Easy ensemble classifier-group and intersectional fairness and threshold (EEC-GIFT): a fairness-aware machine learning framework for lung cancer screening eligibility using real-world data
Piyawan Conahan, Lary A Robinson, Trung Le, Gilmer Valdes, Matthew B Schabath, Margaret M Byrne, Lee Green, Issam El Naqa, Yi Luo

TL;DR
This paper introduces a fairness-aware machine learning framework for lung cancer screening that reduces racial bias while maintaining high accuracy.
Contribution
The novel EEC-GIFT* model mitigates racial bias in lung cancer screening eligibility without sacrificing predictive performance.
Findings
EEC-GIFT* and LR-GIFT* models showed significantly higher sensitivity than the 2021 USPSTF criteria.
EEC-GIFT* achieved unbiased performance with a non-significant equal opportunity difference between Black and White smokers.
EEC-GIFT* and LR-GIFT* models maintained similar accuracy to the PLCOM2012 model.
Abstract
We use real-world data to develop a lung cancer screening (LCS) eligibility mechanism that is both accurate and free from racial bias. Our data came from the Prostate, Lung, Colorectal, and Ovarian (PLCO) cancer screening trial. We built a systematic fairness-aware machine learning framework by integrating a Group and Intersectional Fairness and Threshold (GIFT) strategy with an easy ensemble classifier—(EEC-) or logistic regression—(LR-) based model. The best LCS eligibility mechanism EEC-GIFT* and LR-GIFT* were applied to the testing dataset and their performances were compared to the 2021 US Preventive Services Task Force (USPSTF) criteria and PLCOM2012 model. The equal opportunity difference (EOD) of developing lung cancer between Black and White smokers was used to evaluate mechanism fairness. The fairness of LR-GIFT* or EEC-GIFT* during training was notably greater than that of…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
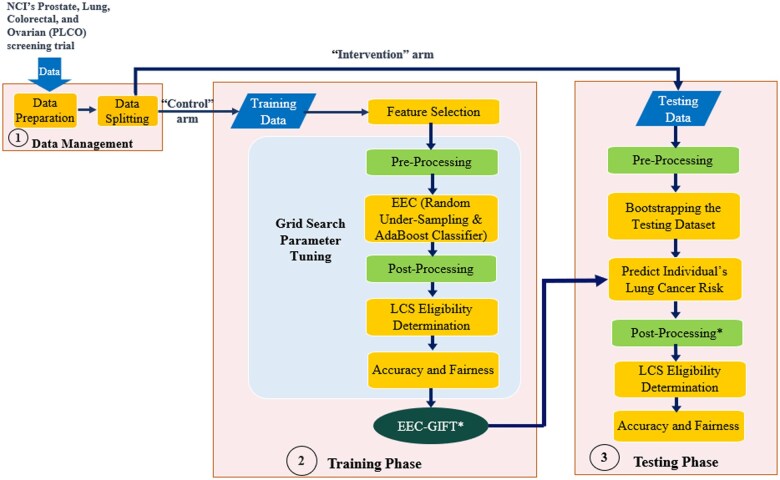 Figure 1
Figure 1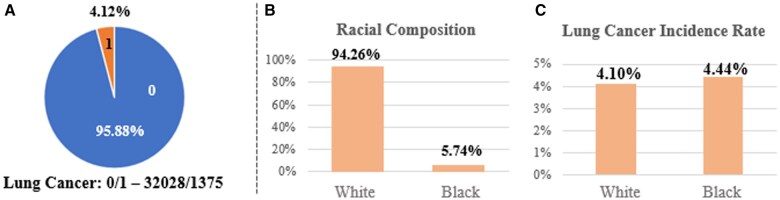 Figure 2
Figure 2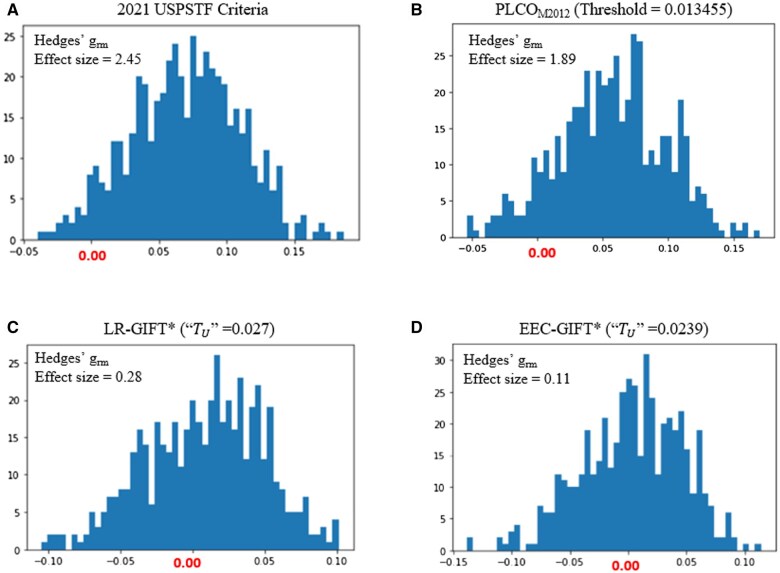 Figure 3
Figure 3| Categories | Features |
|---|---|
| Demographic Factors | (1) age, (2) education level, (3) BMI |
| Smoking History |
(4) smoking status, (5) pack-years, (6) number of years smoked, (7) number of years since stopped smoking |
| Lung-Related Issues |
(8) COPD (aggregation of “bronchitis” and “emphysema”), (9) Personal Health History (aggregation of “family history of lung cancer,” “personal history of any cancer,” and “chest X-ray history”) |
| Performance | LR | LR_RW1 | LR_RW2 | EEC | EEC_RW1 | EEC_RW2 | |
|---|---|---|---|---|---|---|---|
| AUC & 95% CI (Whole) |
0.783 (0.772 to 0.795) |
|
0.783 (0.771 to 0.794) |
0.793 (0.782 to 0.804) |
|
0.792 (0.781 to 0.803) | |
| AUC & 95% CI (Black) |
0.747 (0.700 to 0.794) |
0.747 (0.700 to 0.794) |
0.747 (0.700 to 0.794) |
0.755 (0.705 to 0.804) |
0.752 (0.704 to 0.801) |
0.753 (0.704 to 0.802) | |
| AUC & 95% CI (White) |
0.785 (0.774 to 0.797) |
0.785 (0.774 to 0.797) |
0.785 (0.773 to 0.796) |
0.795 (0.785 to 0.806) |
0.793 (0.782 to 0.804) |
0.794 (0.783 to 0.805) | |
| Avg. EOD & 95% CI |
|
0.024 (−0.05 to 0.093) |
−
|
−0.019 (−0.099 to 0.0558) |
−0.028 (−0.101 to 0.051) |
−
|
−0.021 (−0.099 to 0.045) |
|
|
−0.043 (−0.14 to 0.049) |
−0.060 (−0.161 to 0.032) |
−0.056 (−0.16 to 0.041) |
−0.033 (−0.124 to 0.061) |
−0.030 (−0.12 to 0.064) |
−0.036 (−0.122 to 0.0442) | |
| Performance | Measurement | 2021 USPSTF Criteria | PLCOM2012 (Threshold= 0.013455) | LR-GIFT* (“ |
|
|---|---|---|---|---|---|
| Accuracy | Sensitivity | 78.08% | NA | 85.98% | 85.16% |
| Specificity | 56.48% | NA | 56.01% | 56.70% | |
| F1-Score | 13.60% | NA | 14.74% | 14.80% | |
| AUC and 95% CI (Whole) | NA |
0.788 (0.777 to 0.797) |
0.785 (0.775 to 0.796) |
| |
| AUC and 95% CI (Black) | NA |
0.770 (0.719 to 0.819) |
0.777 (0.728 to 0.818) |
| |
| AUC and 95% CI (White) | NA |
0.789 (0.779 to 0.800) |
0.786 (0.776 to 0.797) |
| |
| Fairness | Average EOD and 95% CI |
0.0673 (0.002 to 0.134) |
0.0566 (−0.015 to 0.122) |
0.0081 (−0.059 to 0.0718) |
|
|
| Paired |
Reject H0 |
Reject H0 |
Reject H0 |
|
|
Effect Size (Hedges’ | 2.45 | 1.89 | 0.28 |
| |
| CL Effect Size | 0.95 | 0.92 | 0.58 |
|
- —2023 George Edgecomb Society Pilot Research
- —Moffitt Cancer Center10.13039/100009164
- —George Edgecomb Society
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsColorectal Cancer Screening and Detection · Radiomics and Machine Learning in Medical Imaging
Introduction
Lung cancer is the leading cause of cancer-related death in the United States. In 2024, lung cancer accounted for an estimated 20% of all cancer-related deaths.1 The National Lung Screening Trial demonstrated that lung cancer screening (LCS) with low-dose computed tomography (LDCT) can detect early-stage lung cancers, reducing lung cancer mortality by up to 20%.2 In the first step of the LCS process, a screening eligibility model identifies individuals most likely to benefit from the screening.
Initially, the 2013 US Preventive Services Task Force (USPSTF) criteria were used to determine eligibility for LCS, which included age (55-80 years) and smoking history ( 30 pack-year, current smoker, or quit within the past 15 years).3 Although these criteria cover many eligible White smokers, they miss many high-risk Black smokers,4 who often develop lung cancer at younger ages, with less smoking intensity, and at more advanced stages.5-8 In 2021, USPSTF updated its guidelines by lowering the age threshold from 55 to 50 and reducing the pack-year from 30 to 20.9 While these changes have reduced racial disparities, the age and smoking history-based criteria lead to limited incidence predictive performance. As such, there still may be a risk of getting a high false positive rate and false negative rate (FNR) for Black and White individuals based on the 2021 USPSTF criteria.10^,^11
Recent studies aim to develop more accurate LCS eligibility policies. Developing risk-based eligibility models that estimate individuals’ lung cancer risk and set screening thresholds is promising—especially since machine learning (ML) can revolutionize personalized healthcare and improve early cancer detection using multidimensional datasets.8 Many models, such as the PLCO_M2012_ model12 and its variants, used logistic regression (LR) to analyze relationships among smokers’ demographic information, smoking history, personal history of any cancer, family history of lung cancer, lung-related diseases, and their lung cancer incidence from retrospective datasets. Results have shown that, compared with the 2021 USPSTF criteria, incorporating additional information can improve lung cancer risk prediction with more sensitivity or specificity within certain racial/ethnic groups.8^,^12 However, the characteristics used to predict lung cancer in these models may not be independent, and their relationship with the disease may be non-linear in clinical practice. Also, incidence predictive models which are trained on datasets with inherent racial biases can perpetuate these biases, leading to racial disparities in lung cancer predictive performance. Moreover, imbalanced Black and White classes in the dataset can provide additional racial disparities in the incidence predictive accuracy, which may further increase the level of over-diagnosis or under-diagnosis of lung cancer within certain racial/ethnic groups.
Algorithmic fairness refers to the un-coverage and rectification of biases along social axes such as race, gender, and class in automated decision processes from ML-based predictive models.13-15 LCS eligibility decisions made by such models after a learning process may be considered unfair if these decisions were based on sensitive attributes (eg, race, gender). When a healthcare organization chooses an appropriate ML–based lung cancer prediction and racial bias mitigation model for clinical decision-making regarding LCS eligibility, both the accuracy of lung cancer prediction and its fairness should be considered simultaneously. Though risk-based eligibility models (eg, the PLCO_M2012_ model) are promising for determining LCS eligibility, their fairness across different racial groups, particularly between Black and White smokers, remains underexamined.16 This gap poses a significant barrier to effectively integrating these models into clinical practice. In response, we sought to develop a systematic fairness-aware ML framework for an accurate and racially unbiased LCS eligibility model.
An important preliminary step for our research was to determine the best strategy for defining and evaluating fairness. Group fairness is a popular approach for treating 2 groups equally. With this approach, groups are typically identified by sensitive attributes, such as race or gender, and quantities are compared at the group level. Group fairness criteria mainly include demographic parity, equalized odds, and equal opportunity.17 A major shortcoming of group fairness is that it does not prevent unfairness against those who are found at the intersection of multiple types of discrimination (eg, Black females). Conversely, intersectional fairness explores the biases that might be encoded in ML models by considering different subgroups that overlap and intersect across multiple dimensions,18 potentially improving fairness and preventing fairness gerrymandering, which is the substantial violation of the fairness constraint on 1 or more structured subgroups defined over the protected attributes (eg, Black females).19
Additionally, it was crucial to identify our core bias mitigation approaches for fairness. Strategies for bias mitigation can be broadly classified as pre-processing, in-processing, or post-processing,20 each of which targets different stages of the ML model development pipeline to ensure the fairness and equity of its outcomes. Pre-processing methods tackle bias by adjusting the training data before model development21; in-processing methods modify the learning algorithms during the training process22; and post-processing methods adjust the model’s outputs after training to achieve fairer outcomes.23
Building on these insights, we developed a Group and Intersectional Fairness and Threshold (GIFT) fairness-enhancing strategy by integrating both pre- and post-processing bias mitigation approaches. To achieve a racially unbiased LCS eligibility mechanism with intersectional fairness, we defined multiple types/combinations of discrimination, which always included race. We applied the reweighing method for group fairness to intersectional fairness as a pre-processing approach,21 and then determined a risk threshold from different risk decision boundaries as a post-processing method.23
However, though this integration was devised to ensure racial parity, any bias mitigation approach will inevitably affect the accuracy of ML models.24 The GIFT fairness-enhancing strategy is not an exception, especially in handling the National Cancer Institute Prostate, Lung, Colorectal, and Ovarian (PLCO) cancer screening trial datasets25 with imbalances in both the number of participants with and without lung cancer and the distribution of Black and White participants. Given that these existing imbalances cannot be changed, it is crucial to choose an appropriate ML model to mitigate biases due to the imbalances and achieve a high lung cancer predictive performance. Typically, decision tree–based algorithms, such as bagging- and boosting-based techniques, perform well on imbalanced datasets.26 Resampling the imbalanced data before entering it into an ML model can help better capture the decision boundary of lung cancer incidence (Yes/No). Therefore, an easy ensemble classifier (EEC) model,27 which combines random under-sampling and AdaBoost classifier, is a suitable approach to handle imbalanced datasets and improve the accuracy of lung cancer prediction. In the EEC model, random under-sampling is designed to improve the accuracy for less frequently represented groups without significantly affecting predictions for the majority group. Therefore, we developed a systematic fairness-aware ML framework, named EEC-GIFT, to identify a new LCS eligibility mechanism from real-world data by embedding the GIFT strategy into the EEC-based lung cancer prediction model. All technical terms used throughout this paper are explained by a glossary in Table S1.
Methods
Assumptions and algorithmic fairness measurement
Because our study used real-world data, our fairness analysis was conducted with two major assumptions. Statistical parity difference (SPD) was used to evaluate the difference of the probabilities of lung cancer diagnosis (positive outcomes) between Black and White groups with a value of 0 indicating fairness. However, if the base rates of White and Black participants were significantly different, a fully accurate classifier to satisfy SPD = 0 may be considered unfair. Thus, our first assumption was that the base rates of Black and White smokers developing lung cancer were not significantly different. Furthermore, we used equal opportunity to define fairness across Black and White groups based on their true positive rates (TPRs)/FNRs and average equal opportunity difference (EOD) to measure and compare the fairness of LCS eligibility mechanisms (Supplementary Methods). If the base rates of Black and White participants developing lung cancer are not representative of the “true” values and were obtained with bias, a fully accurate classifier to satisfy this equal opportunity constraint may be considered unfair. Therefore, our second assumption was that Black and White participants are representative of the true real-world population, and their data were not obtained in a biased manner.
Training and testing of the EEC-GIFT–based LCS eligibility model
Our study was conducted based on the PLCO trial, where institutional review board approvals were received at all 10 sites. Informed consent was secured, and participants completed self-reported questionnaires on demographics and medical history at baseline and throughout the study.25 After performing data preparation and feature selection (Supplementary Methods), the EEC-GIFT–based LCS eligibility model was developed by integrating pre- and post-processing bias mitigation strategies and embedding them into the EEC–based lung cancer prediction model (Supplementary Methods) as illustrated in Figure 1. The pre-processing reweighing approach allows multiple sensitive attributes, and the post-processing strategy permits numerous threshold options to determine eligibility. Let be the threshold of LCS eligibility associated with the specificity of the 2021 USPSTF criteria, and “ be the threshold of LCS eligibility associated with the Youden Index28 of the ROC curve of the incidence prediction model (Supplementary Methods**)**. To proof-of-concept, we trained the best EEC-GIFT* LCS eligibility model by considering 1 (“race”) and 2 (“race” and “gender”) sensitive attributes for the pre-processing reweighing approach and assigning 2 thresholds (“ ” and “ ”) for the post-processing strategy. Additionally, we trained the best LR_GIFT*–based prediction model based on the features in the PLCO_M2012_ model and the GIFT strategy with the same sensitive attributes and threshold strategy. Then we tested the EEC-GIFT* and LR-GIFT* models and compared their accuracy and fairness to other LCS eligibility mechanisms.
Training and testing an EEC-GIFT–based LCS eligibility mechanism. The best EEC-GIFT–based LCS eligibility model can be trained by performing a grid search from stratified 10-fold cross-validation (CV) based on the training dataset to identify the optimal pre-processing strategy, the best parameters of the EEC in the EEC-GIFT*-based LCS eligibility model, and the best post-processing threshold in terms of both accuracy and fairness. Then, we applied the EEC-GIFT* model to our testing dataset to evaluate its accuracy and fairness. The details of the “Pre-Processing” reweighing strategy (training and testing) and “easy ensemble classifier (EEC)” (training) are introduced in Supplementary Methods. The “Post-Processing” threshold strategy (training) is introduced in Figure S1. The evaluations and statistical tests of “Accuracy and Fairness” (training and testing) are introduced in the Statistical Analysis section.*
Statistical analysis
We evaluated and compared the accuracy and fairness of the USPSTF criteria, PLCO_M2012_, LR-GIFT*– and EEC-GIFT*–based models. Since the USPSTF standard is a rule–based model with binary outcomes, we used sensitivity and specificity to evaluate its predictive performance and employed McNemar’s test29 to compare it with other LCS eligibility models. For risk–based models, we used area under the receiver operating characteristic curves (AUCs) to evaluate their accuracy and employed Delong’s test30 to compare their performance. All statistical tests were performed at a significance level of 0.05.
Fairness was assessed by comparing Black and White participants’ TPRs. Specifically, we used a paired t-test to evaluate a hypothesis of H_0_: average EOD = 0 and H_1_: average EOD ≠ 0. If *P < *.05, H_0_ was rejected and the Black and White groups’ TPRs were considered significantly different. Otherwise, H_0_ was failed to reject and LCS eligibility was considered fair. In addition, we used Hedges’ grm to calculate the size of this difference or effect sizes31 and employed the common language (CL) effect size32 to quantify the magnitude of disparities. Hedges’ grm offers a bias-corrected measure of the standardized difference, where values below 0.2 indicate a small effect, around 0.5 a moderate effect, and above 0.8 a large effect. The CL effect size translates this into the probability that a randomly selected individual from one group outperforms one from another group. Together, these metrics complement the t-test by highlighting both statistical significance and practical relevance.
Results
Data pre-preparation for the training and testing datasets
The original PLCO lung dataset includes 154 887 participants and 251 variables. Given Black and White smokers have higher lung cancer incidence and mortality rates than any other races,5 we focused our analysis on these 2 subgroups. We further narrowed the PLCO dataset to only include current or previous Black and White smokers who had completed the baseline questionnaire, had no history of lung cancer prior to the PLCO screening trial, and did not have any missing incidence information. This resulted in 67 612 participants and 2844 confirmed lung cancer cases. To avoid possible effects of overdiagnosis bias33^,^34 and align with the training and testing processes of other risk-based LCS eligibility models in the literature,12^,^35 we used the PLCO control arm (33 403 participants) to train the models and its intervention arm (34 209 participants) to test the models. The properties of our training dataset are illustrated in Figure 2.
The properties of our training data. (A) Shows that the number of participants who were confirmed to have lung cancer was only 4.12% of the whole population in our training dataset. (B) Illustrates that Black participants comprise only 5.74% of all participants in the training dataset. These class imbalance issues can affect the accuracy and fairness of ML-based LCS eligibility models. (C) Shows racial disparities in lung cancer incidence rates between Black (4.44%) and White (4.10%) smokers in the training dataset. However, a 2-proportion z-test confirms these incidence rates are not significantly different (P = .47), which satisfies the assumption of our study.
Best LCS eligibility mechanisms in the training phase
The selected features used to develop the EEC– and EEC-GIFT–based LCS eligibility mechanisms are shown in Table 1. Let RW1 and RW2 represent reweighing approaches associated with 1 (“race”) and 2 (“race” and “gender”) sensitive attributes, respectively. The SPD values and group/subgroup weight coefficients based on pre-processing strategies RW1 (Table S2) and RW2 (Table S3) were computed by using the pre-processing reweighting formulas (Supplementary Methods**)**. The post-processing strategy of identifying thresholds “ ” and “ ” based on an ROC curve is illustrated in Figure S1. The accuracy and fairness of different LCS eligibility mechanisms in the training phase are shown and compared in Table 2, where the best LCS eligibility models “EEC_RW1 & ” and “LR_RW1 & ” were subsequently tagged as “EEC-GIFT*” and “LR-GIFT*,” respectively. Important features to determine lung cancer risk based on the EEC-GIFT* model are shown in Figure S2.
Comparison of different LCS eligibility mechanisms during the testing phases
We bootstrapped 80% of the testing dataset 500 times and used this dataset to test and compare the accuracy and fairness of the trained LR-GIFT*– and EEC-GIFT*–based LCS eligibility mechanisms with that of the 2021 USPSTF criteria and the PLCO_M2012_–based eligibility model. Figure 3 illustrates the distributions of EODs between Black and White participants for the different LCS eligibility mechanisms. Table 3 shows that only the EEC-GIFT* model could significantly improve the fairness of LCS eligibility without compromising the accuracy of lung cancer prediction.
The EOD distributions of (A) 2021 USPSTF criteria, (B) PLCOM2012 model (threshold = 0.013455), (C) LR-GIFT (“TU” = 0.027) (D) EEC-GIFT* (“TU” = 0.0239)—based LCS eligibility mechanisms. The comparison of the EOD distributions of the LR-GIFT* and EEC-GIFT* to the 2021 USPSTF criteria and PLCOM2012 model shows that the GIFT strategy can greatly improve the fairness of ML-based incidence predictive models. With the same GIFT strategy, the fairness of the EEC-GIFT* is better than that of the LR-GIFT*, since the class imbalance issue had been solved during the process of developing the EEC model. Due to biases in the PLCO data collection, White smokers are an unfair group with a lower average TPR compared to the Black group. Our numerical experiments show that, for lung cancer diagnosis in the unfair group, the EEC-GIFT* LCS eligibility model can lead to about 10% reduction of the FNR (early detection of 104 more smokers with lung cancer) compared to the 2021 USPSTF criteria, and 5% reduction of the FNR (early detection of 46 more smokers with lung cancer) compared to the PLCOM2012 model based on the testing dataset.*
Discussion
Although accuracy and fairness are both key objectives when developing a fairness-aware ML framework to determine LCS eligibility, accuracy plays a more essential role than fairness, given that the values of TPR/FNR to measure fairness also depend on lung cancer predictive performance. Our bias mitigation strategy, GIFT, centered around equal opportunity or TPR/FNR. In the pre-processing process, we used a reweighing approach to evaluate the group weight coefficients based on sensitive attributes by pushing the value of SPD to 0. In the post-processing strategy, in addition to the threshold of “ ” generated by using equal weights to maximize the TPR and TNR of a ROC curve, we also used “ ” to increase the number of individuals who qualify for LCS by adding more weight to the TPR than the TNR. The fairness notions in the GIFT strategy are compatible in terms of equal opportunity. Notably, though in-processing methods are integrated within the ML models themselves, pre- and post-processing methods can be applied across various classification methods. Thus, our fairness GIFT strategy is a model-agnostic approach and is compatible with a wide range of ML models regardless of their specific architecture or design.
Because most participants in our training dataset did not develop lung cancer, an ML model built on this data tends to be biased towards these smokers. Given the limitation of the LR model in handling class imbalance, we used the EEC model for lung cancer prediction. This model integrates 2 key components of random under-sampling and AdaBoost. The random under-sampling intends to address class imbalances, whereas AdaBoost focuses on instances with higher sample weights at each successive iteration and adjusts the weights of misclassified classes during each training iteration. Our numerical experiments showed that, with the same racial bias mitigation GIFT* strategy, the trained EEC-GIFT* model that considers the class imbalance issue significantly increased the fairness of LCS eligibility between Black and White smokers without compromising its accuracy. Thus, we consider the EEC-GIFT approach, which integrates the GIFT strategy into the EEC model, to be a systematic fairness-aware ML framework that can identify accurate and racially unbiased risk-based eligibility models from real-world data.
Our systematic fairness-aware ML framework is still in its infancy and has several limitations. First, one of our assumptions is that the base rates for sensitive lung cancer groups/subgroups are the same; thus, our approach can only be used when there is no significant base distribution difference among different sensitive groups/subgroups. Given that recent research has revealed significant racial disparities in lung cancer incidence rates between Black and White smokers,36 we plan to develop a more robust fairness-aware ML framework for LCS eligibility determination by employing error rate disparity to better define the fairness. Second, selection bias and missing data in real-world datasets can affect lung cancer predictions. Future research should account for these “true” imbalances and mitigate their impacts on the accuracy and fairness of the LCS eligibility models. Third, our study relied on a single dataset, which may not capture the variability encountered in broader clinical practice. The homogeneity of our data raises concerns about the models’ generalizability to other population samples, potentially limiting their applicability. Further validation with additional independent datasets is essential to ensure that the EEC-GIFT framework is robust and unbiased.
This study demonstrated the concept and development of our systematic fairness-aware ML framework. The framework could be used to develop an optimal LCS eligibility mechanism by considering more sensitive attributes, evaluating other advanced ML models that can handle class imbalances, and including additional eligibility threshold choices. Our framework can also be used for other types of cancer to identify appropriate screening eligibility mechanisms.
Conclusion
This study used an EEC model, including random under-sampling and AdaBoost, to handle class imbalance issues in our training dataset and to predict lung cancer incidence for LCS eligibility identification. To mitigate racial biases in lung cancer incidence rates, we developed a fairness-enhancing GIFT strategy by integrating a pre-processing reweighing approach based on group or intersectional fairness and a post-processing eligibility threshold method with equal opportunity for Black and White participants. Applying the GIFT strategy to the EEC model resulted in a systematic fairness-aware ML framework, titled EEC-GIFT, for LCS eligibility determination. We identified LR-GIFT* and EEC-GIFT* as the best models for determining LCS eligibility in the training phase. Our testing results show that only the EEC-GIFT*–based LCS eligibility mechanism could significantly remove racial bias in the screening eligibility between Black and White participants without compromising the accuracy of lung cancer prediction. However, the systematic fairness-aware ML-based LCS eligibility model still needs to be validated with external independent datasets.
Supplementary Material
pkaf030_Supplementary_Data
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Siegel RL , Giaquinto AN, Jemal A. Cancer statistics, 2024. CA Cancer J Clin. 2024;74:12-49. 10.3322/caac.2182038230766 · doi ↗ · pubmed ↗
- 2Aberle DR , Adams AM, Berg CD, et al Reduced lung-cancer mortality with low-dose computed tomographic screening. N Engl J Med. 2011;365:395-409. 10.1056/NEJ Moa 110287321714641 PMC 4356534 · doi ↗ · pubmed ↗
- 3Moyer VA , US Preventive Services Task Force. Screening for lung cancer: U.S. Preventive Services Task Force recommendation statement. Ann Intern Med. 2014;160:330-338. 10.7326/M 13-277124378917 · doi ↗ · pubmed ↗
- 4Tindle HA , Stevenson Duncan M, Greevy RA, et al Lifetime smoking history and risk of lung cancer: results from the Framingham Heart Study. J Natl Cancer Inst. 2018;110:1201-1207. 10.1093/jnci/djy 04129788259 PMC 6235683 · doi ↗ · pubmed ↗
- 5Haddad DN , Sandler KL, Henderson LM, Rivera MP, Aldrich MC. Disparities in lung cancer screening: a review. Ann Am Thorac Soc. 2020;17:399-405. 10.1513/Annals ATS.201907-556CME 32017612 PMC 7175982 · doi ↗ · pubmed ↗
- 6Haiman CA , Stram DO, Wilkens LR, et al Ethnic and racial differences in the smoking-related risk of lung cancer. N Engl J Med. 2006;354:333-342. 10.1056/NEJ Moa 03325016436765 · doi ↗ · pubmed ↗
- 7Robbins HA , Engels EA, Pfeiffer RM, Shiels MS. Age at cancer diagnosis for Blacks compared with Whites in the United States. J Natl Cancer Inst. 2015;107:dju 489. 10.1093/jnci/dju 489PMC 432630825638255 · doi ↗ · pubmed ↗
- 8Toumazis I , Bastani M, Han SS, Plevritis SK. Risk-based lung cancer screening: a systematic review. Lung Cancer. 2020;147:154-186. 10.1016/j.lungcan.2020.07.00732721652 · doi ↗ · pubmed ↗