Nonparametric estimation via partial derivatives
Xiaowu Dai

TL;DR
This paper introduces a new nonparametric estimation method using partial derivatives that achieves faster convergence rates in high-dimensional settings.
Contribution
The novel approach uses partial derivatives to achieve near-parametric convergence rates in nonparametric estimation.
Findings
The method achieves optimal rates with gradient information equal to those without gradients in interaction models.
Additive models using gradient information reach the parametric rate of n.
Theoretical results are validated through synthetic and real data applications.
Abstract
Traditional nonparametric estimation methods often lead to a slow convergence rate in large dimensions and require unrealistically large dataset sizes for reliable conclusions. We develop an approach based on partial derivatives, either observed or estimated, to effectively estimate the function at near-parametric convergence rates. This novel approach and computational algorithm could lead to methods useful to practitioners in many areas of science and engineering. Our theoretical results reveal behaviour universal to this class of nonparametric estimation problems. We explore a general setting involving tensor product spaces and build upon the smoothing spline analysis of variance framework. For d-dimensional models under full interaction, the optimal rates with gradient information on p covariates are identical to those for the (d−p)-interaction models without gradients and,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
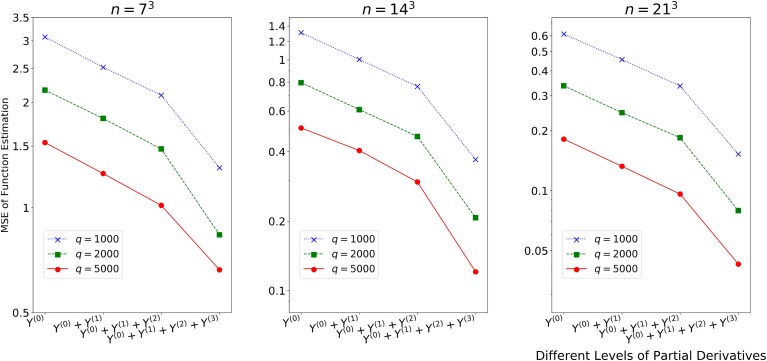 Figure 1
Figure 1| 1: |
| 2: |
| 3: |
| 4: |
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Our estimator ( |
| Our estimator ( | ||
|---|---|---|---|---|
| with only | with | with | ||
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Our estimator |
| Our estimator | |
|---|---|---|---|
| with only | with | with | |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- —Eunice Kennedy Shriver National Institute of Child Health and Human Development (NICHD)10.13039/100009633
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsControl Systems and Identification · Statistical Methods and Inference · Probabilistic and Robust Engineering Design
Introduction
1
Gradient information for complex systems arises in many areas of science and engineering. Economists estimate cost functions, where data on factor demands and costs are collected together. By Shephard’s Lemma, the demand functions are the first-order partial derivatives of the cost function (Hall & Yatchew, 2007). In actuarial science, demography provides data on the force of mortality, which, along with samples from the survival distribution, yields gradients for the survival distribution function (Frees & Valdez, 1998). In stochastic simulation, gradient estimation has been studied for a large class of problems (Glasserman, 2013). In discrete event simulation, the gradient can be estimated with a negligible computational burden compared to the effort required for obtaining a new response (Chen et al., 2013). In meteorology, wind speed and direction are gradient functions of barometric pressure and are measured over broad geographic regions (Breckling, 2012). In dynamical and time series applications, gradient information can be observed or estimated, as in biological and infectious disease modelling (Dai & Li, 2022, 2024; Ramsay et al., 2007). In traffic engineering, real-time motion sensors can record velocity in addition to positions (Solak et al., 2002).
This paper focuses on nonparametric function estimation under smoothness constraints. Rates of convergence often limit the applications of traditional nonparametric estimation methods in high-dimensional settings, where the number of covariates is large (Stone, 1980, 1982). A considerable amount of research effort has been devoted to countering this curse of dimensionality. The additive model is a popular choice (Hastie & Tibshirani, 1990; Stone, 1985). An additive model assumes that the high-dimensional function is a sum of one-dimensional functions and drops interactions among covariates in order to reduce the variability of an estimator. Stone (1985) showed that the optimal convergence rate for additive models is the same as that for univariate nonparametric estimation problems. Thus, additive models effectively mitigate the curse of dimensionality. However, additive models could be too restrictive and lead to incorrect conclusions in applications where interactions among the covariates may be present. As a more flexible alternative, smoothing spline analysis of variance (SS-ANOVA) models, the analogues of parametric ANOVA models, have attracted significant attention (Huang, 1998; Lin & Zhang, 2006; Wahba et al., 1995; Zhu et al., 2014). In particular, SS-ANOVA models include additive models as special cases. Lin (2000) proved that when interactions among covariates are in tensor product spaces, the optimal rates of convergence for SS-ANOVA models exponentially depend on the order of interaction. Thus, when SS-ANOVA models are used in problems that involve high-order interactions, they lead to the requirement of unrealistically large dataset sizes for reliable conclusions. We call this phenomenon the curse of interaction.
We develop a new approach based on partial derivatives to effectively compromise the curse of interaction. Let be the function data that follow a regression model,
Here is a random error, is a function of d covariates , and is the design point. Write as the jth partial derivative of . Let be the partial derivatives that follow a regression model,
Here s are random errors, and s are the design points in . We allow to be directly observable or estimated from function data. The denotes the number of gradient types. Without loss of generality, we focus on the first p covariates in model (2). In particular, when , model (2) gives the full gradient data. We allow for a relaxed error structure for both function and gradient data. Specifically, we assume the random errors and s in models (1) and (2) to satisfy,
where and . We assume the short-range correlation in (3) with some . This assumption is generally valid in practice, as gradient data are often estimated by using local function data through methods such as finite-difference techniques. We provide three concrete examples in online supplementary material Appendix to elaborate on the assumption (3). Moreover, random errors in (3) can be uncentred and correlated, which are typical for estimated gradients, and include the i.i.d. errors in Hall and Yatchew (2007) as a special case.
The SS-ANOVA model (Wahba et al., 1995) amounts to the assumption that
where the component functions include main effects s, two-way interactions s, and so on. Component functions are modelled nonparametrically, and we assume that they reside in certain reproducing kernel Hilbert spaces (RKHS, Wahba, 1990). The series on the right-hand side of (4) is truncated to some order r of interactions to enhance interpretability. We call as full or truncated interaction SS-ANOVA model if or , respectively. The SS-ANOVA model (4) can be identified with space,
The components of the SS-ANOVA model in (4) are in the mutually orthogonal subspaces of in (5). The additive model can be viewed as a special case of the SS-ANOVA model (4) by taking . We assume that all component functions come from a common RKHS given by for . Obviously the linear model is a special example of (4) by taking and letting be the collection of all univariate linear functions defined over . Another canonical example of is the mth order Sobolev space ; see, e.g. Wahba (1990) for further examples.
We study the possibility of near-parametric rates in the general setting of SS-ANOVA models. Suppose the eigenvalues of the kernel function decay polynomially, i.e. its νth largest eigenvalue is of the order . Our results show that the minimax optimal rates for estimating under the full interaction (i.e. ) are
The rates in (6) present an interesting two-regime dichotomy between the scenarios of and . When , the rate given by (6) matches with the minimax optimal rate for estimating a -interaction model without gradient information (Lin, 2000). For example, when with no partial derivative data, the rate from (6) is . This rate aligns with the known rate for estimating a d-interaction SS-ANOVA model (Lin, 2000). However, with a large d, this rate is heavily affected by the exponential term , which makes the estimation challenging and leads to the curse of interaction. The inclusion of gradient data provides a substantial advantage in overcoming these challenges. For instance, when , the rate in (6) becomes , which is the same as the optimal rate for estimating additive models without gradient information and independent of d (Stone, 1985). This indicates that SS-ANOVA models can be immune to the curse of interaction through the use of partial derivative data.
On the other hand, when , the rate in (6) becomes
This rate converges faster than the optimal rate for additive models . When , the rate in (6) is . If , the rate in (6) is the same as the parametric convergence rate, . It is also worth noting that when has truncated interaction (i.e. ), the rates also improve by incorporating partial derivatives, which will be discussed in Section 3. In particular, the rate for additive models (i.e. ) under matches with the parametric rate, .
In the literature, various studies have outlined the construction of linear estimators for the linear functionals of , with the difficulty of estimation characterized by a modulus of continuity (Cai & Low, 2005; Donoho, 1994; Donoho & Liu, 1991; Klemelä & Tsybakov, 2001). These studies are relevant to our work in two ways: first, they demonstrate the feasibility of achieving a parametric rate in estimating a univariate function from noisy derivative data, which aligns with the rate in our paper as a special case in the univariate context. Second, they provide the optimal rate for estimating partial derivatives of from observations of , which differs from our target of estimating itself. Our methodology and new convergence rates bridge a gap in these studies by focusing on incorporating noisy gradient data for multivariate function estimation. A similar observation of accelerated rates has been noted earlier with higher-order derivatives (Hall & Yatchew, 2007, 2010). Our results suggest that such a phenomenon holds with first-order derivatives and applies to general SS-ANOVA models involving tensor product spaces. While our theoretical comparison primarily involves Hall and Yatchew (2007) due to its seminal importance and relevance to integrating noisy gradients in nonparametric regression, we recognize the continuous advancements in the field over the last decade. These developments include applications of joint models (1) and (2) in areas such as stochastic simulations and Gaussian process methodologies, where gradient data enhances estimation and prediction (see, e.g. Chen et al., 2013; Fu & Qu, 2014; Lim, 2024; Riihimäki & Vehtari, 2010; Wang & Berger, 2016; Zhang et al., 2023). Nonetheless, a comprehensive statistical theory explaining the benefit of incorporating noisy gradient data has been lacking. This paper develops a theoretical framework that shows how gradient data can mitigate the curse of interaction and significantly enhance the scalability of nonparametric modelling, especially for high-dimensional SS-ANOVA models.
Our contributions
1.1
We develop an approach and computational algorithm that incorporate partial derivatives, leading to methods useful for practitioners in many areas of science and engineering. We have derived a new theory that reveals behaviour universal to this class of nonparametric estimation problems. Our approach and theoretical results differ considerably from existing works in multiple ways, summarized as follows.
First, our results broaden the i.i.d. error structure by allowing the random errors in function data and gradient data to be biased and correlated. This relaxed assumption aligns with applications where the gradient data are estimated (Chen et al., 2013).
Second, we develop a new approach and computational algorithm in RKHS that easily incorporates gradient information. The proposed estimator also offers interpretability by providing a direct description of interactions. We find that partial derivatives can reduce interactions in terms of the minimax convergence rates.
Finally, we obtain a sharper theory on estimation with partial derivatives. We show that when , the optimal rate for estimating d-dimensional SS-ANOVA models under full interaction is , which is independent of the interaction order r. Thus, the SS-ANOVA models are immune to the curse of interaction when using gradients. In contrast, Hall and Yatchew (2007) showed that when , the convergence rate for estimating d-dimensional functions is , which suffers from the curse of dimensionality in d. Therefore, our results demonstrate that partial derivatives are beneficial for the scalability of nonparametric estimation in high dimensions, particularly when using SS-ANOVA models.
The rest of the sections are organized as follows: We first provide background in Section 2, and present main results in Section 3. Section 4 presents both synthetic and real data examples. Section 5 discusses related works. We conclude in Section 6. The results under other types of designs and their proofs, along with additional numerical examples, are relegated to the online supplementary material Appendix.
Background
2
We begin with a motivating example with partial derivatives. Then we briefly review basic facts about RKHS for the setting of our interest.
Motivating example
2.1
We study a stochastic simulation application to motivate models (1) and (2). Let be the response of a stochastic simulation, which has a design point and a random variable ω. It is of interest to build fast and accurate estimation for (Chen et al., 2013; Glasserman, 2013). At each replication , the stochastic simulation has a different random variable . A user can select design and run the stochastic simulation to obtain a response , where is i.i.d. centred simulation noise. In practice, it is common to average responses to reduce the variance of simulation noises, i.e. let , where q is the number of simulation replications and is at the order of hundreds or thousands. Then the response follows model (1), where is the averaged simulation noise. Under regularity conditions ensuring the interchange of expectation and differentiation (L’Ecuyer, 1990), the infinitesimal perturbation analysis (IPA) gives the gradient estimator of that follows model (2),
Moreover, the IPA estimators are unbiased, (Glasserman, 2013). We provide details of our stochastic simulation in Section 4.1. The results are reported in Figure 1, which shows mean-squared errors (MSEs) for varying sample size n, replication number q, and different methods. Those include stochastic kriging with function data (i.e. ), our estimator with function and one type of gradient data (i.e. ), two types of gradient data (i.e. ), the full gradient data (i.e. ). A significant decrease in MSEs is observed when incorporating partial derivatives. Moreover, the computational cost for obtaining the gradient estimator is relatively low, as calculating the IPA estimator does not need additional replication of the simulation. In contrast, getting a new function response requires q new replications of the simulation, and each replication could incur a high cost.
Estimation error of our estimator incorporating different levels of gradient information, for the stochastic simulation example. The y-axis is in the log scale.
Reproducing kernel for partial derivatives
2.2
We briefly review some basic facts about RKHS. Interested readers are referred to Aronszajn (1950) and Wahba (1990) for further details. Let K be a Mercer kernel that is a symmetric positive semidefinite and square-integrable function on . It can be uniquely identified with the Hilbert space that is the completion of under the inner product . Most commonly used kernels are differentiable, which we shall assume in what follows. In particular, we assume that
where is the space of continuous functions. Let the kernel . Then is the kernel corresponding to the RKHS in (5); see, e.g. Aronszajn (1950). The condition (7) together with the continuity of yield that for any , . Thus, the gradient is a bounded linear functional in and has a representer . By Mercer’s theorem (Riesz, 1955), the kernel function K admits an eigenvalue decomposition:
where are eigenvalues and are the corresponding eigenfunctions. For example, for under the Lebesgue measure (Wahba, 1990), which will be also discussed in online supplementary material Appendix.
Main results
3
In this section, we present a new approach for nonparametric estimation via partial derivatives and develop a fast algorithm. We also derive a new theory and show a convergence behaviour universal to this class of estimation problems.
Estimation via partial derivatives
3.1
We introduce a method that merges function and derivative information for better estimation. When the function in (4) is smooth in , we add the empirical loss of partial derivatives as a penalty. Combining these information, we derive the function that meets the smoothness criteria and aligns closely with the observed data,
Here is an appropriately chosen Hilbert radius, and is a weight parameter, where a natural choice is . If and are unknown, we can replace them with consistent estimators for variances (Hall et al., 1990). The concept of derivative-based penalty has also been employed in the generalized profiling approach of Ramsay et al. (2007), which derives a penalty by comparing the derivative of the estimated function to a trajectory generated by ordinary differential equations (ODEs). However, the approach in (9) is different by directly comparing the derivative of the estimated function with either observed or estimated derivatives at discrete data points, which avoids the complexities associated with ODE computations. The following theorem gives a closed-form solution to (9).
Theorem 1Assume that kernel K satisfies the differentiability condition (7). Then, for any , there exists a minimizer of (9) in a finite-dimensional space,
where the coefficients for .
This theorem is a generalization of the well-known representer lemma for smoothing splines (Wahba, 1990). It in effect turns an infinity-dimensional optimization problem into an optimization problem over finite number of coefficients. We will devise a fast algorithm for this optimization in Section 3.2 and show its scalability for large data.
The estimator (9) is different from existing methods of incorporating gradients. For example, Morris et al. (1993) proposed a stationary Gaussian process to combine noiseless gradients, whereas the estimator (9) applies to noisy gradients. Hall and Yatchew (2007) studied a regression-kernel estimator to incorporate noisy derivatives and required special structures on the observed derivatives. However, the estimator (9) can incorporate all types of estimated or observed partial derivatives. Hall and Yatchew (2010) used a series-type estimator but could have a curse of dimensionality problem. In contrast, (9) can scale up to a large dimension d. Chen et al. (2013) considered a stochastic kriging method, where the correlation coefficients between gradients and function data are required to be estimated. Differently, it is unnecessary to estimate such correlations for implementing (9). Moreover, we will demonstrate that the estimator (9) outperforms competing alternatives through numerical examples in Section 4.
Computational algorithm
3.2
We now develop a fast algorithm for computing the minimizer in Theorem 1. Note that can be further written as, for any ,
where . The column vector has the νth element equal to for . The vector is generated by the Kronecker product that combines two vectors and into a single vector, where for each element in the first vector , we multiply the entire second vector by that element, and the resulting vectors from each multiplication are then concatenated, forming a long vector that captures all pairwise interactions between the elements of and . Similarly, is the Kronecker product of the r corresponding vectors. Here is the infinite-dimensional coefficient vector, where .
The key idea is to employ the random feature mapping (Dai et al., 2023; Rahimi & Recht, 2007) to approximate the kernel function, which enables us to construct a projection operator between the RKHS and the original predictor space. Specifically, if the kernel functions that generate are shift-invariant, i.e. , and integrate to one, i.e. , then the Bochner’s theorem (Bochner, 1934) states that such kernel functions satisfy the Fourier expansion:
where is a probability density defined by
We note that many kernel functions are shift-invariant and integrate to one. Examples include the Matérn kernel, , the Laplacian kernel, , the Gaussian kernel, , and the Cauchy kernel, , where are the normalization constants, and are the scaling parameters. It is then shown that (Rahimi & Recht, 2007) the minimizer in Theorem 1 can be approximated by,
where , and is a vector of s Fourier bases with the frequencies drawn from the density , i.e.
and , and so on. We write the augmented random feature vector as,
Then the minimizer in Theorem 1 can be approximated by,
We estimate the coefficient vector by minimizing the following convex objective function,
where is the penalty parameter. We remark that the penalty in (14) is different from the penalty in kernel ridge regression (Wainwright, 2019), which takes the form . Since the random feature mapping generally cannot form an orthogonal basis, there is no closed-form representation of the RKHS norms in our setting. As a result, the kernel ridge regression penalty is difficult to implement, and instead we adopt the penalty in (14) that is easy for computing. We choose the smoothing parameter λ in (14) by generalized cross-validation (GCV) (Golub et al., 1979). Let be the influence matrix as , where y is the vector of function and gradient data , and is the estimate, . Then GCV selects by minimizing the following risk,
The use of random feature mapping achieves potentially substantial dimension reduction. More specifically, the estimator in (13) only requires to learn the finite-dimensional coefficient , compared to the estimator in (10) that involves an infinite-dimensional vector for . It is known that the random feature mapping obtains the optimal bias-variance tradeoff if s scales at a certain rate and when n grows (Rudi & Rosasco, 2017). We note that the random feature mapping also efficiently reduces the computational complexity. Given any , the computation complexity of the estimator in (13) is only , compared to the computation complexity of the kernel estimator in Theorem 1 that is . The saving of the computation is substantial if as n grows.
Algorithm 1: Estimation via partial derivatives.
We summarize the above estimation procedure in Algorithm 1.
Minimax optimality
3.3
We show that our proposed estimator achieves optimality. Suppose that design points in (1) and s in (2) are independently drawn from and s, respectively, where and s have densities bounded away from zero and infinity. We first present a minimax lower bound in the presence of partial derivatives.
Theorem 2Assume that for some and the kernel K admits the decomposition in (8). Under the regression models (1) and (2) where follows the SS-ANOVA model (4) and . Then under the error structure (3), there exists a constant c such that
where the infimum of is taken over all measurable functions of the data.
This lower bound is new in the literature, and its proof is established via Fano’s lemma (Tsybakov, 2009). Next, we show that the lower bound is attainable via our estimator.
Theorem 3Assume that for some and the kernel K admits the decomposition in (8). Under the regression models (1) and (2) where follows the SS-ANOVA model (4) and . Then under the error structure (3) and with the number of random features in (11) set to , the estimator in (13) satisfies
Here the tuning parameter λ in (14) is chosen by when , and when , and when , and when , .
The proof of Theorem 3 relies on several techniques from empirical process and stochastic process theory, including the linearization method and operator gradients. In our analysis of SS-ANOVA models incorporating gradient information, unlike the approach by Lin (2000) which lacks such data, we have developed a method for the simultaneous diagonalization of two positive definite kernels: one including only function data, and the other incorporating both function and gradient data. We have obtained sharper results on the minimax rates of convergence than those in Lin (2000). Moreover, Theorem 3 demonstrates that the optimal rate in (15) can be achieved with the random feature estimator , as defined in (13). This represents another contribution compared to Lin (2000).
Theorems 2 and 3 together immediately imply that the minimax optimal rate for estimating is
This result connects with two strands of literature–estimating SS-ANOVA models without gradient information, and estimating nonparametric functions using derivatives.
First, in the case of estimating SS-ANOVA models without gradient information, the result in (15) recovers the rate known in the literature (see, e.g. Lin, 2000),
For a high-order interaction r, the exponential term in (16) introduces the curse of interaction and makes the SS-ANOVA models impractical. Surprisingly, the result in (15) shows that incorporating gradient data mitigates this curse. For example, when , the rate given by (15) becomes,
This rate is identical to the minimax optimal rate for estimating a -interaction model without gradient information (Lin, 2000). Increasing p types of gradient data to accelerates the rate at the order of , where and . Moreover, when , the rate given by (17) is , which coincides with the optimal rate for estimating additive models without gradient information (Stone, 1985). The result in (15) indicates a phase transition from to . Specifically, the rate with full gradient is further improved compared to that with . We also note that when the SS-ANOVA models have full interaction with , the result in (15) yields the special result in (6).
Second, in the case of estimating functions using derivatives, Hall and Yatchew (2007) pioneered the proposal of a regression-kernel method for incorporating derivative data under random design and i.i.d. errors. Hall and Yatchew (2007) proved that with first-order partial derivatives, their estimator achieves the rate for general Hölder spaces (e.g. their Theorem 3). This rate converges slower than the rate given by (15) when , and it suffers from the curse of dimensionality when d is large. In contrast, our work, employing a reproducing kernel approach within the function space of SS-ANOVA models, a subspace of Hölder spaces characterized by a tensor product structure, achieves the improved convergence rate in (15). This new result shows the practical value of gradient information in enhancing the scalability of nonparametric modelling, especially in high-dimensional settings typical of SS-ANOVA models.
Extension of the main results
3.4
We discuss various ways to extend the optimal rates established in Theorems 2 and 3. For instance, these rates can be adapted to scenarios where the function values and partial derivatives have different sample sizes. Let denote the sample size for the dataset , where . By applying the same arguments as in our proofs, the rate in these theorems can be expressed as
This rate is essentially the minimum of two scenarios: the rate obtained by replacing (15) in terms of the value of and the conventional rate (16) based solely on the function data with samples. If the sample size for noisy function values is significantly smaller than , the optimal rate in (15) still holds with . In this case, the noisy function values contribute to anchoring the absolute level of the function, making function estimation identifiable. Conversely, if the dataset of noisy function values alone is substantially large, i.e. is much greater than , the convergence rate by Theorems 2 and 3 aligns with the conventional rate (16) based solely on the noisy function values.
The optimal rates in Theorems 2 and 3 also apply under deterministic designs, where the design points in (1) and in (2) are equally spaced in , rather than independently drawn from distributions and , respectively. The results for deterministic designs are given in online supplementary material Appendix S1. Additionally, the optimal rates are valid under a more general error assumption than (3). Specifically, they hold when . A rigorous proof of Theorem 3 under this general error assumption follows a similar argument to that of the original proof.
Finally, we discuss additive models, which can be regarded as a special case of the SS-ANOVA model (4) by setting . In this scenario, with gradient data available where , Theorems 2 and 3 suggest that the estimation of additive models can achieve the parametric rate of , which is a significant improvement over the traditional optimal rate of typically achieved without gradient information (Stone, 1985). We provide intuition behind achieving the parametric rate in additive models to illustrate the benefits of incorporating gradient information in statistical estimations. Heuristically, for a univariate function , the problem of estimating with noisy gradient data is analogous to settings where is observed with noise, but the integral of is the estimation target, which can achieve the parametric rate through nonlocal averaging (Donoho, 1994; Donoho & Liu, 1991). This analogy suggests that the availability of gradient data eliminates the need for smoothing or local averaging, typically necessary in nonparametric estimation, thus allowing for a faster parametric rate. In the case of multivariate additive models, where , gradient data effectively provides observations on the derivatives of each component function, , enabling the estimation of each component at the parametric rate and, consequently, the entire function .
Applications
4
In this section, we demonstrate the aspects of our method and theory via various applications. We study a stochastic simulation example in Section 4.1, and an economics example in Section 4.2. We analyse a real data experiment of ion channel in Section 4.3.
Call option pricing with stochastic simulations
4.1
We discussed a motivating example of stochastic simulation in Section 2.1. Now we consider a detailed stochastic simulation of the call option pricing. The Black–Scholes stochastic differential equation is commonly used to model stock price at time T through
where is the Wiener process, is the risk-free rate, and is the volatility of the stock price. The equation has a closed-form solution: with the standard normal variable ω and initial stock price . The European call option is the right to buy a stock at the prespecified time T with a prespecified price . The value of the European option is
where . Our goal is to estimate the expected net present value of the option with fixed T and : . It can be seen that follows the SS-ANOVA model (4). In the experiment, we fix , , and choose the design from equally spaced points from , , and with the sample size . The end points of each interval are always included. We set the number of random feature for constructing the random feature estimator in (13). To address the impact of stochastic simulation noise, we simulate i.i.d. replications of at each design point and then average the responses. Independent sampling is used across design points. It is known that IPA estimators for the gradient: , , are given by Glasserman (2013),
The IPA estimators (18) are unbiased, , . We show in online supplementary material Appendix S2 that the error assumption (3) holds for IPA estimators in (18). In this example, obtaining function data at a new design point requires the generation of q new random numbers and the computation of for each of these q simulation replications. In contrast, the gradient estimator given by (18) can be obtained at a negligible cost and without a new simulation.
Comparison with existing method
Stochastic kriging (Ankenman et al., 2010; Chen et al., 2013) is a popular method for the mean response estimation of a stochastic simulation. We compare the results of our estimator (13) incorporating gradient information and the stochastic kriging method without gradient. Consider the tensor product Matérn kernel,
This kernel satisfies the differentiability condition (7), where lengthscale parameters s are chosen by the fivefold cross-validation. We use the actual output as the reference given by when , where and is the CDF of standard normal distribution. We estimate the by a Monte Carlo sample of test points in .
Figure 1 reports the MSEs for different methods: stochastic kriging with only function data (i.e. ), our estimator with different types of gradient data. The results are averaged over simulations in each setting. It is seen that our estimator with gradient data gives a substantial improvement in estimation compared to stochastic kriging without gradient. For example, the MSE of with full gradient (i.e. ) is comparable to the MSE of without gradient (i.e. ). Since it needs little additional cost to estimate gradients by (18), our estimator essentially saves the computational cost of sampling at new designs. It is also seen that a faster convergence rate is obtained when incorporating all gradient data (i.e. ) compared to . This confirms our theoretical finding in Section 3.3.
Table 1 reports the ratios of the MSE of our estimator with two types of gradient data (i.e. ) relative to the MSE of stochastic kriging with only function data (i.e. ). It is seen that incorporating gradient data leads to a faster convergence rate, which also agrees with our finding in Section 3.3.
Cost estimation in economics
4.2
We consider an economic problem of the cost function estimation. Write the cost function , where denotes the level of output and represent the prices of factor inputs. The Cobb–Douglas production function (Varian, 1992) yields that
Here is the efficiency parameter, are elasticity parameters, and . Our goal is to estimate the cost function . The function data of are observed at design . The gradient data of with respect to input prices are the quantities of factor inputs that are also observable (Hall & Yatchew, 2007),
Here for that typically follows a random design. Moreover, the observational errors are usually assumed to be i.i.d. (Hall & Yatchew, 2007) and hence satisfy the error structure (3). Since the gradient data about is not usually observable, it motivates our modelling of in model (2). Clearly, in this example follows the SS-ANOVA model (4). In the experiment, we consider and fix since the cost function is homogeneous of degree one in , that is . The data are generated through,
where , and the designs follow the i.i.d. uniform distribution in . Suppose that are Gaussian with zero means, standard deviations , and correlation ρ. We consider varying sample size , the correlation , and set the number of random feature for constructing the random feature estimator in (13).
Comparison with existing method
Hall and Yatchew (2007) proposed a regression-kernel method for incorporating gradient for cost function estimation. We compare the performance of our estimator (13) with that of Hall and Yatchew’s estimator. For the estimator in Hall and Yatchew (2007), we follow Hall and Yatchew’s Example 3 to use the tensor product Matérn kernel (19) to average and directions locally, and then average the estimates. The MSE is estimated by a Monte Carlo sample of test points in .
Table 2 reports the MSEs and standard errors for varying sample size n, correlation ρ, and different methods: our estimator with only function data (i.e. ), Hall and Yatchew’s estimator with function and gradient data (i.e. ), our estimator with function and gradient data (i.e. ). The results are obtained over simulations in each setting. It is seen that MSEs and standard errors of incorporating gradient information are significantly smaller than that without gradient. Moreover, the performances of our estimator compare favourably with that of Hall and Yatchew’s estimator.
Table 3 reports the ratios of the MSE of our estimator incorporating two types of gradient data (i.e. ) relative to the MSE of Hall and Yatchew’s estimator incorporating two types of gradient data (i.e. ). It is seen that the ratio decreases with the sample size, which agrees with our theoretical finding in Section 3.3, since our estimator in this example converges at the rate by Theorem 3, and Hall and Yatchew’s estimator converges at a slower rate .
Tables 2 and 3 also indicate that yields sufficient accuracy for the estimations by the random feature estimator in (13). Therefore, in practical applications, an s significantly smaller than the theoretical minimum of in Theorem 3 might often suffice.
Ion channel experiment
4.3
We consider a real data example from a single voltage clamp experiment. The experiment is on the sodium ion channel of the cardiac cell membranes. The experiment output measures the normalized current for maintaining a fixed membrane potential of and the input is the logarithm of time. The sample size of the ion channel experiment is . Computer model has been used to study the ion channel experiment (Plumlee, 2017). Let be the computer model that approximates the physical system for the ion channel experiment, where x is the experiment input and is the calibration parameter whose value are unobservable. For analysing the ion channel experiment, the computer model is given by , where , , , and
Our goal is to estimate the function, , which is useful for visualization, calibration, and understanding how well the computer model approximates the physical system in this experiment (Kennedy & O’Hagan, 2001). The function data at design is generated by,
The gradient of computer model, i.e. , can be obtained using the chain rule-based automatic differentiation. By the cheap gradient principle (Griewank & Walther, 2008), the cost for computing is at most four or five times the cost for function evaluation and hence, the gradient is cheap to obtain. Then the estimator for the gradient of is given by,
In the experiment, we choose i.i.d. uniform designs for s, from with the sample size .
Comparison with existing method
Morris et al. (1993) proposed a stationary Gaussian process method to incorporate gradient data for estimation. We compare the performance of our estimator (13) with that of Morris et al.’s estimator. We use the Matérn kernel (19) for both our estimator and Morris et al.’s estimator, and estimate the MSE by a Monte Carlo sample of test points in . We set the number of random feature for constructing the estimator (13). Since the true function is unknown at each test point, we approximate it by using total real ion channel samples at each test point. The function and gradient training data are generated using real ion channel samples, which are randomly chosen from the total samples.
Table 4 reports the MSEs and standard errors for varying sample size n and different methods: our estimator with only function data (i.e. ), Morris et al.’s estimator with function and gradient data (i.e. ), our estimator with function and gradient data (i.e. ). The results are obtained over simulations in each setting. It is evident that the gradient data can significantly improve the estimation performance, and our estimator outperforms Morris et al.’s estimator.
Related work
5
We review related work from multiple fields of literature, including nonparametric regression, function interpolation, and dynamical systems.
There is a growing body of literature on nonparametric regression with derivatives. Our work relates to the pioneering work of Hall and Yatchew (2007, 2010), which established the root-n consistency for nonparametric estimation given mixed and sufficiently higher-order derivatives. However, obtaining higher-order derivatives in practice, such as in economics and stochastic simulation, is challenging. In contrast, we focus on gradient information, which comprises first-order derivatives that are easier to obtain in practice. We demonstrate that the minimax optimal rates for estimating SS-ANOVA models are accelerated by using gradient data. In particular, we show that SS-ANOVA models are immune to the curse of interaction when gradient information is utilized.
Function interpolation with gradients has been widely studied. For exact data and one-dimensional functions, Karlin (1969) and Wahba (1971) showed that at certain deterministic designs for data without gradients, incorporating gradients into the dataset provides no new information for function interpolation. However, this result cannot be extended to the case of noisy data. Morris et al. (1993) incorporated noiseless derivatives for deterministic surface estimation in computer experiments. Unlike these works, we consider noisy gradient information for nonparametric estimation.
Our work is also related to the literature on dynamical systems and stochastic simulation. Solak et al. (2002) considered the identified linearization around an equilibrium point for estimating derivatives in nonlinear dynamical systems, using Gaussian processes for a combination of function and derivative observations. Chen et al. (2013) used stochastic kriging to incorporate gradient estimators and improve surface estimation, where stochastic kriging (Ankenman et al., 2010) is a metamodelling technique for representing the mean response surface implied by a stochastic simulation. However, the rates of convergence are not studied in the works by Solak et al. (2002) and Chen et al. (2013). We quantify the improved rates of convergence in nonparametric estimation by using gradient data.
Conclusion
6
Statistical modelling of gradient information has become an increasingly important issue in many areas of science and engineering. We have developed an approach based on partial derivatives, either observed or estimated, to effectively estimate nonparametric functions. This proposed approach and computational algorithm could lead to methods useful for practitioners. Our theoretical results demonstrate that SS-ANOVA models are immune to the curse of interaction when using gradient information. Moreover, for additive models, the rates using gradient information achieve the parametric rate of root-n.
As a working model, we assume that the eigenvalues decay at the same polynomial rate across component RKHSs, , which is characteristic of Sobolev kernels, among other commonly used kernels. It is of interest to consider incorporating gradient information in more general settings, for example, when eigenvalues decay at different rates, or if the eigenvalues for some components decay exponentially. These directions will be left for future studies.
Supplementary Material
qkae093_Supplementary_Data
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ankenman B. E., Nelson B. L., & Staum J. (2010). Stochastic kriging for simulation metamodeling. Operations Research, 58(2), 371–382. 10.1287/opre.1090.0754 · doi ↗
- 2Aronszajn N. (1950). Theory of reproducing kernels. Transactions of the American Mathematical Society, 68(3), 337–404. 10.1090/tran/1950-068-03 · doi ↗
- 3Bochner S. (1934). A theorem on Fourier-Stieltjes integrals. Bulletin of the American Mathematical Society, 40(4), 271–276. 10.1090/bull/2003-40-04 · doi ↗
- 4Breckling J. (2012). The analysis of directional time series: Applications to wind speed and direction. (Vol. 61). Springer Science & Business Media.
- 5Cai T. T., & Low M. G. (2005). On adaptive estimation of linear functionals. The Annals of Statistics, 33(5), 2311–2343. 10.1214/009053605000000633 · doi ↗
- 6Chen X., Ankenman B. E., & Nelson B. L. (2013). Enhancing stochastic kriging metamodels with gradient estimators. Operations Research, 61(2), 512–528. 10.1287/opre.1120.1143 · doi ↗
- 7Dai X., & Li L. (2022). Kernel ordinary differential equations. Journal of the American Statistical Association, 117(540), 1711–1725. 10.1080/01621459.2021.188246636845295 PMC 9949731 · doi ↗ · pubmed ↗
- 8Dai X., & Li L. (2024). Post-regularization confidence bands for ordinary differential equations. Journal of Machine Learning Research, 25(23), 1–51. https://jmlr.org/papers/v 25/22-0487.html