Monocular Object-Level SLAM Enhanced by Joint Semantic Segmentation and Depth Estimation
Ruicheng Gao, Yue Qi

TL;DR
This paper introduces a monocular SLAM system enhanced with joint semantic segmentation and depth estimation to improve performance in dynamic scenes.
Contribution
The novel contribution is a real-time multi-task network, JSDNet, that jointly predicts depth and semantic segmentation with specific architectural innovations.
Findings
JSDNet achieves state-of-the-art depth estimation and strong segmentation precision on NYU depth v2.
The system demonstrates improved trajectory accuracy on TUM RGB-D compared to other SLAM systems.
The proposed method integrates pixel- and object-level semantics into traditional SLAM processes.
Abstract
SLAM is regarded as a fundamental task in mobile robots and AR, implementing localization and mapping in certain circumstances. However, with only RGB images as input, monocular SLAM systems suffer problems of scale ambiguity and tracking difficulty in dynamic scenes. Moreover, high-level semantic information can always contribute to the SLAM process due to its similarity to human vision. Addressing these problems, we propose a monocular object-level SLAM system enhanced by real-time joint depth estimation and semantic segmentation. The multi-task network, called JSDNet, is designed to predict depth and semantic segmentation simultaneously, with four contributions that include depth discretization, feature fusion, a weight-learned loss function, and semantic consistency optimization. Specifically, feature fusion facilitates the sharing of features between the two tasks, while semantic…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
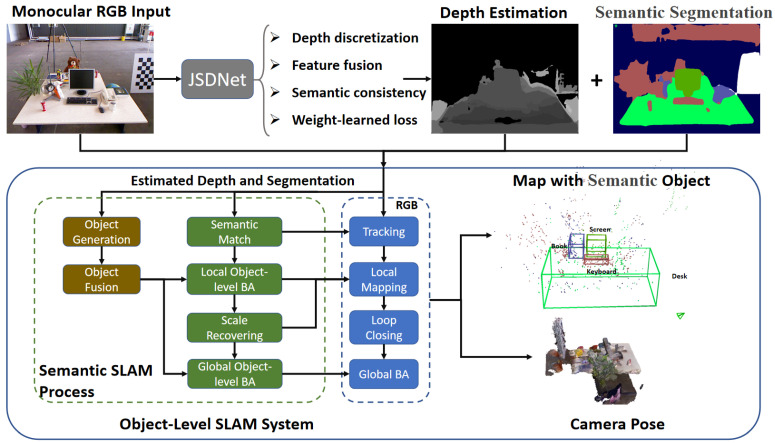 Figure 1
Figure 1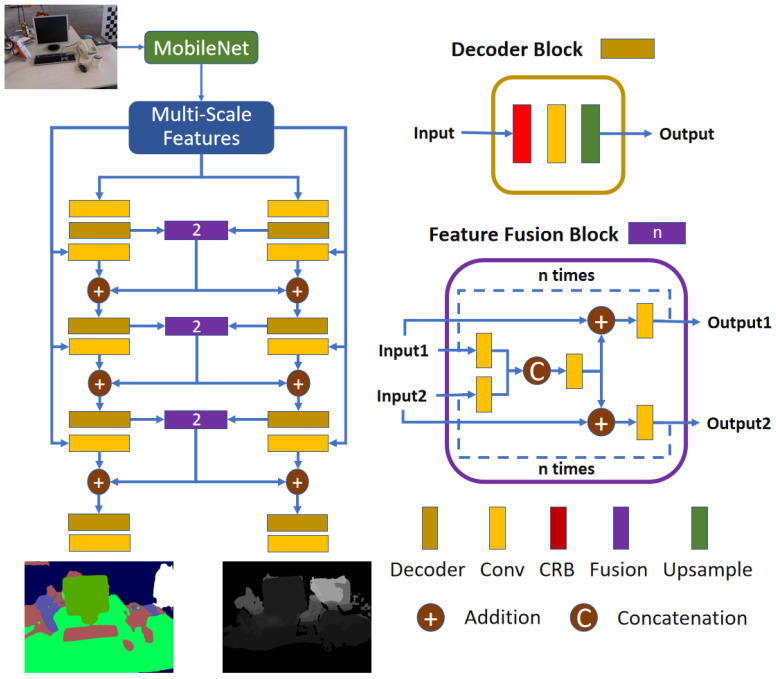 Figure 2
Figure 2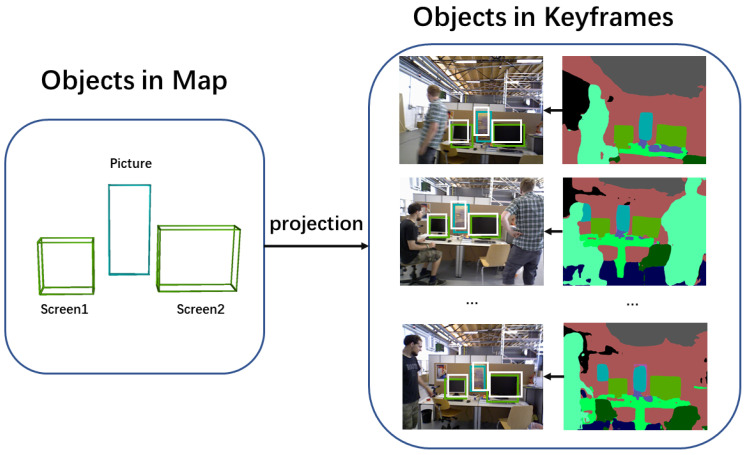 Figure 3
Figure 3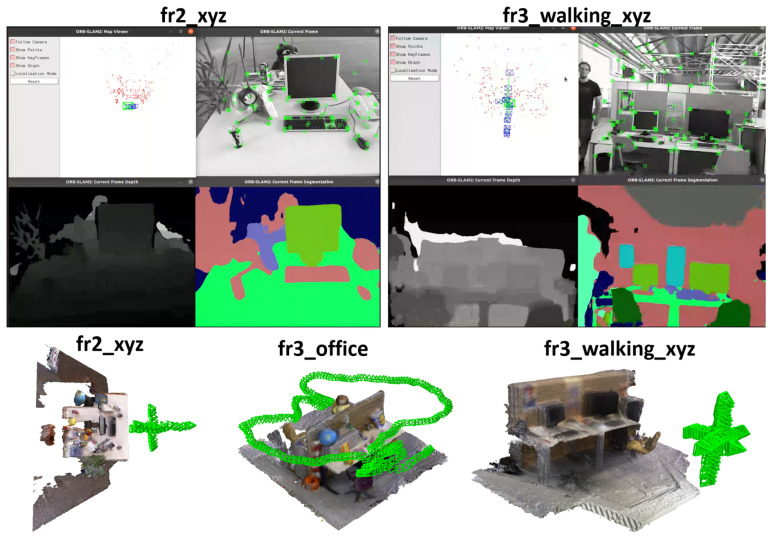 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Advanced Image and Video Retrieval Techniques · Advanced Vision and Imaging