MAB-Based Online Client Scheduling for Decentralized Federated Learning in the IoT
Zhenning Chen, Xinyu Zhang, Siyang Wang, Youren Wang

TL;DR
This paper introduces an online client scheduling method for decentralized federated learning in IoT using multi-armed bandit algorithms to optimize performance and reduce delays.
Contribution
A novel MAB-based online learning algorithm for client scheduling in DFL without prior client information.
Findings
The proposed algorithm achieves asymptotic optimal performance in client scheduling.
It significantly reduces the cumulative delay compared to existing methods.
Theoretical analysis and experiments validate the algorithm's effectiveness.
Abstract
Different from conventional federated learning (FL), which relies on a central server for model aggregation, decentralized FL (DFL) exchanges models among edge servers, thus improving the robustness and scalability. When deploying DFL into the Internet of Things (IoT), limited wireless resources cannot provide simultaneous access to massive devices. One must perform client scheduling to balance the convergence rate and model accuracy. However, the heterogeneity of computing and communication resources across client devices, combined with the time-varying nature of wireless channels, makes it challenging to estimate accurately the delay associated with client participation during the scheduling process. To address this issue, we investigate the client scheduling and resource optimization problem in DFL without prior client information. Specifically, the considered problem is reformulated…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
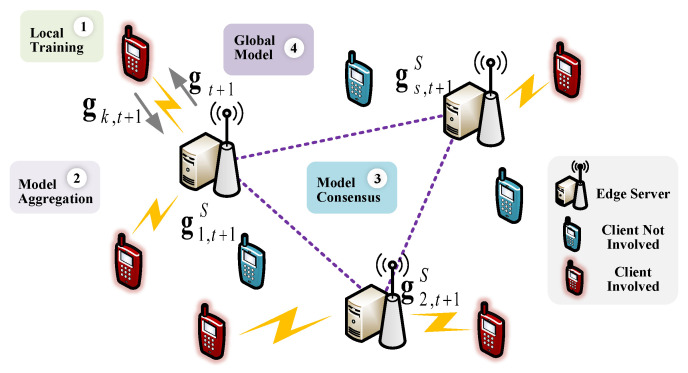 Figure 1
Figure 1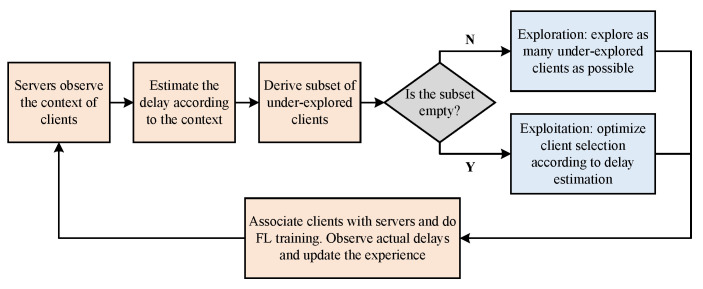 Figure 2
Figure 2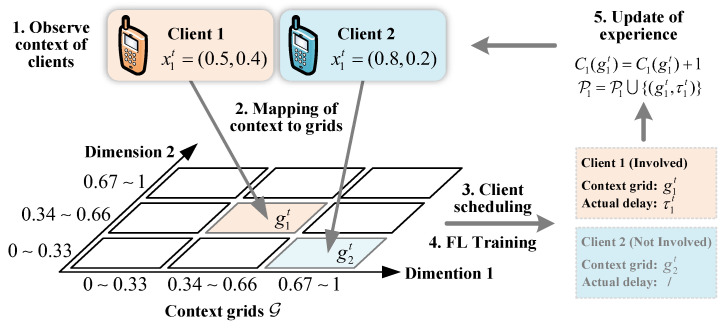 Figure 3
Figure 3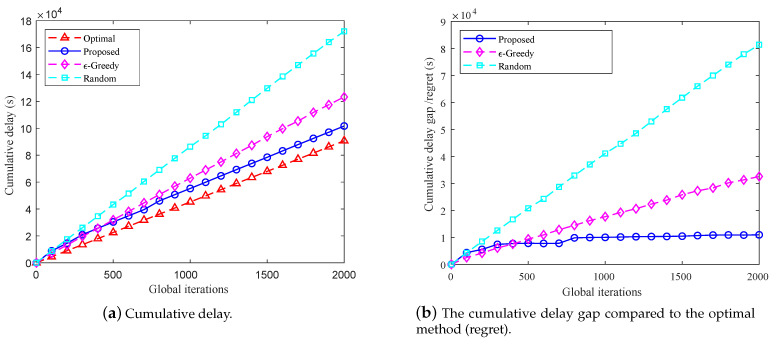 Figure 4
Figure 4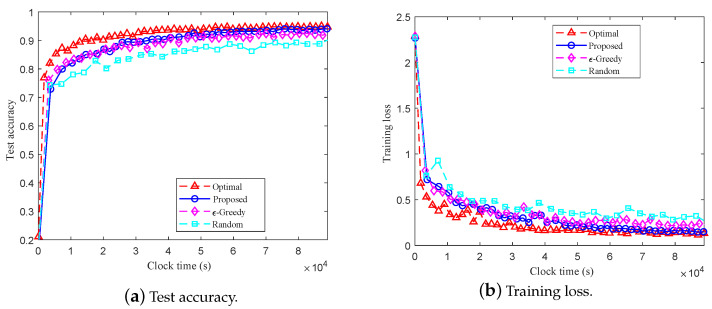 Figure 5
Figure 5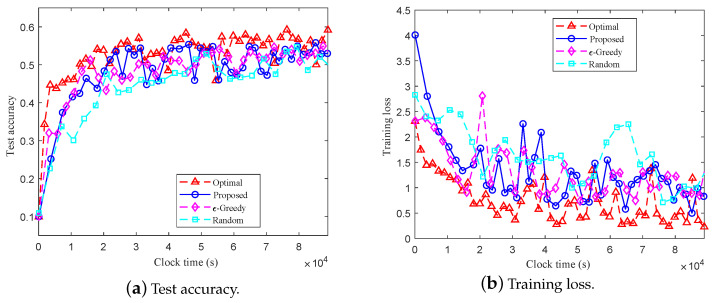 Figure 6
Figure 6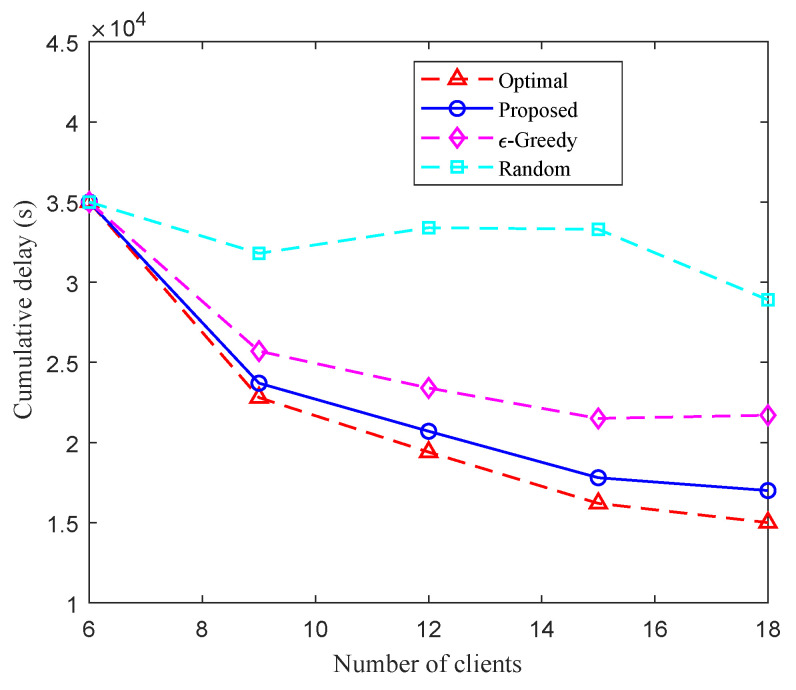 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPrivacy-Preserving Technologies in Data · Advanced Bandit Algorithms Research · Age of Information Optimization
1. Introduction
The Internet of Things (IoT), driven by the latest advancements in information and communication technologies, connects countless devices to the Internet, enabling seamless connectivity and real-time interaction between people, machines, and objects [1]. Recently, with the development of IoT, a large number of intelligent applications and services based on IoT have begun to emerge; while bringing great convenience to people’s daily work and life, it is also promoting profound changes in the fields of industrial manufacturing, agricultural production, and infrastructure construction [2]. At the same time, the development and widespread use of machine learning [3] makes it possible to mine huge amounts of potential value from the vast amounts of data generated by IoT devices, providing more intelligent solutions to existing and newly developed applications.
However, conventional centralized machine learning methods require user devices to upload their raw data, which may contain sensitive information, thus increasing the risk of privacy leakage [4]. Moreover, uploading large-scale raw data to the central server will consume many network bandwidth resources and cause considerable communication delays. Recently, federated learning (FL) [5] has been introduced as a solution to the aforementioned challenges. In FL, clients do not need to share their local data with the cloud or other clients; instead, they can train models locally and upload the updated model for global aggregation. Therefore, the risk of sensitive data leakage, as well as communication overhead, is significantly reduced. FL has been widely applied in different fields, such as natural language processing [6], intelligent manufacturing [7], intelligent transportation [8], and smart healthcare [9].
Traditional centralized FL systems are susceptible to the single point of failure effects; that is to say, when the central server is broken down, the FL training process cannot continue. Furthermore, the limited wireless resources cannot support ever-increasing user devices to participate in FL training simultaneously, and the scalability of the centralized FL systems is constrained [10]. Thus, decentralized FL (DFL) [11] architecture attracts researchers’ interest, deploying multiple servers and enabling more user devices to collaborate on global model training. DFL can reduce the impact of single server failure on model training and further improve system scalability.
However, the deployment of DFL in IoT still faces challenges [12]. Firstly, different user devices have different computing and communication resources, and we refer to this issue as resource heterogeneity [13]. Secondly, the data collected by different user devices are imbalanced and non-identically and independently distributed (non-i.i.d.), which is referred to as data heterogeneity. Thirdly, because the resource availability of user devices is time-varying, the local training delay and communication delay are difficult to estimate, and the training efficiency of FL cannot be guaranteed [14]. Finally, with the increase of user devices, multiple servers still cannot allow simultaneous access to massive devices due to the limited radio resources. To address these challenges, this work aims to propose a novel client scheduling strategy that selects a portion of clients to participate in the DFL training process in each round. The main contributions of this paper can be summarized as follows:
- This paper considers the client scheduling problem in DFL scenarios. Due to the heterogeneity of local computing and communication resources, as well as the time-varying nature of wireless channels, the total delay of each client in each round cannot be predicted. Thus, we formulate the client scheduling problem as a contextual combinatorial multi-armed bandit (CC-MAB) program [15].
- We propose an online client scheduling algorithm that estimates the delay of clients based on their contextual information during training and continuously updates the estimator according to the actual delay. Through theoretical analysis and algorithm parameter design, this algorithm can achieve asymptotic optimal performance in theory.
- Finally, through extensive experiments, we show that the algorithm can make asymptotically optimal client scheduling decisions, which is superior to existing algorithms in reducing the cumulative delay of the system.
The rest of this work is organized as follows. Section 2 presents the related works. Section 3 and Section 4 introduces the system model and formulates the optimization problem. Section 5 and Section 6 provides the convergence analysis and client scheduling algorithm. Section 7 presents the simulation results, followed by the conclusions in Section 8.
2. Related Works
2.1. Client Scheduling in Centralized FL
There have been many works studying client scheduling and resource allocation in the traditional centralized FL. The authors in [16] aimed to reduce the communication load on the central server by identifying clients with irrelevant updates and excluding them from model aggregation. In [17], a communication- and computation-efficient client selection method was proposed where the clients with significant local training losses were selected to accelerate model convergence. In [18], the importance of local learning updates was measured based on the gradient differences of local learning updates, and then a client scheduling method was proposed to balance between client channel quality and update importance. A joint optimization method for client selection and wireless resource allocation based on bipartite matching was proposed in [19], which minimized the global training loss function by optimizing the transmission power of client devices and the wireless resource allocation of servers. The authors in [20] modeled the client scheduling problem in wireless FL with unknown client channel states as an MAB program [21] and proposed a solution based on the -greedy method to balance exploration and exploitation.
There are also some works focusing on optimizing the efficiency of hierarchical FL. For example, the work [22] formulated a joint problem of client scheduling and resource optimization in a hierarchical FL architecture and solved the problem by decomposing the original problem into two sub-problems: resource allocation and edge server cooperation. The authors in [23] simultaneously considered the uncertainty of wireless channels and the weights of client models and transformed the original optimization problem into a mixed integer nonlinear programming problem through theoretical derivation for a solution. The work [24] considered a multi-objective optimization problem under local computing resources and client transmit power constraints and proposed an algorithm based on deep reinforcement learning. In terms of improving system energy efficiency, the work [25] simultaneously considers the local data distribution of clients and the delay caused by model transmission. By jointly optimizing the association strategy between clients and edge servers and resource allocation, the system communication energy consumption is minimized. The work [26] considers the joint optimization of client-server association and client local computing power control under long-term energy consumption constraints to simultaneously minimize global training loss and delay. The authors in [27] studied the client scheduling problem in a hierarchical FL framework and proposed a method based on contextual combined MAB to learn the states of clients who successfully participate in training during the global iteration process, thereby providing appropriate client selection strategies for subsequent training.
2.2. Client Scheduling in DFL
Due to limited communication and computing resources, the key to optimizing the DFL performance lies in balancing the number of communication and computing rounds. The authors in [28] proposed a universal DFL framework to achieve a balance between system communication efficiency and global model convergence by performing a certain number of local model updates and model exchanges between nodes in each round of global iteration. Similarly, the authors in [29] considered the resource heterogeneity of different devices and analyzed the impact of local training on the global model convergence. Based on the analysis results, closed-form solutions for local training rounds of different local nodes were obtained. Furthermore, the authors in [30] incorporated the node selection strategy into a regularized multi-objective optimization problem, aiming to maximize system knowledge gain while minimizing energy consumption. In response to the limited node resources in large-scale IoT scenarios, the work [31] proposed a joint optimization method of node scheduling and bandwidth allocation in asynchronous DFL, aiming to minimize the transmission delay of FL models and improve convergence speed.
However, the above literature assumes that there are no model errors or losses during the model propagation process, which is unrealistic, especially in wireless environments. Although the reliability of model transmission can be improved through the use of the transmission control protocol (TCP) [32] and other methods, more additional communication overhead is caused, and the scalability of the system is reduced. To address this issue, the work [33] divided the model parameters into multiple data packets and sent them through the user datagram protocol (UDP) [34]. Then, the weighted matrix of the inter-node model mixture based on the reliability matrix of inter-node communication was optimized.
3. System Model
We consider an area comprising S cellular cells, each served by a base station (BS) located at the center of the cell. Each BS is equipped with an edge server, and the set of these edge servers is denoted by . There are K single-antenna devices (clients), denoted by a set , that are randomly distributed in the considered area. We assume that each edge server has N orthogonal wireless channels. In other words, each server can communicate with up to N clients within the communication range of the BS at the same time (See Figure 1). The set of clients in the cell s is located is denoted as with . In this work, we assume that .
All the clients and edge servers in the area are organized to train a shared global model through DFL. The edge servers select the participating clients at the beginning of each training round. We define the binary variable . Specifically, if device k participates in the training of round t, ; otherwise, . We further define the set of clients participating in round t as . Similarly, we denote by a set of clients which are associated with edge server s. Furthermore, we collect these into and denote by the client participation metric of all the training rounds.
3.1. DFL Process
The goal of DFL is to minimize the weighted global training loss, i.e.,
where are the global model parameters, and is the local training loss of client k, denoted as
where is the size of the local dataset of client k, and is the local loss function of training data .
Each global training round of the DFL involves three phases: (1) local model training, (2) intra-cluster model aggregation, and (3) inter-cluster model aggregation. During the local model training phase, each client updates model parameters based on their local training dataset as
where denotes the local model of client k in round , denotes the global model at the end of the previous training round, represents the learning rate, and is the gradient of the model on the training dataset . In the phase of intra-cluster model aggregation, the clients participating in the training process upload their latest local model parameters to the associated edge servers via cellular communication. Then, each edge server aggregates the received model parameters as follows:
where is the model of server s after intra-cluster model aggregation in round .
In the phase of inter-cluster model aggregation, each server transmits the updated model to other servers connected to it via high-speed wired links. In this work, we assume that the edge servers are fully connected. Thus, each server aggregates its received models and its models to obtain a global model:
where represents the global model obtained during the inter-cluster model aggregation in round . After inter-cluster model aggregation, each server sends the global model back to the associated clients, and the clients then substitute their local models with the global model.
3.2. Delay Model
Considering the sufficient computational power of the edge servers, the delay caused by model aggregation at the edge servers can be ignored. Additionally, the transmission delay of model transmission between the edge servers can also be ignored because of the high-speed wired links between these edge servers. Therefore, the total delay of client k in training round t is as follows:
where denotes the delay of the client downloading the latest global model from the associated server, denotes the delay of the client uploading the local model to the associated server, represents the delay caused by local model updates, and represents the maximum delay allowed for each training round. Specifically, the delay of client k in downloading the global model can be expressed as
with
where m is the data size of model parameters, B is the downlink channel bandwidth, is the downlink transmission rate, is the downlink transmission power, is the downlink channel gain, and is the noise power spectral density. Similarly, the delay of the client uploading the local model can be expressed as follows:
with
where is the uplink transmission rate, is the uplink transmit power, and is the uplink channel gain. The local update delay can be expressed as follows:
where is the number of CPU rounds required for calculating the unit data volume, are the computational resources of client k, and are the available computational resources of client k in round t.
4. Problem Formulation
In this work, we consider synchronous DFL training, which means that at the intra-cluster aggregation phase of each training round, the server conducts model aggregation only after receiving the models from all clients associated with it. Therefore, the delay of round t, denoted by , is determined by the slowest client, i.e.,
Due to the ever-changing wireless channel state and the available resources of client devices, the transmission and computational delay will vary during the training process. To shorten the training time of synchronous DFL, this paper optimizes the client participation scheme in a T-round training process to minimize the total delay, i.e.,
where (13c) is the access constraint that limits the maximum number of clients that each edge server can serve in each round. However, due to the uncertainty of wireless channels and client activities, the local processing delay and model transmission delay in (11) are hard to obtain.
Fortunately, we can infer the client delay in each round by observing contextual information. Specifically, the context of client k in round t is denoted as , where . The server estimates the delay of client k based on experience , i.e., , where is the estimator corresponding to client k. Based on the estimated delay of clients in each round, the system selects clients to participate in each training round. Therefore, the problem (13) is re-expressed as follows:
The key to Problem (14) is how to estimate client delay in each round according to the observed contextual information. In the following, we will introduce the contextual combinatorial multi-armed bandit (CC-MAB) programming [15], based on which a client scheduling algorithm is proposed.
5. Algorithm Design
In a CC-MAB problem, the player performs actions by pulling one or more of a set of arms. Every time an action is executed, the player will receive a reward value. Before executing an action, the player first observes the contextual information of each arm, and by recording the reward value obtained from executing the action, the player can obtain the corresponding expected reward of the action in that context. By continuously pulling different arms and recording reward values, players gradually learn the best strategy to maximize the expected reward value. It is worth noting that the action corresponding to the un-pulled arm will not be executed; therefore, no corresponding reward values will be recorded.
In our work, each edge server acts as the player, with its arms being all clients within its coverage area. The action of the server is to select a group of clients for scheduling in each training round, while the action space consists of all possible client combinations, subject to the constraint that each edge server can schedule at most N clients simultaneously. The reward obtained by the server in each round is defined as , where represents the delay in the current round. Therefore, we propose a client scheduling method based on CC-MAB programming, enabling the system to learn the optimal strategy and minimize cumulative delay. The client scheduling process is described as follows.
Before each training round begins, each edge server observes the context of clients within the cell. Subsequently, the servers estimate the delay of the clients in this round based on their historical experience information and contextual information. Afterward, each edge server determines client selection. After determining the clients participating in the training round, the system organizes the aforementioned clients to perform DFL model training. After the training is completed, each edge server records the actual delay of the clients participating in this training round and adds it to the client’s historical experience information along with the contextual information observed before the next round of training. Figure 2 summarizes the flow of the proposed client scheduling algorithm.
5.1. Delay Estimation Based on Contextual Information
The context of client k in round t is denoted as , where the context space contains D dimensions, denoted as . The contextual information considered in this work includes the following: (1) the client’s current device activity , such as the number of running programs, is reported by the client themselves; (2) the size of the local dataset used for training. Due to the continuous values in each dimension of the context space, training an estimator based on every possible scenario in the context space and estimating the delay will result in high computational complexity. Meanwhile, a set of similar contexts within a certain range often corresponds to similar delays. Therefore, we discretize each dimension of the context space and map the observed values to the partitioned grid points of the context space after observing the context information and estimating the delay based on the discretized context information (See Figure 3).
Assume that each dimension of the context space is uniformly divided into G parts. Then, in total, subspaces will be included. Each subspace in is referred to as a grid point, and the set of all grid points in forms a context set . Therefore, a mapping relationship from to can be established. Due to the fact that the value of G will affect the size of the context set, which, in turn, affects algorithm performance, it is necessary to set a reasonable value for parameter G.
The server observes the client’s contextual information before each training round and maps it to the corresponding grid points in the context set. Assuming that, before training round t, the context of client k is mapped to the grid point . If client k is selected to participate in this training round, the server will receive the actual delay of the client after the training is completed, denoted as . Subsequently, the pair is saved as experiences to update the corresponding estimator for the client. We denote the set of historical experiences corresponding to client k as .
The times of client k participating in training before round t with the context falling on the context grid is recorded using a counter . When client k is selected to participate in training in round t, and its context falls on the context grid point g, the counter corresponding to the grid point g of client k will be updated, i.e., .
In this work, the maximum likelihood estimator (MLE) is leveraged to estimate client delay. Assuming that the delay of client k corresponding to the same grid point g follows a normal distribution, then the estimation method can be expressed as follows:
5.2. Exploration and Exploitation
We define the empirical threshold function as , which is a monotonically increasing function of the training round t, representing the minimum value of that the client needs to reach on any grid point if they are considered to be well explored in round t. Therefore, the proposed algorithm selects the subset of clients to be explored in round t as follows:
where represents the set of all clients within the cell where edge server s is located, and represents the set of clients selected to be explored. Note that if , it indicates that there are still clients in the cell that need to be explored; thus, the cell enters the exploration phase in the current training round. Otherwise, the cell enters the exploitation phase.
(a) Exploration Phase: In the exploration phase, the player needs to select as many under-explored clients as possible to participate in training in order to enrich their experience and train the estimator. Here, two cases are considered, i.e., and . In the first case, all the clients in the cell are selected to participate in this training round. After that, the player will greedily select the client with the minimum estimated delay value from the remaining clients until . In the second case of , N clients are randomly selected from to participate in the current round of training.
(b) Exploitation Phase: In the exploitation phase, the player estimates the delay of each client in the current round based on the current estimator and contextual information and selects the clients participating in the training based on the estimated values to minimize the expected delay of the current round. For each well-explored cell, the optimization problem is formulated as follows:
Problem (17) can be simply solved using a greedy algorithm, which arranges the delay of all clients in the cell in ascending order and selects the top N clients to participate in this training round.
6. Key Parameter Design
In this section, the key parameters G and are designed to minimize cumulative delay of T-round training. Since the setting of parameter G depends on the total number T of training rounds, we re-express it using .
6.1. Upper Bound of Regret
Denote the optimal solution to Problem (14) by . The difference between the delay corresponding to the optimal solution in each round t and the actual delay based on the proposed algorithm is defined as the regret, i.e.,
The expected cumulative regret of round T is denoted as follows:
We also introduce two assumptions, as follows.
Assumption 1. For a specific estimator, as its historical experience increases, its estimation error for client delay will decrease. Therefore, it is assumed that for any grid point in the context set , the estimator corresponding to client k satisfies the following probably appropriately correct (PAC) property:
where represents the delay expectation when the client context is prior. is a term that decreases with the increase of the counter , which is related to the estimator.
Assumption 2. Empirically, it can be inferred that when the contextual information is similar, the delay of clients is also similar. Therefore, it is assumed that for each client , there exists and such that for any grid point in the context space , the following inequality holds:
where represents the Euclidean norm in .
With the above assumptions, we have the following theorem.
Theorem 1. Given Assumptions 1 and 2, when , the expected cumulative regret is upper bounded as follows:
Proof. Please see the Appendix A for reference. □
6.2. Parameter Design Based on the Upper Bound
It is assumed that the historical delay in the experience corresponding to the grid points . With the MLE, an unbiased estimate of is given as follows:
Note that the PAC property in Assumption 1 can be further refined as follows:
We further let with and with . Then, the first term on the right-hand side of (22) can be rewritten as follows:
Considering , we have the following:
Let . Then. the third term on the right-hand side of (22) can be rewritten as follows:
Considering , we have
Let , , and . Then, the highest power term of T in is , where .
Therefore, given and , the expected cumulative regret increases sub-linearly with respect to T and the asymptotic optimal decisions of client scheduling are obtained.
7. Experimental Results
7.1. Simulation Setup
All of the experiments involved in this work are conducted on a personal computer with a CPU 2.10 GHz Intel Core i712700F and 32 GB of RAM, running a 64-bit Windows operating system and PyTorch 1.13.1. Assuming that there are 3 edge servers and 18 client devices. Each edge server can communicate with up to 2 clients simultaneously. A total of 2000 rounds of DFL training are conducted.
The communication-related parameters are configured as follows. The channel gains for both uplink and downlink links consist of small-scale and large-scale fading. The small-scale fading follows a Rayleigh distribution with uniform variance, while the large-scale fading is modeled using the path-loss equation, , where d represents the distance in kilometers. The noise power is set to dBm, and the uplink resource block bandwidth is 1 Mbps. The transmit power of clients and edge servers is set to 10 mW and 1 W, respectively. The data size of model parameters is configured as .
The local computing-related parameters for clients are configured as follows. The computing capability of each client k is uniformly distributed within the range . The computational resource allocation is set to . The available computational resource follows a uniform random distribution given by in each round, where represents the number of active programs running on client k in round t, uniformly distributed within . Furthermore, the maximum interval is set to s. Table 1 summarizes the key parameters used in this work.
The MNIST dataset [35], comprising 70,000 grayscale images of handwritten digits (0–9), and the CIFAR-10 dataset [36], containing 60,000 color images across 10 categories, were employed for training handwritten digit recognition and image classification models, respectively. For each dataset, the data partitioning scheme was implemented as follows. After random shuffling, the dataset was uniformly distributed across all clients. In each training round, clients randomly determined the quantity of local data to utilize for model updates. For the MNIST dataset, a multi-layer perceptron (MLP) consisting of an input layer, a fully connected layer, and an output layer is chosen as the target model with a total of 101,770 trainable parameters. For the CIFAR-10 dataset, a convolutional neural network (CNN) consisting of two convolutional layers (and corresponding pooling layers), a fully connected layer, and an output layer is chosen as the target model with a total of 313,802 trainable parameters. During the training process, the batch size is set to 64. For the MNIST and CIFAR-10 datasets, the learning rates are set as 0.05 and 0.02, respectively.
To verify the effectiveness of the client selection strategy proposed in this work in reducing long-term cumulative delay, the following methods are introduced for comparison:
- Optimal client selection. In this method, the total delay of each client in each round of the system is known as a priority. When making decisions in each round, edge servers select the N clients with the smallest total delay in the covered cells to participate in training. Note that this method serves as the upper bound.
- -greedy client selection. This method employs a greedy metric to decide between exploration and exploitation. In the exploration round, each edge server randomly selects N clients from their covered cells to participate in training. In the exploitation round, each edge server selects the N clients with the minimum delay expectation to participate in training. This method does not utilize contextual information when making selection decisions, relying solely on randomness and delay-based selection. In this work, the value of is 0.3.
- Random client selection. At the beginning of each training round, each edge server randomly selects N clients from the corresponding cells to participate in the training.
7.2. Performance Analysis
Figure 4 shows the cumulative delay and the corresponding performance regret during the training process using different client selection methods on the MINIST dataset. It can be observed from Figure 4 that, compared to the random and -greedy client selection methods, the proposed method significantly reduces delay within the given number of training rounds. This observation indicates that the proposed method can effectively mitigate the effects of heterogeneous and time-varying client resources and improve training efficiency. In addition, we find that the cumulative delay performance gap of the proposed method can gradually have sub-linear growth over communication rounds.
Figure 5 and Figure 6 show the test accuracy and training loss over training time using different client selection methods on the MINIST and CIFAR-10 datasets, respectively. We observe that for both datasets, compared with the random and -greedy client selection methods, the proposed method can achieve the best performance, which suggests that the client selection method proposed in this work can effectively accelerate the convergence of the global model and reduce delay. Figure 7 shows the cumulative delay over different numbers of clients. As shown in Figure 7, when , i.e., all the clients can be associated with the edge BSs simultaneously, all four methods have similar delay performance. With the increase of clients (e.g., new clients joining the systems), the cumulative delay of the methods, except for the random selection method, decreases. Moreover, the cumulative delay of the proposed method is always lower than that of the -greedy and random client selection methods. The results in Figure 7 indicate that, compared to the random and -greedy client selection methods, the proposed method can effectively reduce the cumulative delay of the system.
8. Conclusions
This work investigates the client scheduling problem in a DFL scenario with multiple servers, where the local computing and communication resources of clients are heterogeneous and time-varying, and the aforementioned client resource priors are unknown. Firstly, model the delay generated during the FL training process and propose a client scheduling problem to minimize the cumulative delay. Subsequently, this work proposes a client scheduling algorithm based on context multi-arm slot machines. Through theoretical analysis and algorithm parameter design, this algorithm can achieve asymptotic optimal performance in theory. The experimental results show that the algorithm can make asymptotic optimal client selection decisions, and this method is superior to existing algorithms in reducing the cumulative delay of the system.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Nguyen D.C. Ding M. Pathirana P.N. Seneviratne A. Li J. Niyato D. Dobre O. Poor H.V. 6G Internet of Things: A Comprehensive Survey IEEE Internet Things J.2021935938310.1109/JIOT.2021.3103320 · doi ↗
- 2Lampropoulos G. Siakas K. Anastasiadis T. Internet of things (Io T) in industry: Contemporary application domains, innovative technologies and intelligent manufacturing People 2018610911810.31695/IJASRE.2018.32910 · doi ↗
- 3Jordan M.I. Mitchell T.M. Machine learning: Trends, perspectives, and prospects Science 201534925526010.1126/science.aaa 841526185243 · doi ↗ · pubmed ↗
- 4Majeed I.A. Kaushik S. Bardhan A. Tadi V.S.K. Min H.K. Kumaraguru K. Muni R.D. Comparative assessment of federated and centralized machine learningar Xiv 20222202.01529
- 5KonečnýJ. Brendan Mc Mahan H. Ramage D. Richtárik P. Federated Optimization: Distributed Machine Learning for On-Device Intelligencear Xiv 201610.48550/ar Xiv.1610.025271610.02527 · doi ↗
- 6Zhao P. Jin Y. Ren X. Li Y. A personalized cross-domain recommendation with federated meta learning Multim. Tools Appl.202483714357145010.1007/s 11042-024-18495-3 · doi ↗
- 7Hao M. Li H. Luo X. Xu G. Yang H. Liu S. Efficient and Privacy-Enhanced Federated Learning for Industrial Artificial Intelligence IEEE Trans. Ind. Inform.2020166532654210.1109/TII.2019.2945367 · doi ↗
- 8Samarakoon S. Bennis M. Saad W. Debbah M. Federated Learning for Ultra-Reliable Low-Latency V 2V Communications Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM)Abu Dhabi, United Arab Emirates 9–13 December 201817