IA-DTPSO: A Multi-Strategy Integrated Particle Swarm Optimization for Predicting the Total Urban Water Resources in China
Zheyu Zhu, Jiawei Wang, Kanhua Yu

TL;DR
This paper introduces IA-DTPSO, a new particle swarm optimization algorithm that improves efficiency and accuracy in predicting China's urban water resources.
Contribution
The novel IA-DTPSO algorithm integrates multiple strategies to enhance PSO performance and is applied for the first time to urban water resource prediction.
Findings
IA-DTPSO outperforms other algorithms on 58.33% of CEC2022 functions in 10 dimensions and 41.67% in 20 dimensions.
The optimized TDGM model using IA-DTPSO achieves the smallest error (MAPE 5.9439%) in predicting China's urban water resources.
Abstract
In order to overcome the drawbacks of low search efficiency and susceptibility to local optimal traps in PSO, this study proposes a multi-strategy particle swarm optimization (PSO) with information acquisition, referred to as IA-DTPSO. Firstly, Sobol sequence initialization on particles to achieve a more uniform initial population distribution is performed. Secondly, an update scheme based on information acquisition is established, which adopts different information processing methods according to the evaluation status of particles at different stages to improve the accuracy of information shared between particles. Then, the Spearman’s correlation coefficient (SCC) is introduced to determine the dimensions that require reverse solution position updates, and the tangent flight strategy is used to improve the inherent single update method of PSO. Finally, a dimension learning strategy is…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
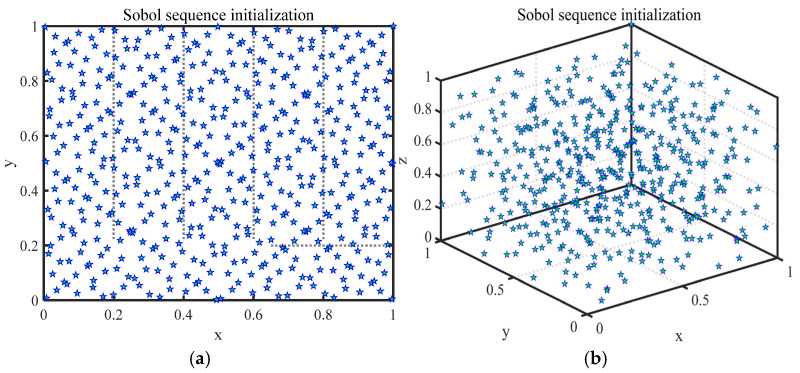 Figure 1
Figure 1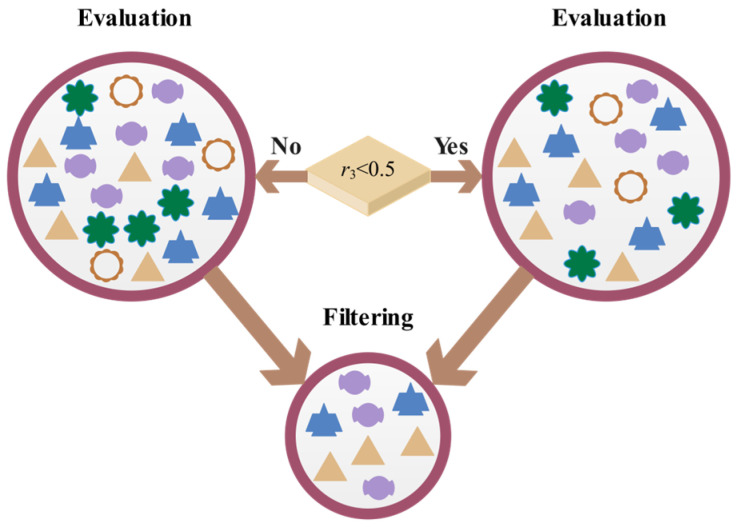 Figure 2
Figure 2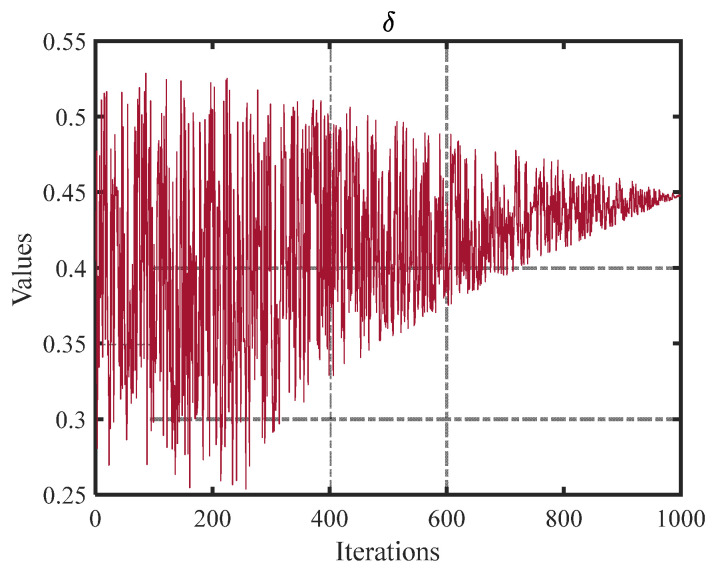 Figure 3
Figure 3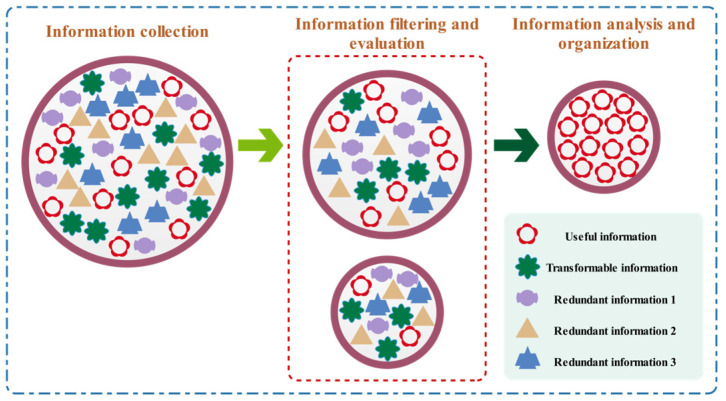 Figure 4
Figure 4 Figure 5
Figure 5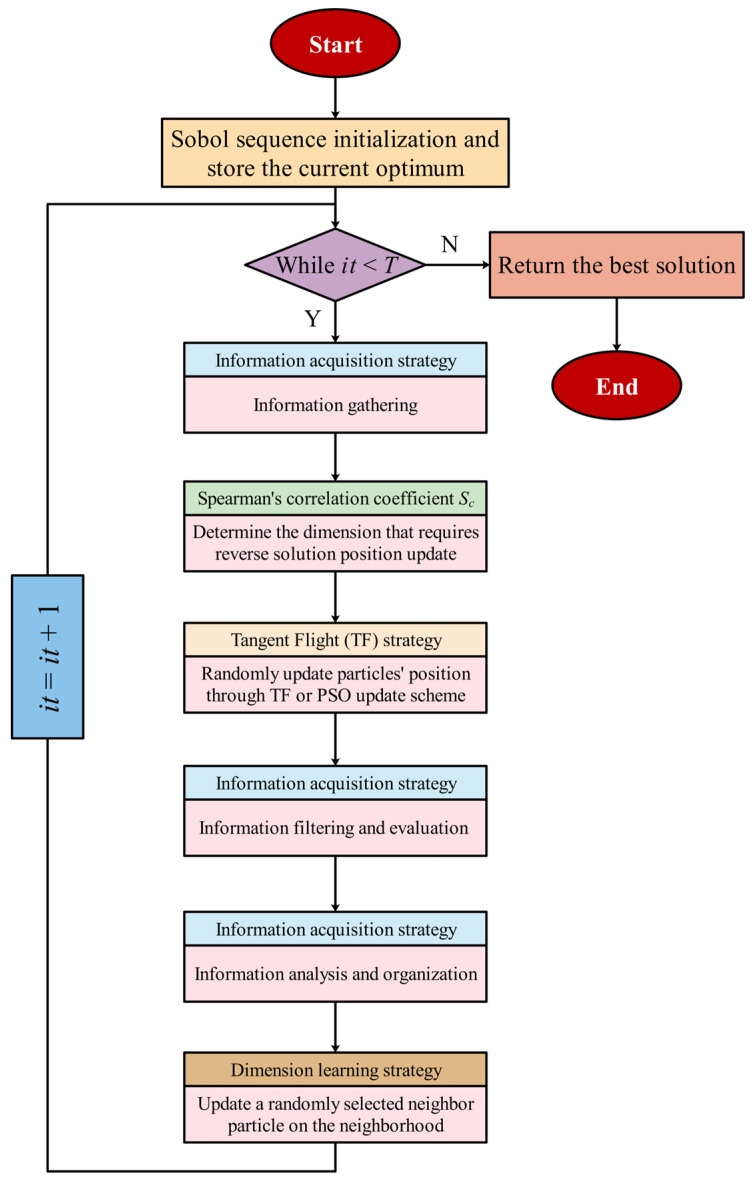 Figure 6
Figure 6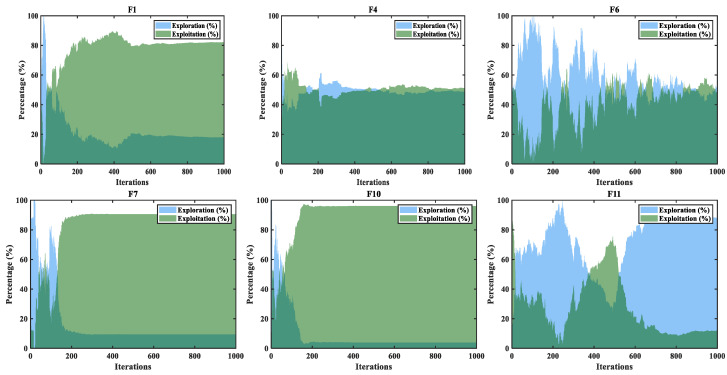 Figure 7
Figure 7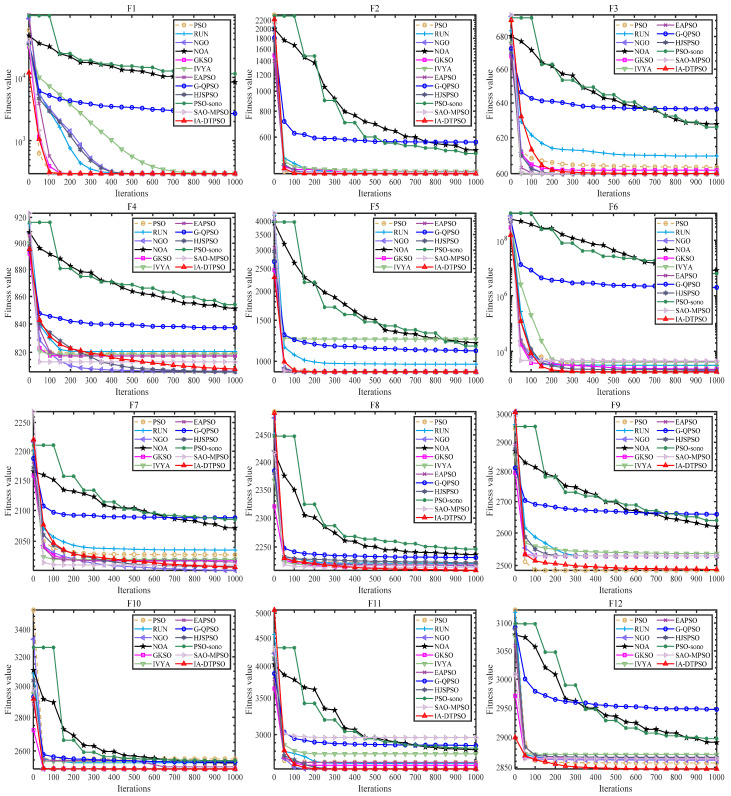 Figure 8
Figure 8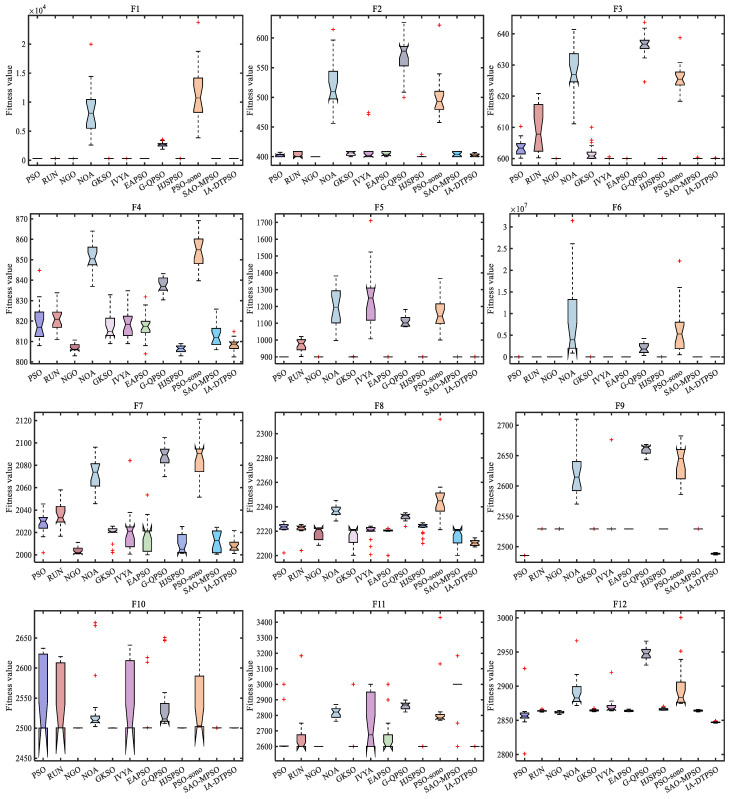 Figure 9
Figure 9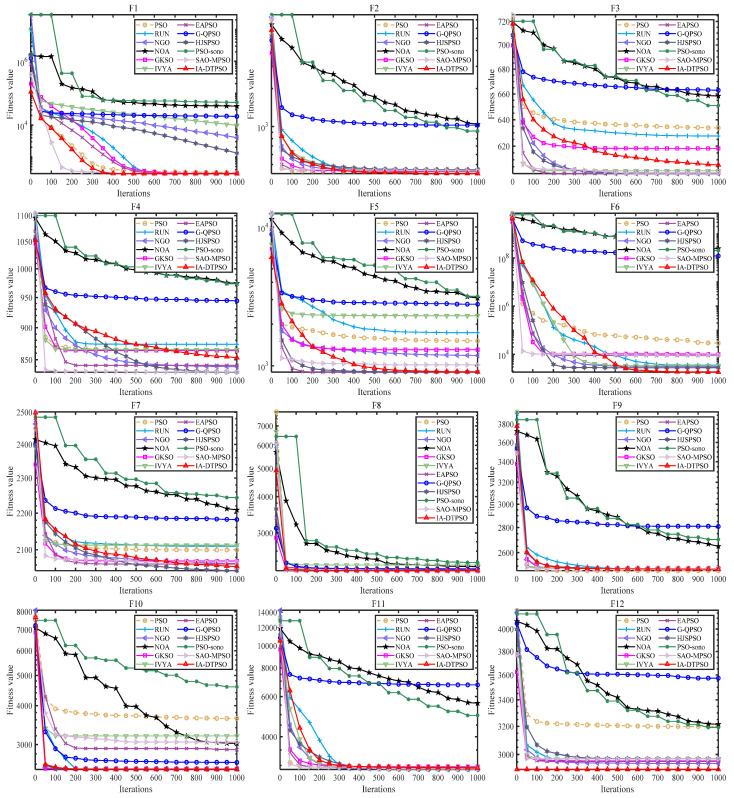 Figure 10
Figure 10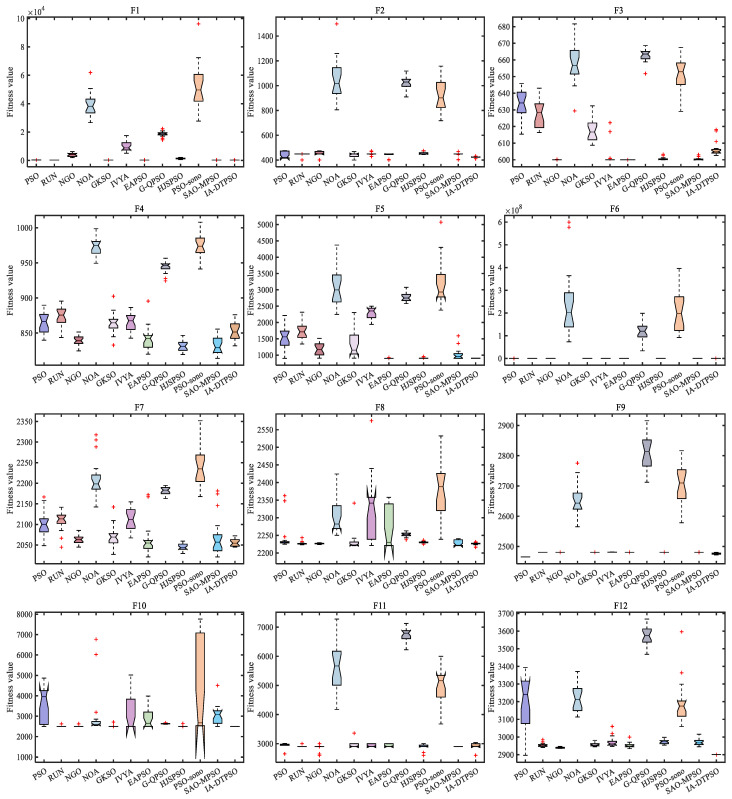 Figure 11
Figure 11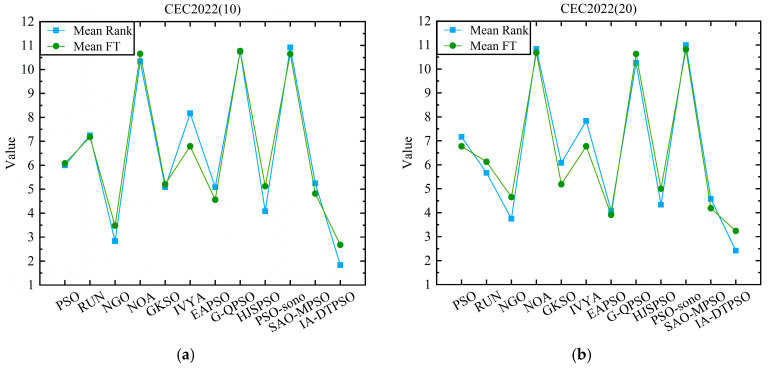 Figure 12
Figure 12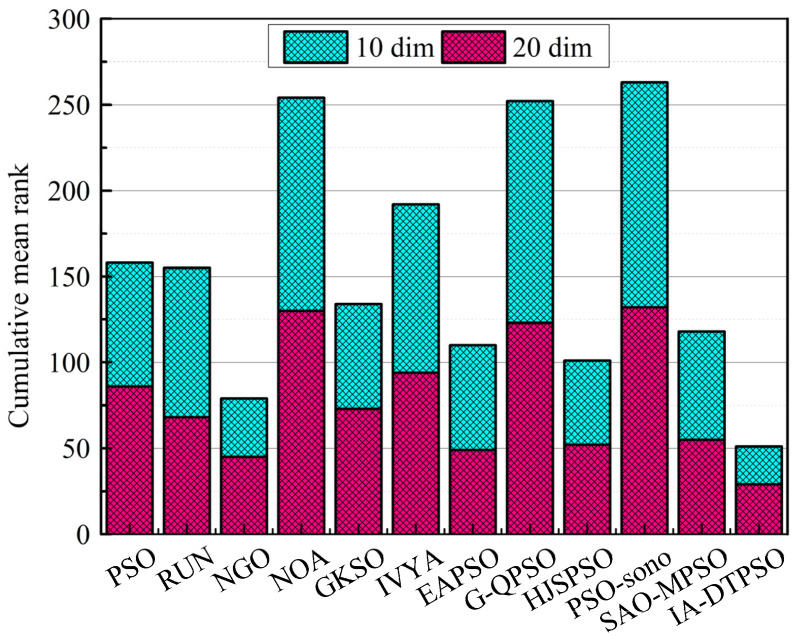 Figure 13
Figure 13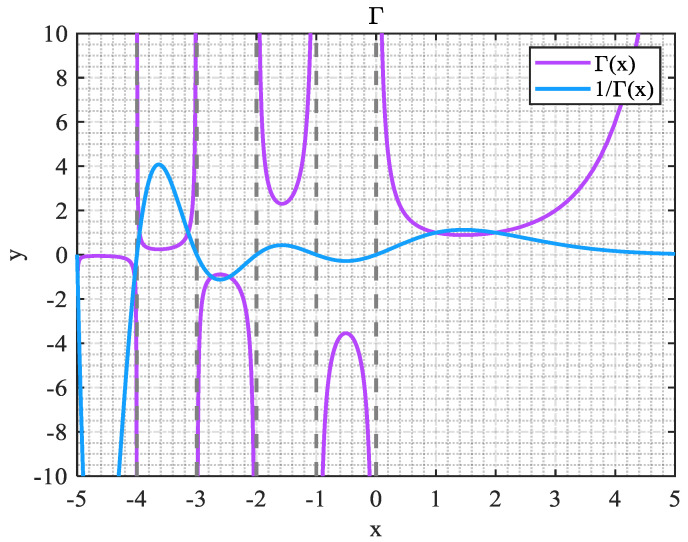 Figure 14
Figure 14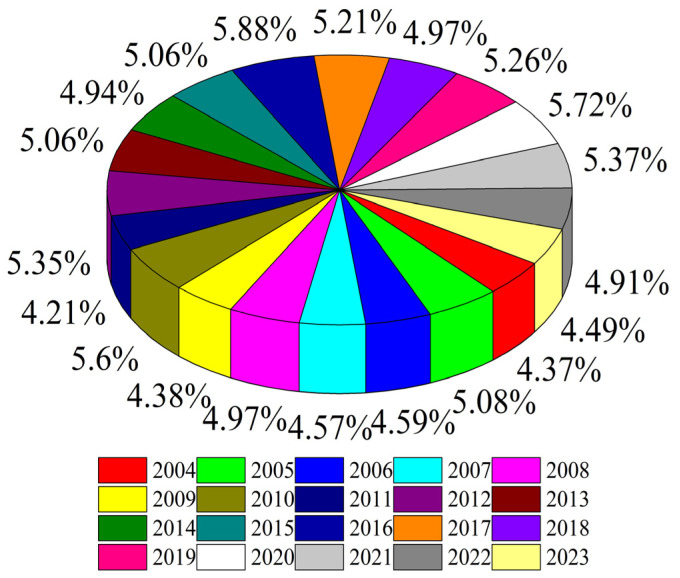 Figure 15
Figure 15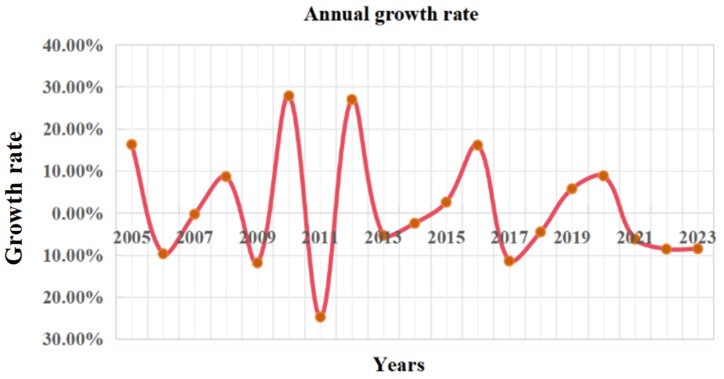 Figure 16
Figure 16- —The National Natural Science Foundation of China
- —Key Research Projects of the Shaanxi Provincial Government Research Office
- —2024 Shaanxi Provincial Communist Youth League and Youth Work Research Project
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsWater resources management and optimization · Water Resources and Sustainability · Water Quality and Pollution Assessment
1. Introduction
Optimization is the procedure of determining the most efficient solution for practical problems. For an optimization problem, it is necessary to first clarify the three basic elements of the problem: the number of decision variables, the optimization range of variables, and the objective function. At present, optimization techniques have been employed in various domains such as business, engineering, science, and medicine [1,2,3,4]. However, classical numerical methods struggle to offer accurate solutions for non-convex problems with non-linear constraints, leading to extended computation time [5]. Meta-heuristics are key tools for developing efficient optimizers that can effectively solve challenging real-world problems [6,7]. Metaheuristic algorithms (MAs) can traverse the solution space with effect in indeterminate environments to recognize global optima or find an approximate optimum [8]. This means that although MAs cannot guarantee an accurate solution, they can definitely generate an optimal solution [9]. MAs have high scalability and can be directly designed and implemented and can surmount challenges related to the enormous sophistication of mathematical inference [10,11]. Therefore, when traditional optimization techniques cannot handle exact solutions, MAs become an alternative method for quickly solving large-scale optimization problems [12]. MAs’ main features can be generalized as below:
- It is an approximate method that is not specific to a particular problem.
- It is a process of continuously learning towards the optimal solution through trial and error.
- Demonstrates significant multi-functionality and robustness.
- It is an optimization logic used to determine approximate solutions to complex global optimization problems.
All population-based MAs possess these characteristics, with differences only in the use of operators and mechanisms. In addition, MAs also include two essential search tactics, namely ENE [13,14]. Exploration is the ability to search the solution space on a global scale, which is associated with averting local optimality and solving traps in local optimality. Exploitation is about making optimal decisions from promising solutions in the vicinity to increase MAs’ local quality [15]. Therefore, the key to whether a MA has excellent performance depends on whether an appropriate balance can be achieved between these two strategies. This typically involves how to use search operators to effectively extract and utilize information, thereby generating more promising solutions to problems [16].
Thirty years ago, MAs represented by PSO [17] gained widespread recognition in the research community, and more and more MAs rapidly emerged under its influence. So far, thousands of MAs have been made public. According to different sources of inspiration, MAs can be broadly divided into four categories: swarm-behavior inspired, human-behavior inspired, evolution-phenomena inspired, and nature-science-phenomena inspired.
- (i)Swarm-behavior inspired: Swarm-behavior-inspired algorithms are techniques that mimic collaborative behavior in biological social systems to solve problems. They organize a large number of simple individual units (such as ants, bees, bird swarm agents) together, allowing them to interact and learn in complex environments, and jointly search for optimal solutions. In recent years, newly proposed population-based algorithms include: Whale Optimization Algorithm (WOA) [18], Northern Goshawk Optimization (NGO) [19], Bottlenose Dolphin Optimizer (BDO) [20], Nutcracker Optimization Algorithm (NOA) [21], Mantis Search Algorithm (MSA) [22], Genghis Khan Shark Optimizer (GKSO) [23], Black-winged kite algorithm (BKA) [24], Secretary Bird Optimization Algorithm (SBOA) [25], and Horned Lizard Optimization Algorithm (HLOA) [26].
- (ii)Human-behavior inspired: Human-behavior-inspired algorithms typically draw inspiration from human creativity, artistic thinking, and problem-solving approaches, simulating the process of humans making a series of decisions through team collaboration. In recent years, this type of algorithm includes: Enterprise Development Optimizer (EDO) [27], Hiking Optimization Algorithm (HOA) [28], Great Wall Construction Algorithm (GWCA) [29], Football Team Training Algorithm (FTTA) [30], Alpine Skiing Optimization (ASO) [31], Information Acquisition Optimizer (IAO) [32], Adolescent Identity Search Algorithm (AISA) [33], and Information Decision Search Algorithm (IDSE) [34].
- (iii)Evolution-phenomena inspired: Evolution-phenomena-inspired algorithms are mainly a type of computational technology that draw inspiration from biological evolution theory. These mainly include Genetic Algorithm (GA) [35], Genetic Programming (GP) [36], Evolutionary Programming (EP) [37], Evolutionary Strategy (ES) [38], Differential Evolution (DE) algorithm [39], Biogeography-based optimization (BBO) [40], Clonal Selection Algorithm (CSA) [41], and Alpha Evolution (AE) [42].
- (iv)Nature-science-phenomena inspired: Nature-science-phenomena-inspired algorithms based on natural science phenomena mainly come from observations of natural phenomena and scientific laws in various fields. The latest achievements in this research direction mainly include: Tangent Search Algorithm (TSA) [43], Kepler Optimization Algorithm (KOA) [44], Exponential- Trigonometric Optimization (ETO) algorithm [45], Artemisinin Optimization (AO) algorithm [46], Weighted Average Algorithm (WAA) [5], Newton-Raphson-based Optimizer (NRBO) [47], Polar Lights Optimization (PLO) [48], and FATA morgana algorithm (FATA) [49].
In addition to these classic MAs, many improved versions of MAs have emerged in this field and been applied in various practical applications. Yan et al. [50] developed an enhanced human memory optimizer to solve engineering optimization problems. Hu et al. [51] studied a multi-strategy DE algorithm for the smooth path planning of multi-scale robots and obtained a motion path with higher smoothness. Gobashy et al. [7] used WOA to solve the problem of spontaneous potential energy anomalies caused by 2D tilted plates of infinite horizontal length. Li et al. [52] proposed an improved seagull optimizer for fault location in distribution networks. Jamal et al. [53] proposed an improved Pelican optimization algorithm to solve non-convex stochastic optimal power flow problems in power systems, thereby reducing generation costs and emissions.
Although the successive emergence of various new MAs has added great vitality to the field of intelligent optimization, existing MAs still have several limitations, which can be generalized as below:
- Difficulty in achieving the optimal balance of ENE, resulting in MAs to local optimum.
- Multiple operators are typically used to approximate the optimum, complicating the search scenario.
- Performance degradation in high-dimensional search space.
As one of the classic MAs, PSO has hundreds or thousands of improved versions, but it is difficult to select the best from these improved versions due to the No Free Lunch (NFL) theorem that all MAs have to rely on [54]. This theorem emphasizes that no MA can be universally applicable to all types of problems. That is to say, different MAs may perform better for specific types of problems but may not be as effective for other types of problems. Furthermore, search operators’ basis vectors in PSO typically determine the starting point of the search and are sampled straightforwardly from the solution set instead of being adaptively selected. In addition, particles overly rely on obtaining information from two historical best positions while lacking the capacity to gain more information from other particles. Finally, PSO still exposes the imbalance of ENE. In response to the shortcomings of PSO mentioned above and combined with the NFL theorem, this study proposes a multi-strategy improved PSO (IA-DTPSO), which is based on the information acquisition strategy and involves four other improvement strategies for targeted auxiliary improvement. Compared with a large number of existing PSO variants, this method has a more novel structure and refined update method.
In recent years, combining MAs with predictive models has become a hot topic. However, existing prediction models have the characteristics of slow technological updates and slow application of new technologies. Usually, these models are mostly based on historical data, which makes it difficult to cope with complex changes in the future, thereby affecting prediction accuracy and efficiency. At present, this field has achieved relatively satisfactory optimization results by utilizing various hybrid MAs or other machine learning methods to process models. However, these methods often have low universality, and there is still room for improvement in terms of prediction accuracy and efficiency. In order to overcome these limitations, this study combines the proposed IA-DTPSO with the simulation and prediction of China’s TUWRs. Through the distinctive update method of PSO variants, the parameters of TDGM (1,1,r,ξ,Csz) are optimized step by step to achieve the solution of the simulation and prediction problem of China’s TUWRs.
This study’s main contributions are as below:
- (i)A multi-strategy PSO with information acquisition, referred to as IA-DTPSO, is proposed and the entire optimization process is modeled.
- (ii)The good ENE ability of IA-DTPSO is validated on CEC2022.
- (iii)IA-DTPSO is compared with 11 other algorithms on different dimensions of CEC2022, verifying the superiority of IA-DTPSO.
- (iv)IA-DTPSO and seven other algorithms are employed to optimize parameters of TDGM (1,1,r,ξ,Csz) and applied to predict TUWRs in China. In addition, the IA-DTPSO optimized model is compared with three existing models, and the results indicate that the model optimized by IA-DTPSO achieves the minimum error among the four error evaluation metrics in both comparisons.
This study’s remaining parts are arranged as below: Section 2 reviews PSO’s basic framework. Section 3 gives an optimization model for IA-DTPSO. Section 4 analyzes and discusses the experimental results of IA-DTPSO on CEC2022. Section 5 utilizes the proposed IA-DTPSO to optimize TDGM (1,1,r,ξ,Csz) and applies it to simulate and predict TUWRs in China. Section 6 provides a summary of this study and prospects for the future.
2. The Classic PSO
PSO [16] regards bird flocks as a group of particles with self-activity trajectories, and the activity trajectories of particles depend on their velocity v and position x. Then, the calculation formula for v at time t + 1 is shown in Equation (1) [16]:
where ω is the inertia weight, c1 and c2 represent individual and social cognitive factors, respectively, and r1 and r2 are random numbers between [0, 1]. Assuming there are N populations, and represent the historical best positions found by the i-th and all N particles up to time t.
At time t + 1, x is updated according to the current position of the particle and the rate of change towards the next position, as shown in Equation (2) [16]:
3. The Proposed IA-DTPSO
In this section, we introduce five strategies to optimize PSO and propose an improved PSO (IA-DTPSO) method. The proposed IA-DTPSO is described in detail below.
3.1. Sobol Sequence Initialization
The initial solutions’ distribution is an important prerequisite for affecting the convergence speed of MAs. A homogeneously spread initial population can effectively improve the search efficiency of MAs. Therefore, this article uses a Sobol sequence initialization [55] population instead of the random initialization scheme in PSO. The Sobol sequence is a low-variance sequence that uses a deterministic quasi-random number sequence instead of a pseudo-random number sequence to fill, as evenly as possible, points into a multidimensional hypercube, thereby generating wider coverage in the solution space. The initial population position generated by the Sobol sequence is shown in Equation (3) [55]:
where Sobol**i denotes the i-th randomly generated number in the sequence. ub and lb denote the upper and lower bounds, respectively. The population spatial distribution of Sobol sequence initialization is shown in Figure 1.
3.2. Information Acquisition Strategy
The information acquisition strategy is to collect and acquire useful information through the key stages of information gathering, information filtering and evaluation, information analysis and organization.
3.2.1. Information Gathering
Information gathering is a crucial step in gaining valuable feedback. Therefore, particles use various approaches and utilize a variety of channels to gather information, forming a more complete initial information system. This procedure can be expressed as [32]:
where and are two randomly generated particles at time t. μ is used as a random number between [−1, 1] to control the strength and direction of particle information collection. Generally speaking, collecting more information is not necessarily better. A large amount of information may lead to new candidate solutions exceeding the global optimum, thereby weakening the exploitation of the equation.
3.2.2. Information Filtering and Evaluation
After the particles have collected the information, they need to quickly identify the relevant useful information, and this key mechanism can be expressed as
where r3 is a random number between [0, 1], and r_N_ is a particle randomly selected from N populations. is the error generated when subjective factors filter and evaluate information, defined by Equations (6)–(9) [32]:
where is the subjective influencing factor, which serves as a quantitative indicator of particle subjectivity. It may make two extreme judgments on the information, thereby changing the result of information acquisition. Owing to changes in subjective states, the evaluation of different particles or the same particle at different time points may vary. Another key factor is , which characterizes the algorithm’s ability to self-adjust based on the information quality at different iteration stages. Among it, represents the information quality factor, which avoids the algorithm from neglecting the basic requirements of information quality due to excessive optimization iteration dynamics. Furthermore, r_i_ (i = 4, 5, 6, 7) is a random number between [0, 1] in these equations.
Figure 2 shows a schematic diagram of information filtering and evaluation, from which it can be seen that particles exhibit adaptive adjustment behavior when evaluating different information, which not only effectively eliminates unconventional information but also significantly improves the overall quality of information.
3.2.3. Information Analysis and Organization
After filtering out the information, particles need to seek out existing valuable information. They increase the likelihood of obtaining the optimal target information by converting the convertible information identified in the preceding stage into valuable information. This operation can be shown by Equations (10) to (11) [32]:
where r_i_ (i = 8, 9, 10, 11) is a random number between [0, 1]. indicates a controlling factor, the trend of which is shown in Figure 3.
During this process, particles can optimize the depth and breadth of this stage dynamically, according to the quality of the information, thus increasing the target information body’s accuracy. In the next iteration, the novel information subject will totally substitute the previous information subject. Figure 4 depicts the entire framework of the information acquisition strategy.
3.3. SCC Method
SCC is a method used to evaluate the statistical dependence between two ranking sequences (here are two candidate solution positions) [56]. By measuring the consistency of the particle ranking differences between two candidate solutions, the statistical correlation between these two rankings can be evaluated. The expression of this method is shown in Equation (12) [56]:
where z_i_ = m_i_ − n_i_, where m_i_ and n_i_ are the rankings of N populations in two sequences, respectively. When two sequences are completely identical, they are considered positively correlated. In this case, m_i_ = n_i_. For each individual i, there is , so S_C_ = 1. Similarly, when there is inconsistency between two sequences, it can be inferred that S_C_ < 1.
In IA-DTPSO, the SCC’s calculation method shown in Equation (4) is used to measure the correlation between GB and each particle in each dimension, which determines the dimension that requires an inverse solution position update. The specific calculation formulas are shown in Equations (13)–(15) [56]:
where j is the j-th dimension on the D-dimensional problem. This targeted non-complete reverse operation helps the algorithm improve computational accuracy while maintaining its fast convergence.
3.4. Tangent Flight Strategy
Due to the fact that there is only one update method in PSO that calculates the next position based on the rate of change, this single-search method often carries the risk of convergence stagnation. Therefore, based on the PSO update method, this section utilizes the tangent flight strategy to compensate for this deficiency. The updated formula obtained by combining Equations (1) and (2) and introducing the tangent flight strategy is shown in Equation (16) [43]:
where r12 is a random number between [0, 1]. In tangent flight, all motion equations are controlled by a global step, which takes the form of step × tan(θ), and θ is a random number between . step is the move’s size, and its calculation formula is
where r13 is a random number between [0, 1], the sign controls the direction of ENE, and the norm is a Euclidean norm.
As shown in Figure 5a,b, the stride interval generated by tangent flight is large and the stride randomness is small, which keeps the search distance stable during the iteration process and greatly shortens the optimization iteration cycle of the algorithm. In addition, particles can obtain more information in this large step frequency search to get rid of local optima’s constraints.
3.5. Dimension Learning Strategy
For particles in PSO, they can only passively be limited by the radiation of PB and GB, and cannot extract more effective information from other particles. In the introduced dimension learning strategy, particles can learn based on the behavior of their neighbors. Calculate the radius between the particle and other candidate particles based on the Euclidean distance [57]:
The neighborhood of can be expressed as:
where is the Euclidean distance between and . Once the neighborhood of is constructed, a neighbor particle can be randomly selected from the j-th dimensional neighborhood for updating using Equation (20):
where r14 is a random number between [0, 1], is a randomly selected neighbor from the neighborhood , and is a randomly selected particle from N populations.
Dimension learning strategy increases the algorithm’s exploration capacity and ability to retain population diversity by increasing the interaction between particles and their neighbors and introducing other randomly selected particles from the population.
In order to present the structure and process of IA-DTPSO more intuitively, Algorithm 1 provides IA-DTPSO’s pseudo-code and draws IA-DTPSO’s flowchart as mirrored in Figure 6. Algorithm 1: IA-DTPSO’s pseudo-codeStart IA-DTPSOInput: Particles’ number (N) and iterations (T)Output: The optimum1: Use Equation (3) for Sobol sequence initialization and store the current optimum 2: While (it < T) Do3: For i = 1 to N Do4: Use Equation (4) to form the initial information system5: End For6: Update the parameter a using Equation (15)7: Calculate the Spearman’s correlation coefficient S_c_ using Equations (12) and (14)8: For i = 1 to N Do9: For j = 1 to D Do10: If S_c_ <= 0 11: For 12: Use Equation (13) to determine the dimension that requires reverse solution position update13: End For14: End If 15: End For 16: End For 17: For i = 1 to N Do 18: Calculate the movement size step using Equation (15)19: Use Equation (16) for the tangent flight or PSO update scheme to randomly update particles’ position 20: End For21: For i = 1 to N Do22: Exploration 23: Update relevant parameters using Equations (6)–(9) 24: Use Equation (5) for information filtering and evaluation process 25: End 26: Exploitation 27: Update parameter using Equation (11)28: Use Equation (10) for information analysis and organization29: End30: End For 31: For i = 1 to N Do32: Update radius using Equation (18)33: Construct the neighborhood using Equation (19)34: For j = 1 to D Do35: Update a randomly selected neighbor particle on the neighborhood using Equation (20)36: End For37: End For38: Compute fitness values and store the current optimum39: it = it + 140: End While 41: Output the optimumEnd IA-DTPSO
3.6. Time Complexity Analysis of IA-DTPSO
In this section, we discuss the time complexity of IA-DTPSO. The time complexity of IA-DTPSO mainly depends on four parts: Sobel sequence initialization O(N × D), fitness evaluation O(5 × N), fitness ranking O(N × logN), and update O(5 × N × D). Therefore, the time complexity of IA-DTPSO is as follows:
4. Experimental Results and Discussion
4.1. Experimental Design and Parameter Setting
In this section, we test IA-DTPSO with 11 different types of comparison algorithms on the 10 and 20 dimensions of CEC2022 [23]. This test set provides a train of challenging test functions, as shown in Algorithm 1. By inputting variables N and T, continuous position updates and iterations are carried out until the optimum is output. The entire process reflects the solving performance of IA-DTPSO on these functions. Therefore, CEC2022 is an effective tool for fair comparison between different MAs. Comparative algorithms can be categorized into the following two types:
- (1)New MAs proposed in recent years: RUNge Kutta Optimizer (RUN) [58], Northern Goshawk Optimization (NGO) [19], Nutcracker Optimization Algorithm (NOA) [21], Genghis Khan Shark Optimizer (GKSO) [23], and IVY Algorithm (IVYA) [59].
- (2)PSO [17] and its various improved versions: Elite Archives-driven PSO (EAPSO) [60], Gaussian Quantum-behaved PSO (G-QPSO) [61], Hybrid algorithm based on Jellyfish Search PSO (HJSPSO) [62], single-objective variant PSO (PSO-sono) [63], and Multi-strategy PSO incorporating Snow Ablation Optimizer (SAO-MPSO) [64].
Table 1 displays the parameter settings for each MA. To avoid the influence of unexpected factors on the experiment, the runs are set to 20, which means that all MAs are independently run 20 times on each test function. Meanwhile, set N to 100 and T to 1000. Evaluate the optimization results through six evaluation metrics: Best, Worst, Mean, Wilcoxon Rank Sum Test (WRST), Friedman Test (FT), and Rank. In addition, optimization results are evaluated through three error indicators: Standard deviation (Std), Root Mean Square Error (RMSE), and relative error (δ). All tests are conducted according to the equipment specifications displayed in Table 2.
4.2. ENE Behavior Analysis
In order to further confirm that the improvement strategy proposed in this study is promising and effective in solving potential problems, this section discusses the trend of ENE rate changes of IA-DTPSO on CEC2022. The relevant formulas are as follows [64]:
where denotes all particles’ median on the j-th dimension. Divmax indicates the maximum diversity. E1% and E2% mean exploration rate and exploitation rate, respectively.
The two intersecting nonlinear curves shown in Figure 7 represent the ENE change rate of IA-DTPSO on the CEC2022 partial function. From these graphs, it can be seen that ENE rapidly approaches the intersection point at the beginning of iteration, which is attributed to the fact that the initial population under Sobol sequence initialization can effectively improve the search efficiency of particles. Subsequently, ENE reaches the first equilibrium point, where the two are intertwined and the ENE rate is 50%. This is due to the fact that the updated equations of Equations (5) and (9) in the information acquisition strategy effectively balance ENE. As shown in F1, F7, and F10 in Figure 7, after the first intersection of ENE, IA-DTPSO quickly transitioned from exploration to exploitation, focusing on local exploitation and completing the entire search in subsequent iterations. This is due to the targeted non-complete reverse operation of SCC, which helps IA-DTPSO improve convergence accuracy. However, ENE may experience fluctuations and even multiple intersections on certain functions. As shown in F6, ENE intersects several times at 50% and eventually stabilizes. This is because in tangent flight, the random step frequency and size generated by particles can obtain more information, and this random execution of exploration or exploitation operations can effectively break free from the constraints of local optima. The dimension learning strategy enhances the algorithm’s exploration ability and ability to maintain population diversity by increasing the interaction between particles and their neighbors. Specifically, as shown in F11, after 500 iterations, the proportion of exploration continues to increase, indicating that IA-DTPSO is still searching for the global optimum. In summary, the proposed strategies play their respective roles in solving CEC2022 and jointly promote the convergence of IA-DTPSO towards the theoretical optimum.
4.3. Experimental Results and Analysis
Table 3 displays statistical results of IA-DTPSO and other MAs on 10-dimensional CEC2022, with the optimal data highlighted in bold. In addition, the Theoretical Optimal (TO) values for F1–F12 in CEC2022 are 300, 400, 600, 800, 900, 1800, 2000, 2200, 2300, 2400, 2600, and 2700, respectively. All values that reach theoretical optimum in experimental results of this section are replaced by “TO”. For an algorithm, the more times it reaches TO, the better its performance. Firstly, IA-DTPSO achieves smaller values on 7 out of 12 test functions, accounting for 58.33% of CEC2022. Secondly, IA-DTPSO performs particularly well on uni-modal functions (F1), hybrid functions (F6–F8), and composition functions (F9–F12), all of which have achieved at least the top 2 rankings. Finally, according to the final ranking results, IA-DTPSO has a mean rank of 1.833 and a mean FT of 2.681, both leading the other comparison MAs. This denotes that IA-DTPSO has a great ability to solve complex optimization problems, and a smaller FT also means that IA-DTPSO has better stability. If FT is designed for repeated testing, then WRST is designed to test the pairing between two groups. Table 3 presents the WRST results under the condition of significance level = 0.05. The symbol “-” denotes comparison algorithms’ number that are inferior to IA-DTPSO; “+” is the quantity of opposite effects to “-”; “=“ represents the number of algorithms with similar performance compared to IA-DTPSO. The final functions’ numbers that are superior/similar/inferior to IA-DTPSO for each comparison algorithm are 2/0/10, 0/1/11, 4/3/5, 0/0/12, 0/1/11, 0/0/12, 1/2/9, 0/0/12, 3/2/7, 0/0/12, and 0/2/10, respectively. The WRST results show that NOA, IVYA, G-QPSO, and PSO-sono obtain the same test data, and these algorithms do not outperform IA-DTPSO on any of the functions. RUN and GKSO also obtain the same test data, which only show similar performance to IA-DTPSO on one function and inferior to IA-DTPSO on the other functions. Although NGO and HJSPSO, ranked second and third respectively, outperform IA-DTPSO in some functions, they are inferior to IA-DTPSO in more functions. Therefore, it can be said that NGO and HJSPSO also have certain competitiveness. In addition, PSO ranked seventh, which is inferior to IA-DTPSO on 10 functions, indicating that IA-DTPSO has significantly improved its optimization ability compared to PSO. However, PSO still outperforms IA-DTPSO on two functions, and further improvement of IA-DTPSO’s performance on these functions can be considered in the future.
To further compare the discrepancy in performance between IA-DTPSO and various MAs, Table 4 provides the error data for IA-DTPSO and other algorithms in solving the 10-dimensional CEC2022. Based on the relevant data in Table 4, the Std values of PSO are relatively high on F1 and F6, indicating that PSO exhibits instability on different test functions. Meanwhile, the RMSE and δ values of PSO on F6 are also high, indicating that PSO has low accuracy in complex problems and inconsistent performance in different runs. In addition to PSO, NOA, IVYA, and PSO-sono also perform poorly on complex problems, with low stability and accuracy. EAPSO and NGO perform well on simple issues but are still slightly inferior to IA-DTPSO on complex issues. IA-DTPSO gains relatively small RMSE and δ values on most functions, suggesting that IA-DTPSO has high accuracy to assure that more experimental results are close to the TO solution.
Figure 8 mirrors IA-DTPSO’s convergence curves and other MAs on 12 functions. IA-DTPSO quickly converges to the global optimum in the early stage and finds the TO solution around 100 iterations. This is due to the Sobol sequence initialization generating a good initial solution for the particle population, which gives IA-DTPSO extraordinary optimization ability. In addition, IA-DTPSO still has a downward convergence trend after 1000 iterations when solving the F4 function, indicating that IA-DTPSO still has the capacity to find the global optimum. This is also due to the information acquisition strategy that maintains the diversity between different particles, resulting in a steady increase in population diversity. Based on the box plots shown in Figure 9, IA-DTPSO’s box shape is relatively narrow and positioned downwards, indicating that IA-DTPSO has good robustness and high accuracy.
Table 5 presents the statistical results of IA-DTPSO and other MAs on 20-dimensional CEC2022. Firstly, IA-DTPSO achieves smaller values on 5 out of the 12 test functions, accounting for 41.67% of CEC2022. Secondly, IA-DTPSO performs particularly well on uni-modal functions (F1) and hybrid functions (F6–F8), both ranking at least in the top two. Finally, according to the final ranking results, IA-DTPSO has a mean rank of 2.417 and a mean FT of 3.242, both leading the other comparison algorithms. This indicates that with the increase in problem dimensions, IA-DTPSO still has a positive optimization ability. Meanwhile, Table 5 presents the WRST results of IA-DTPSO and other MAs. The number of functions obtained for each comparison MA that are superior/similar/inferior to IA-DTPSO is 1/1/10, 0/2/10, 3/2/7, 0/0/12, 0/2/10, 1/0/11, 3/4/5, 0/0/12, 4/1/7, 0/0/12, and 4/3/5, respectively. From the WRST results of this group, NOA, G-QPSO, and PSO-sono obtain the same test data, and these algorithms do not outperform IA-DTPSO on any of the functions. Similar to the test results on the 10-dimensional CEC2022, RUN and GKSO also obtain the same settlement data. They only perform similarly to IA-DTPSO on one function and are inferior to IA-DTPSO on the other functions. In addition, PSO ranked eighth and only outperformed IA-DTPSO on one function and is inferior to IA-DTPSO on ten functions, indicating that IA-DTPSO has significantly improved its optimization level compared to PSO. It is worth mentioning that HJSPSO and SAO-MPSO, ranked fourth and fifth, respectively, have a higher number of functions than IA-DTPSO, NGO, and EAPSO, ranked second and third, respectively. Combined with the mean rank outcomes, there is no appreciable discrepancy in the performance of these MAs.
Table 6 provides error data for IA-DTPSO and other algorithms in solving 20-dimensional CEC2022. Based on the relevant data of the best and worst values in Table 5, IA-DTPSO has smaller Std values on most functions. Combined with the relevant data of Mean in Table 5, IA-DTPSO also gains smaller RMSE and δ values on most functions. Thus, IA-DTPSO has high accuracy and always approaches the TO solution with minimal error, making it the algorithm with the best overall performance. In addition, EAPSO and SAO-MPSO perform well on simple problems, but are slightly inferior to IA-DTPSO on complex problems. It is worth mentioning that PSO, NOA, IVYA, and PSO-sono still perform poorly in high-dimensional complex problems, manifested in low stability and accuracy.
Figure 10 mirrors the convergence curves of IA-DTPSO and other MAs on a 20-dimensional CEC2022. IA-DTPSO has a faster convergence rate on most functions, and its convergence curve can reach a lower landing point within a limited number of iterations. In addition, IA-DTPSO still has a downward convergence trend after iteration termination when solving F3, F4, and F7 functions, indicating that IA-DTPSO still has the capacity to find the global optimum. Figure 11 mirrors the box plots of IA-DTPSO and other MAs on a 20-dimensional CEC2022. IA-DTPSO’s box shape is relatively narrow and positioned downwards, indicating that IA-DTPSO has good robustness and high accuracy.
Figure 12 shows a line graph comparison of the mean rank and mean FT of IA-DTPSO and other algorithms in different dimensions of CEC2022. Among them, (a) is the comparison result in 10 dimensions, and (b) is the comparison result in 20 dimensions. From the two sub-graphs in Figure 12, IA-DTPSO has the smallest mean rank and mean FT in both dimensions, which is due to the stable performance of IA-DTPSO in both dimensions under the influence of the dimension learning strategy. In addition, owing to discrepancies in statistical approaches, the mean FT and mean rank of each algorithm also vary slightly. The smaller this difference, the better the stability of the algorithm’s operation. Finally, Figure 13 mirrors the stacked rank and bar chart of IA-DTPSO and other algorithms in different dimensions and finds that IA-DTPSO obtains the lowest cumulative column height. In summary, the comprehensive performance of IA-DTPSO is obviously better than the other compared MAs.
5. Simulation and Prediction of TUWRs in China Based on IA-DTPSO and TDGM(1,1,r,ξ,Csz)
We verified the superiority of the proposed IA-DTPSO on the test set. In this section, we use IA-DTPSO to optimize TDGM (1,1,r,ξ,Csz) and apply the optimized TDGM (1,1,r,ξ,Csz) model to simulate and predict TUWRs’ situation in China.
5.1. TDGM(1,1,r,ξ,Csz)
Definition **1.**Let a set of data sequences , *is a one-time accumulation sequence of * , as shown in Equation (26):
where the calculation formula for is shown in Equation (27):
where * function is utilized to optimize the space of order r in the model. Figure 14 shows the graph of function.*
It is not difficult to derive the expression for the inverse first-order accumulation sequence of from Definition 1, which will not be repeated here.
Definition 2. is the average sequence generated by consecutive neighboring neighbors of , as shown in Equation (28):
where the calculation method of is shown in Equation (29):
Definition **3.***If * , , and have the same definitions as above, then there are
Equation (30) is denoted as TDGM (1,1,r,ξ,Csz).
Theorem **1.**Let be computed as shown in Equation (31):
where Y and B are matrices (n − 1) × 1 and (n − 1) × 3, respectively, expressed as:
Theorem **2.**The r-order time response function of TDGM (1,1,r,ξ,Csz) is
*where * and
The proof process of TDGM (1,1,r,ξ,Csz) is described in reference [65].
5.2. Investigation Data Analysis
TUWRs refer to the surface and underground water production formed by urban precipitation, which is the sum of surface runoff and precipitation infiltration recharge [66]. China is a country with abundant water resources, but also a country with scarce and unevenly distributed water resources [67]. With the acceleration of urbanization, people’s demand for water resources has sharply increased. In order to improve prediction accuracy and water resource utilization efficiency, this section selects the TUWRs in China from 2004 to 2023 for simulation and prediction. Table 7 presents the total urban water resources data in China over the past 20 years, sourced from the National Bureau of Statistics (https://data.stats.gov.cn/ access on 20 March 2025). As an important input data for this method, 75% of the data (2004–2018) will be used for the training set and 25% (2019–2023) for the test set.
Figure 15 shows the distribution of the proportion of TUWRs in China from 2004 to 2023. It can be seen that China’s TUWRs do not increase linearly over time, and their annual TUWRs are influenced by actual social conditions. Figure 16 shows the growth rate of TUWRs in China, from which it can be seen that the total urban water resources growth rate was the most significant from 2009 to 2013, while the growth rate in the past two years has been relatively slow.
5.3. Model Evaluation Criteria
This study uses four error evaluation metrics to gauge the predictive performance of TDGM (1,1,r,ξ,Csz), including Absolute Percentage Error (APE), Mean Absolute Percentage Error (MAPE), simulation MAPE (MAPEsimulation), and prediction MAPE (MAPEprediction). The descriptions of these indicators are shown in Equations (35)–(38) [68]:
where and are the fitted value and the raw data, respectively.
5.4. IA-DTPSO and Other Algorithms for Parameter Optimization and Prediction of TDGM (1,1,r,ξ,Csz)
This section uses IA-DTPSO, PSO [17], GKSO [23], IVYA [59], EAPSO [60], HJSPSO [62], PSO-sono [63], and SAO-MPSO [64] to optimize TDGM (1,1,r,ξ,Csz) and applies them to simulate and predict TUWRs in China. Table 8 shows the statistical results of IA-DTPSO and other MAs for solving TUWRs in China. Among them, SimD represents simulated data, and ResE represents residuals. It is not difficult to see from Table 8 that all data except for the true values given over these years are output data. Among them, the MAPEsimulation (%) and MAPEprediction (%) of IA-DTPSO on the training and testing sets are 5.6366 and 6.8041, respectively, and the total MAPE (%) is 5.9439. It can be seen that the three performance indicators of IA-DTPSO have achieved the minimum values compared with the other seven MAs. Furthermore, the MAPEsimulation (%) and MAPEprediction (%) of PSO on the training and testing sets are 6.6432 and 7.2254, respectively, and the total MAPE (%) is 6.7964. Obviously, IA-DTPSO has significantly reduced the error in predicting TUWRs in China compared to PSO. Table 9 shows the parameters calculated by IA-DTPSO and other algorithms after optimizing the TDGM (1,1,r,ξ,Csz). Finally, Table 10 displays the forecast results of TUWRs in China in the next five years. TUWRs in China will reach 3368.846 hundred million cubic meters in 2028, which is the year with the highest total water resources since 2004. How to reasonably utilize and manage these huge water resources will be a challenge in the future.
5.5. Four Models for Simulating and Predicting TUWRs in China
In this section, the IA-DTPSO optimized TDGM (1,1,r,ξ,Csz) and existing GM (1,1) [69], DGM (1,1) [70], and NGBM (1,1) [71] models are used to simulate and predict TUWRs in China. The statistical results are shown in Table 11. From the output data in the table, it can be seen that the TDGM (1,1,r,ξ,Csz) model optimized by IA-DTPSO (referred to as ID_T) has a MAPEsimulation (%) and a MAPEprediction (%) of 5.6366 and 6.8041 on the training and testing sets, respectively, and a total MAPE (%) of 5.9439. Its three performance indicators have reached the minimum values among the four compared models, further indicating the superiority of IA-DTPSO. Table 12 presents the forecast results of TUWRs in China for the next five years under four different models. It can be seen from the table that the GM (1,1), DGM (1,1), and NGBM (1,1) models predict a relatively flat growth trend in TUWRs for the next five years, while the TDGM (1,1,r,ξ,Csz) model optimized by IA-DTPSO shows a large fluctuation in the forecast results, which is closely related to the iteration and randomness of meta-heuristic methods and can better reflect the more fitting forecast data.
6. Conclusions and Future Prospects
This study proposes a multi-strategy improved PSO (IA-DTPSO). Firstly, Sobol sequences are introduced to produce a wider coverage of the initial particles. Secondly, an update mechanism based on information acquisition methods is established, which applies three different types of information processing operations to different stages. Among them, information gathering is the preparatory stage for particles to obtain useful information, and the remaining two methods correspond to the ENE stage of algorithms. This method improves the overall quality of information obtained by particles. Then, the SCC is introduced to gauge the correlation between GB and particles in each dimension, determining the dimensions that require reverse solution position updates, ensuring that the algorithm improves computational accuracy without sacrificing convergence speed. In addition, the use of tangent flight strategy combined with the original update method of PSO prevents the algorithm from falling into convergence stagnation. Finally, the introduced dimension learning strategy increases the interactivity between particles, enhances the overall particle vitality, and sustains the population diversity.
In the experimental section, the changing trend of the ENE rate of IA-DTPSO on CEC2022 was first discussed, further confirming the promising improvement strategy proposed in this study in solving potential problems. Then, by comparing IA-DTPSO with 11 other algorithms on different dimensions of CEC2022, the results show that IA-DTPSO achieves the minimum mean rank and mean FT index in both dimensions. According to the WRST results, IA-DTPSO outperforms other algorithms with a larger number of optimization functions in pairwise comparisons. Therefore, this study utilizes IA-DTPSO to optimize the TDGM (1,1,r,ξ,Csz) model and applies it to simulate and predict TUWRs in China. At the same time, numerical experiments are conducted to compare IA-DTPSO with seven other algorithms and three existing models, and the results show that TDGM (1,1,r,ξ,Csz) optimized by IA-DTPSO obtains the smallest error among the four error evaluation indicators compared in the two groups, verifying the superiority of the proposed method. Finally, the total urban water resources in China for the next five years are predicted, and results show that by 2028, the TUWRs in China will reach 3368.846 hundred million cubic meters. In summary, the proposed IA-DTPSO achieves good results in both numerical experiments and simulation examples.
However, IA-DTPSO still has some limitations. Its performance on two functions did not surpass PSO in solving the 10-dimensional CEC2022. In addition, the accuracy obtained by IA-DTPSO in solving F3, F4, and F11 on 20-dimensional CEC2022 is not high. In the future, further improvement of IA-DTPSO’s performance on these functions can be considered. In future work, IA-DTPSO can be applied to more existing models and compared with the optimized model in this study. IA-DTPSO may not be the most perfect optimizer, but it can definitely demonstrate its applicability in a wide range of fields. It can be attempted to use IA-DTPSO to solve other complex optimization problems, such as engineering optimization [72], feature selection [73], and path planning [74].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zhang J. Wang Y. Yang Y. Ma Y. Dai Z. Fault diagnosis and intelligent maintenance of industry 4.0 power system based on internet of things technology and thermal energy optimization Therm. Sci. Eng. Prog.202455102902
- 2Li Z. Song P. Li G. Han Y. Ren X. Bai L. Su J. AI energized hydrogel design, optimization and application in biomedicine Mater. Today Bio 20242510101410.1016/j.mtbio.2024.101014 PMC 1092406638464497 · doi ↗ · pubmed ↗
- 3Yaiprasert C. Hidayanto A.N. AI-powered ensemble machine learning to optimize cost strategies in logistics business Int. J. Inf. Manag. Data Insights 20244100209
- 4Hong Q. Jun M. Bo W. Sichao T. Jiayi Z. Biao L. Tong L. Ruifeng T. Application of Data-Driven technology in nuclear Engineering: Prediction, classification and design optimization Ann. Nucl. Energy 2023194110089
- 5Cheng J. De Waele W. Weighted average algorithm: A novel meta-heuristic optimization algorithm based on the weighted average position concept Knowl. -Based Syst.2024305112564
- 6Huang L. Wang Y. Guo Y. Hu G. An Improved Reptile Search Algorithm Based on Lévy Flight and Interactive Crossover Strategy to Engineering Application Mathematics 202210232910.3390/math 10132329 · doi ↗
- 7Gobashy M. Abdelazeem M. Metaheuristics Inversion of Self-Potential Anomalies Self-Potential Method: Theoretical Modeling and Applications in Geosciences Biswas A. Springer International Publishing Cham, Switzerland 202135103
- 8Peng L. Cai Z. Heidari A.A. Zhang L. Chen H. Hierarchical Harris hawks optimizer for feature selection J. Adv. Res.2023532612783669020610.1016/j.jare.2023.01.014PMC 10658428 · doi ↗ · pubmed ↗