Weak Identification Robust Tests for Subvectors Using Implied Probabilities
Marine Carrasco, Saraswata Chaudhuri

TL;DR
This paper introduces a new statistical test that improves accuracy when testing parts of a model's parameters under weak identification.
Contribution
A novel two-step test using implied probabilities is proposed to address over-rejection in weakly identified models.
Findings
The new test reduces size distortion and improves finite-sample performance.
Simulations confirm the test's strong size and power properties.
Application to veteran earnings data shows a negative impact of veteran status.
Abstract
This paper develops tests for hypotheses concerning subvectors of parameters in models defined by moment conditions. It is well known that conventional tests such as Wald, Likelihood-ratio and Score tests tend to over-reject when the identification is weak. To prevent uncontrolled size distortion and introduce refined finite-sample performance, we extend the projection-based test to a modified version of the score test using implied probabilities obtained by information theoretic criteria. Our test is performed in two steps, where the first step reduces the space of parameter candidates, while the second one involves the modified score test mentioned earlier. We derive the asymptotic properties of this procedure for the entire class of Generalized Empirical Likelihood implied probabilities. Simulations show that the test has very good finite-sample size and power. Finally, we apply our…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
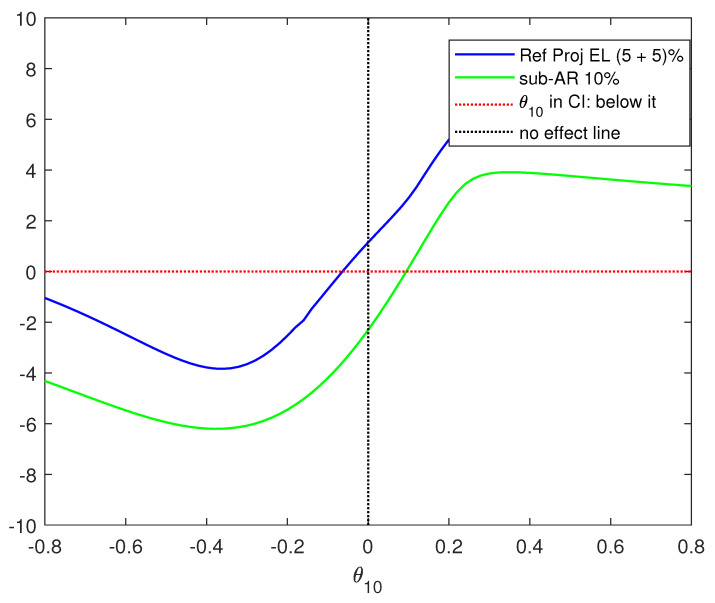 Figure 1
Figure 1- —FQRSC
- —SSHRC
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMonetary Policy and Economic Impact · Statistical Methods and Inference · Economic Policies and Impacts
1. Introduction
We are interested in developing tests for hypotheses concerning subvectors of an unknown parameter The true value of the parameter denoted by satisfies a vector of moment conditions:
where the vector is known and The moment conditions may stem from the first-order condition of the maximization of any criterion written as an expectation (for instance the expected utility in economics). They may also come from matching theoretical and empirical moments (see Section 4.1) or from instrumental variables (see Section 5). Other examples can be found in the book by Hall [1]. A particularity of our tests is that they are robust to weak identification.
To illustrate the notion of weak identification, consider the example of the linear instrumental variable regression:
where the endogenous regressor is a scalar random variable related to the instruments through the reduced-form equation
where . Let , and the moment condition corresponding to the orthogonality between and is
If is non-null and independent of n, the instruments are strongly correlated with the endogenous regressor , and hence the instruments are said to be strong. In that case, is identified in the sense that Then, the GMM estimator is consistent with the rate of convergence. When , the correlations between and go to zero, and the instruments are said to be weak (in the sense of Staiger and Stock [2]). In that case, the GMM estimator of is not consistent because as for all (with fixed). Then, the standard confidence intervals and tests are not reliable. In the nearly weak/semi-strong case, i.e., when with , the GMM estimator of is consistent with a slower rate of convergence than the usual (see Antoine and Renault [3] and Andrews and Cheng [4]).
Based on a random sample , the standard approach of inference is to conduct a Wald test based on the Generalized Method of Moments (GMM) estimator of or a score test. Wald tests have been shown to be inappropriate in the presence of weak identification (Dufour [5]). Moreover, the GMM-based score test proposed by Newey and West [6] is plagued by size distortions under common scenarios such as skewed moment vectors or models with weak identification; see the discussion in Wang and Zivot [7]. To improve the finite sample properties of this test, Chaudhuri and Renault [8] and Chaudhuri and Renault [9] propose to replace the uniform weights by implied probabilities obtained from an Information Theory criterion. These probabilities exploit the information from the model, namely that . So the implied probabilities are selected such that the moments hold exactly:
However, given that the number of moments, is smaller than the sample size n, there is an infinity of possibilities for , . The estimation of is an ill-posed problem. Which distribution should be used? A solution inspired from the entropy literature is to select the distribution obtained by minimizing the Cressie–Read divergence measure under the moment restrictions. Equivalently, one could also work with the Generalized Empirical Likelihood (GEL) that is characterized by the dual problem of this Cressie–Read divergence minimization. Two notable members of this class are the Empirical Likelihood estimator and the exponential tilting estimator (see Newey and Smith [10]). All these estimators can be viewed as Information Theory estimators (see Kitamura and Stutzer [11] and Golan [12]).
Chaudhuri and Renault [9] focus on tests for the entire parameter vector, i.e., and they show that implied probability-based score tests lead to improved finite sample properties compared to the conventional score test. In particular, they have better size control and remain powerful.
In this paper, we are concerned with testing the subsets of parameters . More precisely, we want to test The subset version of score tests suffers from important size distortion as shown by Guggenberger et al. [13]. To address this issue, we suggest to use the projection-based test developed by Chaudhuri and Zivot [14] coupled with the score test that includes the GEL implied probabilities.
The contribution of our paper is to provide a framework that opens up the possibility of applying any type of the Generalized Empirical Likelihood or Cressie–Read implied probabilities to the type of score tests discussed in Chaudhuri and Zivot [14]; see also Smith [15], Newey and Smith [10]. We derive the asymptotic properties of the resulting tests using the properties of the implied probabilities obtained in Chaudhuri and Renault [9] and generalized to include all the GEL estimators. Special care is taken to allow for weak identification. The simulations show that these tests perform well in terms of finite-sample size and exhibit strong power under the alternative. We complete the paper with an empirical illustration examining the effect of veteran status on earnings. Using our proposed test, we construct confidence intervals for the returns to veteran status on earnings, leveraging instrumental variables. This analysis, inspired by Chaudhuri and Rose [16], builds on the seminal natural experiment framework developed by Angrist [17] and Card [18], which earned them the 2021 Sveriges Riksbank Prize in Economic Sciences in Memory of Alfred Nobel. Our findings provide evidence of a negative impact of the veteran status on earnings.
The related literature is vast. The application of Information Theory measures to the estimation of econometric models goes back to Golan et al. [19], Kitamura and Stutzer [11], Imbens et al. [20], Smith [21], and Kitamura [22], among others. The use of the implied probabilities in the context of testing the hypothesis in the GMM setup was pioneered by Guggenberger and Smith [23] and further developed by Caner [24], Chaudhuri and Renault [8], and Chaudhuri and Renault [9]. Our current paper builds on this literature. Extensive research in econometrics has demonstrated that testing subsets of parameters in the face of commonly encountered problems such as weak identification is a much more difficult problem than testing the full parameter vector studied in Chaudhuri and Renault [9]; see Guggenberger et al. [13], Andrews et al. [25]. Chaudhuri and Zivot [14] provide an early contribution to the weak identification robust testing of subsets of parameters that is subsequently extended and refined in Andrews [26] and Andrews [27], and that is particularly suitable for application of the Information Theory. Time series extensions of generalized empirical likelihood are proposed by Otsu [28] and Guggenberger and Smith [29]. Recent papers have tried to develop most powerful tests for subvectors; see Guggenberger et al. [30], Kleibergen [31], and Kleibergen et al. [32]. In the current paper, we demonstrate that the application of Information Theory in the form of implied probabilities to the test of Chaudhuri and Zivot [14] for subsets of parameters delivers improved finite-sample performance.
The remainder of this paper is organized as follows. Section 2 describes the GMM framework and the implied probabilities in the context of the null hypothesis for subsets of parameters that is the focus of our interest. Section 3 discusses the score test for subsets of parameters and establishes its asymptotic properties. Section 4 provides evidence of the improved performance of this test using simulation results in empirically relevant settings. Section 5 includes the empirical application. Finally, Section 6 concludes. The main proofs are collected in Appendix A.
Notation. For a sequence of real numbers, means as for some constant c; means as The notation represents the convergence in probability as . If is a sequence of random variables, then if where is a deterministic sequence. Similarly if
2. Implied Probabilities for Hypothesis on Subsets of Parameters in
the GMM Framework
2.1. Background
Let be independent and identically distributed (i.i.d.) random variables. Let be the -dimensional moment vector, a -dimensional random vector, the parameter space, and let . The dimensions , and are fixed and hence do not depend on n. Suppose that we have a set of moment restrictions:
which holds for the true value of the parameter
Our goal is the testing of hypotheses on subsets of parameters, i.e., a subvector of . Without loss of generality, let , and let the null hypothesis of interest be
The parameter is the parameter of primary interest, while is the nuisance parameter.
The usual approach to tackle this problem consists in estimating by constrained GMM. Constrained estimators are obtained by imposing the null hypothesis. The estimator takes the form that restricts by but lets the parameters be unrestricted. Given a first-step consistent estimator of , denoted , the constrained GMM estimator is a solution of
where is the set of elements of such that , , and Let . The score test proposed by Newey and West [6] is
where
According to Chaudhuri and Renault [8] and Chaudhuri and Renault [9], the poor finite sample properties of the score test can be improved by replacing the averages in and by weighted sum using Information Theory. Instead of averaging using an equal weight one should use the implied probabilities obtained from information theoretic criteria. The criterion considered is the Cressie–Read family.
The optimization problem solved by the implied probabilities for is
The objective function (4) is defined for any real , including the two limit cases and corresponds to Empirical Likelihood (EL), and corresponds to the Euclidean Empirical Likelihood (EEL), and to the Kullback–Leibler Information Criterion (KLIC) that is consistent with Shannon’s entropy. The so-called Generalized Empirical Likelihood (GEL) estimator of is obtained by minimizing the criterion in (4) with respect to or alternatively by minimizing the dual problem based on the Lagrange multipliers associated with the constraints ; see Guggenberger and Smith [23] and Chaudhuri and Renault [9]. Here, however, the aim is not to estimate but to perform a test. Therefore, we need to go further than the aforementioned references and devise the two-step approach described in Section 3 to address the additional inferential issues of the uncontrolled over-rejection of the truth without an unnecessary loss in power.
2.2. Assumptions
Let us define
We remark that this definition of corresponds to the appropriate estimator of for the EEL estimator.
Consider a sequence of subsets of containing . is a neighborhood of whose width depends on the identification strength in (1). Typically, is narrower for strongly identified parameters and wider for weakly identified parameters.
We will maintain Assumptions 1 and 2 below to show the asymptotic equivalence of the implied probabilities for ; see Guggenberger and Smith [23] and Chaudhuri and Renault [9] for more discussion.
Assumption 1.
- (i)
- .*
- (ii)
- .*
- (iii)
- for .*
- (iv)
- .*
Assumption 2.
- (i)
-
, ,*
-
and .*
- (ii)
- where and stand for the smallest and largest eigenvalues, respectively, of .*
Assumption 1 is not restrictive if is reduced to for all In that case, Assumptions 1(i) and 1(iii) are fulfilled by definition. Assumptions 1(ii) and 1(iv) follow from the fact that is i.i.d. with zero mean and finite variance. Assumption 1(ii) is a consequence of the Borel–Cantelli Lemma. Assumption 1(iv) can be proved by the Lindeberg–Levy Central Limit Theorem. The validity of Assumption 1 when is a local neighborhood of , where the definition of local depends on the identification strength of , follows under mild conditions.
Regarding Assumption 2(i), it requires the uniform law of large numbers for the sample covariance matrix only. The two convergences on the first line of (i) are equivalent, provided Assumptions 1(i) and 1(iv) hold. The same is true for the convergence on the second line under the extra condition of Assumption 2(ii), which ensures that the population covariance matrix is positive definite and finite.
2.3. Properties of GEL Implied Probabilities
In this section, we investigate the properties of weighted sums based on implied probabilities. To do so, it is convenient to use the dual representation of the estimators introduced in Section 2.1.
Let be a scalar function that is concave on its domain , an open interval containing 0. The GEL class of estimators of is indexed by the function and is defined as
Different choices of lead to different GEL estimators. The Continuous-Updating GMM or Euclidean Empirical Likelihood (EEL) estimator is a special case with ( ) corresponding to in Equation (4), the Empirical Likelihood (EL) estimator ( ) corresponds to , the exponential tilting (ET) estimator ( ) to , etc., all of which satisfy Assumption below.
Assumption : (GEL function) is a continuous function such that
(i) is concave on its domain , which is an open interval containing 0.(ii) is twice continuously differentiable on its domain. Defining for and , let (standardization for convenience).(iii)There exists a positive constant b such that for each , hold.
The desirable higher-order properties of the GEL estimators are due to the GEL first-order condition, which, assuming the differentiability of the moment vector with respect to , is given by
where for given and
Interestingly, the form of for EL leads to for . It is because of this along with the orthogonalization property of the implied probabilities (shown in Proposition 2 below) that the EL estimator has superior higher-order properties among the GEL class (see Newey and Smith [10]).
Note that Assumption is a technical assumption needed only for the proofs. Now, we are able to establish some important results relative to the GEL implied probabilities.
Proposition 1. Let Assumptions 1, 2, and ρ hold. Then, for :
- (A)
- defined in (5) is such that ,*
- (B)
- defined in (6) is such that for a given ,*
where ’s are the implied probabilities from EEL with the closed-form expression
Remark 1. It follows from (B) that the difference between the EEL and GEL implied probabilities is of a smaller order than that between the EEL implied probabilities and the naive empirical probabilities . It may be tempting to argue that the use of the GEL implied probabilities to reweight the observations results in an equivalence up to one higher order. However, this result, in itself, is not sufficient for such a claim because (B) is not uniform in . We provide a formal proof of this claim in Proposition 2.
Proposition 2. Let Assumptions 1, 2, and ρ hold, and let θ be an arbitrary element of . Consider n i.i.d. realizations of a random vector . Denote . Assume that , (finite) and that
Then, as , we have
- (B)
- ,*
- (B)
- .*
Remark 2. The proofs of Propositions 1 and 2 are given in the Appendix. Some of these results are already established in Chaudhuri and Renault [9]. However, the result for the ET estimator is not covered in Chaudhuri and Renault [9]. This is important because ET is the only GEL estimator fully consistent with Shannon’s entropy.
Proposition 2 shows that the weighted average involving the implied probabilities is asymptotically independent of the average . Replacing by the first derivative of or by one can deduce that the implied probability estimates of the Jacobian and variance are asymptotically independent of . In the case of weak identification, this asymptotic independence of the estimated Jacobian (and estimated variance) with the moment vector leads to better finite-sample properties.
It follows from Proposition 2 that the use of the implied probabilities provides a more precise estimator of since the asymptotic variance is smaller than The score test for the subsets of parameters that we will discuss now allows for weak identification that makes the use of implied probabilities necessary. Chaudhuri and Zivot [14] followed Kleibergen [33] and therefore implicitly used the EEL (Euclidean Empirical Likelihood) implied probabilities. Our paper opens up the possibility of using other implied probabilities for the same test for subsets of parameters, and demonstrates using simulations that other implied probabilities, such as those from EL, can provide significant improvement in its finite-sample performance.
3. Score Test for Subsets of Parameters Using the Implied Probabilities
3.1. Score Vector and Score Statistic Using the Implied Probabilities
Following Chaudhuri and Renault [9], we define the general score vector:
where
and and may be different but such that
The choice of leads to the standard GMM score statistic (3) as defined in Newey and West [6]. The choice of (EEL) and leads to the K-statistic of Kleibergen [33]. The other choices in (8) cover the various score statistics of Guggenberger and Smith [23]. Importantly, note that and can be based on different s, accommodating for hybrid GEL score statistics in the spirit of Schennach [34]. We refer the interested reader to Chaudhuri and Renault [9] for further discussion on the score vector.
Pretending that the parameters are all strongly identified, the natural estimator of the asymptotic variance of would be
Using (9), the general score statistic based on the general score vector in (7) is given by
It is now well known that if is weakly identified, then plugging in a GMM estimator of that is restricted by in (2) generally results in a badly over-sized test; see Andrews [26] for a comprehensive discussion. An alternative to such plug-in tests is the projection tests as in, for example, Dufour and Taamouti [35,36]. However, projection tests can be needlessly conservative.
Therefore, we adopt here the idea of the refined projection score test as in Chaudhuri [37], Zivot and Chaudhuri [38], Chaudhuri et al. [39], Chaudhuri and Zivot [14]. Our presentation can be adapted to the more sophisticated version of the aforementioned tests that was introduced in Andrews [26], but that is not performed here for simplicity and brevity.
To present the refined projection score test for the null hypothesis (2) on , treating as the nuisance parameters, it will be useful to introduce the natural partition of and conformable to the partition of as
where the right-hand side of the last two lines above use to denote to avoid notational clutter. Using the notation in (11), it is straightforward to decompose the score statistic in (10) as follows:
where, borrowing the maximum-likelihood terminology from Cox and Hinkley [40],
are respectively the score statistic for and the efficient score statistic for . The efficient score statistic expressed at can be seen as the statistic of Neyman [41] for testing Interestingly, this test has, under standard regularity conditions, an asymptotic distribution that is invariant to the -local perturbation of from the truth ; see, for example, Bera and Bilias [42]. So the unknown nuisance parameter can be replaced by a -consistent estimator without altering the asymptotic distribution of the statistic.
Another important fact is that can be constructed using any choice of implied probabilities (including ) for the Jacobian or the variance matrix, which will now allow us to explore the improved performance of the refined projection score test idea for the null hypothesis in (2) with the use of these implied probabilities.
3.2. Refined Projection Score Test Using the Implied Probabilities
To test the null hypothesis we propose to use the refined projection score test as in Chaudhuri [37], Zivot and Chaudhuri [38], Chaudhuri et al. [39], Chaudhuri and Zivot [14] but with the accommodation for the various choice of implied probabilities. The test is conducted in two steps:
- Step 1: Construct a confidence interval for under the restriction of the null hypothesis . is a random subset of the parameter space of and is defined as follows:
where denotes the b-th quantile of a chi-square distribution with a degrees of freedom.
- Step 2: Reject the null hypothesis if either is empty or
where is the dimension of . When deemed necessary, one should impose following Kleibergen [33,43] to be robust to the weak identification of .
Step 1 corresponds to inverting the S-test of Stock and Wright [44]. In special cases, such as the linear instrumental variables regression with conditionally homoskedastic error, can be obtained analytically using closed-form formula presented in Dufour and Taamouti [35]. Moreover, Sun [45] provides a STATA command “twostepweakiv” with the “project” option to obtain confidence intervals for based on the version of this refined projection test from Chaudhuri and Zivot [14].
The difference between the refined projection test and the Newey and West [6], Kleibergen [33,43] or Guggenberger and Smith [23] score test is that the former performs a projection of from , while the latter plugs in an estimator of in that makes in (12) zero. This difference enables the refined projection test to guard against the uncontrolled over-rejection of a true under weak identification. All these tests are asymptotically equivalent under strong identification thanks to the form of .
On the other hand, the refinement provided by the refined projection test over the standard projection test principle is two-fold. First, the projection is performed from instead of from , as is performed by the latter. Second, the test statistic and critical values used are and instead of and , as is performed by the standard projection score test. The restricted projection from instead of from and the use of the smaller critical values based on the degrees of freedom instead of of the chi-squared distribution are what make the refined projection test more powerful than the standard projections tests.
Without the weak identification problem, the refined projection test is the efficient test in the sense of Newey and West [6]. The standard projection score test is less powerful. In presence of weak identification, both the standard projection score test and the refined projection score test guard against the uncontrolled over-rejection of the truth, while the Newey and West [6], Kleibergen [33,43] or Guggenberger and Smith [23] score tests do not do so.
The following proposition makes precise the statement about “uncontrolled over-rejection” and “efficient test” made above. For brevity, we list the technical assumptions , SW, and D in the Appendix. These additional assumptions are essential for establishing the asymptotic properties of the refined projection test in Chaudhuri and Zivot [14] to which we refer the readers for the proof. Then, by appealing to the results in Propositions 1 and 2 that were obtained under Assumptions 1, 2, and , the results stated in Proposition 3 follow directly.
Proposition 3. Let Assumptions 1, 2, and the three assumptions Θ, and D, stated in the Appendix, hold. Then, we obtain the following results for the refined projection score test using the implied probabilities in (8):
- (i) The asymptotic size of the test cannot exceed for any choice of and with under a restriction in (8) that .
- (ii) If all elements of θ are strongly identified as in Newey and West [6], and , then the test with any given such that is non-empty and is asymptotically equivalent to the infeasible efficient score test that rejects if .
Remark 3. The tests discussed here involving various implied probabilities have the same first-order asymptotic properties as the test in Chaudhuri and Zivot [14]. Indeed, their asymptotic size cannot exceed , and if there is no problem of weak identification, then for any choice of τ (however small or large), these tests are asymptotically equivalent to the asymptotically efficient infeasible score test with asymptotic size α. So, with strong identification, the asymptotic size of this test is α, provided the first-step confidence interval is non-empty. The results in Chaudhuri and Renault [9] suggest that the use of the implied probabilities could lead to better properties in the finite samples. This is precisely what we find in the Monte Carlo experiment described below.
4. Monte Carlo Experiment
The improvement in the finite-sample size properties of tests by the use of implied probabilities is well known. The characterization of the asymptotic size described in Proposition 3(i) of the refined projection test appeals to the Bonferroni inequality applied to the size properties of two full vector score tests. Guggenberger and Smith [23] and Chaudhuri and Renault [9] document evidence that the finite-sample size of the full vector score tests with various implied probabilities is similar to their nominal level under various scenarios involving different strengths of identification. This will be confirmed here in our simulations.
On the other hand, less attention has been paid to the matter of improvement in power; the work of Chaudhuri and Renault [9] is an exception but only when testing a full vector ( and not ). However, there is a big difference between the power of a test for the full vector versus a test for subset of , and the main advantage of the refined projection test concerns its power. Therefore, we will primarily focus on the power properties of the refined projection score test for , compared to that of the plug-in tests. Since the power properties of the plug-in tests are better understood when parameters are strongly identified (see Andrews [26]), we will maintain strong identification of in this section.
4.1. Design
In this section, we examine a model that is not subject to weak identification but is instead affected by large higher-order moments, leading to difficult estimation of the variance matrix. This is the same experiment as that considered in the unpublished manuscript by Chaudhuri and Renault [46]. We generate
where and . We exploit the first two moments of the Gamma distribution, i.e., and to conduct the score tests. Consequently, the moment vector is defined as
and it satisfies the moment restrictions in (1) for . The Jacobian does not depend on , so the implied probabilities are not involved in its estimation. The elements of the moment vector are skewed. Indeed, the skewness of the first element is 2, while that of the second element is approximately 6.6. Moreover, the two elements of the moment vector are strongly leptokurtic with fourth moments equal to 144 (kurtosis = 9) and 8,982,528 (kurtosis = 87.7), respectively. Hence, the estimation of the variance might be problematic and, therefore, appropriate weighting for the estimator of the variance matrix might be crucial.
4.2. Results
There is no weak identification issue in this design. Hence, without the fear of over-rejection of the truth, according to the first-order asymptotics, one could plug in the restricted GMM estimator of in the second-step test statistic instead of minimizing the test statistic over values of in the first-step confidence interval. This is similar in spirit to the score test of Newey and West [6]. Taking advantage of the form of ’s asymptotic invariance to -local deviation of from , we plug in the computationally convenient restricted GMM estimator of in . We consider this plug-in version of the score test for three popular choices: (i) ; (ii) , i.e., the EEL implied probabilities; and (iii) , i.e., the EL implied probabilities. We similarly consider each of these choices for the refined projection score test with two choices and for the first-step confidence interval. Asymptotic theory says that all tests considered here are asymptotically equivalent and efficient in this case.
To explore the finite-sample properties of the tests, we run 5000 Monte Carlo trials for the sample sizes and The theoretical size is for all tests. Table 1 contains the rejection rate of the null of all these tests for a grid of deviations from the null, i.e., . The columns contain rejection rates for the plug-in score test and our refined test with two values of , 5%. The row with corresponds to the empirical size of the tests.
First, we analyze the size. We see that the plug-in version of the score test for all three choices of over-rejects the true null. Over-rejection goes down for the choices and when the sample size increases to . However, the refined projection version of the score test for all three choices largely solves this problem of the over-rejection of the truth even when . Importantly, we see that the choice of versus for the refined projection does not much affect the finite-sample rejection rate of the truth under this strong identification setup.
Moving to the discussion of power, we see that the refined projection test has good power in small samples. Now, comparing the choices , , , we see that the finite sample power of the third choice, i.e., EL, is much better than that of the other two. The lower power in small samples for the choice supports that orthogonalization by the implied probabilities in the variance matrix estimator is important for power. However, do note that the (EEL) delivers the worst power in spite of the orthogonalization by the implied probabilities in the variance matrix estimator. This happens because the EEL implied probabilities can be negative, which rules out the positive (semi-) definiteness of the variance estimator and, in turn, leads to an unduly small under false null hypotheses. The shrinkage of the EEL implied probabilities to make them positive, as suggested in Antoine et al. [47] and extensively used in Chaudhuri and Renault [9], can alleviate this problem of poor power to some extent but is not investigated here.
The refined projection test with the EL implied probabilities is the clear winner in terms of size and power. Its superiority is more prominent in the smaller sample, where it matters more.
Another Monte Carlo experiment using a linear instrumental variables regression confirms the good size and power of our test (the results are available from the authors upon request).
5. Application to the Impact of Veteran Status on Earnings
Following Chaudhuri and Rose [16], we propose to estimate the effect of the veteran status on future earnings for Vietnam war veterans in the United States by running an instrumental variables regression of log annual earnings on the dummy variable veteran status and a variety of control variables related to both earnings and veteran status. One important variable which influences earnings is years of schooling. However, since schooling is related to some unobservable variable (“ability”) that is related to both earnings and veteran status, it is obviously endogenous. So, we wish to estimate a regression of the log earnings on both veteran status and schooling. (The causal question in this empirical illustration is a difficult one due to the nature of the relationship between veteran status and schooling. First, the veteran status can help increase the years of schooling because of the subsidy provided by the GI Bill. Hence, schooling can be a mediator through which the veteran status affects wages. Second, the draft avoidance behavior of individuals was often enacted by enrolling in college and thereby increasing years of schooling. That is, the decisions to join the military and for the continuation of schooling were often made simultaneously. A more complete analysis is beyond the scope of this paper.) Given both regressors are endogenous, we need to use instrumental variables.
Angrist [17,48] used the Vietnam Era draft lottery that determined the draft eligibility of individuals, to instrument for an individual’s veteran status in the Vietnam war. A popular choice of instrument for schooling since Card [18,49,50] has been the presence of colleges in the neighborhood of where the individual grew up. Following these seminal references, we use four instrumental variables: (i) the lottery number assigned to the individual based on their date of birth, (ii) the lottery ceiling for the year when this individual attained draft age, (iii) a dummy variable indicating the presence of a 4 year accredited public college, and (iv) a dummy variable indicating the presence of a 4 year accredited private college in the neighborhood of the individual’s residence in 1966.
Partialling out the control variables from the system by taking the residuals from a regression of the concerned variables on those controls and the intercept, we focus on the instrumental variables regression model
with moment vector
where denote the residuals from the regression on the controls and the intercept of the variables log earnings, veteran status, and years of schooling, respectively, and is the vector of instruments such that .
We use the same data (the dataset is available on https://saraswata.research.mcgill.ca/MC_SC_Data.xlsx, accessed on 2 February 2025) as in Chaudhuri and Rose [16], which were obtained from the National Longitudinal Survey of Young Men. The sample includes 1080 (i.e., 39%) veterans and 1674 non-veterans. In this dataset, the instruments are weak for both veteran status and schooling with the first stage F statistic equal to 8.46 and 2.53, respectively.
Using these data, Chaudhuri and Rose [16] implemented a variety of plug-in methods, namely, the subset-K, subset-KJ and subset-CLR tests, and obtained a significant (at the 5% level) negative effect of the veteran status. However, these tests are not reliable in the presence of weak identification as shown by Guggenberger et al. [13] and Andrews [26].
The only genuinely weak-identification robust method used in Chaudhuri and Rose [16] is the so-called subset-Anderson–Rubin test proposed by Guggenberger et al. [13]. The subset-AR test lead to a 90% confidence interval for the coefficient of the veteran status whose upper bound is approximately 0.095, signifying that rather large positive effects of veteran status— increase in wage—cannot be ruled out. The lower bound of the subset-AR confidence interval asymptotes to , which is a consequence of weak identification. The inclusion of positive values in the confidence renders this test inconclusive.
The subset-AR test can be conservative when the effective number of over-identifying restrictions (the number of instruments minus the dimension of , in this case ) is larger than the number of restrictions in the null (in this case, 1) being tested. Therefore, a priori, there is reason to believe that the refined projection test, that is, the efficient test under strong identification but also robust to weak identification, might alter the conclusion of the subset-AR test.
Indeed, this is what we find with the refined projection test using EL implied probabilities . This confidence interval also includes implausibly large negative values (consequence of weak identification); however, its upper bound is less than zero, supporting the hypothesis that the veteran effect is negative.
For a visual illustration, Figure 1 presents two plots against various values of of —(i) the subset-AR statistic minus the , i.e., the tests statistic minus the 10% critical value for the subset-AR test, and (ii) the second step test statistic for the refined projection test minus the second step critical value, i.e., for the choice . We take the function plotted for (ii) as if the first-step confidence interval is empty (that automatically rejects without requiring the second step). The values for which these two plots are below the horizontal red dotted line at zero are those that are included in the confidence interval for the respective tests. The vertical black dotted line is the zero effect line. Inclusion of the blue or the green line in the south-east quadrant of the graph means the positive effect is not ruled out by the concerned test. We see that while the CI of the subset-AR test includes positive values, that of our refined test includes only negative values which permits to conclude that the veteran effect is negative.
6. Conclusions
In this paper, we propose a two-step approach for testing the subvectors of parameters in models characterized by a vector of moment restrictions. The first step is based on an identification robust confidence interval of the parameter, while the second relies on a score test. We show the advantages of using the implied probabilities obtained from the Information Theory criteria to estimate the Jacobian and variance matrix present in our score tests. These tests exploit efficiently the information content of the moment conditions. As a result, these tests have an empirical size close to the theoretical size and their power is good. The resulting confidence intervals are more reliable than those from alternative tests in the presence of skewness and/or weak identification. The theoretical properties of our tests are derived for all the elements of the Cressie–Read family, including the Kullback–Leibler Information Criterion. Finally, the empirical application brings evidence that veterans have lower earnings than comparable non-veterans.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Hall A. Generalized Method of Moments Advanced Texts in Econometrics Oxford University Press Oxford, UK 2005
- 2Staiger D. Stock J. Intrumal Variables Regression with Weak Instruments Econometrica 199765557586
- 3Antoine B. Renault E. Efficient GMM with Nearly-Weak Instruments Econom. J.200912 S 135S 171
- 4Andrews D. Cheng X. Estimation and Inference with Weak, Semi-Strong, and Strong Identification Econometrica 20128021532211
- 5Dufour J.M. Some Impossibility Theorems in Econometrics with Applications to Structural and Dynamic Models Econometrica 19976513651387
- 6Newey W.K. West K.D. Hypothesis Testing with Efficient Method of Moments Estimation Int. Econ. Rev.198728777787
- 7Wang J. Zivot E. Inference on Structural Parameters in Instrumental Variables Regression with Weak Instruments Econometrica 19986613891404
- 8Chaudhuri S. Renault E. Shrinkage of Variance for Minimum Distnce Based Tests Econom. Rev.201534328351