Correction to “Comparing Scientific Machine Learning With Population Pharmacokinetic and Classical Machine Learning Approaches for Prediction of Drug Concentrations”

Abstract
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
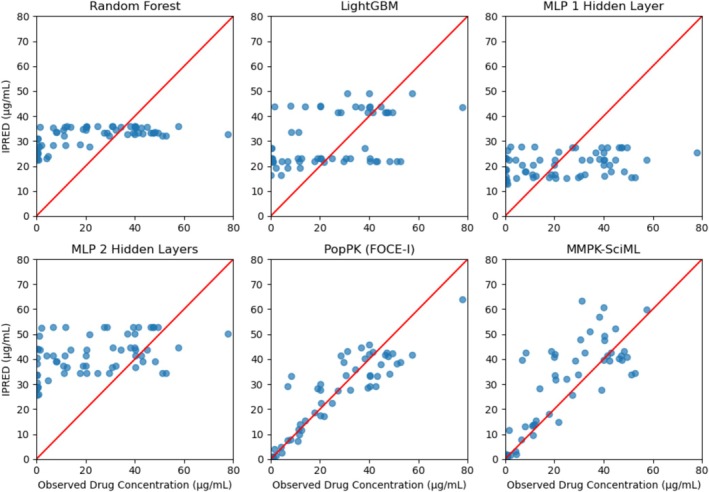 Figure 1
Figure 1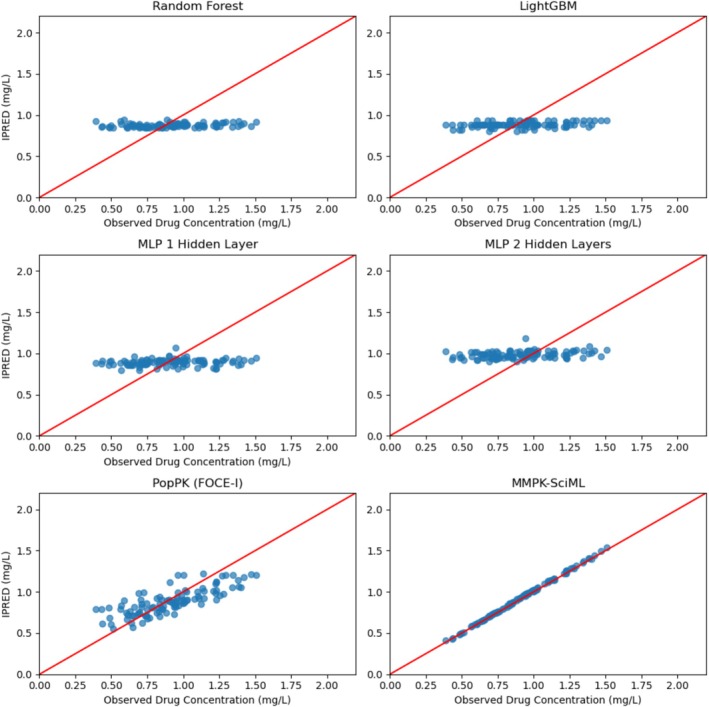 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsComputational Drug Discovery Methods
Valderrama, D. , Teplytska, O. , Koltermann, L.M. , Trunz, E. , Schmulenson, E. , Fritsch, A. , Jaehde, U. and Fröhlich, H. (2025), Comparing Scientific Machine Learning With Population Pharmacokinetic and Classical Machine Learning Approaches for Prediction of Drug Concentrations. CPT Pharmacometrics Syst Pharmacol. 10.1002/psp4.13313 PMC1200127539921335
In the published version of the above article, we noticed an inaccuracy in Figures 2 and 3 (the goodness‐of‐fit plots) and the corresponding Tables 3 and S3.
Goodness‐of‐fit plots illustrate how well a model fits the data by plotting individual predictions (IPRED) (or just predictions) against the actual observations. Upon further discussion, we realized that the IPRED shown for the Multimodal Scientific Machine Learning model were derived from maximum‐a posteriori (MAP) individual parameter estimation and those shown for the population pharmacokinetic (PopPK) models were pure simulations, that did not make use of the concentrations in the test data.
Although we stated this truthfully in our Methods section, we now realize that this comparison can be misleading. We have therefore replaced the goodness‐of‐fit plots for the PopPK model with more appropriate plots representing IPRED after MAP estimation and added the corresponding metrics to our Tables 3 and S3.
The conclusions of our article are not affected by this correction.