently, the Lyapunov’s equation [17]
is solved by a positive definite symmetric matrix . Consider the quadratic form . Calling the minimum and the maximum eigenvalue of respectively a and A, it follows that and
Recall that
where is the Jacobian matrix of in and
Therefore, setting and performing the substitution yields
where the last equality is a consequence of Theorem 4. By definition of , by (23), and using that ,
Hence,
Suppose now that for some , the expression
is positive for every . Then, the inequality holds on . By Gronwall’s lemma [17], this implies that , and so by (24)
for every . What is left is proving that for sufficiently small, if , then (26) is positive for every . This follows easily from (25) and (27).Finally, to prove that is the unique optimal input distribution, suppose by absurd that there exists an optimal input distribution . Note that, by convexity of , the set of optimal input distributions is a convex subset of . Then every convex combination of and is an optimal input distribution. In particular, infinitely many stationary points exist whose distance from does not exceed , and this contradicts the definition of . □
Theorem 5 is a continuous-time counterpart of the following result reported in [9]:
Theorem 6(Nakagawa et al. [9]). Suppose (N1) and (N2) hold, and that there exists a unique optimal input distribution for the channel . Define as the maximum of the set . Then for every , there exists δ, such that for every , if , then
6.2. Noiseless Symmetric Channels
In this section, we refine the result given in Theorem 5 under the additional hypothesis that is a noiseless symmetric channel. Following [18] (pp. 77–78), we recall that the channel is called
- Deterministic if the output Y is a deterministic function of the input X.
- Lossless if the input X is completely determined by the output Y.
- Noiseless if it is both deterministic and lossless.
- Symmetric if in the transition matrix every row is a permutation of every other row, and every column is a permutation of every other column.
We now assume that is noiseless and symmetric. Then and, up to a suitable reordering of the output alphabet, we may assume that the transition matrix is the identity matrix. Note that in this case, and so , the objective function is
and the CC-ODE is
The channel admits a unique optimal input distribution, which is , the barycenter of ; thus —see, e.g., Ref. [18] (pp. 84–85). In addition to that, it is easy to verify an interesting property of noiseless symmetric channels, namely that, for these channels, the BAA requires at most one iteration to find the optimal input distribution. By Theorem 2, we deduce that, for , we have as , and also . We will see that a more precise asymptotic estimate on is available by leveraging the explicit solution of (29) on .
Theorem 7. If is the noiseless channel, then, for every ,
as .
Proof. Given , the function is given by the following explicit analytical expression:
Note that as ; hence, using the McLaurin expansion of the exponential function,
Therefore,
which gives (30). □
7. Analog Implementation
An attractive feature of continuous-time methods is their amenability to be mapped onto hardware circuits [39,40]. Figure 1 depicts a circuit implementing the CC-ODE flow to compute analogically the capacity of a DMC.
The circuit requires , …, as input, which represent the coordinates of a point in which a trajectory of (7) is initialized. Moreover, the circuit requires, for every , a module to implement , which we here consider as a black-box. These modules encode the dependence of the circuit on the transition matrix of the DMC. We remark on the following feature of these modules:
Proposition 4. For every , the map can be extended to a continuous function defined on .
Proof. Consider the function given by for and , which is a continuous function on . Then, by Proposition 1, for every ,
and since , it follows that is bounded and admits a continuous extension to , which is given by
□
The circuit outputs , which at time coincides with , and thanks to the integrator elements appearing in the circuit [40], the recurrent design of the circuit evolves according to Volterra’s equation [33]:
Hence, for every . By Theorem 2, it follows that converges to an optimal input distribution as , which is also a stationary point for the system. Moreover, if the channel admits a unique optimal input distribution, then Theorem 2 ensures that this optimal input distribution is also an asymptotically stable stationary point of the system. Besides that, the circuit computes , which equals by Proposition 1 and converges to the capacity by Theorem 2.
We stress that the circuit drawn in Figure 1 is supposed to work in an ideal setting, where no noise affects . Indeed, the circuit relies on the property that is invariant under , as shown in Theorem 1. By contrast, Figure 2 shows a variation in the circuit design that may mitigate the effect of small perturbations on thanks to an additional normalization module. The normalization module sets every negative signal received as input to zero, and then normalizes the resulting vector of non-negative signals with respect to the -norm.
So long as stays in , as should theoretically happen if also is in , then the additional normalization module has no effect on the system, and both circuits in Figure 1 and Figure 2 behave in the same way. However, in the presence of a perturbation that affects the system, then the normalization module prevents from exiting . In addition to this, if the modules are devised to implement the corresponding continuous extension described in Proposition 4, then by Peano’s existence theorem [33], the actual ODE solved by the circuit is well defined on , and not just on , even though some trajectories may lead to a suboptimal input distribution, as explained in Section 9.
8. Some Illustrative Examples
To give a graphical demonstration showing the qualitative behavior of the CC-ODE flow, we simulated the CC-ODE for some specific channels. This was accomplished by applying the MWU described in (17) as an integration scheme to discretize the flow. To run the simulations, we considered two channels, and for each channel, we selected a different starting point to initialize the dynamics. For each of these configurations, we computed the (unique) optimal input distribution by running the BAA for 10,000 iterations. In particular, we considered the DMC with transition matrix
which admits the unique optimal input distribution , and we considered the corresponding CC-ODE flow initialized in . Similarly, we considered the noiseless and symmetric DMC with transition matrix
for which the optimal input distribution is approximately , and we considered the corresponding flow initialized in . To make a comparison between the CC-ODE vector flow and the BAA, we applied the MWU rule given by (17) with and with , since the choice yields exactly the Blahut–Arimoto map, whereas smaller values of lead to a better approximation of the CC-ODE flow. Figure 3 shows how the components of the input distribution vary as t runs. Note that, for both channels, the dynamics drive the system towards the optimal input distribution of the corresponding channel. Moreover, for the noiseless symmetric channel, note in Figure 3b that the BAA converges in one step. Figure 4 illustrates how the mutual information of input and output variable evolves. Also in this case, the figure displays that the CC-ODE can be used to attain the capacity, similarly to what happens for the BAA. Clearly, for the noiseless symmetric channel, the capacity is attained via the BAA with just one step—see Figure 4b. Finally, in Figure 5, we depict some graphs plotted in semilog scale to provide some estimates about the speed of convergence of the CC-ODE. For every channel considered and for every integer value of t, we have marked with diamonds in Figure 5 the Euclidean distance between the input distributions obtained via the CC-ODE at time t and the corresponding input distribution computed with the BAA. As shown in the figure, this quantity exhibits exponential decay after just a few iterations of the BAA.Moreover, we reported with a solid red line the Euclidean distance between the limit optimal input distribution and the points on the orbit produced with . The channels considered have a non-singular transition matrix, and their optimal input distribution does not have null entries. Consequently, Theorem 5 is applicable for both channels. As displayed in Figure 5, the solid red line decays roughly as the dotted grey line, which is the graph of a function of the form , with being the maximum eigenvalue discussed in Theorem 5, which equals for the noiseless symmetric channel and is for the other. For the noiseless symmetric channel, we also report in Figure 5b the theoretical asymptotic behavior described in Theorem 7 for the error decay. It is possible to see that in Figure 5b, the computed error decay deviates from the expected behavior for . However, the plot also shows that the error stabilizes when it reaches a value close to . Considering that the simulations were carried out using double precision, we interpret this outcome as a consequence of approaching the machine precision.
The interested reader may also see Ref. [29], where other integration schemes were tested in conjunction with Algorithm 1. Algorithm 1 Discretizing the CC-ODE to compute the capacity [29].Input: , stepsize; Niter, maximum number of iterations; , tolerance; , initialization point.Output: , estimated channel capacity; , estimated optimal input distribution; k, number of integration steps performed. 1: 2: ▹ Initializing . 3: 4: while do 5: 6: ▹ Note: is the -norm of . 7: ▹ Updating . 8: 9: end while10: 11: 12: return , , k
9. Discussion
We report in this section some additional remarks related to the results treated so far:
- In formulating Lemma 1, we tried to require only the essential hypotheses we used in its proof. Consequently, even though we apply Lemma 1 only in Proposition 2, it is applicable also in other, more general settings.
- In the proof of Theorem 1, note that if , then , and the thesis is just a mere application of classical results—see, e.g., Refs. [16,31]. By contrast, the proof deviates from a standard setting in case , which implies .
- As far as the proposed circuits are concerned, note that could be produced by considering a module that outputs and whose output is then multiplied by . However, note that is a bounded function of the input by Proposition 4, which in general is not true for .
- We also remark on the following feature of the circuit presented in Figure 1. Assume that, for whatever reason, there are u input symbols , , …, that become unavailable, in the sense that any input distribution is now constrained to assign null probability to , , …, . Indeed, this constraint on the channel corresponds to replacing it with , where and is obtained from by removing the rows , , …, . In case every symbol of the output alphabet can still be obtained with positive probability, then the capacity of may be computed without altering the circuit design displayed for , but by simply modifying the initialization rules on . Specifically, by Proposition 2.(d), it is sufficient to initialize so that if and only if , , …, , and the dynamics evolves so as to maximize under this constraint;
- Note that noise could negatively affect the capacity computation, despite the normalization module of Figure 2. Indeed, suppose that a perturbation causes to change its support at time , and that for , no additional perturbations affect the dynamics. Then it is possible that converges towards an input distribution that is still optimal, but for the wrong channel, as in the case discussed in the previous remark. To check if this has occurred, a good idea could be to consider some “perturb and restart” strategies. For instance, when the capacity of is sought in the presence of noise, assume that a trajectory initialized in some converges to some . We may then restart the dynamics in some that is obtained by perturbing slightly , and then check whether converges once again to , or if converges to in case we know in advance that there exists a unique optimal input distribution.
- By Proposition 4 and Peano’s theorem, the ODE (7) extended by continuity admits a solution for any initialization , regardless of whether lies in or not. Indeed, a solution for (7) can always be found by considering the “subchannel” of induced by the support of , similarly to the approach discussed before in Proposition 2.(d). However, in case , note that the Picard–Lindelöf theorem cannot be applied, and we did not manage to prove that such a solution is unique. Despite this, for symmetric noiseless channels, note that the general integral (31) can be extended by continuity also for , and arguing by induction it is not hard to see that, for these trivial channels, solutions for the extended ODE are unique.
10. Conclusions
We performed a theoretical analysis on the flow of the CC-ODE, which rules a continuous-time dynamical system that enables us to compute the capacity, as well as an optimal input distribution, of a DMC. We showed that the proposed dynamical system can be regarded as a continuous-time version of the BAA and that, under some technical conditions, the flow rate of convergence to an optimal input distribution is exponential, with constants that correspond to those arising from iterating the Blahut–Arimoto map. We described possible implementations of the CC-ODE flow in a circuit that may compute analogically the capacity of a DMC, and we discussed how the circuit may be still useful in case the channel changes due to the unavailability of some input symbols.
Possible future work stemming from this paper might be the exploration of continuous-time dynamics to maximize mutual information under some additional constraints, as in [6], or for quantum channels [41]. Moreover, an interesting aspect of Theorem 3 is that it shows that the CC-ODE flow is related to some accelerated versions of the BAA [8] that correspond to an application of (17) with but where the stepsize is adjusted at every iteration. This link suggests investigating strategies to speed up analog computation by accelerating the CC-ODE flow. Lastly, a theoretical question that we have not addressed is whether solutions of the ODE obtained by extending (7) by continuity on are unique, even though the hypotheses of the Picard-Lindelöf theorem are not met.
As mentioned by M. T. Chu in [42], continuous methods may help understand the corresponding discrete methods, and we hope that this paper may enrich our collective knowledge of the BAA, which is still a subject of active research.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Shannon C.E. A Mathematical Theory of Communication Bell Syst. Tech. J.19482737942310.1002/j.1538-7305.1948.tb 01338.x · doi ↗
- 2Mac Kay D.J.C. Information Theory, Inference, and Learning Algorithms Cambridge University Press Cambridge, UK 2003
- 3Cover T.M. Thomas J.A. Elements of Information Theory 2nd ed.Wiley Hoboken, NJ, USA 2006
- 4Csiszár I. Tusnády G. Information geometry and alternating minimization procedures Stat. Decis.19841205237
- 5Arimoto S. An algorithm for computing the capacity of arbitrary discrete memoryless channels IEEE Trans. Inf. Theory 197218142010.1109/TIT.1972.1054753 · doi ↗
- 6Blahut R. Computation of channel capacity and rate-distortion functions IEEE Trans. Inf. Theory 19721846047310.1109/TIT.1972.1054855 · doi ↗
- 7Yu Y. Squeezing the Arimoto-Blahut algorithm for faster convergence IEEE Trans. Inf. Theory 2010563149315710.1109/TIT.2010.2048452 · doi ↗
- 8Matz G. Duhamel P. Information geometric formulation and interpretation of accelerated Blahut-Arimoto-type algorithms 2004 IEEE Information Theory Workshop IEEE Press Piscataway, NJ, USA 2004667010.1109/ITW.2004.1405276 · doi ↗