The Effect of Naturally Acquired Immunity on Mortality Predictors: A Focus on Individuals with New Coronavirus
Mónica Queipo, Jorge Mateo, Ana María Torres, Julia Barbado

TL;DR
This study uses machine learning to identify key predictors of mortality in hospitalized, unvaccinated patients with natural immunity to COVID-19.
Contribution
The study introduces a machine learning approach to assess mortality predictors in patients with natural immunity, not prior vaccination.
Findings
Variables like CURB-65, age, GCS, and comorbidities were top predictors of mortality at hospital admission.
Hospitalization-related variables like acute renal failure and APACHE-II showed significant predictive value.
The Random Forest model achieved over 95% precision in predicting mortality outcomes.
Abstract
Background/Objectives: The spread of the COVID-19 pandemic has spurred the development of advanced healthcare tools to effectively manage patient outcomes. This study aims to identify key predictors of mortality in hospitalized patients with some level of natural immunity, but not yet vaccinated, using machine learning techniques. Methods: A total of 363 patients with COVID-19 admitted to Río Hortega University Hospital in Spain between the second and fourth waves of the pandemic were included in this study. Key characteristics related to both the patient’s previous status and hospital stay were screened using the Random Forest (RF) machine learning technique. Results: Of the 19 variables identified as having the greatest influence on predicting mortality, the most powerful ones could be identified at the time of hospital admission. These included the assessment of severity in…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
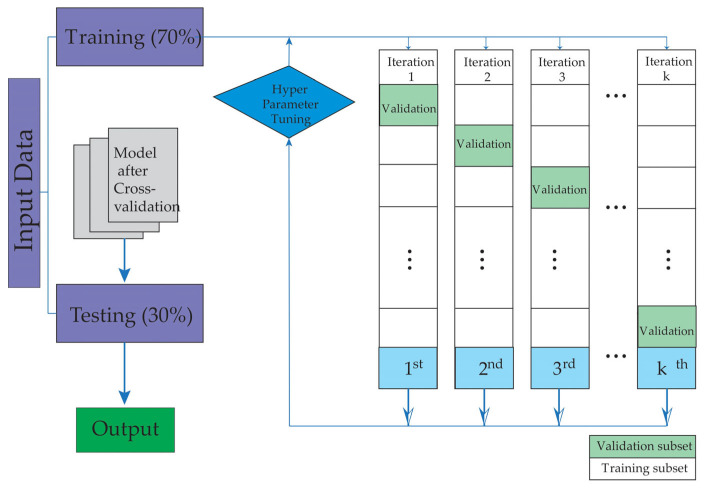 Figure 1
Figure 1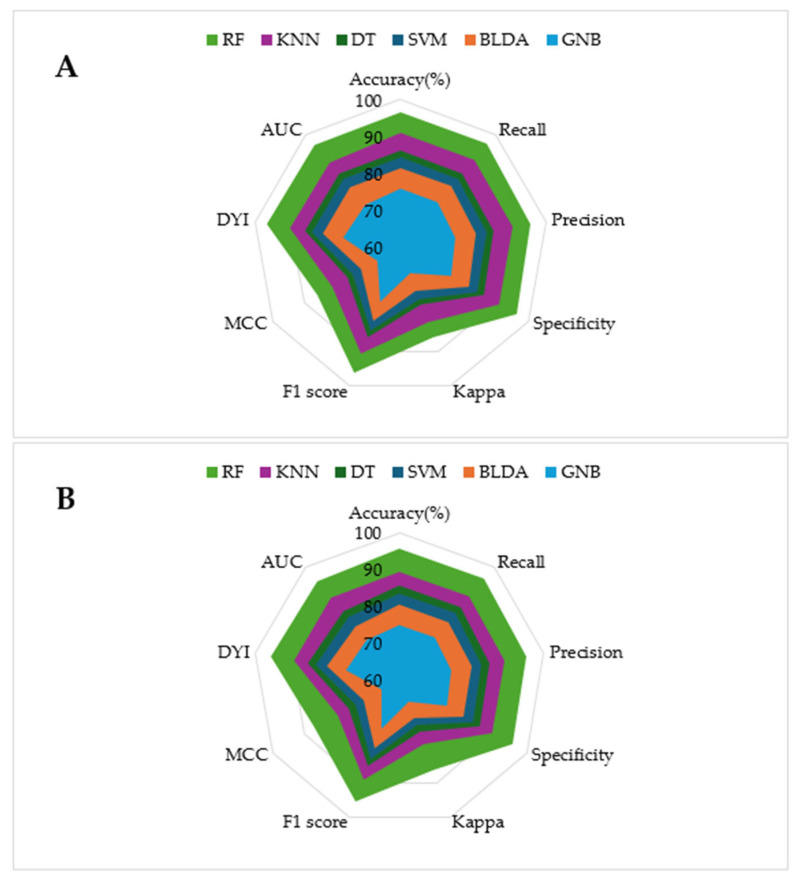 Figure 2
Figure 2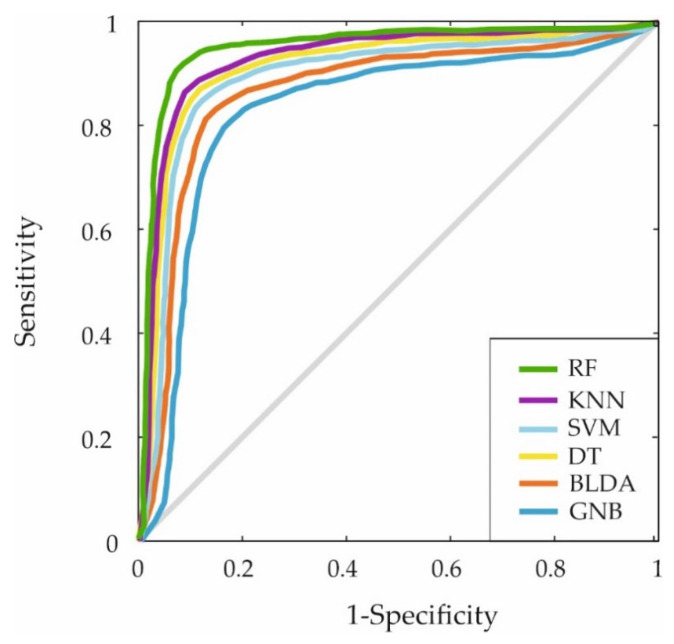 Figure 3
Figure 3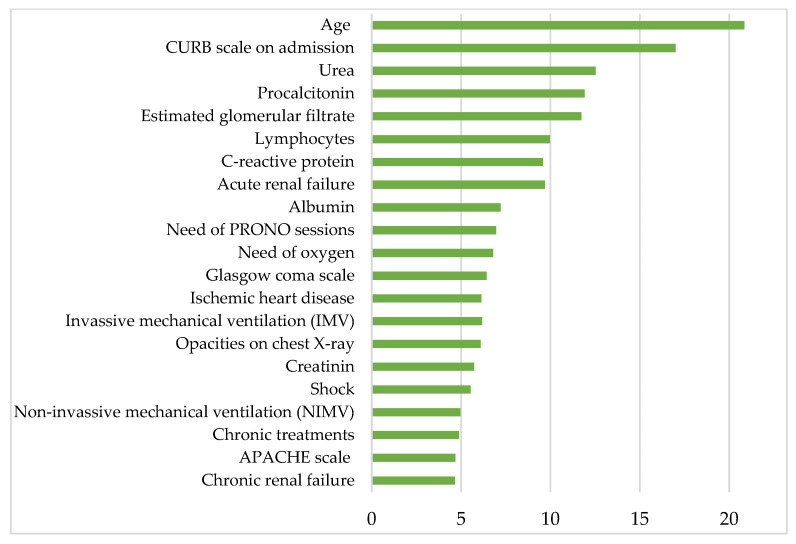 Figure 4
Figure 4- —Institute of Technology (University of Castilla-La Mancha, Spain)
- —Río Hortega University Hospital (Valladolid, Spain)
- —University of Valladolid
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCOVID-19 Clinical Research Studies · COVID-19 diagnosis using AI · SARS-CoV-2 and COVID-19 Research
1. Introduction
When a sufficient number of individuals are immunized against a pathogen, the probability of transmission between the infected and susceptible population decreases due to the interruption of the chain of transmission [1]. In the case of a contagious, direct contact-transferable pathogen that induces long-term immunity, this is maximized if the population has a random pattern of interaction [2]. Diseases such as rubella, measles or pertussis are under control, and others such as smallpox are even eradicated today thanks to herd immunity, either by natural means or through vaccination strategies [3].
Natural immunity, which develops after infection with COVID-19, and vaccine-induced immunity, achieved through controlled exposure to viral antigens, are key mechanisms for protection against the virus. While natural immunity depends on factors like the initial viral load and may be less predictable, vaccines offer more uniform protection and mitigate the risks associated with severe disease [4]. Moreover, recent studies suggest that the combination of both types of immunity can provide more robust and long-lasting protection [5].
This concept gained significant visibility during the coronavirus disease-2019 (COVID-19) pandemic, as the need to achieve herd immunity became a critical objective to minimize the clinical and societal impact of the health emergency. Early estimates indicated that 70% of the population would need immunization to achieve this goal [6]. Data from populations with full vaccination schedules suggest that this threshold was reached between the third and fourth waves of the pandemic (June–September 2021) in regions, such as Europe, Oceania, the Middle East, and North America, while Asia and Africa reached these rates later, between late 2021 and mid-2022 [7].
Well before vaccination campaigns began, however, a substantial percentage of the population had already acquired natural immunity. Studying the characteristics of individuals infected during this period—before vaccination but after the first wave—is of profound clinical interest. Understanding their natural immune responses, the variability in disease severity, treatment protocols, and virus epidemiology provides invaluable insights for managing future outbreaks or similar health crises.
Severe cases of COVID-19 are characterized by an inflammatory response and a cytokine storm that affects all cells of the immune system [8], especially lymphocytes. This has been shown to cause a dysregulation that can lead to an uncontrolled immune response, lung tissue damage or even multi-organ failure [9]. The initial symptoms of the disease, as reported at the onset of the pandemic, included fever, dyspnea, pneumonia and a dry cough [10,11,12]. Nevertheless, differences in clinical presentation across pandemic waves have been observed, such as reduced intensive care unit (ICU) admission rates [13] or decreased mortality [14,15]. It is evident that this progression can be attributed, firstly, to a heightened comprehension of the disease, facilitated by scientific research and the implementation of social policies. However, it is also associated with the modification of immunological characteristics at both the individual and population levels, owing to the progressive development of immunity, as a growing number of individuals recover from the infection and achieve immunological protection.
Comparing COVID-19 with earlier respiratory infections caused by coronaviruses, such as severe acute respiratory syndrome coronavirus (SARS-CoV) (2002–2003) and Middle Eastern respiratory syndrome coronavirus (MERS-CoV) (2012), offers additional perspective. Both SARS-CoV and MERS-CoV share similarities with SARS-CoV-2 in transmission routes [16] and clinical features, though with distinct differences in transmission rates and global impacts [17]. Lessons learned from studies on these viruses provide a framework for analyzing COVID-19 data and underscore the utility of advanced analytical techniques such as machine learning (ML).
In the context of data analysis from a limited sample of patients during a pandemic, advanced data analysis techniques are increasingly being used. Among artificial intelligence (AI) tools, machine learning (ML) has seen a surge in utilization in studies dealing with voluminous datasets. This branch of AI and computational analysis entails the employment of data and algorithms that emulate human information processing capabilities while enhancing efficiency [18]. Its efficacy has been demonstrated in several areas of knowledge, including biology [19] or medicine [20,21,22]. Furthermore, these machine learning tools have been extensively utilized in research related to the novel coronavirus, SARS-CoV-2, particularly in the study of mortality [23,24] and/or severity [25,26], the study of populations with specific characteristics (smokers [27], cancer patients [28,29], etc.) and biomarker analysis [30,31].
A notable benefit of leveraging ML models over conventional statistical tools is their capacity to generate precise predictions while exhibiting high levels of scalability and adaptability. This capability enables the identification of patterns within voluminous datasets. This is particularly relevant in the context of a public health problem that was not only unknown in its early stages but has shown a remarkable evolution over different time periods. Consequently, the objective of this study is to identify key predictors of mortality risk in a cohort of patients hospitalized for COVID-19 during a period when vaccines were not yet available but immunity obtained by natural means was present.
For this purpose, the specific ML model to be validated is the Random Forest (RF). This method might be utilized systematically as a risk evaluation tool in any population, enabling the derivation of conclusions in a relatively brief time frame with data from a limited number of patients (150–300). This approach would enable the development of customized protocols for diverse populations, such as health centers or cities, with the objective of optimizing resource utilization and ensuring a highly personalized healthcare experience.
2. Materials and Methods
2.1. Data Source and Description
The clinical data used in this study were taken from the electronic medical record system of the Río Hortega University Hospital in Valladolid (Spain). Data from 363 patients hospitalized with polymerase chain reaction (PCR)-confirmed COVID-19 infection between the beginning of the second wave (2 May 2020) and the end of the fourth wave (10 June 2021) were obtained from this platform. The information used in this study corresponds to the patients’ hospital stay from the time of admission to the emergency department until discharge from the hospital. Each patient was given an anonymous code to protect their privacy, and all patients gave informed consent. This study was conducted according to the principles of Helsinki and was approved by the Ethics Committee of the University Hospital of Rio Hortega.
Data were collected, retrospectively reviewed, and manually entered into a predesigned database. These data included demographics, comorbidities, chronic treatments, date of admission, date of discharge or death and cause, symptoms on admission, date of COVID-19 diagnosis and virus variant, if available, chest X-ray on admission, community acquired pneumonia severity scales (CURB-65), sequential organ failure assessment (SOFA), acute physiology and chronic health disease classification system (APACHE-II), Glasgow Coma Scale (GCS), vital signs, laboratory data, need for intensive care unit (ICU) admission and date (if applicable), need and type of ventilatory support, co-infections, nosocomial infections (specimen typing), complications during hospitalization, previous COVID-19 episodes, COVID-19 specific treatment, and number and type of COVID-19 vaccines received.
The laboratory tests whose results were used in this study were performed at the same hospital center using the following instruments: DXH900 Beckman Coulter Diagnosis (Brea, CA, USA) for whole blood samples, AU5820 Beckman Coulter Diagnosis for serum biochemistry samples and Gem5000 Werfen (Barcelona, Spain) for blood gasometry analysis. The data were entered into the aforementioned hospital electronic data storage system prior to their use in this study. The laboratory parameters considered relevant to this study were the following: leukocytes, neutrophils, lymphocytes, monocytes, eosinophils, basophils, erythrocytes, hemoglobin, hematocrit, mean corpuscular volume (M.C.V.), platelets, D-dimer, prothrombin activity (PT), international normalized ratio (I.N.R.), activated partial thromboplastin time (aPTT), aPTT ratio, derived fibrinogen, sodium, potassium, chloride, glucose, urea, creatinine, estimated glomerular filtration rate (CKD-EPI 2009), alanine aminotransferase (ALT/GPT), aspartate aminotransferase (AST/GOT), gamma glutamyl transferase (GGT), total bilirubin, alkaline phosphatase, lactate dehydrogenase (LDH), phosphate, C-reactive protein, procalcitonin, albumin, pH, pCO_2_, pO_2_, HCO_3_, FIO_2_, pO_2_/FIO_2_, O_2_ gradient Aa and lactate.
These variables were selected after a thorough literature review to identify the most critical factors during the pandemic. The focus was on those that could significantly aid in evaluating disease severity, immune response, and associated risk factors. Additionally, the chosen parameters were those that could be quickly and routinely measured both at the time of hospital admission and throughout the patient’s stay in the hospital.
2.2. Machine Learning Methods
In this study, the Random Forest algorithm was developed, an ensemble method that employs the bagging aggregation approach to construct multiple decision trees independently, thereby reducing variance and enhancing the robustness of the model. Random Forest is based on bootstrap sampling of the training data to build a set of independent trees, where each tree is trained on a random sample of the original dataset. Furthermore, at each tree node, a random subset of features is selected instead of considering all variables, introducing an additional source of randomness and minimizing correlation between the trees, thereby increasing the accuracy of the ensemble [32,33].
During the training process, each tree makes decisions independently, and the results are combined using a majority voting scheme for classification. Feature importance is calculated by analyzing the decrease in accuracy or Gini index when the values of a feature are randomly permuted, thereby identifying the most relevant variables for the model. Finally, the model’s performance was evaluated using specific metrics such as accuracy, sensitivity, specificity, and the area under the receiver operating characteristic (ROC) curve (AUC), enabling validation of its predictive capability and generalization to unseen data.
In the proposed Random Forest algorithm, a set of decision trees {T1, T2, …, Tm} is constructed using a bagging aggregation approach. To build each tree T_i_, the following steps were performed:
Bootstrap sampling: Given a training dataset with n observations and p features, a subset of data Di is generated by selecting n random samples with replacement from the original dataset. This sampling technique allows certain data points to appear multiple times in Di, while others may not appear at all.
Random feature selection: At each node of every tree, instead of evaluating all p features, a random subset of k features is selected, where . This reduces the correlation between individual trees, thereby increasing the model’s generalization ability.
Splitting criterion at each node: Each node is split according to an impurity reduction criterion, which can be either entropy or the Gini index for classification. In our study, we use the Gini index. The Gini impurity G of a node with a proportion pk of elements belonging to class k is defined as:
Combination of trees: Once the trees are trained, the prediction of the Random Forest is obtained through aggregation. For a set of trees {T1, T2, …, Tm}, the final prediction is calculated using majority voting:
Feature importance: The importance of each feature was measured by evaluating the change in the splitting criterion when the feature was randomly permuted in the dataset. For importance based on the Gini index, if permuting a specific feature increased the impurity of the tree nodes, that feature was considered important.
Model optimization and tuning: In order to improve the predictive performance of the Random Forest model and avoid overfitting, hyperparameter tuning was performed using a Bayesian optimization strategy. This approach was preferred over grid search due to its efficiency in navigating large parameter spaces with fewer evaluations. The optimization was carried out with a fivefold cross-validation strategy applied to the training data. The hyperparameters included the number of trees in the forest (n_estimators), the maximum depth of the trees (max_depth), the minimum number of samples required to split an internal node (min_samples_split), and the number of features considered at each split (max_features). The optimization objective was to maximize the average cross-validated AUC. This procedure allowed us to determine an optimal configuration that balances model complexity and generalization capacity, minimizing the risk of overfitting.
Model evaluation: The model’s performance was evaluated using metrics, such as accuracy, sensitivity, specificity, and the AUC.
In this study, the proposed method underwent extensive evaluation, comparing it with various machine learning techniques for classifying COVID-19 patients. The algorithms included in the comparative analysis were Gaussian Naive Bayes (GNB) [34,35], k-Nearest Neighbors (KNNs) [36,37], Bayesian Linear Discriminant Analysis (BLDA) [38,39], Support Vector Machines (SVM) [40], decision trees (DT) [41,42], and the novel system developed in this study, Random Forest (RF) [32,43,44]. The implementation and evaluation of the models were conducted using MATLAB’s Statistics and Machine Learning Toolbox (version 2024a).
To mitigate overfitting, a fivefold cross-validation strategy was applied. The data were split into two subsets, assigning 70% for training and 30% for testing, ensuring the independence of patient groups in each set. Figure 1 schematically illustrates the study workflow, which begins with patient selection and database creation, followed by the training and validation phases of the machine learning models.
3. Results
A total cohort of 363 patients was studied, corresponding to the second (135 patients), third (115 patients) and fourth (113 patients) waves of the pandemic, when mass vaccination campaigns had not yet begun. The study identified 40 deceased patients, resulting in an overall mortality rate of 11%.
The medical treatments and protocols used during the second to fourth waves of COVID-19 were stable during this period and followed hospital, local health and ministry of health protocols, based on WHO indications.
The information obtained is related to the patient’s previous condition, the time of admission, and also the evolution of the patient during the hospital stay. More detailed data on demographics, comorbidities, chronic treatments, symptoms on admission, ICU stay, need for ventilatory support or complications during hospital stay, among others, are shown in Table 1, Table 2, Table 3 and Table 4.
Several ML methods were used to identify risk patterns in a population with confirmed COVID-19 infection. The goal was to determine which algorithm provided the best predictive results. This study presents performance metrics for these ML methods, including balanced accuracy, recall, specificity, precision, Mathew’s correlation coefficient (MCC), F1 score, kappa, AUC, and degenerated Youden’s index (DYI), as shown in Table 5 and Table 6.
The data clearly indicate that the proposed method, RF, is the one with the highest acquisition and recall value. The RF algorithm consistently provides a positive predictive value of greater than 95%, demonstrating consistent performance.
The model training subset and the test subset both present high scores for all the metrics, with slightly lower scores for the test subset. This consistency is attributed to the algorithm reaching an optimal level of training without overfitting or underfitting. As shown in the radar plots in Figure 2, the RF model covers a larger area compared to the other methods tested, which is an example of a well-balanced model with high generalization capability, ensuring accurate outputs for new inputs.
Furthermore, the ROC curve was generated by plotting the sensitivity and specificity measures for each threshold to evaluate the classification capabilities of the different ML algorithms. The results are displayed in Figure 3. Again, the proposed RF-based system covers a larger area, indicating superior predictive accuracy.
Figure 4 shows the most clinically relevant parameters contributing to mortality in patients hospitalized for COVID-19 after the first wave and before mass vaccination, according to the proposed RF model. Listed in descending order of relevance, the aforementioned parameters are age, CURB-65 scale on admission, urea, procalcitonin, estimated glomerular filtrate, lymphocytes, C-reactive protein, acute renal failure, albumin, PRONO sessions, oxygen requirements, Glasgow Coma Scale, ischemic heart disease, invasive mechanical ventilation (IMV), creatinine, shock, noninvasive mechanical ventilation (NIMV), APACHE-II scale and chronic renal failure.
4. Discussion
Despite significant progress in the fight against COVID-19 and the time we have been coexisting with the virus after the global emergency, the pandemic remains a global concern. The emergence of new variants and the increase in cases during certain periods underscore the need to continue to research and improve our response strategies. In addition, the pandemic has highlighted weaknesses in health systems and the importance of researching more effective interventions and protocols to provide higher-quality care.
In this study, the analysis of the most relevant parameters for predicting the risk of mortality in hospitalized COVID-19 patients is organized into different categories for clarity and understanding. These categories include demographic factors, clinical features observed on admission, laboratory parameters, and variables monitored during hospitalization. This categorization highlights the complementary roles these parameters play in predicting mortality and enhances the study’s contribution to clinical decision making.
The most relevant parameters for predicting the risk of mortality in this group of hospitalized patients with COVID-19 during the period from the second to the fourth wave of the pandemic were identified. At that time, there was some immunity following infections in previous waves, and the population had not yet been vaccinated with more than one dose or had not yet been vaccinated at all. Among the key variables identified, the most powerful parameters were those that could be obtained at the time of hospital admission, either previous comorbidities or the clinical features assessed in the emergency department.
Thus, the strongest predictor among demographic factors is age, a conclusion common to many studies [45,46]. It should be emphasized that, although the majority of the patients in this cohort were older adults, this does not diminish the importance of age as a predictive factor. Rather than merely reflecting the higher mortality commonly associated with older populations, age itself plays a crucial role in the progression and outcome of COVID-19. This is supported by extensive evidence in the medical literature highlighting the physiological and immunological changes associated with aging that increase susceptibility to severe disease. To ensure the robustness of the analysis, statistical techniques were employed, including multivariate models, to isolate the independent contribution of age and confirm its predictive power while accounting for the influence of other clinical and pathologic parameters.
Similar trends were observed in SARS-CoV and MERS, where older age was also a significant risk factor for mortality, although the overall case fatality rates differed markedly, SARS-CoV at ~10% and MERS-COV at ~35%, compared to COVID-19′s lower fatality rate but higher transmissibility [47]. However, Philipps and Carver [48] concluded that it is not so much the age itself but what comes with advanced age that is a risk factor for mortality, namely comorbidities, chronic treatments and social situation. The results of this study support their theory, in that some of the factors that emerge as strong predictors of mortality are related to chronic diseases, such as ischemic heart disease and chronic renal failure.
The CURB-65 scale, a hallmark in the results, includes age as a variable. This scale has been evaluated in other studies as an adequate predictor of mortality in patients prior to hospitalization with COVID-19 pneumonia [49,50,51], and it is also commonly used to determine the severity in patients with any type of pneumonia. In addition to demographic factors, clinical features such as those included in the CURB-65 scale, such as urea levels or low level of consciousness, have considerable predictive power for mortality. In this study, the CURB-65 scale is a good parameter, and since it can be determined at the time of admission, this information can be used to perform rapid and efficient triage. Furthermore, a comparison with other viruses reveals that this scale, which focuses on clinical severity, has also been used to effectively manage pneumonia-like symptoms [52,53].
Laboratory parameters obtained at the time of hospitalization, such as urea levels, C-reactive protein, procalcitonin, albumin and/or lymphocyte count, are also good predictors of mortality according to the model used. Mohammadi et al. studied more than 1000 patients and concluded that elevated creatinine and urea levels were associated with poor prognosis in patients with COVID-19 [54]. Other studies, such as those of Al-Shajlawi et al. [55] or Singh and Singh [56], also include elevated C-reactive protein and procalcitonin levels, low albumin levels and low lymphocyte count as good predictors of mortality. Elevated urea levels, together with low lymphocyte levels, may be related to a severe systemic inflammatory response and consequent inflammation. C-reactive protein and procalcitonin are known markers of inflammation and sepsis, and their elevation reflects the severity of the inflammatory response. On the other hand, albumin, a protein produced by the liver, is normally decreased in states of chronic inflammation and physiological stress due to its role in the acute-phase response. A low lymphocyte count, or lymphopenia, may indicate immune dysfunction, which is common in severe viral infections such as COVID-19. All of these data would be consistent with a state of advanced inflammation and organ damage, explaining the association with an increased risk of mortality.
Moreover, this study shows that certain in-hospital monitoring variables, including acute renal failure and shock, have predicting significance. These belong to the category of monitoring parameters, which track the disease progression during hospitalization and provide critical insights into mortality risk. The study by Yüksel et al. [57] associates the aforementioned imbalances in laboratory parameters with the development of acute renal failure. At the same time, studies such as that by Qureshi et al. [58] have shown that non-surviving patients have a higher incidence of septic shock, among other pathologies. This underscores the importance of continuous monitoring and early intervention in COVID-19 patients with these alterations.
Additional monitored variables, such as the need for oxygen therapy, prone positioning sessions (PRONO), or mechanical ventilation, have also shown predictive significance for mortality risk as the disease progresses. Studies show they hold predictive significance for mortality risk as the disease progresses during ICU stay [59]. In turn, the APACHE-II scale has been shown to be a good predictor of mortality in some studies, although there are contradictions in this regard [59,60,61,62]. These include physiologic and biochemical parameters assessed on admission to the ICU that reflect the systemic response to severe physiologic stress common in severe cases of COVID-19. The higher relevance of APACHE-II in our study may be related to its ability to better capture multiorgan dysfunction in the early stages, providing a more robust prediction of mortality.
The data management approach used in this study involved an RF machine learning model, which was based on either bootstrap aggregation or bagging. This model has exhibited several advantageous characteristics, including high generalizability, stability and interpretability, along with a low risk of overfitting. Other studies have used the same method to analyze diseases, such as cardiovascular disease [63], interstitial lung disease [64], breast [65] or pancreatic cancer [66], autoimmune diseases [63] or neurological diseases [67] or neurodegenerative diseases [68]. The model can, therefore, be used as a strategic tool to quickly address clinical questions with relatively little data.
The application of the aforementioned model in the analysis of the variables with the most significant influence on the prediction of mortality in the cohort of hospitalized patients with COVID-19 during the second and third waves reveals a discrepancy in the results compared to those of analogous studies conducted in the first wave [11,12,13,69,70,71]. In these studies, patients had not yet developed any form of immunity. In contrast, the present study demonstrates that once a population achieves a certain level of immunity, additional predictive variables can be obtained at the time of admission. Furthermore, during the patient’s hospital stay, variables related to the stay itself were identified, and these variables can be used in decision making.
5. Conclusions
After the first wave of the recent COVID-19 pandemic, the size of the population that has overcome the infection and developed natural immunity is increasing. Therefore, it is crucial to study how natural immunity affects the evolution of the disease in order to improve general knowledge about it and improve preparedness for potential new health challenges.
The present study demonstrates that predictive variables for mortality risk, and, therefore, severity, can be identified in a given population at the time of hospital admission using an RF machine learning model. In this cohort, the CURB-65 scale and age were the strongest predictors of mortality, along with other laboratory tests. These results underscore the need to emphasize not only the early patient assessment but also the personalized analysis of the population and situation, given their capacity for change.
The present study shows that the increase in the number of immunized patients, even in the absence of herd immunity, generates a significant modification in the evolution of the disease, as well as the mortality risk parameters. This underscores the necessity for a more customized approach to patient care, employing distinct protocols tailored to specific groups and temporal periods. In this regard, the employment of machine learning tools emerges as a highly valuable and efficient resource.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Suryawanshi Y.N. Biswas D.A. Herd Immunity to Fight Against COVID-19: A Narrative Review Cureus 20231510.7759/cureus.33575 PMC 990912636779140 · doi ↗ · pubmed ↗
- 2Clemente-Suárez V.J. Hormeño-Holgado A. Jiménez M. Benitez-Agudelo J.C. Navarro-Jiménez E. Perez-Palencia N. Maestre-Serrano R. Laborde-Cárdenas C.C. Tornero-Aguilera J.F. Dynamics of Population Immunity Due to the Herd Effect in the COVID-19 Pandemic Vaccines 2020823610.3390/vaccines 802023632438622 PMC 7349986 · doi ↗ · pubmed ↗
- 3Fine P. Eames K. Heymann D.L. “Herd Immunity”: A Rough Guide Clin. Infect. Dis.20115291191610.1093/cid/cir 00721427399 · doi ↗ · pubmed ↗
- 4Hussain A. Yang H. Zhang M. Liu Q. Alotaibi G. Irfan M. He H. Chang J. Liang X.-J. Weng Y. m RNA Vaccines for COVID-19 and Diverse Diseases J. Control. Release 202234531433310.1016/j.jconrel.2022.03.03235331783 PMC 8935967 · doi ↗ · pubmed ↗
- 5Zhang M. Hussain A. Yang H. Zhang J. Liang X.-J. Huang Y. m RNA-Based Modalities for Infectious Disease Management Nano Res.20231667269110.1007/s 12274-022-4627-535818566 PMC 9258466 · doi ↗ · pubmed ↗
- 6Omer S.B. Yildirim I. Forman H.P. Herd Immunity and Implications for SARS-Co V-2 Control JAMA 2020324209510.1001/jama.2020.2089233074293 · doi ↗ · pubmed ↗
- 7Mathieu E. Ritchie H. Rodés-Guirao L. Appel C. Gavrilov D. Giattino C. Hasell J. Macdonald B. Dattani S. Beltekian D. Total COVID-19 Vaccine Doses Administered COVID-19 Pandemic Data Adapted from Official Data Collated by Our World in Data World Health Organization Geneva, Switzerland 2020
- 8Ruan Q. Yang K. Wang W. Jiang L. Song J. Clinical Predictors of Mortality Due to COVID-19 Based on an Analysis of Data of 150 Patients from Wuhan, China Intensive Care Med.20204684684810.1007/s 00134-020-05991-x 32125452 PMC 7080116 · doi ↗ · pubmed ↗