Predicting Restroom Dirtiness Based on Water Droplet Volume Using the LightGBM Algorithm
Sumio Kurose, Hironori Moriwaki, Tadao Matsunaga, Sang-Seok Lee

TL;DR
This paper introduces a system that predicts restroom dirtiness by measuring water droplet volume using the LightGBM algorithm to optimize cleaning schedules.
Contribution
A novel prediction system using water droplet volume data and LightGBM to forecast restroom cleaning needs.
Findings
Water droplet accumulation correlates with restroom usage and potential dirtiness.
The LightGBM-based system accurately predicts cleaning needs based on droplet measurements.
Near-infrared photography effectively tracks changes in droplet volume over time.
Abstract
This study examines restroom cleanliness in public facilities, department stores, supermarkets, and schools by using water droplet volumes around washbowls as an indicator of usage. Rising cleaning costs due to labour shortages necessitate more efficient restroom maintenance. Quantifying water droplet accumulation and predicting cleaning schedules can help optimise cleaning frequency. To achieve this, water droplet volumes were measured at specific time intervals, with significant variations indicating increased restroom usage and potential dirt buildup. For real-world assessment, acrylic plates were placed on both sides of washbowls in public restrooms. These plates were collected every hour over five days and analysed using near-infrared photography to track changes in water droplet areas. The collected data informed the development of a prediction system based on the decision tree…
Click any figure to enlarge with its caption.
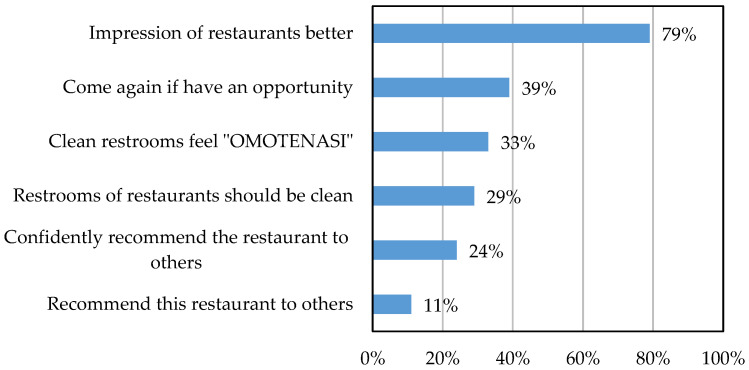 Figure 1
Figure 1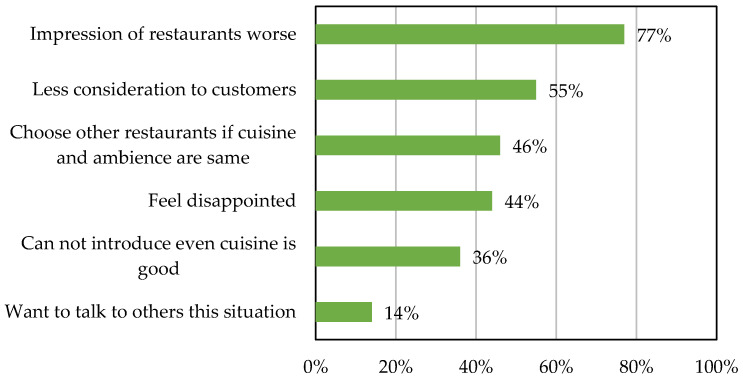 Figure 2
Figure 2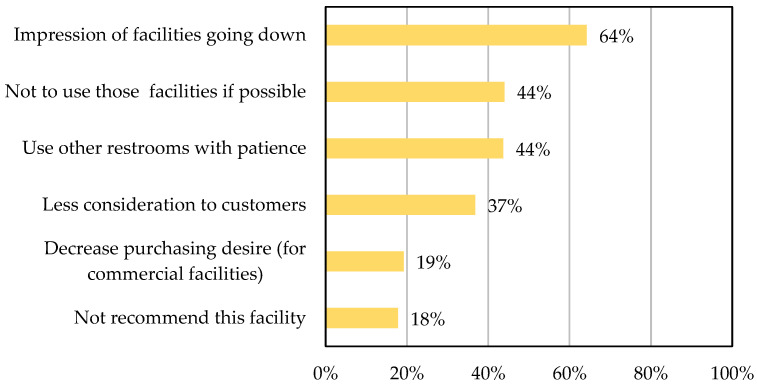 Figure 3
Figure 3 Figure 4
Figure 4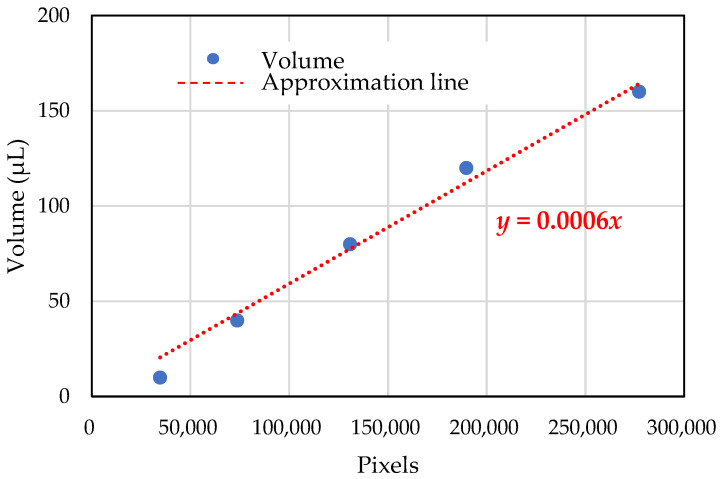 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8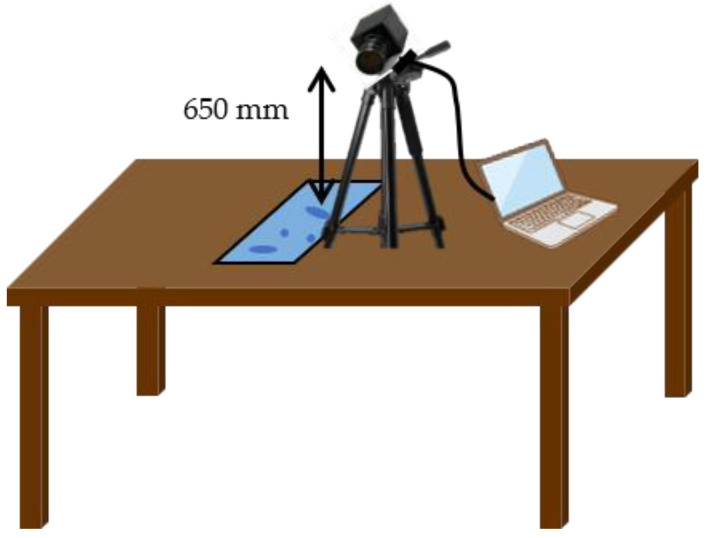 Figure 9
Figure 9 Figure 10
Figure 10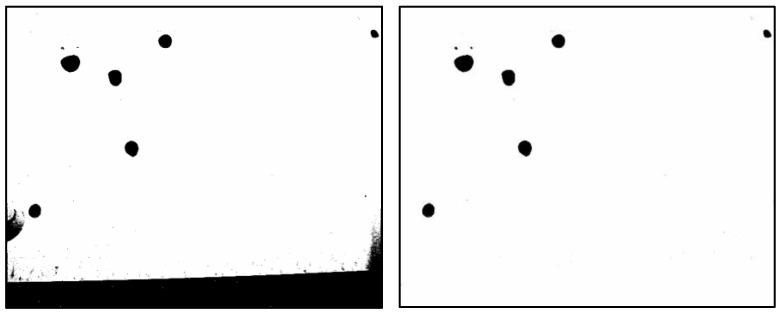 Figure 11
Figure 11 Figure 12
Figure 12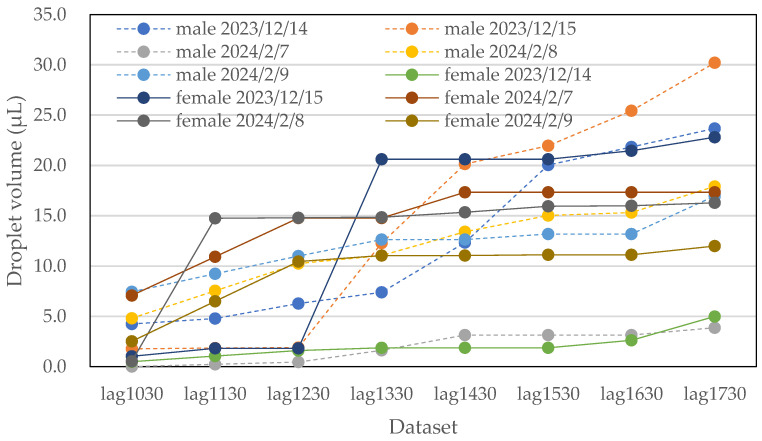 Figure 13
Figure 13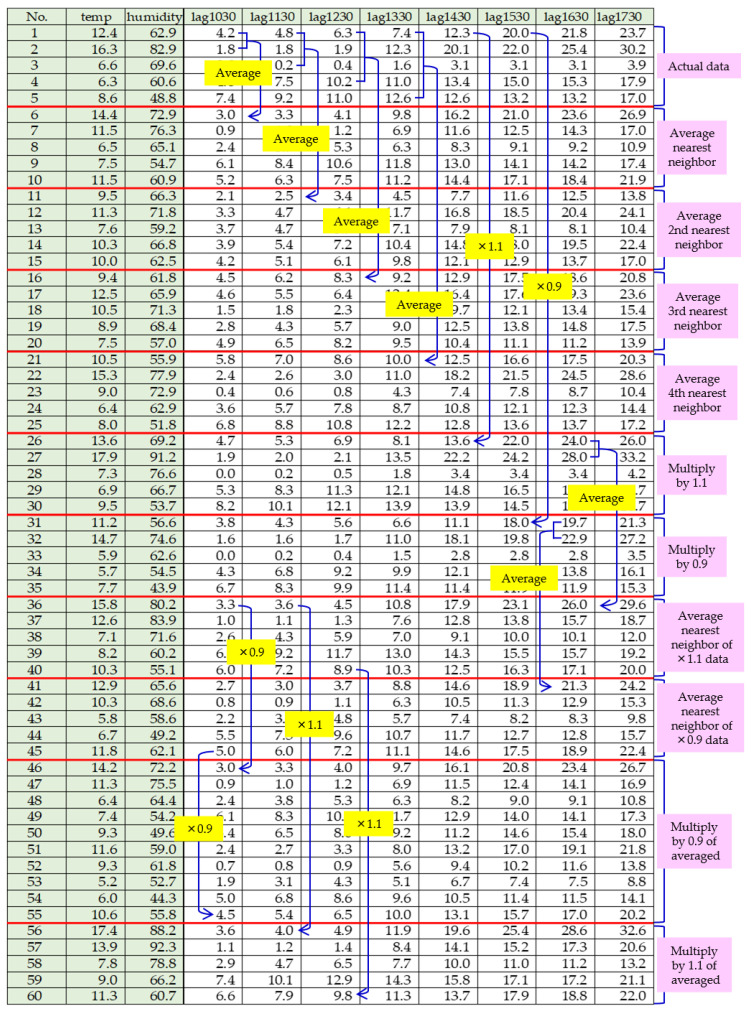 Figure 14
Figure 14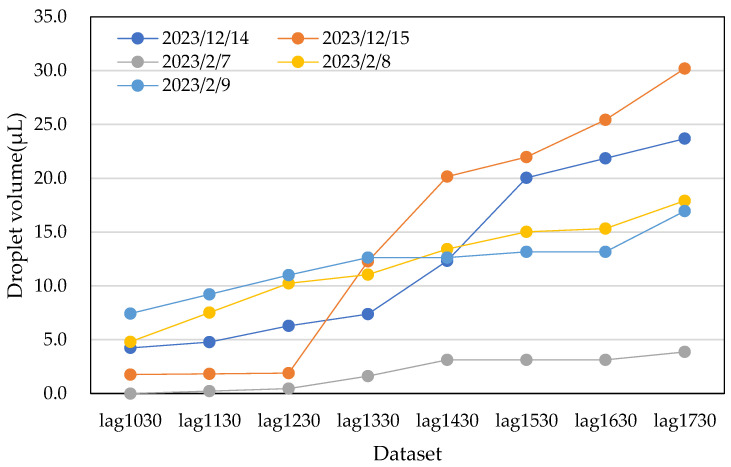 Figure 15
Figure 15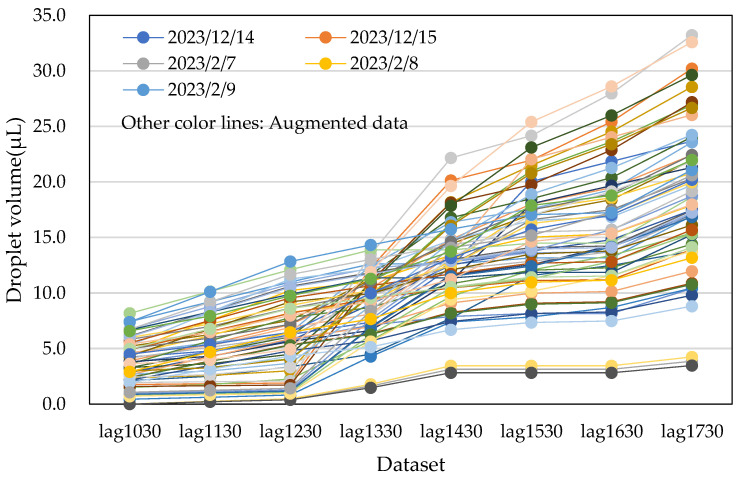 Figure 16
Figure 16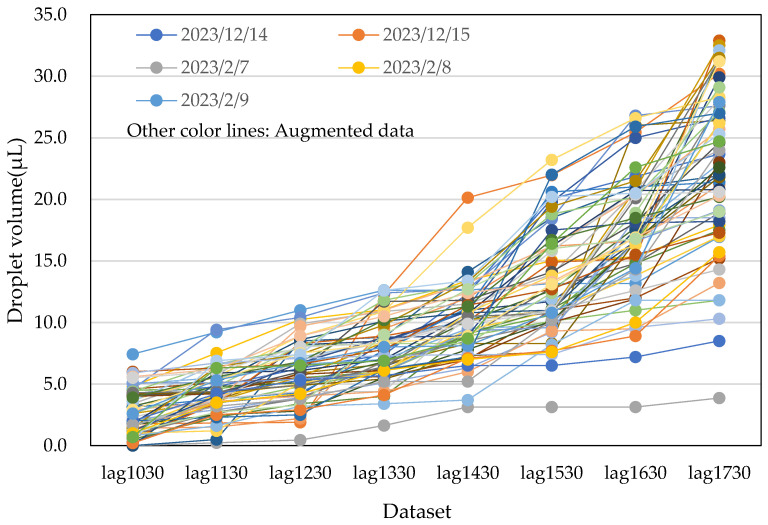 Figure 17
Figure 17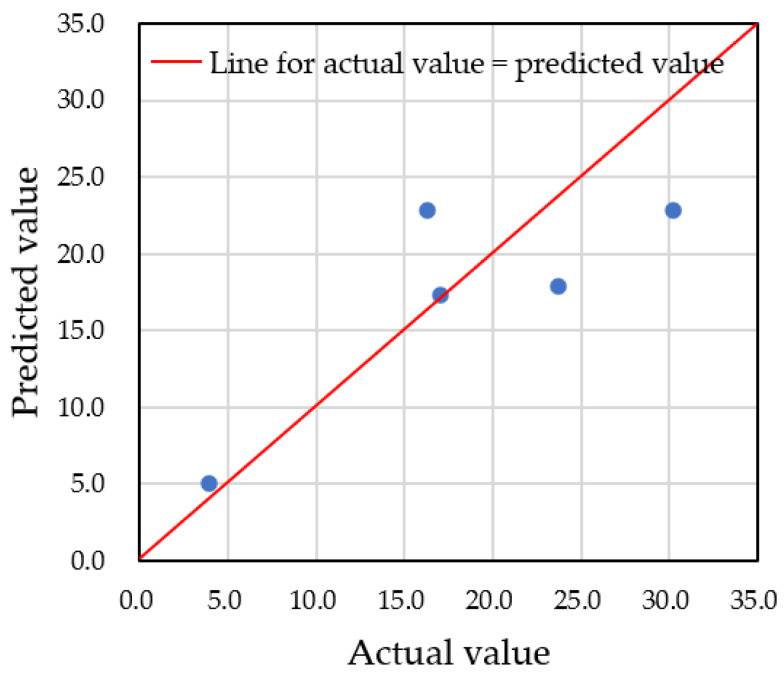 Figure 18
Figure 18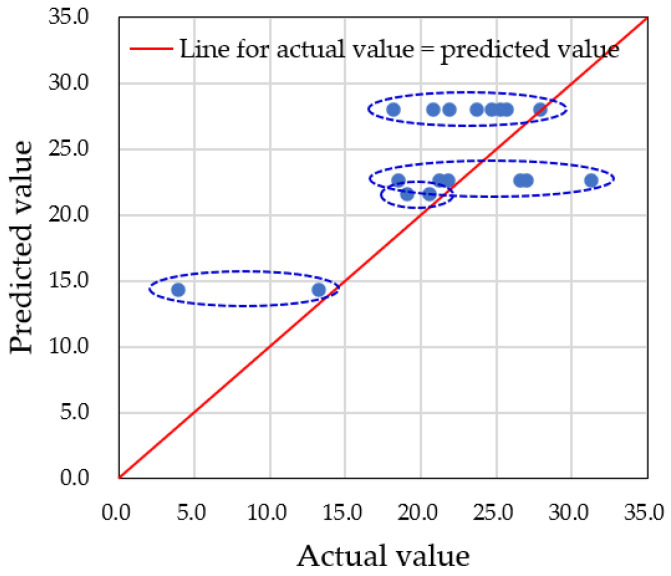 Figure 19
Figure 19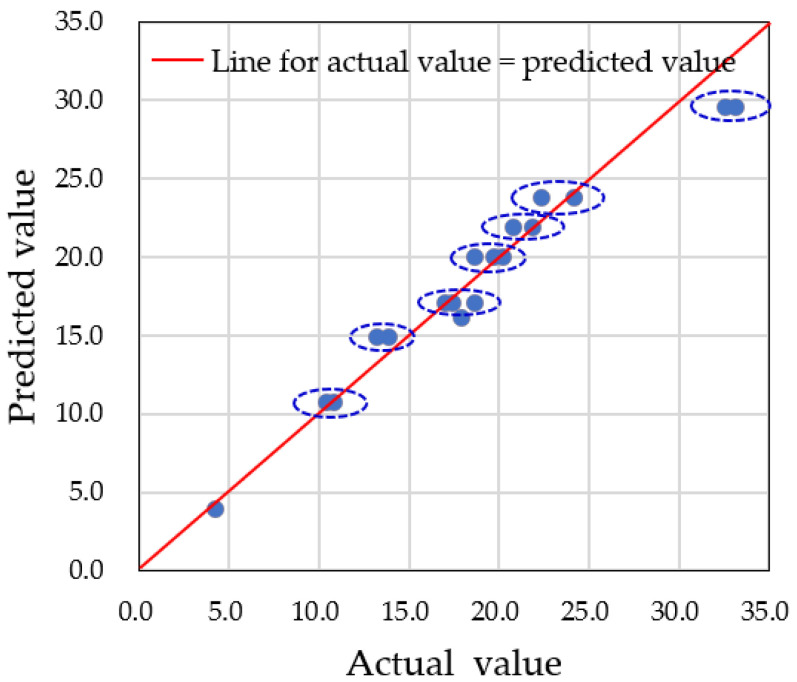 Figure 20
Figure 20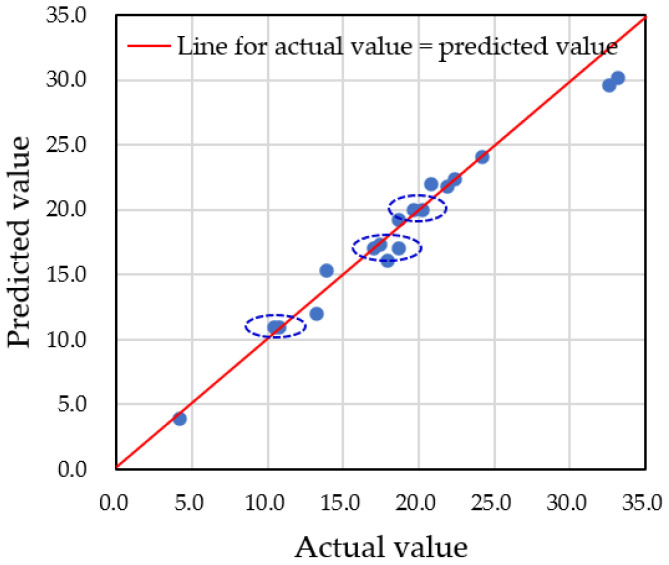 Figure 21
Figure 21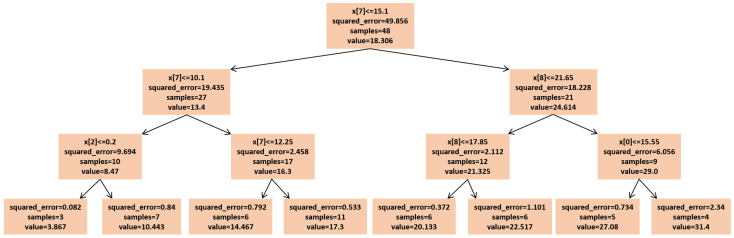 Figure 22
Figure 22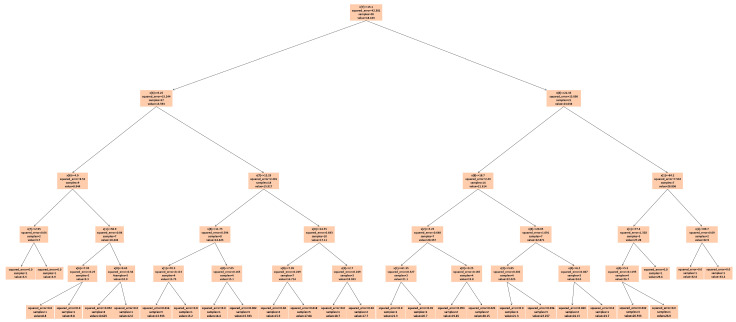 Figure 23
Figure 23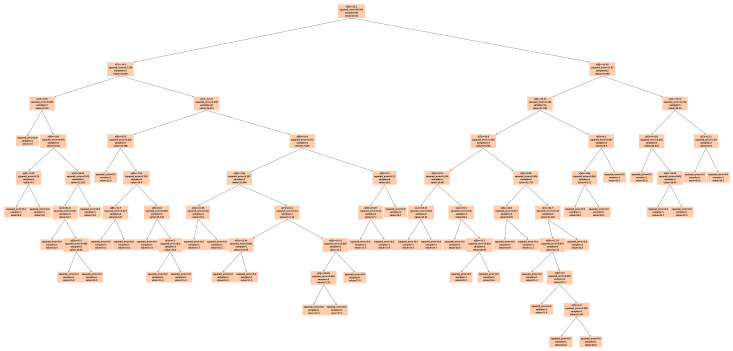 Figure 24
Figure 24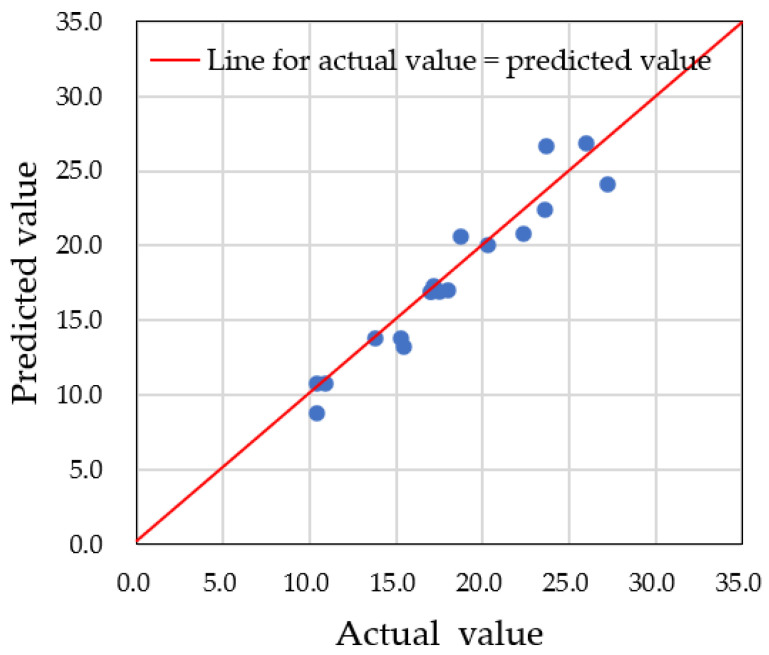 Figure 25
Figure 25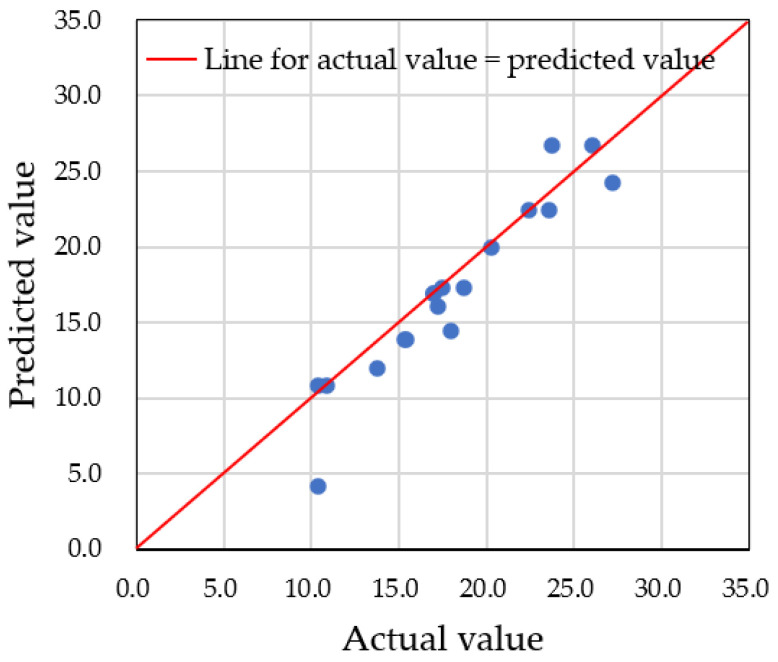 Figure 26
Figure 26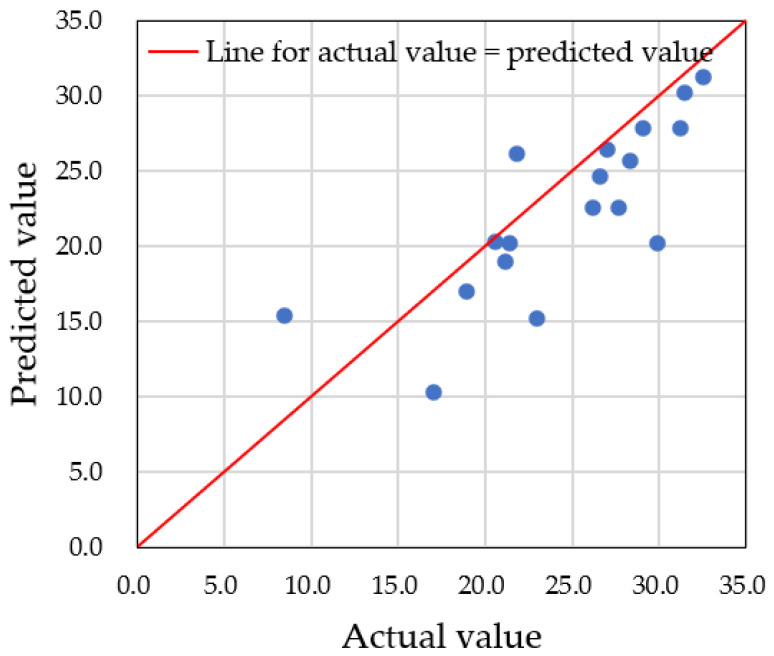 Figure 27
Figure 27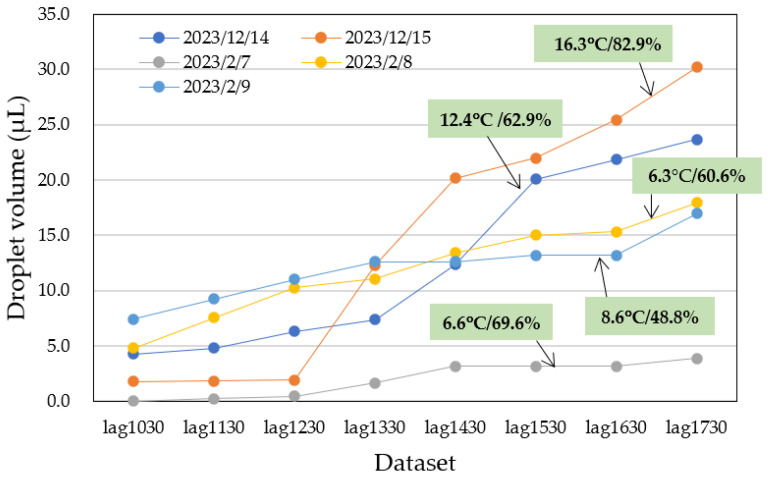 Figure 28
Figure 28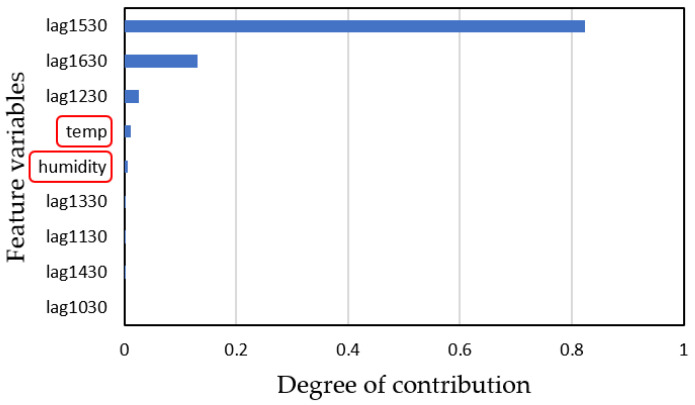 Figure 29
Figure 29Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBuilding Energy and Comfort Optimization
1. Introduction
1.1. Current Issues Faced by Cleaning Companies
Restrooms in public and commercial facilities, such as department stores, supermarkets, and schools, are typically maintained by cleaning companies. However, cleaning is often not considered a value-adding service, leading to cost compromises. Recently, rising labour costs have further increased cleaning expenses, prompting companies to focus on efficiency by optimizing cleaning frequency and duration.
Typically, commercial and public restrooms are cleaned before opening to the public, followed by periodic inspections. During these inspections, consumables such as toilet paper and hand soap are restocked, and any visible dirt or stains are addressed to maintain cleanliness [1,2,3,4,5]. This additional effort ensures that restrooms remain hygienic and well maintained.
1.2. Solution for Restroom Cleaning Issues
Historically, public restroom cleanliness has received minimal attention. However, restrooms in restaurants, department stores, and supermarkets are now more closely monitored, as their cleanliness directly impacts the facility’s image. Recognizing this, businesses have increasingly prioritised restroom maintenance.
Figure 1 and Figure 2 present survey responses from 2000 participants regarding restroom cleanliness in restaurants. Figure 1 illustrates responses to the question ‘How do you feel about clean restaurant restrooms?’. Nearly 80% of respondents stated that clean restrooms improve a restaurant’s image. Figure 2 shows responses to the question ‘How do you feel about dirty restaurant restrooms?’. Here, 77% of respondents felt that unclean restrooms negatively impact a restaurant’s image, indicating a lack of consideration for customers. These findings suggest that restroom cleanliness significantly influences public perception, not just in restaurants but also in department stores and supermarkets.
Figure 3 presents survey responses to the question ‘How comfortable do you feel using public restrooms?’. Participants, aged 20 to 60, included 80 respondents per sex per age group (totalling 800 respondents). Multiple answers were allowed [7].
Current cleaning routines are insufficient to ensure restroom cleanliness at all times. Setting an appropriate cleaning frequency and timing is essential [8,9]. Furthermore, if cleaning duration can be accurately predicted, restrooms can remain clean while minimizing cleaning costs.
As previously mentioned, assessing restroom dirtiness enables the determination of an optimal cleaning frequency and duration, allowing for a more flexible and efficient cleaning strategy. To achieve this, this study develops a prediction system and establishes a methodology for effective restroom maintenance.
2. Dirtiness Quantification Method
2.1. Definition of Dirtiness
Restrooms contain various sources of dirt, such as water droplets, hairs, and paper waste. While all types of dirt should be removed during cleaning, quantifying these different types of dirt presents challenges. Specifically, paper waste, dirt around urinals, and hairs in washbowls are difficult to measure precisely. To simplify the process, we defined the presence of water droplets around washbowls as an indicator of overall dirtiness.
Figure 4 displays images of water droplets placed using a digital pipette. The relationship between the number of pixels representing the water droplets and the corresponding volume was determined before the experiments, as shown in Figure 5. This relationship is approximated as linear.
For the in situ experiments, water droplets were collected on acrylic plates installed beside the washbowls. These droplets were then photographed, and the pixel-based images were converted to corresponding volumes using the method outlined in Section 2.2.
2.2. Overview of Method
The experiment followed a series of steps to determine the volume of water droplets around the washbowl. Water droplets were photographed using a near-infrared camera, as shown in Figure 6, where the droplets appear as black areas.
However, the image also contains extraneous black areas outside the acrylic plate, caused by background differences where no water droplets exist. To ensure accurate pixel counting, image-editing software (Photos, version 2024.11040.1002.0) was used to remove these irrelevant black areas. The cleaned-up bitmap image is shown in Figure 7. The number of pixels in the cleaned image (Figure 7) was then counted using the open-source software ImageJ (version 1.53). Finally, the pixel count was converted into the volume of water droplets using the established relationship shown in Figure 5.
This method enables the quantification of restroom dirtiness based on the volume of water droplets around the washbowl. While it does not provide a perfectly accurate estimate due to factors such as overlapping droplets, the method offers a reliable means to assess water droplet amounts. Additionally, it allows for the establishment of a cleanliness threshold, which is crucial for determining optimal cleaning timing.
3. In Situ Experiment and Results
3.1. Preparation of Water Droplet Images
To capture time-varying images of water droplets, experiments were conducted in the restrooms of a language school with approximately 70 students. The number of students present on any given day varied, and most students were from Asian countries studying Japanese for college entrance exams or Japanese qualification exams.
To collect water droplets around the washbowl, acrylic plates were placed on either side of the washbowl and replaced every hour for analysis. Figure 8 shows the actual setup, with transparent acrylic plates used in the experiment. The plates were colour-coded blue in the figure for better visibility.
Setting up a camera inside the restroom posed privacy concerns, and it was difficult to maintain the same camera position every hour. Moreover, distinguishing between male and female users was necessary. Consequently, the acrylic plates were collected every hour, and photographed in a separate room under consistent conditions, and the images were transferred to a computer connected to the camera. The camera lens was positioned 650 mm above the acrylic plates, as shown in Figure 9.
A near-infrared camera (NIRCam-640SN, Vision Sensing Co., Ltd., Osaka, Japan) was used for capturing the images, with specifications listed in Table 1. Since water absorbs at wavelengths of 1200, 1450, and 1940 nm in the near-infrared spectrum, a 1450 nm bandpass filter was attached to the camera to capture water droplets effectively. As a result, water droplets were depicted as black areas in the images.
Representative photographs taken during the in situ experiment are shown in Figure 10, Figure 11 and Figure 12. These images were captured at 10:30, 11:30, and 12:30 on the first day of the experiment at male restroom. The images on the left show the raw bitmap images, while the processed images on the right have had irrelevant black areas removed, as described in Section 2.2. Water droplet volumes were then estimated using the pre-determined relationship shown in Figure 5. These volume data were subsequently used as input for the prediction system.
3.2. Data Collection
Photographs of water droplets on the acrylic plates were captured at 1 h intervals, and the data were accumulated into ‘1 h before’ datasets. These images were collected over five days from both male and female restrooms. The data are presented in Figure 13 and Table 2. The variables lag1030 through lag1730 represent data collected at hourly intervals from 10:30 to 17:30. Additionally, the average temperature and humidity were recorded, as shown in Table 2.
The collected data on water droplet volumes exhibited significant variation, depending on individual usage, as shown in Figure 13. On some days, there were abrupt changes in droplet volumes in response to time variations. However, as the number of data points increased, this variation became less pronounced. Generally, the data indicated a tendency for the accumulated water droplet volume to increase with the number of restroom users. It is important to note that ventilation fans were continuously running in the restrooms, which led to the evaporation of water droplets over time. As a result, the observed water droplet volumes were slightly lower than the actual volumes, implying that the prediction may be somewhat underestimated.
3.3. Data Augmentation
As noted earlier, the data were collected for five days from both male and female restrooms but these were insufficient for training and prediction purposes. To overcome this limitation, a data augmentation method was applied, as long-term restroom experiments are constrained. Several data augmentation techniques have been reported in the literature, including the addition of random noise, data scaling, weighted dynamic time warping (DTW), dynamic time warping barycentric averaging (DBA) [11,12,13], moving block bootstrapping (MBB) [14,15,16,17], and the DoppelGANger framework based on generative adversarial networks (GAN) [18,19,20]. In anomaly detection, adding random noise is effective, and GANs can generate high-fidelity datasets. MBB generates pseudo-scattering through random sampling. However, our application required only a small portion of scattered datasets, and the datasets needed to be time-series. Therefore, we adopted the DBA method for our prediction model.
We primarily employed two methods for data augmentation:
- Averaging and scaling method: This approach involved successively taking averages of two nearest neighbouring data points, two second-nearest neighbouring data points, and so on. These averages were then multiplied by 0.9 and 1.1, and the process was repeated. This method generated three sets of augmented data by expanding the margins of the minimum and maximum values.
- Random number generation method: In this method, random numbers were generated between the maximum and minimum values for each dataset.
Based on the above, we primarily attempted the following two methods:
Details of the first method, involving averaging and scaling, are illustrated in Figure 14. This method resulted in a total of 60 datasets: five original datasets (data No. 1–5) and 55 augmented datasets (data No. 6–60). Each augmented dataset also included the average temperature and humidity for the day, obtained from a meteorological agency. In Figure 14, data No. 6 represents the average of data No. 1 and data No. 2, including temperature and humidity averages. Similarly, data No. 11 is the average of data No. 1 and data No. 3, and so on. By successively taking averages with two nearest neighbours, two second-nearest neighbours, and so on, we generated 20 augmented data points from the original five datasets.
Next, data No. 26 and data No. 27 were obtained by multiplying data No. 1 and data No. 2 by 1.1, respectively. Similarly, data No. 31 and data No. 33 were multiplied by 0.9. This step provided an additional 10 augmented datasets. The process was repeated by averaging the new data points, resulting in a total of 60 datasets. Figure 15 and Figure 16 show the actual water droplet data from the male restroom (Figure 13) and the augmented data from the male restroom, respectively.
The second method for data augmentation used random number generation. First, the maximum and minimum values from each hourly dataset were identified. The maximum value was multiplied by 1.1, and the minimum value by 0.9. Random numbers were then generated between these two values. This generated 55 random datasets, which, when combined with the five original datasets, resulted in a total of 60 datasets. To ensure consistency, the data were sorted in ascending order, as water droplet volumes could not decrease over time. Table 3 and Figure 17 display the augmented datasets generated by this method. Temperature and humidity were not incorporated, as the random number generation process is not time- or date-dependent.
Ultimately, three augmented datasets were prepared: (1) the averaging and scaling method, including temperature and humidity, (2) the averaging and scaling method without temperature and humidity, and (3) the random number generation method. These datasets were then used to predict water droplet volumes, and the accuracy of the prediction methods was evaluated.
3.4. Water Droplet Volume Prediction
We aimed to predict water droplet volumes at 17:30 based on data collected from 10:30 to 16:30. Specifically, our goal was to predict the water droplet volume for the hour following data collection. Although predicting the volume for 2 or 3 h intervals is more practical in real-world cleaning scenarios, this study focused on constructing and evaluating a model. Therefore, we initially chose to predict the volume for just 1 h after the data collection period.
For our predictions, we used the light gradient boosting machine (LightGBM) method [21,22,23,24,25,26], which operates within a decision tree framework. Specifically, we employed the DecisionTreeRegressor algorithm. Several other methods are available for time-series predictions, including recurrent neural networks (RNN) [27,28,29] and long short-term memory (LSTM) networks [30,31,32,33,34,35]. Both RNNs and LSTMs are based on neural networks: in RNNs, past time-series data are stored in hidden layers, whereas LSTMs store them in additional gates (forget, input, and output gates). These stored values are weighted and added to the input data.
We first evaluated the applicability and validity of the LightGBM method for our prediction task. While RNNs and LSTMs are widely used, they present challenges. RNNs are susceptible to the vanishing gradient problem, which occurs due to the activation function, and the exploding gradient problem, which arises from matrix multiplication. The data we work with are highly variable and depend on individual behaviours, making them inherently random. Although LSTMs attempt to handle this randomness by incorporating weighted past data through their gates, designing and stabilizing the weights for such unpredictable data can be difficult.
Given these challenges, we decided to first assess the LightGBM (version 4.4) framework for our prediction task. In the LightGBM model, the data were split as follows: 70% for training (42 datasets out of 60) and 30% for testing (18 out of 60).
4. Results and Discussion
4.1. Prediction Using Actual Data
First, we present the results of predictions made using only the actual datasets obtained from the in situ experiment. There were five datasets for each sex, but since this number is too small to construct a reliable prediction system with the LightGBM framework, we combined the datasets without considering gender in order to evaluate the accuracy of the prediction system. In this case, the hyperparameters were set as follows: 50% of the data (5 out of 10 datasets) was used for training, while the remaining 50% (5 out of 10) was used for testing. The decision tree depth (max_depth) was set to 9, and the random_seed was fixed. Figure 18 presents a comparison between the predicted and actual values. The results show an R^2^ value of 0.656 and a root mean squared error (RMSE) of 5.137, indicating relatively poor prediction accuracy due to the limited dataset. To improve accuracy, it was clear that augmented datasets, as described in Section 3.3, would be necessary.
4.2. Setting Hyperparameters of LightGBM
For accurate predictions of water droplet volume using augmented datasets, it is critical to carefully set the hyperparameters of the model. In this study, we focused on adjusting the depth of the decision tree, controlled by the ‘max_depth’ parameter. If the number of nodes is too small, multiple predicted data points will converge into one node, resulting in inaccurate predictions. Therefore, an adequate number of nodes is needed to properly distribute the data. In our case, we had a total of 60 datasets, with predictions made on 18 testing datasets. To classify each testing dataset into one node, at least five nodes were required. We examined three different max_depth values—3, 5, and 9—and compared the predicted values to the actual data. Figure 19, Figure 20 and Figure 21 show the results for max_depth values of 3, 5, and 9, respectively.
For max_depth = 3 (Figure 19), the model grouped multiple actual data points into a single predicted data point, resulting in four incorrect predictions. The decision tree diagram for this case, with only three nodes, is shown in Figure 22. When max_depth was increased to 5 (Figure 20), seven incorrect predictions occurred, indicating insufficient classification. With max_depth = 9 (Figure 21), only three incorrect predictions were made, with a more suitable distribution of nodes. Decision tree diagrams for max_depth values of 5 and 9 are shown in Figure 23 and Figure 24, respectively. Based on these results, we determined that a max_depth of 9 provided the most accurate predictions and should be adopted depending on the number of test cases.
4.3. Differences in Prediction Accuracy with Augmented Data
The use of only five real-world data points was insufficient for accurate predictions. Additionally, continuous data collection beyond these five days was not feasible due to privacy concerns in the restroom facilities. To address this limitation, we augmented the data using two methods, as described earlier. Figure 25, Figure 26 and Figure 27 display the prediction results using augmented datasets generated by the averaging and scaling method (including temperature and humidity), the averaging and scaling method (without temperature and humidity), and the random number generation method, respectively. In these cases, the random_seed was fixed to ensure consistency in the training and testing data across all methods. Similarly, max_depth was fixed at 9 for all comparisons.
Using the augmented datasets generated by the averaging and scaling method (including temperature and humidity), the model achieved an R^2^ value of 0.913 and an RMSE of 1.459 (Figure 25). When the augmented datasets did not include temperature and humidity data, the R^2^ value decreased to 0.812, with an RMSE of 2.138 (Figure 26). Finally, using the random number generation method resulted in an R^2^ of 0.462 and an RMSE of 4.358, as shown in Figure 27. From Figure 25 and Figure 26, we observed that omitting temperature and humidity slightly decreased prediction accuracy, suggesting that these weather variables are important for more precise predictions. However, for a simplified prediction system, omitting these variables may be acceptable, as their influence on water droplet volume is relatively minor, as shown in Figure 28. This figure compares actual water droplet data with temperature and humidity measurements taken from a male restroom. Figure 29 further illustrates the contribution of various feature variables to the prediction model, showing that temperature and humidity are less significant contributors.
The prediction using the random number generation method resulted in unnatural data, as seen in Figure 27, and produced the least accurate predictions. Therefore, the random number generation method is not suitable for this application.
In this study, we used the DecisionTreeRegressor framework within the LightGBM method for predicting water droplet volumes. LightGBM, which utilises decision trees, is well-suited for time-series data and is commonly used for regression tasks, such as the one in this study.
The main focus of our prediction system was to determine when water droplet volumes would exceed a predefined threshold, indicating maximum dirtiness. This system quantifies dirtiness using water droplet volumes around the washbowl and is designed for practical use in cleaning environments. However, due to the limited amount of real-world data, data augmentation was essential to improve prediction accuracy. Ultimately, our augmented dataset-based model allowed for reliable predictions of water droplet volumes at specific times based on earlier measurements in restrooms.
5. Conclusions
In this study, we predicted restroom cleanliness by evaluating the volume of water droplets outside washbowls as an indicator of dirtiness. Using a near-infrared camera, we captured photographs of the water droplets, converted the image data into volume measurements, and accumulated the data over a 1 h period. These measurements were collected over five days through experiments, but the limited amount of data was insufficient to develop an effective learning and prediction algorithm. To address this, we augmented the dataset using two methods: the first method involved averaging and scaling the data, while the second used random number generation. The random number method was found unsuitable, as it caused the water droplet data to fluctuate unpredictably. In contrast, the averaging and scaling method proved effective for our application.
The LightGBM-based prediction system, with optimised hyperparameters and data augmentation, is nearly practical for real-world use. Specifically, this methodology is suitable for restrooms with limited user traffic, such as those in offices and schools. By predicting future dirtiness levels, the system can determine optimal cleaning times or adjust cleaning frequency, ultimately leading to more efficient and future-oriented cleaning practices.
6. Future Study
Our system successfully predicts water droplet volume 1 h ahead, but it could also predict 2 or 3 h future volumes. The process is sequential: we first predicted the 1 h ahead droplet volume, used this as actual data, and then predicted the 2 h ahead volume, followed by 3 h prediction. However, the accuracy of predictions for the 2 and 3 h intervals is expected to be lower than for the 1 h prediction. To improve the accuracy of longer-term predictions, additional data collection is necessary.
Currently, our prediction system relies on photographs of water droplets, which may not be practical in all real-world scenarios. Future work will explore methods that eliminate the need for photographs, making the system more feasible for actual cleaning operations.
Although the LightGBM method treats data as an array, not a time-series, other techniques could be integrated into our system. LSTM networks, which are designed to handle time-series data and retain past information, could enhance the prediction accuracy. Furthermore, the GRU [36,37] offers a simpler and computationally less intensive alternative to LSTM. RNNs are another promising approach. We plan to evaluate these three methods—LSTM, GRU, and RNN—to determine the most optimal solution for our application.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kim H. Bachman J.R. Examining Customer Perceptions of Restaurant Restroom Cleanliness and Their Impact on Satisfaction and Intent to Return J. Foodserv. Bus. Res.20192219120810.1080/15378020.2019.1596002 · doi ↗
- 2Afacan Y. Gurel M.O. Public Toilets: An Exploratory Study on the Demands, Needs, and Expectations in Turkey Environ. Plan. B Plan. Des.20154224226210.1068/b 130020 p · doi ↗
- 3Hartigan S.M. Bonnet K. Chisholm L. Kowalik C. Dmochowski R.R. Schlundt D. Reynolds W.S. Why Do Women Not Use the Bathroom? Women’s Attitudes and Beliefs on Using Public Restrooms Int. J. Environ. Res. Public Health 202017205310.3390/ijerph 1706205332244871 PMC 7142493 · doi ↗ · pubmed ↗
- 4Jayasinghe L. Wijerathne N. Yuen C. Zhang M. Feature Learning and Analysis for Cleanliness Classification in Restrooms IEEE Access 20197148711488210.1109/ACCESS.2019.2894006 · doi ↗
- 5Lewkowitz S. Gilliland J. A Feminist Critical Analysis of Public Toilets and Gender: A Systematic Review Urban Aff. Rev.20246128230910.1177/10780874241233529 · doi ↗
- 6TOTO LTD Customer Awareness Survey of Restaurant Restrooms Available online: https://jp.toto.com/products/machinaka/restaurantquestionnaires/(accessed on 8 December 2024)
- 7Aica Kogyo Company, Limited Survey on Awareness About Comfort of Restrooms Available online: https://www.aica.co.jp/news/detail/post_143.html(accessed on 8 December 2024)
- 8Lokman A. Ramasamy R.K. Ting C.Y. Scheduling and Predictive Maintenance for Smart Toilet IEEE Access 202311179831799910.1109/ACCESS.2023.3241942 · doi ↗